Linux C 知识点笔记
1. 可变长的参数列表
-
首先说明一下函数参数传递的原理:
-
函数参数是以栈的形式存取,从右至左入栈。
-
参数的内存存放格式:参数存放在内存的堆栈段中,在执行函数的时候,从最后一个最开始入栈。因此栈底高地址,栈顶低地址,举个例子如下:
-
1void func(int x, float y, char z); -
调用函数的时候,实参 char z 先进栈,然后是 float y,最后是 int x,因此在内存中变量的存放次序是 x->y->z。从理论上说,我们只要探测到任意一个变量的地址,并且知道其他变量的类型,通过指针移位运算,则总可以顺藤摸瓜找到其他的输入变量。
-
-
需要注意的是,这种参数入栈的顺序可能受到编译器、操作系统和函数调用约定的影响。不同的编译器和操作系统可能采用不同的参数传递方式(如寄存器传递、栈传递等),所以具体的实现细节可能会有所不同。但是,通常情况下,函数参数是按照从右到左的顺序在栈中入栈的。
-
-
C语言可创建接收参数个数不确定的函数。如常用的标准库函数printf就是一个接收参数个数可变的函数。函数printf至少要接收一个字符串作为它的第一个实参。但事实上,printf还能够接收任意数目的其他实参。printf的函数原型是:
int printf(const char *format, ...);
其中的省略号(…)表示这个函数可以接收可变数目的各种类型的实参。
需要注意:这个省略号必须放在形参列表的末尾。
可变参数头文件
<stdarg.h>中的宏和定义,为创建一个可变长参数列表的函数提供了必须的功能。stdarg.h可变长参数列表类型和宏。
-
标识符 说明 va_list 该类型适合于保存宏va_start、va_arg、和va_end所需的信息。为了访问到一个可变长参数列表中的参数,必须定义一个类型为va_list的对象。本质就是一个指针。 va_start 在一个可变长参数列表中的参数被访问前,先调用这个宏。这个宏将初始化用va_list声明的对象,以供va_arg和va_end使用。作用是使得va_list对象指向可变参数表里面的第一个参数。 va_arg 这个宏展开成一个表示可变长参数列表中下一个参数的值的表达式,值的类型由宏的第二个参数决定。每次对va_arg的调用都要修改用va_list声明的对象,以使这个对象指向列表中的下一个实参 va_end 释放指针,将输入的参数 ap 置为 NULL。通常va_start和va_end是成对出现。 va_copy 制作可变参数函数参数(函数宏)的副本(不常用) -
使用上面的宏获取参数的步骤如下:
<Step 1> 定义一个 va_list 类型的变量,(假设va_list 类型变量被定义为ap); <Step 2> 调用va_start ,对ap 进行初始化,让它指向可变参数表里面的第一个参数。
<Step 3> 获取参数,并使用参数。
<Step 4> 获取所有的参数之后,将 ap 指针关掉。
-
示例
-
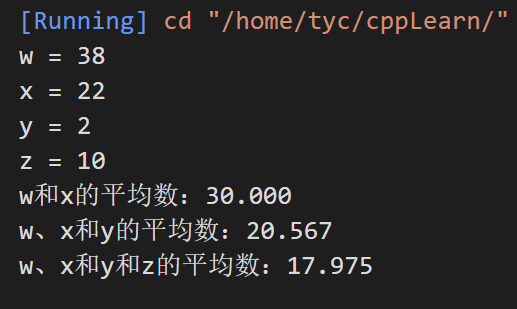
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28#include <stdarg.h> #include <stdio.h> double average(int i, ...) { double total = 0; va_list ap; // 指向传入的第一个可选参数 va_start(ap, i); for (int j = 1; j <= i; ++j) { total += va_arg(ap, double); } va_end(ap); return total / i; } int main() { double w = 37.5; double x = 22.5; double y = 1.7; double z = 10.2; printf("w = %.lf\nx = %.lf\ny = %.lf\nz = %.lf\n", w, x, y, z); printf( "w和x的平均数:%.3f\nw、x和y的平均数:%.3f\nw、x和y和z的平均数:%.3f\n", average(2, w, x), average(3, w, x, y), average(4, w, x, y, z)); } -
-
值得注意的是,C++11在标准库中提供了
initializer_list类,用于处理参数数量可变但是类型相同的情况。 -
需要说明的是,C++还有可变参数模板 Variadic Template。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26#include <bits/stdc++.h> using namespace std; // 定义 void print() {} //为了结束递归 template <typename T, typename... Types> void print(T firstArg, Types... args) { std::cout << firstArg << '\n'; // print first argument print(args...); // call print() for remaining arguments } int main() { string s("hello!"); // 使用 print(7.5, "fff", 9, s); return 0; } /*输出结果 7.5 fff 9 hello!
2. vsnprintf 函数
-
vsnprintf函数用于将一组变长参数格式化为一个字符串,并将其存储到一个字符缓冲区buffer中。
-
与sprintf()函数不同的是,vsnprintf()函数使用一个va_list参数,该参数包含要格式化的变长参数列表。这使得vsnprintf()函数更加灵活,可以根据需要在运行时传递变长参数列表,而不需要在编译时指定参数类型和数量。
-
示例
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20#include <stdarg.h> #include <stdio.h> void my_printf(const char *str, ...) { char buffer[100]; int len; va_list args; va_start(args, str); // 返回长度,最后自动添加 '\0' 表示结束,这不算在长度里面 len = vsnprintf(buffer, sizeof(buffer), str, args); va_end(args); printf("Result: %s, length: %d\n", buffer, len); } int main() { my_printf("My name is %s and my age is %d", "Alice", 88); return 0; } -

3. fork函数
-
fork系统调用用于创建一个新进程,称为子进程,它与进程(称为系统调用fork的进程)同时运行,此进程称为父进程。创建新的子进程后,两个进程将执行fork()系统调用之后的下一条指令。子进程使用相同的pc(程序计数器),相同的CPU寄存器,在父进程中使用的相同打开文件。
它不需要参数并返回一个整数值。下面是fork()返回的不同值。
负值:创建子进程失败。
零:返回到新创建的子进程。
正值:返回到父进程或调用者。返回值为新创建的子进程的进程ID 。
-
有两个注意点
- fork()系统调用是Unix下以自身进程创建子进程的系统调用,一次调用,两次返回,如果返回是0,则是子进程,如果返回值>0,则是父进程(返回值是子进程的pid),这是众为周知的。
- 还有一个很重要的东西是,在fork()的调用处,整个父进程空间会原模原样地复制到子进程中,包括指令,变量值,程序调用栈,环境变量,缓冲区,等等。
-
示例1
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <sys/types.h> #include <sys/wait.h> int main(void) { int x = 2; printf("hello world (pid:%d)\n", (int)getpid()); int rc = fork(); if (rc < 0) { fprintf(stderr, "fork failed\n"); exit(1); } else if (rc == 0) { // 子进程 x++; printf("hello, I am child (pid:%d)\n", (int)getpid()); printf("x = %d\n", x); } else { x--; printf("hello, I am parent of %d (pid:%d)\n", rc, (int)getpid()); printf("x = %d\n", x); } printf("pid = %d\n", (int)getpid()); printf("x = %d\n", x); wait(NULL); return 0; } -
输出结果为
-
1 2 3 4 5 6 7 8 9hello world (pid:2486) hello, I am parent of 2487 (pid:2486) x = 1 hello, I am child (pid:2487) x = 3 pid = 2487 x = 3 pid = 2486 x = 1 -
从结果可以看到,返回值就是子进程id,且从fork后开始,子进程和父进程的执行代码是一样的,变量也是一样的,但是两者之间并不共享,而是各自独立的变量。
-
示例2
-
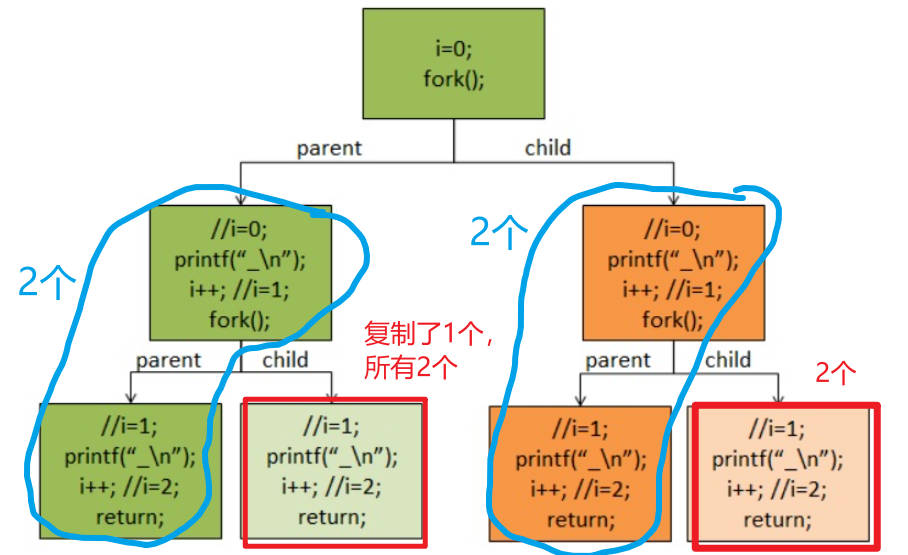
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <sys/types.h> #include <sys/wait.h> int main(void) { int i; for (i = 0; i < 2; i++) { fork(); printf("g"); } wait(NULL); wait(NULL); return 0; } -
问题是:以上程序会输出多少个 “g”。
-
实际结果是8个,而不是6个。
-
可以借以下这张图解释一下。i=0,创建了一个子进程,此时共两个进程,输出2个g;i=1,再次创建,变成4个进程,按理论是输出4个g;i=2,结束。
-
可以看到,理论上应该输出2+4=6个g。
-

-
但实际是8个。
-
输出8个的原因,是因为因为printf(“g“);语句有buffer,所以,对于上述程序,printf(“g“);把“g”放到了缓存区中,并没有真正的输出。
-
而从上面所讲,子进程会把父进程的缓冲区内存也复制一份。
-
在fork的时候,缓存被复制到了子进程空间,所以,就多了两个,就成了8个,而不是6个。
-
-
我们知道,Unix下的设备有“块设备”和“字符设备”的概念。
所谓块设备,就是以一块一块的数据存取的设备,字符设备是一次存取一个字符的设备。
磁盘、内存都是块设备,字符设备如键盘和串口。块设备一般都有缓存,而字符设备一般都没有缓存。
-
对于上述的问题,我们如果修改一下上面的printf的那条语句为:
-
1 2 3 4printf("g\n"); // 或者 printf("g"); fflush(stdout); -
就会按我们所想输出6个g字符了。
-
因为程序遇到“\n”,或是EOF,或是缓中区满,或是文件描述符关闭,或是主动flush,或是程序退出,就会把数据刷出缓冲区。
-
需要注意的是,标准输出是行缓冲,所以遇到“\n”的时候会刷出缓冲区;
-
但对于磁盘这个块设备来说,“\n”并不会引起缓冲区刷出的动作,那是全缓冲,你可以使用setvbuf来设置缓冲区大小,或是用fflush刷缓存。
4. linux内核之文件描述符表、文件表、索引结点(i-node)表
-
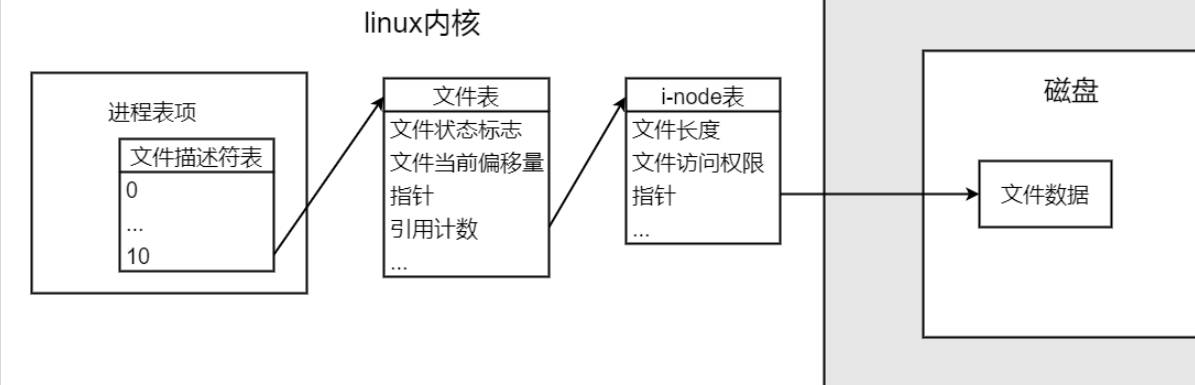
-
这里以《UNIX环境高级编程》的设计阐述。
-
unix内核使用3种数据结构表示打开文件。
-
(1)每个进程都有一个进程表,进程表有一张文件描述符表,表的每一项代表了一个打开的文件。表项中包含的内容如下
- a.文件描述符 fd。
- b.指向一个文件表项的指针。
-
(2)内核为所有打开文件维持一张文件表。每个文件表项包含:
- a.文件状态标志(读、写、添写、同步和非阻塞等)。
- b.当前文件偏移量。
- c.指向该文件v节点表项的指针。
-
(3)每个打开文件(或设备)都有一个v节点(v-node)表,每个v节点结构包含:
- a.文件类型。
- b.对文件的各种操作函数指针。
- c. i节点(索引结点(i-node))(对于大多数文件)。
-
对于Linux系统,没有使用v节点,而是通用了i节点结构。
-
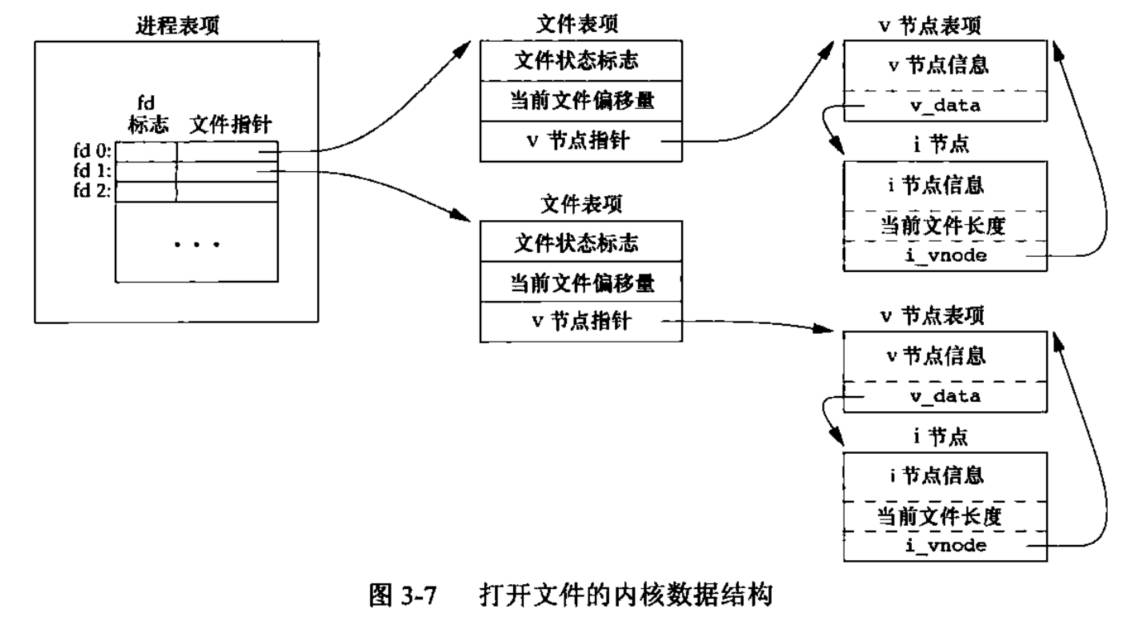
-
对于不同的进程,如果打开了同一个文件,结构如下图所示,此时的文件表项是不一样的,两者的文件偏移指针不共享。
-
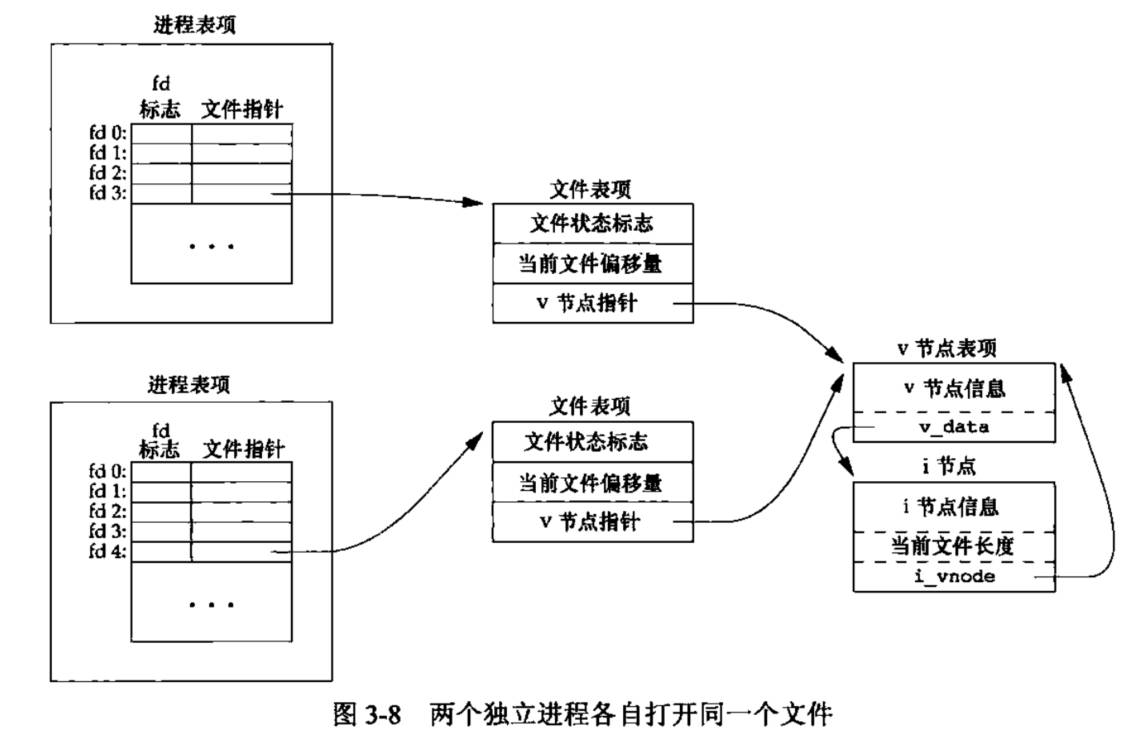
-
但是如果调用dup函数或者fork函数,则父、子进程的每一个打开文件描述符都共享同一个文件表项。
-
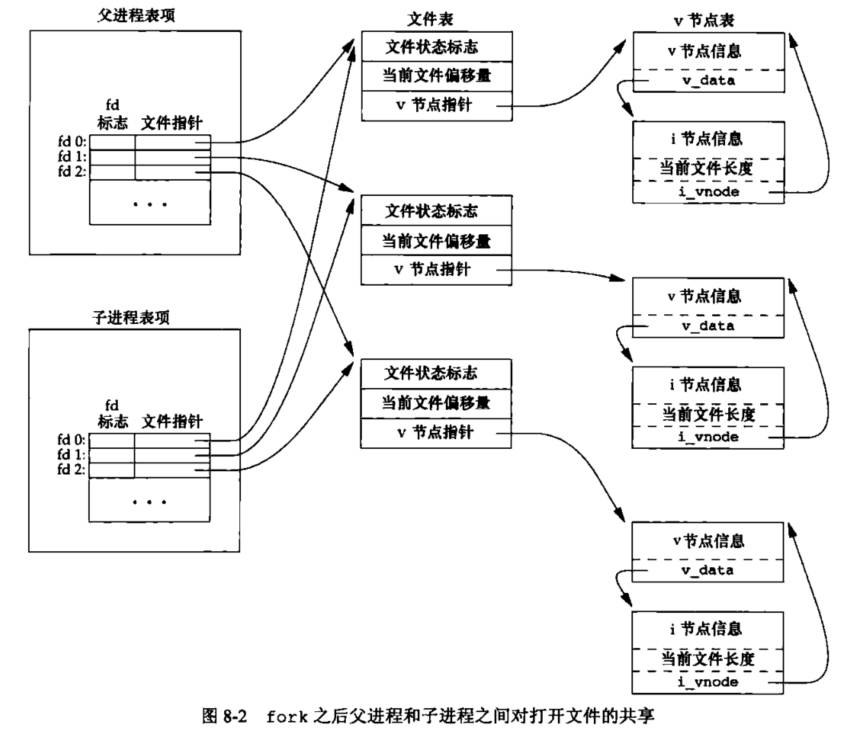
-
可以看到fork后的子进程只是复制了父进程的文件描述符表,但是指向同一个文件表,两者的指针偏移是共用的。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26#include <fcntl.h> #include <stdio.h> #include <sys/types.h> #include <unistd.h> int main() { int fd1, fd2, fd3, nr; char buff[20]; pid_t pid; fd1 = open("data.in", O_RDWR); pid = fork(); if (pid == 0) { // 子进程 nr = read(fd1, buff, 10); buff[nr] = '\0'; printf("child pid#%d content#%s#\n", getpid(), buff); close(fd1); exit(0); } wait(NULL); nr = read(fd1, buff, 10); buff[nr] = '\0'; printf("paren pid#%d content#%s#\n", getpid(), buff); close(fd1); return 0; } -
输出结果
-
1 2 3 4 5 6 7data.in文件 abcdefghijklmnopqrstuvwxyz1234567890 EOF // 输出结果 child pid#3205 content#abcdefghij# paren pid#3204 content#klmnopqrst# -
可以看到,父进程读取内容是子进程读取完后的偏移位置开始读取。
5.C++中NULL和nullptr的区别
-
在编写C程序的时候只看到过NULL,而在C++的编程中,我们可以看到NULL和nullptr两种关键字,其实nullptr是C++11版本中新加入的,它的出现是为了解决NULL表示空指针在C++中具有二义性的问题。
-
在C语言中,NULL通常被定义为:
1#define NULL ((void *)0) -
如果在C语言中写入以下代码,编译是没有问题的,因为在C语言中把空指针赋给int和char指针的时候,发生了隐式类型转换,把void指针转换成了相应类型的指针。
-
1 2int *pi = NULL; char *pc = NULL; -
但是问题来了,以上代码如果使用C++编译器来编译则是会出错的,因为C++是强类型语言,void*是不能隐式转换成其他类型的指针的,所以实际上为了能编译通过,编译器提供的头文件做了如下的处理:
-
1 2 3 4 5#ifdef __cplusplus #define NULL 0 #else #define NULL ((void *)0) #endif -
可见,在C++中,NULL实际上是0。因为C++中不能把void*类型的指针隐式转换成其他类型的指针,所以为了结果空指针的表示问题,C++引入了0来表示空指针,这样就有了上述代码中的NULL宏定义。
-
但是这样用NULL代替0表示空指针在函数重载时会出现问题,也就产生了**二义性问题。**如下所示。
-
1 2 3 4 5 6 7 8 9 10#include <iostream> using namespace std; void func(char *ptr) { cout << "Char pointer version\n"; } void func(int ptr) { cout << "int version\n"; } int main() { func(NULL); // 无法通过编译,可能导致二义性 func(nullptr); // 仅调用char*版本 return 0; } -
为解决NULL代指空指针存在的二义性问题,在C++11版本(2011年发布)中特意引入了nullptr这一新的关键字来代指空指针,从上面的例子中我们可以看到,使用nullptr作为实参,确实选择了正确的以char *ptr作为形参的函数版本。
-
总结
-
NULL:NULL是C++中早期版本用于表示空指针的宏,通常被定义为0或者((void*)0)。- 在C++11之前,
NULL是主要用于表示空指针的方法。 - 由于历史原因,
NULL存在一些潜在的问题。例如,如果函数期望一个指针参数,传递NULL可能导致歧义,因为它实际上可以被解释为整数0。
-
nullptr:nullptr是C++11引入的新特性,专门用于表示空指针。它是一种空指针常量,具有自己的类型std::nullptr_t。nullptr解决了一些NULL可能引起的歧义问题。它是类型安全的,不会被隐式转换为整数类型,从而减少了一些潜在的错误。- 推荐在新的C++代码中使用
nullptr而不是NULL。
vim 分屏技巧
-
分屏,命令模式下
-
:sp水平分屏 -
:vsp竖直分屏 -
分屏命令+filename,分屏并打开这个文件 -
分屏后屏幕切换,
Ctrl+w+w -
使用
:q退出光标所在窗口 -
使用
:qall退出所有窗口 -
从shell启动vim打开多个文件并分屏显示:
1 2 3 4 5vim -on file1 file2 o为小写字母,水平分割,即上下分屏,n是分屏的个数(可缺省),后面是待打开的文件 vim -On file1 file2 O为大写字母,垂直分割,即左右分屏,n是分屏的个数(可缺省),后面是待打开的文件在已经打开的vim中对文件进行分屏
1 2 3 4 5 6 7 8 9 10 11 12 13对光标所在的窗口进行上下分屏 :sp [file2] 或者 :split [file2] ctrl + w s # 后面不跟文件名是将当前文件垂直分屏;跟文件名是将新文件在垂直分屏中打开 对光标所在的窗口进行左右分屏 :vsp [file2] 或者 :vsplit [file2] ctrl + w v # 创建空白分屏 :new [file2]不同窗口间的移动(可直接Ctrl + w + w 自动切换到另一个分屏)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15移动到光标左边的窗口 ctrl + w h ctrl + w ← 移动到光标上边的窗口 ctrl + w k ctrl + w ↑ 移动到光标下边的窗口 ctrl + w j ctrl + w ↓ 移动到光标右边的窗口 ctrl + w l ctrl + w →关闭当前窗口
1 2 3 4 5 6 7 8 9ctrl + w c (不能用于最后一个分屏) ctrl + w q (可用于最后一个分屏) :q #取消其它分屏,只保留当前分屏 :only #关闭所有分屏 :qa
Linux 开启telnet服务
-
1.安装telnet服务,yum -y 表示自动选择yes,不用手动写。
1yum install xinetd telnet telnet-server -y -
2.设置开机自启动
1 2 3# 这两条命令设置开机时自动启动telnet服务 systemctl enable telnet.socket systemctl enable xinetd -
3.启动telnet服务
1 2 3# 启动telnet服务 systemctl start telnet.socket systemctl start xinetd -
4.查看状态
1 2 3# 查看telnet服务的状态 systemctl status telnet.socket systemctl status xinetd -
5.关闭telnet服务
1 2 3 4systemctl stop telnet.socket systemctl stop xinetd firewall-cmd --remove-service=telnet --permanent # 防火墙不开放telnet服务端口 firewall-cmd --reload -
6.参考
-
7.参考
C语言坑点
1.隐式函数声明:
-
在C语言中,函数在调用前不一定非要声明。如果没有声明,那么编译器会自己主动依照一种隐式声明的规则,为调用函数的C代码产生汇编代码。以下是一个样例:
1 2 3 4 5int main(int argc, char** argv) { double x = any_name_function(); return 0; }单纯的编译上述源代码。并没有不论什么报错,仅仅是在链接阶段由于找不到名为any_name_function的函数体而报错。
1 2 3 4 5[smstong@centos192 test]$ gcc -c main.c [smstong@centos192 test]$ gcc main.o main.o: In function `main': main.c:(.text+0x15): undefined reference to `any_name_function' collect2: ld 返回 1之所以编译不会报错,是由于C语言规定,对于没有声明的函数,自己主动使用隐式声明。
-
但注意,编译器自动声明的函数返回值类型只能是
int,换言之,如果静态库的函数返回值不是int,最后结果会出错,尽管程序运行没问题。 -
因此编译静态库,一般会把函数声明在自带的静态库头文件里面,以能够更好的编译通过。
2.段错误
-
段错误就是指访问的内存超出了系统所给这个程序的内存空间。
-
在编程中以下几类做法容易导致段错误,基本上是错误地使用指针引起的。
1)访问系统数据区,尤其是往系统保护的内存地址写数据。最常见就是给一个指针以0地址,即指向nullptr,此时不能赋值。
2)内存越界(数组越界,变量类型不一致等): 访问到不属于你的内存区域。
-
寻找段错误的方法:直接gdb进行run即可。
GCC 编译工具
四步骤
- gcc 编译可以执行程序 4 步骤: 预处理、编译、汇编、链接。
- 预处理
gcc -E - 编译
gcc -S - 汇编
gcc -c - 链接
无参数,-o 只是指定生成的可执行程序的名字 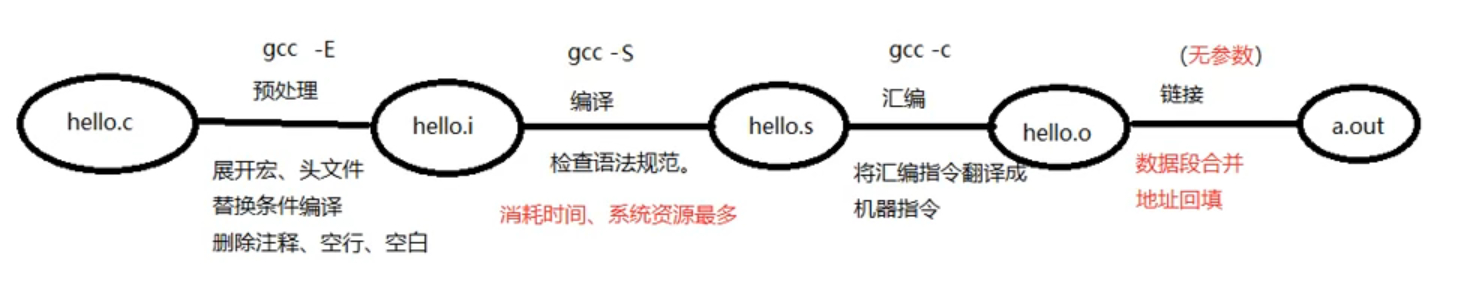
基本使用
-
在CentOs上安装gcc
1yum -y install gcc gcc-c++ kernel-devel -

-
- 预处理, 展开头文件/宏替换/去掉注释/条件编译 (test.i main.i)
- 编译, 检查语法,生成汇编代码 (test.s main.s)
- 汇编, 汇编代码转换机器码 (test.o main.o)
- 链接, 链接到一起生成可执行程序 (test.out mian.out 或没后缀)
-
gcc使用语法:
gcc [选项] <文件名> -
1.
gcc filename -o targetname: 直接生成可执行文件main.out
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15[root@Tyc c++code]# cat test1.c #include <stdio.h> int main(){ printf("hello gcc!\n"); return 0; } [root@Tyc c++code]# gcc test1.c -o test1 [root@Tyc c++code]# ll total 16 -rwxr-xr-x 1 root root 8360 Feb 25 21:02 test1 -rw-r--r-- 1 root root 70 Feb 25 21:01 test1.c [root@Tyc c++code]# ./test1 hello gcc! [root@Tyc c++code]# -
2.
gcc -c fileName: 只对源文件进行编译和汇编,不链接,生成main.o文件
1 2 3 4 5 6 7 8 9[root@Tyc c++code]# gcc -c test1.c [root@Tyc c++code]# ls test1.c test1.o [root@Tyc c++code]# gcc test1.o -o test [root@Tyc c++code]# ls test test1.c test1.o [root@Tyc c++code]# ./test hello gcc! [root@Tyc c++code]# -
3.
gcc -S filename:对源文件只进行编译而不汇编操作,生成汇编代码,生成main.s汇编代码文件1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32[root@Tyc c++code]# ls main.e test1.c [root@Tyc c++code]# gcc -S test1.c [root@Tyc c++code]# ls main.e test1.c test1.s [root@Tyc c++code]# cat test1.s .file "test1.c" .section .rodata .LC0: .string "hello gcc!" .text .globl main .type main, @function main: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movl $.LC0, %edi call puts movl $0, %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size main, .-main .ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-44)" .section .note.GNU-stack,"",@progbits -
4.
gcc -E filename:只进行预编译,把所有头文件、宏替换过来,生成最终的编译文件main.i文件1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27[root@Tyc c++code]# gcc -E test1.c > main.i [root@Tyc c++code]# ls main.i test1.c [root@Tyc c++code]# cat main.i | more # 1 "test1.c" # 1 "<built-in>" # 1 "<command-line>" # 1 "/usr/include/stdc-predef.h" 1 3 4 # 1 "<command-line>" 2 # 1 "test1.c" # 1 "/usr/include/stdio.h" 1 3 4 # 27 "/usr/include/stdio.h" 3 4 # 1 "/usr/include/features.h" 1 3 4 # 375 "/usr/include/features.h" 3 4 # 1 "/usr/include/sys/cdefs.h" 1 3 4 # 392 "/usr/include/sys/cdefs.h" 3 4 # 1 "/usr/include/bits/wordsize.h" 1 3 4 # 393 "/usr/include/sys/cdefs.h" 2 3 4 # 376 "/usr/include/features.h" 2 3 4 # 399 "/usr/include/features.h" 3 4 # 1 "/usr/include/gnu/stubs.h" 1 3 4 # 10 "/usr/include/gnu/stubs.h" 3 4 # 1 "/usr/include/gnu/stubs-64.h" 1 3 4 # 11 "/usr/include/gnu/stubs.h" 2 3 4 # 400 "/usr/include/features.h" 2 3 4 # 28 "/usr/include/stdio.h" 2 3 4 ... -
5.
gcc -g filename -o targetname: 生成带debug调试信息的可执行文件。以下例子可以看到带调试信息的可执行文件相当于windows上的debug按钮,而一般生成的是release按钮,可以看到带调试信息的可执行文件的容量更大。后面使用GDB进行调试,可以跟进代码。1 2 3 4 5 6 7 8 9 10[root@Tyc c++code]# gcc -g test1.c -o main_d [root@Tyc c++code]# ls main_d test1.c [root@Tyc c++code]# gcc test1.c -o main_r [root@Tyc c++code]# ls -l total 28 -rwxr-xr-x 1 root root 9360 Feb 25 21:57 main_d -rwxr-xr-x 1 root root 8360 Feb 25 21:57 main_r -rw-r--r-- 1 root root 70 Feb 25 21:01 test1.c [root@Tyc c++code]#
常用参数
-

-
gcc -v或者gcc --version:查看gcc版本号 -
gcc -I filename:指定头文件目录g++ main.cpp -o main -I ../include/I后面的空格可有可没有。- 如果头文件和源文件在同一个目录下面,则不需要指定头文件
-
gcc -Wall:显示所有的警告信息 -
gcc main.c -o main -Wall。 -
gcc hello.c -D HELLO:向程序中“动态” 注册宏定义。-
gcc hello.c -o hello -D HELLO -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22[root@Tyc test]# vim hello.c [root@Tyc test]# cat hello.c #include <stdio.h> #ifdef HELLO #define I 20 #endif int main(){ printf("_------%d",I); return 0; } [root@Tyc test]# gcc hello.c -o hello hello.c: In function ‘main’: hello.c:6:21: error: ‘I’ undeclared (first use in this function) printf("_------%d",I); ^ hello.c:6:21: note: each undeclared identifier is reported only once for each function it appears in [root@Tyc test]# gcc hello.c -o hello -D HELLO [root@Tyc test]# ls hello hello.c main.cpp [root@Tyc test]# ./hello _------20[root@Tyc test]# [root@Tyc test]#
-
-
gcc -O:编译优化等级设置
Linux 动态库和静态库
绪论
- 函数库分为静态库和动态库两种。
- 静态库:静态库在程序编译时会被连接到目标代码中,程序运行时将不再需要该静态库。编译时空间消耗大,运行速度理论上大于动态库。
- 动态库:也称共享库,动态库在程序编译时并不会被连接到目标代码中,而是在程序运行是才被载入,因此在程序运行时还需要动态库存在。
静态库制作
-
lib[xxx].a -

-
静态库名字以
lib开头,以.a结尾——例如:libmylib.a。 -
步骤:
- 1.
gcc -c生成.o汇编文件 - 2.
ar rcs libmylib.a file1.o生成静态库文件
- 1.
-
静态库生成指令——
ar rcs 生成静态库库名 汇编文件名ar rcs libmylib.a file1.o -
例子
ar rcs libmyMath.a add.o div1.o sub.o -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26[root@Tyc staticLib]# vim add.c [root@Tyc staticLib]# ls add.c div1.c red.c [root@Tyc staticLib]# cat add.c int add(int a, int b){ return a+b; } [root@Tyc staticLib]# cat div1.c int add(int a, int b){ return a/b; } [root@Tyc staticLib]# cat red.c int red(int a, int b){ return a-b; } [root@Tyc staticLib]# gcc -c add.c -o add.o [root@Tyc staticLib]# gcc -c red.c -o sub.o [root@Tyc staticLib]# gcc -c div1.c -o div1.o [root@Tyc staticLib]# ls add.c add.o div1.c div1.o red.c sub.o [root@Tyc staticLib]# ar rcs libmyMath.a add.o div1.o sub.o [root@Tyc staticLib]# ls add.c add.o div1.c div1.o libmyMath.a red.c sub.o [root@Tyc staticLib]# file libmyMath.a libmyMath.a: current ar archive [root@Tyc staticLib]# -
静态库的使用:
-
gcc test.c lib库名.a -o test.out -
如果不加lib进行编译,链接会发生错误,有
collect2收集器表示链接出错。如果是编译出错,会显示行号表示语法错误。 -
注意一定是源文件在静态库文件之前。
-
1gcc test.c libmyMath.a -o test.out
-
-
头文件守卫,防止头文件被重复包含
1 2 3 4#ifndef _HEAD_H_ #define _HEAD_H_ ... #endif
动态库制作
lib[xxx].so
基本原理
- 首先看自己同一个源文件里面的函数调用步骤。主要是要在链接的时候进行数据段合并以及地址回填,如下图所示,fun1函数的地址以 main函数的地址为依据拥有自身的地址从而得到调用,fun2函数同理。

- 动态库的调用和普通函数的调用不同,
延迟绑定,查看生成的汇编代码可知,调用动态库函数依赖@plt的地址,就像上图的函数依赖main函数的地址一样,而@plt的地址当内存载入动态库的时候就会产生,从而可以调用动态库函数。
步骤
-
步骤1:将源文件
.c生成汇编文件.o,生成与位置无关的汇编代码——-fPIC。 -
gcc -c add.c -o add.o -fPIC -
步骤2:使用
gcc -shared制作动态库gcc -shared -o lib库名.so add.o sub.o div1.o- 注意库名自定义,前面+
lib,后面+.so。
-
步骤3:编译可执行程序,指定所使用的的动态库。
-l:指定库名,注意这个库名没有前缀lib,也没有后缀.so-L:指定库路径,不需要空格。gcc test.c -o test.out -lmymath -L./lib
-
步骤4:更改动态库的文件路径,不更改步骤三的执行程序会报错。有两种方式:
-
临时更改,切换终端后无效——
export LD_LIBRARY_PATH=动态库路径。支持相对路径。 -
更改配置文件,添加环境变量
export LD_LIBRARY_PATH=动态库路径,一直有效。1 2vim ~/.bashrc source ~/.bashrc
-
-

-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19[root@Tyc source]# gcc -c add.c -o add.o -fPIC [root@Tyc source]# gcc -c sub.c -o sub.o -fPIC [root@Tyc source]# gcc -c div1.c -o div1.o -fPIC [root@Tyc source]# ls add.c add.o div1.c div1.o sub.c sub.o [root@Tyc source]# gcc -shared -o libmymath.so add.o sub.o div1.o [root@Tyc source]# ls add.c add.o div1.c div1.o libmymath.so sub.c sub.o [root@Tyc cplusCode]# ls dynamicLib include staticLib test testDll.c [root@Tyc cplusCode]# gcc testDll.c -o testdll.out -lmymath -L ./dynamicLib/ -I ./include/ [root@Tyc cplusCode]# ls dynamicLib include staticLib test testDll.c testdll.out [root@Tyc cplusCode]# export LD_LIBRARY_PATH=./dynamicLib/ [root@Tyc cplusCode]# ./testdll.out add=21 sub=7 div=2 [root@Tyc cplusCode]# -
1 2 3 4 5 6 7 8 9[root@Tyc cplusCode]# vim ~/.bashrc [root@Tyc cplusCode]# ./testdll.out ./testdll.out: error while loading shared libraries: libmymath.so: cannot open shared object file: No such file or directory [root@Tyc cplusCode]# source ~/.bashrc [root@Tyc cplusCode]# ./testdll.out add=21 sub=7 div=2 [root@Tyc cplusCode]# -
除了上述两种添加动态库路径的方式,还有以下两种方式。

GDB 调试工具
基础指令
-
gcc -g:使用该参数编译执行文件,得到调试表; -
gdb a.out:开始调试; -
list:列出源码,list可以使用缩写l; -
l 行数n:从第n行开始列出源码,l是list的缩写; -
b 行数n:breakPoint缩写,在第n行设置断点; -
run/r:运行程序; -
n/next:下一条指令,会越过函数; -
s/step:单步执行,会进入函数; -
p/print 变量i:打印出当前变量i的值; -
continue:继续执行断点的后续指令; -
quit:退出gdb调试。 -
delete 行数n:删除行数n的断点。 -

其他指令
run:使用run查找段错误出现位置;finish:结束当前函数调用;info b:查看断点信息表;b if i = 5:设置条件断点;- set args: 设置main函数命令行参数 (在 start、run 之前);
- run 字串1 字串2 ...: 设置main函数命令行参数;
- ptype:查看变量类型;
- bt:列出当前程序正存活着的栈帧;
- frame: 根据栈帧编号,切换栈帧;
- display:设置跟踪变量;
- undisplay:取消设置跟踪变量。 使用跟踪变量的编号。

Makefile 项目管理
绪论
-
文件命名:makefile或者Makefile,最好不要更改,更改就不能使用默认的命令了。
-
入门Makefile,需要掌握
1 2 3; -
1代表一个规则;2代表两个函数;3代表自动变量。
一个规则
-
1 2 3 4 5目标:依赖条件 命令(注意要有一个tab的缩进) ###以下是例子 hello:hello.c gcc hello.c -o hello -
1.若想生成
目标,检查规则中的依赖条件是否存在,如不存在,则得找是否有规则用来生成该依赖文件。 -
2.检查规则中的
目标是否需要更新,必须先检查它的所有依赖条件,依赖条件中有任一个被更新,则目标必须更新。 -
3.makefile默认编译的最终目标是第一行的目标,要想自定义最终目标,可以使用
ALL:a.out -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16ALL:a.out a.out:hello.o add.o sub.o div1.o gcc hello.o add.o sub.o div1.o -o a.out add.o:add.c gcc -c add.c -o add.o sub.o:sub.c gcc -c sub.c -o sub.o div1.o:div1.c gcc -c div1.c -o div1.o hello.o:hello.c gcc -c hello.c -o hello.o
两个函数和 clean
-
src = $(wildcard ./*.c):匹配当前工作目录下所有后缀为.c的文件,将文件名组成列表,赋值给src变量。(wildcard是通配符的意思)。 -
obj = $(patsubst %.c, %.o, $(src)):将参数3(src)中,包含参数1的部分,替换为参数2,赋值个obj变量。 -
还可以在makefile里面删除生成为汇编文件,使用
clean命令。其中的-表示当删除文件不存在,不报错继续执行,直至完成任务,否则会终止执行没有删除剩下的文件。注意clean后面没有依赖。 -
1 2clean: -rm -rf $(obj) a.out #注意有tab键- 注意在默认情况下,执行
make命令时,clean规则将不会被运行,因为它不是生成目标的先决条件。要运行clean规则,你需要输入make clean命令。
- 注意在默认情况下,执行
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22src = $(wildcard ./*.c) #add.c sub.c divi.c hello.c obj = $(patsubst %.c,%.o,$(src)) #add.o sub.o div1.o hello.o ALL:a.out a.out:$(obj) gcc $(obj) -o a.out add.o:add.c gcc -c add.c -o add.o sub.o:sub.c gcc -c sub.c -o sub.o div1.o:div1.c gcc -c div1.c -o div1.o hello.o:hello.c gcc -c hello.c -o hello.o clean: -rm -rf $(obj) a.out
三个自动变量
-
注意这三个变量只能用于规则的命令里面,不能用于目标或者依赖。
-
$@:在规则命令中,表示规则中的目标。 -
$<:在规则命令中,表示规则中的第一个依赖条件;如果将该变量用在模式规则中,它可以将依赖条件列表中的依赖依次取出,套用模式规则。 -
$^:在规则命令中,表示规则中的所有依赖条件。 -

模式规则
-
很明显在上图中,makefile的可扩展性不强。比如要增加一个mul.c文件要重新加一行编译命令,不符合makefile一次编写一生受用的目标,所有有了模式规则。
-
模式规则的代码
-
1 2%.o:%.c gcc -c $< -o $@ -
-
以后增加函数的时候,不用改makefile,只需要增加.c文件,改一下源码就可以了。
-
静态模式规则
-
静态模式规则,就是指定模式规则给谁用。因为以后不止一个obj,还会有其他的obj1等等。
-
代码格式
-
1 2$(obj):%.o:%.c gcc -c $< -o $@ -
-
其他拓展
-
当前文件夹下有ALL文件或者clean文件时,会导致makefile不执行clean以及ALL的目标编译。
- 用伪目标来解决,最后添加一行
.PHONY: clean ALL。
- 用伪目标来解决,最后添加一行
-
编译时的参数,-g,-Wall,-I 这些,都可以放在makefile里面。
一般模板
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16src = $(wildcard *.c) obj = $(patsubst %.c, %.o, $(src)) myArgs = -Wall -g ALL:a.out a.out:$(obj) gcc $^ -o $@ $(myArgs) $(obj):%.o:%.c gcc -c $< -o $@ $(myArgs) clean: -rm -rf $(obj) a.out .PHONY: clean ALL -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19src = $(wildcard ./src/*.cpp) obj = $(patsubst ./src/%.cpp, ./obj/%.o, $(src)) inc_path = ./inc myArgu = -Wall -g ALL:server.out $(obj):./obj/%.o:./src/%.cpp g++ -c $< -o $@ $(myArgu) -I $(inc_path) server.out:$(obj) g++ $^ -o $@ $(myArgu) clean: -rm -rf $(obj) server.out .PHONY: clean ALL -
把源文件放src文件夹,头文件放inc文件夹,生成放obj文件夹。(注意3个文件夹要先创建好了)
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19src = $(wildcard ./src/*.cpp) obj = $(patsubst ./src/%.cpp, ./obj/%.o, $(src)) inc_path = ./inc myArgu = -Wall -g ALL:a.out $(obj):./obj/%.o:./src/%.cpp g++ -c $< -o $@ $(myArgu) -I $(inc_path) a.out:$(obj) g++ $^ -o $@ $(myArgu) clean: -rm -rf $(obj) a.out .PHONY: clean ALL
《Linux高性能服务器编程》学习笔记
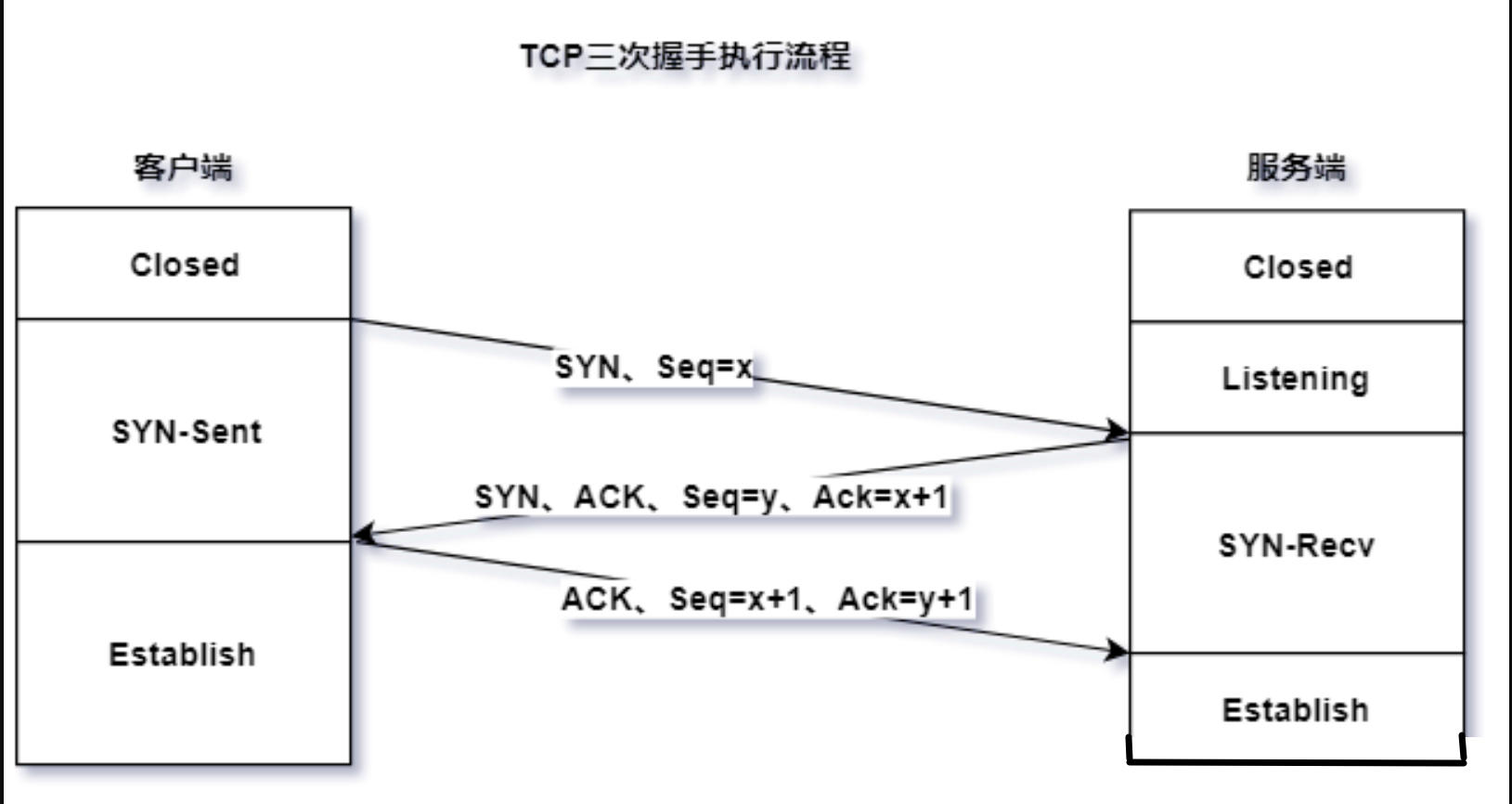
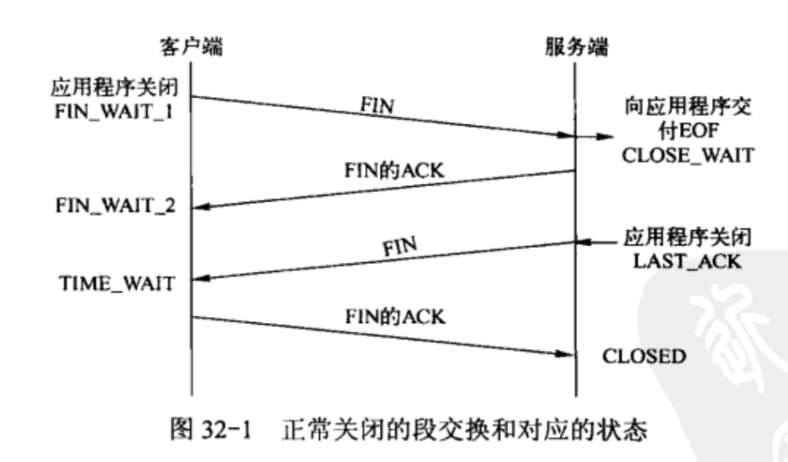
第3章 tcp 协议详解
1. TIME_WAIT 状态
-
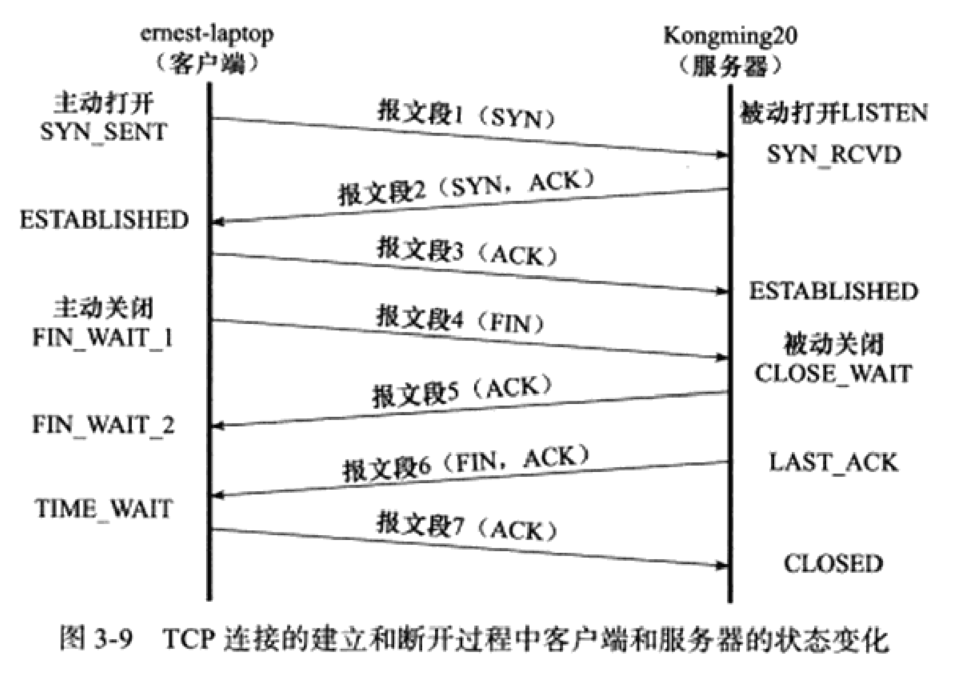
-
从上图可以看出,客户端连接在收到服务器的结束报文段(TCP报文段6)之后,并没有直接进人CLOSED状态,而是转移到TIME_WAIT状态。在这个状态,客户端连接要等待一段长为2MSL(Maximum Segment Life,报文段最大生存时间)的时间,才能完全关闭。MSL是TCP报文段在网络中的最大生存时间,标准文档RFC1122的建议值是2min。
-
每个TCP实现必须选择一个MSL。它是任何报文段被丢弃前在网络内的最长时间。这个时间是有限的,因为TCP报文段以IP数据报在网络内传输,而IP数据报则有限制其生存时间的TTL时间。RFC1122 指出MSL为2分钟,现实中常用30秒或1分钟。
-
TIME_WAIT 存在的原因有两点:
- 1.可靠的终止TCP连接。若处于 TIME_WAIT 的客户端发送给服务器确认报文段丢失的话,服务器将在此重新发送FIN报文段,那么客户端必须处于一个可接收的状态就是 TIME_WAIT 而不是CLOSE状态,以处理重复收到的FIN报文。否则,客户端将以复位RST报文段来回应服务器,服务器会认为这是一个错误。
- 2.保证让迟来的TCP报文段有足够的时间被识别并丢弃。在Linux系统上,一个TCP端口不能被同时打开多次(两次及以上)。当一个TCP连接处于TIME_WAIT状态时,我们将无法立即使用该连接占用着的端口来建立一个新连接。反过来思考,如果不存在TIME WAIT状态,则应用程序能够立即建立一个和刚关闭的连接相似的连接(这里说的相似,是指它们具有相同的P地址和端口号)。这个新的、和原来相似的连接被称为原来的连接的化身(incarnation)。新的化身可能接收到属于原来的连接的、携带应用程序数据的TCP报文段(迟到的报文段),这显然是不应该发生的。这就是TIME_WAIT状态存在的第二个原因。
-
为什么需要等待一段长为2MSL(Maximum Segment Life,报文段最大生存时间)的时间来维持 TIME_WAIT 的时间呢?
- 因为TCP报文段的最大生存时间是MSL,所以坚持2MSL时间的TIME_WAIT状态能够确保网络上两个传输方向上尚未被接收到的、迟到的TCP报文段都已经消失(被中转路由器丢弃)。因此,一个连接的新的化身可以在2MSL时间之后安全地建立,而绝对不会接收到属于原来连接的应用程序数据,这就是TIME_WAIT状态要持续2MSL时间的原因。
-
有时候我们希望避免TIME_WAIT状态,因为当程序退出后,我们希望能够立即重启它。但由于处在TIME_WAIT状态的连接还占用着端口,程序将无法启动(直到2MSL超时时间结束)。
-

-
对客户端程序来说,我们通常不用担心上面描述的重启问题。因为客户端一般使用系统自动分配的临时端口号来建立连接,而由于随机性,临时端口号一般和程序上一次使用的端口号(还处于TIME_WAIT状态的那个连接使用的端口号)不同,所以客户端程序一般可以立即重启。上面的例子仅仅是为了说明问题,我们强制客户端使用12345端口,这才导致立即重启客户端程序失败。
-
但如果是服务器主动关闭连接后异常终止,则因为它总是使用同一个知名服务端口号,所以连接的TIME_WAIT状态将导致它不能立即重启。不过,我们可以通过socket选项SO_REUSEADDR来强制进程立即使用处于TIME_WAIT状态的连接占用的端口,解决这种问题。
-
这里需要说明,客户端在发送 FIN 后仍然能发送 ACK 是不矛盾的,因为 ACK 不是本地服务的数据,是放在 tcp 头部的,而不是body中。
2. 复位报文段 RST
- 在某些特殊条件下,TCP连接的一端会向另一端发送携带RST标志的报文段,即复位报文段,以通知对方关闭连接或重新建立连接。以下是产生复位报文段RST的3种情况。
- (1) 访问不存在的端口或者处于 TIME_WAIT 的端口
- 当客户端访问一个不存在的端口是,目标主机将给它发送一个复位报文段RST,因为复位报文段的接收通告窗口大小为0,所以可以预见:收到复位报文段的一端应该关闭连接或者重新连接,而不能回应这个复位报文段。实际上,当客户端程序向服务器的某个端口发起连接,而该端口仍被处于TIME_WAIT状态的连接所占用时,客户端程序也将收到复位报文段。
- (2) 异常终止连接
- 正常的终止方式为:数据交换完成之后,一方给另一方发送结束报文段。
- TCP提供了异常终止一个连接的方法,即给对方发送一个复位报文段。一旦发送了复位报文段RST,发送端所有排队等待发送的数据都将被丢弃。
- 应用程序可以使用socket选项SO_LINGER来发送复位报文段,以异常终止一个连接。
- (3) 处理半打开连接
- 考虑下面的情况:服务器(或客户端)关闭或者异常终止了连接,而对方没有接收到结束报文段(比如发生了网络故障),此时,客户端(或服务器)还维持着原来的连接,而服务器(或客户端)即使重启,也已经没有该连接的任何信息了。我们将这种状态称为半打开状态,处于这种状态的连接称为半打开连接。如果客户端(或服务器)往处于半打开状态的连接写入数据,则此时服务器(或客户端)将回应一个复位报文段RST。
- 举例来说,我们在Kongming20上使用nc命令模拟一个服务器程序,使之监听12345端口,然后从ernest-laptop运行telnet命令登录到该端口上,接着拔掉ernest-laptop的网线,并在Kongming20上中断服务器程序。显然,此时ernest--laptop上运行的telnet客户端程序维持着一个半打开连接。然后接上ernest-laptop的网线,并从客户端程序往半打开连接写入1字节的数据“a”。同时,运行tcpdump程序抓取整个过程中telnet客户端和nc服务器交换的TCP报文段。

3. TCP 头部选项
-
TCP头部的最后一个选项字段(options)是可变长的可选信息。这部分最多包含40字节,因为TCP头部最长是60字节(其中还包含前面讨论的20字节的固定部分)。
-

-
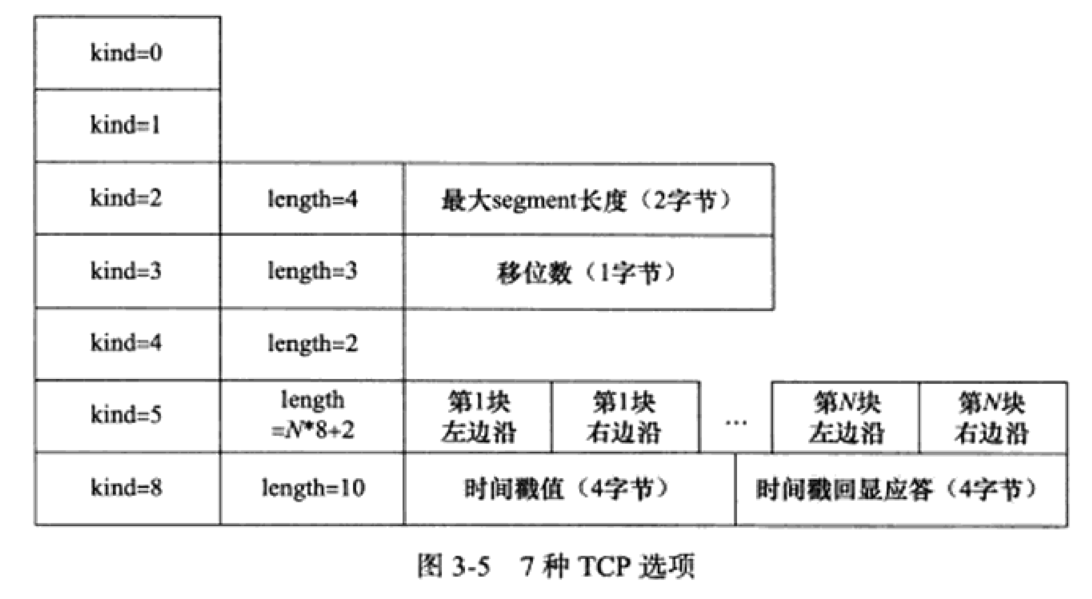
-

-

-

-
这里重点了解窗口扩大因子的作用,在同步报文出现的win,是实际的窗口大小;在传输报文出现的,是压缩的窗口大小。
4. TCP 状态转移
-
这里需要说明,客户端在发送 FIN 后仍然能发送 ACK 是不矛盾的,因为 ACK 不是本地服务的数据,是放在 tcp 头部的,而不是body中。
-
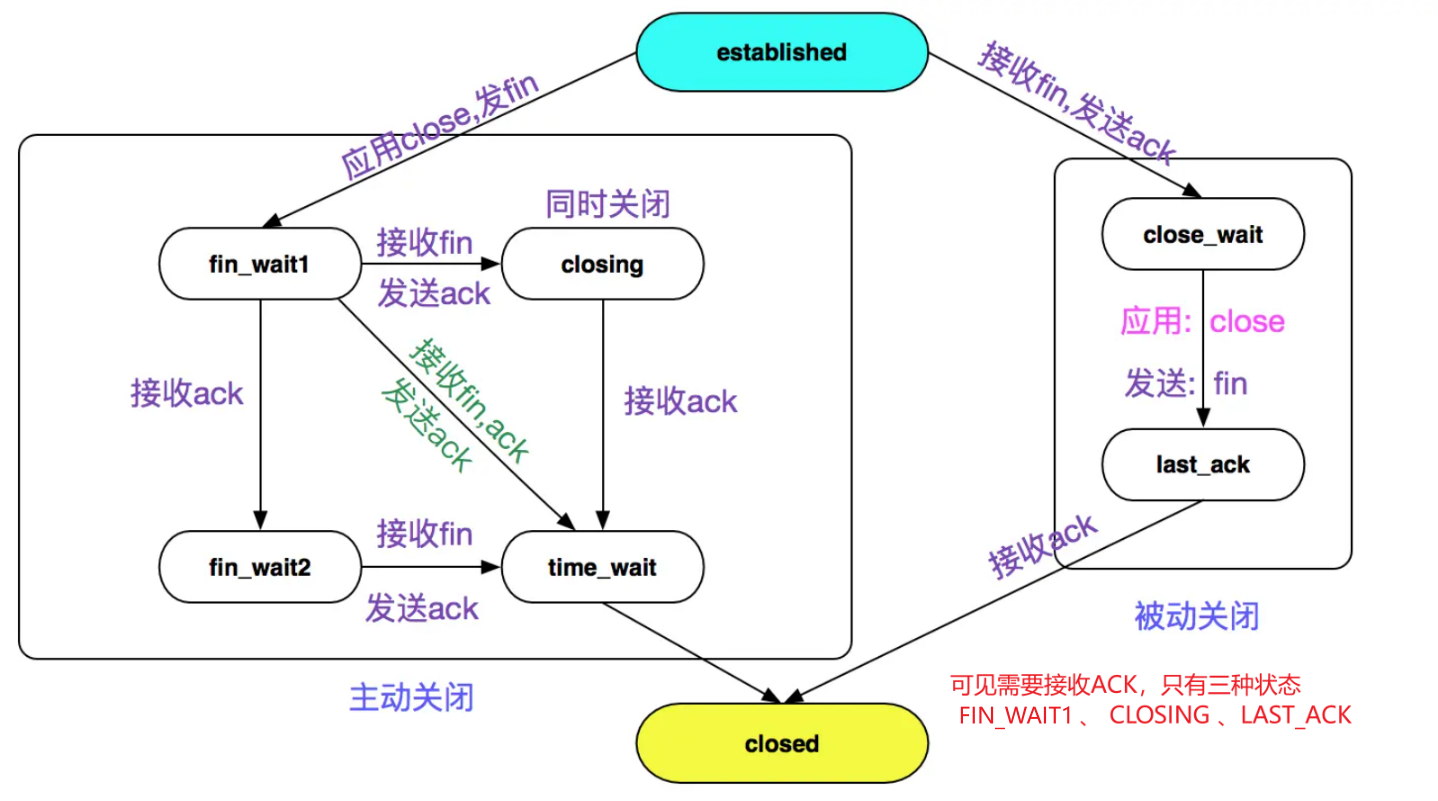
-
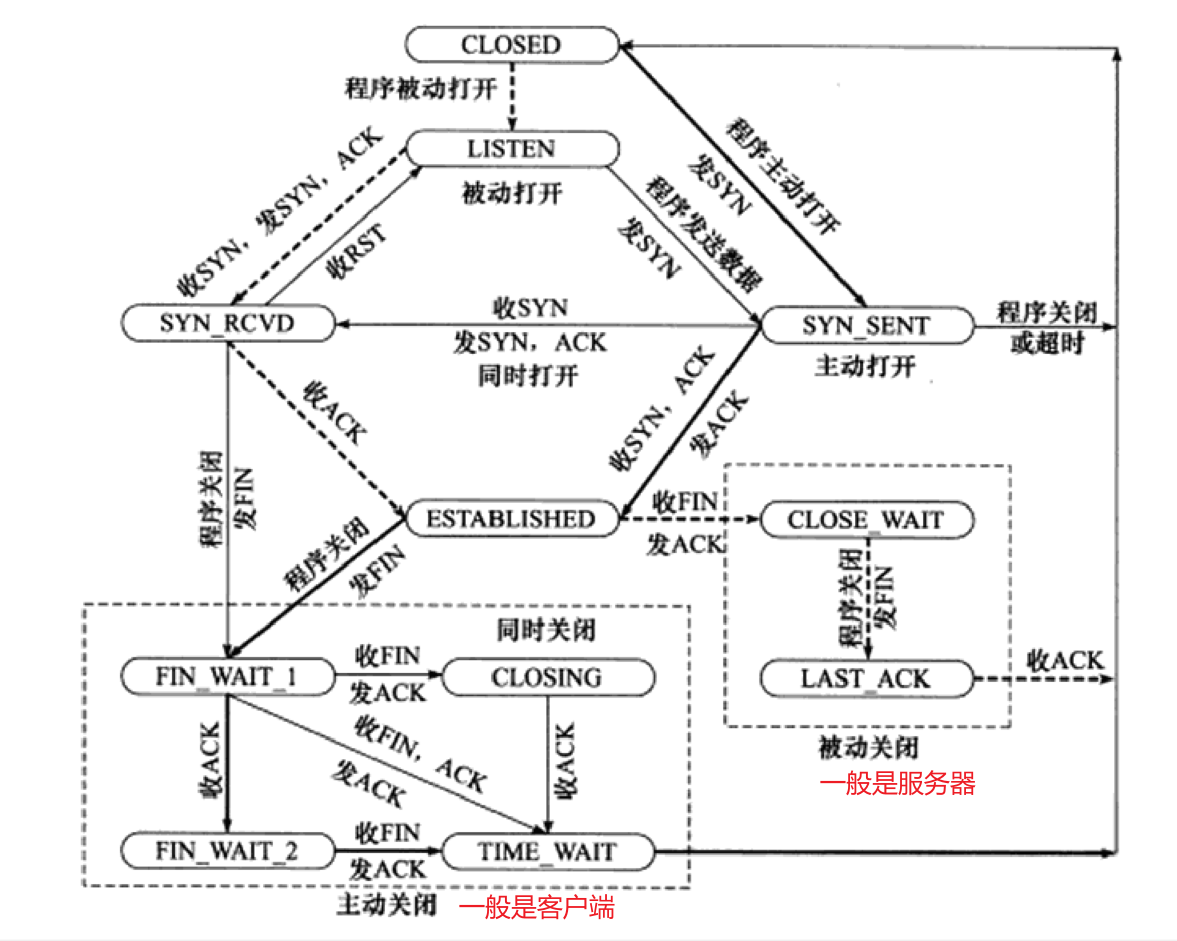
第5章 Linux网络编程基础api
1. 主机字节序和网络字节序
-
主机字节序一般为小端字节序(little endian),但也有大端字节序的主机,如java虚拟机。
- 一个整数的高位字节(23-31bit)存储在内存的高地址处,低位字节(0-7bit)存储在低地址处。
-
网络字节序默认都是大端字节序(big endian)。
- 一个整数的高位字节(23-31bit)存储在内存的低地址处,低位字节(0-7bit)存储在高地址处。
-
检查机器的字节序代码。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23#include <stdio.h> void byteorder() { // 内存共享,两个字节 union { short value; char union_values[sizeof(short)]; } test; // 1为整数的高地址,2为整数的低地址 test.value = 0x0102; if (test.union_values[0] == 1 && test.union_values[1] == 2) { printf("big endian\n"); } else if (test.union_values[0] == 2 && test.union_values[1] == 1) { printf("little endian\n"); } else { printf("unkonwn \n"); } } int main() { byteorder(); return 0; } -
Linux提供了如下4个函数完成主机字节序和网络字节序之间的转换。
-
长整型函数通常用来转换IP地址(32位),短整型函数一般用来转换端口号(16位)。一个字节一个字节的交换。
-
1 2 3 4 5#include <netinet/in.h> unsigned long int htonl(unsigned long int hostlong); unsigned short int htons(unsigned short int hostshort); unsigned long int ntohl(unsigned long int netlong); unsigned short int ntohs(unsigned short int netshort);
2. 通用socket地址
-
socket网络编程接口中表示socket地址的是结构体sockaddr,其定义如下:
-
1 2 3 4 5 6 7 8 9#include <bits/socket.h> typedef unsigned short int sa_family_t; /* Structure describing a generic socket address. */ struct sockaddr { sa_family_t sa_family; /* Common data: address family and length. */ char sa_data[14]; /* Address data. */ }; -
所有专用socket地址(以及sockaddr_storage)类型的变量在实际使用时都需要转化为通用socket地址类型sockaddr(强制转换即可),因为所有socket编程接口使用的地址参数的类型都是sockaddr。
-
常见的协议族有以下三种
-
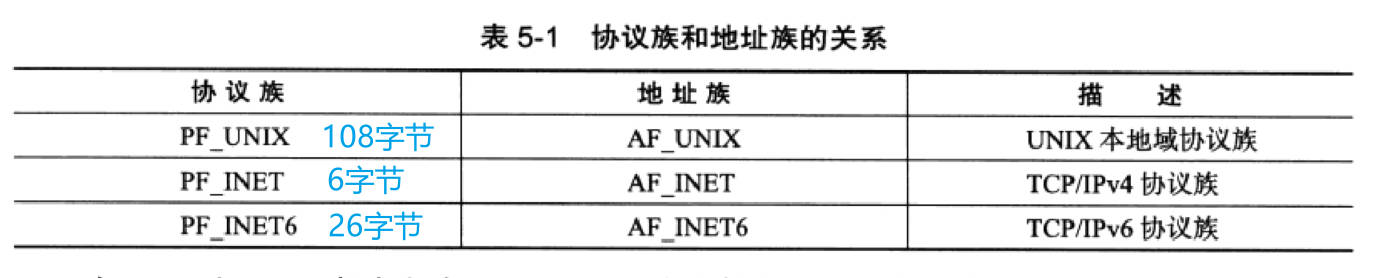
-
显然,14字节的sa_data根本不能完成容纳多数协议族的地址值。因此Linux定义了下面这个新的通用socket地址结构体。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19#define __ss_aligntype unsigned long int #define _SS_PADSIZE \ (_SS_SIZE - __SOCKADDR_COMMON_SIZE - sizeof (__ss_aligntype)) #define __SOCKADDR_COMMON(sa_prefix) \ sa_family_t sa_prefix##family #define __SOCKADDR_COMMON_SIZE (sizeof (unsigned short int)) /* Size of struct sockaddr_storage. */ #define _SS_SIZE 128 struct sockaddr_storage { __SOCKADDR_COMMON (ss_); /* Address family, etc. */ char __ss_padding[_SS_PADSIZE]; __ss_aligntype __ss_align; /* Force desired alignment. */ }; -
这个结构体不仅提供了足够大的空间用于存放地址值,而且是内存对齐的(这是__ss_align成员的作用)。
-
但实际开发中,所有socket编程接口使用的地址参数的类型都是sockaddr。
3. 专用socket地址
-
用于IPv4的sockaddr_in 结构体
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21#include <netinet/in.h> /* Internet address. */ typedef uint32_t in_addr_t; struct in_addr { in_addr_t s_addr; }; /* Structure describing an Internet socket address. */ struct sockaddr_in { __SOCKADDR_COMMON (sin_); in_port_t sin_port; /* Port number. */ struct in_addr sin_addr; /* Internet address. */ /* Pad to size of `struct sockaddr'. */ unsigned char sin_zero[sizeof (struct sockaddr) - __SOCKADDR_COMMON_SIZE - sizeof (in_port_t) - sizeof (struct in_addr)]; }; -

-
用于IPv6的sockaddr_in6 结构体
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24#include <netinet/in.h> struct in6_addr { union { uint8_t __u6_addr8[16]; uint16_t __u6_addr16[8]; uint32_t __u6_addr32[4]; } __in6_u; #define s6_addr __in6_u.__u6_addr8 #ifdef __USE_MISC # define s6_addr16 __in6_u.__u6_addr16 # define s6_addr32 __in6_u.__u6_addr32 #endif }; struct sockaddr_in6 { __SOCKADDR_COMMON (sin6_); in_port_t sin6_port; /* Transport layer port # */ uint32_t sin6_flowinfo; /* IPv6 flow information */ struct in6_addr sin6_addr; /* IPv6 address */ uint32_t sin6_scope_id; /* IPv6 scope-id */ }; -

4. 点分十进制和整数的ip地址转换函数
-
(1)IPv4的点分十进制字符串转为ip地址的整数。
-
注意这些函数,已经把ip地址的整数转换为网络字节序的整数了!结果已经是网络字节序了。
-
①函数
inet_addr(const char* strptr); -
1 2 3 4 5#include <arpa/inet.h> /* Internet address. */ typedef uint32_t in_addr_t; in_addr_t inet_addr(const char *strptr); // 返回:若字符串有效则将字符串转换为32位二进制网络字节序的IPV4地址,否则为INADDR_NONE -
但需要注意转为大小端字节序的结果是不一样的, 示例
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14#include <arpa/inet.h> #include <stdio.h> int main() { // 看成一个大整数,从高位到低位为,0xC0, 0xA8 ,0x00 ,0x01 in_addr_t res = inet_addr("192.168.0.1"); // 转换为大端字节序的整数,从高位到低位为,则为 01 00 A8 C0 // 转换为小端字节序的整数,从高位到低位为,则为 C0 A8 00 01 printf("%X\n", res); /*输出结果,可以看到确实转换为网络字节序 100A8C0 */ return 0; } -
②函数
int inet_aton(const char *string, struct in_addr *addr); -
inet_aton完成和inet_addr一样的功能,但是会把结果存在输入的addr指针里面。
-
1 2 3 4 5 6 7 8 9 10 11 12 13struct in_addr { in_addr_t s_addr; } int inet_aton(const char *string, struct in_addr *addr); /* 参数描述: 1 输入参数string包含ASCII表示的IP地址。 2 输出参数addr是将要用新的IP地址更新的结构。 返回值: 如果这个函数成功,函数的返回值1,如果输入地址不正确则会返回0。 使用这个函数并没有错误码存放在errno中,所以它的值会被忽略。 */ -
(2)IPv4的网络字节序ip地址整数转为主机字节序的点分十进制字符串。
-
使用函数
char *inet_ntoa(struct in_addr in); -
需要注意的是,这个函数返回的char* 指向的是一个静态内存,即每调用一次,都会更改一次,因此该函数是不可重入的。要想重入,需要自己开辟新的内存空间。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24#include <arpa/inet.h> #include <stdio.h> #include <stdlib.h> #include <string.h> int main() { struct in_addr addr1 = {0x08070605}; struct in_addr addr2 = {0x04030201}; const char *s1 = inet_ntoa(addr1); printf("#line %d,addr1 = %s\n", __LINE__, s1); const char *s2 = inet_ntoa(addr2); printf("#line %d,addr2 = %s\n", __LINE__, s2); printf("----------------------------------\n"); printf("#line %d,addr1 = %s,pointer = %p\n", __LINE__, s1, s1); printf("#line %d,addr2 = %s,pointer = %p\n", __LINE__, s2, s2); printf("----------------------------------\n"); char *s11 = strcpy((char *)malloc(32), inet_ntoa(addr1)); char *s12 = strcpy((char *)malloc(32), inet_ntoa(addr2)); printf("#line %d,addr1 = %s\n", __LINE__, s11); printf("#line %d,addr2 = %s\n", __LINE__, s12); free(s11); free(s12); return 0; } -
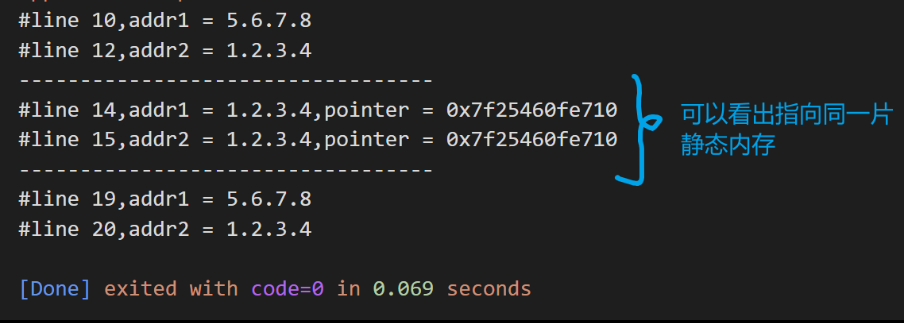
-
(3)关于IPv6的转换函数
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23#include <arpa/inet.h> int inet_pton(int af, const char *src, void *dst); /* 参数说明: af:协议家族。 src:待转换的字符串IP。 dst:转换后的整数IP,这是一个输出型参数。 返回值说明: 如果转换成功,则返回1。 如果输入的字符串IP无效,则返回0,并设置error。 如果输入的协议家族af无效,则返回-1,并将errno设置为EAFNOSUPPORT。 */ const char *inet_ntop(int af, const void *src, char *dst, socklen_t cnt); /* 参数说明: af:协议家族。 src:待转换的整数IP。 dst:转换后的字符串IP,这是一个输出型参数。 cnt:用于指明dst中可用的字节数。 返回值说明: 如果转换成功,则返回一个指向dst的非空指针,即输入的 dst ;如果转换失败,则返回NULL。 */ -

-
其实在实际上,pton(int af, const char *src, void *dst);更常用。
-
函数中的p和n分别代表 表达式(presentation) 和 数值(numeric)。
-
同理,a 表示 ASCII码。
-
inet_pton示例
-
1 2 3 4 5 6// 创建socket struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); -
inet_ntop示例,和inet_ntoa 的最大区别就是,这个是可重入的。
-
1 2 3 4 5 6 7 8 9// 输出接收的 socket struct sockaddr_in client; char remote[INET_ADDRSTRLEN]; // 这个clientIp其实和remote是一样的,如果转换成功的话 const char *clientIp = inet_ntop(AF_INET, &client.sin_addr, remote, INET_ADDRSTRLEN); // 输出客户端 IP地址 和 端口号 printf("connected with ip: %s and port: %d\n", clientIp, ntohs(client.sin_port));
5. 创建 socket
-
使用 socket 函数。
-
1 2 3#include <sys/socket.h> #include <sys/types.h> int socket (int __domain, int __type, int __protocol) -

-
因此,将socket设置成非阻塞的可有以下两种方法:
-
(1)生成socket时设置
-
socket函数创建socket默认是阻塞的,也可以增加选项将socket设置为非阻塞的:
-
1int listenfd = socket(PF_INET, SOCK_STREAM | SOCK_NONBLOCK, 0); -
(2)使用fcntl设置
-
1 2 3 4 5 6 7// 将文件描述符设置为非阻塞的 int setnonblocking(int fd) { int old_option = fcntl(fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl(fd, F_SETFL, new_option); return old_option; }
6. 绑定/命名 bind socket
-
命名socket实际上就是把创建之后的socket描述符,和服务器的IP地址和端口号进行绑定。
-
注意接下来的几乎所有关于socket的库函数,传递的socket地址参数都是通用socket地址
struct sockaddr。 -
使用bind函数进行绑定。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15#include <sys/socket.h> #include <sys/types.h> int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen); /* (1)sockfd表示socket文件的文件描述符,一般为socket函数的返回值; (2)addr 表示服务器的IP地址和端口号; (3)addrlen表示参数addr的长度;addr参数可以接受多种类型的结构体,而这些结构体的长度各不相同,因此需要使用addrlen参数额外指定结构体长度; */ struct sockaddr { sa_family_t sa_family; /* Common data: address family and length. */ char sa_data[14]; /* Address data. */ }; -

7. 监听 listen socket
-
listen函数在一般在调用bind之后-调用accept之前调用。
-
socket被bind之后,不能马上accept接收客户连接,我们需要使用listen系统调用来创建一个监听队列以存放待处理的客户连接。此时的socket称为监听socket。
-
1 2 3 4 5 6 7 8 9 10 11 12 13#include <sys/socket.h> int listen(int sockfd, int backlog); /* (1)参数sockfd是被listen函数作用的socket的描述符; (2)参数backlog是侦听队列的长度; 在进程正在处理一个连接请求的时候,可能还存在其它的连接请求。 因为TCP连接是一个过程,所以可能存在一种半连接的状态,有时由于同时尝试连接的用户过多, 使得服务器进程无法快速地完成连接请求。 如果这个情况出现了,服务器进程希望内核如何处理呢? 内核会在自己的进程空间里维护一个队列以跟踪这些完成的连接但服务器进程还没有接手处理的连接 (还没有调用accept函数的连接),这样的一个队列内核不可能让其任意大, 所以必须有一个大小的上限。这个backlog告诉内核使用这个数值作为上限。 */ -

-
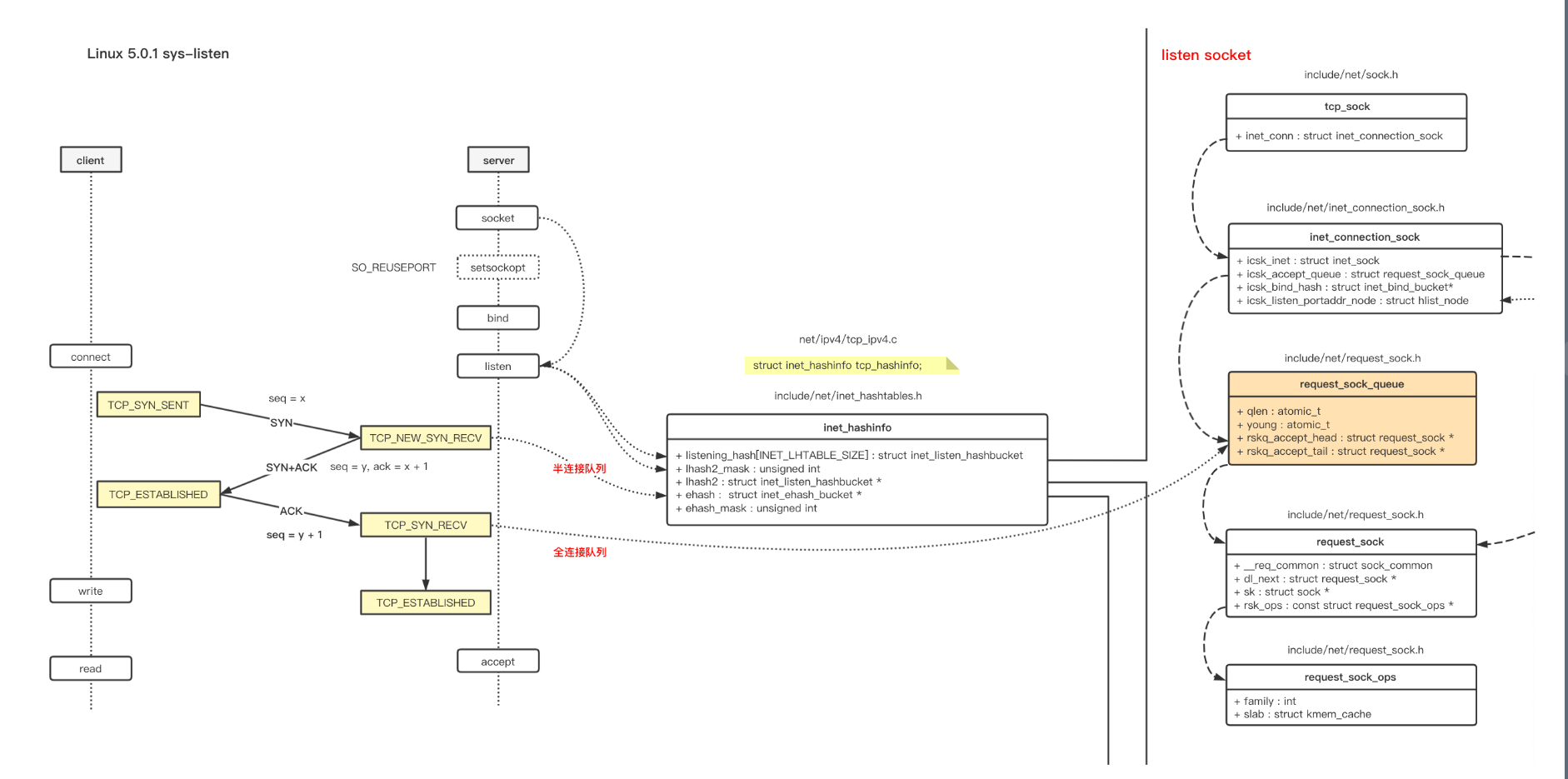
listen函数在内核中的具体实现流程如下。带
*的函数表示是通过函数指针引用而不是直接调用。 -

-
-
使用tcpdump观察三次握手过程。
tcpdump -S '(src 192.168.141.1 or dst 192.168.141.1) and port 12345' -
-S的作用是显示初始序列号,而不是相对序列号。 -

-
第一次握手,服务器进入 SYN-Recv 状态;第三次握手,服务器进入 Establish 状态。
-
因此 TCP 在listen后有两个队列:
- (1)SYN队列(半连接队列):当服务器端收到客户端的SYN报文时,会响应SYN/ACK报文,然后连接就会进入SYN RECEIVED状态,处于SYN RECEIVED状态的连接被添加到SYN队列,并且当它们的状态改变为ESTABLISHED时,即当接收到3次握手中的ACK分组时,将它们移动到accept队列。SYN队列的大小由内核参数/proc/sys/net/ipv4/tcp_max_syn_backlog设置,默认值为128。
- (2)accept队列(完全连接队列):accept队列存放的是已经完成TCP三次握手的连接,而accept系统调用只是简单地从accept队列中取出连接而已,并不是调用accept函数才会完成TCP三次握手。accept队列的大小由内核参数/proc/sys/net/core/somaxconn指定,默认值是128。
-
为什么要存在半连接队列? 因为根据TCP协议的特点,会存在半连接这样的网络攻击存在,即不停的发SYN包,而从不回应SYN_ACK。如果发一个SYN包就让Kernel建立一个消耗极大的sock,那么很容易就内存耗尽。所以内核在三次握手成功之前,只分配一个占用内存极小的request_sock,以防止这种攻击的现象,再配合syn_cookie机制,尽量抵御这种半连接攻击的风险。
-
以下是 Linux5.0.1的内核运行解释。
-
第一次握手时,服务端先创建一个轻量版本的 request_sock,第三次握手时,才会创建 sock,这样可以减少资源的消耗。(Linux 5.0.1)其实没有半连接队列,半连接的 request_sock 指针保存于 inet_hashinfo.ehash 哈希表里,而半连接的统计数据 qlen,保存于 listen sock 的 inet_connection_sock.icsk_accept_queue 里。
-
三次握手后,request_sock 指针会保存于全连接队列:inet_connection_sock.icsk_accept_queue.rskq_accept_head,等待 accept。
-
-
参考博客 listen (tcp)
8. 创建绑定监听socket实验
8.1 signal 系统调用
-
signal()是一个用于处理Unix和类Unix操作系统(如Linux)中的信号的系统调用。信号是用于在进程间或者进程内部传递通知或者异常事件的机制。信号可以由用户按下某个键、硬件异常、软件中断或者其他进程产生。signal()系统调用允许进程捕获、忽略或者改变特定信号的默认处理行为。
-
函数原型
-
1 2 3 4 5 6 7 8 9 10 11 12 13#include <signal.h> //使用此函数需导入此头文件 // sighandler_t 为函数指针类型,其指向一个参数为int,返回值为void的函数。 typedef void (*sighandler_t)(int); sighandler_t signal(int signum, sighandler_t handler); /* 参数: (1)int signum:指定要处理的信号。例如:SIGINT(终端中断)、SIGTERM(终止信号)等。 (2)sighandler_t handler:一个函数指针。可以是一个用户定义的函数,或者特殊值SIG_IGN(忽略信号)和SIG_DFL(使用默认处理行为)。 返回值: 如果成功,signal()返回之前的信号处理函数指针;否则,返回SIG_ERR,并设置errno以表示错误原因。 */ -
除了用户自定义信号处理函数外,
bits/signum.h头文件中还定义了信号的两种其他处理SIG_IGN和SIG_DEL: -
1 2 3#define SIG_ERR ((__sighandler_t) -1) /* Error return. */ #define SIG_DFL ((__sighandler_t) 0) /* Default action. */ #define SIG_IGN ((__sighandler_t) 1) /* Ignore signal. */ -
SIG_IGN表示忽略目标信号,SIG_DFL表示使用信号的默认处理方式。信号的默认处理方式有如下几种:结束进程(Term)、 忽略信号(Ign)、 结束进程并生成核心转储文件(Core)、暂停进程(Stop), 以及继续进程(Cont)。 -
下面是一个简单的cpp程序,使用signal()捕获SIGINT程序终止信号(当用户按下Ctrl+C时产生)并执行自定义处理函数。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22#include <signal.h> #include <stdio.h> #include <stdlib.h> #include <unistd.h> bool fg = true; void sigint_handler(int sig) { printf("捕获到信号 %d\n", sig); fg = false; } int main() { signal(SIGINT, sigint_handler); while (fg) { printf("等待信号...\n"); sleep(1); } return 0; } -
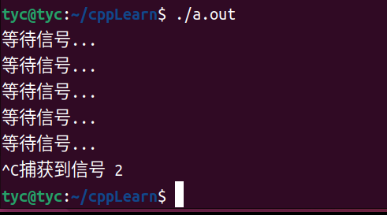
-
signal()在不同的Unix和类Unix系统中的行为可能会有所不同。对于可移植性和更多功能,推荐使用sigaction()系统调用。
-
这里浅浅说一下信号。
-
信号可以直接进行用户空间进程和内核空间进程的交互,内核进程可以利用它来通知用户空间进程发生了哪些系统事件。
每个信号的名字都以字符 SIG 开头。 每个信号和一个数字编码相对应,在头文件 signum.h 中,这些信号都被定义为正整数。
-
在 Linux 下,要想查看这些信号和编码的对应关系,可使用命令:kill -l
-
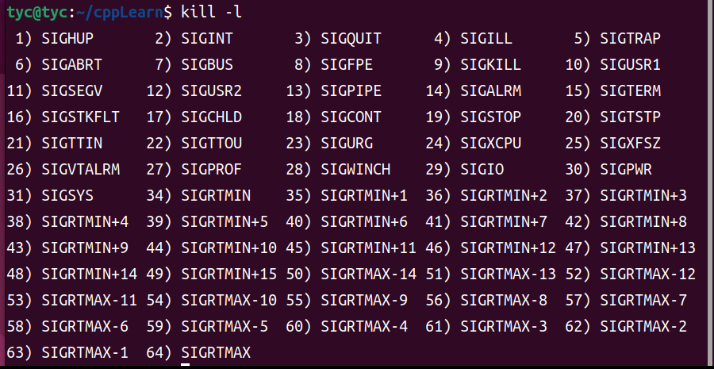
-
以下是部分信号解释
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 351) SIGHUP 本信号在用户终端连接(正常或非正常)结束时发出, 通常是在终端的控制进程结束时, 通知同一session内的各个作业, 这时它们与控制终端不再关联. 2) SIGINT 程序终止(interrupt)信号, 在用户键入INTR字符(通常是Ctrl-C)时发出。 3) SIGQUIT 和SIGINT类似, 但由QUIT字符(通常是Ctrl-)来控制. 进程在因收到 SIGQUIT退出时会产生core文件, 在这个意义上类似于一个程序错误信号. 4) SIGILL 执行了非法指令. 通常是因为可执行文件本身出现错误, 或者试图执行 数据段. 堆栈溢出时也有可能产生这个信号. 5) SIGTRAP 由断点指令或其它trap指令产生. 由debugger使用. 6) SIGABRT 程序自己发现错误并调用abort时产生. 7) SIGBUS 非法地址, 包括内存地址对齐(alignment)出错. eg: 访问一个四个字长 的整数, 但其地址不是4的倍数. 8) SIGFPE 在发生致命的算术运算错误时发出. 不仅包括浮点运算错误, 还包括溢 出及除数为0等其它所有的算术的错误. 9) SIGKILL 用来立即结束程序的运行. 本信号不能被阻塞, 处理和忽略. 10) SIGUSR1 留给用户使用 11) SIGSEGV 试图访问未分配给自己的内存, 或试图往没有写权限的内存地址写数据. 12) SIGUSR2 留给用户使用 13) SIGPIPE Broken pipe 14) SIGALRM 时钟定时信号, 计算的是实际的时间或时钟时间. alarm函数使用该信号. 15) SIGTERM 程序结束(terminate)信号, 与SIGKILL不同的是该信号可以被阻塞和处理. 通常用来要求程序自己正常退出. shell命令kill缺省产生这个信号. 17) SIGCHLD 子进程结束时, 父进程会收到这个信号. 18) SIGCONT 让一个停止(stopped)的进程继续执行. 本信号不能被阻塞. 可以用 一个handler来让程序在由stopped状态变为继续执行时完成特定的工作. 例如, 重新显示提示符. 19) SIGSTOP 停止(stopped)进程的执行. 注意它和terminate以及interrupt的区别: 该进程还未结束, 只是暂停执行. 本信号不能被阻塞, 处理或忽略. 20) SIGTSTP 停止进程的运行, 但该信号可以被处理和忽略. 用户键入SUSP字符时 (通常是Ctrl-Z)发出这个信号. 21) SIGTTIN 当后台作业要从用户终端读数据时, 该作业中的所有进程会收到SIGTTIN 信号. 缺省时这些进程会停止执行. 22) SIGTTOU 类似于SIGTTIN, 但在写终端(或修改终端模式)时收到. 23) SIGURG 有"紧急"数据或out-of-band数据到达socket时产生. 24) SIGXCPU 超过CPU时间资源限制. 这个限制可以由getrlimit/setrlimit来读取/ 改变 25) SIGXFSZ 超过文件大小资源限制. 26) SIGVTALRM 虚拟时钟信号. 类似于SIGALRM, 但是计算的是该进程占用的CPU时间. 27) SIGPROF 类似于SIGALRM/SIGVTALRM, 但包括该进程用的CPU时间以及系统调用的时间. 28) SIGWINCH 窗口大小改变时发出. 29) SIGIO 文件描述符准备就绪, 可以开始进行输入/输出操作. 有两个信号可以停止进程:SIGTERM和SIGKILL。 SIGTERM比较友好,进程能捕捉这个信号,根据您的需要来关闭程序。在关闭程序之前,您可以结束打开的记录文件和完成正在做的任务。在某些情况下,假如进程正在进行作业而且不能中断,那么进程可以忽略这个SIGTERM信号。 对于SIGKILL信号,进程是不能忽略的。这是一个 “我不管您在做什么,立刻停止”的信号。假如您发送SIGKILL信号给进程,Linux就将进程停止在那里。 -
SIGINT:程序终止信号。当用户按下CRTL+C时通知前台进程组终止进程 或者
kill -2 <pid>触发。 -
SIGTERM:程序结束信号, 可以使用
kill -15 <pid>触发 -
SIGKILL:用来立即结束程序的运行。可以使用
kill -9 <pid>触发 -
SIGTERM和SIGKILL的区别:SIGTERM信号是可以被捕获的,因此可以尝试block,或者忽视,但是SIGKILL不能。
8.2 实验
-
这里需要注意的是,为sockaddr_in成员赋值时需要显式地将主机字节序转换为网络字节序,而通过 write()/send() 函数发送数据时TCP协议会自动转换为网络字节序,不需要再调用相应的函数。
-
实验代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58#include <arpa/inet.h> #include <assert.h> #include <netinet/in.h> #include <signal.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> static bool stop = false; static void handle_term(int sig) { stop = true; } int main(int argc, char *argv[]) { signal(SIGTERM, handle_term); if (argc <= 3) { printf("usage: %s ip_address port_number backlog\n", basename(argv[0])); return 1; } // 输入的ip、端口、个数 const char *ip = argv[1]; int port = atoi(argv[2]); int backlog = atoi(argv[3]); int sock = socket(PF_INET, SOCK_STREAM, 0); assert(sock >= 0); // 创建 socket 地址 struct sockaddr_in address; /* bzero()函数已经被标记为废弃函数,不再建议使用。 在新的代码中,可以使用memset()函数来代替bzero()函数。 bzero(&address, sizeof(address)); */ memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; // 转换为网络字节序的整数ip inet_pton(AF_INET, ip, &address.sin_addr); // 转换为网络字节序的端口号 address.sin_port = htons(port); int ret = bind(sock, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); // 创建监听队列 ret = listen(sock, backlog); assert(ret != -1); // 一直监听,等待手动退出 kill -15 while (!stop) { sleep(1); } close(sock); return 0; } -
本地ip地址为 192.168.141.1,服务器地址为 192.168.141.128。
-
(1) 首先在服务器运行上述程序
-
1./listen 192.168.141.128 12345 4 -
(2) 然后在服务器创建监视的命令
-
1watch -n 1 "netstat -an | grep 12345 >> a.txt" -
(3) 最后依次在本地多次telent服务器,至少执行6次。
-
1telnet 192.168.141.128 12345 -
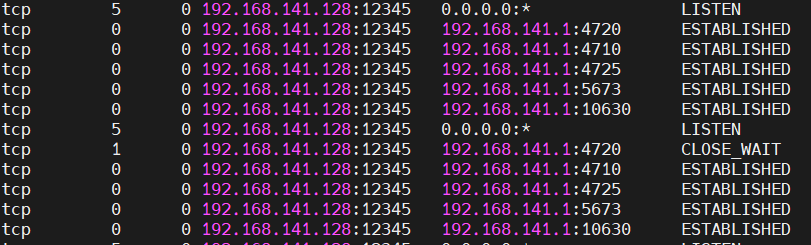
(4) 结果分析
-
首先可以看到,本地的第6次telnet,就无法连接成功了。可见,在监听队列中,处于ESTABLISHED状态的最多连接只有5个(backlog值加1)。
-
其次服务器重定向输出到txt的结果中,可见确实只有5个连接。
-
1 2 3 4 5 6tcp 5 0 192.168.141.128:12345 0.0.0.0:* LISTEN tcp 0 0 192.168.141.128:12345 192.168.141.1:4720 ESTABLISHED tcp 0 0 192.168.141.128:12345 192.168.141.1:4710 ESTABLISHED tcp 0 0 192.168.141.128:12345 192.168.141.1:4725 ESTABLISHED tcp 0 0 192.168.141.128:12345 192.168.141.1:5673 ESTABLISHED tcp 0 0 192.168.141.128:12345 192.168.141.1:10630 ESTABLISHED -
-
这里说明一下,虽然连接队列的最大长度是指定的,但这只是影响在队列中等待的连接请求的数量。一旦父进程或任意子进程调用
accept来接受一个连接,就会从队列中取出一个连接进行处理。
9. 接受连接 accept
9.1 函数详解
-
listen函数存在最大连接队列长度,因此需要accept函数来取出连接进行处理。
-
listen函数不会阻塞,它只是相当于把socket的属性更改为被动连接,可以接收其他进程的连接。listen侦听的过程并阻塞的,它只是设置好socket的属性之后就会返回。监听的过程实质由操作系统完成。但是accept会阻塞(也可以设置为非阻塞),如果listen的套接字对应的连接请求队列为空(没有客户端连接请求),它会一直阻塞等待。
-
accept()函数本身是阻塞等待的。
-
accept()接受一个客户端的连接请求(从ESTABLISHED完全连接队列里面提出),并返回一个新的套接字socket描述符。
-
所谓“新的”就是说这个套接字与socket()返回的用于监听和接受客户端的连接请求的套接字不是同一个套接字。与本次接受的客户端的通信是通过在这个新的套接字上发送和接收数据来完成的,这样的好处是可以进行并发通信。
-
1 2 3# include <sys/types.h> # include <sys/socket.h> int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen); -
参数一sockfd:用来标识服务端套接字(也就是listen函数中设置为监听状态的套接字); 参数二addr:是用来保存客户端套接字对应的内存空间变量(包括客户端IP和端口信息等); 参数三addrlen:参数二内存空间大小。
-
返回值
1)成功: 返回一个服务器用于以后通信的“通信描述符”,即通信的socket描述符。 2)失败: 返回-1,并设置errno。
-

-
需要注意的是,三次握手完成后,服务器可以调用accept()接受连接,如果服务器调用accept()时还没有客户端的连接请求,就阻塞等待直到有客户端连接上来。
-
可见accept函数本身并不会等待一个特定的时间,而是会一直阻塞,直到有一个客户端连接请求到达为止。当有一个连接请求到达时,accept函数会返回一个新的套接字描述符,用于与客户端进行通信。
9.2 实验
-
现在考虑如下情况:如果监听队列中处于ESTABLISHED状态的连接对应的客户端出现网络异常(比如掉线),或者客户端直接关闭,那么服务器对这个连接执行的accept调用是否成功?实验代码如下。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> int main(int argc, char *argv[]) { // if (argc <= 2) { // printf("usage: %s ip_address port_number\n", basename(argv[0])); // return 1; // } // const char *ip = argv[1]; // int port = atoi(argv[2]); const char *ip = "192.168.141.128"; int port = 12345; // 创建socket struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int sock = socket(PF_INET, SOCK_STREAM, 0); assert(sock >= 0); // 绑定 int ret = bind(sock, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); // 监听 ret = listen(sock, 5); assert(ret != -1); // 接受一个连接 struct sockaddr_in client; socklen_t client_addrlength = sizeof(client); int connfd = accept(sock, (struct sockaddr *)&client, &client_addrlength); if (connfd < 0) { printf("errno is: %d\n", errno); } else { char remote[INET_ADDRSTRLEN]; const char *clientIp = inet_ntop(AF_INET, &client.sin_addr, remote, INET_ADDRSTRLEN); // 输出客户端 IP地址 和 端口号 printf("connected with ip: %s and port: %d\n", clientIp, ntohs(client.sin_port)); // 等待20s客户端进行提前关闭 sleep(20); close(connfd); printf("close accept socket\n"); } sleep(2); close(sock); printf("close listen socket\n"); return 0; } -
(1)在服务器运行上述程序之后,本地在20s范围内在命令行输入
telnet 192.168.141.128 12345,然后按ctrl+]马上断开客户端网络,此时查看服务器的socket状态如下: -

-
这种输出说明,accept调用对客户端网络断开毫不知情。
-
(2)这时候直接关闭客户端程序,即关闭命令行界面。此时查看服务器的socket状态如下:
-

-
-
可以看到 CLOSE_WAIT 状态是由客户端发起关闭请求后进入的状态。
-
(3)上两次关闭,服务器均可正常输出。
-

10. 客户端发起连接 connect
-
如果说服务器通过listen调用来被动接受连接,那么客户端需要通过connect系统调用来主动与服务器建立连接。
-
在Linux系统中,
connect函数默认是阻塞的。当调用connect函数时,如果连接建立成功,该函数会立即返回;如果连接建立失败或者正在进行连接过程中,connect函数会阻塞程序的执行,直到连接建立成功或者发生错误(判断无法正常连接)。 -
1 2 3 4 5 6 7 8 9 10#include <sys/types.h> #include <sys/socket.h> int connect(int sockfd, const struct sockaddr *server_addr, socklen_t *addrlen); /** * 建立连接 * @param sockfd: socket函数返回的一个socket,用于标识该连接; * @param server_addr: 服务端地址, ip地址+端口号; * @param addrlen: 服务端地址地址长度; * @return 函数执行成功返回0,失败返回-1 */ -
一旦成功建立连接,sockfd就唯一地标识了这个连接,客户端就可以通过读写sockfd来与服务器通信。
-
connect失败则返回-1并设置errno。其中两种常见的errno是ECONNREFUSED和ETIMEDOUT,它们的含义如下
- ECONNREFUSED,目标端口不存在,连接被拒绝。
- ETIMEDOUT,连接超时。
11. 关闭连接 close 和 shutdown
11.1 函数详解
-
(1)close
-
1 2 3 4#include <unistd.h> int close(int fd) // fd 是待关闭的socket描述符 // 返回值:成功返回0,出错返回-1并设置errno- 读方向上,内核会将套接字设置为不可读,任何读操作都会返回异常;
- 写方向上,内核会尝试将发送缓冲区的数据发送给对端,之后发送fin包结束连接,这个过程中,往套接字写入数据都会返回异常。
- 若对端还发送数据过来,会返回对方一个rst报文。
-
因此 close 终止了两个数据传输的方向。
-
套接字会维护一个计数,当有一个进程持有,计数加一,close调用时会检查计数,只有当计数为0时,才会关闭连接,否则,只是将套接字的计数减一。
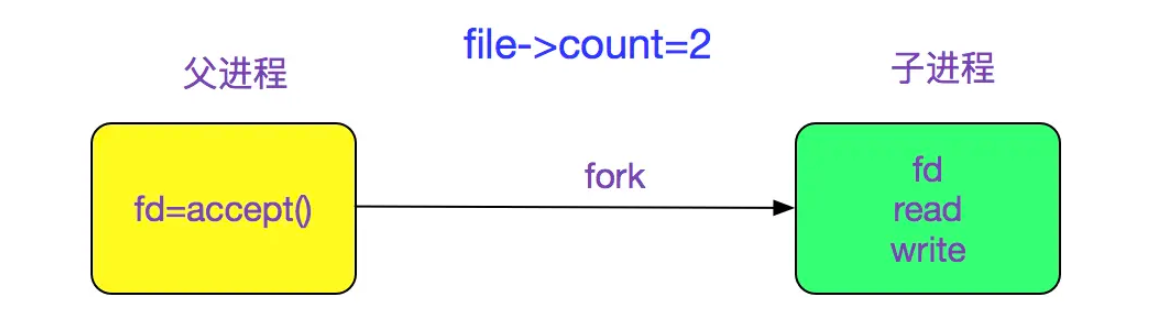
-
多进程程序中,一次fork系统调用默认将使父进程中打开的socket的引用计数加1,因此我们必须在父进程和子进程中都对该socket执行close调用才能将连接关闭。
-
(2)shutdown
-
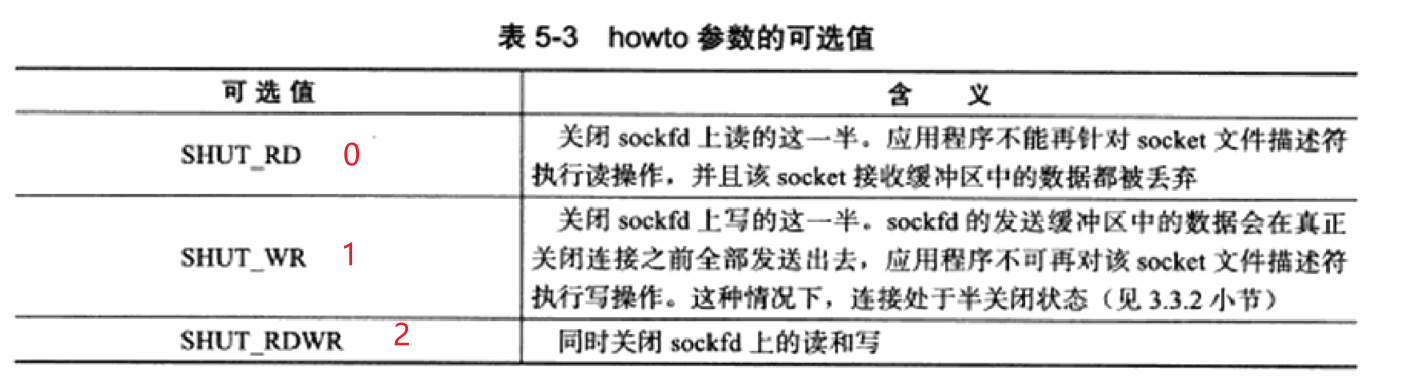
1 2#include <sys/socket.h> int shutdown(int sockfd, int howto) -
shutdown显得更加优雅,能控制只关闭连接的一个方向;
-
sockfd参数是待关闭的socket,howto参数决定了shutdown的行为。
howto = 0关闭连接的读方向,对该套接字进行读操作直接返回EOF;将接收缓冲区中的数据丢弃,之后再有数据到达,会对数据进行ACK,然后悄悄丢弃。howto = 1关闭连接的写方向,会将发送缓冲区上的数据发送出去,然后发送fin包;应用程序对该套接字的写入操作会返回异常(shutdown不会检查套接字的计数情况,会直接关闭连接)howto = 20+1各操作一遍,关闭连接的两个方向。
-
-
shutdown成功时返回0,失败则返回-1并设置error。
-
(3)考虑如下场景:
-
我们知道,TCP的四次挥手是半关闭的操作,即服务器收到客户端的 FIN 报文时,先回一个 ACK 应答报文,而服务端可能还有数据需要处理和发送 。等服务端不再发送数据时,才发送 FIN 报文给客户端来表示同意现在关闭连接。
-
假设现在客户端调用了close同时关闭了读写,然后服务端收到了FIN报文,这时候服务器端套接字缓冲区还有数据未发送出去,这时候服务端socket是否会将这些发送出去呢,如果发送出去了,客户端是否会接收呢?
-
解答:
-
客户端调用close后,会尽量将内核中的数据发送出去,然后调用FIN包结束连接;同时会关闭读写两个方向的缓冲区。
-
这个时候如果服务端调用write写数据时,可能会发现write能正常返回,但最终会收到一个RST重置报文。因为发送数据分两步:
- write将数据写入到内核缓冲区中,这一步是可以成功的。
- 内核缓冲区将数据发送到客户端,这个时候由于客户端已经关闭了接收缓冲区,无法正常接收,所以会回复一个rst报文让服务端重置连接。
-
所以,「想要服务端收到客户端FIN报文后能继续向客户端发数据,客户端必须使用shutdown SHUT_WR?」 是的。再多提一点,服务端当收到rst包后,继续往关闭的socket中写数据,会触发SIGPIPE信号, 该信号默认结束进程。 所以你可以发现很多服务端,都会忽略sigpipe信号的处理,避免客户端粗鲁关闭+服务器端对客户端断开连接读写处理不当导致整个进程奔溃。
-
(4)close 和 shutdown的区别
-
close 会关闭 fd,而shutdown不会;在使用了shutdown SHUT_RDWR 后,仍然需要close来关闭这个文件描述符。
-
close 在fd 被多进程持有或被复制时,不会立马关闭连接,只是使得引用个数减1,直到等于0才实际关闭;shutdown SHUT_RDWR会直接关闭连接(发送FIN),而无论是否有其他打开的文件描述符指向套接字。
-
因此,优雅地关闭连接,一般是shutdown读端和写端,接着close。
11.2 close 源码分析
-
(1) close (int fd) 是通过系统调用 sys_close 来执行的:
-
1 2 3 4 5 6 7 8 9 10 11asmlinkage long sys_close(unsigned int fd) { // 清除(close_on_exec即退出进程时)的位图标记 FD_CLR(fd, fdt->close_on_exec); // 释放文件描述符 // 将fdt->open_fds即打开的fd位图中对应的位清除 // 再将fd挂入下一个可使用的fd以便复用 __put_unused_fd(files, fd); // 调用file_pointer的close方法真正清除 retval = filp_close(filp, files); } -
(2) 我们看到最终是调用的 filp_close 方法:
-
1 2 3 4 5 6 7 8 9int filp_close(struct file *filp, fl_owner_t id) { // 如果存在flush方法则flush if (filp->f_op && filp->f_op->flush) filp->f_op->flush(filp, id); // 调用fput fput(filp); ...... } -
(3) 紧接着我们进入fput(filp);
-
1 2 3 4 5 6 7void fastcall fput(struct file *file) { // 对应file->count--,同时检查是否还有关于此file的引用 // 如果没有,则调用_fput进行释放 if (atomic_dec_and_test(&file->f_count)) __fput(file); } -
这个函数的前半部分是为了减少打开的socket的引用计数,进而判断是否真的需要 close 这个socket。
-
同一个 file (socket) 有多个引用的情况很常见,例如下面的例子:
-
-
所以在多进程的 socket 服务器编写过程中,父进程也需要 close (fd) 一次,以免 socket 无法最终关闭。
-
(4) 然后进入 __fput(file) 函数。
-
1 2 3 4 5 6 7 8void fastcall __fput(struct file *file) { // 从eventpoll中释放file eventpoll_release(file); // 如果是release方法,则调用release if (file->f_op && file->f_op->release) file->f_op->release(inode, file); } -
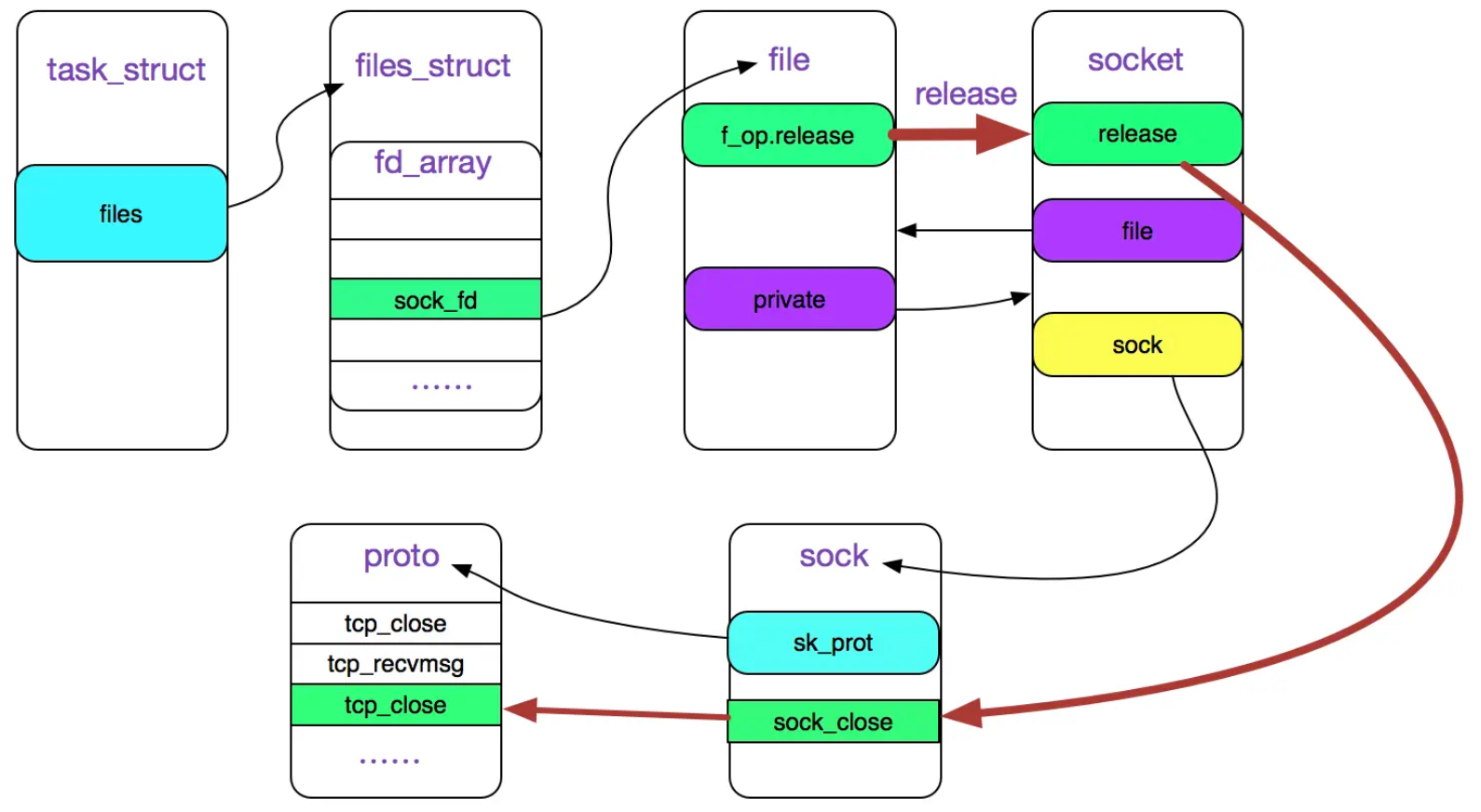
由于我们讨论的是 socket 的 close, 所以,我们重点探查下
file->f_op->release在 socket 情况下的实现: -
在C语言中,通过函数指针实现重载,即多态。
-
可以看到,最终会调用文件系统对应的
release()方法来处理关闭操作。对于 socket 文件系统,release()方法对应的是sock_close()函数。 -
(5) 进入 sock_close 函数
-
sock_close 用来关闭套接口文件。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17static int sock_close(struct inode *inode, struct file *filp) { /* * It was possible the inode is NULL we were * closing an unfinished socket. */ if (!inode) { printk(KERN_DEBUG "sock_close: NULL inode\n"); return 0; } //与从文件描述符filp关联的套接口异步通知队列中删除与文件描述符filp有关的异步通知节点。 sock_fasync(-1, filp, 0); //关闭套接口 sock_release(SOCKET_I(inode)); return 0; } -
(6) 然后进入 sock_release 函数
-
sock_release 来实现关闭套接口功能。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23void sock_release(struct socket *sock) { if (sock->ops) { struct module *owner = sock->ops->owner; sock->ops->release(sock); // inet_release sock->ops = NULL; module_put(owner); } //处理异步通知队列之后,若还发现异步通知队列不为空,表明系统有问题,打印信息提示 if (sock->fasync_list) printk(KERN_ERR "sock_release: fasync list not empty!\n"); //更新sockets_in_use,该字段主要用来统计当前cpu打开的套接口文件的数量 get_cpu_var(sockets_in_use)--; put_cpu_var(sockets_in_use); // 释放i节点和套接口 if (!sock->file) { iput(SOCK_INODE(sock)); return; } sock->file = NULL; } -
可以看到,最终会调用到sock->ops->release(sock);依据函数重载,以及TCP/IP协议,sock->ops->release(sock)对应的方法实际上就是inet_release函数。
-
1 2 3sock_close |-sock_release |-sock->ops->release(sock); -
(7) 进入inet_release函数
-
inet_release 为 IPV4 协议中 close 系统调用的套接口层的实现。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22int inet_release(struct socket *sock) { struct sock *sk = sock->sk; if (sk) { long timeout; /* Applications forget to leave groups before exiting */ ip_mc_drop_socket(sk); /*timeout的值和SOCK_LINGER选项有关,这个选项可以通过setsockopt()来设置, 该选项表示在关闭连接时需要等待的时间,设置的事件值保存在sk_lingertime */ timeout = 0; if (sock_flag(sk, SOCK_LINGER) && !(current->flags & PF_EXITING)) timeout = sk->sk_lingertime; sock->sk = NULL; sk->sk_prot->close(sk, timeout);//tcp_close } return 0; } -
最终会调用到 sk->sk_prot->close 函数,对于 TCP 协议来说,就是tcp_close函数。
-
-
(8) 进入最终boss函数 tcp_close
-
对于TCP,关闭套接口的实现为 tcp_close。
-
有些概念这里需要说明下:
-
(a)skb(struct sk_buffer)是TCP/IP堆栈中用于收发包的缓冲区域。它在接收数据的时候会进行2次拷贝,以提升性能:数据包进入网卡驱动后拷贝一次,从内核空间递交给用户空间的应用时再拷贝一次。网络中所有数据包的封装及解封都是通过这个结构进行的。
-
(b)tcp_close_state 函数的作用是进行 TCP 的状态转移,并判断是否可以发送 FIN 报文。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19/* Location: net/ipv4/tcp.c Function: 进行状态转移,并且判断是否可以发送 FIN。 Parameter: sk: 传输控制块 */ static int tcp_close_state(struct sock *sk) { int next = (int)new_state[sk->sk_state]; /* 去除可能的 FIN_ACTION*/ int ns = next & TCP_STATE_MASK; /* 根据状态图进行状态转移 */ tcp_set_state(sk, ns); /* 如果需要执行发送 FIN 的动作,则返回真 */ return next & TCP_ACTION_FIN; } -
tcp_close_state 的作用就是根据sk当前状态来设置sk下一状态,比如当前状态为TCP_ESTABLISHED,则下一状态为TCP_FIN_WAIT1。该函数的返回要么为0,要么为TCP_ACTION_FIN。为0说明不需要发送fin报文。为TCP_ACTION_FIN说明需要发送FIN报文。
-
-
(c)tcp_time_wait 函数的作用是主动进入TIME_WAIT 状态,分为两种情况,Move a socket to time-wait or dead fin-wait-2 state.
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84/* * Move a socket to time-wait or dead fin-wait-2 state. */ /* * @sk: 被取代的传输控制块。 * @state: timewait控制块内部的状态,为FIN_WAIT2或TIME_WAIT,即子状态 * @timeo: 等待超时时间 sock结构进入TIME_WAIT状态有两种情况: (1)一种是在真正进入了TIME_WAIT状态,即在规定时间内主动关闭端收到了第二个fin进入time_wait状态; (2)还有一种是FIN_WAIT_2的TIME_WAIT状态。 之所以让FIN_WAIT_2状态在没有接收到FIN包的情况下也可以进入TIME_WAIT状态,是因为tcp_sock结构占用的资源要比tcp_timewait_sock结构占用的资源多,而且在TIME_WAIT下也可以处理连接的关闭。内核在处理时通过inet_timewait_sock结构的tw_substate成员(子状态)来区分这种两种情况。 */ void tcp_time_wait(struct sock *sk, int state, int timeo) { const struct inet_connection_sock *icsk = inet_csk(sk); const struct tcp_sock *tp = tcp_sk(sk); struct net *net = sock_net(sk); struct inet_timewait_sock *tw; tw = inet_twsk_alloc(sk, &net->ipv4.tcp_death_row, state); if (tw) { struct tcp_timewait_sock *tcptw = tcp_twsk((struct sock *)tw); const int rto = (icsk->icsk_rto << 2) - (icsk->icsk_rto >> 1); struct inet_sock *inet = inet_sk(sk); tw->tw_transparent = inet->transparent; tw->tw_mark = sk->sk_mark; tw->tw_priority = sk->sk_priority; tw->tw_rcv_wscale = tp->rx_opt.rcv_wscale; tcptw->tw_rcv_nxt = tp->rcv_nxt; tcptw->tw_snd_nxt = tp->snd_nxt; tcptw->tw_rcv_wnd = tcp_receive_window(tp); tcptw->tw_ts_recent = tp->rx_opt.ts_recent; tcptw->tw_ts_recent_stamp = tp->rx_opt.ts_recent_stamp; tcptw->tw_ts_offset = tp->tsoffset; tcptw->tw_last_oow_ack_time = 0; tcptw->tw_tx_delay = tp->tcp_tx_delay; tw->tw_txhash = sk->sk_txhash; #if IS_ENABLED(CONFIG_IPV6) if (tw->tw_family == PF_INET6) { struct ipv6_pinfo *np = inet6_sk(sk); tw->tw_v6_daddr = sk->sk_v6_daddr; tw->tw_v6_rcv_saddr = sk->sk_v6_rcv_saddr; tw->tw_tclass = np->tclass; tw->tw_flowlabel = be32_to_cpu(np->flow_label & IPV6_FLOWLABEL_MASK); tw->tw_ipv6only = sk->sk_ipv6only; } #endif tcp_time_wait_init(sk, tcptw); /* Get the TIME_WAIT timeout firing. */ if (timeo < rto) timeo = rto; if (state == TCP_TIME_WAIT) timeo = TCP_TIMEWAIT_LEN; /* tw_timer is pinned, so we need to make sure BH are disabled * in following section, otherwise timer handler could run before * we complete the initialization. */ local_bh_disable(); inet_twsk_schedule(tw, timeo); /* Linkage updates. * Note that access to tw after this point is illegal. */ inet_twsk_hashdance(tw, sk, net->ipv4.tcp_death_row.hashinfo); local_bh_enable(); } else { /* Sorry, if we're out of memory, just CLOSE this * socket up. We've got bigger problems than * non-graceful socket closings. */ NET_INC_STATS(net, LINUX_MIB_TCPTIMEWAITOVERFLOW); } // 设置sk状态为TCP_CLOSE,然后回收sk资源 tcp_update_metrics(sk); tcp_done(sk); }
-
-
-
tcp_close 源码分析如下:
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215void __tcp_close(struct sock *sk, long timeout) { struct sk_buff *skb; int data_was_unread = 0; int state; // 设置SHUTDOWN_MASK表示recv和send都已经shutdown WRITE_ONCE(sk->sk_shutdown, SHUTDOWN_MASK); // TCP_LISTEN 状态处理 if (sk->sk_state == TCP_LISTEN) { // 设置close状态 tcp_set_state(sk, TCP_CLOSE); /* Special case. */ // 清理完成连接队列,并向每个socket发送rst报文 inet_csk_listen_stop(sk); goto adjudge_to_death; } /* We need to flush the recv. buffs. We do this only on the * descriptor close, not protocol-sourced closes, because the * reader process may not have drained the data yet! */ /*如果此时接收队列中不为空,即接收到的数据没有被用户进程读取, 这时需要将接受队列中的SKB包全都释放掉,释放的数据长度存储在data_was_unread中 */ while ((skb = __skb_dequeue(&sk->sk_receive_queue)) != NULL) { u32 len = TCP_SKB_CB(skb)->end_seq - TCP_SKB_CB(skb)->seq; if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN) len--; data_was_unread += len; __kfree_skb(skb); } /* If socket has been already reset (e.g. in tcp_reset()) - kill it. */ // 如果 socket 本身就是 close 状态的话,直接跳到 adjudge_to_death 就好 if (sk->sk_state == TCP_CLOSE) goto adjudge_to_death; /* As outlined in RFC 2525, section 2.17, we send a RST here because * data was lost. To witness the awful effects of the old behavior of * always doing a FIN, run an older 2.1.x kernel or 2.0.x, start a bulk * GET in an FTP client, suspend the process, wait for the client to * advertise a zero window, then kill -9 the FTP client, wheee... * Note: timeout is always zero in such a case. */ if (unlikely(tcp_sk(sk)->repair)) { sk->sk_prot->disconnect(sk, 0); } else if (data_was_unread) { /* Unread data was tossed, zap the connection. */ /* 在存在未读数据情况下处理断开连接。如果关闭的套接口还有未读取的数据, 则发送RST而不是FIN给对方,因为FIN表示一切正常。 */ NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONCLOSE); tcp_set_state(sk, TCP_CLOSE); tcp_send_active_reset(sk, sk->sk_allocation); } else if (sock_flag(sk, SOCK_LINGER) && !sk->sk_lingertime) { /* Check zero linger _after_ checking for unread data. */ /* 当需要关闭的TCP连接设置了so_linger延迟关闭,并且延迟时间设置为0, 直接丢掉所有的发送和接收队列中的报文,设置连接状态为TCP_CLOSE; 若此TCP不处于TCP_SYN_SENT状态,则发送reset报文给对端; 备注: 此项可知设置 SO_LINGER+时间为0可以调用close()用reset报文关闭连接; */ sk->sk_prot->disconnect(sk, 0); NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA); } else if (tcp_close_state(sk)) { /* 其他情况,如禁止SO_LINGER选项或启用了SO_LINGER选项且延时时间不为O, 则从当前状态转换到对应的状态,并返回得到转换后的动作; 如果是TCP_ACTION_FIN动作(即新的状态可以发送FIN段),则发送FIN段给对端, 将发送队列上未发送的段发送出去。 */ /* We FIN if the application ate all the data before * zapping the connection. */ /* RED-PEN. Formally speaking, we have broken TCP state * machine. State transitions: * * TCP_ESTABLISHED -> TCP_FIN_WAIT1 * TCP_SYN_RECV -> TCP_FIN_WAIT1 (forget it, it's impossible) * TCP_CLOSE_WAIT -> TCP_LAST_ACK * * are legal only when FIN has been sent (i.e. in window), * rather than queued out of window. Purists blame. * * F.e. "RFC state" is ESTABLISHED, * if Linux state is FIN-WAIT-1, but FIN is still not sent. * * The visible declinations are that sometimes * we enter time-wait state, when it is not required really * (harmless), do not send active resets, when they are * required by specs (TCP_ESTABLISHED, TCP_CLOSE_WAIT, when * they look as CLOSING or LAST_ACK for Linux) * Probably, I missed some more holelets. * --ANK * XXX (TFO) - To start off we don't support SYN+ACK+FIN * in a single packet! (May consider it later but will * probably need API support or TCP_CORK SYN-ACK until * data is written and socket is closed.) */ tcp_send_fin(sk); } /* 调用 sk_stream_wait_close () 进入阻塞状态。超时时间是 SO_LINGER 选项中设置的。 在给对端发送RST或FIN段后,等待套接口的关闭,直到TCP状态不为FIN_WAIT_1、CLOSING、LAST_ACK或等待超时; 也即是若如处于这3种状态时,进程会阻塞,直到超时; 因为这3种状态需要接收 ACK 的确认。 */ sk_stream_wait_close(sk, timeout); adjudge_to_death: /* 置套接口为DEAD状态,成为孤儿套接口,同时更新系统中孤儿套接口数。 在真正关闭之前,先处理接收到后备队列上的段。 */ state = sk->sk_state; sock_hold(sk); sock_orphan(sk); local_bh_disable(); bh_lock_sock(sk); /* remove backlog if any, without releasing ownership. */ __release_sock(sk); this_cpu_inc(tcp_orphan_count); /* 如果此时该传输控制块TCP状态已经为CLOSE,则无需再作处理了。 */ /* Have we already been destroyed by a softirq or backlog? */ if (state != TCP_CLOSE && sk->sk_state == TCP_CLOSE) goto out; /* This is a (useful) BSD violating of the RFC. There is a * problem with TCP as specified in that the other end could * keep a socket open forever with no application left this end. * We use a 1 minute timeout (about the same as BSD) then kill * our end. If they send after that then tough - BUT: long enough * that we won't make the old 4*rto = almost no time - whoops * reset mistake. * * Nope, it was not mistake. It is really desired behaviour * f.e. on http servers, when such sockets are useless, but * consume significant resources. Let's do it with special * linger2 option. --ANK */ // 处理从 FIN_WAIT_2 状态到 CLOSE 状态的转换 if (sk->sk_state == TCP_FIN_WAIT2) { struct tcp_sock *tp = tcp_sk(sk); if (tp->linger2 < 0) { /* 如果该传输控制块的TCP_LINGER2选项值小于0, 表示无需在FIN_WAIT_2状态等待转换到CLOSE状态, 而是立即设置为CLOSE状态,然后给对端发送RST段。 */ tcp_set_state(sk, TCP_CLOSE); tcp_send_active_reset(sk, GFP_ATOMIC); __NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONLINGER); } else { /* 根据tcp_fin timeout()和往返时间获取需要保持FIN_WAIT_2状态的时长tmo。 如果大于60s(TCP_TIMEWAIT_LEN),则需要用FIN_WAIT_2定时器来处理,否则调用tcp_time_wait()由timewait控制块取代tcp_sock传输控制块,从FN_WAIT_2状态转换到CLOSE状态。 这里等待第三次挥手。 */ const int tmo = tcp_fin_time(sk); if (tmo > TCP_TIMEWAIT_LEN) { inet_csk_reset_keepalive_timer(sk, tmo - TCP_TIMEWAIT_LEN); } else { tcp_time_wait(sk, TCP_FIN_WAIT2, tmo); goto out; } } } if (sk->sk_state != TCP_CLOSE) { if (tcp_check_oom(sk, 0)) { tcp_set_state(sk, TCP_CLOSE); tcp_send_active_reset(sk, GFP_ATOMIC); __NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONMEMORY); } else if (!check_net(sock_net(sk))) { /* Not possible to send reset; just close */ tcp_set_state(sk, TCP_CLOSE); } } if (sk->sk_state == TCP_CLOSE) { struct request_sock *req; req = rcu_dereference_protected(tcp_sk(sk)->fastopen_rsk, lockdep_sock_is_held(sk)); /* We could get here with a non-NULL req if the socket is * aborted (e.g., closed with unread data) before 3WHS * finishes. */ if (req) reqsk_fastopen_remove(sk, req, false); inet_csk_destroy_sock(sk); } /* Otherwise, socket is reprieved until protocol close. */ out: bh_unlock_sock(sk); local_bh_enable(); } -
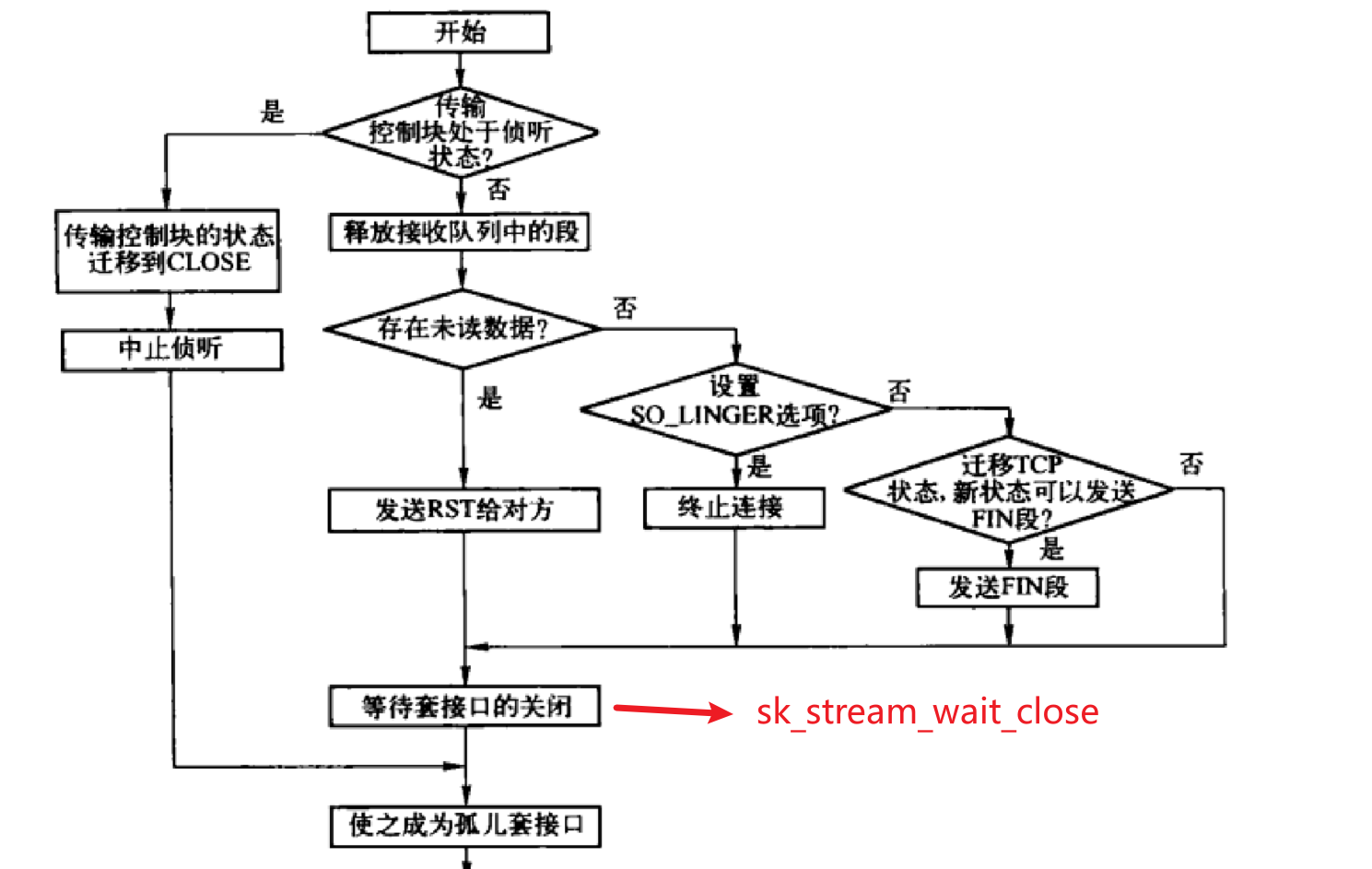
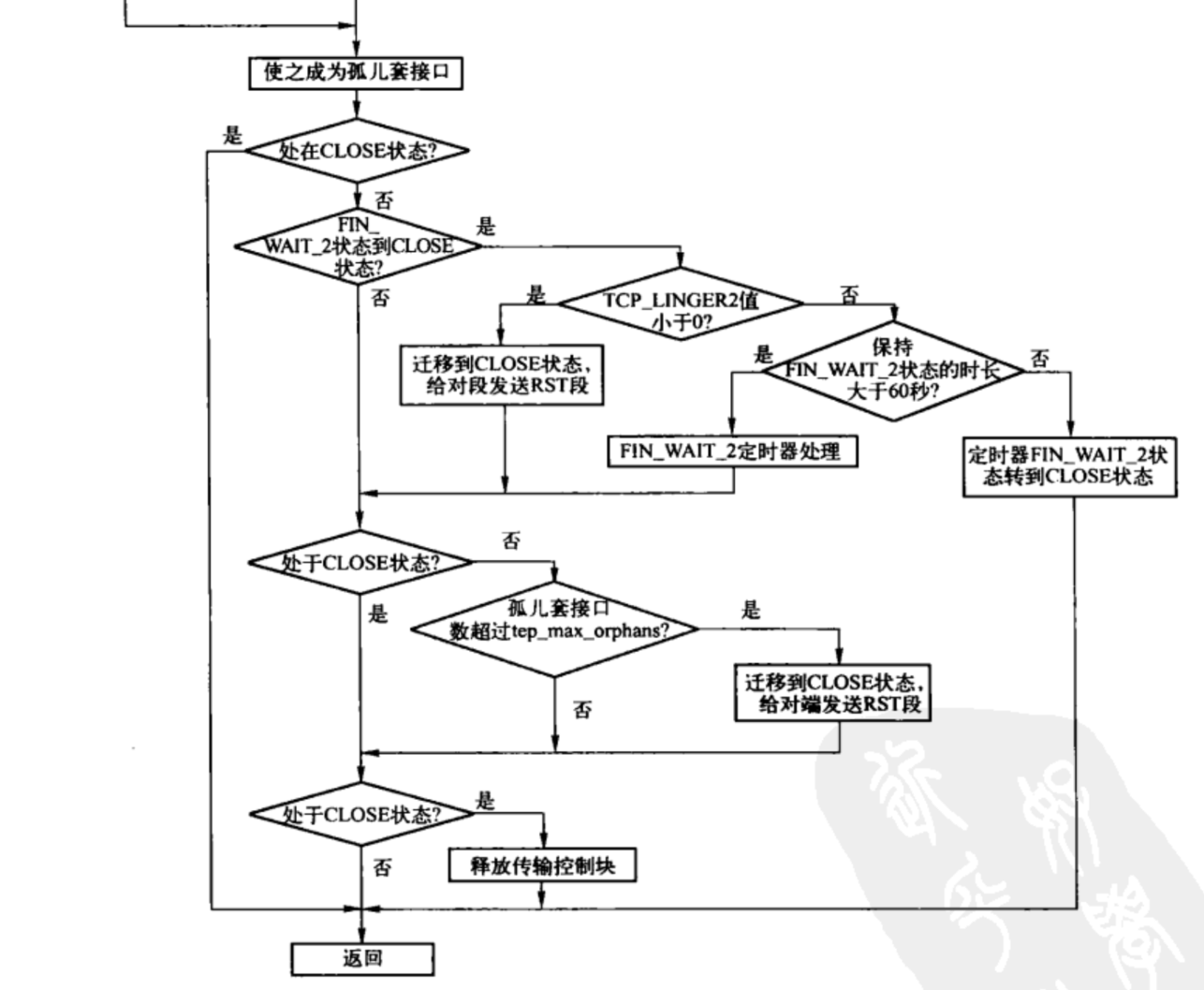
以下是Linux2.6.20的close的实现流程图,上述代码是Linux6.2.9的实现,虽然有点出入,但是大框架差不多。
-
-
-
综上可知:
-
(a)当套接字处于 TCP_LISTEN 状态,则关闭套接字,清理完成连接队列,设置 TCP_CLOSE 状态,并向每个 socket 发送 RST 报文
-
(b)非 TCP_LISTEN 状态,先判断发送队列中是否有数据未被用户进程读取完,若有,说明异常关闭,设置 TCP_CLOSE 状态,给对端发送 RST 报文,不走四次挥手过程。
-
(c)若设置套接字选项 SOCK_LINGER,且超时时间为0,则执行断开连接,删除定时器,清除接收和发送队列上的数据,设置 TCP_CLOSE 状态,发送 RST 报文,不走四次挥手过程。
-
(d)若数据都被用户进程读完,把发送队列中的数据发送完后,发送 FIN 报文,走四次挥手。
-
11.3 收包函数 tcp_v4_rcv
-
Linux内核中TCP的收包函数为
tcp_v4_rcv,这里就以这个函数为起点来进行讲解。 -
tcp_v4_rcv函数只要做以下几个工作:(1) 设置TCP_CB (2) 查找控制块 (3)根据控制块状态做不同处理,包括TCP_TIME_WAIT状态处理,TCP_NEW_SYN_RECV状态处理,TCP_LISTEN状态处理 (4) 接收TCP段;
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250int tcp_v4_rcv(struct sk_buff *skb) { struct net *net = dev_net(skb->dev); enum skb_drop_reason drop_reason; int sdif = inet_sdif(skb); int dif = inet_iif(skb); const struct iphdr *iph; const struct tcphdr *th; bool refcounted; struct sock *sk; int ret; drop_reason = SKB_DROP_REASON_NOT_SPECIFIED; if (skb->pkt_type != PACKET_HOST) goto discard_it; /* Count it even if it's bad */ __TCP_INC_STATS(net, TCP_MIB_INSEGS); if (!pskb_may_pull(skb, sizeof(struct tcphdr))) goto discard_it; th = (const struct tcphdr *)skb->data; if (unlikely(th->doff < sizeof(struct tcphdr) / 4)) { drop_reason = SKB_DROP_REASON_PKT_TOO_SMALL; goto bad_packet; } if (!pskb_may_pull(skb, th->doff * 4)) goto discard_it; /* An explanation is required here, I think. * Packet length and doff are validated by header prediction, * provided case of th->doff==0 is eliminated. * So, we defer the checks. */ if (skb_checksum_init(skb, IPPROTO_TCP, inet_compute_pseudo)) goto csum_error; th = (const struct tcphdr *)skb->data; iph = ip_hdr(skb); lookup: sk = __inet_lookup_skb(net->ipv4.tcp_death_row.hashinfo, skb, __tcp_hdrlen(th), th->source, th->dest, sdif, &refcounted); if (!sk) goto no_tcp_socket; process: // 首先判断 TIME_WAIT 状态 if (sk->sk_state == TCP_TIME_WAIT) goto do_time_wait; if (sk->sk_state == TCP_NEW_SYN_RECV) { struct request_sock *req = inet_reqsk(sk); bool req_stolen = false; struct sock *nsk; sk = req->rsk_listener; if (!xfrm4_policy_check(sk, XFRM_POLICY_IN, skb)) drop_reason = SKB_DROP_REASON_XFRM_POLICY; else drop_reason = tcp_inbound_md5_hash(sk, skb, &iph->saddr, &iph->daddr, AF_INET, dif, sdif); if (unlikely(drop_reason)) { sk_drops_add(sk, skb); reqsk_put(req); goto discard_it; } if (tcp_checksum_complete(skb)) { reqsk_put(req); goto csum_error; } if (unlikely(sk->sk_state != TCP_LISTEN)) { nsk = reuseport_migrate_sock(sk, req_to_sk(req), skb); if (!nsk) { inet_csk_reqsk_queue_drop_and_put(sk, req); goto lookup; } sk = nsk; /* reuseport_migrate_sock() has already held one sk_refcnt * before returning. */ } else { /* We own a reference on the listener, increase it again * as we might lose it too soon. */ sock_hold(sk); } refcounted = true; nsk = NULL; if (!tcp_filter(sk, skb)) { th = (const struct tcphdr *)skb->data; iph = ip_hdr(skb); tcp_v4_fill_cb(skb, iph, th); nsk = tcp_check_req(sk, skb, req, false, &req_stolen); } else { drop_reason = SKB_DROP_REASON_SOCKET_FILTER; } if (!nsk) { reqsk_put(req); if (req_stolen) { /* Another cpu got exclusive access to req * and created a full blown socket. * Try to feed this packet to this socket * instead of discarding it. */ tcp_v4_restore_cb(skb); sock_put(sk); goto lookup; } goto discard_and_relse; } nf_reset_ct(skb); if (nsk == sk) { reqsk_put(req); tcp_v4_restore_cb(skb); } else if (tcp_child_process(sk, nsk, skb)) { tcp_v4_send_reset(nsk, skb); goto discard_and_relse; } else { sock_put(sk); return 0; } } if (static_branch_unlikely(&ip4_min_ttl)) { /* min_ttl can be changed concurrently from do_ip_setsockopt() */ if (unlikely(iph->ttl < READ_ONCE(inet_sk(sk)->min_ttl))) { __NET_INC_STATS(net, LINUX_MIB_TCPMINTTLDROP); drop_reason = SKB_DROP_REASON_TCP_MINTTL; goto discard_and_relse; } } if (!xfrm4_policy_check(sk, XFRM_POLICY_IN, skb)) { drop_reason = SKB_DROP_REASON_XFRM_POLICY; goto discard_and_relse; } drop_reason = tcp_inbound_md5_hash(sk, skb, &iph->saddr, &iph->daddr, AF_INET, dif, sdif); if (drop_reason) goto discard_and_relse; nf_reset_ct(skb); if (tcp_filter(sk, skb)) { drop_reason = SKB_DROP_REASON_SOCKET_FILTER; goto discard_and_relse; } th = (const struct tcphdr *)skb->data; iph = ip_hdr(skb); tcp_v4_fill_cb(skb, iph, th); skb->dev = NULL; // 开始调用tcp_v4_do_rcv if (sk->sk_state == TCP_LISTEN) { ret = tcp_v4_do_rcv(sk, skb); goto put_and_return; } sk_incoming_cpu_update(sk); bh_lock_sock_nested(sk); tcp_segs_in(tcp_sk(sk), skb); ret = 0; if (!sock_owned_by_user(sk)) { ret = tcp_v4_do_rcv(sk, skb); } else { if (tcp_add_backlog(sk, skb, &drop_reason)) goto discard_and_relse; } bh_unlock_sock(sk); put_and_return: if (refcounted) sock_put(sk); return ret; no_tcp_socket: drop_reason = SKB_DROP_REASON_NO_SOCKET; if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) goto discard_it; tcp_v4_fill_cb(skb, iph, th); if (tcp_checksum_complete(skb)) { csum_error: drop_reason = SKB_DROP_REASON_TCP_CSUM; trace_tcp_bad_csum(skb); __TCP_INC_STATS(net, TCP_MIB_CSUMERRORS); bad_packet: __TCP_INC_STATS(net, TCP_MIB_INERRS); } else { tcp_v4_send_reset(NULL, skb); } discard_it: SKB_DR_OR(drop_reason, NOT_SPECIFIED); /* Discard frame. */ kfree_skb_reason(skb, drop_reason); return 0; discard_and_relse: sk_drops_add(sk, skb); if (refcounted) sock_put(sk); goto discard_it; do_time_wait: if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) { drop_reason = SKB_DROP_REASON_XFRM_POLICY; inet_twsk_put(inet_twsk(sk)); goto discard_it; } tcp_v4_fill_cb(skb, iph, th); if (tcp_checksum_complete(skb)) { inet_twsk_put(inet_twsk(sk)); goto csum_error; } switch (tcp_timewait_state_process(inet_twsk(sk), skb, th)) { case TCP_TW_SYN: { struct sock *sk2 = inet_lookup_listener( net, net->ipv4.tcp_death_row.hashinfo, skb, __tcp_hdrlen(th), iph->saddr, th->source, iph->daddr, th->dest, inet_iif(skb), sdif); if (sk2) { inet_twsk_deschedule_put(inet_twsk(sk)); sk = sk2; tcp_v4_restore_cb(skb); refcounted = false; goto process; } } /* to ACK */ fallthrough; case TCP_TW_ACK: tcp_v4_timewait_ack(sk, skb); break; case TCP_TW_RST: tcp_v4_send_reset(sk, skb); inet_twsk_deschedule_put(inet_twsk(sk)); goto discard_it; case TCP_TW_SUCCESS:; } goto discard_it; } -
(1) 在找到对应的套接口后,内核会首先判断其是否是TIME_WAIT套接口,因为这种套接口不能处理报文,因此要放到最前面来处理。从上面可以看出,对于TIME_WAIT真正的处理函数为
tcp_timewait_state_process,根据该函数的返回值会做出不同的行为。这个函数主要用来处理在TIME_WAIT状态下,收到各种类型的报文(SYN、ACK、新数据等)需要做出的响应行为。其处理过程为tcp_v4_rcv -> tcp_timewait_state_process。
- 这里有个点需要说明一下,对于FIN_WAIT_2状态,其实并不在tcp_timewait_state_process函数中进行处理;但是对于状态为TIME_WAIT子状态为FIN_WAIT_2 的状态,确实在tcp_timewait_state_process函数中处理。
-
(2) 对于非TIME_WAIT且非ESTABLISHED状态下的套接口,其处理过程会通过
tcp_v4_rcv -> tcp_v4_do_rcv -> tcp_rcv_state_process来进入到 tcp_rcv_state_process 函数中,来做出相应的行为。-
tcp_v4_rcv判断状态为LISTEN时会直接调用tcp_v4_do_rcv;
-
如果是其他状态,将TCP包投递到目的套接字进行接收处理。如果套接字未被上锁则调用tcp_v4_do_rcv。当套接字正被用户锁定,TCP包将暂时排入该套接字的后备队列(sk_add_backlog)。
-
这里需要着重说明,对于 FIN_WAIT_2 状态,并不在
tcp_timewait_state_process函数进行处理,而是在接收到FIN报文后的tcp_fin函数中处理,处理完成后即变成真正的TIME_WAIT状态;如果没有收到FIN报文,FIN_WAIT_2 也会在定时器超时后自动转为子状态为FIN_WAIT_2的TIME_WAIT状态以减少资源开销。-
tcp_v4_rcv |-tcp_v4_do_rcv |-tcp_rcv_state_process |-tcp_data_queue |-tcp_fin
-
-
-
(3) 对于如果状态是ESTABLISHED,其处理过程会通过
tcp_v4_rcv -> tcp_v4_do_rcv -> tcp_rcv_established来进入到 tcp_rcv_established函数中,来做出相应的行为。
11.4 主动关闭源码分析
-
-
(1)第一次挥手 tcp_send_fin,发送FIN报文
-
当一段完成数据发送任务之后,应用层即可调用 close系统调用 发送一个 FIN 报文来终止该方向上的连接,当另一端收到这个 FIN 后,必须通知应用层,另一端已经终止了数据传送。而 close 系统调用在传输层接收的实现就是 tcp_close,最终落到第一次挥手的就是 tcp_send_fin 函数。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56/* Location: net/ipv4/tcp_output.c Function: Send a FIN. The caller locks the socket for us. We should try to send a FIN packet really hard, but eventually give up. Parameter: sk: 传输控制块 */ void tcp_send_fin(struct sock *sk) { /* 取得 sock 发送队列的最后一个元素,如果为空,返回 null*/ struct sk_buff *skb, *tskb = tcp_write_queue_tail(sk); struct tcp_sock *tp = tcp_sk(sk); /* 这里做了一些优化, 如果发送队列的末尾还有段没有发出去,则利用该段发送 * FIN。 */ if (tskb && (tcp_send_head(sk) || tcp_under_memory_pressure(sk))) { /* 如果当前正在发送的队列不为空,或者当前 TCP 处于内存压力下 * (值得进一步分析),则进行该优化 */ coalesce: TCP_SKB_CB(tskb)->tcp_flags |= TCPHDR_FIN; // 递增序列号 TCP_SKB_CB(tskb)->end_seq++; tp->write_seq++; /* 队头为空 */ if (!tcp_send_head(sk)) { /* This means tskb was already sent. * Pretend we included the FIN on previous transmit. * We need to set tp->snd_nxt to the value it would have * if FIN had been sent. This is because retransmit path * does not change tp->snd_nxt. */ tp->snd_nxt++; return; } } else { /* 为封包分配空间 */ skb = alloc_skb_fclone(MAX_TCP_HEADER, sk->sk_allocation); if (unlikely(!skb)) { /* 如果分配不到空间,且队尾还有未发送的包,利用该包发出 FIN。 */ if (tskb) goto coalesce; return; } skb_reserve(skb, MAX_TCP_HEADER); sk_forced_mem_schedule(sk, skb->truesize); /* FIN eats a sequence byte, write_seq advanced by tcp_queue_skb(). */ /* 构造一个 FIN 包,并加入发送队列。 */ tcp_init_nondata_skb(skb, tp->write_seq, TCPHDR_ACK | TCPHDR_FIN); tcp_queue_skb(sk, skb); } __tcp_push_pending_frames(sk, tcp_current_mss(sk), TCP_NAGLE_OFF); } -
tcp_send_fin() 的实现比较简单,过程大致如下:
- 由于发送FN无需占用额外的负载, 因此如果发送队列不空, 则在发送队列的最后一个TCP段上设置FN标志。但FIN标志会占用一个序号, 因此需递增序号。
- 如果发送队列为空, 则需构造一个新的TCP段, 但该TCP段不需要负荷, 只需要TCP首部即可。设置相应的值, 然后添加到发送队列中。
- 最后关闭Nagle算法, 立即将发送队列上未发送的段(包括FN段)全部发送出去。
-
在函数的最后,将所有的剩余数据一口气发出去,完成发送 FIN 包的过程。至此,主动关闭过程的第一次握手完成。此时处于FIN_WAIT1状态。
-
(2)第二次挥手,接收ACK报文
-
tcp_send_fin()函数调用后,会调用sk_stream_wait_close阻塞等待接收ACK。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33#define sk_wait_event(__sk, __timeo, __condition) \ ({ \ int rc; \ release_sock(__sk); \ rc = __condition; \ if (!rc) { \ *(__timeo) = schedule_timeout(*(__timeo)); \ } \ lock_sock(__sk); \ rc = __condition; \ rc; \ }) void sk_stream_wait_close(struct sock *sk, long timeout) { if (timeout) { DEFINE_WAIT(wait); do { prepare_to_wait(sk->sk_sleep, &wait, TASK_INTERRUPTIBLE); /*sk_stream_closing(sk),该函数判断的是套接口当前状态, 如果处于TCPF_FIN_WAIT1 或 TCPF_CLOSING 或 TCPF_LAST_ACK 则返回 1*/ if (sk_wait_event(sk, &timeout, !sk_stream_closing(sk))) break; } while (!signal_pending(current) && timeout); finish_wait(sk->sk_sleep, &wait); } } static inline int sk_stream_closing(struct sock *sk) { return (1 << sk->sk_state) & (TCPF_FIN_WAIT1 | TCPF_CLOSING | TCPF_LAST_ACK); } -
在阻塞期间,若接收到报文,则处理报文,该报文在首先存放在 back_log 队列中。之所以在 back_log 队列中,是因为网络层模块在将一个数据包传递给传输层模块处理时(tcp_v4_rcv),如果当前对应的套接字正忙,则将数据包插入到 sock 结构 back_log 队列中。但插入该队列中的数据包并不能算是被接收,该队列中的数据包需要进行一系列处理后插入receive_queue 接收队列中时,才算是完成接收。而 **release_sock 函数 **就是从 back_log 中取数据包重新调用 tcp_v4_rcv 函数 对数据包进行接收。所谓 back_log 队列只是数据包暂居之所,不可久留,所以也就必须对这个队列中数据包尽快进行处理,那么也就表示必须对 release_sock 函数进行频繁调用。
-
调用过程如下图
-
1 2 3 4 5 6 7 8sk_stream_wait_close -> sk_wait_event -> release_sock(__sk) -> __release_sock(sk); -> sk->sk_backlog_rcv(sk, skb); -> tcp_v4_rcv -> tcp_v4_do_rcv -> tcp_rcv_state_process -
最终会调用 tcp_rcv_state_process 函数来处理接收信息。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) { struct tcp_sock *tp = tcp_sk(sk); struct inet_connection_sock *icsk = inet_csk(sk); const struct tcphdr *th = tcp_hdr(skb); struct request_sock *req; int queued = 0; bool acceptable; SKB_DR(reason); switch (sk->sk_state) { case TCP_CLOSE: SKB_DR_SET(reason, TCP_CLOSE); goto discard; case TCP_LISTEN: if (th->ack) return 1; if (th->rst) { SKB_DR_SET(reason, TCP_RESET); goto discard; } if (th->syn) { if (th->fin) { SKB_DR_SET(reason, TCP_FLAGS); goto discard; } /* It is possible that we process SYN packets from backlog, * so we need to make sure to disable BH and RCU right there. */ rcu_read_lock(); local_bh_disable(); acceptable = icsk->icsk_af_ops->conn_request(sk, skb) >= 0; local_bh_enable(); rcu_read_unlock(); if (!acceptable) return 1; consume_skb(skb); return 0; } SKB_DR_SET(reason, TCP_FLAGS); goto discard; case TCP_SYN_SENT: tp->rx_opt.saw_tstamp = 0; tcp_mstamp_refresh(tp); queued = tcp_rcv_synsent_state_process(sk, skb, th); if (queued >= 0) return queued; /* Do step6 onward by hand. */ tcp_urg(sk, skb, th); __kfree_skb(skb); tcp_data_snd_check(sk); return 0; } tcp_mstamp_refresh(tp); tp->rx_opt.saw_tstamp = 0; req = rcu_dereference_protected(tp->fastopen_rsk, lockdep_sock_is_held(sk)); if (req) { bool req_stolen; WARN_ON_ONCE(sk->sk_state != TCP_SYN_RECV && sk->sk_state != TCP_FIN_WAIT1); if (!tcp_check_req(sk, skb, req, true, &req_stolen)) { SKB_DR_SET(reason, TCP_FASTOPEN); goto discard; } } if (!th->ack && !th->rst && !th->syn) { SKB_DR_SET(reason, TCP_FLAGS); goto discard; } if (!tcp_validate_incoming(sk, skb, th, 0)) return 0; /* step 5: check the ACK field ,判断能否接收*/ acceptable = tcp_ack(sk, skb, FLAG_SLOWPATH | FLAG_UPDATE_TS_RECENT | FLAG_NO_CHALLENGE_ACK) > 0; if (!acceptable) { if (sk->sk_state == TCP_SYN_RECV) return 1; /* send one RST */ tcp_send_challenge_ack(sk); SKB_DR_SET(reason, TCP_OLD_ACK); goto discard; } switch (sk->sk_state) { case TCP_SYN_RECV: tp->delivered++; /* SYN-ACK delivery isn't tracked in tcp_ack */ if (!tp->srtt_us) tcp_synack_rtt_meas(sk, req); if (req) { tcp_rcv_synrecv_state_fastopen(sk); } else { tcp_try_undo_spurious_syn(sk); tp->retrans_stamp = 0; tcp_init_transfer(sk, BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB, skb); WRITE_ONCE(tp->copied_seq, tp->rcv_nxt); } smp_mb(); tcp_set_state(sk, TCP_ESTABLISHED); sk->sk_state_change(sk); /* Note, that this wakeup is only for marginal crossed SYN case. * Passively open sockets are not waked up, because * sk->sk_sleep == NULL and sk->sk_socket == NULL. */ if (sk->sk_socket) sk_wake_async(sk, SOCK_WAKE_IO, POLL_OUT); tp->snd_una = TCP_SKB_CB(skb)->ack_seq; tp->snd_wnd = ntohs(th->window) << tp->rx_opt.snd_wscale; tcp_init_wl(tp, TCP_SKB_CB(skb)->seq); if (tp->rx_opt.tstamp_ok) tp->advmss -= TCPOLEN_TSTAMP_ALIGNED; if (!inet_csk(sk)->icsk_ca_ops->cong_control) tcp_update_pacing_rate(sk); /* Prevent spurious tcp_cwnd_restart() on first data packet */ tp->lsndtime = tcp_jiffies32; tcp_initialize_rcv_mss(sk); tcp_fast_path_on(tp); break; // 这里表示对第二次挥手接收ACK的处理 case TCP_FIN_WAIT1: { int tmo; if (req) tcp_rcv_synrecv_state_fastopen(sk); // 这处判断是确认此ack是发送Fin包对应的那个ack if (tp->snd_una != tp->write_seq) break; /* 收到 ACK 后,转移到 TCP_FIN_WAIT2 状态,将发送端关闭。 */ tcp_set_state(sk, TCP_FIN_WAIT2); WRITE_ONCE(sk->sk_shutdown, sk->sk_shutdown | SEND_SHUTDOWN); sk_dst_confirm(sk); if (!sock_flag(sk, SOCK_DEAD)) { /* Wake up lingering close() */ sk->sk_state_change(sk); break; } // 如果无需在该状态等待(linger2<0),或者收到了乱序数据段,则直接关闭连接 if (tp->linger2 < 0) { tcp_done(sk); NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA); return 1; } if (TCP_SKB_CB(skb)->end_seq != TCP_SKB_CB(skb)->seq && after(TCP_SKB_CB(skb)->end_seq - th->fin, tp->rcv_nxt)) { /* Receive out of order FIN after close() */ if (tp->syn_fastopen && th->fin) tcp_fastopen_active_disable(sk); tcp_done(sk); NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA); return 1; } // 计算超时时间,判断是否进入主动 TIME_WAIT 状态。 tmo = tcp_fin_time(sk); // 如果需要等待,则需要判断等待时间与TIMEWAIT时间的大小关系,若>TIMEWAIT_LEN,则添加TIME_WAIT_2定时器 if (tmo > TCP_TIMEWAIT_LEN) { inet_csk_reset_keepalive_timer(sk, tmo - TCP_TIMEWAIT_LEN); } /* 有fin 或者 被用户进程锁定,加入FIN_WAIT_2定时器 */ else if (th->fin || sock_owned_by_user(sk)) { /* Bad case. We could lose such FIN otherwise. * It is not a big problem, but it looks confusing * and not so rare event. We still can lose it now, * if it spins in bh_lock_sock(), but it is really * marginal case. */ inet_csk_reset_keepalive_timer(sk, tmo); } else { // 否则直接进入TIME_WAIT接管(其子状态仍然是FIN_WAIT_2),接管之后会添加TIME_WAIT定时器 tcp_time_wait(sk, TCP_FIN_WAIT2, tmo); goto consume; } break; } case TCP_CLOSING: if (tp->snd_una == tp->write_seq) { tcp_time_wait(sk, TCP_TIME_WAIT, 0); goto consume; } break; case TCP_LAST_ACK: if (tp->snd_una == tp->write_seq) { tcp_update_metrics(sk); tcp_done(sk); goto consume; } break; } /* step 6: check the URG bit */ tcp_urg(sk, skb, th); /* step 7: process the segment text */ switch (sk->sk_state) { case TCP_CLOSE_WAIT: case TCP_CLOSING: case TCP_LAST_ACK: if (!before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt)) { /* If a subflow has been reset, the packet should not * continue to be processed, drop the packet. */ if (sk_is_mptcp(sk) && !mptcp_incoming_options(sk, skb)) goto discard; break; } fallthrough; case TCP_FIN_WAIT1: // 第三次挥手,接收FIN,处理FIN_WAIT2状态,最终会进入tcp_data_queue函数 case TCP_FIN_WAIT2: /* RFC 793 says to queue data in these states, * RFC 1122 says we MUST send a reset. * BSD 4.4 also does reset. */ if (sk->sk_shutdown & RCV_SHUTDOWN) { if (TCP_SKB_CB(skb)->end_seq != TCP_SKB_CB(skb)->seq && after(TCP_SKB_CB(skb)->end_seq - th->fin, tp->rcv_nxt)) { NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA); tcp_reset(sk, skb); return 1; } } fallthrough; case TCP_ESTABLISHED: // 处理FIN_WAIT2状态,进一步进入 tcp_fin 函数 tcp_data_queue(sk, skb); queued = 1; break; } /* tcp_data could move socket to TIME-WAIT */ if (sk->sk_state != TCP_CLOSE) { tcp_data_snd_check(sk); tcp_ack_snd_check(sk); } if (!queued) { discard: tcp_drop_reason(sk, skb, reason); } return 0; consume: __kfree_skb(skb); return 0; } -
之前已经说过,sock结构进入TIME_WAIT状态有两种情况: (a)一种是在真正进入了TIME_WAIT状态,即在规定时间内主动关闭端收到了第二个fin进入time_wait状态; (b)还有一种是FIN_WAIT_2的TIME_WAIT状态。
- 之所以让FIN_WAIT_2状态在没有接收到FIN包的情况下也可以进入TIME_WAIT状态,是因为tcp_sock结构占用的资源要比tcp_timewait_sock结构占用的资源多,而且在TIME_WAIT下也可以处理连接的关闭。内核在处理时通过inet_timewait_sock结构的tw_substate成员(子状态)来区分这种两种情况。
-
因此需要注意的是,调用tcp_time_wait函数后,直接进入TIME_WAIT接管(其子状态tw_substate仍然是FIN_WAIT_2),接管之后会添加TIME_WAIT定时器;同时,出于资源和方面的考虑,Linux内核采用了一个较小的结构体 tcp_timewait_sock 来取代正常的TCP传输控制块,因为TIME_WAIT也可作FIN_WAIT_2状态的处理。
-
转换到TCP_FIN_WAIT2状态以后,计算接受第三次挥手 fin 包的超时时间tmo:
- 若大于TIMEWAIT_LEN,则添加TIME_WAIT_2定时器;
- 否则通过tcp_time_wait函数,直接进入TIME_WAIT接管(其子状态tw_substate仍然是FIN_WAIT_2),接管之后会添加TIME_WAIT定时器。
-
有这样一步的原因是防止对端由于种种原因始终没有发送 fin,防止一直处于 FIN_WAIT2 状态。
-
因此,FIN_WAIT_2状态的最终走向有以下4个流程触发点:①TIME_WAIT_2定时器未超时时间内,收到数据段触发;②TIME_WAIT_2定时器超时触发; ③TIME_WAIT定时器未超时时间内,收到数据段触发;④TIME_WAIT定时器超时触发;
-
(3)第三次挥手,接收 FIN 报文
-
此时TCP状态为FIN_WAIT2状态,从上面可以知道,其有4个走向,下面依次阐述:
-
①TIME_WAIT_2定时器未超时时间内,收到数据段触发,如果设置FIN标记,则直接进入TIME_WAIT状态。
-
这是最理想的第三次挥手状况,跟踪源码,可看到其接收FIN报文的调用过程,如下所示。
-
1 2 3 4 5tcp_v4_rcv |-tcp_v4_do_rcv |-tcp_rcv_state_process |-tcp_data_queue |-tcp_fin -
在函数tcp_rcv_state_process处理数据段的过程中,FIN_WAIT_2状态最终会调用tcp_data_queue来处理数据段;
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) { //... /* step 7: process the segment text */ switch (sk->sk_state) { case TCP_CLOSE_WAIT: case TCP_CLOSING: case TCP_LAST_ACK: if (!before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt)) break; case TCP_FIN_WAIT1: case TCP_FIN_WAIT2: /* RFC 793 says to queue data in these states, * RFC 1122 says we MUST send a reset. * BSD 4.4 also does reset. */ if (sk->sk_shutdown & RCV_SHUTDOWN) { if (TCP_SKB_CB(skb)->end_seq != TCP_SKB_CB(skb)->seq && after(TCP_SKB_CB(skb)->end_seq - th->fin, tp->rcv_nxt)) { NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA); tcp_reset(sk); return 1; } } /* Fall through */ case TCP_ESTABLISHED: tcp_data_queue(sk, skb); queued = 1; break; } //... } -
tcp_data_queue在处理数据段的时候,有对FIN标记的检查,如果有该标记,且数据报无乱序,则进入tcp_fin函数;
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116static void tcp_data_queue(struct sock *sk, struct sk_buff *skb) { struct tcp_sock *tp = tcp_sk(sk); enum skb_drop_reason reason; bool fragstolen; int eaten; /* If a subflow has been reset, the packet should not continue * to be processed, drop the packet. */ if (sk_is_mptcp(sk) && !mptcp_incoming_options(sk, skb)) { __kfree_skb(skb); return; } if (TCP_SKB_CB(skb)->seq == TCP_SKB_CB(skb)->end_seq) { __kfree_skb(skb); return; } skb_dst_drop(skb); __skb_pull(skb, tcp_hdr(skb)->doff * 4); reason = SKB_DROP_REASON_NOT_SPECIFIED; tp->rx_opt.dsack = 0; /* Queue data for delivery to the user. * Packets in sequence go to the receive queue. * Out of sequence packets to the out_of_order_queue. */ if (TCP_SKB_CB(skb)->seq == tp->rcv_nxt) { if (tcp_receive_window(tp) == 0) { reason = SKB_DROP_REASON_TCP_ZEROWINDOW; NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPZEROWINDOWDROP); goto out_of_window; } /* Ok. In sequence. In window. */ queue_and_out: if (skb_queue_len(&sk->sk_receive_queue) == 0) sk_forced_mem_schedule(sk, skb->truesize); else if (tcp_try_rmem_schedule(sk, skb, skb->truesize)) { reason = SKB_DROP_REASON_PROTO_MEM; NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPRCVQDROP); sk->sk_data_ready(sk); goto drop; } eaten = tcp_queue_rcv(sk, skb, &fragstolen); if (skb->len) tcp_event_data_recv(sk, skb); /* ********处理无乱序的FIN报文 */ if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN) tcp_fin(sk); if (!RB_EMPTY_ROOT(&tp->out_of_order_queue)) { tcp_ofo_queue(sk); /* RFC5681. 4.2. SHOULD send immediate ACK, when * gap in queue is filled. */ if (RB_EMPTY_ROOT(&tp->out_of_order_queue)) inet_csk(sk)->icsk_ack.pending |= ICSK_ACK_NOW; } if (tp->rx_opt.num_sacks) tcp_sack_remove(tp); tcp_fast_path_check(sk); if (eaten > 0) kfree_skb_partial(skb, fragstolen); if (!sock_flag(sk, SOCK_DEAD)) tcp_data_ready(sk); return; } if (!after(TCP_SKB_CB(skb)->end_seq, tp->rcv_nxt)) { tcp_rcv_spurious_retrans(sk, skb); /* A retransmit, 2nd most common case. Force an immediate ack. */ reason = SKB_DROP_REASON_TCP_OLD_DATA; NET_INC_STATS(sock_net(sk), LINUX_MIB_DELAYEDACKLOST); tcp_dsack_set(sk, TCP_SKB_CB(skb)->seq, TCP_SKB_CB(skb)->end_seq); out_of_window: tcp_enter_quickack_mode(sk, TCP_MAX_QUICKACKS); inet_csk_schedule_ack(sk); drop: tcp_drop_reason(sk, skb, reason); return; } /* Out of window. F.e. zero window probe. */ if (!before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt + tcp_receive_window(tp))) { reason = SKB_DROP_REASON_TCP_OVERWINDOW; goto out_of_window; } if (before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt)) { /* Partial packet, seq < rcv_next < end_seq */ tcp_dsack_set(sk, TCP_SKB_CB(skb)->seq, tp->rcv_nxt); /* If window is closed, drop tail of packet. But after * remembering D-SACK for its head made in previous line. */ if (!tcp_receive_window(tp)) { reason = SKB_DROP_REASON_TCP_ZEROWINDOW; NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPZEROWINDOWDROP); goto out_of_window; } goto queue_and_out; } tcp_data_queue_ofo(sk, skb); } -
在 tcp_fin 函数中,如果此时连接状态为FIN_WAIT_2,则发送ACK(已经完成第四次挥手),并且直接进入TIME_WAIT状态,子状态设置为TCP_TIME_WAIT;在tcp_time_wait函数处理中,会删除当前控制块,所以FIN_WAIT_2定时器也就不存在了;
-
1 2 3 4 5 6 7 8 9 10 11void tcp_fin(struct sock *sk) { /* ... */ switch (sk->sk_state) { case TCP_FIN_WAIT2: /* Received a FIN -- send ACK and enter TIME_WAIT. */ tcp_send_ack(sk); tcp_time_wait(sk, TCP_TIME_WAIT, 0); break; } /* ... */ } -
② TIME_WAIT_2定时器超时触发,调用定时器触发函数 tcp_keepalive_timer。
- 如果linger2<0,或者等待时间<=TIMEWAIT_LEN,直接发送reset关闭连接;
- 如果linger2>=0,且等待时间>TIMEWAIT_LEN,则调用tcp_time_wait函数进入TIME_WAIT接管,并设置子状态;
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23static void tcp_keepalive_timer(unsigned long data) { /*...*/ /* 处于fin_wait2且socket即将销毁,用作FIN_WAIT_2定时器 */ if (sk->sk_state == TCP_FIN_WAIT2 && sock_flag(sk, SOCK_DEAD)) { /* 停留在FIN_WAIT_2的停留时间>=0 */ if (tp->linger2 >= 0) { /* 获取时间差值 */ const int tmo = tcp_fin_time(sk) - TCP_TIMEWAIT_LEN; /* 差值>0,等待时间>TIME_WAIT时间,则进入TIME_WAIT状态 */ if (tmo > 0) { tcp_time_wait(sk, TCP_FIN_WAIT2, tmo); goto out; } } /* 发送rst */ tcp_send_active_reset(sk, GFP_ATOMIC); goto death; } /*...*/ } -
③TIME_WAIT定时器未超时时间内,收到数据段触发,若收到合法的FIN,则进入真正的TIME_WAIT状态(子状态修改);
-
tcp_v4_rcv 收入数据段过程中,会对TIME_WAIT状态做特别处理,其对于 TIME_WAIT 状态的处理函数为tcp_timewait_state_process;该函数最终会返回 TCP_TW_ACK,使得 tcp_v4_rcv 函数最后利用 tcp_v4_timewait_ack 函数发送第四次挥手的ACK报文。
-
调用过程如下图
-
1 2tcp_v4_rcv -> tcp_timewait_state_process -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53int tcp_v4_rcv(struct sk_buff *skb) { /*...*/ do_time_wait: if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) { inet_twsk_put(inet_twsk(sk)); goto discard_it; } /* 校验和错误 */ if (tcp_checksum_complete(skb)) { inet_twsk_put(inet_twsk(sk)); goto csum_error; } /* TIME_WAIT入包处理 */ switch (tcp_timewait_state_process(inet_twsk(sk), skb, th)) { /* 收到syn */ case TCP_TW_SYN: { /* 查找监听控制块 */ struct sock *sk2 = inet_lookup_listener( dev_net(skb->dev), &tcp_hashinfo, skb, __tcp_hdrlen(th), iph->saddr, th->source, iph->daddr, th->dest, inet_iif(skb)); /* 找到 */ if (sk2) { /* 删除tw控制块 */ inet_twsk_deschedule_put(inet_twsk(sk)); /* 记录监听控制块 */ sk = sk2; refcounted = false; /* 进行新请求的处理 */ goto process; } /* Fall through to ACK */ } /* 发送ack */ case TCP_TW_ACK: tcp_v4_timewait_ack(sk, skb); break; /* 发送rst */ case TCP_TW_RST: tcp_v4_send_reset(sk, skb); /* 删除tw控制块 */ inet_twsk_deschedule_put(inet_twsk(sk)); goto discard_it; /* 成功*/ case TCP_TW_SUCCESS:; } goto discard_it; } -
其中tcp_timewait_state_process函数如下所示,在其处理流程中,如果TIME_WAIT的子状态为FIN_WAIT_2,并且收到了合法的FIN之后,会进入真正的TIME_WAIT状态,即子状态也为TIME_WAIT,并且设置TIME_WAIT定时器;
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157enum tcp_tw_status tcp_timewait_state_process(struct inet_timewait_sock *tw, struct sk_buff *skb, const struct tcphdr *th) { struct tcp_options_received tmp_opt; struct tcp_timewait_sock *tcptw = tcp_twsk((struct sock *)tw); bool paws_reject = false; tmp_opt.saw_tstamp = 0; if (th->doff > (sizeof(*th) >> 2) && tcptw->tw_ts_recent_stamp) { tcp_parse_options(twsk_net(tw), skb, &tmp_opt, 0, NULL); if (tmp_opt.saw_tstamp) { if (tmp_opt.rcv_tsecr) tmp_opt.rcv_tsecr -= tcptw->tw_ts_offset; tmp_opt.ts_recent = tcptw->tw_ts_recent; tmp_opt.ts_recent_stamp = tcptw->tw_ts_recent_stamp; paws_reject = tcp_paws_reject(&tmp_opt, th->rst); } } /* 子状态是FIN_WAIT2 */ if (tw->tw_substate == TCP_FIN_WAIT2) { /* Just repeat all the checks of tcp_rcv_state_process() */ /* Out of window, send ACK */ if (paws_reject || !tcp_in_window(TCP_SKB_CB(skb)->seq, TCP_SKB_CB(skb)->end_seq, tcptw->tw_rcv_nxt, tcptw->tw_rcv_nxt + tcptw->tw_rcv_wnd)) return tcp_timewait_check_oow_rate_limit( tw, skb, LINUX_MIB_TCPACKSKIPPEDFINWAIT2); if (th->rst) goto kill; if (th->syn && !before(TCP_SKB_CB(skb)->seq, tcptw->tw_rcv_nxt)) return TCP_TW_RST; /* Dup ACK? */ if (!th->ack || !after(TCP_SKB_CB(skb)->end_seq, tcptw->tw_rcv_nxt) || TCP_SKB_CB(skb)->end_seq == TCP_SKB_CB(skb)->seq) { inet_twsk_put(tw); return TCP_TW_SUCCESS; } /* New data or FIN. If new data arrive after half-duplex close, * reset. 如果收到了新的数据或者序号有问题,则销毁控制块并返回 TCP_TW_RST。 */ if (!th->fin || TCP_SKB_CB(skb)->end_seq != tcptw->tw_rcv_nxt + 1) return TCP_TW_RST; /* FIN arrived, enter true time-wait state. */ /* 收到了 FIN 包,进入 TIME_WAIT 状态 */ tw->tw_substate = TCP_TIME_WAIT; tcptw->tw_rcv_nxt = TCP_SKB_CB(skb)->end_seq; if (tmp_opt.saw_tstamp) { tcptw->tw_ts_recent_stamp = ktime_get_seconds(); tcptw->tw_ts_recent = tmp_opt.rcv_tsval; } /*重新设置tw定时器 */ inet_twsk_reschedule(tw, TCP_TIMEWAIT_LEN); return TCP_TW_ACK; } /* * Now real TIME-WAIT state. * * RFC 1122: * "When a connection is [...] on TIME-WAIT state [...] * [a TCP] MAY accept a new SYN from the remote TCP to * reopen the connection directly, if it: * * (1) assigns its initial sequence number for the new * connection to be larger than the largest sequence * number it used on the previous connection incarnation, * and * * (2) returns to TIME-WAIT state if the SYN turns out * to be an old duplicate". */ if (!paws_reject && (TCP_SKB_CB(skb)->seq == tcptw->tw_rcv_nxt && (TCP_SKB_CB(skb)->seq == TCP_SKB_CB(skb)->end_seq || th->rst))) { /* In window segment, it may be only reset or bare ack. */ if (th->rst) { /* This is TIME_WAIT assassination, in two flavors. * Oh well... nobody has a sufficient solution to this * protocol bug yet. */ if (!READ_ONCE(twsk_net(tw)->ipv4.sysctl_tcp_rfc1337)) { kill: inet_twsk_deschedule_put(tw); return TCP_TW_SUCCESS; } } else { inet_twsk_reschedule(tw, TCP_TIMEWAIT_LEN); } if (tmp_opt.saw_tstamp) { tcptw->tw_ts_recent = tmp_opt.rcv_tsval; tcptw->tw_ts_recent_stamp = ktime_get_seconds(); } inet_twsk_put(tw); return TCP_TW_SUCCESS; } /* Out of window segment. All the segments are ACKed immediately. The only exception is new SYN. We accept it, if it is not old duplicate and we are not in danger to be killed by delayed old duplicates. RFC check is that it has newer sequence number works at rates <40Mbit/sec. However, if paws works, it is reliable AND even more, we even may relax silly seq space cutoff. RED-PEN: we violate main RFC requirement, if this SYN will appear old duplicate (i.e. we receive RST in reply to SYN-ACK), we must return socket to time-wait state. It is not good, but not fatal yet. */ if (th->syn && !th->rst && !th->ack && !paws_reject && (after(TCP_SKB_CB(skb)->seq, tcptw->tw_rcv_nxt) || (tmp_opt.saw_tstamp && (s32)(tcptw->tw_ts_recent - tmp_opt.rcv_tsval) < 0))) { u32 isn = tcptw->tw_snd_nxt + 65535 + 2; if (isn == 0) isn++; TCP_SKB_CB(skb)->tcp_tw_isn = isn; return TCP_TW_SYN; } if (paws_reject) __NET_INC_STATS(twsk_net(tw), LINUX_MIB_PAWSESTABREJECTED); if (!th->rst) { /* In this case we must reset the TIMEWAIT timer. * * If it is ACKless SYN it may be both old duplicate * and new good SYN with random sequence number <rcv_nxt. * Do not reschedule in the last case. */ if (paws_reject || th->ack) inet_twsk_reschedule(tw, TCP_TIMEWAIT_LEN); return tcp_timewait_check_oow_rate_limit( tw, skb, LINUX_MIB_TCPACKSKIPPEDTIMEWAIT); } inet_twsk_put(tw); return TCP_TW_SUCCESS; } -
④TIME_WAIT定时器超时触发,定时器超时,将tw控制块(tcp_timewait_sock )从ehash和bhash中删除,在收到数据段会发送reset;
-
定时器超时会进入到tw_timer_handler处理函数,该函数在统计信息之后,调用inet_twsk_kill;
-
这时候四次挥手已经结束了,因为TIME_WAIT也已经到时间了。
-
1 2 3 4 5 6 7 8 9static void tw_timer_handler(unsigned long data) { struct inet_timewait_sock *tw = (struct inet_timewait_sock *)data; if (tw->tw_kill) __NET_INC_STATS(twsk_net(tw), LINUX_MIB_TIMEWAITKILLED); else __NET_INC_STATS(twsk_net(tw), LINUX_MIB_TIMEWAITED); inet_twsk_kill(tw); } -
inet_twsk_kill从ehash和bhash中把tw控制块删除,并且释放其资源;
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20static void inet_twsk_kill(struct inet_timewait_sock *tw) { struct inet_hashinfo *hashinfo = tw->tw_dr->hashinfo; spinlock_t *lock = inet_ehash_lockp(hashinfo, tw->tw_hash); struct inet_bind_hashbucket *bhead; spin_lock(lock); sk_nulls_del_node_init_rcu((struct sock *)tw); spin_unlock(lock); /* Disassociate with bind bucket. */ bhead = &hashinfo->bhash[inet_bhashfn(twsk_net(tw), tw->tw_num, hashinfo->bhash_size)]; spin_lock(&bhead->lock); inet_twsk_bind_unhash(tw, hashinfo); spin_unlock(&bhead->lock); atomic_dec(&tw->tw_dr->tw_count); inet_twsk_put(tw); } -
(4)第四次挥手,发送ACK报文
-
在第三次挥手已经说明了,存在两种发送ACK报文的情况。
-
(a)在TIME_WAIT_2定时器未超时时间内,收到数据段触发,如果设置FIN标记,利用 tcp_fin 函数发送第四次挥手的ACK报文。
-
(b)在TIME_WAIT定时器未超时时间内,收到数据段触发,若收到合法的FIN,利用 tcp_timewait_state_process 函数进行处理,最后在 tcp_v4_rcv 函数中利用 tcp_v4_timewait_ack 函数发送第四次挥手的ACK报文。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47int tcp_v4_rcv(struct sk_buff *skb) { //... if (sk->sk_state == TCP_LISTEN) { ret = tcp_v4_do_rcv(sk, skb); goto put_and_return; } sk_incoming_cpu_update(sk); bh_lock_sock_nested(sk); tcp_segs_in(tcp_sk(sk), skb); ret = 0; if (!sock_owned_by_user(sk)) { ret = tcp_v4_do_rcv(sk, skb); } else { if (tcp_add_backlog(sk, skb, &drop_reason)) goto discard_and_relse; } //... switch (tcp_timewait_state_process(inet_twsk(sk), skb, th)) { case TCP_TW_SYN: { struct sock *sk2 = inet_lookup_listener( net, net->ipv4.tcp_death_row.hashinfo, skb, __tcp_hdrlen(th), iph->saddr, th->source, iph->daddr, th->dest, inet_iif(skb), sdif); if (sk2) { inet_twsk_deschedule_put(inet_twsk(sk)); sk = sk2; tcp_v4_restore_cb(skb); refcounted = false; goto process; } } /* to ACK */ fallthrough; // 回复 FIN 的代码 case TCP_TW_ACK: tcp_v4_timewait_ack(sk, skb); break; case TCP_TW_RST: tcp_v4_send_reset(sk, skb); inet_twsk_deschedule_put(inet_twsk(sk)); goto discard_it; case TCP_TW_SUCCESS:; } goto discard_it; } -
根据上面的分析,在正常情况下,tcp_timewait_state_process会返回 TCP_TW_ACK,因此,会进一步调用 tcp_v4_timewait_ack。该函数如下:
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15static void tcp_v4_timewait_ack(struct sock *sk, struct sk_buff *skb) { struct inet_timewait_sock *tw = inet_twsk(sk); struct tcp_timewait_sock *tcptw = tcp_twsk(sk); /* 发送 ACK 包 */ tcp_v4_send_ack(sk, skb, tcptw->tw_snd_nxt, tcptw->tw_rcv_nxt, tcptw->tw_rcv_wnd >> tw->tw_rcv_wscale, tcp_time_stamp_raw() + tcptw->tw_ts_offset, tcptw->tw_ts_recent, tw->tw_bound_dev_if, tcp_twsk_md5_key(tcptw), tw->tw_transparent ? IP_REPLY_ARG_NOSRCCHECK : 0, tw->tw_tos, tw->tw_txhash); /* 释放 tcp_timewait_sock 控制块 */ inet_twsk_put(tw); }
-
11.5 被动关闭源码分析
-
前置知识:
-
在Linux中,有两种方法来处理传入TCP数据段:快速路径(Fast Path)和慢速路径(Slow Path)。使用快速路径只进行最少的处理,如处理数据段、发生ACK、存储时间戳等。使用慢速路径可以处理乱序数据段、PAWS、socket内存管理和紧急数据等。Linux通过预测标志来区分这两种处理模式,预测标志存储在tp->pred_flags,生成这个标志的函数是__tcp_fast_path_on和tcp_fast_path_on,TCP会直接使用这两个函数来生成预测标记,也可以调用tcp_fast_path_check来完成这一任务。
-

-
tcp_rcv_state_process 实现了 TCP 状态机相对核心的一个部分。该函数可以处理除 ESTABLISHED 、 TIME_WAIT 状态以外的情况下的接收过程。
-
状态为ESTABLISHED时,用 tcp_rcv_established 函数接收处理。
-
状态为TIME_WAIT时,用 tcp_timewait_state_process 函数接收处理。
-
-
-
在正常的被动关闭开始时,TCP 控制块目前处于 ESTABLISHED 状态,此时接收到的 TCP 段都由 tcp_rcv_established 函数来处理,因此 FIN 段必定要做首部预测,当然预测一定不会通过快速路径,所以 FIN 报文段是走慢速路径处理的。
-
在慢速路径中,首先进行 TCP 选项的处理 (假设存在),然后根据段的序号检测该FIN 段是不是期望接收的段。如果是,则调用 tcp_fin函数进行处理。如果不是,则说明在 TCP 段传输过程中出现了失序,因此将该 FIN 段缓存到乱序队列中,等待它之前的所有 TCP 段都到, 才能做处理。
-
-
tcp_fin 函数的源码如下
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81/* * Process the FIN bit. This now behaves as it is supposed to work * and the FIN takes effect when it is validly part of sequence * space. Not before when we get holes. * * If we are ESTABLISHED, a received fin moves us to CLOSE-WAIT * (and thence onto LAST-ACK and finally, CLOSE, we never enter * TIME-WAIT) * * If we are in FINWAIT-1, a received FIN indicates simultaneous * close and we go into CLOSING (and later onto TIME-WAIT)--同时关闭 * * If we are in FINWAIT-2, a received FIN moves us to TIME-WAIT. */ void tcp_fin(struct sock *sk) { struct tcp_sock *tp = tcp_sk(sk); inet_csk_schedule_ack(sk); /* 设置了传输控制块的套接口状态为RCV_SHUTDOWN,表示服务器端不允许再接收数据。 */ WRITE_ONCE(sk->sk_shutdown, sk->sk_shutdown | RCV_SHUTDOWN); sock_set_flag(sk, SOCK_DONE); switch (sk->sk_state) { case TCP_SYN_RECV: case TCP_ESTABLISHED: /* Move to CLOSE_WAIT */ tcp_set_state(sk, TCP_CLOSE_WAIT); inet_csk_enter_pingpong_mode(sk); break; case TCP_CLOSE_WAIT: case TCP_CLOSING: /* Received a retransmission of the FIN, do * nothing. */ break; case TCP_LAST_ACK: /* RFC793: Remain in the LAST-ACK state. */ break; case TCP_FIN_WAIT1: /* This case occurs when a simultaneous close * happens, we must ack the received FIN and * enter the CLOSING state. */ tcp_send_ack(sk); tcp_set_state(sk, TCP_CLOSING); break; case TCP_FIN_WAIT2: /* Received a FIN -- send ACK and enter TIME_WAIT. */ tcp_send_ack(sk); tcp_time_wait(sk, TCP_TIME_WAIT, 0); break; default: /* Only TCP_LISTEN and TCP_CLOSE are left, in these * cases we should never reach this piece of code. */ pr_err("%s: Impossible, sk->sk_state=%d\n", __func__, sk->sk_state); break; } /* It _is_ possible, that we have something out-of-order _after_ FIN. * Probably, we should reset in this case. For now drop them. */ skb_rbtree_purge(&tp->out_of_order_queue); if (tcp_is_sack(tp)) tcp_sack_reset(&tp->rx_opt); if (!sock_flag(sk, SOCK_DEAD)) { sk->sk_state_change(sk); /* Do not send POLL_HUP for half duplex close. */ if (sk->sk_shutdown == SHUTDOWN_MASK || sk->sk_state == TCP_CLOSE) sk_wake_async(sk, SOCK_WAKE_WAITD, POLL_HUP); else sk_wake_async(sk, SOCK_WAKE_WAITD, POLL_IN); } } -
从源码可以看出,tcp_fin函数主要解决四个状态三个方向的转换问题
- (a)TCP_SYN_RECV和TCP_ESTABLISHED状态:转为CLOSE_WAIT状态;
- (b)TCP_FIN_WAIT1状态:转为TCP_CLOSING状态;注意是同时关闭会出现;
- (c)TCP_FIN_WAIT2状态:转为TIME_WAIT状态。
-
(1)收到FIN报文后回复ACK
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18static void tcp_fin(struct sk_buff *skb, struct sock *sk, struct tcphdr *th) { //...... // 这一句表明当前socket有ack需要发送 inet_csk_schedule_ack(sk); // ...... switch (sk->sk_state) { case TCP_SYN_RECV: case TCP_ESTABLISHED: /* Move to CLOSE_WAIT */ // 状态设置程close_wait状态 tcp_set_state(sk, TCP_CLOSE_WAIT); // 这一句表明,当前回复FIN报文的ACK报文可以延迟发送 // 即和后面的数据一起发送或者定时器到时后发送 inet_csk(sk)->icsk_ack.pingpong = 1; break; } // ...... } -
收到对端的 fin 之后并不会立即发送 ack 告知对端收到了,而是等有数据携带一块发送,或者等携带重传定时器到期后发送 ack。
-
因此,收到FIN报文,处于TCP_ESTABLISHED状态,即会转向CLOSE_WAIT状态,且设置了传输控制块的套接口状态为RCV_SHUTDOWN,表示服务器端不允许再接收数据;最后的ACK报文会延迟发送。
-
(2)发送FIN报文
-
这里需要收到调用close函数进行FIN报文的发送。
-
但需要解决的问题是,什么时候发送呢
- 本地不想发送数据了且对端明确发送了FIN报文
-
满足上述条件,我们可以利用如下代码实现
-
如果对端关闭了,应用端在 recv 的时候得到的返回值是 0, 此时就应该手动调用 close 去关闭连接。
-
为什么这样可以,可以查阅 recv 最后调用 tcp_rcvmsg的源码分析,这里说结论,参考
-
一旦当前 skb 读完了而且携带有 fin 标识,则不管有没有读到用户期望的字节数量都会返回已读到的字节数。下一次再读取的时候则在刚才描述的 tcp_rcvmsg 上半段直接不读取任何数据再跳转到 found_fin_ok 并返回 0。这样应用就能感知到对端已经关闭了。
-

-
1 2 3if(recv(sockfd, buf, MAXLINE,0) == 0){ close(sockfd) }
-
-
-
应用层在发现对端关闭之后本地已经是 close_wait 状态,这时候再调用 close 的话,会将状态改为 last_ack 状态,并发送本端的 fin, 源码如下所示。
-
执行过程和主动关闭的第一次挥手发送FIN很类似,最终都是调用tcp_close函数。
-
1 2 3 4 5 6 7 8 9void tcp_close(struct sock *sk, long timeout) { // ...... else if (tcp_close_state(sk)){ // tcp_close_state会将sk从close_wait状态变为last_ack // 发送fin包 tcp_send_fin(sk); } } -
(3)接收 ack 报文
-
在接收到主动关闭端的 ack 之后,在最终的tcp_rcv_state_process函数 调用 tcp_done (sk) 设置 sk 为 tcp_closed 状态,并回收 sk 的资源,如下代码所示:
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21tcp_v4_rcv |-tcp_v4_do_rcv |-tcp_rcv_state_process int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb, struct tcphdr *th, unsigned len) { ...... /* step 5: check the ACK field */ if (th->ack) { ... case TCP_LAST_ACK: // 这处判断是确认此ack是发送Fin包对应的那个ack if (tp->snd_una == tp->write_seq) { tcp_update_metrics(sk); // 设置socket为closed,并回收socket的资源 tcp_done(sk); goto discard; } ... } }
11.6 同时关闭源码分析
-
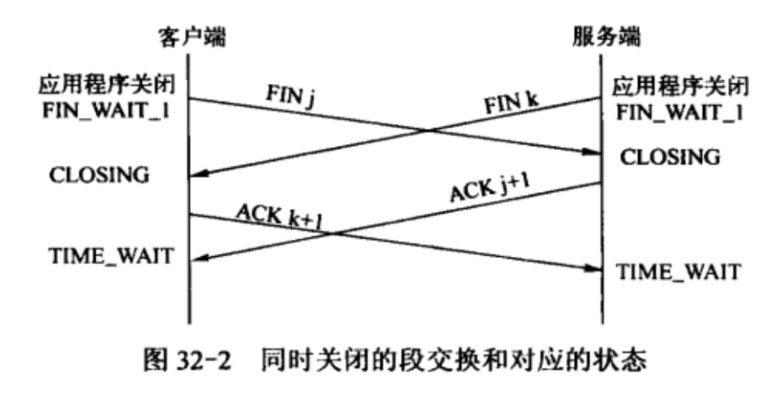
-
双方同时发出了 FIN 报文,准备关闭连接。
-
(1)调用close函数,最终调用tcp_send_fin,发送FIN报文,状态变为 FIN_WAIT_1;
-
(2)接收FIN报文,最终调用tcp_fin函数,状态转为CLOSING 状态;
-
1 2 3 4 5tcp_v4_rcv |-tcp_v4_do_rcv |-tcp_rcv_state_process |-tcp_data_queue |-tcp_fin -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23void tcp_fin(struct sock *sk) { struct tcp_sock *tp = tcp_sk(sk); inet_csk_schedule_ack(sk); /* 设置了传输控制块的套接口状态为RCV_SHUTDOWN,表示服务器端不允许再接收数据。 */ WRITE_ONCE(sk->sk_shutdown, sk->sk_shutdown | RCV_SHUTDOWN); sock_set_flag(sk, SOCK_DONE); switch (sk->sk_state) { //... case TCP_FIN_WAIT1: /* This case occurs when a simultaneous close * happens, we must ack the received FIN and * enter the CLOSING state. */ tcp_send_ack(sk); tcp_set_state(sk, TCP_CLOSING); break; //... } //... } -
(3)接收ACK报文。最终调用tcp_rcv_state_process函数,利用tcp_time_wait函数转为 TIME_WAIT 状态。
-
1 2 3tcp_v4_rcv |-tcp_v4_do_rcv |-tcp_rcv_state_process -
1 2 3 4 5 6 7 8 9 10 11 12 13int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) { //... switch (sk->sk_state) { case TCP_CLOSING: if (tp->snd_una == tp->write_seq) { tcp_time_wait(sk, TCP_TIME_WAIT, 0); goto consume; } break; consume: __kfree_skb(skb); return 0; }
11.7 shutdown 源码分析
-
shutdown 系统调用关闭连接的读通道、写通道或者读写通道。
-
对于关闭读通道,shutdown 丢弃所有进程还没有读取的数据以及调用 shutdown 之后到达的数据。
-
对于关闭写通道,shutdown 使用协议作相应的处理。对于 TCP,所有剩余的数据将被发送,返送完后发送 fin 报文。
-
-
调用过程
-
1 2 3 4sys_shutdown ->inet_shutdown ->tcp_shutdown ->tcp_disconnect -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72asmlinkage long sys_shutdown(int fd, int how) { int err, fput_needed; struct socket *sock; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (sock != NULL) { err = security_socket_shutdown(sock, how); if (!err) err = sock->ops->shutdown(sock, how); // inet_shutdown fput_light(sock->file, fput_needed); } return err; } int inet_shutdown(struct socket *sock, int how) { struct sock *sk = sock->sk; int err = 0; /* This should really check to make sure * the socket is a TCP socket. (WHY AC...) */ // how 增1 是为了利用how变量进行为操作 how++; /* maps 0->1 has the advantage of making bit 1 rcvs and 1->2 bit 2 snds. 2->3 */ if ((how & ~SHUTDOWN_MASK) || !how) /* MAXINT->0 */ return -EINVAL; lock_sock(sk); // 根据传输控制块的状态重新设置套接口状态,使套接口状态在完成关闭前只有2种 if (sock->state == SS_CONNECTING) { if ((1 << sk->sk_state) & (TCPF_SYN_SENT | TCPF_SYN_RECV | TCPF_CLOSE)) sock->state = SS_DISCONNECTING; else sock->state = SS_CONNECTED; } // 若传输控制块处于其他状态,则设置shutdown关闭方式后,调用传输层接口shutdown,进行具体传输层关闭 switch (sk->sk_state) { case TCP_CLOSE: err = -ENOTCONN; /* Hack to wake up other listeners, who can poll for POLLHUP, even on eg. unconnected UDP sockets -- RR */ default: sk->sk_shutdown |= how; // 把关闭信息设置到sk_shutdown 中 if (sk->sk_prot->shutdown) // tcp_shutdown 调用 sk->sk_prot->shutdown(sk, how); break; /* Remaining two branches are temporary solution for missing * close() in multithreaded environment. It is _not_ a good idea, * but we have no choice until close() is repaired at VFS level. */ // 若处于TCP_LISTEN,则需要判断关闭方式,若有接收方向的关闭操作,则和TCP_SYN_SENT处理一样 case TCP_LISTEN: if (!(how & RCV_SHUTDOWN)) break; /* Fall through */ // 若处于连接状态过程中(LISTEN或者SYN_SENT状态),则不允许在继续连接,调用disconnect断开连接操作 case TCP_SYN_SENT: err = sk->sk_prot->disconnect(sk, O_NONBLOCK); // tcp_disconnect sock->state = err ? SS_DISCONNECTING : SS_UNCONNECTED; break; } /* Wake up anyone sleeping in poll. */ // 调用sk_state_change,唤醒在传输控制块的等待队列上的进程。sk_state_change // 在 sock_init_data 中被初始化 sk->sk_state_change(sk); release_sock(sk); return err; } -
(1) 可见,inet_shutdown函数
-
把关闭方式设置到套接口 sk_shutdown 中。
-
若传输控制块处于其他状态,调用 tcp_shutdown 。
-
若处于正在连接过程中,则调用 tcp_disconnect 断开连接。
-
-
(2) 对于tcp_shutdown函数而言
- 对于关闭读通道,不需要发送 FIN 报文,直接返回,关闭方式已经在inet_shutdown设置过了。
- 对于关闭写通道,利用tcp_send_fin函数,把未发送出去的数据发送出去之后,发送 FIN 报文。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18void tcp_shutdown(struct sock *sk, int how) { /* We need to grab some memory, and put together a FIN, * and then put it into the queue to be sent. * Tim MacKenzie(tym@dibbler.cs.monash.edu.au) 4 Dec '92. */ /* 不含有SEND_SHUTDOWN,返回,接收方关闭,不发fin */ if (!(how & SEND_SHUTDOWN)) return; /* If we've already sent a FIN, or it's a closed state, skip this. */ /* 以下这几个状态发fin */ if ((1 << sk->sk_state) & (TCPF_ESTABLISHED | TCPF_SYN_SENT | TCPF_SYN_RECV | TCPF_CLOSE_WAIT)) { /* Clear out any half completed packets. FIN if needed. */ if (tcp_close_state(sk)) /* 设置新状态,发送fin */ tcp_send_fin(sk); } } -
(3) 对于tcp_disconnect函数而言
- 对于监听,全连接上的每个 socket 调用 tcp_disconnect,最终会对每个socket 发送 RST 报文。也即是若 shutdown 的是半打开的连接,则发出 RST 来关闭连接。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49int tcp_disconnect(struct sock *sk, int flags) { struct inet_sock *inet = inet_sk(sk); struct inet_connection_sock *icsk = inet_csk(sk); struct tcp_sock *tp = tcp_sk(sk); int err = 0; int old_state = sk->sk_state; /* 不是close状态则设置为close,从hash中删除控制块 */ if (old_state != TCP_CLOSE) tcp_set_state(sk, TCP_CLOSE); /* ABORT function of RFC793 */ /* LISTEN状态,停止监听 */ if (old_state == TCP_LISTEN) { // 删除keepalive定时器,对全连接上的每个socket调用tcp_disconnect inet_csk_listen_stop(sk); /* 根据状态确定是否需要发送rst || 下一个发送序号并不是最后一个队列数据段序号 && 是被动关闭的结束状态 */ } else if (tcp_need_reset(old_state) || (tp->snd_nxt != tp->write_seq && (1 << old_state) & (TCPF_CLOSING | TCPF_LAST_ACK))) { /* The last check adjusts for discrepancy of Linux wrt. RFC * states */ /* 发送rst */ tcp_send_active_reset(sk, gfp_any()); sk->sk_err = ECONNRESET; } else if (old_state == TCP_SYN_SENT) sk->sk_err = ECONNRESET; /* 清除定时器 */ tcp_clear_xmit_timers(sk); /* 释放接收队列中的skb */ __skb_queue_purge(&sk->sk_receive_queue); /* 释放发送队列中的skb */ sk_stream_writequeue_purge(sk); /*释放未按顺序达到的skb */ __skb_queue_purge(&tp->out_of_order_queue); #ifdef CONFIG_NET_DMA __skb_queue_purge(&sk->sk_async_wait_queue); #endif /* 其他各种清理工作 */ inet->dport = 0; ... return err; }
12. TCP 数据读写 send recv
12.1 函数详解
-
send() — 从套接字发送消息。
-
recv() — 从套接字接收消息。
-
在Linux中,send()和recv()函数可以阻塞或非阻塞,这取决于套接字(socket)的设置和操作系统的行为。
-
默认情况下,套接字是阻塞的。当调用send()函数时,如果发送缓冲区没有足够的空间来容纳要发送的数据,send()函数将阻塞,直到有足够的空间可用为止。类似地,当调用recv()函数时,如果接收缓冲区没有数据可读取,recv()函数也将阻塞,直到有数据可用为止。
-
然而,你可以通过设置套接字为非阻塞模式来改变这种行为。通过将套接字设置为非阻塞模式,send()和recv()函数将立即返回,而不会阻塞等待。在非阻塞模式下,send()函数可能只能发送部分数据,而recv()函数可能只能接收部分数据。因此,在使用非阻塞模式时,你需要检查返回值以确定实际发送或接收的数据量。
-
要将套接字设置为非阻塞模式,可以使用fcntl()函数来获取和修改套接字的属性,或者使用ioctl()函数来设置套接字的属性。
-
总之,send()和recv()函数在默认情况下是阻塞的,但你可以通过将套接字设置为非阻塞模式来改变这种行为。
-
在大多数情况下,
ssize_t和size_t具有相同的大小(通常为 8 字节的 long 和 unsigned long),但ssize_t是有符号的,而size_t是无符号的。 -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28#include <sys/types.h> #include <sys/socket.h> //用于TCP数据发送 ssize_t send(int sockfd, const void *buf, size_t len, int flags); /* 【参数说明】 sockfd:表示与通信对端进行数据交互的套接字文件描述符。 buf:保存待发送数据的缓冲区的地址值。 len:待发送数据的字节数。 flags:发送数据时指定的可选项信息,通常设置为0即可。 【返回值】成功时返回发送的字节数,失败时返回-1并设置error。 */ //TCP数据接收 ssize_t recv(int sockfd, void *buf, size_t len, int flags); /* 【参数说明】 sockfd:表示与通信对端进行数据交互的套接字文件描述符。 buf:保存待接收数据的缓冲区地址值。 len:可接收的最大字节数。 flags:接收数据时指定的可选项信息,通常设置为0即可。 【返回值】 -1 出错并设置error =0 连接关闭 >0 接收到的实际数据大小 */ -

-
可选项(Option) 含义 send recv MSG_OOB 用于传输带外数据(Out-of-band data) Y Y MSG_PEEK 验证输入(接收)缓冲中是否存在待接收的数据 N Y MSG_DONTROUTE 数据传输过程中不参照路由(Routing)表,在本地(Local)网络中寻找目的地 Y N MSG_DONTWAIT 调用 I/O 函数时不阻塞,用于使用非阻塞(Non-blocking)I/O Y Y MSG_WAITALL 防止函数返回,直到接收到全部请求的字节数才返回 N Y
12.2 带外OOB数据
-
有些传输层协议具有带外(Out Of Band,OOB)数据的概念,用于迅速通告对方本端发生的重要事件。因此,带外数据比普通数据(也称为带内数据)有更高的优先级,它应该总是立即被发送,而不论发送缓冲区中是否有排队等待发送的普通数据。带外数据的传输可以使用一条独立的传输层连接,也可以映射到传输普通数据的连接中。实际应用中,带外数据的使用很少见,已知的仅有telnet、ftp等远程非活跃程序。
-
例子:ftp正在传一个文件,传到一半想中止,可以使用带外数据来中断一个文件的传输。
-
UDP没有实现带外数据传输,TCP也没有真正的带外数据。不过TCP利用其头部中的紧急指针标志URG和紧急指针两个字段,给应用程序提供了一种紧急方式。TCP的紧急方式利用传输普通数据的连接来传输紧急数据。这种紧急数据的含义和带外数据类似,因此后文也将TCP紧急数据称为带外数据。
-
假设一个进程已经往某个TCP连接的发送缓冲区中写人了N字节的普通数据,并等待其发送。在数据被发送前,该进程又向这个连接写人了3字节的带外数据“abc”。此时,待发送的TCP报文段的头部将被设置URG标志,并且紧急指针被设置为指向最后一个带外数据的下一字节(进一步减去当前TCP报文段的序号值得到其头部中的紧急偏移值),如下图所示。
-
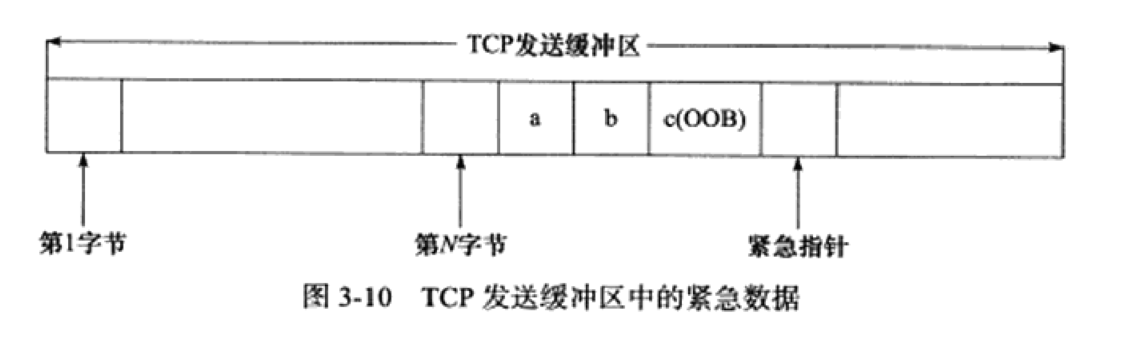
-
TCP接收端只有在接收到紧急指针标志时才检查紧急指针,然后根据紧急指针所指的位置确定带外数据的位置,并将它读入一个特殊的缓存中。这个缓存只有1字节,称为带外缓存。因此上面的abc三个数据,只有c被当作带外数据。如果上层应用程序没有及时将带外数据从带外缓存中读出,则后续的带外数据(如果有的话)将覆盖它。
-
由上图可见,发送端一次发送的多字节的带外数据中只有最后一字节被当做带外数据(字母c),而其他数据(字母a和b)被当成了普通数据。
-
上面讨论的带外数据的接收过程是TCP模块接收带外数据的默认方式。如果我们给TCP连接设置了SO_OOBINLINE选项,则带外数据将和普通数据一样被TCP模块存放在TCP接收缓冲区中。此时应用程序需要像读取普通数据一样来读取带外数据。那么这种情况下如何区分带外数据和普通数据呢?显然,紧急指针可以用来指出带外数据的位置,socket编程接口也提供了系统调用来识别带外数据。
12.3 带外数据发送接收实验
-
服务器为ubuntu,ip地址为192.168.141.128
-
客户端为windows,ip地址为192.168.141.1
-
(1) 在服务器启动如下程序。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> #define BUF_SIZE 1024 int main(int argc, char *argv[]) { // if (argc <= 2) { // printf("usage: %s ip_address port_number\n", basename(argv[0])); // return 1; // } // const char *ip = argv[1]; // int port = atoi(argv[2]); const char *ip = "192.168.141.128"; int port = 12345; struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int sock = socket(PF_INET, SOCK_STREAM, 0); assert(sock >= 0); int ret = bind(sock, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(sock, 5); assert(ret != -1); struct sockaddr_in client; socklen_t client_addrlength = sizeof(client); int connfd = accept(sock, (struct sockaddr *)&client, &client_addrlength); if (connfd < 0) { printf("errno is: %d\n", errno); } else { char buffer[BUF_SIZE]; memset(buffer, '\0', BUF_SIZE); // 最后一个字符串 // '\0',因此长度减1,以便将接收到的数据作为以空字符结尾的字符串进行处理 ret = recv(connfd, buffer, BUF_SIZE - 1, 0); printf("got %d bytes of normal data '%s'\n", ret, buffer); memset(buffer, '\0', BUF_SIZE); ret = recv(connfd, buffer, BUF_SIZE - 1, MSG_OOB); printf("got %d bytes of oob data '%s'\n", ret, buffer); memset(buffer, '\0', BUF_SIZE); ret = recv(connfd, buffer, BUF_SIZE - 1, 0); printf("got %d bytes of normal data '%s'\n", ret, buffer); close(connfd); } close(sock); return 0; } -
输出结果
-
-
(2) 在客户端启动如下程序。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52#include <stdio.h> #include <stdlib.h> #include <string.h> #include <winsock2.h> #include <WS2tcpip.h> #pragma comment(lib, "ws2_32.lib") int main() { WSADATA wsaData; if (WSAStartup(MAKEWORD(2, 2), &wsaData) != 0) { printf("Failed to initialize winsock.\n"); return 1; } const char *ip = "192.168.141.128"; int port = 12345; SOCKET sockfd = socket(AF_INET, SOCK_STREAM, 0); if (sockfd == INVALID_SOCKET) { printf("Failed to create socket.\n"); WSACleanup(); return 1; } struct sockaddr_in server_address; memset(&server_address, 0, sizeof(server_address)); server_address.sin_family = AF_INET; inet_pton(AF_INET, ip, &server_address.sin_addr); server_address.sin_port = htons(port); if (connect(sockfd, (struct sockaddr *)&server_address, sizeof(server_address)) == SOCKET_ERROR) { printf("Connection failed.\n"); closesocket(sockfd); WSACleanup(); return 1; } else { Sleep(5000); printf("Send oob data out.\n"); const char *oob_data = "abc"; const char *normal_data = "123"; send(sockfd, normal_data, strlen(normal_data), 0); send(sockfd, oob_data, strlen(oob_data), MSG_OOB); send(sockfd, normal_data, strlen(normal_data), 0); } closesocket(sockfd); WSACleanup(); return 0; } -
输出结果
-

-
(3) 在服务端通过 tcpdump 抓包。
-
1tcpdump -S '(src 192.168.141.1 or dst 192.168.141.1) and port 12345' -

-
(4) 总结
-
可以看到客户端发送给服务端的3个字节的带外数据“abc"中,仅有最后一个字符”c"被服务器当成真正的带外数据接受。并且,服务器对正常数据的接受将被带外数据截断,即前一部分正常数据”123ab"和后续的正常数据“123”是不能被一个recv调用全部读出的。
-
值得一提的是,flags参数只对send和recv的当前调用生效,后面我们将看到如何通过setsockopt系统调用永久性地修改socket的某些属性。
-
在stack overflow上有这么一个问题,can one call of recv() receive data from 2 consecutive send() calls? - Stack Overflow
-
一个recv调用能接受多个send吗,实际上是可以的,TCP也是这么传输的。也就是说,没有硬性要求一个send必须对应一个recv。
-
修改客户端发送代码,flags全设为0.
-
1 2 3send(sockfd, normal_data, strlen(normal_data), 0); send(sockfd, oob_data, strlen(oob_data), 0); send(sockfd, normal_data, strlen(normal_data), 0); -
修改服务端接受代码,只调用一个recv。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17char buffer[BUF_SIZE]; memset(buffer, '\0', BUF_SIZE); // 最后一个字符串 // '\0',因此长度减1,以便将接收到的数据作为以空字符结尾的字符串进行处理 ret = recv(connfd, buffer, BUF_SIZE - 1, 0); printf("got %d bytes of normal data '%s'\n", ret, buffer); // memset(buffer, '\0', BUF_SIZE); // ret = recv(connfd, buffer, BUF_SIZE - 1, MSG_OOB); // printf("got %d bytes of oob data '%s'\n", ret, buffer); // memset(buffer, '\0', BUF_SIZE); // ret = recv(connfd, buffer, BUF_SIZE - 1, 0); // printf("got %d bytes of normal data '%s'\n", ret, buffer); close(connfd); -
实验结果如下
-

-
tcpdump 抓包结果如下
-
12.4 接收带外数据的三种方式
-
12.3的实验中,我们是上帝视角已知有带外数据,但在实际应用中,我们通常无法预期带外数据何时到来。
-
好在Linux内核检测到TCP紧急标志时,将通知应用程序有带外数据需要接收。
-
内核通知应用程序带外数据到达的三种常见方式是:sockatmark函数、I/O复用(select)产生的异常事件和SIGURG信号。
-
(1)方式1:sockatmark
-
sockatmark 系统调用定义如下:
-
1 2#include <sys/socket.h> int sockatmark (int sockfd) -
sockatmark判断sockfd是否处于带外标记,即下一个被读取到的数据是否是带外数据。
-
如果是,sockatmark返回1,此时我们就可以利用带MSG_OOB标志的recv系统调用来接收带外数据。
-
如果不是,则sockatmark返回0。
-
-
以下是使用 sockatmark 检测带外数据在数据流的具体位置的实验。
-
服务器代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <sys/types.h> #include <unistd.h> int main(int argc, char *argv[]) { const char *ip = "192.168.141.128"; int port = 12345; printf("ip is %s and port is %d\n", ip, port); int ret = 0; struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int listenfd = socket(PF_INET, SOCK_STREAM, 0); assert(listenfd >= 0); ret = bind(listenfd, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(listenfd, 5); assert(ret != -1); struct sockaddr_in client_address; socklen_t client_addrlength = sizeof(client_address); int connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength); if (connfd < 0) { printf("errno is: %d\n", errno); close(listenfd); } char remote_addr[INET_ADDRSTRLEN]; printf("connected with ip: %s and port: %d\n", inet_ntop(AF_INET, &client_address.sin_addr, remote_addr, INET_ADDRSTRLEN), ntohs(client_address.sin_port)); char buf[1024]; // 设置socket接收带外数据存在普通缓存区,使用普通的读取方式 int nReuseAddr = 1; setsockopt(connfd, SOL_SOCKET, SO_OOBINLINE, &nReuseAddr, sizeof(nReuseAddr)); int n = 0; for (;;) { if (sockatmark(connfd)) { // 读取带外标志 printf("at OOB mark\n"); n = recv(connfd, buf, 1, 0); buf[n] = 0; printf("read %d oob bytes: %s\n", n, buf); continue; } if ((n = recv(connfd, buf, sizeof(buf) - 1, 0)) <= 0) { printf("received EOF\n"); break; } buf[n] = 0; /* 结束标志 */ printf("read %d bytes: %s\n", n, buf); } close(connfd); close(listenfd); return 0; } -
客户端代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36#include <arpa/inet.h> #include <assert.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> int main(int argc, char *argv[]) { const char *ip = "192.168.141.128"; int port = 12345; struct sockaddr_in server_address; memset(&server_address, 0, sizeof(server_address)); server_address.sin_family = AF_INET; inet_pton(AF_INET, ip, &server_address.sin_addr); server_address.sin_port = htons(port); int sockfd = socket(PF_INET, SOCK_STREAM, 0); assert(sockfd >= 0); if (connect(sockfd, (struct sockaddr *)&server_address, sizeof(server_address)) < 0) { printf("connection failed\n"); } else { printf("send oob data out\n"); const char *oob_data = "abc"; const char *normal_data = "123"; send(sockfd, normal_data, strlen(normal_data), 0); send(sockfd, oob_data, strlen(oob_data), MSG_OOB); // 使用 MSG_OOB标记 send(sockfd, normal_data, strlen(normal_data), 0); } close(sockfd); return 0; } -
实验结果
-
-
这里有个细节需要说明,在连接建立时设定了 OOB_INLINE 标志位,则应使用不带 MSG_OOB 的 recv 接收数据,因为 OOB 数据已经被当作惯常数据来处理了。
-
如果不设置 OOB_INLINE 标志位,此时的服务器端代码应如下
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <sys/types.h> #include <unistd.h> int main(int argc, char *argv[]) { const char *ip = "192.168.141.128"; int port = 12345; printf("ip is %s and port is %d\n", ip, port); int ret = 0; struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int listenfd = socket(PF_INET, SOCK_STREAM, 0); assert(listenfd >= 0); ret = bind(listenfd, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(listenfd, 5); assert(ret != -1); struct sockaddr_in client_address; socklen_t client_addrlength = sizeof(client_address); int connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength); if (connfd < 0) { printf("errno is: %d\n", errno); close(listenfd); } char remote_addr[INET_ADDRSTRLEN]; printf("connected with ip: %s and port: %d\n", inet_ntop(AF_INET, &client_address.sin_addr, remote_addr, INET_ADDRSTRLEN), ntohs(client_address.sin_port)); char buf[1024]; int n = 0; for (;;) { if (sockatmark(connfd)) { // 读取带外标志 printf("at OOB mark\n"); n = recv(connfd, buf, 1, MSG_OOB); buf[n] = 0; printf("read %d oob bytes: %s\n", n, buf); } if ((n = recv(connfd, buf, sizeof(buf) - 1, 0)) <= 0) { printf("received EOF\n"); break; } buf[n] = 0; /* 结束标志 */ printf("read %d bytes: %s\n", n, buf); } close(connfd); close(listenfd); return 0; } -
此时测试结果如下
-
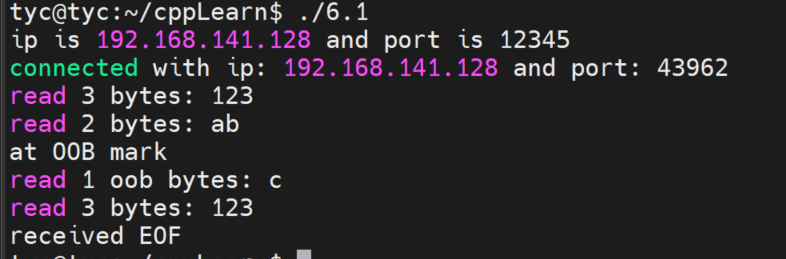
-
(2)方式2:使用select,带外数据出现返回一个待处理的异常
-
(3)方式3:程序捕捉SIGURG信号来处理特殊数据
13. UDP 数据读写 sendto recvfrom
-
1 2 3 4 5 6 7 8 9 10#include <sys/types.h> #include <sys/socket.h> //用于UDP数据接收 ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen); //用于UDP数据发送 ssize_t sendto(int sockfd, const void *buf, size_t len, int flags, const struct sockaddr *dest_addr, socklen_t addrlen); -

14. 通用数据读写 sendmsg recvmsg
-
socket编程接口还提供了一对通用的数据读写系统调用。它们不仅能用于TCP流数据,也能用于UDP数据报。
-
1 2 3 4 5#include <sys/types.h> #include <sys/socket.h> ssize_t recvmsg(int sockfd, const struct msghdr *msg, int flags); ssize_t sendmsg(int sockfd, const struct msghdr *msg, int flags); -
其中msghdr结构体如下
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14struct msghdr { void* msg_name; // socket地址 socklen_t msg_namelen; // socket地址长度 struct iovec* msg_iov; // 分散的内存块,就是个数组地址 int msg_iovlen; // 分散内存块的数量 void* msg_control; // 指向辅助数据的起始位置 socklen_t msg_controllen; // 辅助数据的大小 int msg_flags; // 复制函数中的flags参数,并在调用过程中更新 }; struct iovec { void *iov_base; /*内存起始地址*/ size_t iov_len; /*这块内存的长度*/ }; -
msg_name 和 msg_namelen 这两个成员用于套接字未连接的场合(如未连接 UDP 套接字)。它们类似 recvfrom 和 sendto 的第五个和第六个参数:
- msg_name 指向一个套接字地址结构,调用者在其中存放接收者(对于 sendmsg 调用)或发送者(对于recvmsg调用)的协议地址。如果无需指明协议地址(如对于 TCP 套接字等),msg_name 应置为空指针NULL。
- msg_namelen 对于 sendmsg 是一个值参数,对于 recvmsg 却是一个结果参数。
-
msg_iov 和 msg_iovlen 这两个成员指定输入或输出缓冲区数组(即iovec结构数组),类似 readv 或 writev 的第二个和第三个参数。
-
msg_control 和 msg_controllen 这两个成员指定可选的辅助数据的位置和大小。msg_controllen 对于 recvmsg 是一个结果参数。
-
msg_flags成员无须设定,它会复制recvmsg/sendmsg的flags参数的内容以影响数据读写过程。recvmsg还会在调用结束前,将某些更新后的标志设置到msg_flags中。
-

15. 地址信息函数 getsockname getpeername
-
getsockname函数用于获取与某个套接字关联的本地socket地址;
-
getpeername函数用于获取与某个套接字关联的远端socket地址;
-
1 2 3 4#include<sys/socket.h> int getsockname(int sockfd, struct sockaddr *localaddr, socklen_t *addrlen); int getpeername(int sockfd, struct sockaddr *peeraddr, socklen_t *addrlen);对于这两个函数,如果函数调用成功,则返回0,如果调用出错,则返回-1。
-
使用这两个函数,我们可以通过套接字描述符来获取自己的IP地址和连接对端的IP地址,如在未调用bind函数的TCP服务端程序上,可以通过调用getsockname()函数获取由内核赋予该连接的本地IP地址和本地端口号;还可以在TCP的服务器端accept成功后,通过getpeername()函数来获取当前连接的客户端的IP地址和端口号。
-
这里需要说明,提供的addrlen指针指向的大小应该被初始化一个具体的数,否则,getsockname()/getpeername()函数被调用可能会得到0.0.0.0的结果。
-

-
服务器程序如下
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> int main(int argc, char *argv[]) { const char *ip = "192.168.141.128"; int port = 12345; // 创建socket struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int sock = socket(PF_INET, SOCK_STREAM, 0); assert(sock >= 0); // 绑定 int ret = bind(sock, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); // 监听 ret = listen(sock, 5); assert(ret != -1); // 接受一个连接 struct sockaddr_in client; socklen_t client_addrlength = sizeof(client); int connfd = accept(sock, (struct sockaddr *)&client, &client_addrlength); struct sockaddr_in listendAddr, connectedAddr, peerAddr; // 分别表示监听的地址,连接的本地地址,连接的对端地址 // 长度必须初始化 socklen_t listendAddrLen = sizeof(listendAddr); socklen_t connectedAddrLen = sizeof(connectedAddr); socklen_t peerLen = sizeof(connectedAddr); getsockname(sock, (struct sockaddr *)&listendAddr, &listendAddrLen); // 获取监听的地址和端口 printf("listen address = %s:%d\n", inet_ntoa(listendAddr.sin_addr), ntohs(listendAddr.sin_port)); if (connfd < 0) { printf("errno is: %d\n", errno); } else { getsockname(connfd, (struct sockaddr *)&connectedAddr, &connectedAddrLen); // 获取connfd表示的连接上的本地地址 printf("connected server address = %s:%d\n", inet_ntoa(connectedAddr.sin_addr), ntohs(connectedAddr.sin_port)); getpeername(connfd, (struct sockaddr *)&peerAddr, &peerLen); // 获取connfd表示的连接上的对端地址 printf("connected client address = %s:%d\n", inet_ntoa(peerAddr.sin_addr), ntohs(peerAddr.sin_port)); close(connfd); printf("close accept socket\n"); } close(sock); printf("close listen socket\n"); return 0; } -
telnet一下服务器,会得出如下结果,这样是正确的。
-
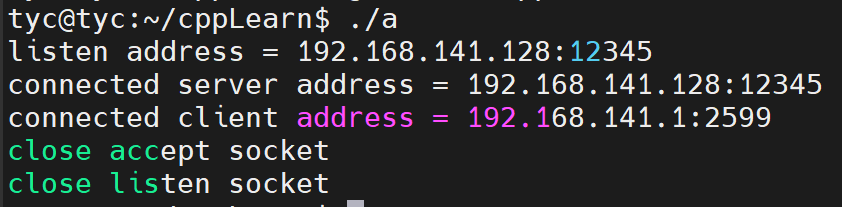
16. socket 文件描述符属性控制 getsockopt setsockopt
16.1 函数详解
-
如果说
fcntl系统调用是控制文件描述符属性的通用POSIX方法,那么下面两个系统调用则是专门用来读取和设置socket文件描述符属性的方法: -
1 2 3 4 5#include <sys/socket.h> #include <sys/types.h> int getsockopt(int sockfd, int level, int option_name, void *option_value, socklen_t *option_len); int setsockopt(int sockfd, int level, int option_name, const void *option_value, socklen_t *option_len); -
(1)sockfd 指定被操作的socket;
-
(2)level 指定哪些协议的选项(属性),如TCP、IPV4、IPV6等等。有如下一些值:
SOL_SOCKET :通用套接字 IPPROTO_IP :IPV4 套接字 IPPROTO_IPV6 :IPV6 套接字 IPPROTO_TCP :TCP 套接字选项
-
(3)option_name 指定选项的名字;
-
(4)option_value:指向某个变量的指针,setsockopt从
*option_value中取得选项待设置的新值,getsockopt把已获取的选项当前值存放在*option_value中。 -
(5)option_len:
*option_value的大小(字节个数)由option_len指定,setsockopt是一个值参数,getsockopt是一个值-结果参数。- option_value 和 option_len 参数一起使用,通过 getsockopt / setsockopt 函数可以获取套接字选项的值和长度,
-
返回值:getsockopt和setsockopt这两个函数成功时返回0,失败时返回-1并设置errno。
-

-
-
对于服务器而言,有部分socket选项只能在调用listen系统调用前针对绑定了的socket设置才有效。这是因为连接socket只能由accept调用返回,而accept从listen监听队列接受的连接已经完成了TCP的三次握手,这说明服务器已经往被接收连接上发送出了TCP同步报文段。
-
但有的socket选项却应该在TCP同步报文段中设置,比如TCP最大报文段选项。
-
对这种情况,linux给服务器开发人员提供的解决方案是:对监听socket(执行了listen系统调用后的socket)设置这些socket选项,那么accept返回的连接socket将自动继承这些选项。这些选项包括:SO_DEBUG、SO_DONTROUTE、SO_KEEPALIVE、SO_LINGER、SO_OOBINLINE、SO_RCVBUF、SO_RCVLOWAT、SO_SNDBUF、SO_SNDLOWAT、TCP_MAXSEG和TCP_NODELAY。对于客户端而言,这些socket选项则应该在调用connect函数之前设置,因为connect调用成功返回之后,TCP三次握手已完成。
-
-

-

-
上图的粗虚线表示典型的服务器连接的状态转移;粗实线表示典型的客户端连接的状态转移。
16.2 SO_REUSEADDR 选项
-
-
从上图的TCP状态转移可以看到,客户端收到服务器的FIN后发送ACK会进入 TIME_WAIT 状态,但是这个时候的socket是没有解除占用的,不能复用。
-
一般客户端是不会有什么问题,因为端口号是系统随机的。但是如果服务器进入了 TIME_WAIT 状态,就不能马上用了。
-
服务器程序可以通过设置socket选项SO_REUSEADDR来强制使用被处于TIME_WAIT状态的连接占用的socket地址。具体实现方法为在bind绑定socket之前,设置socket的状态。
-
1 2int reuse = 1; setsockopt(sock, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof(reuse)); -
经过setsockopt的设置之后,即使sock处于TIME_WAIT状态,与之绑定的socket地址也可以立即被重用。此外,我们也可以通过修改内核参数/proc/sys/net/ipv4/tcp_tw_recycle来快速回收被关闭的socket,从而使得TCP连接根本就不进入TIME_WAIT状态,进而允许应用程序立即重用本地的socket地址。
-
以下是完整的示例代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> int main(int argc, char *argv[]) { if (argc <= 2) { printf("usage: %s ip_address port_number\n", basename(argv[0])); return 1; } const char *ip = argv[1]; int port = atoi(argv[2]); int sock = socket(PF_INET, SOCK_STREAM, 0); assert(sock >= 0); // 设置可重用 int reuse = 1; setsockopt(sock, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof(reuse)); struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int ret = bind(sock, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(sock, 5); assert(ret != -1); struct sockaddr_in client; socklen_t client_addrlength = sizeof(client); int connfd = accept(sock, (struct sockaddr *)&client, &client_addrlength); if (connfd < 0) { printf("errno is: %d\n", errno); } else { char remote[INET_ADDRSTRLEN]; printf("connected with ip: %s and port: %d\n", inet_ntop(AF_INET, &client.sin_addr, remote, INET_ADDRSTRLEN), ntohs(client.sin_port)); close(connfd); } close(sock); return 0; }
16.3 SO_RCVBUF 和 SO_SNDBUF 选项
-
SO_RCVBUF和SO_SNDBUF选项分别表示TCP接收缓冲区和发送缓冲区的大小。不过,当我们用setsockopt来设置TCP的接收缓冲区和发送缓冲区的大小时,系统都会将其值加倍,并且不得小于某个最小值。TCP接收缓冲区的最小值是256字节,而发送缓冲区的最小值是2048字节(不过,不同的系统可能有不同的默认最小值)。系统这样做的目的,主要是确保一个TCP连接拥有足够的空闲缓冲区来处理拥塞(比如快速重传算法就期望TCP接收缓冲区能至少容纳4个大小为SMSS的TC报文段)。此外,我们可以直接修改内核参数/proc/sys/net/ipv4/tcp_rmem和proc/sys/net/ipv4/tcp_wmem来强制TCP接收缓冲区和发送缓冲区的大小没有最小值限制。
-
发送方最大报文段长度 SMSS:SENDER MAXIMUM SEGMENT SIZE。
-
MSS 一般在以太网为 1460 字节大小,等于 MTU(最大传输单元) - 40 。
-
具体方式为为服务端在bind绑定socket之前,设置socket的状态。客户端在accept调用前,设置socket的状态。
-
客户端设置示例代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44#include <arpa/inet.h> #include <assert.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> #define BUFFER_SIZE 512 int main(int argc, char *argv[]) { if (argc <= 3) { printf("usage: %s ip_address port_number send_bufer_size\n", basename(argv[0])); return 1; } const char *ip = argv[1]; int port = atoi(argv[2]); struct sockaddr_in server_address; memset(&server_address, 0, sizeof(server_address)); server_address.sin_family = AF_INET; inet_pton(AF_INET, ip, &server_address.sin_addr); server_address.sin_port = htons(port); int sock = socket(PF_INET, SOCK_STREAM, 0); assert(sock >= 0); int sendbuf = atoi(argv[3]); int len = sizeof(sendbuf); setsockopt(sock, SOL_SOCKET, SO_SNDBUF, &sendbuf, sizeof(sendbuf)); getsockopt(sock, SOL_SOCKET, SO_SNDBUF, &sendbuf, (socklen_t *)&len); printf("the tcp send buffer size after setting is %d\n", sendbuf); if (connect(sock, (struct sockaddr *)&server_address, sizeof(server_address)) != -1) { char buffer[BUFFER_SIZE]; memset(buffer, 'a', BUFFER_SIZE); send(sock, buffer, BUFFER_SIZE, 0); } close(sock); return 0; } -
服务器设置代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> #define BUFFER_SIZE 1024 int main(int argc, char *argv[]) { if (argc <= 3) { printf("usage: %s ip_address port_number receive_buffer_size\n", basename(argv[0])); return 1; } const char *ip = argv[1]; int port = atoi(argv[2]); struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int sock = socket(PF_INET, SOCK_STREAM, 0); assert(sock >= 0); int recvbuf = atoi(argv[3]); int len = sizeof(recvbuf); setsockopt(sock, SOL_SOCKET, SO_RCVBUF, &recvbuf, sizeof(recvbuf)); getsockopt(sock, SOL_SOCKET, SO_RCVBUF, &recvbuf, (socklen_t *)&len); printf("the receive buffer size after settting is %d\n", recvbuf); int ret = bind(sock, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(sock, 5); assert(ret != -1); struct sockaddr_in client; socklen_t client_addrlength = sizeof(client); int connfd = accept(sock, (struct sockaddr *)&client, &client_addrlength); if (connfd < 0) { printf("errno is: %d\n", errno); } else { char buffer[BUFFER_SIZE]; memset(buffer, '\0', BUFFER_SIZE); // 一直读取 while (recv(connfd, buffer, BUFFER_SIZE - 1, 0) > 0) { } close(connfd); } close(sock); return 0; } -

16.4 SO_RCVLOWAT 和 SO_SNDLOWAT 选项
- SO_RCVLOWAT和SO_SNDLOWAT选项分别表示TCP接收缓冲区和发送缓冲区的低水位标记。它们一般被I/O复用系统调用用来判断socket是否可读或可写。
- 当TCP接收缓冲区中可读数据的总数大于其低水位标记时,I/O复用系统调用将通知应用程序可以从对应的socket上读取数据;
- 当TCP发送缓冲区中的空闲空间(可以写入数据的空间)大于其低水位标记时,I/O复用系统调用将通知应用程序可以往对应的socket上写入数据。
- 默认情况下,TCP接收缓冲区的低水位标记和TCP发送缓冲区的低水位标记均为1字节。
16.5 SO_LINGER 选项
-
SO_LINGER选项用于控制close系统调用在关闭TCP连接时的行为。默认情况下,当我们使用close系统调用来关闭一个socket时,close将立即返回(也不是立即返回,就是按close调用走下去,禁止SO_LINGER选项或启用了SO_LINGER选项且延时时间不为0,按四次挥手;弃用了SO_LINGER且l_linger等于0,直接返回RST报文),TCP模块负责把该socket对应的TCP发送缓冲区中残留的数据发送给对方。
-
设置(获取)SO_LINGER选项的值时,我们需要给setsockopt(getsockopt)系统调用传递一个linger类型的结构体,其定义如下:
-
1 2 3 4 5 6#include <sys/socket.h> struct linger { int l_onoff; /* 开启(非0)还是关闭(0) */ int l_linger; /* 滞留时间 */ }; -
根据 l_onoff 和 l_linger 值的不同,可以有以下三种情况。
-
(1)当l_onoff为0时,l_linger的值被忽略,这也是close的默认操作。
-
(2)当l_onoff为非0时,l_linger的值也为0。在这个情况下,当调用close的时候,TCP连接会立即断开。发送缓冲区里面剩余的数据将被丢弃,并向对方发送一个RST复位报文段,而不是通常的四分组(FIN, ACK, FIN, ACK)终止序列,这避免了TIME_WAIT状态,而且这是非正常的断开连接。
-
(3)当 l_onoff 为非0,l_linger为非0,当套接口关闭时内核将拖延一段时间(由l_linger决定)。如果套接口缓冲区中仍残留数据,对于阻塞的socket,进程将处于睡眠状态,直到以下两种情况的一种触发。而如果套接口socket设为非阻塞的,它将不等待close完成,此时我们需要根据其返回值和errno来判断残留数据是否已经发送完毕。
- (a)所有数据发送完且被对方确认,之后进行正常的终止序列(描述字访问计数为0);
- (b)延迟时间到。此种情况下,应用程序检查close的返回值是非常重要的,如果在数据发送完并被确认前时间到,close将返回-1并设置errno为EWOULDBLOCK错误,其套接口发送缓冲区中的任何数据都丢失。需要注意的是close的成功返回仅告诉我们发送的数据(和FIN)已由对方TCP确认,它并不能告诉我们对方应用进程是否已读了数据。
-
示例代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> #define BUFFER_SIZE 1024 int main(int argc, char *argv[]) { if (argc <= 3) { printf("usage: %s ip_address port_number receive_buffer_size\n", basename(argv[0])); return 1; } const char *ip = argv[1]; int port = atoi(argv[2]); struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int sock = socket(PF_INET, SOCK_STREAM, 0); assert(sock >= 0); int ret = bind(sock, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(sock, 5); assert(ret != -1); // 需要在listen之后设置 linger ln; ln.l_onoff = true; ln.l_linger = 30; // linger 30 more seconds setsockopt(sock, SOL_SOCKET, SO_LINGER, &ln, sizeof(linger)); struct sockaddr_in client; socklen_t client_addrlength = sizeof(client); int connfd = accept(sock, (struct sockaddr *)&client, &client_addrlength); if (connfd < 0) { printf("errno is: %d\n", errno); } else { char buffer[BUFFER_SIZE]; memset(buffer, '\0', BUFFER_SIZE); // 一直读取 while (recv(connfd, buffer, BUFFER_SIZE - 1, 0) > 0) { } close(connfd); } close(sock); return 0; }
17. 网络信息 API
-
socket地址的两个要素,即IP地址和端口号,都是用数值表示的。这不便于记忆,也不便于扩展(比如从IPv4转移到IPv6)。因此在前面的章节中,我们用主机名来访问一台机器,而避免直接使用其IP地址。同样,我们用服务名称来代替端口号。比如,下面两条telnet命令具有完全相同的作用:
-
1 2telnet 127.0.0.1 80 telnet localhost www -
上面的例子中,telnet客户端程序是通过调用某些网络信息API来实现主机名到IP地址的转换,以及服务名称到端口号的转换的。
17.1 gethostbyname 和 gethostbyaddr
-
这两个函数都会返回主机的完整信息,即 hostent 结构体类型的指针,hostent结构体的定义如下:
-
需要注意的是,这两个函数是不可重入的。
-
1 2 3 4 5 6 7 8struct hostent { char *h_name; /*正式主机名*/ char **h_aliases; /*主机别名列表,可能有多个*/ int h_addrtype; /*主机IP地址类型 IPv4为AF_INET*/ int h_length; /*主机IP地址字节长度,对于IPv4是4字节,即32位*/ char **h_addr_list; /*按网络字节序列出的主机IP地址列表*/ } -
gethostbyname函数根据主机名称获取主机的完整信息;
- gethostbyname函数通常先在本地的/etc/hosts配置文件中查找主机,如果没有找到,再去访问DNS服务器。
-
示例
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26#include <arpa/inet.h> #include <netdb.h> #include <stdio.h> int main() { char hostname[] = "www.tycilyz.top"; struct hostent *host; host = gethostbyname(hostname); if (host == NULL) { printf("Failed to resolve hostname.\n"); return 1; } printf("Hostname: %s\n", host->h_name); // 获取主机的IP地址列表 printf("IP Address(es):\n"); for (int i = 0; host->h_addr_list[i] != NULL; i++) { // 转换为 主机字节序 printf("%s\n", inet_ntoa(*(struct in_addr *)host->h_addr_list[i])); } return 0; } -
-
gethostbyaddr函数根据IP地址获取主机的完整信息;
-
1 2 3 4 5 6 7 8 9 10 11 12#include <netdb.h> struct hostent* gethostbyname(const char* hostname); /* 参数hostname指向存放域名或主机名的字符串。 */ struct hostent* gethostbyaddr(const void* addr, size_t len, int family); /* addr参数指定目标主机的IP地址,需要注意的是,这并不是 "192.0.2.1" 这种字符串,而是inet_aton转为的网络字节序地址; len参数指定addr所指IP地址的长度; type参数指定addr所指IP地址的类型,其合法取值包括AF_INET(用于IPv4地址)和AF_INET6(用于IPv6地址)。 */ -
示例
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27#include <arpa/inet.h> #include <netdb.h> #include <stdio.h> #include <string.h> int main() { struct in_addr addr; struct hostent *host; // 设置IP地址 if (inet_aton("101.33.232.117", &addr) == 0) { printf("Invalid IP address.\n"); return 1; } host = gethostbyaddr(&addr, sizeof(addr), AF_INET); if (host == NULL) { printf("Failed to resolve IP address.\n"); printf("Error: %s\n", strerror(h_errno)); // 打印错误代码 return 1; } printf("Hostname: %s\n", host->h_name); return 0; } -
实验结果,需要对应的服务器开启相关访问权限。
-

17.2 getservbyname 和 getservbyport
-
getservbyname函数根据名称获取某个服务的完整信息,getservbyport函数根据端口号获取某个服务的完整信息。它们实际上都是通过读取/etc/services 文件来获取服务的信息的。
-
需要注意的是,这两个函数也是不可重入的。
-
这两个函数返回的都是 servent 结构体类型的指针。
-
1 2 3 4 5 6 7struct servent { char *s_name; /* 服务名称 Official service name. */ char **s_aliases; /* 服务的别名列表,可能有多个,Alias list. */ int s_port; /* 端口号,Port number. */ char *s_proto; /* 服务类型,通常是tcp或者udp Protocol to use. */ }; -
函数原型
-
1 2 3#include <netdb.h> struct servent *getservbyname(const char *name, const char *proto); struct servent *getservbyport(int port, const char *proto); -

-

-
实验示例,通过访问开启daytime服务的Linux服务器,代码如下
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35#include <assert.h> #include <netdb.h> #include <netinet/in.h> #include <stdio.h> #include <sys/socket.h> #include <unistd.h> int main(int argc, char *argv[]) { const char *host = "tyc"; // 获取服务器信息 struct hostent *hostinfo = gethostbyname(host); assert(hostinfo); // 获取daytime服务信息 struct servent *servinfo = getservbyname("daytime", "tcp"); assert(servinfo); printf("daytime port is %d\n", ntohs(servinfo->s_port)); struct sockaddr_in address; address.sin_family = AF_INET; address.sin_port = servinfo->s_port; address.sin_addr = *(struct in_addr *)*hostinfo->h_addr_list; int sockfd = socket(AF_INET, SOCK_STREAM, 0); int result = connect(sockfd, (struct sockaddr *)&address, sizeof(address)); assert(result != -1); char buffer[128]; result = read(sockfd, buffer, sizeof(buffer)); assert(result > 0); // 设置结束标志 buffer[result] = '\0'; printf("the day tiem is: %s", buffer); close(sockfd); return 0; } -

17.3 getaddrinfo
-
getaddrinfo函数既能通过主机名获得IP地址(内部使用的是gethostbyname函数),也能通过服务名获得端口号(内部使用的是getservbyname函数)。它是否可重入取决于其内部调用的gethostbyname和getservbyname函数是否是它们的可重入版本。该函数的定义如下:
-
1 2#include <netdb.h> int getaddrinfo(const char *hostname, const char *service,const struct addrinfo *hints, struct addrinfo **result); -
hostname参数可以接收主机名,也可以接收字符串表示的IP地址(IPv4采用点分十进制字符串,IPv6则采用十六进制字符串)。
-
service参数可以接收服务名,也可以接收字符串表示的十进制端口号。
-
hints参数是应用程序给 getaddrinfo 的一个提示,以对 getaddrinfo 的输出进行更精确的控制。hints参数可以被设置为NULL,表示允许getaddrinfo反馈任何可用的结果。
-
result参数指向一个链表,该链表用于存储getaddrinfo反馈的结果,一个指向 addrinfo 结构体链表的指针。
-
返回值 0:成功;非0:出错。
-
因此,在调用
getaddrinfo函数之前通常需要对以下6个参数进行以下设置:hostname、service、hints的ai_flags、ai_family、ai_socktype、ai_protocol。 -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23struct addrinfo { int ai_flags; /* Input flags. */ int ai_family; /* Protocol family for socket. */ int ai_socktype; /* Socket type. */ int ai_protocol; /* Protocol for socket. */ socklen_t ai_addrlen; /* Length of socket address. */ struct sockaddr *ai_addr; /* Socket address for socket. */ char *ai_canonname; /* Canonical name for service location */ struct addrinfo *ai_next; /* Pointer to next in list. */ }; struct addrinfo { int ai_flags; int ai_family; /* 地址族 */ int ai_socktype; /* 服务类型,SOCK_SCREAM 或 SOCK_DGRAM */ int ai_protocol; /* 具体的网络协议 */ size_t ai_addrlen; /* socket的地址长度 */ struct sockaddr *ai_addr; /* 指向socket的地址,我认为这个成员是这个函数最大的便利。 */ char *ai_canonname; /* 主机的别名 */ struct addrinfo *ai_next; /* 指向下一个addrinfo的指针 */ }; -

-
更加需要注意的是,getaddrinfo将隐式地分配堆内存(可以通过valgrind等工具查看),因为res指针原本是没有指向一块合法内存的,所以,getaddrinfo调用结束后,我们必须使用如下配对函数来释放这块内存:
-
1 2#include <netdb.h> void freeaddrinfo (struct addrinfo *res) -
示例
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49#include <arpa/inet.h> #include <ctype.h> #include <errno.h> #include <fcntl.h> #include <netdb.h> #include <netinet/in.h> #include <signal.h> #include <stdarg.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <sys/stat.h> #include <sys/types.h> #include <sys/wait.h> #include <time.h> #include <unistd.h> int main() { struct addrinfo *ailist, *aip; struct addrinfo hint; struct sockaddr_in *sinp; const char *hostname = "tyc"; char buf[INET_ADDRSTRLEN]; const char *server = "13"; /* 这是服务端口号 */ const char *addr; int ilRc; hint.ai_family = AF_UNSPEC; /* hint 的限定设置 */ hint.ai_socktype = SOCK_STREAM; /* 这里可是设置 socket type */ hint.ai_flags = AI_PASSIVE; /* flags 的标志很多 。常用的有AI_CANONNAME; */ hint.ai_protocol = 0; /* 设置协议 一般为0,默认 */ hint.ai_addrlen = 0; /* 下面不可以设置,为0,或者为NULL */ hint.ai_canonname = NULL; hint.ai_addr = NULL; hint.ai_next = NULL; ilRc = getaddrinfo(hostname, server, &hint, &ailist); if (ilRc < 0) { printf("str_error = %s\n", gai_strerror(errno)); return 1; } /* 显示获取的信息 */ for (aip = ailist; aip != NULL; aip = aip->ai_next) { sinp = (struct sockaddr_in *)aip->ai_addr; addr = inet_ntop(AF_INET, &sinp->sin_addr, buf, INET_ADDRSTRLEN); printf(" addr = %s, port = %d\n", addr ? addr : "unknow ", ntohs(sinp->sin_port)); } return 0; } -

17.4 getnameinfo
-
函数原型
-
1 2int getnameinfo(const struct sockaddr *sockaddr, socklen_t addrlen, char *host, size_t hostlen, char *serv, size_t servlen, int flags); -

-

-

-
示例
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35#include <arpa/inet.h> #include <netdb.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <sys/types.h> #include <unistd.h> int main(int argc, char *argv[]) { int ret = 0; const char *ip = "192.168.141.128"; char hostname[128] = {0}; char servername[128] = {0}; struct sockaddr_in addr_dst; memset(&addr_dst, 0, sizeof(addr_dst)); addr_dst.sin_family = AF_INET; // 转换为网络字节序的端口号 addr_dst.sin_port = htons(13); // 转换为网络字节序的整数ip inet_pton(AF_INET, ip, &addr_dst.sin_addr); ret = getnameinfo((struct sockaddr *)&addr_dst, sizeof(addr_dst), hostname, sizeof(hostname), servername, sizeof(servername), NI_NAMEREQD); if (ret != 0) { fprintf(stderr, "error in getnameinfo: %s \n", gai_strerror(ret)); } else { printf("hostname : %s \n", hostname); printf("servername : %s \n", servername); } return 0; } -
-
如果输入的socket无法解析的话,会返回错误
-

第6章 Linux高级I/O函数
- Linux提供了很多高级的I/O函数。它们并不像Linux基础I/O函数(比如open和read)那么常用(编写内核模块时一般要实现这些I/O函数),但在特定的条件下这些函数却表现出优秀的性能。这些函数大致分为三类:
- 用于创建文件描述符的函数,包括pipe、dup/dup2 函数。
- 用于读写数据的函数,包括 readv/writev、sendfile、mmap/munmap、splice和tee函数。
- 用于控制I/O行为和属性的函数,包括fcntl函数。
6.1 pipe 系列函数
(1)pipe 函数
-
在Linux中,pipe() 是一个底层系统调用,用于
创建管道(pipe)。管道是用于进程间通信的一种简单机制,通过pipe()函数可以创建一个匿名的、单向的管道,可以在不同的进程之间传递数据。pipe()函数的原型如下: -
1 2#include <unistd.h> //使用函数需导入此头文件 int pipe(int fd[2]); -
pipe函数的参数是一个包含两个int型整数的数组指针。该函数成功时返回0,并将一对打开的文件描述符值填入其参数指向的数组。如果失败,则返回-1并设置errno。总结,fd[2] 这个参数是一个传出参数,因此传递数组就是传的指针。
-
其中
fd[0]为管道读端,fd[1]为管道写端。这两个文件描述符可以像其他文件描述符一样进行读写操作。 -
管道默认是阻塞的:如果管道中没有数据,read阻塞;如果管道满了,write阻塞。
-
通过pipe函数创建的这两个文件描述符fd[0]和fd[1],分别构成管道的两端,往fd[1]写入的数据可以从fd[0]读出。并且,f[0]只能用于从管道读出数据,fd1]则只能用于往管道写入数据,而不能反过来使用。
-
如果要实现双向的数据传输,就应该使用两个管道。默认情况下,这一对文件描述符都是阻塞的。
-
如果管道的写端文件描述符fd[1]的引用计数减少至0,即没有任何进程需要往管道中写入数据,则针对该管道的读端文件描述符fd[0]的read操作将返回0,即读取到了文件结束标记(End Of File,EOF);
-
反之,如果管道的读端文件描述符fd[1]的引用计数减少至0,即没有任何进程需要从管道读取数据,则针对该管道的写端文件描述符fd[1]的write操作将失败,并引发SIGPIPE信号。
-
需要注意,
pipe()函数创建的管道是基于文件描述符的通信机制,只能用于具有亲缘关系(如父子进程、兄弟进程)的进程之间。这是因为管道的读取端和写入端是通过文件描述符进行通信的,而文件描述符是进程特定的。故,pipe也称为匿名管道。 -
管道内部传输的数据是字节流,这和TCP字节流的概念相同。但二者又有细微的区别。应用层程序能往一个TCP连接中写入多少字节的数据,取决于对方的接收通告窗口的大小和本端的拥塞窗口的大小。而管道本身拥有一个容量限制,它规定如果应用程序不将数据从管道读走的话,该管道最多能被写入多少字节的数据。自Linux2.6.11内核起,管道容量的大小默认是65536字节。我们可以使用fcntl函数来修改管道容量。
(2)socketpair 函数
-

-
socketpair函数创建一对相互连接的套接字(sockets)。尽管函数名中包含 "socket",但实际上socketpair创建的是用于进程间通信的套接字对,而不是网络套接字。这对套接字可以用于在同一台机器上的两个进程之间进行通信。 -
1 2 3#include <sys/types.h> #include <sys/socket.h> int socketpair(int domain, int type, int protocol, int fd[2]);-
domain指定套接字的协议族,通常使用AF_UNIX表示在同一台机器上的进程间通信。 -
type指定套接字的类型,通常使用SOCK_STREAM或SOCK_DGRAM。 -
protocol通常为 0,表示使用默认协议。 -
fd[2]是一个数组,用于存储创建的套接字对的文件描述符。
-
-
socketpair创建的套接字对可以用于父子进程之间或任意两个进程之间的通信。这种方式比使用管道 (pipe) 更灵活,因为它提供了双向通信的能力,而且支持面向连接的SOCK_STREAM类型和面向消息的SOCK_DGRAM类型。
(3)pipe 函数实验
-
以下是使用pipe函数的示例
-
- 父进程创建管道,打开
fd[0]、fd[1]分别作为读写端
- 父进程创建管道,打开
-
- 父进程
fork出子进程,子进程继承读写端
- 父进程
-
- 父进程关闭
fd[0],子进程关闭fd[1](或者反着来,按需求)
- 父进程关闭
-
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67/* #include <unistd.h> int pipe(int pipefd[2]); 功能:创建一个匿名管道,用来进程间通信。 参数:int pipefd[2] 这个数组是一个传出参数。 pipefd[0] 对应的是管道的读端 pipefd[1] 对应的是管道的写端 返回值: 成功 0 失败 -1 管道默认是阻塞的:如果管道中没有数据,read阻塞,如果管道满了,write阻塞 注意:匿名管道只能用于具有关系的进程之间的通信(父子进程,兄弟进程) */ // 子进程发送数据给父进程,父进程读取到数据输出 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/types.h> #include <sys/wait.h> #include <unistd.h> int main() { int pipefd[2]; int retPipe = pipe(pipefd); if (retPipe == -1) { perror("pipe"); exit(0); } int pid = fork(); if (pid > 0) { close(pipefd[1]); // 关闭父进程写端 char buf[1024]; ssize_t len = read(pipefd[0], buf, sizeof(buf)); // 读取子进程写入的信息 if (len == -1) { perror("read"); exit(0); } buf[len] = '\0'; // 确保字符串以 null 结尾 printf("我是父进程,我的进程号是:%d,正在接受来自子进程的信息…\n", getpid()); printf("收到的子进程信息为:%s\n", buf); } else if (pid == 0) { close(pipefd[0]); // 关闭子进程读端 char buf[1024]; sprintf(buf, "%s%d", "我是子进程,这是我发送的信息,我的进程号是:", getpid()); ssize_t len = write(pipefd[1], buf, strlen(buf)); // 写入子进程信息 if (len == -1) { perror("write"); exit(0); } } else { perror("fork"); return -1; } wait(NULL); return 0; } -
输出结果如下图
-

6.2 dup 和 dup2 函数
-
有时我们希望把标准输入重定向到一个文件,或者把标准输出重定向到一个网络连接(比如CGI编程)。
-
这可以通过用于复制文件描述符的dup或dup2函数来实现。
-
dup和dup2也是两个非常有用的调用,它们的作用都是用来复制一个文件的描述符。它们经常用来重定向进程的stdin、stdout和stderr。
-
1 2 3#include <unistd.h> int dup(int oldfd); int dup2(int oldfd, int newfd); -
两个系统调用失败时返回-1并设置errno。
-
(1)dup() 系统调用会分配一个全新的、未用过的、值为最小的文件描述符指向dup()函数内的参数oldfd所指向的文件,并返回该值。
-
(2)关于dup2函数
- (a)dup2() 会先看看oldfd是不是一个有效的文件描述符,如果不是则调用失败,newfd文件描述符也不关闭;
- (b)如果newfd等于oldfd,则不关闭该文件并正常返回;
- (c)不属于上面两种情况,则检测newfd是否被使用,如在使用,则将其关闭,并将newfd指向oldfd所指向的文件,并返回newfd。
-
在Linux中,文件描述符前三位0、1、2分别对应: STDIN_FILENO 0 标准输入文件 STDOUT_FILENO 1 标准输出文件(即调用printf函数) STDERR_FILENO 2 标准错误输出文件
-
需要说明的是,进程间的标准输出是相互独立的,一个进程的重定向操作不会影响其他进程的标准输出。每个进程都有自己的文件描述符表和I/O流,包括标准输入、标准输出和标准错误流。重定向操作只对当前进程有效,不会影响其他进程。
6.2.1 简易 CGI 服务器
-
CGI(Common Gateway Interface 公共网关接口)服务器是一种用于执行动态网页的服务器软件。它是一种标准化的协议,定义了Web服务器和脚本程序之间的通信方式。通过CGI服务器,Web服务器可以调用外部脚本程序来生成动态内容,并将结果返回给客户端。
-
以下代码,把printf输出重定向到了socket。服务器输出到标准输出的内容(这里是“abcd”)就会直接发送到与客户连接对应的socket上,因此printf调用的输出将被客户端获得(而不是显示在服务器程序的终端上)。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> int main(int argc, char *argv[]) { if (argc <= 2) { printf("usage: %s ip_address port_number\n", basename(argv[0])); return 1; } const char *ip = argv[1]; int port = atoi(argv[2]); struct sockaddr_in address; bzero(&address, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int sock = socket(PF_INET, SOCK_STREAM, 0); assert(sock >= 0); int ret = bind(sock, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(sock, 5); assert(ret != -1); struct sockaddr_in client; socklen_t client_addrlength = sizeof(client); int connfd = accept(sock, (struct sockaddr *)&client, &client_addrlength); if (connfd < 0) { printf("errno is: %d\n", errno); } else { // 重定向输出为socket close(STDOUT_FILENO); dup2(connfd, 1); printf("abcd\n"); close(connfd); } close(sock); return 0; }
6.2.2 重定向输出
-
实验代码如下
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18#include <fcntl.h> #include <stdio.h> #include <sys/stat.h> #include <sys/types.h> #include <unistd.h> int main() { // 0666 是文件权限 int fd = open("log.txt", O_WRONLY | O_CREAT, 0666); if (fd < 0) { perror("open"); return 1; } close(1); dup2(fd, 1); printf("hello printf\n"); fprintf(stdout, "hello fprintf\n"); return 0; } -
实验结果,创建了 log.txt 文件,内容如下。
-
-
可见确实重定向了标准输出。
6.3 readv 和 writev 函数
-
readv函数将数据从文件描述符读到分散的内存块中,即分散读;writev函数则将多块分散的内存数据一并写人文件描述符中,即集中写。 -
1 2 3#include <sys/uio.h> ssize_t readv(int fd, const struct iovec *iov, int iovcnt); ssize_t writev(int fd, const struct iovec *iov, int iovcnt); -
fd被操作的目标文件描述符。iov是iovec类型的数组。iovcnt是iov数组的长度。iovec结构体封装了一块内存的起始位置和长度,其定义如下(前面说过) -
1 2 3 4struct iovec { /* Scatter/gather array items */ void *iov_base; /* Starting address */ size_t iov_len; /* Number of bytes to transfer */ }; -
readv和writev在成功时返回读出/写入fd的字节数,失败则返回-1并设置errno。 -
readv和writev是个非常有用的函数。比如:当Web服务器解析完一个HTTP请求之后,如果目标文档存在且客户具有读取该文档的权限,那么它就需要发送一个HTTP应答来传输该文档。这个HTTP应答包含1个状态行、多个头部字段、1个空行和文档的内容。其中,前3部分的内容可能被Web服务器放置在一块内存中,而文档的内容则通常被读入到另外一块单独的内存中(通过read函数或mmap函数)。我们并不需要把这两部分内容拼接到一起再发送,而是可以使用writev函数将它们同时写出。
-
使用 writev 的小实验。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21#include <string.h> #include <sys/uio.h> #include <unistd.h> int main(int argc, char const *argv[]) { // const char *str0 = "hello\n"; // const char *str1 = "world\n"; char str0[] = "hello\n"; char str1[] = "world\n"; struct iovec iov[2]; ssize_t nwritten; iov[0].iov_base = str0; iov[0].iov_len = strlen(str0); iov[1].iov_base = str1; iov[1].iov_len = strlen(str1); // 直接标准输出 nwritten = writev(STDOUT_FILENO, iov, 2); return 0; } -

-
这里需要说明一下,C语言的char*不能修改常量字符串,保存常量存储区,因此必须为
const char*。 -
C语言要想修改,只能用
char a[]来初始化常量字符串。 -
以下是第二个示例。使用wirtev来进行web服务器的集中写。忽略Http请求的解析,以下只是应答。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <sys/stat.h> #include <sys/types.h> #include <sys/uio.h> #include <unistd.h> #define BUFFER_SIZE 1024 static const char *status_line[2] = {"200 OK", "500 Internal server error"}; int main(int argc, char *argv[]) { if (argc <= 3) { printf("usage: %s ip_address port_number filename\n", basename(argv[0])); return 1; } const char *ip = argv[1]; int port = atoi(argv[2]); const char *file_name = argv[3]; struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int sock = socket(PF_INET, SOCK_STREAM, 0); assert(sock >= 0); int ret = bind(sock, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(sock, 5); assert(ret != -1); struct sockaddr_in client; socklen_t client_addrlength = sizeof(client); int connfd = accept(sock, (struct sockaddr *)&client, &client_addrlength); if (connfd < 0) { printf("errno is: %d\n", errno); } else { char header_buf[BUFFER_SIZE]; memset(header_buf, '\0', BUFFER_SIZE); char *file_buf; struct stat file_stat; bool valid = true; int len = 0; if (stat(file_name, &file_stat) < 0) { valid = false; } else { if (S_ISDIR(file_stat.st_mode)) { valid = false; } else if (file_stat.st_mode & S_IROTH) { int fd = open(file_name, O_RDONLY); file_buf = new char[file_stat.st_size + 1]; memset(file_buf, '\0', file_stat.st_size + 1); if (read(fd, file_buf, file_stat.st_size) < 0) { valid = false; } } else { valid = false; } } if (valid) { ret = snprintf(header_buf, BUFFER_SIZE - 1, "%s %s\r\n", "HTTP/1.1", status_line[0]); len += ret; ret = snprintf(header_buf + len, BUFFER_SIZE - 1 - len, "Content-Length: %d\r\n", file_stat.st_size); len += ret; ret = snprintf(header_buf + len, BUFFER_SIZE - 1 - len, "%s", "\r\n"); struct iovec iv[2]; iv[0].iov_base = header_buf; iv[0].iov_len = strlen(header_buf); iv[1].iov_base = file_buf; iv[1].iov_len = file_stat.st_size; ret = writev(connfd, iv, 2); } else { ret = snprintf(header_buf, BUFFER_SIZE - 1, "%s %s\r\n", "HTTP/1.1", status_line[1]); len += ret; ret = snprintf(header_buf + len, BUFFER_SIZE - 1 - len, "%s", "\r\n"); send(connfd, header_buf, strlen(header_buf), 0); } close(connfd); delete[] file_buf; } close(sock); return 0; }
6.4 零拷贝 Zero-Copy 技术
-
很多应用程序在面临客户端请求时,可以等价为进行如下的系统调用:
- File.read(file, buf, len);
- Socket.send(socket, buf, len);
例如消息中间件 Kafka 就是这个应用场景,从磁盘中读取一批消息后原封不动地写入网卡(NIC,Network interface controller)进行发送。
-
在没有任何优化技术使用的背景下,操作系统为此会进行 4 次数据拷贝,以及 4 次上下文切换。
-
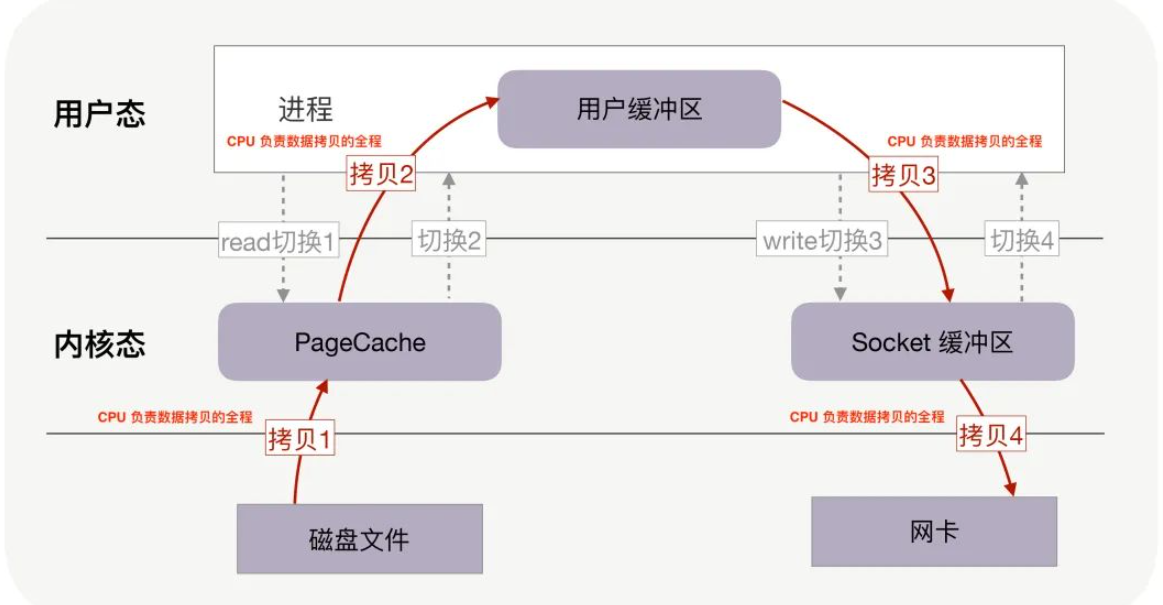
-
4 次 copy:
- CPU 负责将数据从磁盘搬运到内核空间的 Page Cache (页高速缓冲存储器,简称页缓存)中;
- CPU 负责将数据从内核空间的 Page Cache 搬运到用户空间的缓冲区;
- CPU 负责将数据从内核空间的 Page Cache 搬运到用户空间的缓冲区;
- CPU 负责将数据从内核空间的 Socket 缓冲区搬运到网卡送到互联网。
-
4 次上下文切换:
- read 系统调用时:用户态切换到内核态;
- read 系统调用完毕:内核态切换回用户态;
- write 系统调用时:用户态切换到内核态;
- write 系统调用完毕:内核态切换回用户态。
-
我们不免发出抱怨:
- CPU 全程负责内存内的数据拷贝还可以接受,因为效率还算可以接受,但是如果要全程负责内存与磁盘、网络的数据拷贝,这将难以接受,因为磁盘、网卡的速度远小于内存,内存又远远小于 CPU;
- 4 次 copy 太多了,4 次上下文切换也太频繁了。
-
因此有了 DMA 技术。直接存储器访问(Direct Memory Access),简称DMA。DMA用来提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。无须CPU的干预,通过DMA数据可以快速地移动。这就节省了CPU的资源来做其他操作。
-
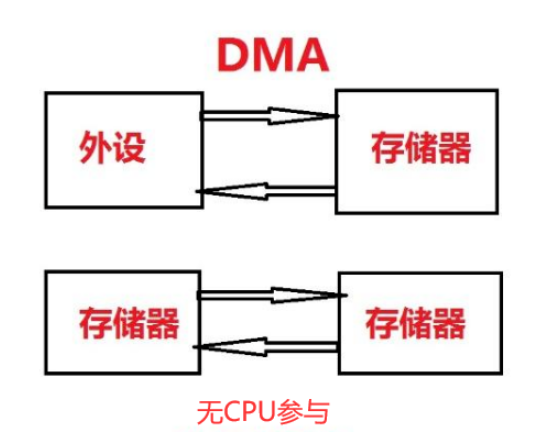
-
本质上,DMA 技术就是我们在主板上放一块独立的芯片。在进行内存和 I/O 设备的数据传输的时候,我们不再通过 CPU 来控制数据传输,而直接通过 DMA 控制器(DMA Controller,简称 DMAC)。这块芯片,我们可以认为它其实就是一个协处理器(Co-Processor)。
-
注意,这里面的“协”字。DMAC 是在“协助”CPU,完成对应的数据传输工作。在 DMAC 控制数据传输的过程中,我们还是需要 CPU 的进行控制,但是具体数据的拷贝不再由 CPU 来完成。
-
原本,计算机所有组件之间的数据拷贝(流动)必须经过 CPU,如下图所示:
-
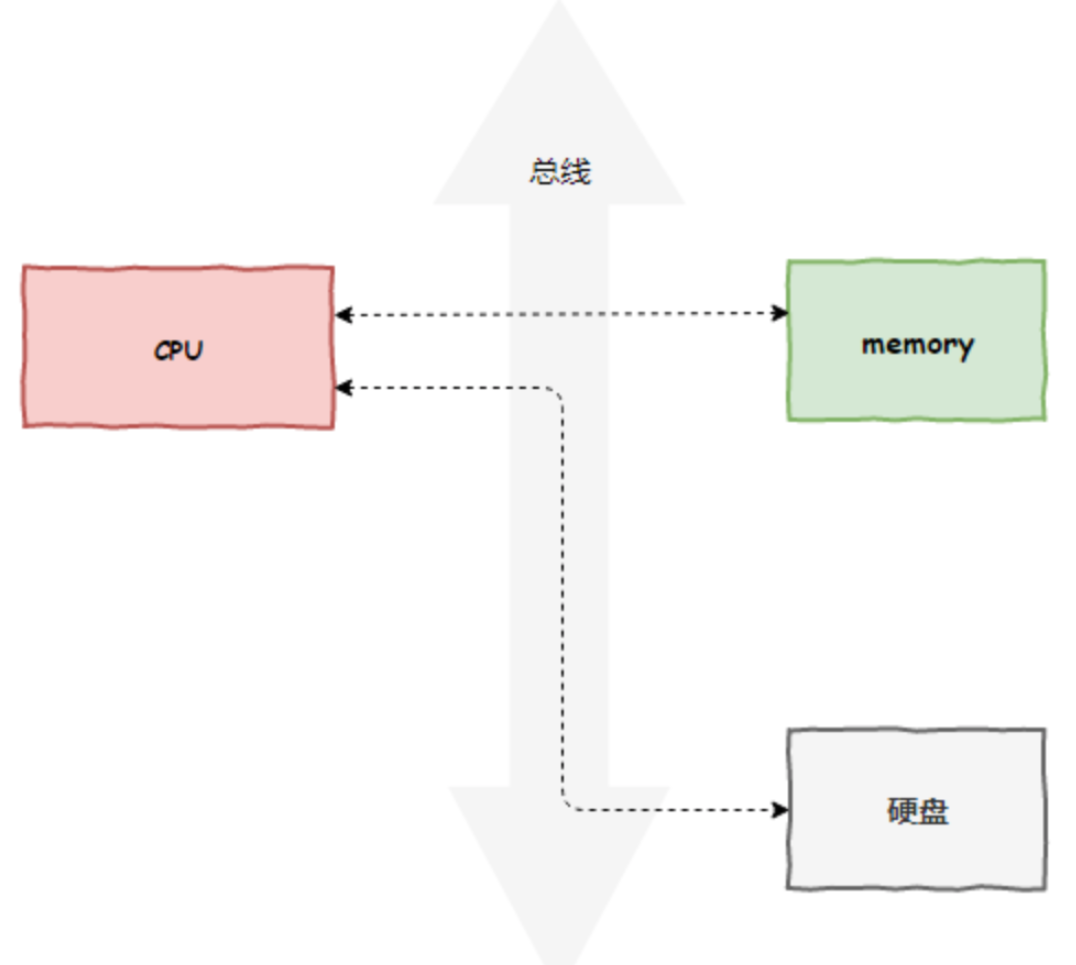
-
现在,DMA 代替了 CPU 负责内存与磁盘以及内存与网卡之间的数据搬运,CPU 作为 DMA 的控制者,如下图所示:
-
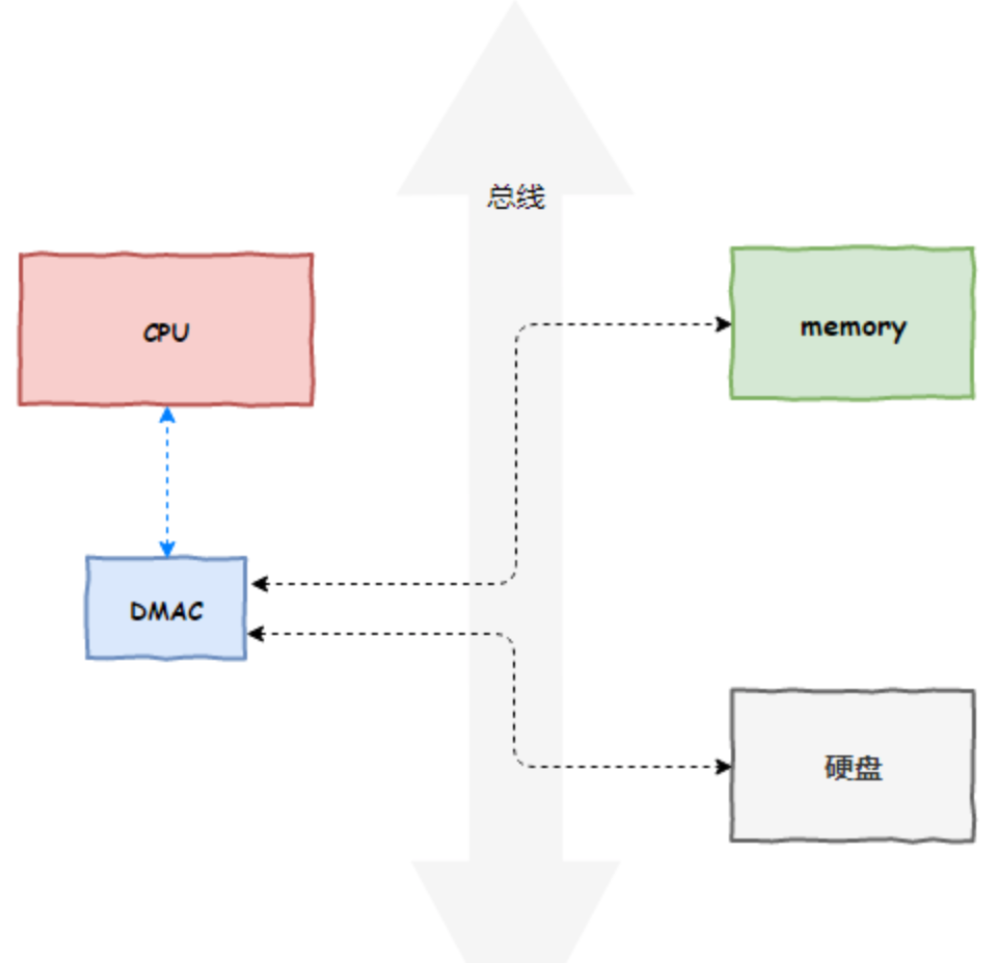
-
但是 DMA 有其局限性,DMA 仅仅能用于IO设备之间交换数据时进行数据拷贝,但是设备内部的数据拷贝还需要 CPU 进行,例如 CPU 需要负责内核空间数据与用户空间数据之间的拷贝(内存本身内部的拷贝),如下图所示。
-
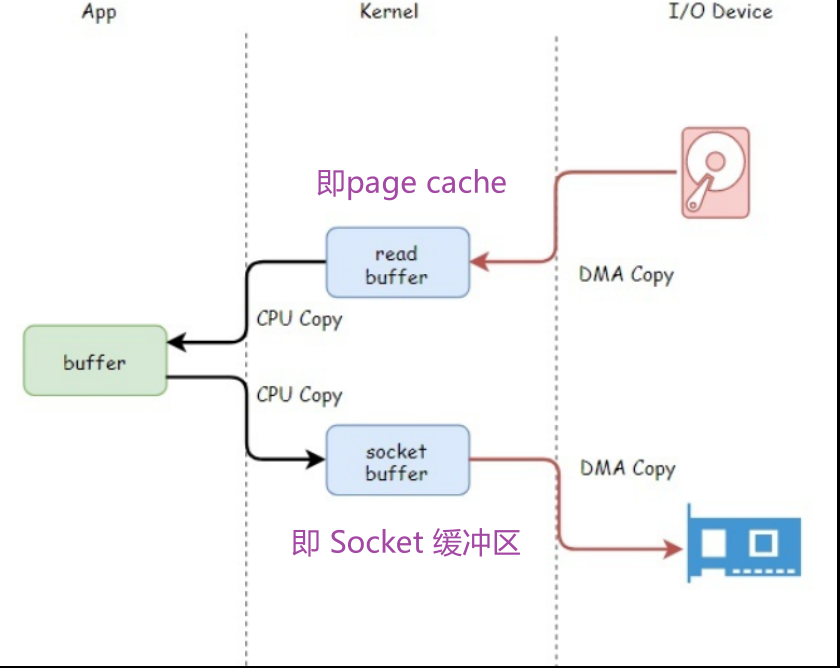
-
即使有了DMA,整个IO的过程仍然需要进行两次DMA拷贝,两次CPU拷贝,四次上下文切换。总共四次拷贝,四次切换。代价还是很大的。
-
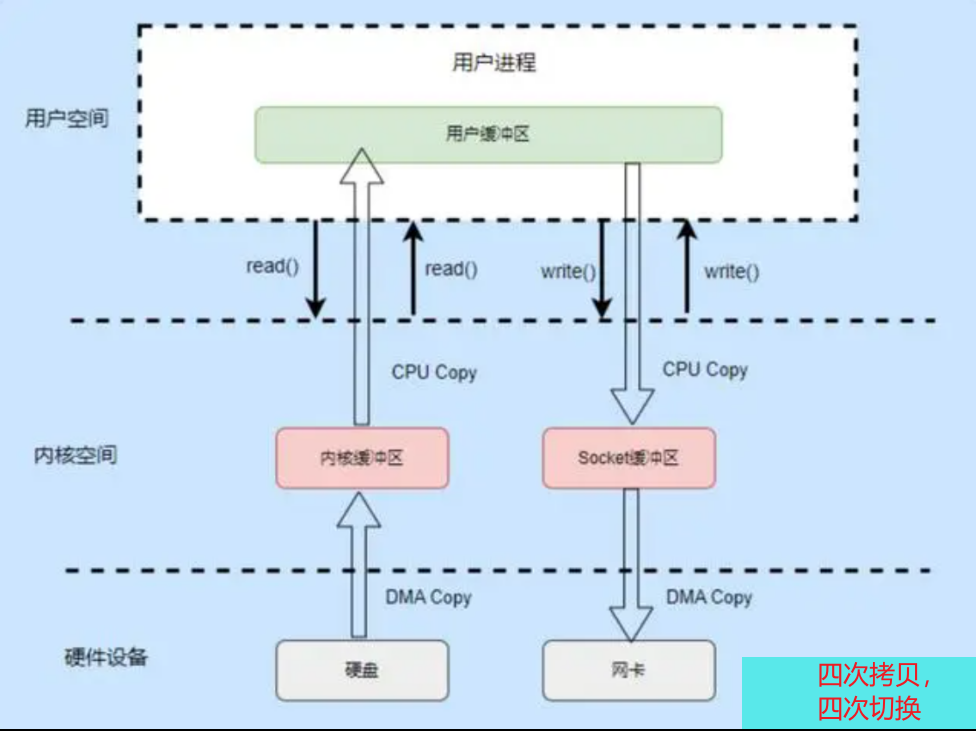
-
因此,又产生了零拷贝技术(zero copy)。
-
零拷贝这个词,在很多地方都出现过,比如Kafka、Nginx、Tomcat等等这些技术的底层都有用到零拷贝技术,那么究竟什么是零拷贝呢?零拷贝技术是一个思想,指的是指计算机执行操作时,CPU 不需要先将数据从某处内存复制到另一个特定区域。可见,零拷贝的特点是 CPU 不全程负责内存中的数据写入其他组件,CPU 仅仅起到管理的作用。但注意,零拷贝不是不进行拷贝,而是 CPU 不再全程负责数据拷贝时的搬运工作。
-
零拷贝技术的具体实现方式有很多,例如:
- sendfile
- mmap
- splice
- 直接 Direct I/O
- tee
(1)sendfile
-
snedfile 的应用场景是:用户从磁盘读取一些文件数据后不需要经过任何计算与处理就通过网络传输出去。此场景的典型应用是消息队列。在传统 I/O 下,上述应用场景的一次数据传输需要四次 CPU 全权负责的拷贝与四次上下文切换。
-
sendfile 主要使用到了两个技术:
- DMA 技术;
- 传递文件描述符代替数据拷贝。
-
①sendfile 依赖于 DMA 技术,将四次 CPU 全程负责的拷贝与四次上下文切换减少到两次,如下图所示:
-
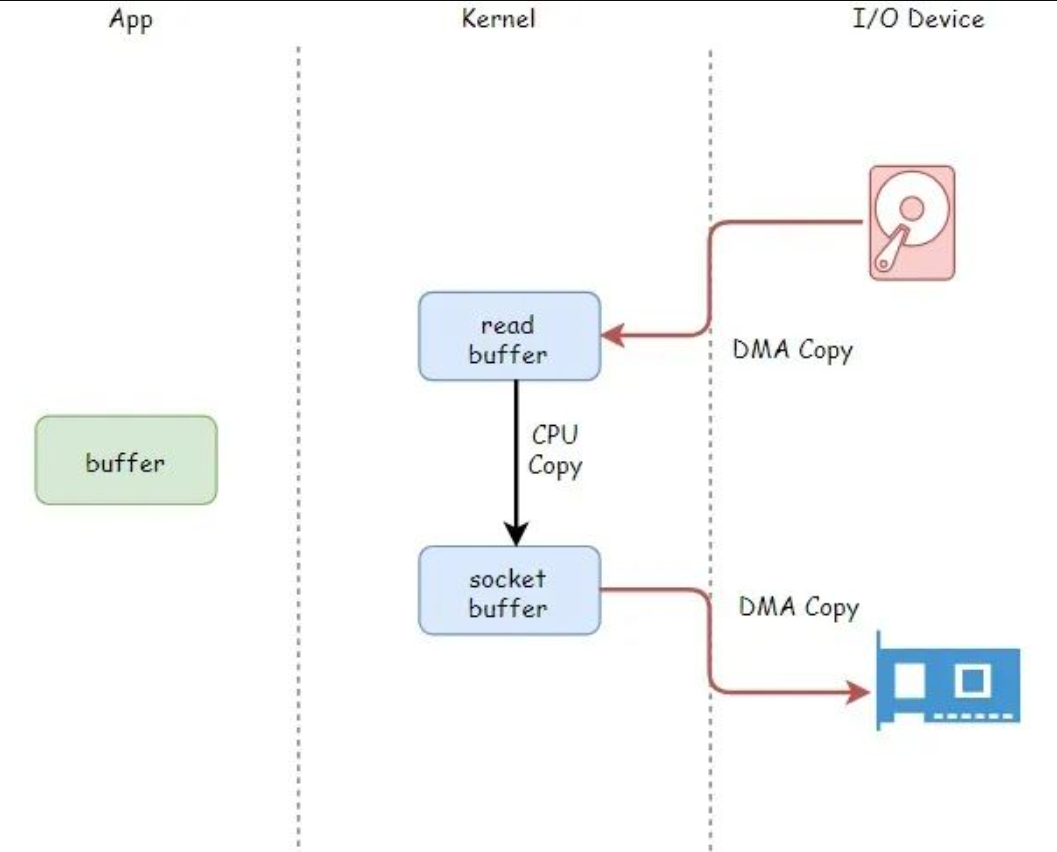
-
DMA 负责磁盘到内核空间中的 Page cache(read buffer)的数据拷贝以及从内核空间中的 socket buffer 到网卡的数据拷贝。
-
② sendfile 利用传递文件描述符代替数据拷贝
-
传递文件描述可以代替数据拷贝,这是由于两个原因:
- page cache 以及 socket buffer 都在内核空间中;
- 数据传输过程前后没有任何写操作。
-
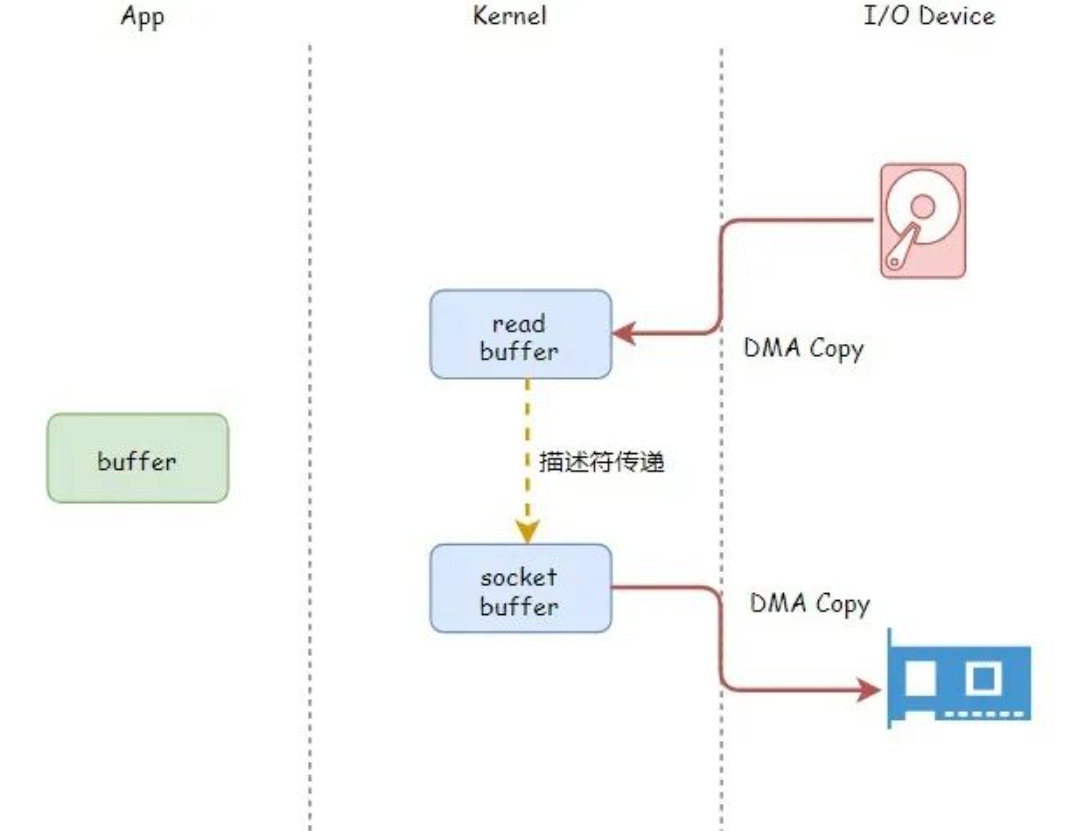
-
注意事项:只有网卡支持 SG-DMA(The Scatter-Gather Direct Memory Access)技术才可以通过传递文件描述符的方式避免内核空间内的一次 CPU 拷贝。这意味着此优化取决于 Linux 系统的物理网卡是否支持(Linux 在内核 2.4 版本里引入了 DMA 的 scatter/gather -- 分散/收集功能,只要确保 Linux 版本高于 2.4 且网卡支持 SG-DMA 功能即可)。
-
③总结
-
(1)在支持网卡支持 SG-DMA 技术的情况下(Linux大于2.4),sendfile的整个过程会发生 2 次上下文切换、0 次 CPU 拷贝以及 2 次 DMA 拷贝。
-
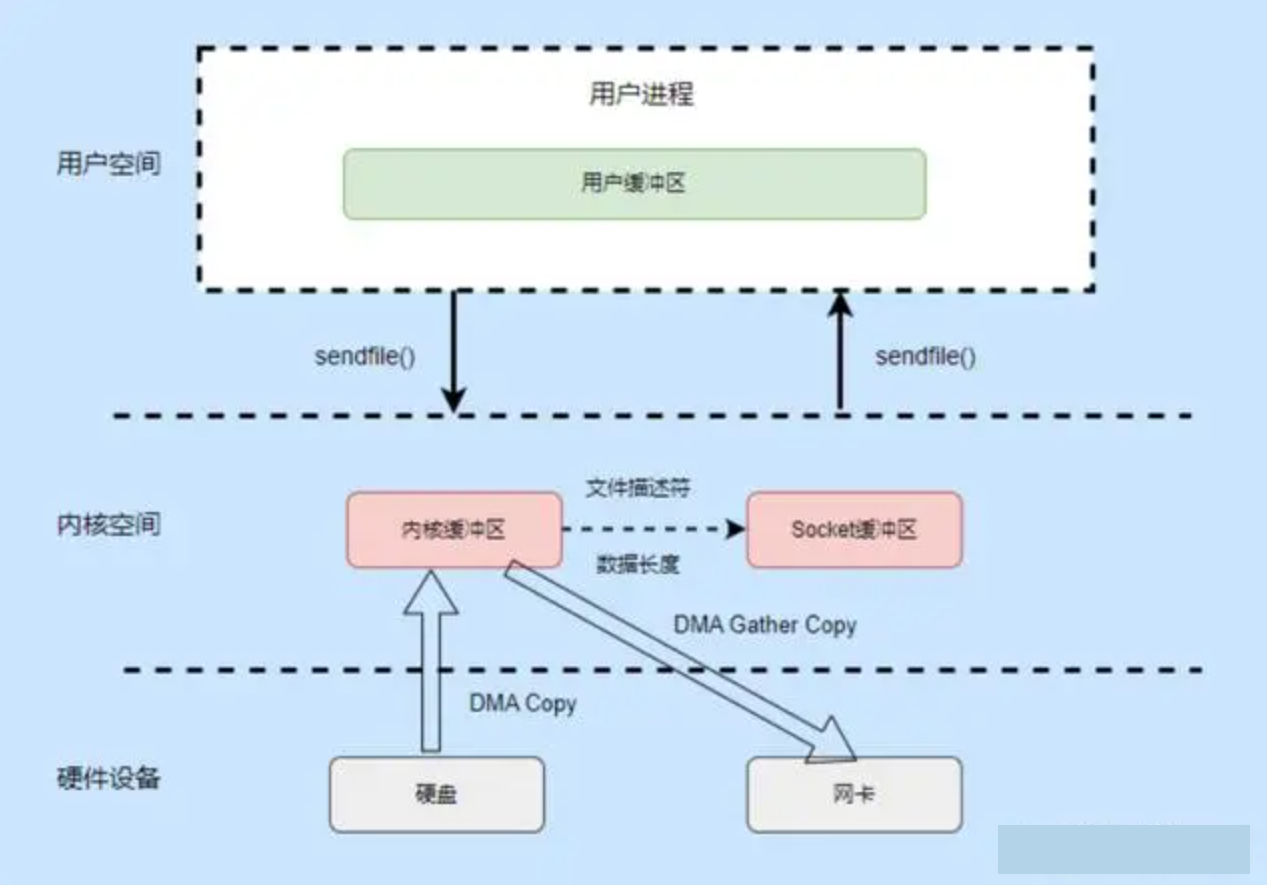
-
(2)在支持网卡不支持 SG-DMA 技术的情况下,,sendfile的整个过程会发生 2 次上下文切换、1次 CPU 拷贝以及 2 次 DMA 拷贝。
-
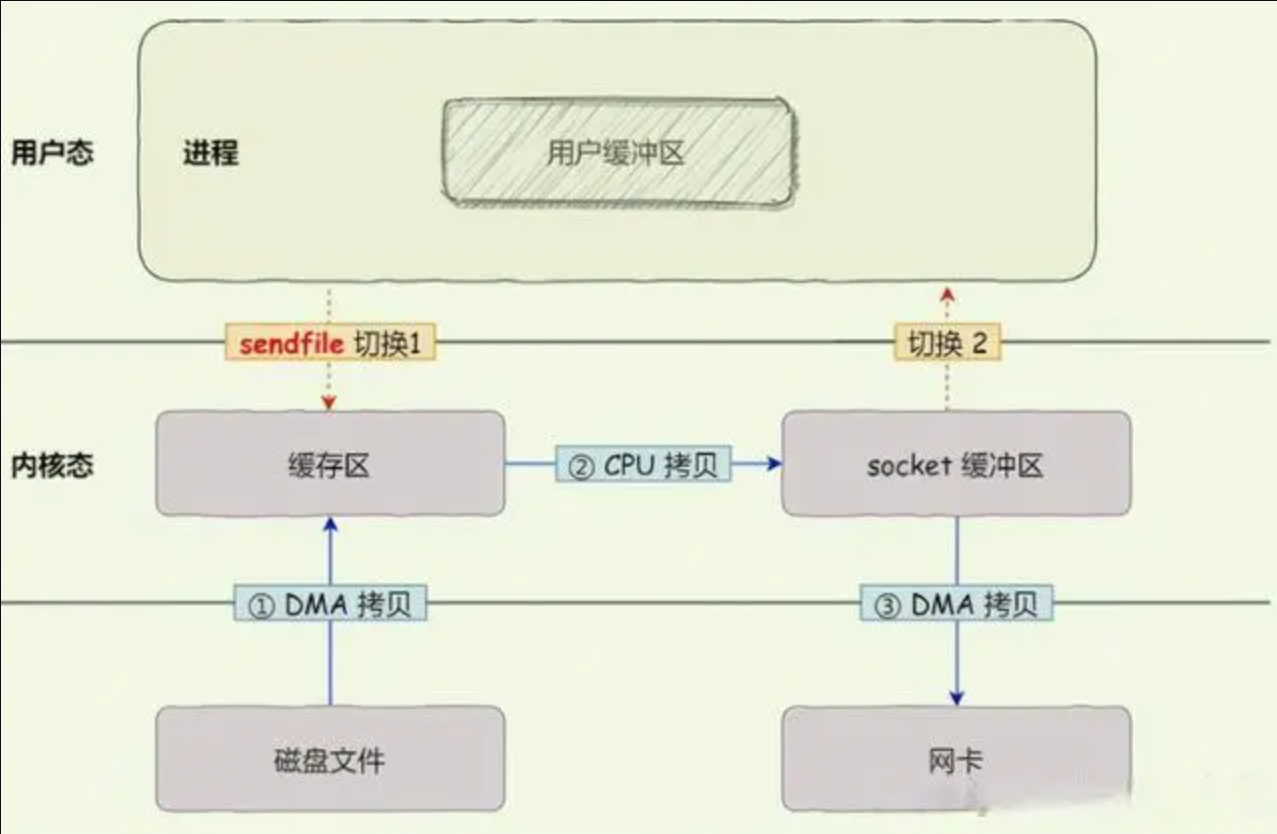
(2)mmap
-
mmap 即 memory map,也就是内存映射。
-
mmap 是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用 read、write 等系统调用函数。同时,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。如下图所示:
-

-
mmap的作用,是让你把文件的某一段,当作内存一样来访问。将文件映射到物理内存,将进程虚拟空间映射到那块内存。这样,进程不仅能像访问内存一样读写文件,多个进程映射同一文件,还能保证虚拟空间映射到同一块物理内存,达到文件共享的作用。
-
mmap 内存映射实现过程,总的来说可以分为三个阶段:
(一)进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域
1、进程在用户空间调用函数mmap ,原型:void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
2、在当前进程虚拟地址空间中,寻找一段空闲的满足要求的连续的虚拟地址
3、为此虚拟区分配一个vm_area_struct 结构,接着对这个结构各个区域进行初始化
4、将新建的虚拟区结构(vm_area_struct)插入进程的虚拟地址区域链表或树中
(二)调用内核空间的系统调用函数mmap (不同于用户空间函数),实现文件物理地址和进程虚拟地址的一一映射关系
5、为映射分配新的虚拟地址区域后,通过待映射的文件指针,在文件描述符表中找到对应的文件描述符,通过文件描述符,链接到内核“已打开文集”中该文件结构体,每个文件结构体维护者和这个已经打开文件相关各项信息。
6、通过该文件的文件结构体,链接到file_operations模块,调用内核函数mmap,其原型为:int mmap(struct file *filp, struct vm_area_struct *vma),不同于用户空间库函数。
7、内核mmap函数通过虚拟文件系统inode模块定位到文件磁盘物理地址。
8、通过remap_pfn_range函数建立页表,即实现了文件地址和虚拟地址区域的映射关系。此时,这片虚拟地址并没有任何数据关联到主存中。
(三)进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内存(主存)的拷贝。
前两个阶段仅在于创建虚拟区间并完成地址映射,但是并没有将任何文件数据拷贝至主存。真正的文件读取是当进程发起读或者写操作时。
9、进程的读写操作访问虚拟地址空间这一段映射地址后,通过查询页表,先这一段地址并不在物理页面。因为目前只建立了映射,真正的硬盘数据还没有拷贝到内存中,因此引发缺页异常。
10、缺页异常进行一系列判断,确定无法操作后,内核发起请求掉页过程。
11、调页过程先在交换缓存空间中寻找需要访问的内存页,,如果没有则调用nopage函数把所缺的页从磁盘装入到主存中。
12、之后进程即可对这片主存进行读或者写的操作了,如果写操作改变了内容,一定时间后系统自动回写脏页面到对应的磁盘地址,也即完成了写入到文件的过程。
注:修改过的脏页面并不会立即更新回文件,而是有一段时间延迟,可以调用msync() 来强制同步,这样所写的内容就能立即保存到文件里了。
-
mmap() 函数需要配合 write() 系统调用进行配合操作,这与 sendfile() 函数有所不同,后者一次性代替了 read() 以及 write();因此 mmap 也至少需要 4 次上下文切换;
-
利用
mmap()替换read(),配合write()调用的整个流程如下:- 用户进程调用
mmap(),从用户态陷入内核态,将内核缓冲区映射到用户缓存区; - DMA 控制器将数据从硬盘拷贝到内核缓冲区(可见其使用了 Page Cache 机制);
mmap()返回,上下文从内核态切换回用户态;- 用户进程调用
write(),尝试把文件数据写到内核里的套接字缓冲区,再次陷入内核态; - CPU 将内核缓冲区中的数据拷贝到的套接字缓冲区;
- DMA 控制器将数据从套接字缓冲区拷贝到网卡完成数据传输;
write()返回,上下文从内核态切换回用户态。
- 用户进程调用
-

-
整个拷贝过程会发生 4 次上下文切换,1 次 CPU 拷贝和 2 次 DMA 拷贝。可见 mmap + write 的主要用处是提高 I/O 性能,特别是针对大文件。对于小文件,内存映射文件反而会导致碎片空间的浪费。
(3)splice
- splice 相当于在 sendfile+DMA gather copy 上的提升,splice 系统调用可以在内核空间的读缓冲区(read buffer)和网络缓冲区(socket buffer)之间建立管道(pipeline),从而避免了两者之间的 CPU 拷贝操作。
- Linux 在 2.6.17 版本引入 splice 系统调用,不再需要SG-DMA硬件支持,即可实现了两个文件描述符之间的数据零拷贝。
- splice 系统调用可以在内核空间的读缓冲区(read buffer)和网络缓冲区(socket buffer)之间建立管道(pipeline),从而避免了用户缓冲区和Socket缓冲区的 CPU 拷贝操作。
- splice的具体过程如下:
-
- 用户进程通过 splice() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
-
- CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
-
- CPU 在内核空间的读缓冲区(read buffer)和网络缓冲区(socket buffer)之间建立管道(pipeline)。
-
- CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
-
- 上下文从内核态(kernel space)切换回用户态(user space),splice 系统调用执行返回。
-
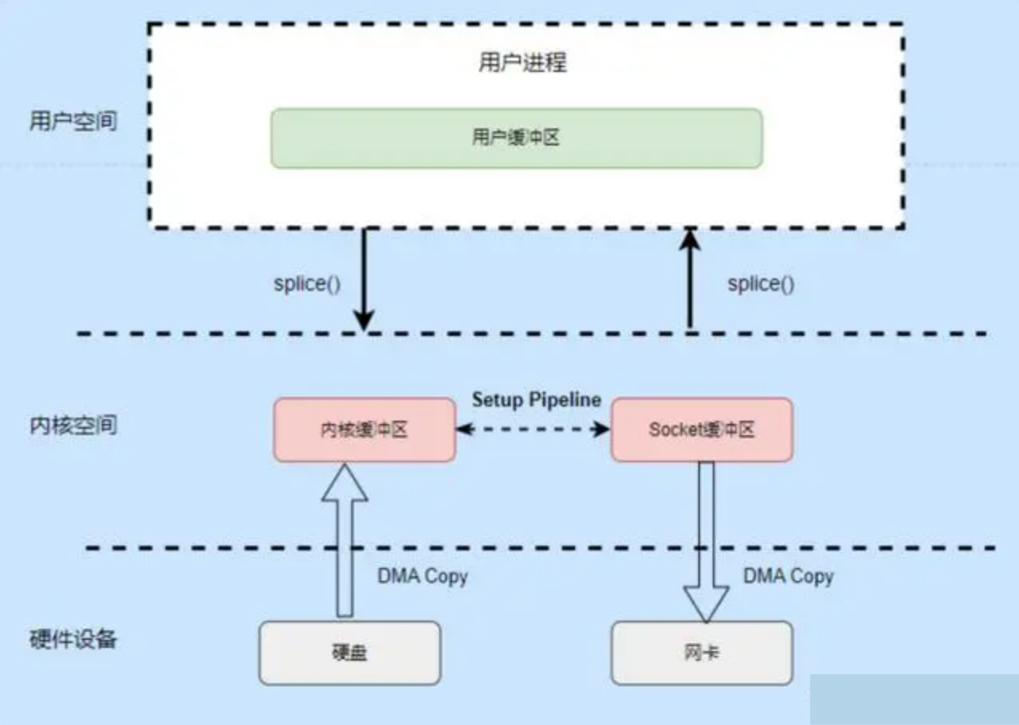
- 基于 splice 系统调用的零拷贝方式,整个拷贝过程会发生 2 次上下文切换,0 次 CPU 拷贝以及 2 次 DMA 拷贝。
(4)直接 Direct I/O
-
Direct I/O 即直接 I/O。其名字中的“直接”二字用于区分使用 page cache 机制的缓存 I/O。
- 缓存文件 I/O:用户空间要读写一个文件并不直接与磁盘交互,而是中间夹了一层缓存,即 page cache;
- 直接文件 I/O:用户空间读取的文件直接与磁盘交互,没有中间 page cache 层。
-
“直接”在这里还有另一层语义:其他所有技术中,数据至少需要在内核空间存储一份,但是在 Direct I/O 技术中,数据直接存储在用户空间中,绕过了内核。
-
Direct I/O 模式如下图所示:
-
-
此时用户空间直接通过 DMA 的方式与磁盘以及网卡进行数据拷贝。
-
不使用 page cache 的 Direct I/O:读写操作直接在磁盘上进行,不使用 page cache 机制,通常结合用户空间的用户缓存使用。通过 DMA 技术直接与磁盘/网卡进行数据交互,实现了 zero copy。
-
Direct I/O 的优缺点:
优点:
- Linux 中的直接 I/O 技术省略掉缓存 I/O 技术中操作系统内核缓冲区的使用,数据直接在应用程序地址空间和磁盘之间进行传输,从而使得自缓存应用程序可以省略掉复杂的系统级别的缓存结构,而执行程序自己定义的数据读写管理,从而降低系统级别的管理对应用程序访问数据的影响。
- 与其他零拷贝技术一样,避免了内核空间到用户空间的数据拷贝,如果要传输的数据量很大,使用直接 I/O 的方式进行数据传输,而不需要操作系统内核地址空间拷贝数据操作的参与,这将会大大提高性能。
缺点:
- 由于设备之间的数据传输是通过 DMA 完成的,因此用户空间的数据缓冲区内存页必须进行 page pinning(页锁定),这是为了防止其物理页框地址被交换到磁盘或者被移动到新的地址而导致 DMA 去拷贝数据的时候在指定的地址找不到内存页从而引发缺页错误,而页锁定的开销并不比 CPU 拷贝小,所以为了避免频繁的页锁定系统调用,应用程序必须分配和注册一个持久的内存池,用于数据缓冲。
- 如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘进行加载,这种直接加载会非常缓慢。
- 在应用层引入直接 I/O 需要应用层自己管理,这带来了额外的系统复杂性。
-
自缓存应用程序( self-caching applications)可以选择使用 Direct I/O。
-
对于某些应用程序来说,它会有它自己的数据缓存机制,比如,它会将数据缓存在应用程序地址空间,这类应用程序完全不需要使用操作系统内核中的高速缓冲存储器,这类应用程序就被称作是自缓存应用程序( self-caching applications )。例如,应用内部维护一个缓存空间,当有读操作时,首先读取应用层的缓存数据,如果没有,那么就通过 Direct I/O 直接通过磁盘 I/O 来读取数据。缓存仍然在应用,只不过应用觉得自己实现一个缓存比操作系统的缓存更高效。
-
数据库管理系统是自缓存应用程序的一个代表。
6.5 sendfile 函数
-
需要注意的是,sendfile是一个专门为在网络上传输文件而设计的函数。
-
sendfile函数在两个文件描述符之间直接传递数据(完全在内核中操作),从而避免了内核缓冲区和用户缓冲区之间的数据拷贝,效率很高,这被称为零拷贝,sendfile函数的定义如下:
-
1 2#include <sys/sendfile.h> ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count) -
out_fd:待写入文件描述符;
in_fd: 待读出文件描述符;
offset:从读入文件流的哪个位置开始读,如果为空NULL,则默认从起始位置开始;
count:指定在文件描述符in_fd 和out_fd之间传输的字节数;
返回值:成功时,返回出传输的字节数,失败返回-1, 并设置errno。
-
注意: in_fd必须指向真实的文件,不能是socket和管道;而out_fd则必须是一个socket。
-
使用sendfile发送文件示例代码如下
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/sendfile.h> #include <sys/socket.h> #include <sys/stat.h> #include <sys/types.h> #include <unistd.h> int main(int argc, char *argv[]) { // if (argc <= 3) { // printf("usage: %s ip_address port_number filename\n", // basename(argv[0])); // return 1; // } const char *ip = "192.168.141.128"; int port = 12345; const char *file_name = "log.txt"; int filefd = open(file_name, O_RDONLY); assert(filefd > 0); // 根据fd获取文件的属性,st_size为文件的字节大小 struct stat stat_buf; fstat(filefd, &stat_buf); struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int sock = socket(PF_INET, SOCK_STREAM, 0); assert(sock >= 0); int ret = bind(sock, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(sock, 5); assert(ret != -1); struct sockaddr_in client; socklen_t client_addrlength = sizeof(client); int connfd = accept(sock, (struct sockaddr *)&client, &client_addrlength); if (connfd < 0) { printf("errno is: %d\n", errno); } else { sendfile(connfd, filefd, NULL, stat_buf.st_size); close(connfd); } close(sock); return 0; } -
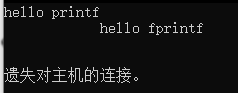
-
如上代码没有为目标文件分配任何用户空间的缓存,也没有执行读取文件的操作,但同样实现了文件的发送,其效率显然要高得多。
6.6 mmap 和 munmap 函数
6.6.1 内存映射
-
内存映射(memory map)简称mmap,是直接将实际存储的物理地址映射到进程空间,而不使用read/write函数。这样,可以省去中间繁杂调用过程, 快速对文件进行大量输入输出。
-
mmap() 用于申请一段内存空间,将一个文件或Posix共享内存区对象映射到进程的地址空间;munmap() 释放由mmap创建的这段内存空间。二者是实现存储映射的关键。 注意:用mmap时,open()不可省,read()/write()可省。
-
根据内存背后有无实体文件与之关联,映射可以分为两种:
- 文件映射:内存映射区域有实体文件与之关联。mmap系统调用将普通文件的一部分内容直接映射到进程的虚拟地址空间。一旦完成映射,就可以通过在相应的内存区域中操作字节来访问文件内容。这种映射也称为基于文件的映射。
- 匿名映射:匿名映射没有对应的文件。这种映射的内存区域会被初始化成0。
-
可以看到,调用mmap,会申请一段内存空间(文件的内存映射部分),并且这段内存会自动映射到指定的文件内存映射部分。返回的是这段内存的起始地址,对应文件的内存映射部分offset处。
-
一个进程映射的内存可以与其他进程中的映射共享物理内存。所谓共享是指各个进程的页表条目指向RAM中的相同分页。以下是两个进程内存共享映射的示意图。
-
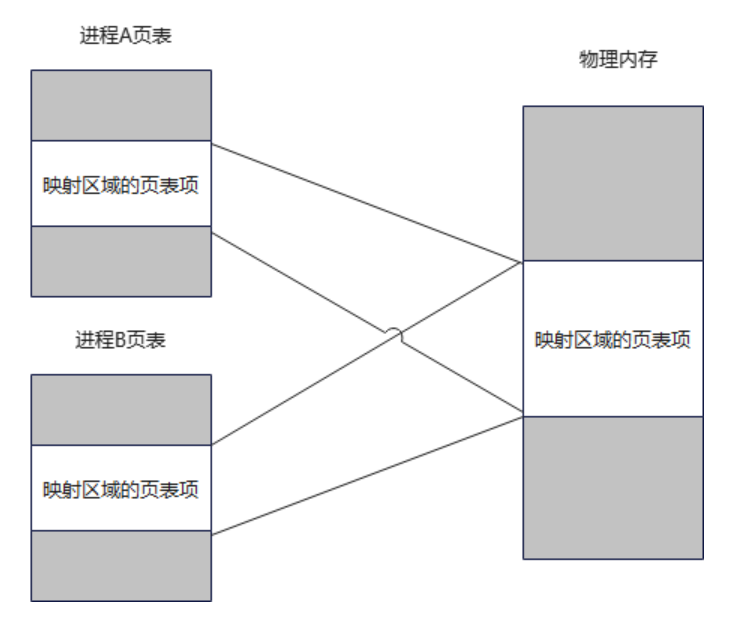
-
这种进程间的内存映射的共享,通常发生在两种情况; 1)通过fork,子进程继承父进程通过mmap映射的副本; 2)多个进程通过mmap映射同一个文件的同一个区域;
-
根据映射是否在进程间共享,分成私有和共享
- 私有映射(MAP_PRIVATE) 映射内容上发生的变更对其他进程不可见,也就是说堆映射内容的改变是私有的。对文件映射,变更不会同步到底层文件。内核用写时复制技术完成这个任务。
- 共享映射(MAP_SHARED) 在映射内容上发生的所有变更,对所有共享同一个映射的其他进程都可见。对文件映射,变更会同步到底层文件。共享映射用于进程间通信。
-
因此,内存映射根据有无文件关联和是否在进程间共享,可产生以下4种情形:
-
文件 匿名 共享 内存映射IO,进程间共享内存 进程间共享内存 私有 根据文件内存初始化内存 内存分配 -

6.6.2 函数详解
-
函数声明如下
-
1 2 3 4#include <sys/mman.h> void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset); int munmap(void *start, size_t length); -
参数
- start 允许用户使用某个特定的地址作为这段内存的起始地址。如果被设为NULL,则系统自动分配一个地址。
- length 指定内存段的长度。
- prot 用来设置内存段的访问权限(注意是prot不是port)。可取以下四个值的按位或: 1)PROT_READ,内存段可读; 2)PROT_WRITE,内存段可写; 3)PROT_EXEC,内存段可执行; 4)PROT_NONE,内存段不能被访问。
- flags 控制内存段内容被修改后程序的行为。可以被设置为以下值的按位或(列举几个常用值): 1)MAP_SHARED 进程间共享这段内存,对该内存段的修改将反映到被映射的文件中。提供了进程间共享内存的POSIX方法。 2)MAP_PRIVATE 内存段为调用进程所私有。对该内存段的修改不会反映到被映射的文件中。 3)MAP_ANONYMOUS 这段内存不是从文件映射而来的。其内容被初始化为全0。这种情况下,mmap函数的最后2个参数将被忽略。 4)MAP_FIXED 内存段必须位于start参数指定的地址处。start必须是内存页面大小(4096byte)的整数倍。 5)MAP_HUGETLB 按照“大内存页面”来分配内存空间。“大内存页面”的大小可通过/proc/meminfo 文件来查看。
- fd 被映射文件对应的文件描述符。一般通过open系统调用获得。
- offset 设置从文件的何处开始映射,对于不需要读入整个文件的情况时,需要设置。
-
返回值
mmap成功返回指向目标内存区域的指针;失败,返回MAP_FAILED ((void*)-1),并设置errno。 munmap成功返回0;失败返回-1,并设置errno
-

6.7 splice 函数
-
splice用于在两个文件描述符之间移动数据, 也是零拷贝。
-
1 2#include <fcntl.h> ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags); -
fd_in参数是待输入描述符。
- 如果fd_in是一个管道文件描述符,则off_in必须设置为NULL;
- 如果fd_in不是一个管道文件描述符(比如socket),则off_in表示从输入数据流的何处开始读取;此时若为NULL,则从输入数据流的当前偏移位置读入。
-
fd_out/off_out与上述相同,不过是用于输出。
-
len参数指定移动数据的长度。
-
flags参数则控制数据如何移动:
- 1)SPLICE_F_MOVE 如果合适的话,按整页内存移动数据。只是给内核的一个提示。不过,因为它的实现存在BUG,所以自内核2.6.21后,实际上没有任何效果。
- 2)SPLICE_F_NONBLOCK 非阻塞的splice操作,实际效果还会受文件描述符本身的阻塞状态的影响。
- 3)SPLICE_F_MORE 给内核的一个提示:后续splice调用将读取更多数据。
- 4)SPLICE_F_GIFT 对splice没有效果。
-

-
使用splice时,fd_in和fd_out必须至少有一个是管道文件描述符。
-
调用成功,返回移动字节的数量。可能是0,表示没有数据需要移动,发生在从管道中读取数据(fd_in是管道文件描述符),而该管道没有被写入任何数据时。
-
调用失败返回-1,errno被设置。常见errno: 1)EBADF 参数所指文件描述符有错; 2)EINVAL 目标文件系统不支持splice,或者目标文件以追加方式打开,或两个文件描述符都不说管道文件描述符,或者某个offset参数被用于不支持随机访问的设备(如字符设备,终端设备); 3)ENOMEM 内存不够; 4)EPIPE 参数fd_in(或fd_out)是管道文件描述符,而off_in(或off_out)不为NULL。
-

-
这里注意的是,sendfile只能用于发送数据,但是splice既能发送也能接收数据。
-
以下是使用splice函数实现一个零拷贝的服务器,将客户端发送数据原样返回给客户端。
-
值得注意的是,以下代码的整个过程都没执行 recv/send 操作,因此也未涉及用户空间和内核空间之间的数据拷贝。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> int main(int argc, char *argv[]) { // if (argc <= 2) { // printf("usage: %s ip_address port_number\n", basename(argv[0])); // return 1; // } const char *ip = "192.168.141.128"; int port = 12345; struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int sock = socket(PF_INET, SOCK_STREAM, 0); assert(sock >= 0); int ret = bind(sock, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(sock, 5); assert(ret != -1); struct sockaddr_in client; socklen_t client_addrlength = sizeof(client); int connfd = accept(sock, (struct sockaddr *)&client, &client_addrlength); if (connfd < 0) { printf("errno is: %d\n", errno); } else { int pipefd[2]; assert(ret != -1); ret = pipe(pipefd); // 接收数据,写入管道的写端 ret = splice(connfd, NULL, pipefd[1], NULL, 32768, SPLICE_F_MORE | SPLICE_F_MOVE); assert(ret != -1); // 发送同样的数据,利用管道的读端 ret = splice(pipefd[0], NULL, connfd, NULL, 32768, SPLICE_F_MORE | SPLICE_F_MOVE); assert(ret != -1); close(connfd); } close(sock); return 0; }
6.8 tee 函数
-
tee函数在两个管道文件描述符之间复制数据,也是零拷贝,直接复制数据,不消耗数据,因此源文件描述符上的数据仍然可以用于后续的读操作。
-
函数原型如下
-
1 2#include<fcntl.h> ssize_t tee(int fd_in,int fd_out,size_t len,unsigned int flags) -
fd_in_ : 待读出内容的管道描述符;
fd_out : 待写入内容的管道描述符;
len : 需要复制的字节数;
flags : 选项,和splice的flags的意义。
-
返回值:
成功:返回在两个文件描述符之间复制的字节数;没有数据返回0;
失败:返回-1并设置errno
-
需要注意的是,fd_in 和 fd_out 都必须是管道文件描述符。
-
以下程序,利用tee和splice函数,实现了Linux下根据终端输入,同时输出数据到终端和文件的功能。最终输入的字符串,和输出的字符串,以及test.txt里面的字符串是一样的。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49#include <assert.h> #include <errno.h> #include <fcntl.h> #include <stdio.h> #include <string.h> #include <unistd.h> int main(int argc, char *argv[]) { // if (argc != 2) { // printf("usage: %s <file>\n", argv[0]); // return 1; // } int filefd = open("test.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666); assert(filefd > 0); int pipefd_stdout[2]; int ret = pipe(pipefd_stdout); assert(ret != -1); int pipefd_file[2]; ret = pipe(pipefd_file); assert(ret != -1); /*将标准输入内容输入管道pipefd_stdout的写*/ ret = splice(STDIN_FILENO, NULL, pipefd_stdout[1], NULL, 32768, SPLICE_F_MORE | SPLICE_F_MOVE); assert(ret != -1); /*管道pipefd_stdout的读复制到管道pipefd_file的写*/ ret = tee(pipefd_stdout[0], pipefd_file[1], 32768, SPLICE_F_NONBLOCK); assert(ret != -1); /*管道pipefd_file的读写入文件*/ ret = splice(pipefd_file[0], NULL, filefd, NULL, 32768, SPLICE_F_MORE | SPLICE_F_MOVE); assert(ret != -1); /*管道pipefd_stdout的读标准输出*/ ret = splice(pipefd_stdout[0], NULL, STDOUT_FILENO, NULL, 32768, SPLICE_F_MORE | SPLICE_F_MOVE); assert(ret != -1); close(filefd); close(pipefd_stdout[0]); close(pipefd_stdout[1]); close(pipefd_file[0]); close(pipefd_file[1]); return 0; }
6.9 fcntl 函数
-
fcntl函数,正如其名字(file control)描述的那样,提供了对文件描述符的各种控制操作。另外一个常见的控制文件描述符属性和行为的系统调用是ioctl,而且ioctl比fcntl能够执行更多的控制。但是,对于控制文件描述符常用的属性和行为,fcntl函数是由POSIX规范指定的首选方法。
-
函数原型
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21#include <unistd.h> #include <fcntl.h> int fcntl(int fd,int cmd, ...); /* 参数: fd : 表示需要操作的文件描述符 cmd: 表示对文件描述符进行如何操作(一些系统定义宏值) - F_DUPFD : 复制文件描述符,复制的是第一个参数fd,得到一个新的文件描述符(返回值) int ret = fcntl(fd, F_DUPFD); - F_GETFL : 获取指定的文件描述符文件状态flag 获取的flag和我们通过open函数传递的flag是一个东西。 - F_SETFL : 设置文件描述符文件状态flag 必选项:O_RDONLY, O_WRONLY, O_RDWR 不可以被修改 可选性:O_APPEND, O_NONBLOCK O_APPEND 表示追加数据 O_NONBLOK 设置成非阻塞 ... :可变参数,看需求添加。 */ -

-

-
fcntl 函数的返回值如上表的最后一列所示,失败则返回-1并设置errno。
-
在网络编程中,fcntl 函数通常用来将一个文件描述符设置为非阻塞,代码如下所示。
-
1 2 3 4 5 6int setnonblocking(int fd) { int old_opt = fcntl(fd, F_GETFL); // 获取旧标志 int new_opt = old_opt | O_NONBLOCK; // 设置非阻塞标志 fcntl(fd, F_SETFL, new_opt); return old_opt; // 返回就标志,以便日后恢复 }
第7章 Linux 服务器程序规范
7.1 日志
(1)关于守护进程
-
守护进程也称为精灵进程(daemon),是运行在后台的一种特殊进程。它独立于控制中断并且周期性的执行某种任务或者等待处理某些发生的事件。
-
Linux系统启动是会启动很多服务进程,这些系统服务进程没有控制终端,不能直接和用户交互。其他进程都是在用户登录或运行程序时创建。在运行结束或者用户注销时终止,但系统服务进程不受用户登录注销的影响,它们一直运行这。这种进程都有一个名称叫守护进程(daemon)。
例如:udevd 负责维护/dev目录下的设备文件,acpid 负责电源管理,syslogd(现在是 rsyslogd) 负责维护/var/log下的日志文件,可以看出守护进程通常采用以d结尾的名称,表示daemon。
-
Linux服务器程序一般以后台进程形式运行。后台进程又称守护进程(daemon)。它没有控制终端,因而也不会意外接收到用户输入。守护进程的父进程通常是init进程(PID为1的进程)。
(2)Linux系统日志
-
Linux系统日志是记录了系统运行状态、程序运行情况以及系统事件的文件。它包含了各种级别的信息,从调试信息和错误报告到警告和系统事件等。Linux系统日志主要分为四个部分:内核日志、系统日志、安全日志和应用程序日志。
- 内核日志:记录了系统内核的运行状态和事件,例如系统启动和关机时间、硬件错误等。
- 系统日志:记录了系统服务和进程的运行情况,例如登录信息、网络连接等。
- 安全日志:记录了系统的安全事件,例如认证失败、攻击尝试等。
- 应用程序日志:记录了应用程序的运行状态和事件,例如数据库服务器的连接信息、Web服务器的请求信息等。
通过查看系统日志,管理员可以了解系统的状态和运行情况,诊断问题并进行故障排除。
-
服务器的调试和维护都需要一个专业的日志系统,Linux提供了一个守护进程来处理系统日志——syslogd。但是现在的Linux系统上使用的都是它的升级版——rsyslogd。
-
在大多数 Linux 发行版中,系统日志文件通常保存在
/var/log目录下。这个目录包含了许多不同的日志文件,每个日志文件都用于记录特定类型的日志信息。 -
常见的日志的作用
-
日志名称 日志路径 日志功能 备注 定时任务日志 /var/log/cron 记录了系统定时任务相关的日志。 打印日志 /var/log/cups 记录打印信息的日志 内核自检日志 /var/log/dmesg 记录了系统在开机时内核自检的信息。也就是使用dmesg命令直接查看内核自检信息。 内核日志 /var/log/kern.log 记录内核产生的日志,有助于在定制内核时解决问题。 登录失败日志 /var/log/btmp 记录错误登录的日志。这个文件是二进制文件,不能直接用vi查看,而是要用lastb命令查看。 如果有人攻击你的电脑就这个文件就会有大量的日志信息。 最后登录日志 /var/log/lastlog 记录系统中所有用户最后一次的登录时间的日志。这个文件也是二进制文件,不能直接vi,而要用lastlog命令查看。 邮件日志 /var/log/mail.log 记录邮件信息 系统日志 /var/log/messages 记录系统重要信息的日志。这个日志文件中会记录Linux系统的绝大多数重要信息,如果系统出现问题时,首先要检查的就应该是这个日志文件。 该日志文件默认还会记录一些服务日志哟。 安全日志 /var/log/secure 记录验证和授权方面的信息,只要涉及账户和密码程序的都会记录。比如说系统的登录,ssh的登录,su切换用户,sudo授权,甚至添加用户和修改用户密码都会记录在这个日志文件中。 登录日志 /var/log/wtmp 永久记录所有用户的登录,注销信息,同时记录系统的启动,重启,关机时间。同样这也是一个二进制文件,不能直接vi打开,而需要last命令来查看。 当前登录日志 /var/run/utmp 记录当前已经登录的用户的信息,这个文件会随着用户的登录和注销而不断变化,只记录当前登录用户的信息。同样这个文件也不能直接用vi打开,而是要用 w,who,users等命令来查询。 函数默认 /var/log/syslog 日志系统自身信息。 -
syslogd 守护进程既能接收用户进程输出的日志,又能接收内核日志。
- 用户进程是通过调用syslog函数生成系统日志的。该函数将日志输出到一个UNIX本地域socket类型(AF_UNIX)的文件**/dcv/log**中,rsyslogd则监听该文件以获取用户进程的输出。
- 内核日志在老的系统上是通过另外一个守护进程rklogd来管理的,rsyslogd 利用额外的模块实现了相同的功能。内核日志由printk 等函数打印至内核的环状缓存(ring buffer) 中。环状缓存的内容直接映射到 /proc/kmsg 文件中。rsyslogd 则通过读取该文件获得内核日志。
-
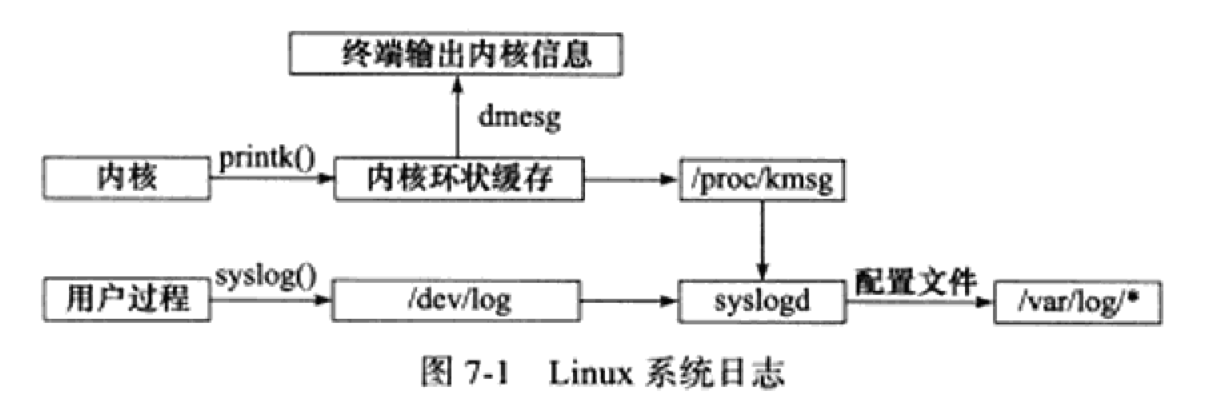
-
rsyslogd 守护进程在接收到用户进程或内核输人的日志后,会把它们输出至某些特定的日志文件。默认情况下,调试信息会保存至/var/log/debug文件,普通信息保存至/var/log/messages文件,内核消息则保存至/var/log/kern.log文件。不过,日志信息具体如何分发,可以在rsyslogd的配置文件中设置。
-
rsyslogd 的主配置文件是/etc/syslog.conf,其中主要可以设置的项包括:内核日志输人路径,是否接收UDP日志及其监听端口(默认是514,见/etc/services文件),是否接收TCP日志及其监听端口,日志文件的权限,包含哪些子配置文件(比如/etc/rsyslog.d/* .conf)。rsyslogd 的子配置文件则指定各类日志的目标存储文件。
(3)syslog系列函数
-
Linux C中提供一套系统日记写入接口,包括三个函数:openlog,syslog和closelog。还有设置日志过滤掩码的函数 setlogmask。
-
1 2 3 4 5#include <syslog.h> void syslog(int priority, const char *message, ...); void openlog(const char *ident, int logopt, int facility); int setlogmask(int maskpri); void closelog(); -
(a) syslog
-
void syslog(int priority, const char *message, ...); -
应用程序使用syslog函数与rsyslogd守护进程通信。syslog()函数类似于write()函数,往系统日志文件中写日志。
-
该函数采用可变参数(第二个参数message和第三个参数...)来结构化输出。
-
priority 参数是所谓的设施值与日志级别的按位或。设施值的默认值是LOG_USER,我们下面的讨论也只限于这一种设施值。日志级别有如下几个:
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17/* * priorities/facilities are encoded into a single 32-bit quantity, where the * bottom 3 bits are the priority (0-7) and the top 28 bits are the facility * (0-big number). Both the priorities and the facilities map roughly * one-to-one to strings in the syslogd(8) source code. This mapping is * included in this file. * * priorities (these are ordered) */ #define LOG_EMERG 0 /* system is unusable */ #define LOG_ALERT 1 /* action must be taken immediately */ #define LOG_CRIT 2 /* critical conditions */ #define LOG_ERR 3 /* error conditions */ #define LOG_WARNING 4 /* warning conditions */ #define LOG_NOTICE 5 /* normal but significant condition */ #define LOG_INFO 6 /* informational */ #define LOG_DEBUG 7 /* debug-level messages */ -

-
(b) openlog
-
void openlog(const char *ident, int logopt, int facility); -
使用openlog 函数可以改变syslog的默认输出方式,进一步结构化日志内容:
-
ident参数指定的字符串将被添加到日志消息的日期和时间之后,它通常被设置为程序的名字。
-
logopt 参数对后续syslog调用的行为进行配置,它可取下列值的按位或:
-
1 2 3 4 5 6 7 8 9 10 11 12/* * Option flags for openlog. * * LOG_ODELAY no longer does anything. * LOG_NDELAY is the inverse of what it used to be. */ #define LOG_PID 0x01 /* log the pid with each message */ #define LOG_CONS 0x02 /* log on the console if errors in sending */ #define LOG_ODELAY 0x04 /* delay open until first syslog() (default) */ #define LOG_NDELAY 0x08 /* don't delay open */ #define LOG_NOWAIT 0x10 /* don't wait for console forks: DEPRECATED */ #define LOG_PERROR 0x20 /* log to stderr as well */ -

-
facility参数可用来修改syslog函数中的默认设施值,上面已经说过,设施值的默认值是LOG_USER,可以是以下值。
-
1 2 3 4 5 6 7 8 9 10 11 12 13/* facility codes */ #define LOG_KERN (0<<3) /* kernel messages */ #define LOG_USER (1<<3) /* random user-level messages */ #define LOG_MAIL (2<<3) /* mail system */ #define LOG_DAEMON (3<<3) /* system daemons */ #define LOG_AUTH (4<<3) /* security/authorization messages */ #define LOG_SYSLOG (5<<3) /* messages generated internally by syslogd */ #define LOG_LPR (6<<3) /* line printer subsystem */ #define LOG_NEWS (7<<3) /* network news subsystem */ #define LOG_UUCP (8<<3) /* UUCP subsystem */ #define LOG_CRON (9<<3) /* clock daemon */ #define LOG_AUTHPRIV (10<<3) /* security/authorization messages (private) */ #define LOG_FTP (11<<3) /* ftp daemon */ -
(c) setlogmask
-
int setlogmask(int maskpri); -
此外,日志的过滤也很重要。程序在开发阶段可能需要输出很多调试信息,而发布之后我们又需要将这些调试信息关闭。解决这个问题的方法并不是在程序发布之后删除调试代码(因为日后可能还需要用到),而是简单地设置日志掩码,使日志级别大于日志掩码的日志信息被系统忽略。使用
int setlogmask(int maskpri);函数设置syslog 的日志掩码: -
maskpri参数指定日志掩码值。该函数始终会成功,它返回调用进程先前的日志掩码值。
-
(d) closelog
-
void closelog(); -
最后,使用closelog函数关闭日志功能。
-
(e) 实验
-
代码如下
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <stdarg.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <syslog.h> #include <unistd.h> #define BUFSZ 4096 static void log_msg(const char *fmt, ...) { char buf[BUFSZ]; va_list ap; va_start(ap, fmt); vsnprintf(buf, BUFSZ - 1, fmt, ap); strcat(buf, "\n"); openlog("test", LOG_CONS | LOG_NDELAY | LOG_PERROR, LOG_USER); // 该行可选 syslog(LOG_INFO, "%s", buf); closelog(); // 该行可选 va_end(ap); } int main(int argc, char *argv[]) { log_msg("Hello World. This is a syslog test,%s,.", "fdsfdafsd"); return 0; } -
在
/var/log/syslog文件,可以看到生成的日志 -

-
终端也会生成信息,取决于
LOG_CONS选项 -

7.2 UID、EUID、GID和EGID
-
用户信息对于服务器程序的安全性来说是很重要的,比如大部分服务器就必须依赖root身份的权限,但不能以root身份运行。下面这一组函数可以获取和设置当前进程的真实用户ID(UID)、有效用户ID (EUID)、真实组ID (GID)和有效组ID ( EGID):
-
1 2 3 4 5 6 7 8 9 10#include <sys/types.h> #include <unistd.h> uid_t getuid();/* 获取真实用户 ID */ uid_t geteuid() ;/*获取有效用户ID */ gid_t getgid() ;/*获取真实组ID */ gid_t getegid() ;/*获取有效组ID */ int setuid( uid_t uid ) ;/*设置真实用户ID */ int seteuid( uid_t uid ) ;/*设置有效用户ID */ int setgid( gid_t gid );/*设置真实组ID */ int setegid( gid_t gid );/*设置有效组ID */ -
setuid和setgid函数说明:
-
若进程具有root权限, 则函数将实际用户的ID(组), 有效用户的ID(组),都设置为参数uid;
-
若进程不具有root权限,但uid等于 实际用户 ID(组), 则 setuid 只将有效用户的ID(组)设置为uid,不改变实际用户ID;
-
若以上两个条件都不满足,则函数调用失败,返回 -1;并设置错误为EPERM。
-
-
也就是说,只有超级用户才能更改实际用户的 ID, 所以一个非root用户进程是不能通过setuid和setgid得到特权用户权限的,但su命令能将一个普通用户变成特权用户,这并不矛盾,因为su是一个“set_uid程序”,执行一个设置了set_uid位的程序时,内核将进程的有效用户ID设置为文件属主的ID,而检查一个进程是否有访问某个文件的权限时,是使用进程的有效ID来进行检查的。su程序的文件属主是root,因此普通用户运行su 时,su的进程权限就是root权限。
-
这里说明以下:
- su是申请切换root用户,需要申请root用户密码。有些Linux发行版,例如ubuntu,默认没有设置root用户的密码,所以需要我们先使用
sudo passwd root设置root用户密码。 - sudo su是当前用户暂时申请root权限,所以输入的不是root用户密码,而是当前用户的密码。sudo是用户申请管理员权限执行一个操作,而此处的操作就是变成管理员。
- su是申请切换root用户,需要申请root用户密码。有些Linux发行版,例如ubuntu,默认没有设置root用户的密码,所以需要我们先使用
-
uid和euid都是与进程的权限有关的属性。
- uid(User ID)是用户ID,用于标识进程所属的用户。每个用户都有一个唯一的uid。当进程执行需要特殊权限的操作时,需要检查进程的UID是否有相应的权限(如读写执行rwx)。
- euid(Effective User ID)是有效用户ID,用于表示当前进程的特权级别。如果进程具有额外的特权,则euid将高于uid。例如,在root用户下运行的程序,其euid为0,而普通用户的euid一般等于uid。当进程被执行时,内核会根据进程的UID和程序的特权级别来设置进程的EUID,以确保程序能够执行需要特殊权限的操作。
-
EUID存在的目的是方便资源访问:它使得运行程序的用户拥有该程序的有效用户的权限。
-
比如su程序,任何用户都可以使用它来修改自己的账户信息,但修改账户时su程序不得不访问/etc/passwd文件,而访问该文件是需要root权限的。那么以普通用户身份启动的su程序如何能访问/etc/passwd文件呢?窍门就在EUID。用Is命令可以查看到,su 程序的所有者是root,并且它被设置了set-user-id标志。这个标志表示,任何普通用户运行su程序时,其有效用户就是该程序的所有者root。那么,根据有效用户的含义,任何运行su程序的普通用户都能够访问/etc/passwd文件。
-
有效用户为root的进程称为特权进程(privileged processes)。
-
EGID 的含义与EUID类似:给运行目标程序的组用户提供有效组的权限。
-

-
上图可以看到,su的权限为
-rwsr-xr-x -
如果一个文件被设置了suid或sgid位,会分别表现在所有者或同组用户的权限的可执行位上;如果文件设置了suid还设置了x(执行)位,则相应的执行位表示为s(小写)。但是,如果没有设置x位,它将表示为S(大写)。如:
-
1 2 3 4-rwsr-xr-x 表示设置了suid,且拥有者有可执行权限x; -rwSr--r-- 表示设置了suid,但拥有者没有可执行权限x; -rwxr-sr-x 表示设置了sgid,且群组用户有可执行权限x; -rw-r-Sr-- 表示设置了sgid,但群组用户没有可执行权限x; -
0位为文件类型,1-3为用户权限,4-6为所在组权限,7-9为其他用户所拥有的权限。
-
(1)测试进程的uid和euid的区别的示例代码
-
1 2 3 4 5 6 7 8 9 10#include <unistd.h> #include <stdio.h> int main() { uid_t uid = getuid(); uid_t euid = geteuid(); printf( "userid is %d, effective userid is: %d\n", uid, euid ); return 0; } -
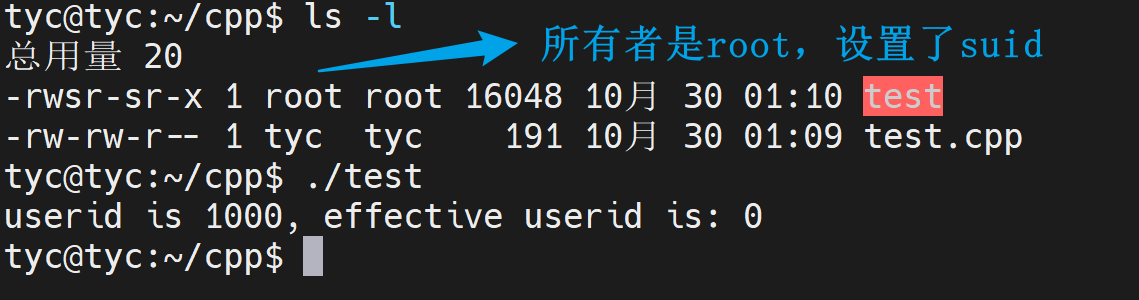
-
从测试程序的输出来看,进程的UID是启动程序的用户的ID,而EUID则是该程序的有效用户(这里是root,即0)的ID。
-
(2)将以root身份启动的进程切换为以普通用户身份运行的程序代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42#include <stdio.h> #include <unistd.h> /** * 从root用户切换到目标用户(user_id, gp_id) * root 用户uid = 0, gid = 0 */ static bool switch_to_user(uid_t user_id, gid_t gp_id) { /* 先确保目标用户不是root */ if ((user_id == 0) && (gp_id == 0)) { return false; } /* 确保当前用户是合法用户: 不是root 且 当前不是目标用户id ,转换失败*/ gid_t gid = getgid(); uid_t uid = getuid(); if (((gid != 0) || (uid != 0)) && ((gid != gp_id) || (uid != user_id))) { return false; } /* 如果不是root, 则已经是目标用户 */ if (uid != 0) { return true; } /* 说明此时是root,则切换到目标用户 */ if ((setgid(gp_id) < 0) || (setuid(user_id) < 0)) { return false; } return true; } /** * 要求以root身份启动程序 */ int main() { printf("current uid = %d, euid = %d\n", getuid(), geteuid()); if (switch_to_user(4000, 4000)) { printf("current uid = %d, euid = %d\n", getuid(), geteuid()); } else { printf("switch false!\n"); } return 0; } -

-
从实验结果可以看出,确实切换成功了。
7.3 进程间关系
7.3.1 进程组
-
Linux下每个进程都隶属于一个进程组,因此它们除了PID信息外,还有进程组ID(PGID)。我们可以用如下函数来获取指定进程的PGID:
-
1 2#include <unistd.h> pid_t getpgid(pid_t pid); -
该函数成功时返回进程pid所属进程组的PGID,失败则返回-1并设置errno。
-
每个进程组都有一个首领进程,其PGID和PID相同。进程组将一直存在,直到其中所有进程都退出,或者加入到其他进程组。
-
可用如下函数设置PGID。
-
1 2 3 4 5/* Set the process group ID of the process matching PID to PGID. If PID is zero, the current process's process group ID is set. If PGID is zero, the process ID of the process is used. */ #include<unistd.h> int setpgid(pid_t pid,pid_t pgid); -
该函数的作用:将pid进程的进程组ID设置成pgid,创建一个新进程组或加入一个已存在的进程组。
-
函数性质
- 性质1:一个进程只能为自己或子进程设置进程组ID,不能设置其父进程的进程组ID。并且,当子进程调用exec系列函数后,我们不能再在父进程中对它设置PGID。
- 性质2:if(pid == pgid), 由pid指定的进程变成进程组长;即进程pid的进程组ID pgid=pid.
- 性质3:if(pid==0),将当前进程的的进程组ID设置为pgid.
- 性质4:if(pgid==0),将pid作为进程组ID.
-

7.3.2 会话
-
一些有关联的进程组将形成一个会话(session)。下面的函数用于创建一个会话:
-
1 2#include<unistd.h> pid_t setsid(void); -
该函数不能由进程组的首领进程调用,否则将产生一个错误。对于非组首领的进程,调用该函数不仅创建新会话,而且有如下额外效果:
- 调用进程成为会话的首领,此时该进程是新会话的唯一成员。
- 新建一个进程组,其PGID就是调用进程的PID,调用进程成为该组的首领。
- 调用进程将甩开终端( 如果有的话)。
-
该函数成功时返回新的进程组的PGID,失败则返回-1并设置errno。
-
Linux进程并未提供所谓会话ID(SID)的概念,但Linux系统认为它等于会话首领所在的进程组的PGID,并提供了如下函数来读取SID:
-
1pid_t getsid (pid_t pid);
7.3.3 用ps命令查看进程关系
-
使用如下命令
-
1ps -o pid,ppid,pgid,sid,comm | less -
-
可以看到,我们是在bash shell下执行ps和less命令的,所以ps和less命令的父进程是bash命令,这可以从PPID (父进程PID)一列看出。这3条命令创建了1个会话(SID 是4622)和2个进程组(PGID分别是9834和4622)。
-
bash命令的PID、PGID和SID都相同,很明显它既是会话的首领,也是组4622的首领。
-
ps 命令则是组9834的首领,因为其PID也是9834。图描述了此三者的关系。
-
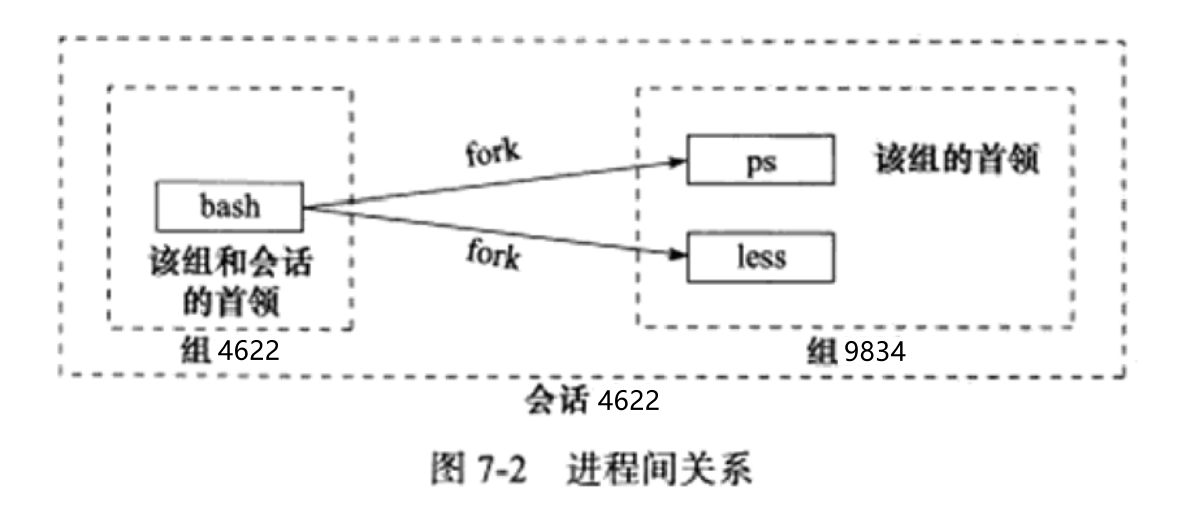
7.4 系统资源限制
-
Linux上运行的程序都会受到资源限制的影响,比如物理设备限制(CPU数量、内存数量等)、系统策略限制(CPU时间等),以及具体实现的限制(比如文件名的最大长度)。Linux系统资源限制可以通过如下一对函数来读取和设置:
-
1 2 3#include <sys/resource.h> int getrlimit(int resource, struct rlimit *rlim); int setrlimit(int resource, const struct rlimit *rlim); -
struct rlimit 结构体(描述软硬限制)的原型如下:
-
1 2 3 4struct rlimit { rlim_t rlim_cur; rlim_t rlim_max; }; -
rlim_t是一个整数类型,它描述资源级别。
-
rlim_cur 成员指定资源的软限制,rlim_max成员指定资源的硬限制。
-
软限制是一个建议性的、最好不要超越的限制,如果超越的话,系统可能向进程发送信号以终止其运行。例如,当进程CPU时间超过其软限制时,系统将向进程发送SIGXCPU信号;当文件尺寸超过其软限制时,系统将向进程发送SIGXFSZ信号。
-
硬限制一般是软限制的上限。普通程序可以减小硬限制,而只有以root身份运行的程序才能增加硬限制。
-
此外,我们可以使用ulimit命令修改当前shell环境下的资源限制(软限制或/和硬限制),这种修改将对该shell启动的所有后续程序有效。我们也可以通过修改配置文件来改变系统软限制和硬限制,注意这种修改是永久的。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16resource:指定资源限制类型,可能的选择有以下几种: RLIMIT_AS //进程的最大虚内存空间,字节为单位。 RLIMIT_CORE //内核转存文件的最大长度。 RLIMIT_CPU //最大允许的CPU使用时间,秒为单位。当进程达到软限制,内核将给其发送SIGXCPU信号,这一信号的默认行为是终止进程的执行。然而,可以捕捉信号,处理句柄可将控制返回给主程序。如果进程继续耗费CPU时间,核心会以每秒一次的频率给其发送SIGXCPU信号,直到达到硬限制,那时将给进程发送 SIGKILL信号终止其执行。 RLIMIT_DATA //进程数据段的最大值。 RLIMIT_FSIZE //进程可建立的文件的最大长度。如果进程试图超出这一限制时,核心会给其发送SIGXFSZ信号,默认情况下将终止进程的执行。 RLIMIT_LOCKS //进程可建立的锁和租赁的最大值。 RLIMIT_MEMLOCK //进程可锁定在内存中的最大数据量,字节为单位。 RLIMIT_MSGQUEUE //进程可为POSIX消息队列分配的最大字节数。 RLIMIT_NICE //进程可通过setpriority() 或 nice()调用设置的最大完美值。 RLIMIT_NOFILE //指定比进程可打开的最大文件描述词大一的值,超出此值,将会产生EMFILE错误。 RLIMIT_NPROC //用户可拥有的最大进程数。 RLIMIT_RTPRIO //进程可通过sched_setscheduler 和 sched_setparam设置的最大实时优先级。 RLIMIT_SIGPENDING //用户可拥有的最大挂起信号数。 RLIMIT_STACK //最大的进程堆栈,以字节为单位。 -

-
setrlimit和getrlimit成功时返回0,失败则返回-1并设置errno。
7.5 改变工作目录和根目录
-
有些服务器程序还需要改变工作目录和根目录。一般来说,Web服务器的逻辑根目录并非文件系统的根目录“/”,而是站点的根目录(对于Linux的Web服务来说,该目录一般是var/www/)。
-
因此需要读取和改变工作目录和根目录。
-
(1)关于工作目录
-
获取所在进程的当前工作目录的函数如下:
-
1 2#include <unistd.h> char *getcwd(char *buf,size_t size); -
buf 参数指向的内存用于存储进程当前工作目录的绝对路径名,其大小由 size 参数指定。如果当前工作目录的绝对路径的长度(再加上一个空结束字符“\0”) 超过了size,则getcwd将返回NULL,并设置erno为 ERANGE。如果 buf 为NULL并且 size 非0,则getcwd可能在内部使用malloc动态分配内存,并将进程的当前工作目录存储在其中。如果是这种情况,则我们必须自己来释放getcwd在内部创建的这块内存。
-
getcwd 函数成功时返回一个指向目标存储区(buf指向的缓存区或是getcwd在内部动态创建的缓存区)的指针,失败则返回NULL并设置errno。
-
改变当前进程的工作目录的函数如下:
-
1 2#include <unistd.h> int chdir(const char * path); -
path 参数指定要切换到的目标目录,注意一定要真实存在的目录,否则报出No such file or directory的errno。
-
返回值执行成功则返回0,失败返回-1,errno为错误代码。
-
利用以上两个函数的实验代码。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26#include <assert.h> #include <errno.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> int main() { char dir[100]; memset(dir, 0, sizeof(dir)); char *ret = getcwd(dir, 100); assert(ret); printf("before change dir = %s\n", ret); int nn = chdir("/home/tyc"); if (nn == -1) { printf("%s\n", strerror(errno)); exit(1); } memset(dir, 0, sizeof(dir)); ret = getcwd(dir, 100); assert(ret); printf("after change dir = %s\n", ret); return 0; } -

-
(2)改变进程根目录
-
使用chroot函数改变进程根目录,定义如下:
-
1 2#include <unistd.h> int chroot (const char *path) -
chroot() 改变根目录中指定的路径。此目录将用于与/开头的路径名。根目录继承当前进程的的所有子目录。
-
path参数指定要切换到的目标根目录。它成功时返回0,失败时返回-1并设置errno。
-
chroot并不改变进程的当前工作目录,所以调用chroot之后,我们仍然需要使用
chdir(“/”)来将工作目录切换至新的根目录。改变进程的根目录之后,程序可能无法访问类似 /dev的文件(和目录),因为这些文件(和目录)并非处于新的根目录之下。不过好在调用chroot之后,进程原先打开的文件描述符依然生效,所以我们可以利用这些早先打开的文件描述符来访问调用 chroot 之后不能直接访问的文件(和目录),尤其是一些日志文件。此外,只有特权进程才能改变根目录。 -
测试代码如下
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27#include <assert.h> #include <errno.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> int main() { // 需要root权限 if (chroot("/home/tyc")) { perror("chroot"); return 1; } // 这时候的实际的本身系统目录是 /home/tyc/snap if (chdir("/snap")) { perror("chdir"); return 1; } char dir[100]; memset(dir, 0, sizeof(dir)); char *ret = getcwd(dir, 100); assert(ret); printf("curr dir = %s\n", ret); return 0; } -
生成的执行程序需要有root权限。否则会有如下的报错。
-

-
赋予root权限后,输出结果为:
-

7.6 服务器程序后台化
7.6.1 后台进程
-
假设如今有一个可执行程序名为
test,如果直接启动./test,那么它是个前台进程,或者称为前台任务(foreground job),它会独占命令行窗口,只有运行完了或者手动中止,才能执行其他命令。如果是./test &方式启动(后面加一个&符号),那么它就变成后台进程,也可以称为后台任务(background job)。 -
后台任务会:
- 继承当前 session(对话)的标准输出(stdout)和标准错误(stderr)。因此,后台任务的所有输出依然会同步地在命令行下显示。
- 不再继承当前 session 的标准输入(stdin)。你无法向这个任务输入指令了。如果它试图读取标准输入,就会暂停执行(halt)。
-
后台进程的相关命令
-
查看当前作业(后台运行程序):
命令 &:表示把当前程序后台运行;(但依然受终端控制,终端退出时也会退出);若有输出,依然会在终端中显示;jobs:查看当前有多少后台运行命令(只能查看当前终端的);ctrl+z:将一个前台执行的命令放到后台,并处于暂停状态;fg:把指定命令(作业号,jobs显示的),调到前台继续运行;bg:将后台暂停的命令(作业号,jobs显示的),变为后台继续运行(相当于在命令后+&继续运行);若有输出,依然会在终端中显示;
-
以以下示例程序为例子,生成test可执行文件
-
1 2 3 4 5 6 7 8 9 10 11 12 13#include <fcntl.h> #include <iostream> #include <stdlib.h> #include <unistd.h> using namespace std; int main(void) { while (1) { cout << "cnt" << endl; sleep(1); } return 0; } -
-
可以看到,确实是转为后台运行,但终端仍有输出。
-
7.6.2 守护进程
-
Linux中的守护进程(daemon进程)相当于Windows中的后台服务程序,一直运行于后台。
-
守护进程是一个在后台运行并且不受任何终端控制的进程。
-
很多进程名字后面加了个d,基本就是个守护进程(这算个约定俗称的规则)。mysql(数据库),ssh(shell登录),cron(定时器)都是以守护进程的方式在运行。
-
Q:后台进程是否就是守护进程了呢?或者说,用户退出session(也即:用户退出shell)后,后台进程是否还会继续执行? A:后台进程和守护进程不一样。
-
这里涉及到SIGHUP信号。我们先了解下,退出shell的过程。 step1:用户准备退出session(shell)。 step2:系统向该shell窗口进程发出SIGHUP信号。 step3:shell窗口进程将SIGHUP信号发送给所有子进程。 step4:子进程受到SIGHUP信号,自动退出。
-
对于前台进程,当shell退出,子进程会收到SIGHUP信号而退出;
-
对于后台进程,当shell退出,是否发送SIGHUP信号给后台进程,取决于shell的 huponexit 参数,当该参数是off,则shell退出,不会发送SIGHUP信号给后台进程;当该参数是on,则shell退出时,会发送SIGHUP信号给后台进程,则后台进程也会跟随退出。可通过如下命令
shopt | grep huponexit查看当前shell的 huponexit 参数。 -
因此,后台进程和守护进程并不相同,比如:有的系统huponexit是on的话,那么shell退出时候,后台进程也会相应地退出。
-
本地测试,huponexit为off,因此后台进程会留下,**并被init进程(pid为1)**收养。
-

-
那么如何使得后台进程变成守护进程呢?可以主动使用nohup命令,默认输出重定向到“nohup.out” 文件
-
1nohup ./test & -

-
如果不想用默认的输出nohup.out,可以自己指定输出:
-
1 2 3 4 5nohup ./test > a.txt 2>&1 & /* 2>&1:这是将标准错误输出重定向到与标准输出相同的位置。2 表示标准错误输出,&1 表示标准输出的位置。 &:这是一个特殊字符,用于将命令置于后台运行,使终端可以继续接受其他命令输入。 */ -
值得注意的是,nohup命令不会自动把进程变为"后台任务",所以必须加上&符号。
7.6.3 编写守护进程
-
常见的编写守护进程有fork与daemon两种方式。
-
(1)fork
-
通过fork子进程,然后退出父进程的方式实现。-
-
实现流程说明:
- fork成功后,父进程退出;
- 子进程调用setsid(),来创建新的进程会话(并成为会话首进程),从而脱离和终端的关联;
- 将当前工作目录切换到根目录:非必须,避免因进程使用当前目录,而影响目录操作(如卸载当前目录所在系统等);
- 重定向输入输出到
/dev/null,通过dup2把标准输入、输出重定向;
-
示例1
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50#include <assert.h> #include <errno.h> #include <fcntl.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/stat.h> #include <sys/types.h> #include <unistd.h> bool daemonize() { // 创建子进程,关闭父进程,这样可以使程序在后台运行 pid_t pid = fork(); if (pid < 0) { return false; } else if (pid > 0) { // 退出父进程 exit(0); } /* 设置文件权限掩码。当进程创建新文件(使用open(const char *path, int oflag, mode_t mode)系统调用)时,文件的权限将是 mode&0777。 */ umask(0); // 创建新的会话,设置本进程为进程组的首领 pid_t sid = setsid(); if (sid < 0) { return false; } /* 切换工作目录 */ if ((chdir("/")) < 0) { return false; } // 关闭标准输入设备、标准输出设备和标准错误输出设备 close(STDIN_FILENO); close(STDOUT_FILENO); close(STDERR_FILENO); /*关闭其他已经打开的文件描述符,代码省略 * / /*将标准翰入、标准输出和标准错误输出都定向到 /dev/nul1 文件*/ open("/dev/null", O_RDONLY); open("/dev/null", O_RDWR); open("/dev/null", O_RDWR); return true; } -
示例2
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31#include <fcntl.h> #include <iostream> #include <stdlib.h> #include <unistd.h> void testFork() { pid_t pid = fork(); if (pid < 0) { return; } else { if (pid != 0) { // parent exit(0); } } setsid(); if (chdir("/") < 0) { exit(-1); } int fd = open("/dev/null", O_RDWR); dup2(fd, STDIN_FILENO); dup2(fd, STDOUT_FILENO); dup2(fd, STDERR_FILENO); int count = 0; while (1) { // do something sleep(1); } } -
(2)daemon
-
Linux中专门提供了一个系统函数daemon,用于创建守护进程。
-
1 2#include <unistd.h> int daemon(int nochdir, int noclose); -
nochdir:为0表示改变工作目录为根目录 "/" ,1不改变; -
noclose:为0表示重定向输入、输出到/dev/null文件,1不重定向仍使用原来的设备; -
该函数成功调用时返回0,失败则返回-1并设置errno。
-

-
因此,最简单的实现后台守护进程,只需添加头文件
#include <unistd.h>,然后在调用daemon(1, 0)函数即可。 -
示例
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14#include <assert.h> #include <stdio.h> #include <unistd.h> int main() { int ret = daemon(1, 1); assert(ret == 0); while (1) { printf("hello\n"); sleep(1); } return 0; } -
-
输出结果为不断在终端输出hello,且是后台运行。通过
ps -aux | grep a.out找到其pid,使用kill删除后才得以结束。
第8章 高性能服务器程序框架
8.1 服务器模型
(1) C/S (客户端/服务器) 模型
- 服务器启动后,首先创建一个(或多个)监听socket,并调用bind函数将其绑定到服务器的ip和端口上,然后调用listen函数等待客户连接。
- 服务器稳定运行之后,客户端就可以调用connect函数向服务器发起连接了。
- 由于客户连接请求是随机到达的异步事件,服务器需要使用某种I/O模型来监听这一事件。I/O模型有多种,下图中服务器使用的是I/O复用技术之一的select系统调用。
- 当监听到连接请求后,服务器就调用accept函数接受它,并分配一个逻辑单元为新的连接服务。逻辑单元可以是新创建的子进程、子线程或者其他。
- 逻辑单元读取客户请求,处理该请求,然后将处理结果返回给客户端。客户端接收到服务器反馈的结果之后,可以继续向服务器发送请求,也可以立即主动关闭连接。如果客户端主动关闭连接,则服务器执行被动关闭连接。至此,双方的通信结束。
- 需要注意的是,服务器在处理一个客户请求的同时还会继续监听其他客户请求,否则就变成了效率低下的串行服务器了(必须先处理完前一个客户的请求,才能继续处理下一个客户请求)。
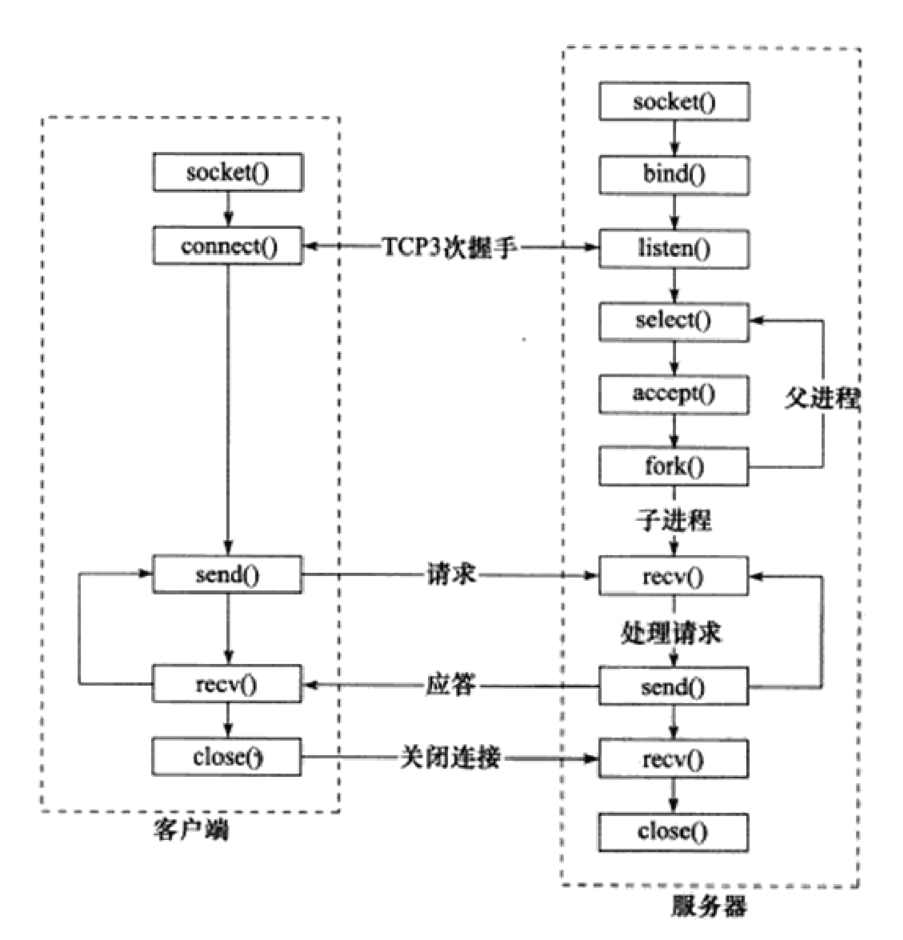
- C/S模型非常适合资源相对集中的场合,并且它的实现也很简单,但其缺点也很明显:服务器是通信的中心,当访问量过大时,可能所有客户都将得到很慢的响应。P2P模型可在一定程度上解决这个问题。
(2)P2P 模型
- P2P(Peer to Peer,点对点)模型比C/S模型更符合网络通信的实际情况。它摒弃了以服务器为中心的格局,让网络上所有主机重新回归对等的地位。
- P2P模型使得每台机器在消耗服务的同时也给别人提供服务,这样资源能够充分、自由地共享。云计算机群可以看作P2P模型的一个典范。但P2P模型的缺点也很明显:当用户之间传输的请求过多时,网络的负载将加重。
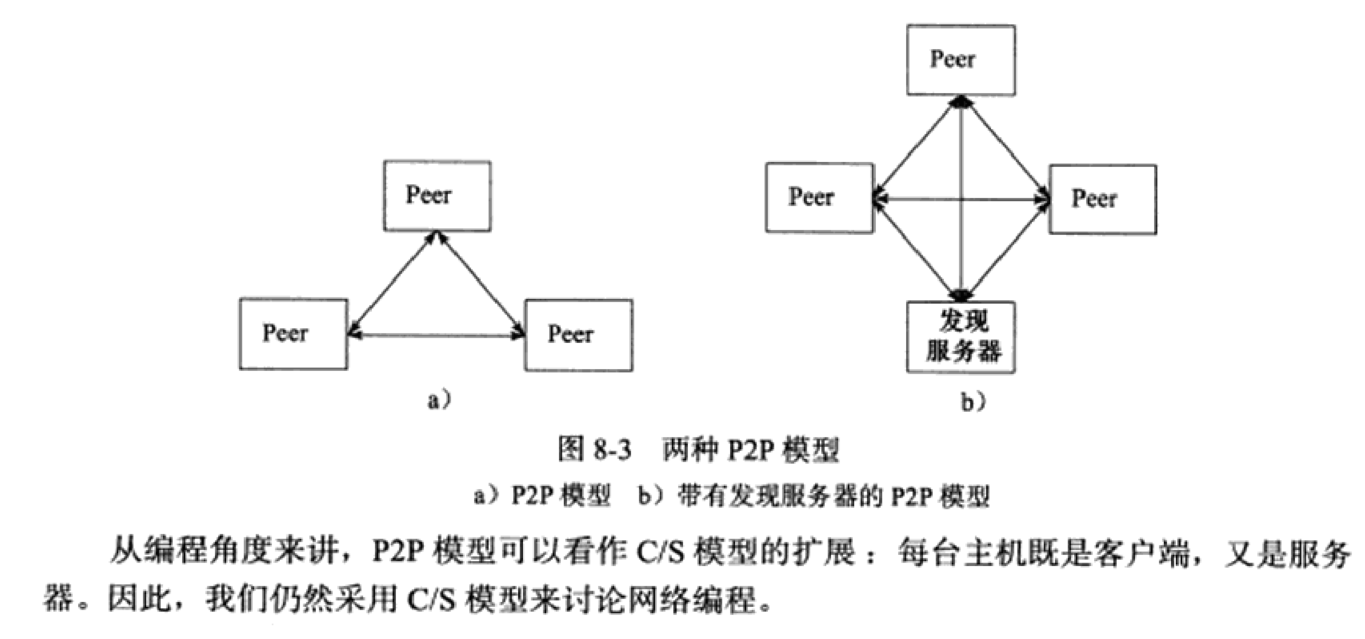
8.2 服务器编程基本框架
-
常见框架如下
-
-
上图既能表示一台服务器,也能表示一个服务器集群。其中各模块的含义和功能如下表所示。
-
模块 单个服务器程序 服务器集群 I/O 处理单元 处理客户连接,读写网络数据(不一定) 作为接入服务器,实现负载均衡 逻辑单元 业务进程或线程 逻辑服务器 请求队列 各单元之间的通信方式 各服务器之间的永久TCP连接 网络存储单元(非必须) 本地数据库、文件或缓存 数据库服务器 -
I/O处理单元是服务器管理客户连接的模块。它通常要完成以下工作:等待并接受新的客户连接,接收客户数据,将服务器响应数据返回给客户端。但是,数据的收发不一定在I/O处理单元中执行,也可能在逻辑单元中执行,具体在何处执行取决于事件处理模式。对于一个服务器机群来说,I/O处理单元是一个专门的接入服务器。它实现负载均衡,从所有逻辑服务器中选取负荷最小的一台来为新客户服务。
-
一个逻辑单元通常是一个进程或线程。它分析并处理客户数据,然后将结果传递给I/O处理单元或者直接发送给客户端(具体使用哪种方式取决于事件处理模式)。对服务器机群而言,一个逻辑单元本身就是一台逻辑服务器。服务器通常拥有多个逻辑单元,以实现对多个客户任务的并行处理。
-
网络存储单元可以是数据库、缓存和文件,甚至是一台独立的服务器。但它不是必须的,比如ssh、telnet等登录服务就不需要这个单元。
-
请求队列是各单元之间的通信方式的抽象。I/O处理单元接收到客户请求时,需要以某种方式通知一个逻辑单元来处理该请求。同样,多个逻辑单元同时访问一个存储单元时,也需要采用某种机制来协调处理竞态条件**。请求队列通常被实现为池的一部分**。对于服务器机群而言,请求队列是各台服务器之间预先建立的、静态的、永久的TCP连接。这种TCP连接能提高服务器之间交换数据的效率,因为它避免了动态建立TCP连接导致的额外的系统开销。
8.3 I/O 模型
- 计算机编程中,I/O模型是描述程序与输入/输出操作之间交互方式的抽象概念。不同的I/O模型可以影响程序的性能、可扩展性和资源利用效率。我们常见有五种 IO 模型:阻塞式 I/O、非阻塞式 I/O 、I/O多路复用 、信号驱动式 I/O、异步 I/O。
- socket 在创建的时候默认是阻塞的,我们可以给socket系统调用的第2个参数传递SOCK_NONBLOCK标志,或者通过fcntl系统调用的F_SETFL命令,将其设置为非阻塞的。阻塞和非阻塞的概念能应用于所有文件描述符,而不仅仅是socket。我们称阻塞的文件描述符为阻塞I/O,称非阻塞的文件描述符为非阻塞I/O。socket的基础API中,可能被阻塞的系统调用包括accept、send、recv和connect。
(1)阻塞 I/O(Blocking I/O)
- 阻塞 I/O 是指,执行可能会发生阻塞的系统调用后,系统调用不能立即完成并返回,因此操作系统会将其挂起,直到等待的事件(写完成、读完成等)发生为止。
- 比如,客户端通过connect向服务器发起连接时,connect将首先发送同步报文段给服务器,然后等待服务器返回确认报文段。如果服务器的确认报文段没有立即到达客户端,则connect调用将被挂起,直到客户端收到确认报文段并唤醒connect调用。
- 再来说read过程,其可以分为两个阶段:等待读就绪(等待数据到达网卡 & 将网卡的数据拷贝到内核缓冲区)、读数据(从内核缓冲区到用户缓冲区)。
(2)非阻塞 I/O (Non-Blocking I/O)
- 非阻塞 I/O 执行的系统调用总是立即返回,不管事件是否已经发生。如果事件没有立即发生,这些系统调用返回 -1,然后设置 errno,应用程序需要根据返回的 errno 进行相应的处理。
- 对accept、send和recv而言,事件未发生时的errno通常被设置成EAGAIN(意为“再来一次”)或者EWOULDBLOCK(意为“期望阻塞”);对connect而言,errno则被设置成EINPROGRESS(意为“在处理中”)。
- 很显然,我们只有在事件已经发生的情况下操作非阻塞I/O(读、写等),才能提高程序的效率。因此,非阻塞I/O通常要和其他I/O通知机制一起使用,比如I/O多路复用和 SIGIO信号。
- 仍然以read系统调用为例子,非阻塞 I/O 只是将read系统调用的第一阶段的等待读就绪改为非阻塞,但是第二阶段的数据读取还是阻塞的,非阻塞 read 最重要的是提供了我们在一个线程内管理多个文件描述符的能力。
(3)I/O 多路复用(I/O Multiplexing)
- 考虑这样一种情况,在并发的环境下,可能会N个人向应用B发送消息,这种情况下我们的应用就必须创建多个线程去读取数据,每个线程都会自己调用 read 去读取数据。那么此时情况可能如下图:
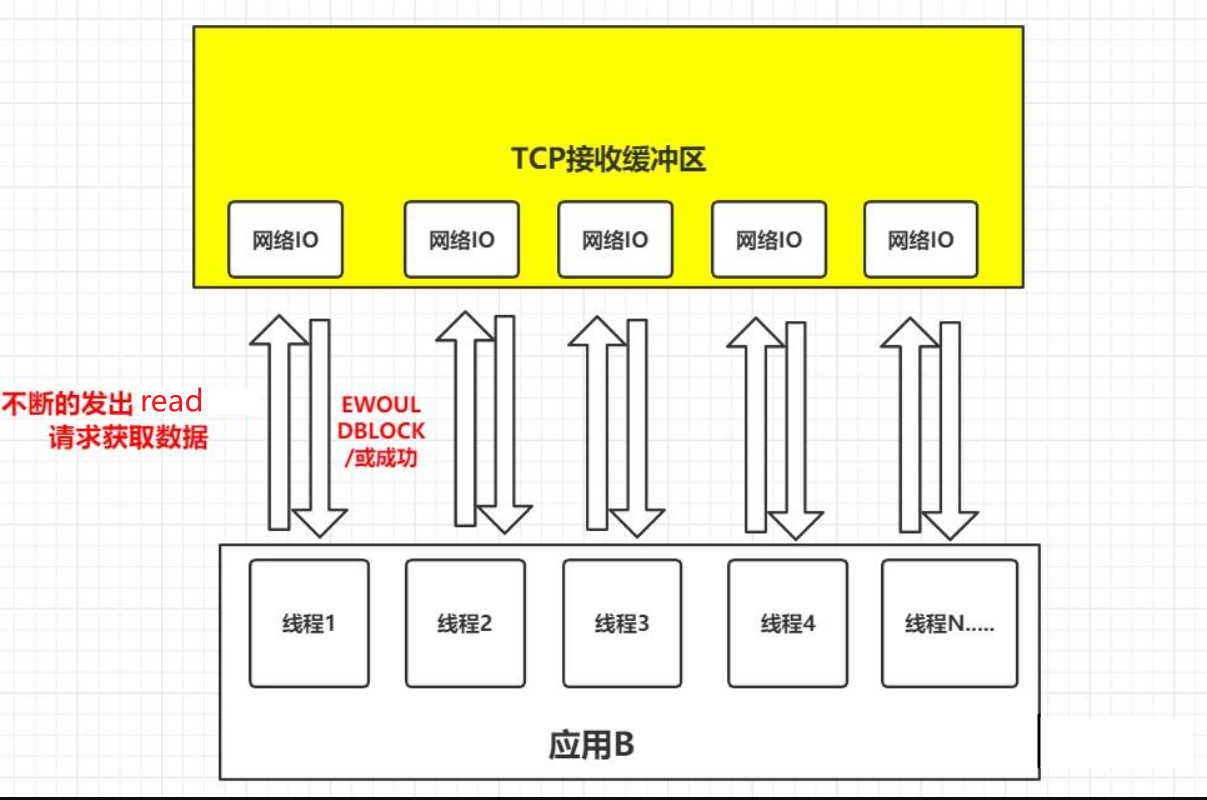
- 如上图一样,并发情况下服务器很可能一瞬间会收到几十上百万的请求,这种情况下应用B就需要创建几十上百万的线程去读取数据,同时又因为应用线程是不知道什么时候会有数据读取,为了保证消息能及时读取到,那么这些线程自己必须不断的向内核发送 read 请求来读取数据;
- 那么问题来了,这么多的线程不断调用 read 请求数据,先不说服务器能不能扛得住这么多线程,就算扛得住那么很明显这种方式是不是太浪费资源了,线程是我们操作系统的宝贵资源,大量的线程用来去读取数据了,那么就意味着能做其它事情的线程就会少。
- 所以,有人就提出了一个思路,能不能提供一种方式,可以由一个线程监控多个网络请求,这样就可以只需要一个或几个线程就可以完成数据状态询问的操作,当有数据准备就绪之后再分配对应的线程去读取数据,这么做就可以节省出大量的线程资源出来,这个就是I/O复用模型的思路。

- 如上图所示,I/O复用模型的思路就是系统提供了一种函数可以同时监控多个fd的操作,这个函数就是我们常说到的select、poll、epoll函数,有了这个函数后,询问线程通过调用select函数就可以同时监控多个fd,select函数监控的fd中只要有任何一个数据状态准备就绪了,select函数就会返回可读状态,这时询问线程再去通知处理数据的线程,对应的接收处理线程此时再发起read请求去读取数据。
- 以上就是I/O多路复用的来由。
- 多路指的是多个数据通道,复用指的是一个进程可以同时监控多个文件描述符(比如socket等),当某个文件描述符状态发生变化(比如变得可读或可写),多路复用的函数将返回变化的文件描述符。
- 这样,在数据传输过程中,同一个进程中不同的任务都能被处理。特点是在数据传输过程中,进程能够同时处理多个任务,提高了程序的效率。select、poll、epoll 等都是 I/O 多路复用的具体实现。
- 需要指出的是,I/O复用函数本身是阻塞的,它们能提高程序效率的原因在于它们具有同时监听多个I/O事件的能力。
(4)信号驱动式I/O(Signal-Driven I/O)
-
信号驱动式I/O利用信号机制来进行数据传输。
-
进程首先告诉内核,当数据准备好时,请发送一个SIGIO信号。进程继续执行其他任务,等到收到信号后,再开始进行数据传输。
-
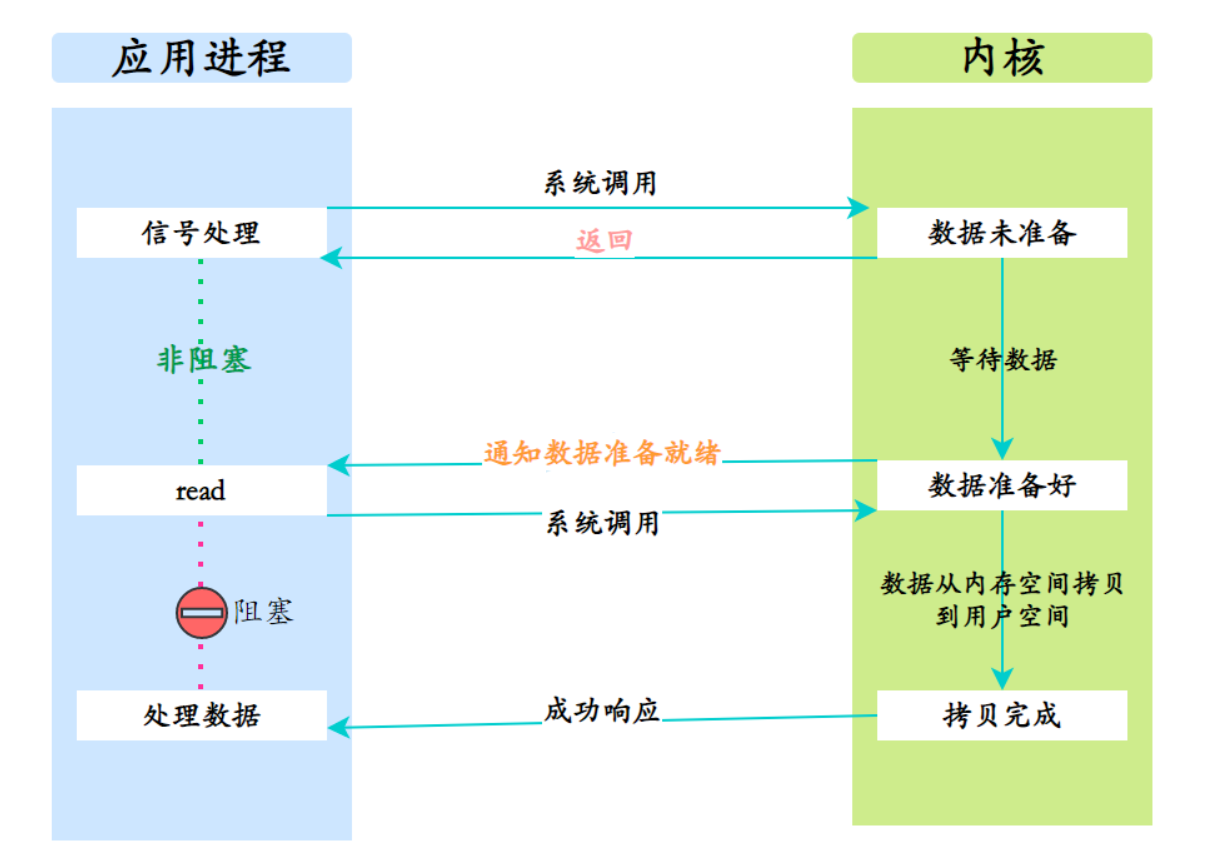
-
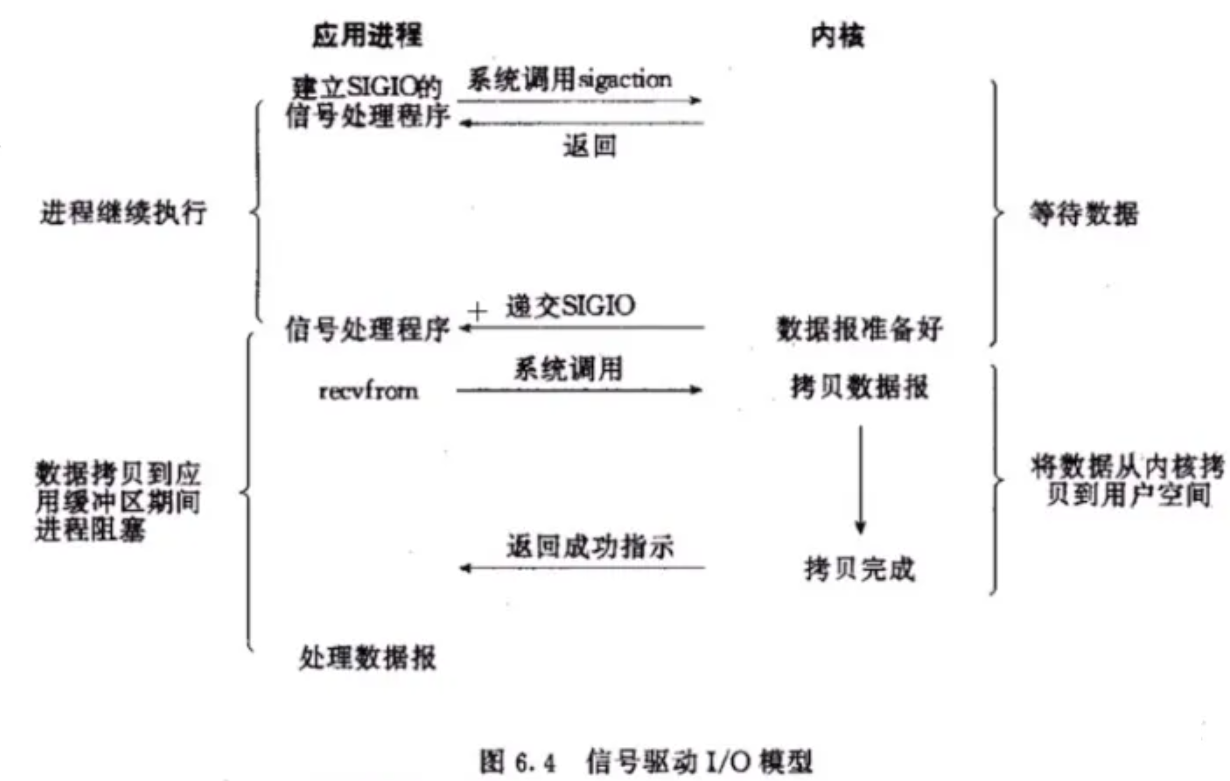
-
I/O复用模型里面的select虽然可以监控多个fd了,但select其实现的本质上还是通过不断的轮询fd来监控数据状态, 但实际上大部分轮询请求其实都是无效的;
-
为了减少这种资源浪费,信号驱动式I/O意在通过建立信号关联的方式,实现了发出请求后只需要等待数据就绪的通知即可,这样就可以避免大量无效的数据状态轮询操作,节约了资源。
(5)异步I/O(Asynchronous I/O)
- 从理论上说,阻塞I/O、I/O多路复用和信号驱动式I/O都是同步I/O模型。因为在这三种I/O模型中,I/O的读写操作,都是在I/O事件发生之后,由应用程序来完成的。
- 而POSIX规范所定义的异步I/O模型则不同。对异步I/O而言,用户可以直接对I/O执行读写操作,这些操作告诉内核用户读写缓冲区的位置,以及I/O操作完成之后内核通知应用程序的方式。异步I/O的读写操作总是立即返回,而不论I/O是否是阻塞的,因为真正的读写操作已经由内核接管。
- 也就是说,同步I/O模型要求用户代码自行执行I/O操作(将数据从内核缓冲区读人用户缓冲区,或将数据从用户缓冲区写入内核缓冲区);而异步I/O机制则由内核来执行I/O操作(数据在内核缓冲区和用户缓冲区之间的移动是由内核在“后台”完成的)。
- 你可以这样认为,同步I/O向应用程序通知的是I/O就绪事件,而异步I/O向应用程序通知的是I/O完成事件。Linux环境下,
aio.h头文件中定义的函数提供了对异步I/O的支持。 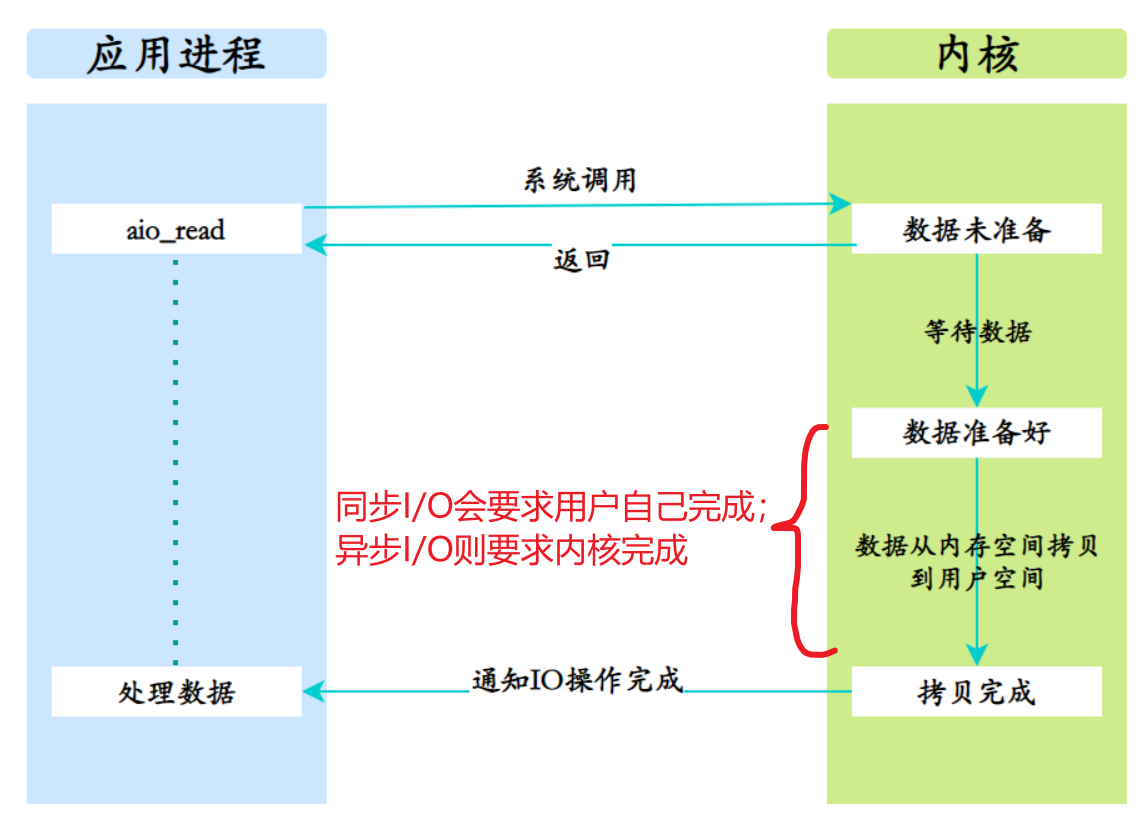
(6)对比总结
- 几种 I/O 模型的对比如下表所示:
I/O模型 读写操作和阻塞阶段 阻塞 I/O 会在读写操作时发生阻塞 I/O 多路复用 对 I/O 本身的读写操作是非阻塞的;会在 I/O 复用系统调用时发生阻塞,但可以同时监听多个 I/O 事件 SIGIO 信号 程序没有阻塞阶段;信号触发读写就绪事件,应用程序来处理读写操作; 异步 I/O 程序没有阻塞阶段;内核执行读写操作并触发读写完成事件;
8.4 事件处理模式
- 服务器程序通常要处理三类事件:I/O 事件、信号及定时事件。
- 事件处理模式是指,各种事件之间的协同处理关系。例如,对于服务端监听 socket 的主进程/主线程,当监听到一个客户端发来的连接请求时,是在主线程处理连接请求,还是使用一个子进程/子线程处理连接请求。可以根据不同的处理连接请求的方式,划分不同的事件处理模式。
- 随着网络设计模式的兴起,Reactor和Proactor事件处理模式应运而生。
- 同步I/O模型通常用于实现Reactor模式,异步I/O模型则用于实现Proactor模式。
- 不过实际上,同步I/O方式也可以模拟出Proactor模式。
(1)Reactor (反应堆)模式
-
Reactor模式是同步I/O。
-
Reactor模式是指,主线程(I/O处理单元)只负责监听文件描述符上是否有事件发生,若有事件发生,则将发生的事件通知(转交给)工作线程(逻辑单元)处理。除此之外,主线程不做任何其他实质性的工作。读写数据,接受新的连接,以及处理客户请求均在工作线程中完成(工作线程需主动把内核缓冲区读取数据到用户缓冲区)。
-

-
上述方案中,工作线程从请求队列中取出事件后,根据事件的类型来决定如何处理。对于读事件,执行读数据或处理请求;对于写事件,执行写数据的操作。因此,Reactor模式中没有读/写工作线程之分。
-
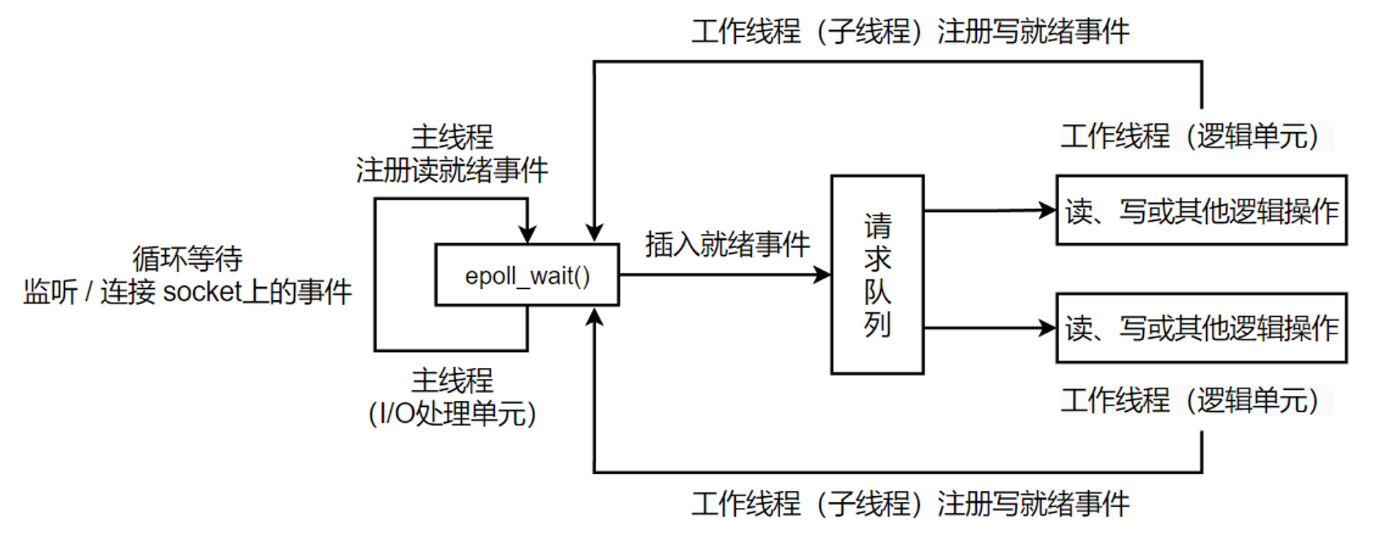
(2)Proactor 模式
-
与Reactor不同,Proactor模式将所有的I/O操作都交给主线程和内核来处理,工作线程仅仅负责业务逻辑(已经得到数据了,工作线程无需从内核缓冲区读取数据到用户缓冲区)。
-
因此,Proactor模式更符合8.2的服务器编程基本框架。
-
使用异步I/O模型(以aio_read和aio_write为例)实现的Proactor模式的工作流程是:
-
- 主线程调用aio_read函数向内核注册socket上读完成事件,并告诉内核用户读缓冲区的位置,以及读操作完成时如何通知应用程序(这里以信号为例)。
-
- 主线程继续处理其他逻辑
-
- 当socket上的数据被读入用户缓冲区后,内核将向应用程序发送一个信号,以通知应用程序数据已经可用。
-
- 应用程序预先定义好的信号处理函数选择一个工作线程来处理客户请求。工作线程处理完客户请求之后,调用aio_write函数向内核注册socket上的写完成事件,并告诉内核用户写缓冲区的位置,以及写操作完成时如何通知应用程序(这里以信号为例)。
-
- 主线程继续处理其他逻辑
-
- 当用户缓冲区的数据被写入socket之后,内核将向应用程序发送一个信号,以通知应用程序数据已经发送完毕。
-
- 应用程序预先定义好的信号处理函数选择一个工作线程来做善后处理,比如决定是否关闭socket。
-
-
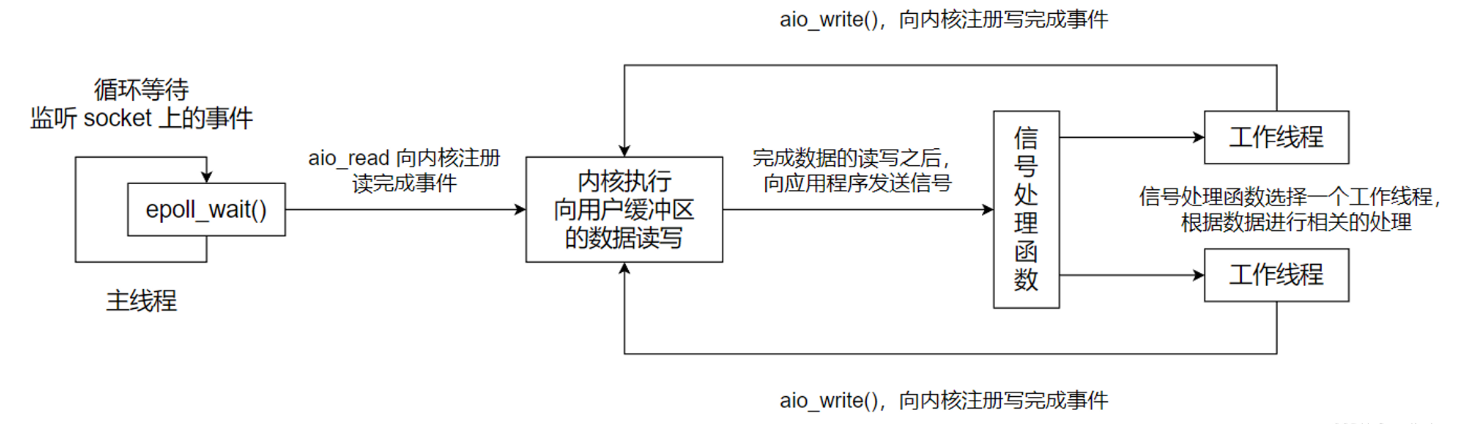
-
在上图中,连接socket上的读写事件是通过aio_read/aio_write向内核注册的,因此内核将通过信号来向应用程序报告连接socket上的读写事件。所以,主线程的epoll_wait调用仅能用来检测监听socket上的连接请求事件,而不能用来检测连接socket的读写事件。
(3)使用同步I/O模拟 Proactor 模式
- 主线程执行数据读写操作,读写完成之后,主线程向工作线程通知这一“完成事件”。那么从工作线程的角度来看,它们就直接获得了数据读写的结果,接下来要做的只是对读写的结果进行逻辑处理。
- 使用同步I/O模型(仍然以epoll_wait为例)模拟出的Proactor模式的工作流程如下:
-
- 主线程往epoll内核事件表中注册socket上的读就绪事件。
-
- 主线程调用epoll_wait等待socket上有数据可读。
-
- 当socket上有数据可读时,epoll_wait通知主线程。主线程从socket循环读取数据,直到没有更多数据可读,然后将读取到的数据封装成一个请求对象并插入请求队列。
-
- 睡眠在请求队列上的某个工作线程被唤醒,它获得请求对象并处理客户请求,然后往epoll内核事件表中注册socket上的写就绪事件。
-
- 主线程调用epoll_wait等到socket可写。
-
- 当socket可写时,epoll_wait通知主线程。主线程往socket上写入服务器处理客户请求的结果。
-
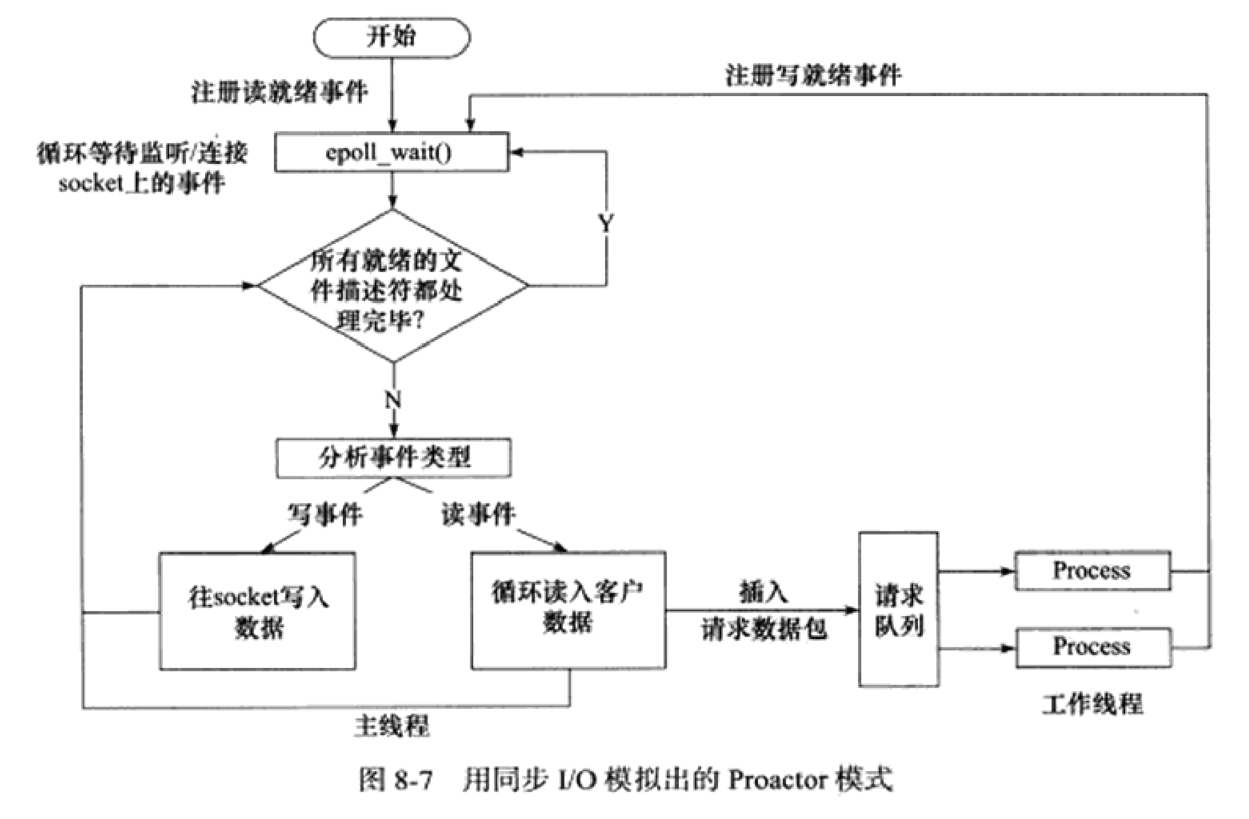
8.5 两种高效的并发模式
- 并发编程的目的是让程序“同时”执行多个任务。如果程序是计算密集型的,并发编程并没有优势,反而由于任务的切换是运行效率降低。但如果程序是I/O密集型的,如经常访问读写文件,访问数据库等,情况就不一样了。由于I/O操作的速度远没有CPU的计算速度快,所以让程序阻塞于I/O操作将浪费大量的CPU时间,如果程序有多个执行线程,则当前被I/O操作所阻塞的执行线程可主动放弃CPU(或有操作系统来调度),并将执行权转移到其他线程。如此,CPU就可以用来做其他的任务,而不是等待I/O操作完成,因此CPU的利用率显著提升。
- 并发编程主要有多进程和多线程两种方式。
- 并发模式是指I/O处理单元和多个逻辑单元之间协调完成任务的方法。服务器主要有两种并发编程模式:半同步/半异步(half-sync/half-async)模式和领导者/追随者(Leader/flowers)模式。
8.5.1 半同步/半异步模式
-
在I/O模型中,“同步”和“异步”区分的是内核向应用程序通知的是何种I/O事件(是就绪事件还是完成事件),以及该由谁来完成I/O读写(是应用程序还是内核)。
-
而在并发模式中,”同步“指的是程序完成按照代码序列的顺序执行;“异步”指的是程序的执行需要操纵系统事件来驱动。常见的系统事件包括中断、信号等。按照同步方式运行的线程称为同步线程,按照异步方式运行的线程称为异步线程。显然,异步线程的执行效率高,实时性强,但是编写异步方式执行的程序相对复杂,难以调试和扩展,而且不适合大量的并发。而同步线程则相反,他虽然效率低,实时性差,但逻辑简单。
-
因此像服务器这种既要求较好的实时性,又要求同时处理多个客户端请求的应用程序,我们就应该同时使用同步线程和异步线程来实现,即采用半同步/半异步模式来实现。
-

-
在半同步/半异步模式中:
- 同步线程用于处理客户逻辑,相当于服务器基本框架图中的逻辑单元;
- 异步线程用于处理I/O请求, 相当于服务器基本框架图中的I/O处理单元。
-
异步线程监听到客户请求后,就将其封装成请求对象并插入请求队列中。请求队列将通知某个工作在同步模式的工作线程来读取并处理该请求对象。具体选择哪个工作线程来为新的客户请求服务,则取决于请求队列的设计。
- 比如最简单的轮流选取工作线程的Round Robin算法,也可以通过条件变量或信号量来随机地选择一个工作线程。
-
半同步/半异步模式的工作流程如下图所示:
-

(1)半同步/半反应堆模式
-
在服务器程序中,如果结合两种事件处理模式和几种I/O模型,则半同步/半异步模式就存在在多种变体。其中有一种变体称为半同步/半反应堆(half-sync/half-reactive)模式。
-
在这种模式下,异步线程只有一个,由主线程来充当。他负责监听所有socket上的事件。如果监听socket上有可读事件发生,既有新的连接请求到来,主线程就接受之以得到的新的连接socket,然后往epoll内核事件表上注册该socket上的读写事件。如果连接socket上有读写事件发生,即有新的客户请求到来或者有数据要发送至客户端,主线程就将该连接socket插入请求队列中。
-
所有的工作线程都睡眠在该请求队列中,当有任务到来时,他们通过竞争(比如申请互斥锁)获得任务的接管权。这种竞争机制使得只有空闲的工作线程才有机会来处理新任务,这是很合理的。
-
需要注意的是,主线程和工作线程共享请求队列,才能实现这种功能。
-
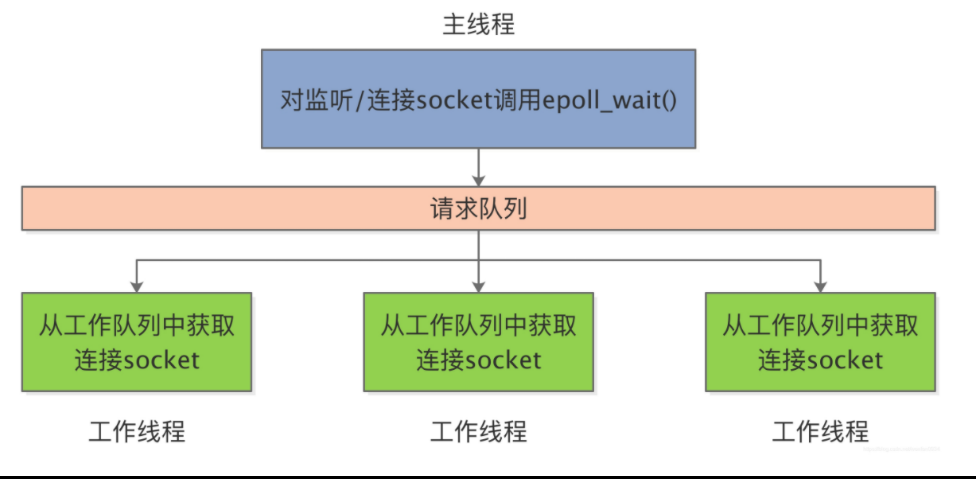
-
在上图中,主线程插入请求队列中的任务是就绪的连接socket。这说明该图所示的半同步/半反应堆模式采用的事件处理模式是Reactor模式:它要求工作线程自己从socket上读取客户请求和往socket写入服务器应答。这就是该模式的名称中“half-reactive”的含义。
-
实际上,半同步/半反应堆模式也可以使用模拟的Proactor事件处理模式,即由主线程来完成数据的读写。在这种情况下,主线程一般会将应用程序数据、任务类型等信息封装为一个任务对象,然后将其(或者指向该任务对象的一个指针)插入请求队列。工作线程从请求队列中取得任务对象之后,即可直接处理之,而无须执行读写操作了。
-
半同步/半反应堆模式有以下两个缺点
- 1、主线程和工作线程共享请求队列。主线程往请求队列中添加任务,或者工作线程从请求队列中取出任务,都需要对请求队列加锁保护,从而耗费了CPU。
- 2、每个工作线程在同一时间只能处理一个客户请求。如果客户端数量较多,而工作线程较少,则请求队列中将堆积很多任务对象,客户端的响应速度将越来越慢。如果通过增加工作线程来解决这一问题,则工作线程的切换也将耗费大量的CPU时间。
(2)高效的半同步/半异步模式
- 下图描述了一种相对高效的半同步/半异步模式,它的每个工作线程都能同时处理多个客户连接。
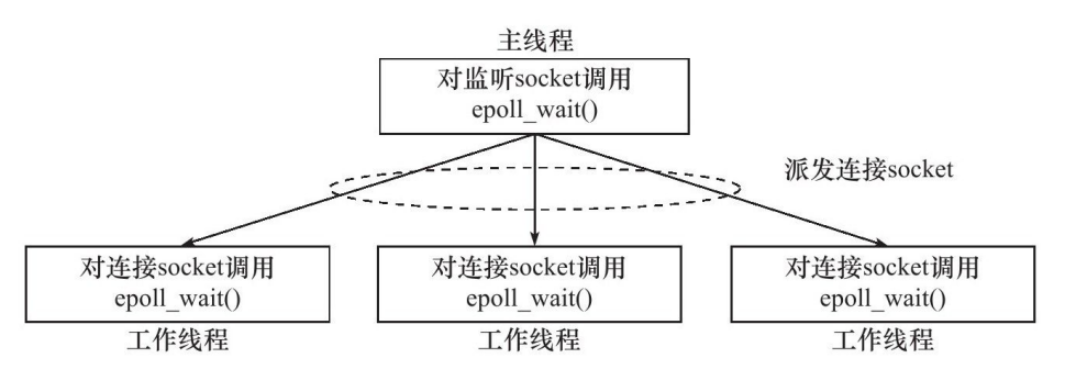
- 主线程只管理监听socket,连接socket由工作线程来管理。
- 当有新的连接到来时,主线程就接受之并将新返回的连接socket派发给某个工作线程,此后该新socket上的任何I/O操作都能由被选中的工作线程来处理,直到客户关闭连接。主线程向工作线程派发socket的最简单的方式,是往它和工作线程之间的管道pipe里写数据。
- 工作线程监测到管道上由数据可读时,就分析是否是一个新的客户连接请求到来。如果是,则把该新socket上的读写事件注册到自己的epoll内核事件表中。
- 上图每个线程(主线程和工作线程)都维持自己的事件循环,他们各自独立地监听不同的事件。因此,在这种高效的半同步/半异步模式中,每个线程都工作在异步模式,所以它并非严格意义上的半同步/半异步模式。
- 正是因为每个工作线程都调用epoll_wait,因此每个工作线程都能同时处理多个客户连接。这也是为什么该模式相对高效的原因。
(3)两者的区别
- 半同步/半反应堆模式只有主线程一个异步线程(epoll);高效的半同步/半异步模式每个线程都工作在异步模式(epoll)。
- 对半同步/半反应堆模式来说,一个客户连接上的所有任务不一定是一个子线程处理的;而对高效的半同步/半异步模式来说,一个客户连接上的所有任务始终是由一个子进程来处理的。
8.5.2 领导者/追随者模式
-
领导者/追随者模式是多个工作线程轮流获得事件源集合,轮流监听、分发并处理事件的一种模式。在任意时间点,程序都仅有一个领导者线程,它负责监听I/O事件。而其他线程则都是追随者,它们休眠在线程池中等待成为新的领导者。当前的领导者如果检测到I/O事件,首先要从线程池中推选出新的领导者线程,然后处理I/O事件。此时,新的领导者等待新的I/O事件,而原来的领导者则处理I/O事件,二者实现了并发。
-
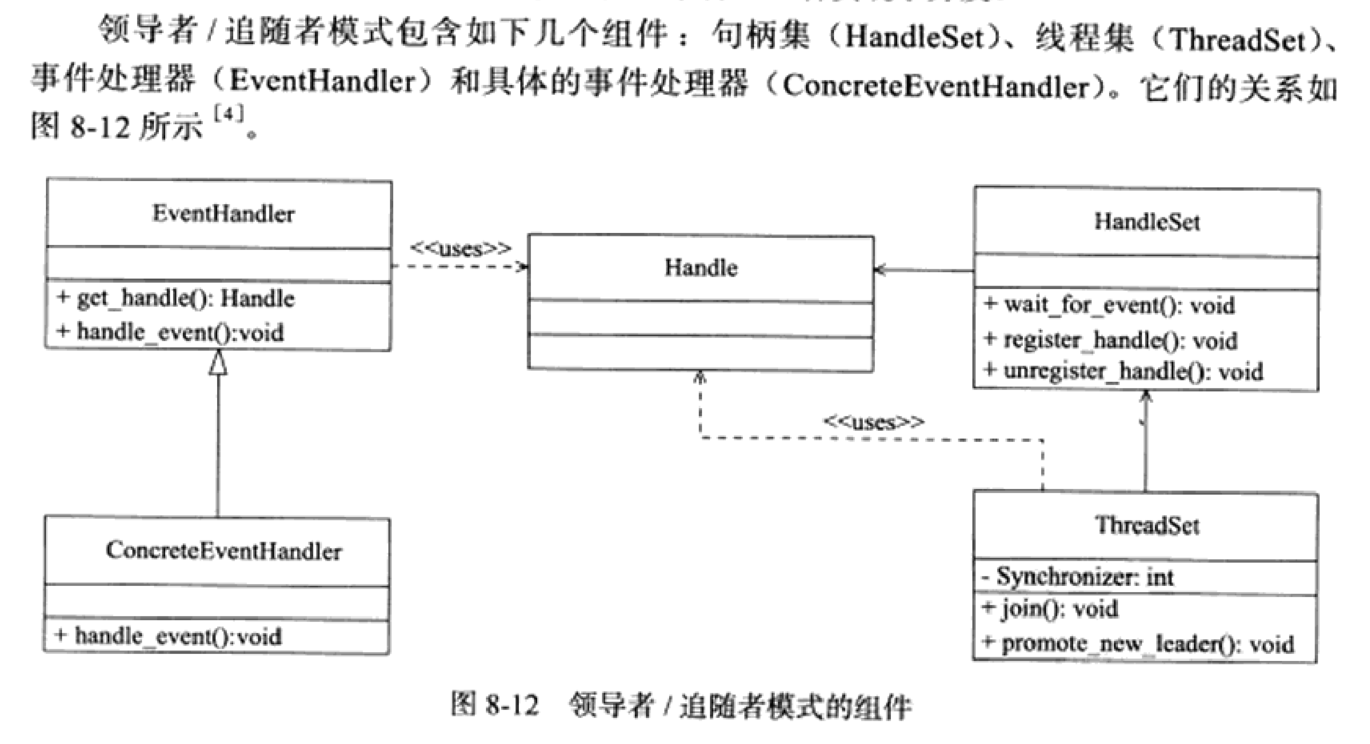
-
在领导者/追随者模式中,通常会有一个领导者线程和多个追随者线程。领导者线程负责处理句柄集,从句柄集中选择任务并将其分配给追随者线程进行处理或自己处理。
-
(1)句柄集HandleSet
句柄用于表示I/O资源,在linux下通常就是一个文件描述符fd,句柄集管理众多句柄(文件描述符、套接字等),使用wait_for_event方法来监听这些句柄上的I/O事件,并将其中就绪事件通知给领导线程。领导者则调用绑定在Handle上的事件处理器来处理I/O事件。领导者将Handle绑定到事件处理器上的方法是register_handle。unregister_handle函数用于解绑句柄和事件处理器。
-
(2)线程集ThreadSet
-
这个组件是所有工作线程(包括领导者线程和追随者线程)的管理者,它主要负责线程的同步,以及线程新领导的推选。
-
线程集中的线程在任一时间必处于如下三种状态:
-
Leader:线程处于领导者,负责等待句柄集上的I/O事件。
-
Processing:线程正在处理事件。领导者检测到I/O事件之后,可以转移到Processing状态来处理该事件,并调用promote_new_leader方法推选新的领导者;也可以指定其他追随者来处理事件(Event Handoff),此时领导者的地位不变。当处于Processing状态的线程处理完事件之后,如果当前线程集中没有领导者,则它将成为新的领导者,否则它就直接转变为追随者。
-
Follower:线程处于追随者,调用join方法等待成为新的领导者,或者被当前领导者指定处理事件。
-
-
需要注意的是,领导者线程推选新的领导者和追随者等待成为新领导者这两个操作都将修改线程集,因此线程集提供一个成员Synchronizer来同步这两个操作,以避免竞态条件。
-
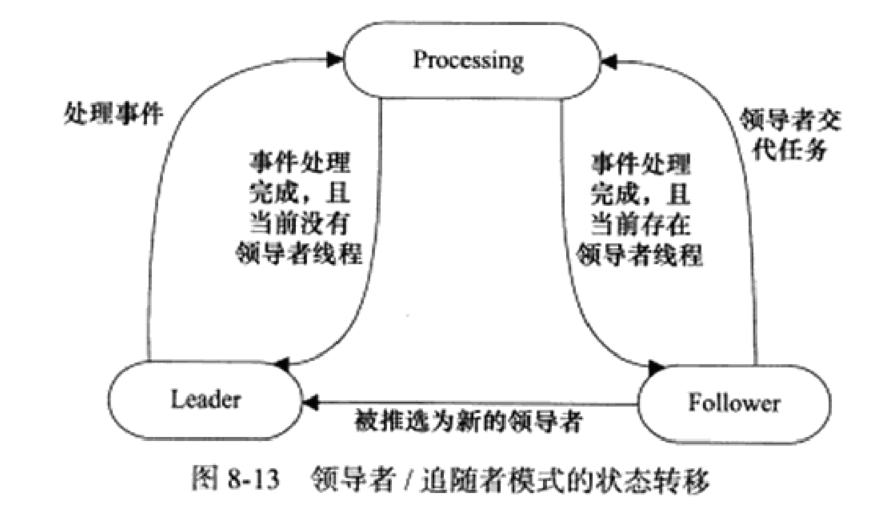
-
(3)事件处理器和具体的事件处理器
-
事件处理器通常包含一个或者多个回调函数handle_event。这些回调函数用于对应的业务逻辑。事件处理器在使用前就被绑定到某个句柄上,当事件发生的时候,领导者就会执行与之绑定的事件处理器中的回调函数。具体的事件处理器是事件处理器的派生类。他们必须重新实现基类中的handle_event方法,用于处理特定事件。
-
(4)工作流程
-
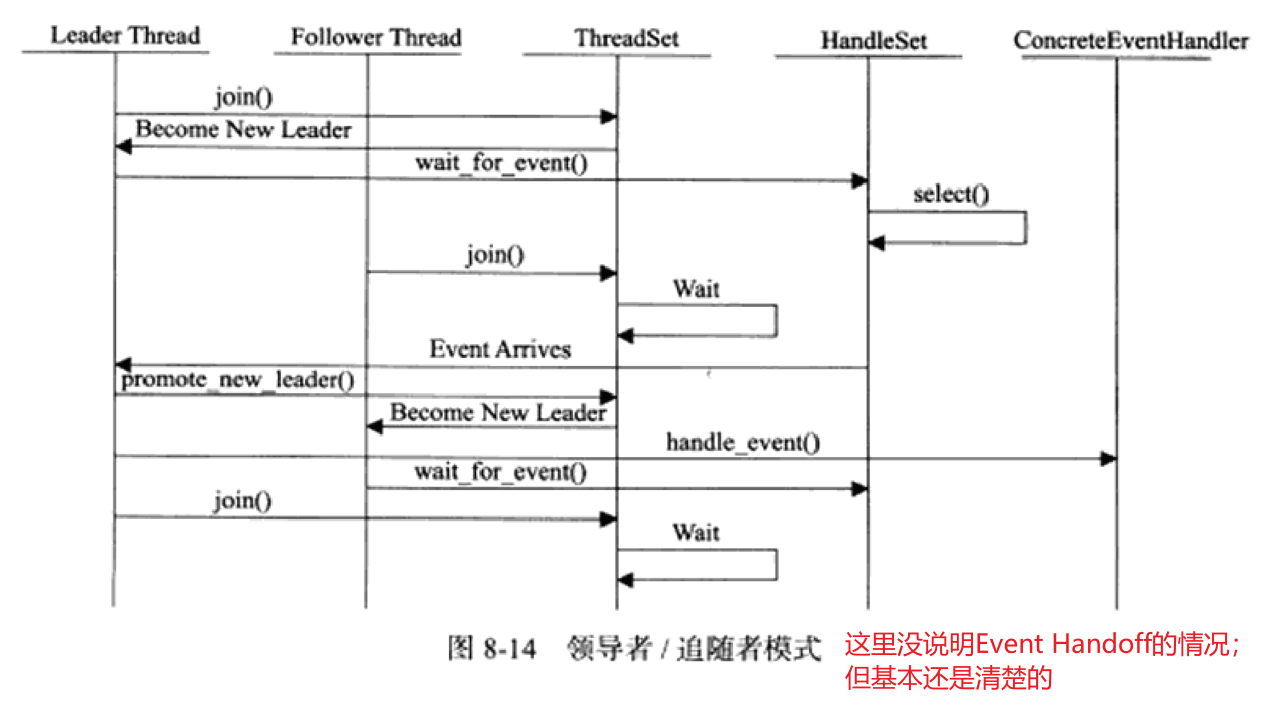
-
优势:
- 不需要在线程之间传递任何额外的数据(领导者自己监听I/O事件并处理请求);
- 线程之间无须同步队请求队列的访问(对比半同步/半反应堆模式)。
-
缺陷:
- 仅支持一个事件源集合,无法(像高效的半同步/半异步模式一样)让每个工作线程独立地管理多个客户连接。
-

8.6 有限状态机 FSM
-
有限状态机(finite state machine)简称FSM,表示有限个状态及在这些状态之间的转移和动作等行为的数学模型,在计算机领域有着广泛的应用。FSM是一种逻辑单元内部的一种高效编程方法,在服务器编程中,服务器可以根据不同状态或者消息类型进行相应的处理逻辑,使得程序逻辑清晰易懂。
-
那有限状态机通常在什么地方被用到?
处理程序语言或者自然语言的tokenizer,自底向上解析语法的parser,各种通信协议发送方和接受方传递数据对消息处理,游戏AI等都有应用场景。
-
一般使用switch语句实现的FSM的结构很清晰了,但其缺点也是明显的:这种设计方法虽然简单,通过一大堆判断来处理,适合小规模的状态切换流程,但如果规模扩大难以扩展和维护。
-
对于程序规模过大的,可以使用函数指针实现FSM。
-

-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> #define BUFFER_SIZE 4096 enum CHECK_STATE { CHECK_STATE_REQUESTLINE = 0, CHECK_STATE_HEADER, CHECK_STATE_CONTENT }; enum LINE_STATUS { LINE_OK = 0, LINE_BAD, LINE_OPEN }; enum HTTP_CODE { NO_REQUEST, GET_REQUEST, BAD_REQUEST, FORBIDDEN_REQUEST, INTERNAL_ERROR, CLOSED_CONNECTION }; static const char *szret[] = {"I get a correct result\n", "Something wrong\n"}; LINE_STATUS parse_line(char *buffer, int &checked_index, int &read_index) { char temp; for (; checked_index < read_index; ++checked_index) { temp = buffer[checked_index]; if (temp == '\r') { if ((checked_index + 1) == read_index) { return LINE_OPEN; } else if (buffer[checked_index + 1] == '\n') { buffer[checked_index++] = '\0'; buffer[checked_index++] = '\0'; return LINE_OK; } return LINE_BAD; } else if (temp == '\n') { if ((checked_index > 1) && buffer[checked_index - 1] == '\r') { buffer[checked_index - 1] = '\0'; buffer[checked_index++] = '\0'; return LINE_OK; } return LINE_BAD; } } return LINE_OPEN; } HTTP_CODE parse_requestline(char *szTemp, CHECK_STATE &checkstate) { char *szURL = strpbrk(szTemp, " \t"); if (!szURL) { return BAD_REQUEST; } *szURL++ = '\0'; char *szMethod = szTemp; if (strcasecmp(szMethod, "GET") == 0) { printf("The request method is GET\n"); } else { return BAD_REQUEST; } szURL += strspn(szURL, " \t"); char *szVersion = strpbrk(szURL, " \t"); if (!szVersion) { return BAD_REQUEST; } *szVersion++ = '\0'; szVersion += strspn(szVersion, " \t"); if (strcasecmp(szVersion, "HTTP/1.1") != 0) { return BAD_REQUEST; } if (strncasecmp(szURL, "http://", 7) == 0) { szURL += 7; szURL = strchr(szURL, '/'); } if (!szURL || szURL[0] != '/') { return BAD_REQUEST; } // URLDecode( szURL ); printf("The request URL is: %s\n", szURL); checkstate = CHECK_STATE_HEADER; return NO_REQUEST; } HTTP_CODE parse_headers(char *szTemp) { if (szTemp[0] == '\0') { return GET_REQUEST; } else if (strncasecmp(szTemp, "Host:", 5) == 0) { szTemp += 5; szTemp += strspn(szTemp, " \t"); printf("the request host is: %s\n", szTemp); } else { printf("I can not handle this header\n"); } return NO_REQUEST; } HTTP_CODE parse_content(char *buffer, int &checked_index, CHECK_STATE &checkstate, int &read_index, int &start_line) { LINE_STATUS linestatus = LINE_OK; HTTP_CODE retcode = NO_REQUEST; while ((linestatus = parse_line(buffer, checked_index, read_index)) == LINE_OK) { char *szTemp = buffer + start_line; start_line = checked_index; switch (checkstate) { case CHECK_STATE_REQUESTLINE: { retcode = parse_requestline(szTemp, checkstate); if (retcode == BAD_REQUEST) { return BAD_REQUEST; } break; } case CHECK_STATE_HEADER: { retcode = parse_headers(szTemp); if (retcode == BAD_REQUEST) { return BAD_REQUEST; } else if (retcode == GET_REQUEST) { return GET_REQUEST; } break; } default: { return INTERNAL_ERROR; } } } if (linestatus == LINE_OPEN) { return NO_REQUEST; } else { return BAD_REQUEST; } } int main(int argc, char *argv[]) { if (argc <= 2) { printf("usage: %s ip_address port_number\n", basename(argv[0])); return 1; } const char *ip = argv[1]; int port = atoi(argv[2]); struct sockaddr_in address; bzero(&address, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int listenfd = socket(PF_INET, SOCK_STREAM, 0); assert(listenfd >= 0); int ret = bind(listenfd, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(listenfd, 5); assert(ret != -1); struct sockaddr_in client_address; socklen_t client_addrlength = sizeof(client_address); int fd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength); if (fd < 0) { printf("errno is: %d\n", errno); } else { char buffer[BUFFER_SIZE]; memset(buffer, '\0', BUFFER_SIZE); int data_read = 0; int read_index = 0; int checked_index = 0; int start_line = 0; CHECK_STATE checkstate = CHECK_STATE_REQUESTLINE; while (1) { data_read = recv(fd, buffer + read_index, BUFFER_SIZE - read_index, 0); if (data_read == -1) { printf("reading failed\n"); break; } else if (data_read == 0) { printf("remote client has closed the connection\n"); break; } read_index += data_read; HTTP_CODE result = parse_content(buffer, checked_index, checkstate, read_index, start_line); if (result == NO_REQUEST) { continue; } else if (result == GET_REQUEST) { send(fd, szret[0], strlen(szret[0]), 0); break; } else { send(fd, szret[1], strlen(szret[1]), 0); break; } } close(fd); } close(listenfd); return 0; }
8.7 提高服务器性能的其他建议
(1)池
- 空间换时间。
- 根据不同的资源类型,池可分为多种,常见的有内存池、进程池、线程池和连接池。它们的含义都很明确。
- 内存池通常用于socket的接收缓存和发送缓存。对于某些长度有限的客户请求,比如HTTP请求,预先分配一个大小足够(比如5000字节)的接收缓存区是很合理的。当客户请求的长度超过接收缓冲区的大小时,我们可以选择丢弃请求或者动态扩大接收缓冲区。
- 进程池和线程池都是并发编程常用的“伎俩”。当我们需要一个工作进程或工作线程来处理新到来的客户请求时,我们可以直接从进程池或线程池中取得一个执行实体,而无须动态地调用fork或pthread_create等函数来创建进程和线程。
- 连接池通常用于服务器或服务器机群的内部永久连接。针对每个逻辑单元可能都需要频繁地访问本地的某个数据库的情景,简单的做法是:逻辑单元每次需要访问数据库的时候,就向数据库程序发起连接,而访问完毕后释放连接。很显然,这种做法的效率太低。一种解决方案是使用连接池。连接池是服务器预先和数据库程序建立的一组连接的集合。当某个逻辑单元需要访问数据库时,它可以直接从连接池中取得一个连接的实体并使用之。待完成数据库的访问之后,逻辑单元再将该连接返还给连接池。
(2)数据复制
- 高性能服务器应该避免不必要的数据复制,尤其是当数据复制发生在用户代码和内核之间的时候。如果内核可以直接处理从socket或者文件读入的数据,则应用程序就没必要将这些数据从内核缓冲区复制到应用程序缓冲区中。这里说的“直接处理”指的是应用程序不关心这些数据的内容,不需要对它们做任何分析。比如即服务器,当客户请求一个文件时,服务器只需要检测目标文件是否存在,以及客户是否有读取它的权限,而绝对不会关心文件的具体内容。这样的话,即服务器就无须把目标文件的内容完整地读人到应用程序缓冲区中并调用send函数来发送,而是可以使用“零拷贝”函数sendfile来直接将其发送给客户端。
- 此外,用户代码内部(不访问内核)的数据复制也是应该避免的。举例来说,当两个工作进程之间要传递大量的数据时,我们就应该考虑使用共享内存来在它们之间直接共享这些数据,而不是使用管道或者消息队列来传递。说白了,就是避免用户缓冲区和内核缓冲区的数据复制,提高效率。
(3)上下文切换和锁
- 并发程序必须考虑上下文切换(context switch)的问题,即进程切换或线程切换导致的的系统开销。即使I/O密集型的服务器,也不应该使用过多的工作线程(或工作进程,下同),否则线程间的切换将占用大量的CPU时间,服务器真正用于处理业务逻辑的CPU时间的比重就显得不足了。因此,为每个客户连接都创建一个工作线程的服务器模型是不可取的。8.5所描述的高效的半同步/半异步模式是一种比较合理的解决方案,它允许一个线程同时处理多个客户连接。此外,多线程服务器的一个优点是不同的线程可以同时运行在不同的CPU上。当线程的数量不大于CPU的数目时,上下文的切换就不是问题了。
- 并发程序需要考虑的另外一个问题是共享资源的加锁保护。锁通常被认为是导致服务器效率低下的一个因素,因为由它引入的代码不仅不处理任何业务逻辑,而且需要访问内核资源。因此,服务器如果有更好的解决方案,就应该避免使用锁。显然,8.5所描述的高效的半同步/半异步模式就比半同步/半反应堆模式的效率高。如果服务器必须使用“锁”,则可以考虑减小锁的粒度,比如使用读写锁。当所有工作线程都只读取一块共享内存的内容时,读写锁并不会增加系统的额外开销。只有当其中某一个工作线程需要写这块内存时,系统才必须去锁住这块区域。
第9章 I/O 复用
- I/O复用使得程序能同时监听多个文件描述符,这对提高程序的性能至关重要。通常,网络程序在下列情况下需要使用I/O复用技术
- 客户端程序要同时处理多个socket。
- 客户端程序要同时处理用户输入和网络连接。
- TCP服务器要同时处理监听socket和连接socket。这是I/O复用使用最多的场合。
- 服务器要同时处理TCP请求和UDP请求。
- 服务器要同时监听多个端口,或者处理多种服务。
- 需要指出的是,I/O复用虽然能同时监听多个文件描述符,但它本身是阻塞的。并且当多个文件描述符同时就绪时,如果不采取额外的措施,程序就只能按顺序依次处理其中的每一个文件描述符,这使得服务器程序看起来像是串行工作的。如果要实现并发,只能使用多进程或多线程等编程手段。
- Linux下实现I/O复用的系统调用主要有select、poll和epoll。
- 本质上,I/O复用即为是I/O事件通知机制。
9.1 select 系统调用
(1)select API
-
select系统调用的原型如下
-
1 2 3#include <sys/select.h> int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout); -
1)nfds参数指定被监听的文件描述符的总数。它通常被设置为select监听的所有文件描述符中的最大值加1,因为文件描述符是从0开始计数的。
-
2)readfds、writefds和exceptfds参数分别指向可读、可写和异常等事件对应的文件描述符集合。应用程序调用select函数时,通过这3个参数传人自己感兴趣的文件描述符。select调用返回时,内核将修改它们来通知应用程序哪些文件描述符已经就绪(就绪的文件描述符fd位被置1)。这3个参数是fd_set结构指针类型。fd_set结构体的定义如下:
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17#include <typesizes.h> #define __FD_SETSIZE 1024 #include <sys/select.h> #define FD_SETSIZE __FD_SETSIZE typedef long int __fd_mask; #undef __NFDBITS #define __NFDBITS (8 * (int)sizeof(__fd_mask)) typedef struct { #ifdef __USE_XOPEN __fd_mask fds_bits[__FD_SETSIZE / __NFDBITS]; #define __FDS_BITS(set) ((set)->fds_bits) #else __fd_mask __fds_bits[__FD_SETSIZE / __NFDBITS]; #define __FDS_BITS(set) ((set)->__fds_bits) #endif } fd_set; -
由以上定义可见,fd_set结构体仅包含一个整型数组,该数组的每个元素的每一位(bit)标记一个文件描述符。fd_set能容纳的文件描述符数量由
FD_SETSIZE指定(默认1024位),这就限制了select能同时处理的文件描述符的总量。且这1024个文件描述符的最大值不能超过1023(0-1023表示1024位)。 -
因为位操作过于繁琐,我们可通过下列宏可以访问 fd_set 结构中的位:
-
1 2 3 4 5#include <sys/select.h> void FD_ZERO(fd_set *fdset); // 清除 fdset 的所有位,置0 void FD_SET(int fd, fd_set *fdset); // 设置 fdset 的位 fd,置位fd为1,这样fd文件描述符就被加入fdset了 void FD_CLR(int fd, fd_set *fdset); // 清除 fdset 的位 fd,置位fd为0,这样fd文件描述符就从fdset删除了 int FD_ISSET(int fd, fd_set *fdset);// 测试 fdset 的位 fd位 是否被设置为1 -
值得注意的是,这3个参数中的任意一个(或全部)可以是空指针NULL,当你不需要进行操作判断读、写、异常的时候可以这么做。
-
3)timeout参数用来设置select函数的超时时间。它是一个timeval结构类型的指针,采用指针参数是因为内核将修改它以告诉应用程序select等待了多久。不过我们不能完全信任select调用返回后的timeout值,比如调用失败时timeout值是不确定的。timeval结构体的定义如下:
-
1 2 3 4 5struct timeval { long tv_sec; //秒数 long tv_usec; // 微秒数 }; -
由以上定义可见,select给我们提供了一个微秒级的定时方式。如果给timeout变量的tv_sec成员和ty_usec成员都传递0,则select将立即返回。如果给timeout传递NULL,则select将一直阻塞,直到某个文件描述符就绪。
-
4)返回值
-
select成功时返回就绪(可读、可写和异常)文件描述符的总数。
-
如果在超时时间内没有任何文件描述符就绪,select将返回0。
-
select失败时返回-1并设置errno。
-
如果在select等待期间,程序接收到信号,则select立即返回-1,并设置errno为EINTR。
(2)文件描述符就绪条件
- 哪些情况下文件描述符可以被认为是可读、可写或者出现异常(即文件描述符已就绪),对于select的使用非常关键。
- 在网络编程中,下列情况下socket可读:
- socket内核接收缓存区中的字节数大于或等于其低水位标记SO_RCVLOWAT,此时我们可以无阻塞地读该socket,并且读操作返回的字节数大于0。
- socket通信的对方关闭连接。此时对该socket的读操作将返回0。
- 监听socket上有新的连接请求。
- socket上有未处理的错误。此时我们可以使用getsockopt来读取和清除该错误。
- 下列情况下socket可写:
- socket内核发送缓存区中的可用字节数大于或等于其低水位标记SO_SNDLOWAT。此时我们可以无阻塞地写该socket,并且写操作返回的字节数大于0。
- socket的写操作被关闭。对写操作被关闭的socket执行写操作将触发一个SIGPIPE信号。
- socket使用非阻塞connect连接成功或者失败(超时)之后。
- socket上有未处理的错误。此时我们可以使用getsockopt来读取和清除该错误。
- 网络程序中,select 能处理的异常情况只有一种:socket 上接收到带外数据(紧急数据)。
(3)处理带外数据
-
socket上接收到普通数据和带外数据都将使select返回,但socket处于不同的就绪状态:前者处于可读状态,后者处于异常状态。
-
以下代码描述了select是如何同时处理二者的。
-
这里说明下 fd_set 结构中位操作函数的调用过程:
- 1、在对文件描述符集合进行设置前,必须对其进行初始化,通过FD_ZERO;
- 2、每次调用select,都需要调用FD_SET重置文件描述符;因为事件发生以后,文件描述符集合将被内核修改;
- 3、调用select后,通过FD_ISSET判断文件描述符是否就绪;
-
在连接建立时设定了 OOB_INLINE 标志位,则应使用不带 MSG_OOB 的 recv 接收OOB数据,因为 OOB 数据已经被当作惯常数据来处理了。
-
而没有设置 OOB_INLINE 标志位,则应使用携带 MSG_OOB 的 recv 接收数据OOB数据。
-
服务器代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <sys/types.h> #include <unistd.h> int main(int argc, char *argv[]) { const char *ip = "192.168.141.128"; int port = 12345; printf("ip is %s and port is %d\n", ip, port); int ret = 0; struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int listenfd = socket(PF_INET, SOCK_STREAM, 0); assert(listenfd >= 0); ret = bind(listenfd, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(listenfd, 5); assert(ret != -1); struct sockaddr_in client_address; socklen_t client_addrlength = sizeof(client_address); int connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength); if (connfd < 0) { printf("errno is: %d\n", errno); close(listenfd); } char remote_addr[INET_ADDRSTRLEN]; printf("connected with ip: %s and port: %d\n", inet_ntop(AF_INET, &client_address.sin_addr, remote_addr, INET_ADDRSTRLEN), ntohs(client_address.sin_port)); char buf[1024]; fd_set read_fds; fd_set exception_fds; // 首先置0 FD_ZERO(&read_fds); FD_ZERO(&exception_fds); while (1) { // 初始化字符串 memset(buf, 0, sizeof(buf)); /*每次调用select之前都要重新在read_fds和exception_fds中设置文件描述符connfd,因为事件发生以后,文件描述符集合将被内核修改*/ FD_SET(connfd, &read_fds); FD_SET(connfd, &exception_fds); ret = select(connfd + 1, &read_fds, NULL, &exception_fds, NULL); if (ret < 0) { printf("selection failure\n"); break; } // 处理正常的数据 if (FD_ISSET(connfd, &read_fds)) { memset(buf, 0, sizeof(buf)); ret = recv(connfd, buf, sizeof(buf) - 1, 0); if (ret <= 0) { break; } printf("get %d bytes of normal data: %s\n", ret, buf); } // 处理OOB数据 if (FD_ISSET(connfd, &exception_fds)) { memset(buf, 0, sizeof(buf)); ret = recv(connfd, buf, sizeof(buf) - 1, MSG_OOB); if (ret <= 0) { break; } printf("get %d bytes of oob data: %s\n", ret, buf); } } close(connfd); close(listenfd); return 0; } -
客户端代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36#include <arpa/inet.h> #include <assert.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> int main(int argc, char *argv[]) { const char *ip = "192.168.141.128"; int port = 12345; struct sockaddr_in server_address; memset(&server_address, 0, sizeof(server_address)); server_address.sin_family = AF_INET; inet_pton(AF_INET, ip, &server_address.sin_addr); server_address.sin_port = htons(port); int sockfd = socket(PF_INET, SOCK_STREAM, 0); assert(sockfd >= 0); if (connect(sockfd, (struct sockaddr *)&server_address, sizeof(server_address)) < 0) { printf("connection failed\n"); } else { printf("send oob data out\n"); const char *oob_data = "abc"; const char *normal_data = "123"; send(sockfd, normal_data, strlen(normal_data), 0); send(sockfd, oob_data, strlen(oob_data), MSG_OOB); // 使用 MSG_OOB标记 send(sockfd, normal_data, strlen(normal_data), 0); } close(sockfd); return 0; } -
实验结果
-
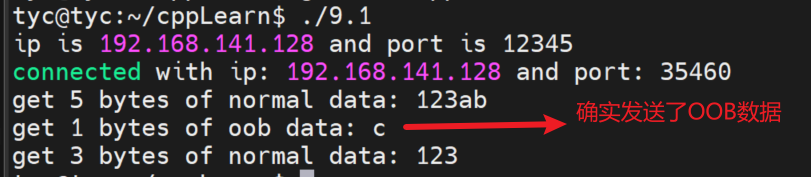
9.2 poll 系统调用
-
poll本身的翻译是轮询的意思。
-
poll系统调用和select类似,也是在指定时间内轮询一定数量的文件描述符,以测试其中是否有就绪者。poll的原型如下:
-
1 2#include <poll.h> int poll(struct pollfd *fds, nfds_t nfds, int timeout); -
(1)fds 参数是一个pollfd 结构类型的数组,他指定所有我们感兴趣的文件描述符上发生的可读、可写和异常等事件。
-
1 2 3 4 5struct pollfd { int fd; /* file descriptor 文件描述符 */ short events; /* requested events 注册的事件 */ short revents; /* returned events 实际发生的事,由内核填充 */ }; -
其中,fd成员指定文件描述符;events成员告诉poll监听fd上的哪些事件,它是下图一系列事件的按位或:revents成员则由内核修改,以通知应用程序fd上实际发生了哪些事件。
-
poll支持的事件类型如下图所示。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28/* Event types that can be polled for. These bits may be set in `events' to indicate the interesting event types; they will appear in `revents' to indicate the status of the file descriptor. */ #define POLLIN 0x001 /* There is data to read. */ #define POLLPRI 0x002 /* There is urgent data to read. */ #define POLLOUT 0x004 /* Writing now will not block. */ #if defined __USE_XOPEN || defined __USE_XOPEN2K8 /* These values are defined in XPG4.2. */ # define POLLRDNORM 0x040 /* Normal data may be read. */ # define POLLRDBAND 0x080 /* Priority data may be read. */ # define POLLWRNORM 0x100 /* Writing now will not block. */ # define POLLWRBAND 0x200 /* Priority data may be written. */ #endif #ifdef __USE_GNU /* These are extensions for Linux. */ # define POLLMSG 0x400 # define POLLREMOVE 0x1000 # define POLLRDHUP 0x2000 #endif /* Event types always implicitly polled for. These bits need not be set in `events', but they will appear in `revents' to indicate the status of the file descriptor. */ #define POLLERR 0x008 /* Error condition. */ #define POLLHUP 0x010 /* Hung up. */ #define POLLNVAL 0x020 /* Invalid polling request. */ -
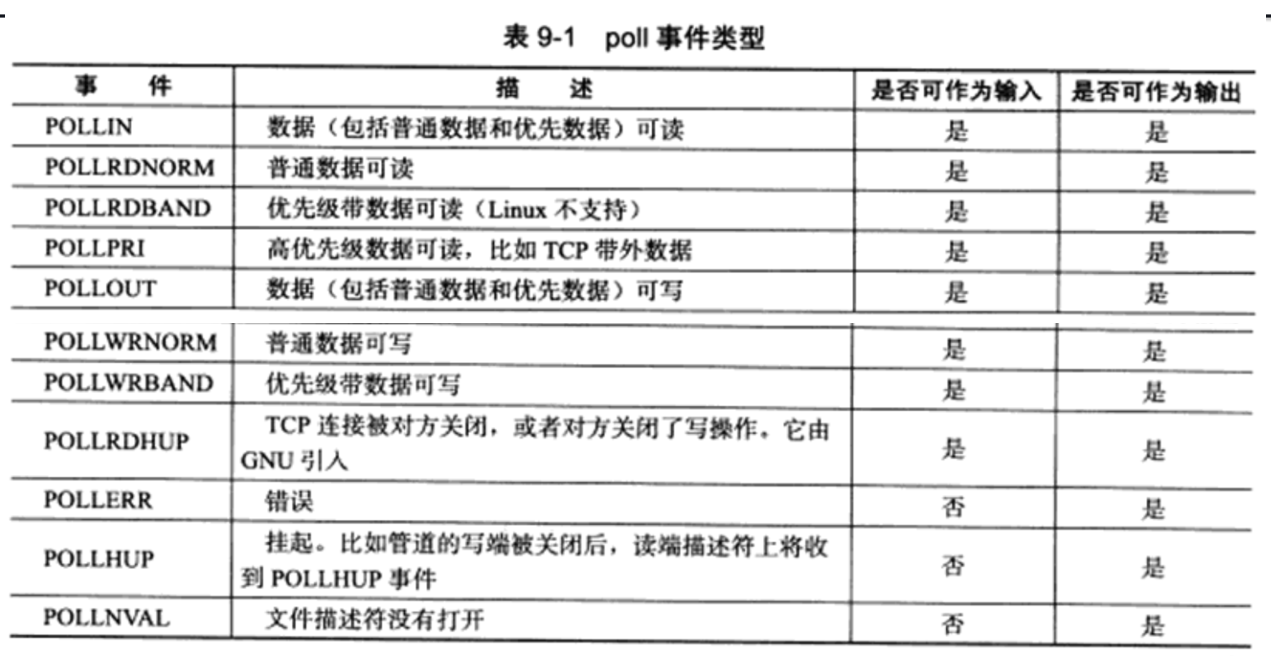
-
(2)nfds参数指定监听事件集合fds的大小(即数组的有效监听个数),类型定义
typedef unsigned long int nfds_t,即无符号长整型。 -
(3)timeout指定poll超时值,单位毫秒,
timeout==-1则poll调用会一直阻塞,当timeout==0,poll调用立刻返回。 -
(4)返回值:大于 0 表示就绪的文件描述符的个数;等于 0 表示超时;返回-1表示失败并设置errno。(和select的调用一样)
-
以下实验代码,使用 poll 系统调用来监控标准输入。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42#include <iostream> #include <poll.h> #include <string> #include <unistd.h> #define FDNUMS 10 #define POLLERROR (-1) using namespace std; int main() { // 构造poll入参 struct pollfd arrFD[FDNUMS]; // 取标准输入 arrFD[0].fd = STDIN_FILENO; arrFD[0].events = POLLIN; // 就监听1个 int nfds = 1; int timeout = 10; loop: int ret = poll(arrFD, nfds, timeout); if (ret == 0) // 超时重新监控 goto loop; else if (ret < 0) // 监控出错 { perror("poll"); return POLLERROR; } // stdin文件描述符已就绪 for (int i = 0; i < 1; i++) { // 从标准输入中读取用户输入的数据,再输出 if (arrFD[i].revents == POLLIN) { char str[1024] = {0}; int n = read(arrFD[i].fd, str, sizeof(str) - 1); str[n] = '\0'; cout << "stdin : " << str; } } return 0; } -

-
值得注意的是,poll 没有 select 跨平台性能优越,poll 也没有 epoll 性能高,故 poll 我们只做简单了解即可。
9.3 epoll 系统调用
9.3.1 内核事件表
-
epoll 是 Linux 特有的I/O复用函数。它在实现和使用上与select、poll 有很大差异。
-
epoll是Linux内核为处理大批量文件描述符而作了改进的poll,是Linux下多路复用I/O接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率。
-
首先,epoll 使用一组函数来完成任务,而不是单个函数。
-
其次,epolI 把用户关心的文件描述符上的事件放在内核里的一个事件表中,从而无须像select和poll那样每次调用都要重复传人文件描述符集或事件集。但epoll需要使用一个额外的文件描述符,来唯一标识内核中的这个事件表。这个文件描述符可以使用
epoll_create函数来创建。 -
(1)epoll_create 函数
-
1 2 3#include <sys/epoll.h> // The fd returned by epoll_create() should be closed with close() int epoll_create(int size); -
size 参数实际只是给内核一个提示,告诉它事件表需要多大(具体由内核实际指定)。该函数返回的文件描述符将用作其他所有epoll系统调用的第一个参数,以指定要访问的内核事件表。
-
需要注意的是,epoll_create() 返回的结果应该用 close() 关闭。
-
(2)epoll_ctl 函数
-
1 2#include <sys/epoll.h> int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event) -
第一个参数 epfd 是 epoll_create() 的返回值,表示要操作的内核事件表。
-
第二个参数 op 表示在操作类型,用三个宏来表示;第三个参数 fd 表示需要监听的文件描述符。
-
1 2 3EPOLL_CTL_ADD:注册新的fd到epfd中; EPOLL_CTL_MOD:修改已经注册的fd的监听事件; EPOLL_CTL_DEL:从epfd中删除一个fd;
-
-
第四个参数 event 指定事件,即告诉内核监听什么事,它是epoll_event结构指针类型。注意这是一个输入参数。epoll_event的定义如下:
-
1 2 3 4struct epoll_event { __uint32_t events; /* Epoll events epoll事件*/ epoll_data_t data; /* User data variable 用户数据*/ }; -
events 成员描述事件类型。epoll支持的事件类型和poll基本相同。表示epoll事件类型的宏是在poll对应的宏前加上“E”,比如epoll的数据可读事件是EPOLLIN。但epoll有两个额外的事件类型一EPOLLET和EPOLLONESHOT。它们对于epoll的高效运作非常关键。events可以是以下几个宏的集合:
-
-
1 2 3 4 5 6 7 8EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭); EPOLLOUT:表示对应的文件描述符可以写; EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来); EPOLLERR:表示对应的文件描述符发生错误; EPOLLHUP:表示对应的文件描述符被挂断; EPOLLRDHUP:表示TCP连接被对方关闭; EPOLLET: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。 EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里。 -
data 成员用于存储用户数据,其类型 epoll_data_t 的定义如下:
-
1 2 3 4 5 6 7typedef union epoll_data { void *ptr; int fd; uint32_t u32; uint64_t u64; } epoll_data_t; -
epoll_data_t 是一个联合体,其4个成员中使用最多的是fd,它指定事件所从属的目标文件描述符。ptr成员可用来指定与fd相关的用户数据。但由于epoll_data_t是一个联合体,我们不能同时使用其ptr成员和fd成员,因此,如果要将文件描述符和用户数据关联起来(如将句柄和事件处理器绑定一样),以实现快速的数据访问,只能使用其他手段,比如放弃使用epoll_data_t的fd成员,而在ptr指向的用户数据中包含fd。
-
-
epoll_ctl 成功时返回0,失败则返回-1并设置errno。
-
注意点:
-
(a)对于
EPOLLERR和EPOLLHUP,不需要在 epoll_event 时针对fd作设置,一样也会触发; -
(b)
EPOLLRDHUP实测在对端关闭时会触发,但对EPOLLRDHUP的处理应该放在EPOLLIN和EPOLLOUT前面,如果采用的是LT触发模式,且没有close相应的fd,EPOLLRDHUP会持续被触发;EPOLLRDHUP想要被触发,需要显式地在epoll_ctl调用时设置在events中;
9.3.2 epoll_wait 函数
-
创建并设置好epoll后,我们需要监听epoll。
-
监听epoll系统调用的主要接口是epoll_wait函数。它在一段超时时间内等待一组文件描述符上的事件,其原型如下:
-
1 2#include <sys/epoll.h> int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout) -
(1)返回值
- 收集在 epoll监控的事件中已经发生的事件,如果 epoll中没有任何一个事件发生,则最多等待timeout毫秒后返回。epoll_wait的返回值表示当前发生的事件个数,如果返回0,则表示本次调用中没有事件发生;如果返回–1,则表示出现错误,需要检查 errno错误码判断错误类型。
-
(2)epfd:内核事件表的文件描述符。
-
(3)events:分配好的 epoll_event 结构体数组,epoll_wait 将会把发生的事件复制到 events 数组中(events不可以是空指针,内核只负责把数据复制到这个 events数组中,不会去帮助我们在用户态中分配内存。内核这种做法效率很高)。
-
(4)maxevents:表示本次可以返回的最大事件数目,通常 maxevents参数与预分配的events数组的大小是相等的。
-
(5)timeout:指定epoll_wait超时值,单位毫秒,
timeout==-1则epoll_wait调用会一直阻塞,当timeout==0,epoll_wait调用立刻返回。 -
epoll_wait函数如果检测到事件,就将所有就绪的事件从内核事件表(由epfd参数指定)中复制到它的第二个参数events指向的数组中。这个数组只用于输出epoll_wait检测到的就绪事件,而不像select和poll的数组参数那样既用于传入用户注册的事件,又用于输出内核检测到的就绪事件。这就极大地提高了应用程序索引就绪文件描述符的效率。
-

9.3.3 LT 和 ET 模式
-
epoll 对文件描述符的操作有两种模式:LT(Level Trigger,电平触发)模式和ET(Edge Trigger,边沿触发)模式。LT模式是默认的工作模式,这种模式下epoll相当于一个效率较高的poll。
-
当往epoll内核事件表中注册一个文件描述符上的EPOLLET事件时,epoll将以ET模式来操作该文件描述符。ET模式是epoll的高效工作模式。
-
对于采用LT工作模式的文件描述符,当epoll_wait 检测到其上有事件发生并将此事件通知应用程序后,应用程序可以不立即处理该事件。这样,当应用程序下一次调用epoll_wait时,epoll_wait 还会再次向应用程序通告此事件,直到该事件被处理。
-
对于采用ET工作模式的文件描述符,当epoll_wait检测到其上有事件发生并将此事件通知应用程序后,应用程序必须立即处理该事件,因为后续的epoll_wait调用将不再向应用程序通知这一事件。可见,ET模式在很大程度上降低了同一个epoll事件被重复触发的次数,因此效率要比LT模式高。
-
这两种模式的区别如下:
- 对于水平触发模式,一个事件只要有,就会一直触发。
- 对于边缘触发模式,在一个事件从无到有时才会触发。
-
以
socket的读事件为例,对于水平模式,只要在socket上有未读完的数据,就会一直产生EPOLLIN事件;而对于边缘模式,socket上每新来以此数据就会触发一次,如果上一次触发后未将socket上的数据读完,也不会再触发,除非再新来一次数据。 -
对于
socket写事件,如果socket的TCP窗口一直不饱和,就会一直触发EPOLLOUT事件;而对于边缘模式,只会触发一次,除非TCP窗口由不饱和变成饱和再一次变成不饱和,才会再次触发EPOLLOUT事件。 -
(1)accept 相关
-
首先accept应设置为无阻塞的,当accept接收到对端连接,会触载
EPOLLIN, 这里可以循环多次调用accept, 直至返回EAGAIN或EWOULDBLOCK, 同时适用于LT和ET,但一般在ET上使用,因为LT会一直触发该信号。 -
(2)recv 相关
-
首先recv应设置为无阻塞的,对于LT模式,因为会一直触发,直接读取即可;对于ET模式,因为只触发一次,因此需要循环多次调用
recv, 直至返回EAGAIN或EWOULDBLOCK错误表示读取完成。 -
以下代码是测试 LT 模式和 ET 模式的区别的。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <pthread.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/epoll.h> #include <sys/socket.h> #include <sys/types.h> #include <unistd.h> #define MAX_EVENT_NUMBER 1024 #define BUFFER_SIZE 10 // 将文件描述符设置为非阻塞的 int setnonblocking(int fd) { int old_option = fcntl(fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl(fd, F_SETFL, new_option); return old_option; } /* 将文件描述符fd上的EPOLLIN注册到epollfd指示的epo1l内核事件表中, 参数enable_et指定是否对fd启用ET模式*/ void addfd(int epollfd, int fd, bool enable_et) { epoll_event event; event.data.fd = fd; // 统一为读 event.events = EPOLLIN; if (enable_et) { event.events |= EPOLLET; } epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event); // 设置为非阻塞 setnonblocking(fd); } // LT 模式工作流程 void lt(epoll_event *events, int number, int epollfd, int listenfd) { char buf[BUFFER_SIZE]; for (int i = 0; i < number; i++) { int sockfd = events[i].data.fd; if (sockfd == listenfd) { struct sockaddr_in client_address; socklen_t client_addrlength = sizeof(client_address); int connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength); // 注册事件 addfd(epollfd, connfd, false); printf("event add once\n"); } else if (events[i].events & EPOLLIN) { /*只要socket读缓存中还有未读出的数据,这段代码就被重复触发*/ printf("event trigger once\n"); memset(buf, '\0', BUFFER_SIZE); int ret = recv(sockfd, buf, BUFFER_SIZE - 1, 0); if (ret <= 0) { // 对方断开连接,结束 close(sockfd); printf("close socket\n"); continue; } printf("get %d bytes of content: %s\n", ret, buf); } else { printf("something else happened \n"); } } } // ET 模式工作流程 void et(epoll_event *events, int number, int epollfd, int listenfd) { char buf[BUFFER_SIZE]; for (int i = 0; i < number; i++) { int sockfd = events[i].data.fd; if (sockfd == listenfd) { struct sockaddr_in client_address; socklen_t client_addrlength = sizeof(client_address); int connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength); addfd(epollfd, connfd, true); printf("event add once\n"); } else if (events[i].events & EPOLLIN) { /*这段代码不会被重复触发,所以我们循环读取数据,以确保把socket读缓存中的所有数据读出*/ printf("event trigger once\n"); while (1) { memset(buf, '\0', BUFFER_SIZE); int ret = recv(sockfd, buf, BUFFER_SIZE - 1, 0); if (ret < 0) { /*对于非阻塞IO,下面的条件成立表示数据已经全部读取完毕。此后,epoll就能再次触发sockfd上的EPOLLIN事件,以驱动下一次读操作*/ if ((errno == EAGAIN) || (errno == EWOULDBLOCK)) { printf("read later\n"); break; } // close(sockfd); break; } else if (ret == 0) { // 关闭了连接,直接退出 printf("close socket\n"); close(sockfd); break; } else { printf("get %d bytes of content: %s\n", ret, buf); } } } else { printf("something else happened \n"); } } } int main(int argc, char *argv[]) { const char *ip = "192.168.163.128"; int port = 12345; int ret = 0; struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int listenfd = socket(PF_INET, SOCK_STREAM, 0); assert(listenfd >= 0); ret = bind(listenfd, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(listenfd, 5); assert(ret != -1); // 返回的就绪的事件 epoll_event events[MAX_EVENT_NUMBER]; int epollfd = epoll_create(5); assert(epollfd != -1); // 监听连接队列 addfd(epollfd, listenfd, true); while (1) { int ret = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1); if (ret < 0) { printf("epoll failure\n"); break; } lt(events, ret, epollfd, listenfd); // et(events, ret, epollfd, listenfd); } close(listenfd); close(epollfd); return 0; } -
(1)LT模式实验结果
-
-
可以看到LT模式会一直触发。
-
(2)ET模式实验结果
-
-
(3)总结
-
正如我们预期的,ET模式下事件被触发的次数要比LT模式下少很多。
-
需要注意的是,每个使用ET模式的文件描述符都应该是非阻塞的,因为如果文件描述将是阻塞的,那么读或写操作将会因为没有后续的事件而一直处于阻塞状态(饥渴状态)。
9.3.4 EPOLLONESHOT 事件
-
即使我们使用ET模式,一个socket上的某个事件还是可能被触发多次。这在并发程序中就会引起一个问题。比如一个线程(或进程,下同)在读取完某个socket上的数据后开始处理这些数据,而在数据的处理过程中该socket上又有新数据可读(EPOLLIN再次被触发),此时另外一个线程被唤醒来读取这些新的数据。于是就出现了两个线程同时操作一个socket的局面。这当然不是我们期望的。我们期望的是一个socket连接在任一时刻都只被一个线程处理。这一点可以使用epoll的EPOLLONESHOT事件实现。
-
对于注册了 EPOLLONESHOT 事件的文件描述符,操作系统最多触发其上注册的一个可读、可写或者异常事件,且只触发一次。 除非我们使用epoll_ctl函数重置该文件描述符上注册的EPOLLONESHOT事件。这样,当一个线程在处理某个socket时候,其他线程是不可能有机会操作该socket的。反过来,注册了EPOLLONESHOT事件的socket一旦被某个线程处理完毕,该线程就应该立即重置这个socket上的EPOLLONESHOT事件,以确保这个socket下一次可读时,其EPOLLIN事件能被触发,进而让其他工作线程有机会继续处理这个socket。
-
以下代码展示了 EPOLLONESHOT 事件的使用。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <pthread.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/epoll.h> #include <sys/socket.h> #include <sys/types.h> #include <unistd.h> #define MAX_EVENT_NUMBER 1024 #define BUFFER_SIZE 1024 struct fds { int epollfd; int sockfd; }; // 设置非阻塞 int setnonblocking(int fd) { int old_option = fcntl(fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl(fd, F_SETFL, new_option); return old_option; } void addfd(int epollfd, int fd, bool oneshot) { epoll_event event; event.data.fd = fd; event.events = EPOLLIN | EPOLLET; if (oneshot) { event.events |= EPOLLONESHOT; } epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event); setnonblocking(fd); } void reset_oneshot(int epollfd, int fd) { epoll_event event; event.data.fd = fd; event.events = EPOLLIN | EPOLLET | EPOLLONESHOT; // 重置事件,使用 EPOLL_CTL_MOD epoll_ctl(epollfd, EPOLL_CTL_MOD, fd, &event); } // 工作线程 void *worker(void *arg) { int sockfd = ((fds *)arg)->sockfd; int epollfd = ((fds *)arg)->epollfd; printf("start new thread to receive data on fd: %d\n", sockfd); char buf[BUFFER_SIZE]; memset(buf, '\0', BUFFER_SIZE); while (1) { int ret = recv(sockfd, buf, BUFFER_SIZE - 1, 0); if (ret == 0) { close(sockfd); printf("foreiner closed the connection\n"); break; } else if (ret < 0) { if (errno == EAGAIN || errno == EWOULDBLOCK) { reset_oneshot(epollfd, sockfd); printf("read later\n"); break; } } else { printf("get content: %s\n", buf); sleep(5); } } printf("end thread receiving data on fd: %d\n", sockfd); } int main(int argc, char *argv[]) { const char *ip = "192.168.141.128"; int port = 12345; int ret = 0; struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int listenfd = socket(PF_INET, SOCK_STREAM, 0); assert(listenfd >= 0); ret = bind(listenfd, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(listenfd, 5); assert(ret != -1); epoll_event events[MAX_EVENT_NUMBER]; int epollfd = epoll_create(5); assert(epollfd != -1); /*注意,监听socket和listenfd上是不能注册EPOLLONESHOT事件的,否则应用程序只能处理一个客户连接!因为后续的客户连接请求将不再触发listenfd上的EPOLLIN事件*/ addfd(epollfd, listenfd, false); while (1) { int ret = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1); if (ret < 0) { printf("epoll failure\n"); break; } for (int i = 0; i < ret; i++) { int sockfd = events[i].data.fd; if (sockfd == listenfd) { struct sockaddr_in client_address; socklen_t client_addrlength = sizeof(client_address); int connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength); // 对每个非监听文件描述符都注册 EPOLLONESHOT 事件 addfd(epollfd, connfd, true); } else if (events[i].events & EPOLLIN) { pthread_t thread; fds fds_for_new_worker; fds_for_new_worker.epollfd = epollfd; fds_for_new_worker.sockfd = sockfd; // 新启动一个线程为sockfd服务 // 参数依次是:创建的线程地址,线程参数,调用的函数,传入的函数参数 pthread_create(&thread, NULL, worker, (void *)&fds_for_new_worker); } else { printf("something else happened \n"); } } } close(listenfd); close(epollfd); return 0; } -
实验结果
-
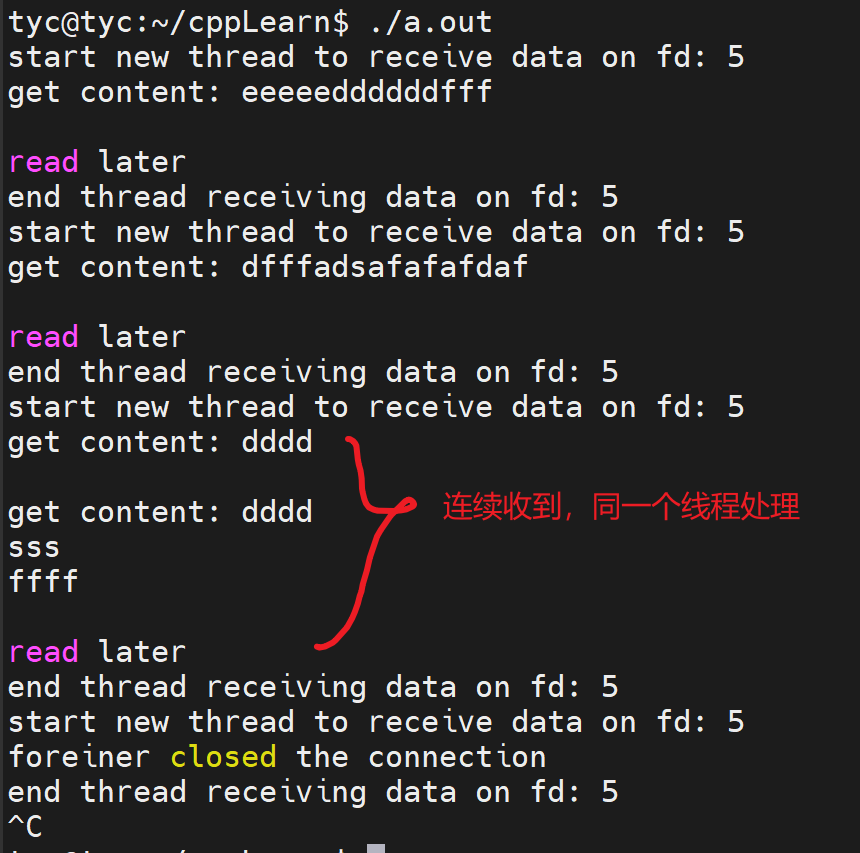
-
从工作线程函数 worker来看,如果一个工作线程处理完某个 socket上的一次请求(我们用休眠5s来模拟这个过程)之后,又接收到该socket上新的客户请求,则该线程将继续为这个socket服务。并且因为该socket上注册了EPOLLONESHOT事件,其他线程没有机会接触这个socket。
-
如果工作线程等待5s后仍然没收到该socket上的下一批客户数据,则它将放弃为该socket服务。同时,它调用reset_oneshot函数来重置该socket上的注册事件,这将使epoll有机会再次检测到该socket上的EPOLLIN事件,进而使得其他线程有机会为该socket服务。
-
由此看来,尽管一个socket在不同时间可能被不同的线程处理,但同一时刻肯定只有一个线程在为它服务。这就保证了连接的完整性,从而避免了很多可能的竞态条件。
9.4 三组 I/O 复用函数的比较
-
以下是表格总结
系统调用 事件集合 应用程序索引就绪文件描述符的时间复杂度 最大支持文件描述符数 工作模式 内核实现和工作效率 select 用户通过3个(fd_set指针)参数分别传入感兴趣的可读、可写及异常等事件,内核通过对这些参数的在线修改来反馈其中的就绪事件。这使得用户每次调用select都要重置这3个参数。 O(n),因为返回整个用户注册的事件集合(包括就绪和未就绪的) 一般有最大限制(1024) LT 采用轮询的方式来检测就绪事件,算法复杂度为O(n) poll 统一处理所有事件类型,因此只需一个事件集参数,用户通过pollfd.events传入感兴趣的事,内核通过修改pollfd.revents反馈其中就绪的事件。因此下次调用poll时应用程序无需重置pollfd类。 O(n),因为返回整个用户注册的事件集合(包括就绪和未就绪的) 65535 LT 采用轮询的方式来检测就绪事件,算法复杂度为O(n) epoll 内核通过一个内核事件表直接管理用户感兴趣的所有事件。因此每次调用epoll_wait时,无需反复传入用户感兴趣的事件。epoll_wait的参数events仅用来反馈就绪的事件。 O(1),因为只返回就绪事件集合 65535 LT 或 ET 采用回调方式来检测就绪事件,算法复杂度为O(1) -

-

-
综上,当监测的fd数量较小,且各个fd都很活跃的情况下,建议使用select和poll;当监听的fd数量较多,且单位时间仅部分fd活跃的情况下,使用epoll会明显提升性能。
9.5 I/O 复用高级应用一:非阻塞 connect
-

-
以上描述了 connect 出错的一种errno值:EINPROGRESS。这种错误发生在对非阻塞的socket调用connect,而连接又没有立即建立时。
-
根据man文档的解释,在这种情况下,我们可以调用select、poll等函数来监听这个连接失败的socket上的可写事件。当select、poll等函数返回后,再利用getsockopt来读取错误码并清除该socket上的错误。如果错误码是0,表示连接成功建立,否则连接失败。
-
具体的实现操作可分为如下三个步骤:
-
步骤1: 设置非阻塞,启动连接
- 实现非阻塞 connect ,首先把 sockfd 设置成非阻塞的。这样调用 connect 可以立刻返回,根据返回值和 errno 处理三种情况: (1) 如果返回 0,表示 connect 成功。 (2) 如果返回值小于 0, errno 为 EINPROGRESS, 表示连接 建立已经启动但是尚未完成。这是期望的结果,不是真正的错误。 (3) 如果返回值小于0,errno 不是 EINPROGRESS,则连接出错了。
-
步骤2:判断可读和可写
- 然后把 sockfd 加入 select 的读写监听集合,通过 select 判断 sockfd是否可写,处理三种情况: (1) 如果连接建立好了,对方没有数据到达,那么 sockfd 是可写的; (2) 如果在 select 之前,连接就建立好了,而且对方的数据已到达,那么 sockfd 是可读和可写的。 (3) 如果连接发生错误,sockfd 也是可读和可写的。
- 判断 connect 是否成功,就得区别 (2) 和 (3),这两种情况下 sockfd 都是可读和可写的,区分的方法是,调用 getsockopt 检查是否出错,错误码为0,表示连接成功。
-
步骤3:使用 getsockopt 函数检查错误
- getsockopt(sockfd, SOL_SOCKET, SO_ERROR, &error, &len)
- 在 sockfd 都是可读和可写的情况下,我们使用 getsockopt 来检查连接是否出错。但这里有一个可移植性的问题。如果发生错误,getsockopt 源自 Berkeley(UNIX系统) 的实现将在变量 error 中返回错误,getsockopt 本身返回0;然而 Linux 却让 getsockopt 返回 -1,并把错误保存在 errno 变量中。所以在获取错误码的时候,要处理这两种情况。
-
以下为在Linux系统下的非阻塞connect的实现代码。如果需要同时发起多个连接并一起等待,可以采用多线程方式实现。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/ioctl.h> #include <sys/socket.h> #include <sys/types.h> #include <time.h> #include <unistd.h> #define BUFFER_SIZE 1023 int setnonblocking(int fd) { int old_option = fcntl(fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl(fd, F_SETFL, new_option); return old_option; } /*超时连接函数,参数分别是服务器IP地址、端口号和超时时间(秒),函数成功时返回已经处于连接状态的socket,失败则返回-1*/ int unblock_connect(const char *ip, int port, int time) { int ret = 0; struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int sockfd = socket(PF_INET, SOCK_STREAM, 0); // 设置非阻塞 int fdopt = setnonblocking(sockfd); ret = connect(sockfd, (struct sockaddr *)&address, sizeof(address)); if (ret == 0) { // 如果连接成功,则恢复sockfd的属性,并立即返回 printf("connect with server immediately\n"); fcntl(sockfd, F_SETFL, fdopt); return sockfd; } else if (errno != EINPROGRESS) { /*如果连接没有立即建立,那么只有当errno是EINPROGRESS时才表示连接还在进行,否则出错返回*/ printf("unblock connect not support\n"); return -1; } fd_set writefds; struct timeval timeout; FD_ZERO(&writefds); FD_SET(sockfd, &writefds); timeout.tv_sec = time; timeout.tv_usec = 0; ret = select(sockfd + 1, NULL, &writefds, NULL, &timeout); if (ret <= 0) { printf("connection time out\n"); close(sockfd); return -1; } if (!FD_ISSET(sockfd, &writefds)) { printf("no events on sockfd found\n"); close(sockfd); return -1; } int error = 0; socklen_t length = sizeof(error); /*调用getsockopt来获取并清除sockfd上的错误*/ if (getsockopt(sockfd, SOL_SOCKET, SO_ERROR, &error, &length) < 0) { printf("get socket option failed\n"); close(sockfd); return -1; } // 调用成功,错误号不为0表示连接错误 if (error != 0) { printf("connection failed after select with the error: %d \n", error); close(sockfd); return -1; } printf("connection ready after select with the socket: %d \n", sockfd); fcntl(sockfd, F_SETFL, fdopt); return sockfd; } int main(int argc, char *argv[]) { const char *ip = "192.168.141.128"; int port = 12345; int sockfd = unblock_connect(ip, port, 10); if (sockfd < 0) { return 1; } printf("send data out\n"); send(sockfd, "abc", 3, 0); sleep(2); close(sockfd); return 0; } -
实验结果
-

-

9.6 I/O 复用高级应用二:聊天室程序
-
像ssh这样的登录服务通常要同时处理网络连接和用户输入,这也可以使用I/O复用来实现。
-
接下来我们以poll为例实现一个简单的聊天室程序,以阐述如何使用I/O复用技术来同时处理网络连接和用户输入。该聊天室程序能让所有用户同时在线群聊,它分为客户端和服务器两个部分。
-
其中客户端程序有两个功能:一是从标准输入终端读入用户数据,并将用户数据发送至服务器:二是往标准输出终端打印服务器发送给它的数据。
-
服务器的功能是接收客户数据,并把客户数据发送给每一个登录到该服务器上的客户端(数据发送者除外)。
-
(1)客户端
-
客户端程序使用poll同时监听用户输入和网络连接,并利用splice函数将用户输人内容直接定向到网络连接上以发送之,从而实现数据零拷贝,提高了程序执行效率。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76// #define _GNU_SOURCE 1 #include <arpa/inet.h> #include <assert.h> #include <fcntl.h> #include <netinet/in.h> #include <poll.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <sys/types.h> #include <unistd.h> #define BUFFER_SIZE 64 int main(int argc, char *argv[]) { const char *ip = "192.168.141.128"; int port = 12345; struct sockaddr_in server_address; memset(&server_address, 0, sizeof(server_address)); server_address.sin_family = AF_INET; inet_pton(AF_INET, ip, &server_address.sin_addr); server_address.sin_port = htons(port); int sockfd = socket(PF_INET, SOCK_STREAM, 0); assert(sockfd >= 0); if (connect(sockfd, (struct sockaddr *)&server_address, sizeof(server_address)) < 0) { printf("connection failed\n"); close(sockfd); return 1; } pollfd fds[2]; fds[0].fd = 0; // 输入 fds[0].events = POLLIN; fds[0].revents = 0; fds[1].fd = sockfd; // socket接收 fds[1].events = POLLIN | POLLRDHUP; fds[1].revents = 0; char read_buf[BUFFER_SIZE]; int pipefd[2]; int ret = pipe(pipefd); assert(ret != -1); while (1) { ret = poll(fds, 2, -1); if (ret < 0) { printf("poll failure\n"); break; } if (fds[1].revents & POLLRDHUP) { printf("server close the connection\n"); break; } else if (fds[1].revents & POLLIN) { memset(read_buf, '\0', BUFFER_SIZE); recv(fds[1].fd, read_buf, BUFFER_SIZE - 1, 0); printf("%s\n", read_buf); } if (fds[0].revents & POLLIN) { // 标准输入接收数据,写入管道的写端,零拷贝 ret = splice(0, NULL, pipefd[1], NULL, 32768, SPLICE_F_MORE | SPLICE_F_MOVE); // 管道读端接收数据,写入socket发送 ret = splice(pipefd[0], NULL, sockfd, NULL, 32768, SPLICE_F_MORE | SPLICE_F_MOVE); } } close(sockfd); return 0; } -
-
(2)服务器
-
服务器程序使用poll同时管理监听socket和连接socket,并且使用牺牲空间换取时间的策略来提高服务器性能。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168// #define _GNU_SOURCE 1 #include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <poll.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <sys/types.h> #include <unistd.h> #define USER_LIMIT 3 #define BUFFER_SIZE 64 #define FD_LIMIT 65536 struct client_data { sockaddr_in address; char *write_buf; // 记录发送的数据指针 char buf[BUFFER_SIZE]; // 缓存本身的数据 }; int setnonblocking(int fd) { int old_option = fcntl(fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl(fd, F_SETFL, new_option); return old_option; } int main(int argc, char *argv[]) { const char *ip = "192.168.141.128"; int port = 12345; int ret = 0; struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int listenfd = socket(PF_INET, SOCK_STREAM, 0); setnonblocking(listenfd); assert(listenfd >= 0); ret = bind(listenfd, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(listenfd, USER_LIMIT); assert(ret != -1); // 直接创建所有描述符的空间(0-65535),空间换时间 client_data *users = new client_data[FD_LIMIT]; pollfd fds[USER_LIMIT + 1]; // 动态添加用户数,初始为0即监听 int user_counter = 0; for (int i = 1; i <= USER_LIMIT; ++i) { fds[i].fd = -1; fds[i].events = 0; } // 0位为接收 fds[0].fd = listenfd; fds[0].events = POLLIN | POLLERR; fds[0].revents = 0; while (1) { ret = poll(fds, user_counter + 1, -1); if (ret < 0) { printf("poll failure\n"); break; } for (int i = 0; i < user_counter + 1; ++i) { if ((fds[i].fd == listenfd) && (fds[i].revents & POLLIN)) { struct sockaddr_in client_address; socklen_t client_addrlength = sizeof(client_address); int connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength); if (connfd < 0) { printf("errno is: %d\n", errno); continue; } // 请求太多,关闭连接,刚好是最后一个(listen的backlog参数决定) if (user_counter >= USER_LIMIT) { const char *info = "too many users\n"; printf("%s", info); send(connfd, info, strlen(info), 0); close(connfd); continue; } user_counter++; users[connfd].address = client_address; setnonblocking(connfd); fds[user_counter].fd = connfd; fds[user_counter].events = POLLIN | POLLRDHUP | POLLERR; fds[user_counter].revents = 0; printf("comes a new user, now have %d users\n", user_counter); } else if (fds[i].revents & POLLERR) { printf("get an error from %d\n", fds[i].fd); char errors[100]; memset(errors, '\0', 100); socklen_t length = sizeof(errors); if (getsockopt(fds[i].fd, SOL_SOCKET, SO_ERROR, &errors, &length) < 0) { printf("get socket option failed\n"); } continue; } else if (fds[i].revents & POLLRDHUP) { // 对端关闭连接 // 和最后一个sokcet转换,保证poll的个数 users[fds[i].fd] = users[fds[user_counter].fd]; printf("a client left: %d\n", fds[i].fd); close(fds[i].fd); fds[i] = fds[user_counter]; i--; user_counter--; } else if (fds[i].revents & POLLIN) { int connfd = fds[i].fd; memset(users[connfd].buf, '\0', BUFFER_SIZE); ret = recv(connfd, users[connfd].buf, BUFFER_SIZE - 1, 0); printf("get %d bytes of client data: [%s] from %d\n", ret, users[connfd].buf, connfd); if (ret < 0) { // 出错了,断开连接 if (errno != EAGAIN) { close(connfd); users[fds[i].fd] = users[fds[user_counter].fd]; fds[i] = fds[user_counter]; i--; user_counter--; } } else if (ret == 0) { printf("code should not come to here\n"); } else { for (int j = 1; j <= user_counter; ++j) { if (fds[j].fd == connfd) { continue; } /* 通知其他sokcet注册 * fds[i]上的可写事件,暂时删除可读事件 */ fds[j].events |= ~POLLIN; fds[j].events |= POLLOUT; users[fds[j].fd].write_buf = users[connfd].buf; } } } else if (fds[i].revents & POLLOUT) { int connfd = fds[i].fd; if (!users[connfd].write_buf) { continue; } ret = send(connfd, users[connfd].write_buf, strlen(users[connfd].write_buf), 0); users[connfd].write_buf = NULL; // 写完数据后重新注册 fds[i] 上的可读事件 fds[i].events |= ~POLLOUT; fds[i].events |= POLLIN; } } } delete[] users; close(listenfd); return 0; } -

-
(3)总结
-
实验结果符合预期,因为设置最多3个客户,所以有以上结果。
-
这里需要说明,关于
#define _GNU_SOURCE 1预处理是什么,虽然上述代码已经注释不用。 -
在C和C++中,
#define _GNU_SOURCE 1是一个预处理指令,用于告诉编译器启用GNU特定的扩展功能和特性。具体来说,_GNU_SOURCE宏定义是为了兼容GNU C库(glibc)的一些特性,并且它通常用于在编译时启用一些非标准的、GNU特有的函数或功能。这些函数或功能可能不符合POSIX标准,但在GNU环境中提供了更多的便利和功能。
-
一些常见的GNU C库特性包括:
扩展的数学函数:启用后可以使用一些额外的数学函数,如erf()、asprintf()等。 字符串函数扩展:启用后可以使用一些额外的字符串处理函数,如strdupa()、asprintf()等。 GNU扩展的文件操作函数:启用后可以使用一些非标准的文件操作函数,如getline()、getdelim()等。 POSIX线程(Pthreads)函数扩展:启用后可以使用一些非标准的线程函数,如pthread_setname_np()、pthread_getattr_np()等。 POSIX信号扩展:启用后可以使用一些非标准的信号处理函数,如sigwaitinfo()、sigqueue()等。
-
需要注意的是,使用#define _GNU_SOURCE 1可能会导致代码在其他平台或非GNU编译器上出现不兼容的问题,因为这些特性是GNU特定的,并不是C或C++标准的一部分。因此,在使用该宏定义时需要谨慎权衡,并确保在目标平台上有正确的库支持和预期的行为。
9.7 I/O 复用高级应用三:同时处理 TCP 和 UDP 服务
-
前面所讲的服务器程序都只监听一个端口。在实际应用中,有不少服务器程序能同时监听多个端口,比如Linux的超级服务inetd和android的调试服务adbd。
-
从bind系统调用的参数来看,一个socket只能与一个socket地址绑定,即一个socket只能用来监听一个端口。因此,服务器如果要同时监听多个端口,就必须创建多个socket,并将它们分别绑定到各个端口上。这样一来,服务器程序就需要同时管理多个监听socket,因此I/O复用技术就有了用武之地。
-
另外,即使是同一个端口,如果服务器要同时处理该端口上的TCP和UDP请求,则也需要创建两个不同的socket:一个是流socket,另一个是数据报socket,并将它们都绑定到该端口上。
-
以下程序就是能同时处理 TCP 请求和 UDP 请求的回射服务器。
-
因为UDP是无连接的,所以其编码无需listen来连接。
-
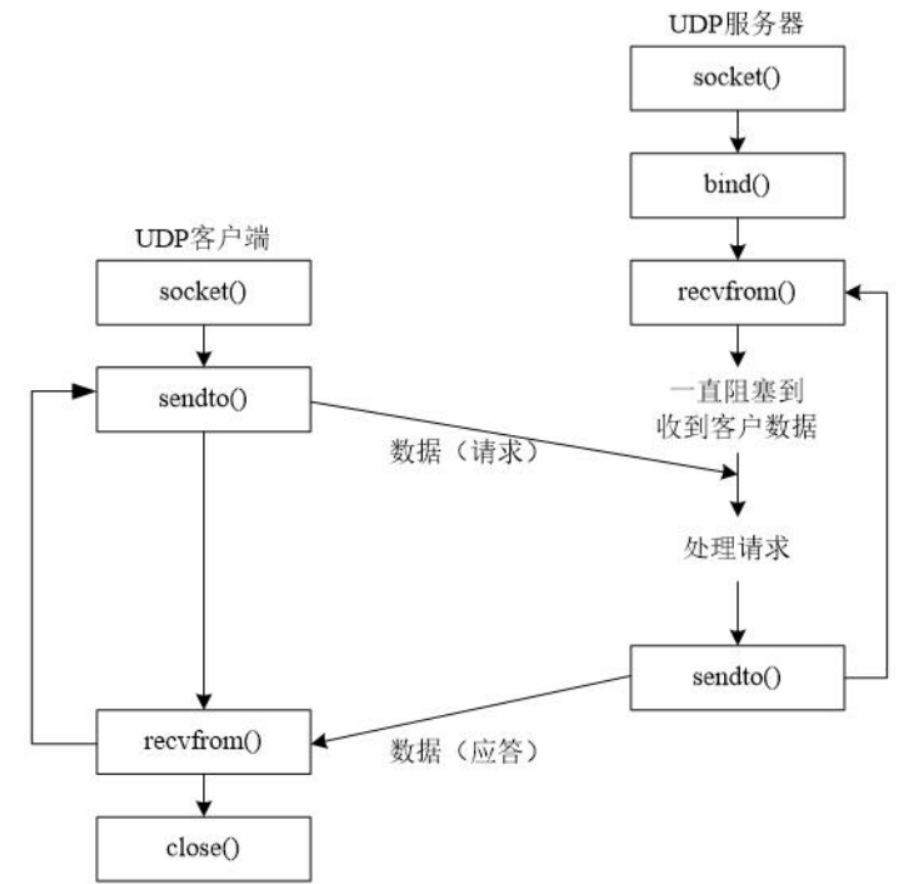
-
以下服务器代码使用epoll监听tcp和udp。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <pthread.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/epoll.h> #include <sys/socket.h> #include <sys/types.h> #include <unistd.h> #define MAX_EVENT_NUMBER 1024 #define TCP_BUFFER_SIZE 512 #define UDP_BUFFER_SIZE 1024 int setnonblocking(int fd) { int old_option = fcntl(fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl(fd, F_SETFL, new_option); return old_option; } void addfd(int epollfd, int fd) { epoll_event event; event.data.fd = fd; // event.events = EPOLLIN | EPOLLET; event.events = EPOLLIN; epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event); setnonblocking(fd); } int main(int argc, char *argv[]) { const char *ip = "192.168.141.128"; int port = 12345; int ret = 0; struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int listenfd = socket(PF_INET, SOCK_STREAM, 0); assert(listenfd >= 0); ret = bind(listenfd, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(listenfd, 5); assert(ret != -1); // 创建UDP memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int udpfd = socket(PF_INET, SOCK_DGRAM, 0); assert(udpfd >= 0); ret = bind(udpfd, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); epoll_event events[MAX_EVENT_NUMBER]; int epollfd = epoll_create(5); assert(epollfd != -1); addfd(epollfd, listenfd); addfd(epollfd, udpfd); while (1) { int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1); if (number < 0) { printf("epoll failure\n"); break; } for (int i = 0; i < number; i++) { int sockfd = events[i].data.fd; if (sockfd == listenfd) { struct sockaddr_in client_address; socklen_t client_addrlength = sizeof(client_address); int connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength); addfd(epollfd, connfd); } else if (sockfd == udpfd) { char buf[UDP_BUFFER_SIZE]; memset(buf, '\0', UDP_BUFFER_SIZE); struct sockaddr_in client_address; socklen_t client_addrlength = sizeof(client_address); ret = recvfrom(udpfd, buf, UDP_BUFFER_SIZE - 1, 0, (struct sockaddr *)&client_address, &client_addrlength); if (ret > 0) { printf("udp recv: [%s] \n", buf); sendto(udpfd, buf, UDP_BUFFER_SIZE - 1, 0, (struct sockaddr *)&client_address, client_addrlength); } } else if (events[i].events & EPOLLIN) { char buf[TCP_BUFFER_SIZE]; while (1) { memset(buf, '\0', TCP_BUFFER_SIZE); ret = recv(sockfd, buf, TCP_BUFFER_SIZE - 1, 0); if (ret < 0) { if ((errno == EAGAIN) || (errno == EWOULDBLOCK)) { break; } close(sockfd); break; } else if (ret == 0) { close(sockfd); } else { printf("tcp recv: [%s] \n", buf); send(sockfd, buf, ret, 0); } } } else { printf("something else happened \n"); } } } close(listenfd); close(udpfd); close(epollfd); return 0; } -
-
使用Netcat测试UDP通信,telnet测试TCP通信。
-
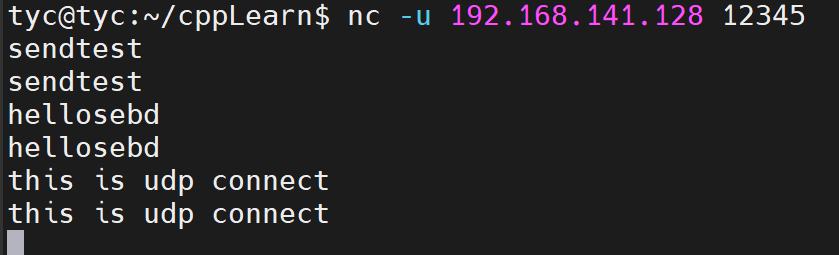
-
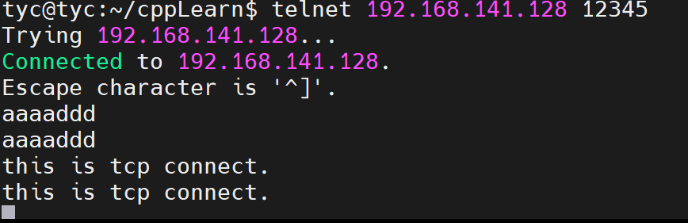
9.8 超级服务 xinetd
-
xinetd:extended internet daemon。
-
Linux因特网服务inetd是超级服务。它同时管理着多个子服务,即监听多个端口。现在Linux系统上使用的inetd服务程序通常是其升级版本xinetd。xinetd程序的原理与inetd相同,但增加了一些控制选项,并提高了安全性。
-
xinetd 是新一代的网络守护进程服务程序,又叫超级Internet服务,常用来管理多种轻量级Internet服务。
-
它管理的服务都是一些不是很常用,但是系统中偶尔也会用到的小服务或者该服务没什么好的安全机制,比如:tftp、rsync、cvs、telnet、ssh等。它并不是一真正意义上的服务,xinetd相当于rync、cvs等服务的代理人,(比如代理了sshd,那就就可以关闭ssh服务了,22端口就由xinetd服务代理了)。
-
原则上任何系统服务都可以使用xinetd,然而最适合的应该是那些常用的网络服务,同时,这个服务的请求数目和频繁程度不会太高。像DNS和Apache就不适合采用这种方式,而像FTP、Telnet、SSH等就适合使用xinetd模式。
(1)xinetd 配置文件
- xinetd采用
/etc/xinetd.conf主配置文件和/etc/xinetd.d目录下的子配置文件来管理所有服务。 - 主配置文件包含的是通用选项,这些选项将被所有子配置文件继承。不过子配置文件可以覆盖这些选项。每一个子配置文件用于设置一个子服务的参数。
- 比如,telnet子服务的配置文件/etc/xinetd.d/telnet的典型内容如下:
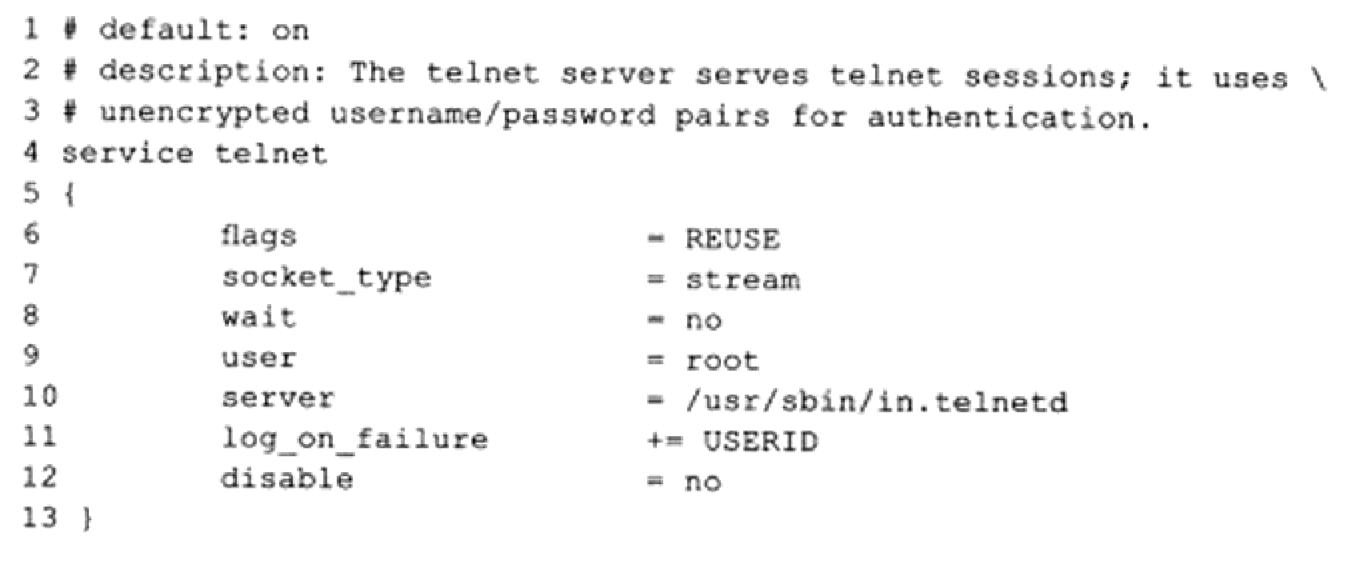
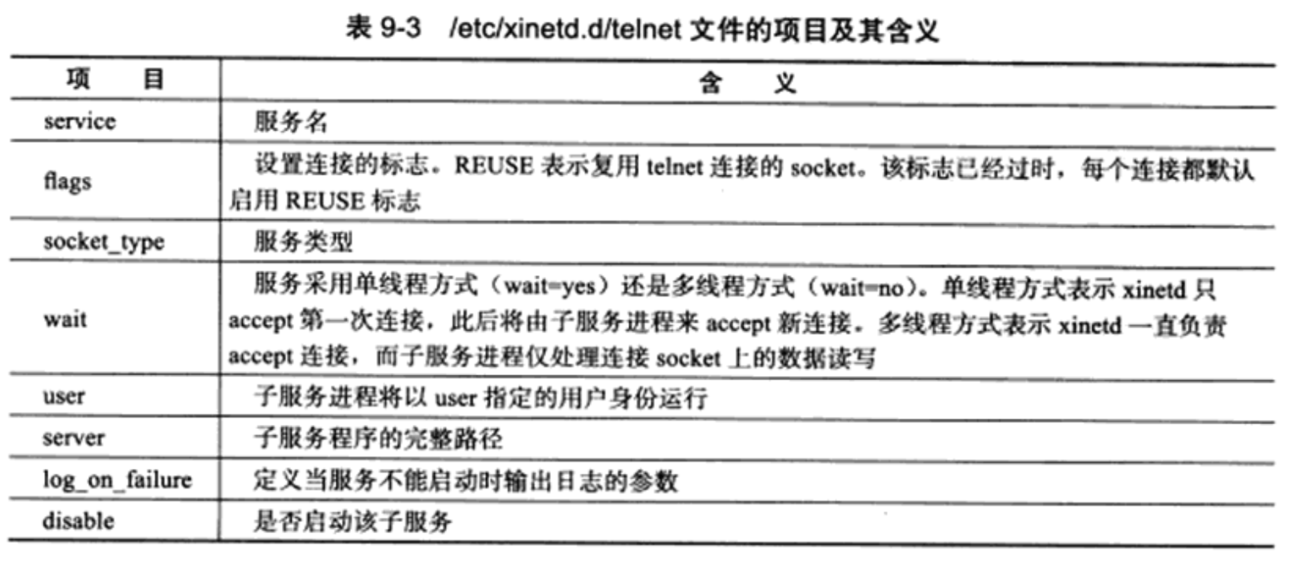
- xinetd 配置文件的内容很多,可以通过
man xinetd.conf查看。
(2)xinetd 工作流程
- xinetd管理的子服务中有的是标准服务,比如时间日期服务daytime、回射服务echo和丢弃服务discard。xinetd服务器在内部直接处理这些服务。
- 还有的子服务则需要调用外部的服务器程序来处理。xinetd通过调用fork和exec函数来加载运行这些服务器程序。比如telnet、ftp服务都是这种类型的子服务。
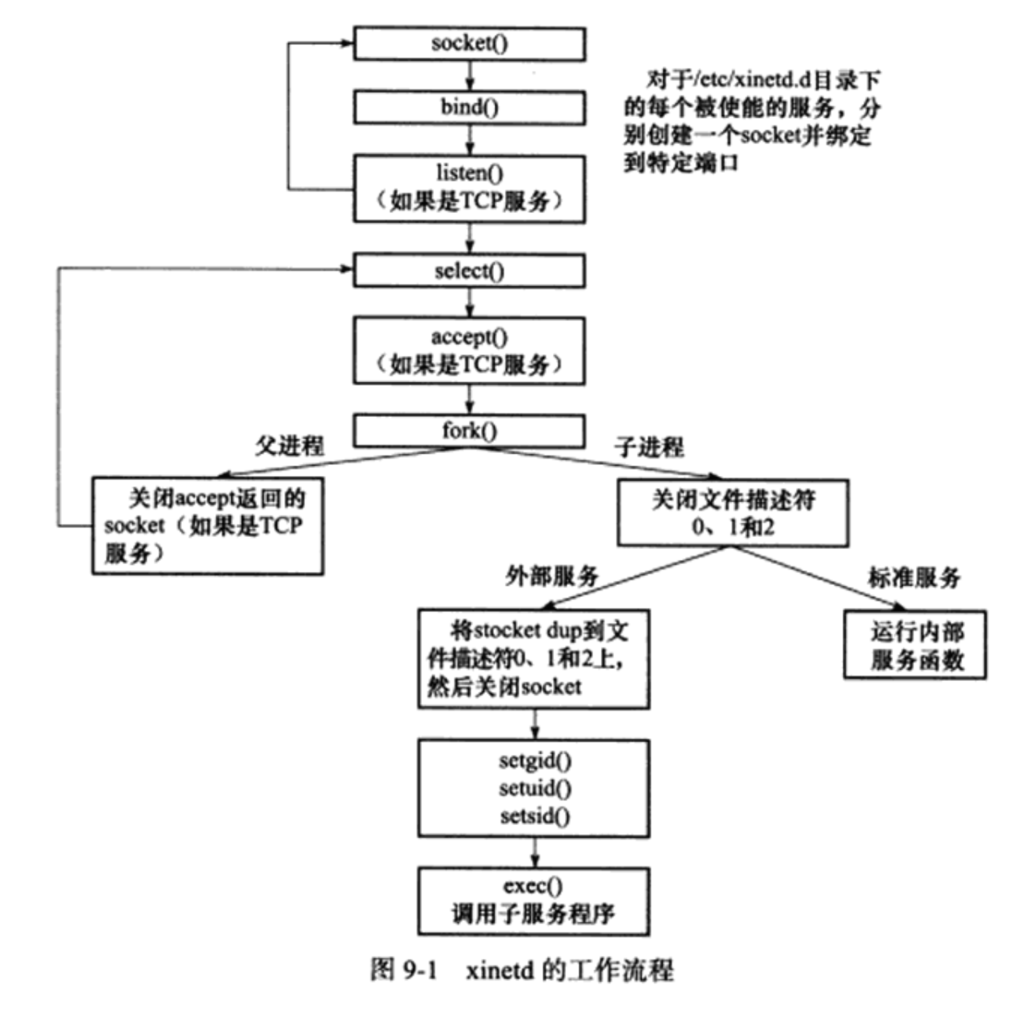
第10章 信号
- 信号是由用户、系统或者进程发送给目标进程的信息,以通知目标进程某个状态的改变或系统异常。Linux信号可由如下条件产生
- 对于前台进程,用户可以通过输人特殊的终端字符来给它发送信号。比如输入Ctrl+C通常会给进程发送一个中断信号。
- 系统异常。比如除0异常和非法内存段访问。
- 系统状态变化。比如alarm定时器到期将引起SIGALRM信号。
- 运行kill命令或调用kill函数。
- 服务器程序必须处理(或至少忽略)一些常见的信号,以免异常终止。
10.1 Linux 信号概述
(1)发送信号
-
一个进程给其他进程发送信号的API是kill函数。
-
1 2 3#include <sys/types.h> #include <signal.h> int kill(pid_t pid, int sig); -
该函数把信号sig发送给目标进程;目标进程由pid参数指定,其可能的取值及含义如下所示。
-

-
函数成功返回0,失败返回-1并设置errno。
-

(2)信号处理函数
-
目标进程在收到信号时,需要定义一个接收函数来处理之。信号处理函数的原型如下:
-
1 2 3#include <signal.h> /* Type of a signal handler. */ typedef void (*__sighandler_t) (int); -
因此,信号处理函数本质上就是一个函数指针,其有一个整形参数表示接收的信号,返回值为void。
-
信号处理函数必须是可重入的,否则很容易引发一些竞态条件。
-
Linux本身定义了两种处理方式,SIG_IGN(1,忽略目标信号),SIG_DFL(0,使用信号默认处理方式)
-
1 2#define SIG_DFL ((__sighandler_t) 0) /* Default action. */ #define SIG_IGN ((__sighandler_t) 1) /* Ignore signal. */
(3)Linux 信号
-
信号的默认处理方式有如下几种:结束进程(Term)、 忽略信号(Ign)、 结束进程并生成核心转储文件(Core)、暂停进程(Stop), 以及继续进程(Cont)。
-
Linux的可用信号都定义在
<bits/signum-generic.h>头文件中,包括标准信号和POSIX实时信号。 -
实际调用的时候,直接
#include <signal.h>即可。 -
以下是Linux标准信号的列举。主要关注的几个信号
SIGHUP,SIGPIPE,SIGURG,SIGALRM,SIGCHLD。 -
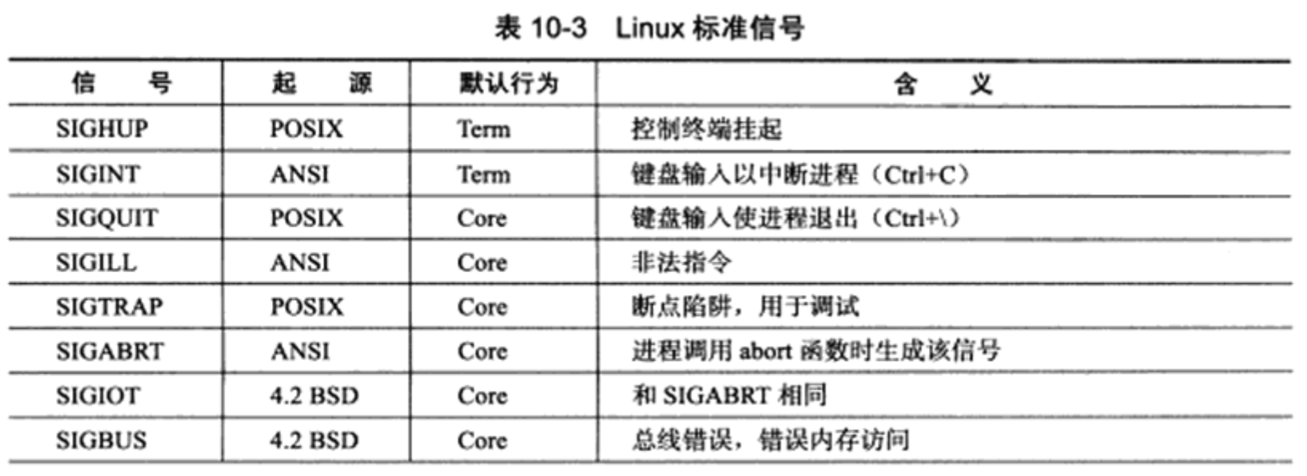
-
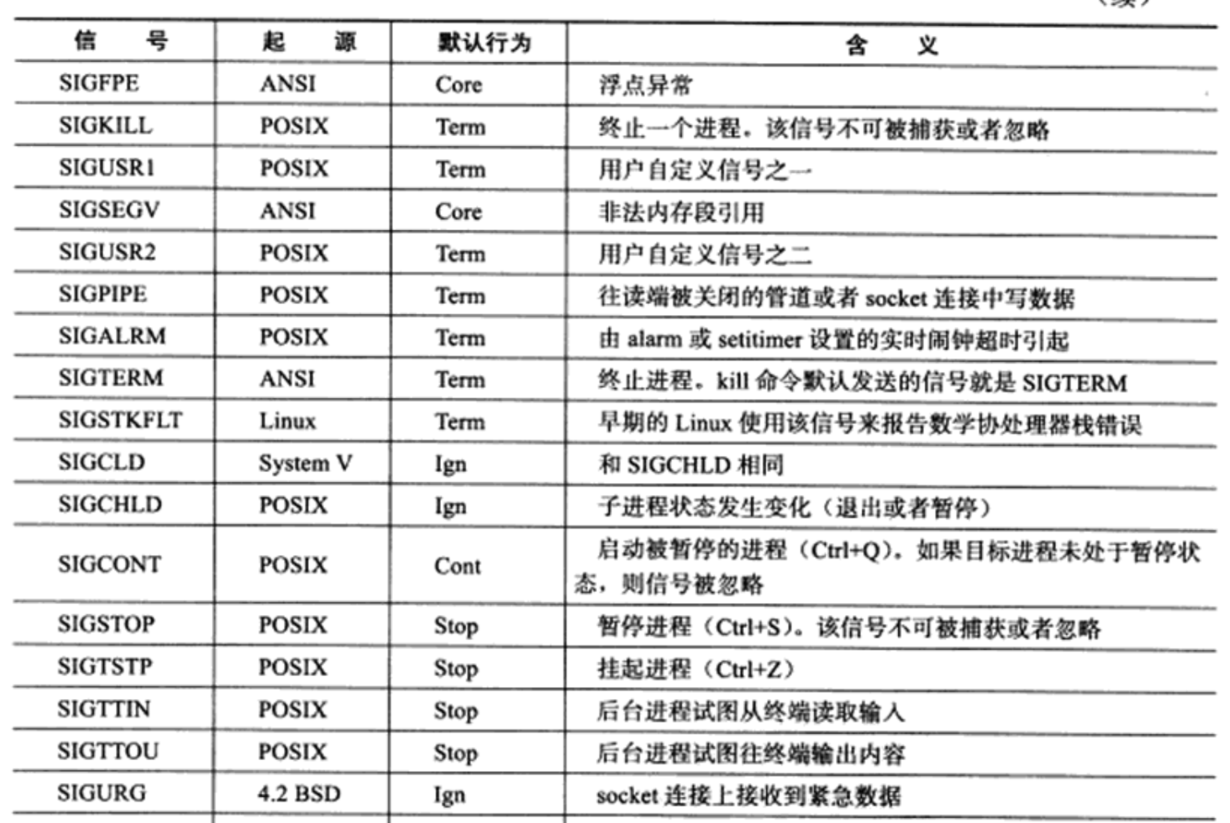
-
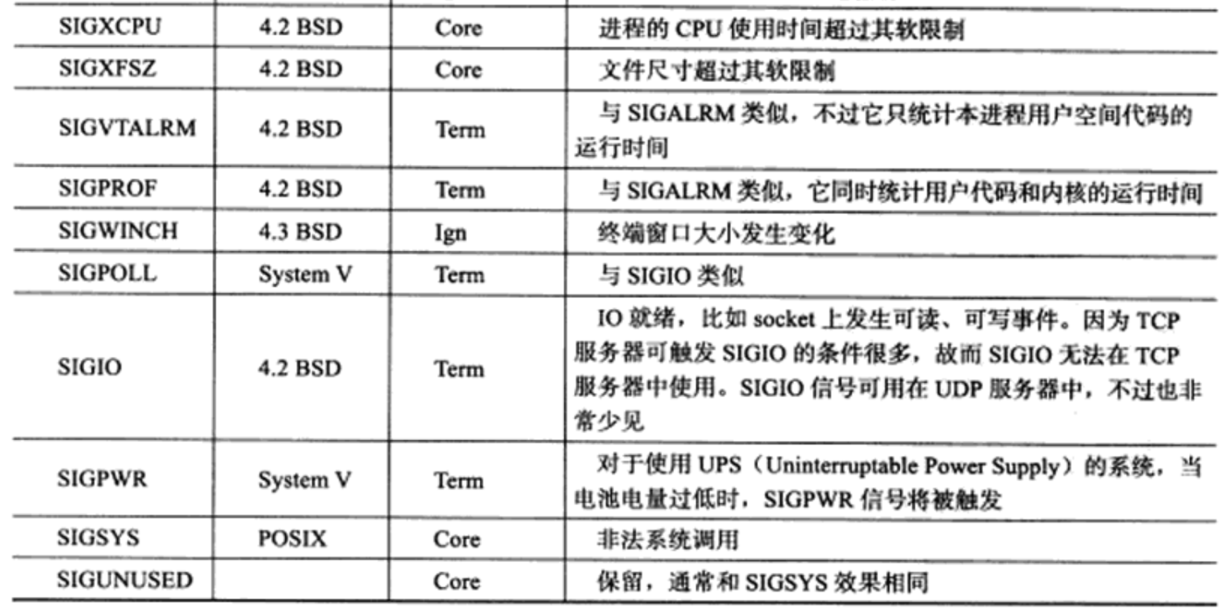
(4)中断系统调用
- 当程序处于阻塞态的系统调用的时候,接收到信号,并且我们为该信号设置了信号处理函数,那么系统调用会被中断,且errno设置为EINTR。
- 我们可以使用sigaction函数为信号设置SA_RESTART标志,以重新启动被改信号中断的系统调用。
- 对于默认行为是暂停进程的信号(SIGSTOP、SIGTTIN),就算没设置信号处理函数,也可以中断一些系统调用(connect,epoll_wait),这是Linux独有。
10.2 信号函数
(1)signal 系统调用
-
函数原型
-
1 2 3#include <signal.h> typedef void (*__sighandler_t) (int); _sighandler_t signal(int sig, _sighandler_t _handler); -
sig参数指出捕获信号类型;
-
_handler参数指定信号sig的处理函数指针;
-
返回值:上一次调用signal传入的函数指针。若是第一次,返回信号sig对应的默认处理函数指针。
-
出错时:返回SIG_ERR并设置errno。
(2)sigaction 系统调用
-
设置信号处理函数的更健壮的接口是sigaction系统调用:
-
1 2 3#include <signal.h> int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact); -
sig参数指出要捕获的信号类型,act参数指定新的信号处理方式,oldact参数则输出信号先前的处理方式(如果不为NULL的话)。act和oldact都是sigaction结构体类型的指针,sigaction结构体描述了信号处理的`细节,其定义如下:
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30typedef __sigset_t sigset_t; /* Structure describing the action to be taken when a signal arrives. */ struct sigaction { /* Signal handler. */ #if defined __USE_POSIX199309 || defined __USE_XOPEN_EXTENDED union { /* Used if SA_SIGINFO is not set. */ __sighandler_t sa_handler; /* Used if SA_SIGINFO is set. */ void (*sa_sigaction) (int, siginfo_t *, void *); } __sigaction_handler; # define sa_handler __sigaction_handler.sa_handler # define sa_sigaction __sigaction_handler.sa_sigaction #else __sighandler_t sa_handler; #endif /* Additional set of signals to be blocked. */ __sigset_t sa_mask; /* Special flags. */ int sa_flags; /* Restore handler. */ void (*sa_restorer) (void); }; -
可以看到,sigaction 结构体有四个成员:
- sa_handler 指定信号处理函数。
- sa_mask 设置进程信号掩码(确切的说是在进程原有信号掩码上增加信号掩码),以指定哪些信号不能发送给本进程。sa_mask是信号集
sigset_t类型,该类型指定一组信号。 - sa_flags 成员用于设置程序收到信号时的行为。
- sa_restorer已经成为历史,最好不用使用。
-
sigaction 系统调用成功时返回0,;失败时返回-1并设置errno。
-
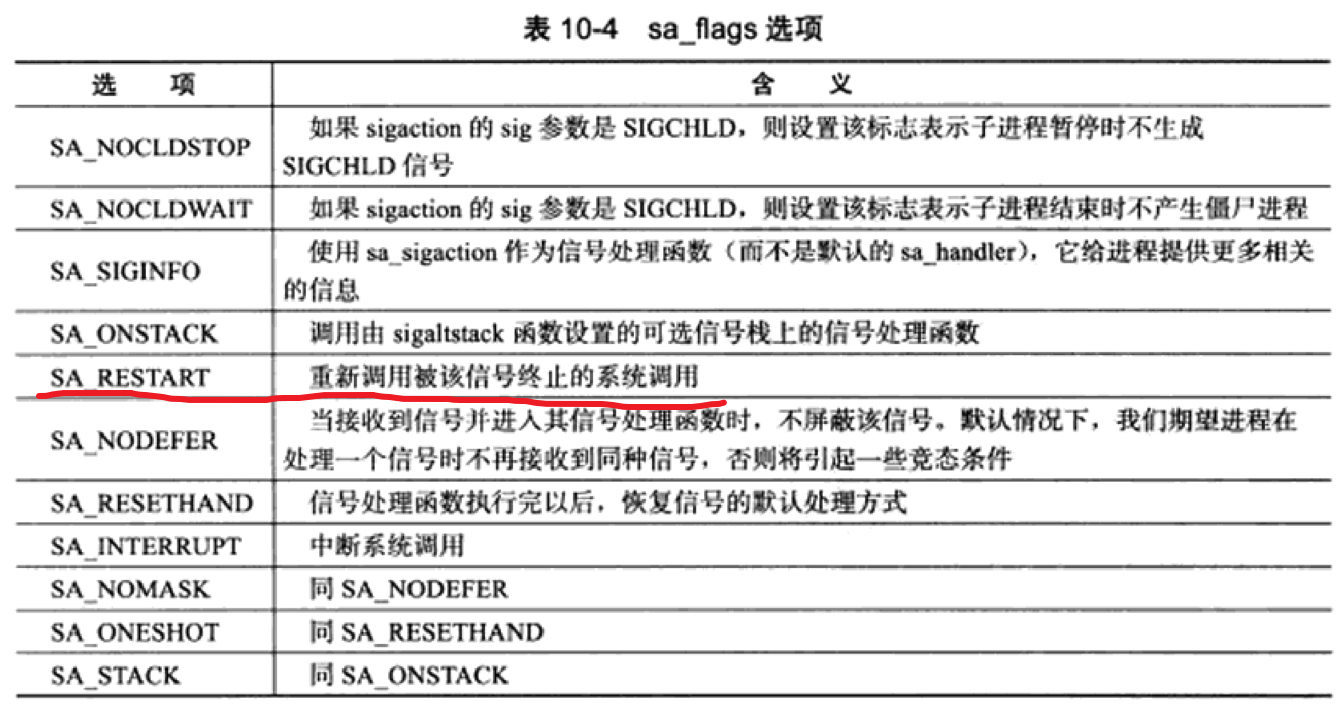
10.3 信号集
(1)信号集函数
-
Linux使用数据结构 sigset_t 来表示一组信号。
-
1 2 3 4 5 6 7typedef __sigset_t sigset_t; #define _SIGSET_NWORDS (1024 / (8 * sizeof (unsigned long int))) typedef struct { unsigned long int __val[_SIGSET_NWORDS]; } __sigset_t; -
可以看到,sigset_t 是一个长整型数组,数组的每个元素的一个位代表一个信号,和selcet系统调用的文件描述符集合fd_set类似。
-
Linux提供了一组函数用来设置、修改、查询和删除信号集。
-
1 2 3 4 5 6#include <signal.h> int sigemptyset(sigset_t *_set); // 清空信号集 int sigfillset(sigset_t *_set); // 在信号集中设置所有信号 int sigaddset(sigset_t *_set, int _signo); // 将信号_signo添加到信号集中 int sigdelset(sigset *_set, int _signo); // 将信号_signo从信号集中删除 int sigismember(sigset *_set, int _signo); // 测试_signo是否在信号集中
(2)进程信号掩码
-
每个进程都有一个信号掩码(Signal Mask),它用来控制哪些信号在当前时刻能够被进程接收。信号掩码是一个位集,其中的每一位对应一个信号,如果某一位被设置为 1,表示对应的信号被屏蔽(blocked)了,即进程当前不能接收这个信号。
-
默认情况下,进程的信号掩码通常是空集,即没有信号被阻塞。这意味着,进程在默认情况下可以接收所有的信号。
-
sigset_t 结构体类型的sa_mask 变量用来设置进程的信号掩码。通过sigprocmask函数进行设置或查看进程的信号掩码。
-
1 2#include <signal.h> int sigprocmask(int how, const sigset_t* _set, sigset_t* _oset); -
_set参数指定新的信号掩码,_oset参数则输出原来的信号掩码(如果不为NULL的话)。- 如果
_set参数不为NULL,则how参数指定设置进程信号掩码的方式,其可选值如下所示。 
- 如果
_set为NULL,则进程信号掩码不变,此时我们仍然可以利用_ost参数来获得进程当前的信号掩码。
- 如果
-
函数成功调用返回0,失败返回-1并设置errno。
-
获取当前进程的信号掩码示例代码如下
-
1 2 3 4 5 6 7 8// 获取当前信号掩码 sigset_t current_mask; if (sigprocmask(SIG_BLOCK, NULL, ¤t_mask) == -1) { perror("sigprocmask"); exit(EXIT_FAILURE); } printf("Default signal mask: %ld\n", current_mask);
(3)被挂起的信号
-
设置进程信号掩码后,被屏蔽的信号将不能被进程接收。如果给进程发送一个被屏蔽的信号,则操作系统将该信号设置为进程的一个被挂起的信号。
-
如果我们取消对被挂起信号的屏蔽,则它能立即被进程接收到。
-
如下函数可以获得进程当前被挂起的信号集:
-
1 2#include <signal.h> int sigpending(sigset_t* set); -
set参数用于保存被挂起的信号集。
-
显然,进程即使多次接收到同一个被挂起的信号,sigpending函数也只能反映一次。
-
并且,当我们再次使用sigprocmask使能该挂起的信号时,该信号的处理函数也只被触发一次。
10.4 统一事件源
- 信号是一种异步事件:信号处理函数和程序的主循环是两条不同的执行路线。很显然,信号处理函数需要尽可能快地执行完毕,以确保该信号不被屏蔽(为了避免一些竞态条件,信号在处理期间,系统不会再次触发它)太久。
- 一种典型的解决方案是:把信号的主要处理逻辑放到程序的主循环中,当信号处理函数被触发时,它只是简单地通知主循环程序接收到信号,并把信号值传递给主循环,主循环再根据接收到的信号值执行目标信号对应的逻辑代码。
- 信号处理函数通常使用管道来将信号“传递”给主循环:信号处理函数往管道的写端写入信号值,主循环则从管道的读端读出该信号值。因为这样足够简单。
- 那么主循环怎么知道管道上何时有数据可读呢?这很简单,我们只需要使用I/O复用系统调用来监听管道的读端文件描述符上的可读事件。
- 如此一来,信号事件就能和其他I/O事件一样被处理,即统一事件源。
- 很多优秀的I/O框架库和后台服务器程序都统一处理信号和I/O事件,比如Libevent I/O框架库和xinetd超级服务。
- 如下代码给出了统一事件源的一个简单实现。把信号的读写和socket的连接统一处理,这里需要注意信号处理函数的实现。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <pthread.h> #include <signal.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/epoll.h> #include <sys/socket.h> #include <sys/types.h> #include <unistd.h> #define MAX_EVENT_NUMBER 1024 static int pipefd[2]; int setnonblocking(int fd) { int old_option = fcntl(fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl(fd, F_SETFL, new_option); return old_option; } // ET模式,添加文件描述符 void addfd(int epollfd, int fd) { epoll_event event; event.data.fd = fd; event.events = EPOLLIN | EPOLLET; epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event); setnonblocking(fd); } // 设置信号的处理函数-写入管道 void sig_handler(int sig) { /*保留原来的errno,在函数最后恢复,以保证函数的可重入性*/ int save_errno = errno; int msg = sig; // 写入管道,通知主循环 send(pipefd[1], (char *)&msg, 1, 0); // 恢复errno errno = save_errno; } void addsig(int sig) { struct sigaction sa; memset(&sa, '\0', sizeof(sa)); // 设置信号处理函数 sa.sa_handler = sig_handler; // 设置中断后恢复标志 sa.sa_flags |= SA_RESTART; // 设置所有信号 sigfillset(&sa.sa_mask); // 添加系统调用 assert(sigaction(sig, &sa, NULL) != -1); } int main(int argc, char *argv[]) { const char *ip = "192.168.141.128"; int port = 12345; int ret = 0; struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int listenfd = socket(PF_INET, SOCK_STREAM, 0); assert(listenfd >= 0); ret = bind(listenfd, (struct sockaddr *)&address, sizeof(address)); if (ret == -1) { printf("errno is %d\n", errno); return 1; } ret = listen(listenfd, 5); assert(ret != -1); epoll_event events[MAX_EVENT_NUMBER]; int epollfd = epoll_create(5); assert(epollfd != -1); addfd(epollfd, listenfd); // 使用 socketpair 创建全双工管道,并注册 pipefd[0] 的可读事件 ret = socketpair(PF_UNIX, SOCK_STREAM, 0, pipefd); assert(ret != -1); setnonblocking(pipefd[1]); addfd(epollfd, pipefd[0]); // 添加感兴趣信号 addsig(SIGHUP); // 1 addsig(SIGCHLD); // 17 addsig(SIGTERM); // 15 addsig(SIGINT); // 2 bool stop_server = false; while (!stop_server) { int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1); if ((number < 0) && (errno != EINTR)) { printf("epoll failure\n"); break; } for (int i = 0; i < number; i++) { int sockfd = events[i].data.fd; if (sockfd == listenfd) { struct sockaddr_in client_address; socklen_t client_addrlength = sizeof(client_address); int connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength); addfd(epollfd, connfd); } // 处理信号 else if ((sockfd == pipefd[0]) && (events[i].events & EPOLLIN)) { int sig; char signals[1024]; ret = recv(pipefd[0], signals, sizeof(signals), 0); if (ret == -1) { continue; } else if (ret == 0) { continue; } else { for (int i = 0; i < ret; ++i) { printf("I caugh the signal %d\n", signals[i]); switch (signals[i]) { case SIGCHLD: printf("signal name is SIGCHLD\n"); break; case SIGHUP: printf("signal name is SIGHUP\n"); break; case SIGTERM: printf("signal name is SIGTERM\n"); stop_server = true; break; case SIGINT: printf("signal name is SIGINT\n"); stop_server = true; break; } } } } else { } } } printf("close fds\n"); close(listenfd); close(epollfd); close(pipefd[1]); close(pipefd[0]); return 0; } - 实验结果
- 在另外一个终端调用如下kill命令

- 在当前终端有如下输出
10.5 网络编程相关信号
(1)SIGHUP
- SIGHUP 信号在用户终端连接(正常或非正常)结束时发出, 通常是在终端的控制进程结束时, 通知同一session内的各个作业, 这时它们与控制终端不再关联。系统对SIGHUP信号的默认处理是终止收到该信号的进程,所以若程序中没有专门处理该信号,当收到该信号时,进程就会退出。
- 在我们登录Linux时,系统会分配给登录用户一个终端(Session)。在这个终端运行的所有程序,包括前台进程组和后台进程组,一般都属于这个 Session。当用户退出Linux登录时,前台进程组和后台(huponexit是on)进程将会收到SIGHUP信号。这个信号的默认操作为终止进程,因此前台进 程组和后台有终端输出的进程就会中止。
- 对于与终端脱离关系的守护进程,这个信号一般用于通知它重新读取配置文件。 比如xinetd超级服务程序。当xinetd程序在接收到SIGHUP信号之后调用hard_reconfig函数,它将循环读取/etc/xinetd.d/目录下的每个子配置文件,并检测其变化。如果某个正在运行的子服务的配置文件被修改以停止服务,则xinetd主进程讲给该子服务进程发送SIGTERM信号来结束它。如果某个子服务的配置文件被修改以开启服务,则xinetd将创建新的socket并将其绑定到该服务对应的端口上。

(2)SIGPIPE
-
在网络编程中经常会遇到
SIGPIPE信号,默认情况下这个信号会终止整个进程。 -
默认情况下,往一个读端关闭的管道或socket连接中写数据将引发SIGPIPE信号。我们需要在代码中捕获并处理该信号,或者至少忽略它,因为程序接收到SIGPIPE信号的默认行为是结束进程,而我们绝对不希望因为错误的写操作而导致程序退出。引起SIGPIPE信号的写操作将设置errno为EPIPE。
-
如何处理呢,有以下几种方式:
-
(1)我们可以使用send函数的MSG_NOSIGNAL标志来禁止写操作触发SIGPIPE信号。在这种情况下,我们应该使用send函数反馈的errno值来判断管道或者socket连接的读端是否已经关闭。
-
(2)我们也可以利用I/O复用系统调用来检测管道和socket连接的读端是否已经关闭。以poll为例:
-
(a)当管道的写端关闭时,读端文件描述符上的POLLHUP事件将被触发;(读端关闭,不会触发写端的POLLHUP事件,而是写端写入数据会引发SIGPIPE信号)
-
以下是测试代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50#include <fcntl.h> #include <iostream> #include <poll.h> #include <sys/stat.h> #include <sys/types.h> #include <unistd.h> int main() { int pipefd[2]; if (pipe(pipefd) == -1) { std::cerr << "Failed to create pipe." << std::endl; return 1; } int readfd = pipefd[0]; int writefd = pipefd[1]; // 在子进程中关闭读端 if (fork() == 0) { close(readfd); // 模拟一段时间后关闭写端 sleep(2); close(writefd); return 0; } else { close(writefd); // 在父进程中关闭写端 struct pollfd fds[1]; fds[0].fd = readfd; fds[0].events = POLLHUP; while (true) { int ret = poll(fds, 1, 200); printf("poll once\n"); if (ret == -1) { std::cerr << "poll() failed." << std::endl; break; } else if (ret > 0) { if (fds[0].revents & POLLHUP) { std::cout << "POLLHUP event received. Read end of the pipe " "has been closed." << std::endl; break; } } } close(readfd); return 0; } } -
-
(b)当socket连接被对方关闭时或对方关闭写的时候,socket上的POLLRDHUP事件将被触发。
-
(3)SIGURG
-
在Linux环境下,内核通知应用程序带外数据到达主要有三种方法:
- 第一种是利用sockatmark函数。
- 第二种是I/O复用技术,select等系统调用在接收到带外数据时将返回,并向应用程序报告socket上的异常事件。
- 第三种方法就是使用SIGURG信号。
-
使用SIGURG接收带外数据,需要利用
fcntl(connfd, F_SETOWN, getpid());来设置socket的宿主进程或进程组。通过将当前进程设置为套接字的宿主进程或进程组,当套接字接收到紧急数据(带外数据)时,操作系统将发送SIGURG信号给宿主进程或进程组。 -
服务器代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <signal.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> #define BUF_SIZE 1024 static int connfd; void sig_urg(int sig) { int save_errno = errno; char buffer[BUF_SIZE]; memset(buffer, '\0', BUF_SIZE); // 直接读取 int ret = recv(connfd, buffer, BUF_SIZE - 1, MSG_OOB); printf("got %d bytes of oob data '%s'\n", ret, buffer); fflush(stdout); // 刷新标准输出缓冲区 errno = save_errno; } void addsig(int sig, void (*sig_handler)(int)) { struct sigaction sa; memset(&sa, '\0', sizeof(sa)); sa.sa_handler = sig_handler; sa.sa_flags |= SA_RESTART; sigfillset(&sa.sa_mask); assert(sigaction(sig, &sa, NULL) != -1); } int main(int argc, char *argv[]) { const char *ip = "192.168.141.128"; int port = 12345; struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int sock = socket(PF_INET, SOCK_STREAM, 0); assert(sock >= 0); int ret = bind(sock, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(sock, 5); assert(ret != -1); struct sockaddr_in client; socklen_t client_addrlength = sizeof(client); connfd = accept(sock, (struct sockaddr *)&client, &client_addrlength); if (connfd < 0) { printf("errno is: %d\n", errno); } else { // 设置信号处理函数 addsig(SIGURG, sig_urg); /*使用SIGURG信号之前,我们必须设置socket的宿主进程或进程组*/ fcntl(connfd, F_SETOWN, getpid()); char buffer[BUF_SIZE]; while (1) { memset(buffer, '\0', BUF_SIZE); ret = recv(connfd, buffer, BUF_SIZE - 1, 0); if (ret <= 0) { break; } printf("got %d bytes of normal data '%s'\n", ret, buffer); } close(connfd); } close(sock); return 0; } -
客户端代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37#include <arpa/inet.h> #include <assert.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> int main(int argc, char *argv[]) { const char *ip = "192.168.141.128"; int port = 12345; struct sockaddr_in server_address; memset(&server_address, 0, sizeof(server_address)); server_address.sin_family = AF_INET; inet_pton(AF_INET, ip, &server_address.sin_addr); server_address.sin_port = htons(port); int sockfd = socket(PF_INET, SOCK_STREAM, 0); assert(sockfd >= 0); if (connect(sockfd, (struct sockaddr *)&server_address, sizeof(server_address)) < 0) { printf("connection failed\n"); } else { printf("send oob data out\n"); const char *oob_data = "abc"; const char *normal_data = "123"; send(sockfd, normal_data, strlen(normal_data), 0); sleep(2); send(sockfd, oob_data, strlen(oob_data), MSG_OOB); // 使用 MSG_OOB标记 send(sockfd, normal_data, strlen(normal_data), 0); } close(sockfd); return 0; } -
第11章 定时器
- 网络程序需要处理的第三类事件是定时事件,比如定期检测一个客户连接的活动状态。
- 服务器程序通常管理着众多定时事件,因此有效地组织这些定时事件,使之能在预期的时间点被触发且不影响服务器的主要逻辑,对于服务器的性能有着至关重要的影响。为此,我们要将每个定时事件分别封装成定时器,并使用某种容器类数据结构,比如链表、排序链表和时间轮,将所有定时器串联起来,以实现对定时事件的统一管理。
- 常见有两种高效的管理定时器的容器:时间轮和时间堆。
- 不过,在讨论如何组织定时器之前,我们先要介绍定时的方法。定时是指在一段时间之后触发某段代码的机制,我们可以在这段代码中依次处理所有到期的定时器。换言之,定时机制是定时器得以被处理的原动力。
- Linux提供了三种定时方法,它们是:
- socket选项SO_RCVTIMEO和SO_SNDTIMEO。
- SIGALRM信号。
- I/O复用系统调用的超时参数。

11.1 SO_RCVTIMEO和SO_SNDTIMEO
- socket选项SO_RCVTIMEO 和SO_SNDTIMEO,它们分别用来设置socket接收数据超时时间和发送数据超时时间。因此,这两个选项仅对与tcp数据接收和发送相关的socket专用系统调用有效,这些系统调用包括send、sendmsg、 recv、 recvmsg、accept 和connect。我们将选项SO_RCVTIMEO和SO_SNDTIMEO对这些系统调用的影响总结于表中。
- 我们可以根据系统调用(send、 sendmsg、 recv、recvmsg、accept和connect)的返回值以及errno来判断超时时间是否已到,进而决定是否开始处理定时任务。
- 下列代码以connect为例,说明程序中如何使用SO_SNDTIMEO选项定时。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <sys/types.h> #include <unistd.h> int timeout_connect(const char *ip, int port, int time) { int ret = 0; struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int sockfd = socket(PF_INET, SOCK_STREAM, 0); assert(sockfd >= 0); struct timeval timeout; // 定时10s timeout.tv_sec = time; timeout.tv_usec = 0; socklen_t len = sizeof(timeout); ret = setsockopt(sockfd, SOL_SOCKET, SO_SNDTIMEO, &timeout, len); assert(ret != -1); ret = connect(sockfd, (struct sockaddr *)&address, sizeof(address)); if (ret == -1) { // 超时事件 if (errno == EINPROGRESS) { printf("connecting timeout\n"); return -1; } printf("error occur when connecting to server\n"); return -1; } return sockfd; } int main(int argc, char *argv[]) { const char *ip = "98.168.141.128"; int port = 12345; int sockfd = timeout_connect(ip, port, 10); if (sockfd < 0) { return 1; } close(sockfd); return 0; } - 测试结果如下:
11.2 SIGALRM 信号
- 由alarm和setitimer函数设置的实时闹钟一旦超时,将触发SIGALRM信号。因此,我们可以利用该信号的信号处理函数来处理定时任务。但是,如果要处理多个定时任务,我们就需要不断地触发SIGALRM信号,并在其信号处理函数中执行到期的任务。一般而言,SIGALRM信号按照固定的频率生成,即由alarm或setitimer函数设置的定时周期T保持不变。如果某个定时任务的超时时间不是T的整数倍,那么它实际被执行的时间和预期的时间将略有偏差。因此定时周期T反映了定时的精度。
- 需要注意的是,windows下的接口支持单进程中拥有多个定时器,而linux则只允许单进程拥有一个定时器,因此在linux下的单进程中要使用多个定时器,则需要自己维护管理。
(1)alarm 函数
-
通过alarm函数触发定时信号,在linux系统中,alarm函数需要的头文件为:
-
1#include <unistd.h> -
函数原型如下:
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15unsigned int alarm(unsigned int seconds) /* - 功能:设置定时器(闹钟)。函数调用,开始倒计时,当倒计时为0的时候, 函数会给当前的进程发送一个信号:SIGALARM - 参数: seconds: 倒计时的时长,单位:秒。如果参数为0,定时器无效(不进行倒计时,不发信号)。 取消一个定时器,通过alarm(0)。 - 返回值: - 之前没有定时器,返回0 - 之前有定时器,返回之前的定时器剩余的时间 alarm(10); -> 返回0 过了1秒 alarm(5); -> 返回9 */ -
需要注意的是
- 闹钟信号只会触发一次,若想循环触发,可以在闹钟到时后重新通过alarm函数触发。这是因为每一个进程都有且只有唯一的一个定时器。
- 可以重新设置闹钟信号,即在上一个闹钟到时之前,通过alarm函数重新设定响铃时刻或取消闹钟。
- alarm 与进程的状态(运行、阻塞等)无关。
-
示例程序
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17#include <signal.h> #include <stdio.h> #include <stdlib.h> #include <unistd.h> int main() { int t = alarm(5); // 设定闹钟5秒之后响铃 printf("set alarmer: %d \n", t); sleep(2); int ret = alarm(4); // 重新设定闹钟4秒之后响铃,上一个闹钟还剩3秒 printf("reset alarmer: %d \n", ret); int i; for (i = 0; i < 15; i++) { printf(" sleep % d ... \n ", i); sleep(1); } return 0; } -
(2)setitimer 函数
-
函数原型
-
1 2#include <sys/time.h> int setitimer(int which, const struct itimerval *new_val, struct itimerval *old_value); -
作用:设置定时器,可以替代 alarm 函数。精度是微秒(us)。
-
1 2 3 4 5 6 7 8struct itimerval { //定时器结构体 struct timeval it_interval; //每个阶段的时间,间隔时间 struct timeval it_value; //延迟多长时间执行定时器 }; struct timeval { //时间的结构体 time_t tv_sec; //秒数 suseconds_t tv_usec; //微秒 }; -
参数:
---- which:定时器以什么时间定时
-------- ITIMER_REAL:真实时间,时间到达后发送 SIGALRM ,是最常用的
-------- ITIMER_VIRTUAL:用户时间,时间到达后发送 SIGVTALRM
-------- ITIMER_PROF:以该进程在用户态和内核态下所消耗的时间来计算,时间到达后发送 SIGPROF
---- new_val:设置定时器的属性
---- old_value:记录上一次的定时的时间参数,一般不使用,指定 NULL
返回:成功返回 0,失败返回 -1
-
注意的是,setitimer 函数在设定的时间间隔过去后触发一个信号,这说明这是一个周期定时器,而不是像alarm一样只定时一次。
-
示例
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34#include <cstdio> #include <cstdlib> #include <signal.h> #include <sys/time.h> static int times = 0; void mysignal(int num) { printf("times : %d -- recv signal : %d\n", times++, num); } int main() { signal(SIGALRM, mysignal); itimerval neval; // 每个2s定时一次 neval.it_interval.tv_sec = 2; neval.it_interval.tv_usec = 0; // 延迟5s执行 neval.it_value.tv_sec = 5; neval.it_value.tv_usec = 0; int ret = setitimer(ITIMER_REAL, &neval, NULL); printf("start alarm\n"); if (-1 == ret) { perror("setimer"); exit(0); } getchar(); return 0; } -
-
值得说明下,信号处理函数里面的时间和主程序的时间是一致的,即如果我在上述程序中信号处理函数中每次都sleep(5),停滞5s,返回主线程会直接再次调用信号处理函数(因为5>2,此时下一个定时器早就到点了),而不会另外在等2s。
(3)基于升序链表的定时器
-
定时器通常至少要包含两个成员:一个超时时间(相对时间或者绝对时间)和一个任务回调函数。有的时候还可能包含回调函数被执行时需要传入的参数,以及是否重启定时器等信息。
-
如果使用链表作为容器来串联所有的定时器,则每个定时器还要包含指向下一个定时器的指针成员。进一步,如果链表是双向的,则每个定时器还需要包含指向前一个定时器的指针成员。
-
如下代码就是一个升序链表的定时器,其中按照超时时间做升序。时间使用绝对时间。命名为
lst_timer.h头文件。 -
其核心函数tick相当于一个心搏函数,它每隔一段固定的时间就执行一次,以检测并处理到期的任务。判断定时任务到期的依据是定时器的expire值小于当前的系统时间。从执行效率来看,添加定时器的时间复杂度是O(n),删除定时器的时间复杂度是O(1),执行定时任务的时间复杂度是O(1)。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160#ifndef LST_TIMER #define LST_TIMER #include <arpa/inet.h> #include <stdio.h> #include <time.h> #define BUFFER_SIZE 64 class util_timer; /*用户数据结构:客户端socket地址、socket文件描述符、读缓存和定时器*/ struct client_data { sockaddr_in address; int sockfd; char buf[BUFFER_SIZE]; util_timer *timer; }; // 通用定时器类 class util_timer { public: util_timer() : prev(NULL), next(NULL) {} public: time_t expire; /*任务的超时时间,这里使用绝对时问*/ void (*cb_func)(client_data *); // 任务回调函数 /*回调函数处理的客户数据,由定时器的执行者传递给回调函数*/ client_data *user_data; util_timer *prev; // 前一个定时器 util_timer *next; // 后一个定时器 }; /*定时器链表。它是一个升序、双向链表,且带有头结点和尾节点*/ class sort_timer_lst { public: sort_timer_lst() : head(NULL), tail(NULL) {} // 析构删除所有定时器 ~sort_timer_lst() { util_timer *tmp = head; while (tmp) { head = tmp->next; delete tmp; tmp = head; } } void add_timer(util_timer *timer) { if (!timer) { return; } if (!head) { head = tail = timer; return; } if (timer->expire < head->expire) { timer->next = head; head->prev = timer; head = timer; return; } // 不能插入头部就调用重载函数保证升序性 add_timer(timer, head); } /*当某个定时任务发生变化时,调整对应的定时器在链表中的位置。这个函数只考虑被调整的定时器的超时时间延长的情况,即该定时器需要往链表的尾部移动*/ void adjust_timer(util_timer *timer) { if (!timer) { return; } util_timer *tmp = timer->next; if (!tmp || (timer->expire < tmp->expire)) { return; } if (timer == head) { head = head->next; head->prev = NULL; timer->next = NULL; add_timer(timer, head); } else { timer->prev->next = timer->next; timer->next->prev = timer->prev; add_timer(timer, timer->next); } } void del_timer(util_timer *timer) { if (!timer) { return; } if ((timer == head) && (timer == tail)) { delete timer; head = NULL; tail = NULL; return; } if (timer == head) { head = head->next; head->prev = NULL; delete timer; return; } if (timer == tail) { tail = tail->prev; tail->next = NULL; delete timer; return; } timer->prev->next = timer->next; timer->next->prev = timer->prev; delete timer; } void tick() { if (!head) { return; } printf("timer tick\n"); time_t cur = time(NULL); util_timer *tmp = head; while (tmp) { // 判断是否超时,以绝对时间为例 if (cur < tmp->expire) { break; } // 调用回调 tmp->cb_func(tmp->user_data); head = tmp->next; if (head) { head->prev = NULL; } delete tmp; tmp = head; } } private: void add_timer(util_timer *timer, util_timer *lst_head) { util_timer *prev = lst_head; util_timer *tmp = prev->next; while (tmp) { if (timer->expire < tmp->expire) { prev->next = timer; timer->next = tmp; tmp->prev = timer; timer->prev = prev; break; } prev = tmp; tmp = tmp->next; } if (!tmp) { prev->next = timer; timer->prev = prev; timer->next = NULL; tail = timer; } } private: util_timer *head; util_timer *tail; }; #endif
(3)处理非活动连接
-
现在我们考虑上述升序定时器链表的实际应用——处理非活动连接。
-
服务器程序通常要定期处理非活动连接:给客户端发一个重连请求,或者关闭该连接,或者其他。Linux在内核中提供了对连接是否处于活动状态的定期检查机制,我们可以通过socket选项KEEPALIVE来激活它。不过使用这种方式将使得应用程序对连接的管理变得复杂。
-
因此,我们可以考虑在应用层实现类似于KEEPALIVE的机制,以管理所有长时间处于非活动状态的连接。比如利用alarm函数周期性地触发SIGALRM信号,该信号的信号处理函数利用管道通知主循环执行定时器链表上的定时任务——关闭非活动的连接。
-
以下是实验代码。一个定时器,使用升序链表串联所有的定时任务。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210#include "lst_timer.h" #include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <pthread.h> #include <signal.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/epoll.h> #include <sys/socket.h> #include <sys/types.h> #include <unistd.h> #define FD_LIMIT 65535 #define MAX_EVENT_NUMBER 1024 #define TIMESLOT 5 static int pipefd[2]; static sort_timer_lst timer_lst; static int epollfd = 0; int setnonblocking(int fd) { int old_option = fcntl(fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl(fd, F_SETFL, new_option); return old_option; } // ET 模式 void addfd(int epollfd, int fd) { epoll_event event; event.data.fd = fd; event.events = EPOLLIN | EPOLLET; epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event); setnonblocking(fd); } // 返回信号主进程处理 void sig_handler(int sig) { int save_errno = errno; int msg = sig; send(pipefd[1], (char *)&msg, 1, 0); errno = save_errno; } void addsig(int sig) { struct sigaction sa; memset(&sa, '\0', sizeof(sa)); sa.sa_handler = sig_handler; sa.sa_flags |= SA_RESTART; sigfillset(&sa.sa_mask); assert(sigaction(sig, &sa, NULL) != -1); } void timer_handler() { timer_lst.tick(); /*因为一次alarm调用只会引起一次SIGALRM信号,所以我们要重新定时,以不断触发SIGALRM信号*/ alarm(TIMESLOT); } /*定时器回调函数,它删除非活动连接socket上的注册事件,并关闭之*/ void cb_func(client_data *user_data) { epoll_ctl(epollfd, EPOLL_CTL_DEL, user_data->sockfd, 0); assert(user_data); close(user_data->sockfd); printf("close fd %d\n", user_data->sockfd); } int main(int argc, char *argv[]) { const char *ip = "192.168.141.128"; int port = 12345; int ret = 0; struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int listenfd = socket(PF_INET, SOCK_STREAM, 0); assert(listenfd >= 0); ret = bind(listenfd, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(listenfd, 5); assert(ret != -1); epoll_event events[MAX_EVENT_NUMBER]; epollfd = epoll_create(5); assert(epollfd != -1); addfd(epollfd, listenfd); ret = socketpair(PF_UNIX, SOCK_STREAM, 0, pipefd); assert(ret != -1); setnonblocking(pipefd[1]); addfd(epollfd, pipefd[0]); // 添加信号 addsig(SIGALRM); addsig(SIGTERM); bool stop_server = false; // 空间换时间 client_data *users = new client_data[FD_LIMIT]; bool timeout = false; // 定时5s alarm(TIMESLOT); while (!stop_server) { int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1); if ((number < 0) && (errno != EINTR)) { printf("epoll failure\n"); break; } for (int i = 0; i < number; i++) { int sockfd = events[i].data.fd; if (sockfd == listenfd) { struct sockaddr_in client_address; socklen_t client_addrlength = sizeof(client_address); int connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength); addfd(epollfd, connfd); users[connfd].address = client_address; users[connfd].sockfd = connfd; /*创建定时器,设置其回调函数与短时时间,然后绑定定时器与用户数据,最后将定时器添加到链表timer1st中*/ util_timer *timer = new util_timer; timer->user_data = &users[connfd]; timer->cb_func = cb_func; time_t cur = time(NULL); timer->expire = cur + 3 * TIMESLOT; users[connfd].timer = timer; timer_lst.add_timer(timer); } else if ((sockfd == pipefd[0]) && (events[i].events & EPOLLIN)) { int sig; char signals[1024]; ret = recv(pipefd[0], signals, sizeof(signals), 0); if (ret == -1) { // handle the error continue; } else if (ret == 0) { continue; } else { for (int i = 0; i < ret; ++i) { switch (signals[i]) { case SIGALRM: { /*用timeout变量标记有定时任务需要处理,但不立即处理定时任务。这是因为定时任务的优先级不是很高,我们优先处理其他更重要的任务*/ timeout = true; break; } case SIGTERM: { stop_server = true; } } } } } else if (events[i].events & EPOLLIN) { memset(users[sockfd].buf, '\0', BUFFER_SIZE); ret = recv(sockfd, users[sockfd].buf, BUFFER_SIZE - 1, 0); printf("get %d bytes of client data %s from %d\n", ret, users[sockfd].buf, sockfd); util_timer *timer = users[sockfd].timer; // 这里没有循环读,当个示例算了 if (ret < 0) { /*如果发生读错误,则关闭连接,并移除其对应的定时器 */ if (errno != EAGAIN) { cb_func(&users[sockfd]); if (timer) { timer_lst.del_timer(timer); } } } else if (ret == 0) { /*如果对方已经关闭连接,则关闭连接,并移除其对应的定时器 */ cb_func(&users[sockfd]); if (timer) { timer_lst.del_timer(timer); } } else { // 确实有数据可读,则我们需要调整定义的定时器,延迟连接被关闭的时间 if (timer) { time_t cur = time(NULL); timer->expire = cur + 3 * TIMESLOT; printf("adjust timer once\n"); timer_lst.adjust_timer(timer); } } } else { printf("something else happened\n"); } } /*最后处理定时事件,因为I/O事件有更高的优先级。当然,这样做将导致定时任务不能精确地按照预期的时间执行*/ if (timeout) { timer_handler(); timeout = false; } } close(epollfd); close(listenfd); close(pipefd[1]); close(pipefd[0]); delete[] users; return 0; } -
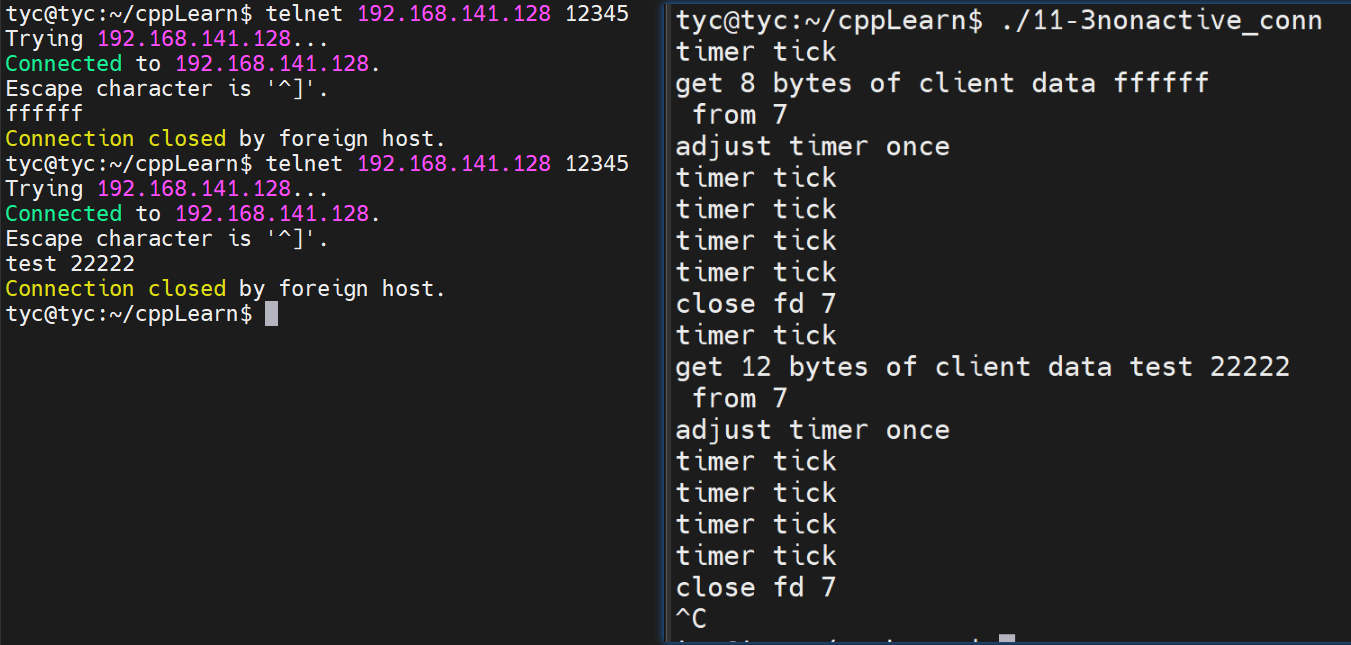
-
可以看到确实经过4次tick即处理非活动连接,尽管时间不是非常准确。
11.3 I/O复用系统调用的超时参数
-
Linux下的3组I/O复用系统调用都带有超时参数,因此它们不仅能统一处理信号和I/O事件,也能统一处理定时事件。 但是由于I/O复用系统调用可能在超时时间到期之前就返回(有I/O事件发生),所以如果我们要利用它们来定时,就需要不断更新定时参数以反映剩余的时间。
-
利用epoll的超时参数,实现定时5s的定时器
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41#define TIMEOUT 5000 #define MAX_EVENT_NUMBER 1024 int timeout = TIMEOUT; // 定时5s time_t start = time(NULL); time_t end = time(NULL); int epollfd = epoll_create(5); struct epoll_event events[MAX_EVENT_NUMBER]; while (1) { printf("the timeout now is %d mil-seconds\n"); start = time(NULL); int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, timeout); if ((number < 0) && (errno != EINTR)) { printf("epoll failture\n"); break; } /*超时时间到,此时可处理定时任务,并重置定时时间 */ if (number == 0) { timeout = TIMEOUT; // do something 可处理定时任务 continue; } end = time(NULL); /*如果epoll_wait返回值大于0,则本次epoll_wait调用持续时间是 (end - start)*1000ms,要将定时时间timeout减去这段时间,以 获得下次epoll_wait调用的超时参数 */ timeout -= (end - start) * 1000; /*重新计算之后的timeout值有可能等于0,说明本次epoll_wait调用 返回时,不仅有文件描述符就绪,而且超时时间也刚好到达,此时也要 处理定时任务,并重置定时时间 */ if (timeout <= 0) { timeout = TIMEOUT; // do something 可处理定时任务 // 处理其他I/O事件 continue; } }
11.4 高性能定时器
(1)时间轮
-
时间轮(Timing Wheel)算法的应用非常广泛,在 Dubbo、Netty、Kafka、ZooKeeper、Quartz 的组件中都有时间轮思想的应用,甚至在 Linux 内核中都有用到。
-
前面的基于升序链表的定时器存在一个问题:添加定时器的效率偏低。
-
-
上图所示的时间轮内,(实线) 指针指向轮子上的一个槽(slot)。 它以恒定的速度顺时针转动,每转动一步就指向下一个槽( 虚线指针指向的槽),每次转动称为一个滴答(tick)。一个滴答的时间称为时间轮的槽间隔si (slot interval), 它实际上就是心搏时间。
-
该时间轮共有N个槽,因此它运转一周的时间是
N*si。每个槽指向一条定时器链表,每条链表上的定时器具有相同的特征:它们的定时时间相差N*si的整数倍(可能是0)。 -
时间轮正是利用这个关系将定时器散列到不同的链表中。假如现在指针指向槽cs,我们要添加一个定时时间为ti的定时器,则该定时器将被插人槽ts (timer slot)对应的链表中:
-
1ts=(cs+(ti/si))%N -
基于排序链表的定时器使用唯一的一条链表来管理所有定时器,所以插人操作的效率随着定时器数目的增多而降低。而时间轮使用哈希表的思想,将定时器散列到不同的链表上。这样每条链表上的定时器数目都将明显少于原来的排序链表上的定时器数目,插入操作的效率基本不受定时器数目的影响。
-
很显然,对时间轮而言,要提高定时精度,就要使si值足够小;要提高执行效率,则要求N值足够大。
-
上图描述的是一种简单的时间轮,因为它只有一个轮子。而复杂的时间轮可能有多个轮子,不同的轮子拥有不同的粒度。相邻的两个轮子,精度高的转一圈, 精度低的仅往前移动一槽,就像水表一样。
-
以下是简单时间轮的实现代码。定时时间是相对时间。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137#ifndef TIME_WHEEL_TIMER #define TIME_WHEEL_TIMER #include <netinet/in.h> #include <stdio.h> #include <time.h> #define BUFFER_SIZE 64 class tw_timer; // 绑定socket和定时器 struct client_data { sockaddr_in address; int sockfd; char buf[BUFFER_SIZE]; tw_timer *timer; }; // 定时器类 class tw_timer { public: tw_timer(int rot, int ts) : next(NULL), prev(NULL), rotation(rot), time_slot(ts) {} public: int rotation; // 记录定时器在时间轮转多少圈后生效 int time_slot; // 记录定时器属于时间轮上的哪个槽slot void (*cb_func)(client_data *); // 回调函数 client_data *user_data; // 客户数据 tw_timer *next; // 指向下一个定时器 tw_timer *prev; // 指向上一个定时器 }; class time_wheel { public: time_wheel() : cur_slot(0) { for (int i = 0; i < N; ++i) { // 初始化每个槽的头结点 slots[i] = NULL; } } ~time_wheel() { for (int i = 0; i < N; ++i) { tw_timer *tmp = slots[i]; while (tmp) { slots[i] = tmp->next; delete tmp; tmp = slots[i]; } } } // 根据定时值timeout创建一个定时器,并插入到合适的槽中 tw_timer *add_timer(int timeout) { if (timeout < 0) { return NULL; } int ticks = 0; if (timeout < TI) { ticks = 1; } else { ticks = timeout / TI; } int rotation = ticks / N; int ts = (cur_slot + (ticks % N)) % N; tw_timer *timer = new tw_timer(rotation, ts); if (!slots[ts]) { printf("add timer, rotation is %d, ts is %d, cur_slot is %d\n", rotation, ts, cur_slot); slots[ts] = timer; } else { timer->next = slots[ts]; slots[ts]->prev = timer; slots[ts] = timer; } return timer; } // 删除目标定时器 void del_timer(tw_timer *timer) { if (!timer) { return; } int ts = timer->time_slot; if (timer == slots[ts]) { slots[ts] = slots[ts]->next; if (slots[ts]) { slots[ts]->prev = NULL; } delete timer; } else { timer->prev->next = timer->next; if (timer->next) { timer->next->prev = timer->prev; } delete timer; } } void tick() { tw_timer *tmp = slots[cur_slot]; printf("current slot is %d\n", cur_slot); // 遍历当前槽的所有定时器 while (tmp) { printf("tick the timer once\n"); if (tmp->rotation > 0) { tmp->rotation--; tmp = tmp->next; } else { tmp->cb_func(tmp->user_data); if (tmp == slots[cur_slot]) { printf("delete header in cur_slot\n"); slots[cur_slot] = tmp->next; delete tmp; if (slots[cur_slot]) { slots[cur_slot]->prev = NULL; } tmp = slots[cur_slot]; } else { tmp->prev->next = tmp->next; if (tmp->next) { tmp->next->prev = tmp->prev; } tw_timer *tmp2 = tmp->next; delete tmp; tmp = tmp2; } } } cur_slot = ++cur_slot % N; } private: static const int N = 60; // 槽的个数 static const int TI = 1; // 槽间隔1s tw_timer *slots[N]; // 每个槽的无序链表 int cur_slot; // 当前槽 }; #endif -
从以上代码可以看出,时间轮算法,添加定时器的时间复杂度是O(1),删除定时器的时间复杂度是O(1),执行定时任务的时间复杂度是O(n)。但实际上执行的实际复杂度是小于 O(n)的,因为离散化了。当使用多个轮子的时候,执行时间复杂度可以接近于O(1)。
(2)时间堆
-
前面讨论的两种(升序链表、时间轮)定时方案都是以固定的频率调用心搏函数tick,并在其中依次检测到期的定时器,然后执行到期定时器上的回调函数。
-
设计定时器的另外一种思路是:将所有定时器中超时时间最小的一个定时器的超时值作为心搏间隔。这样,一旦心搏函数tick被调用,超时时间最小的定时器必然到期,我们就可以在tick函数中处理该定时器。然后,再次从剩余的定时器中找出超时时间最小的一个,并将这段最小时间设置为下一次心搏间隔。如此反复,就实现了较为精确的定时。
-
显然,实现这种算法的最好数据结构就是最小堆(小根堆)。
-
最小堆,是一种经过排序的完全二叉树,其中任一非终端节点的数据值均不大于其左子节点和右子节点的值(左右子节点无排序要求,但要大于根节点,和二叉搜索树的区别)。
-
最小堆的基本操作是插入节点和删除节点。
-
插入元素时,插入到数组中的最后一个元素的后面,然后与该节点的父节点比较大小。如果插入的元素小于父节点元素,那么与父节点交换位置。然后插入元素交换到父节点位置时,又与该节点的父节点比较,直到大于父节点元素或者到达堆顶。该过程叫做上浮,即插入时上浮。
-
-
移除元素时,只能从堆顶移除元素,再取最后一个元素放到堆顶中。然后堆顶节点与子节点比较时,先取子节点中的较小者,如果堆顶节点大于较小子节点,那么交换位置。此时堆顶节点元素交换到较小子节点上。然后再与其较小子节点比较,直到小于较小子节点或者到达叶子节点为止。该过程叫做下沉,即移除元素时下沉。
-
-
因此,构建最小堆有两种方法:
- 上浮构建:每次插入新元素到末尾,依次上浮。
- 下沉构建:将一个完全无序的二叉树构造成最小堆,从最后一个非叶子节点开始,依次进行下沉操作下沉。
-
以下是时间堆的简单实现
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189#ifndef intIME_HEAP #define intIME_HEAP #include <iostream> #include <netinet/in.h> #include <time.h> using std::exception; #define BUFFER_SIZE 64 class heap_timer; // 绑定socket和定时器 struct client_data { sockaddr_in address; int sockfd; char buf[BUFFER_SIZE]; heap_timer *timer; }; // 定时器类 class heap_timer { public: heap_timer(int delay) { expire = time(NULL) + delay; } public: time_t expire; // 定时器生效的绝对时间 void (*cb_func)(client_data *); // 回调函数 client_data *user_data; // 用户数据 }; // 时间堆类 /* 0 1 2 3 4 parent: (x-1)/2 left: 2x+1 right 2x+2 */ class time_heap { public: time_heap(int cap) : capacity(cap), cur_size(0) { array = new heap_timer *[capacity]; if (!array) { throw std::exception(); } for (int i = 0; i < capacity; ++i) { array[i] = NULL; } } // 用原始数组建堆 time_heap(heap_timer **init_array, int size, int capacity) : cur_size(size), capacity(capacity) { if (capacity < size) { throw std::exception(); } array = new heap_timer *[capacity]; if (!array) { throw std::exception(); } for (int i = 0; i < capacity; ++i) { array[i] = NULL; } if (size != 0) { for (int i = 0; i < size; ++i) { array[i] = init_array[i]; } // 从最后一个非叶子节点开始,依次进行下沉操作 for (int i = (cur_size - 1) / 2; i >= 0; --i) { percolate_down(i); } } } ~time_heap() { for (int i = 0; i < cur_size; ++i) { delete array[i]; } delete[] array; } public: void add_timer(heap_timer *timer) { if (!timer) { return; } if (cur_size >= capacity) { resize(); } int hole = cur_size++; int parent = 0; // 依次上浮 for (; hole > 0; hole = parent) { parent = (hole - 1) / 2; if (array[parent]->expire <= timer->expire) { break; } array[hole] = array[parent]; } array[hole] = timer; } void del_timer(heap_timer *timer) { if (!timer) { return; } // 这个删除很敷衍,实际上还需要删除后重新调整堆 timer->cb_func = NULL; } heap_timer *top() const { if (empty()) { return NULL; } return array[0]; } // 删除堆顶 void pop_timer() { if (empty()) { return; } if (array[0]) { delete array[0]; array[0] = array[--cur_size]; percolate_down(0); } } void tick() { heap_timer *tmp = array[0]; time_t cur = time(NULL); while (!empty() && !tmp) { if (!tmp) { break; } if (tmp->expire > cur) { break; } if (array[0]->cb_func) { array[0]->cb_func(array[0]->user_data); } pop_timer(); tmp = array[0]; } } bool empty() const { return cur_size == 0; } private: // 下沉操作: void percolate_down(int hole) { heap_timer *temp = array[hole]; int child = 0; for (; ((hole * 2 + 1) <= (cur_size - 1)); hole = child) { child = hole * 2 + 1; // 取左右较小值 if ((child < (cur_size - 1)) && (array[child + 1]->expire < array[child]->expire)) { ++child; } if (array[child]->expire < temp->expire) { array[hole] = array[child]; } else { break; } } array[hole] = temp; } // 容量扩大两倍 void resize() { heap_timer **temp = new heap_timer *[2 * capacity]; for (int i = 0; i < 2 * capacity; ++i) { temp[i] = NULL; } if (!temp) { throw std::exception(); } capacity = 2 * capacity; for (int i = 0; i < cur_size; ++i) { temp[i] = array[i]; } delete[] array; array = temp; } private: heap_timer **array; // 指针数组,最小堆 int capacity; // 堆数组容量 int cur_size; // 当前个数 }; #endif -
虽然上述实现的删除操作很敷衍,但是也确实可行,且降低了删除的时间复杂度。
-
从代码可以看出,对于时间堆算法,添加定时器的时间复杂度是O(lgn),删除定时器的时间复杂度是O(1),执行定时任务的时间复杂度是O(1)。
-
因此时间堆的效率是很高的。
第12章 高性能I/O框架库 Libevent
12.1 I/O 框架库概述
-
I/O 框架库以库函数的形式,封装了较为底层的系统调用,给应用程序提供了一组更便于使用的接口。这些库函数往往比程序员自己实现的同样功能的函数更合理、更高效,且更健壮。因为它们经受住了真实网络环境下的高压测试,以及时间的考验。
-
各种 I/O 框架库的实现原理基本相似,要么以 Reactor 模式实现,要么以 Proactor 模式实现,要么同时以这两种模式实现。
-
基于 Reactor 模式的 I/O 框架库包含如下几个组件:句柄(Handle)、事件多路分发器(EventDemultiplexer)、事件处理器(EventHandler)和具体的事件处理器(ConcreteEventHandler)、Reactor 。这些组件的关系下:
-

-
(1)句柄(Handle)
-
I/O 框架库要处理的对象,即 I/O 事件、信号和定时事件,统一称为事件源。一个事件源通常和一个句柄绑定在一起。句柄的作用是:当内核检测到就绪事件时,它将通过句柄来通知应用程序这一事件。
-
在 Linux 环境下,I/O 事件对应的句柄是文件描述符,信号事件对应的句柄就是信号值。
-
(2)事件多路分发器(EventDemultiplexer)
-
事件的到来是随机的、异步的。我们无法预知程序何时收到一个客户连接请求,又亦或收到一个暂停信号。所以程序需要循环地等待并处理事件,这就是事件循环。在事件循环中,等待事件一般使用 I/O 复用技术来实现。I/O 框架库一般将系统支持的各种 I/O 复用系统调用封装成统一的接口,称为事件多路分发器。
-
事件多路分发器的 demultiplex 方法是等待事件的核心函数,其内部调用的是 select 、poll 、epoll_wait 等函数。
-
此外,事件多路分发器还需要实现 register_event 和 remove_event 方法,以供调用者往事件多路分发器中添加事件和从事件多路分发器中删除事件。
-
(3)事件处理器和具体事件处理器
-
事件处理器执行事件对应的业务逻辑。它通常包含一个或多个 handle_event 回调函数,这些回调函数在事件循环中被执行。 I/O 框架库提供的事件处理器通常是一个接口,用户需要继承它来实现自己的事件处理器,即具体事件处理器。因此,事件处理器中的回调函数一般被声明为虚函数,以支持用户的扩展。
-
此外,事件处理器一般还提供一个 get_handle 方法,它返回与该事件处理器关联的句柄。那么,事件处理器和句柄有什么关系?当事件多路分发器检测到有事件发生时,它是通过句柄来通知应用程序的。因此,我们必须将事件处理器和句柄绑定,才能在事件发生时获取到正确的事件处理器。
-
(4)Reactor
-
Reactor 是 I/O 框架库的核心。它提供的几个主要方法是:
- handle_events:该方法执行事件循环。它重复如下过程:等待事件,然后依次处理所有就绪事件对应的事件处理器;
- register_handler:该方法调用事件多路分发器的 register_event 方法来往事件多路分发器中注册一个事件;
- remove_handler:该方法调用事件多路分发器的 remove_event 方法来删除事件多路分发器中的一个事件。
-
(5)基于 Reactor 模式的 I/O 框架库的总体工作时序
-
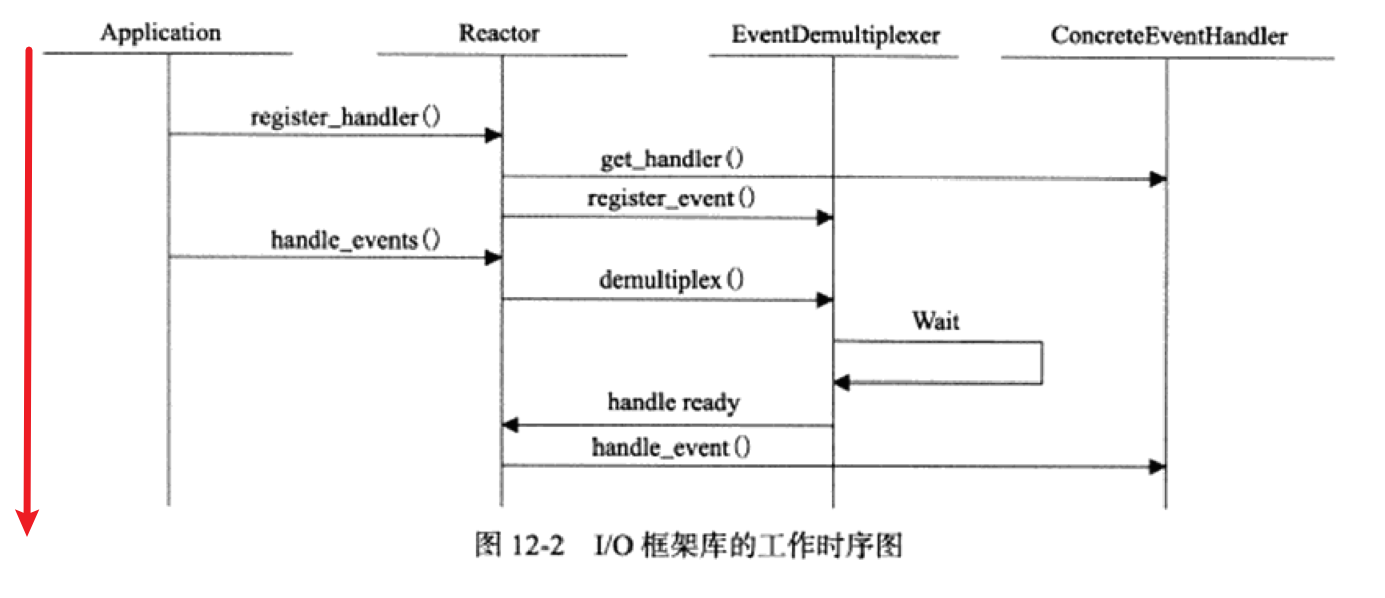
12.2 libevent 源码分析
(1)实例
-
首先在ubuntu上安装libevent。
-
libevent 官网下载安装包。
-
1 2 3 4 5 6tar -zxvf libevent-2.1.12-stable.tar.gz sudo apt-get update sudo apt-get install libssl-dev ./configure -prefix=/usr/local/libevent // 更改安装位置为/usr/local/libevent make make install -
以下是测试代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29#include <event.h> #include <sys/signal.h> void signal_cb(int fd, short event, void *argc) { struct event_base *base = (event_base *)argc; struct timeval delay = {2, 0}; printf("Caught an interrupt signal; exiting cleanly in two seconds...\n"); event_base_loopexit(base, &delay); } void timeout_cb(int fd, short event, void *argc) { printf("timeout\n"); } int main() { struct event_base *base = event_init(); struct event *signal_event = evsignal_new(base, SIGINT, signal_cb, base); event_add(signal_event, NULL); timeval tv = {1, 0}; struct event *timeout_event = evtimer_new(base, timeout_cb, NULL); event_add(timeout_event, &tv); event_base_dispatch(base); event_free(timeout_event); event_free(signal_event); event_base_free(base); return 0; } -
编译命令
g++ test.cpp -o test -I /usr/local/libevent/include/ -L /usr/local/libevent/lib/ -l event -
这里说明一下,使用 g++ 命令行进行编译的时候可以使用如下结构:
-
g++ -std=c++17 xxx.cpp -o xxx.o -L 链接库目录 -I 头文件目录 -ltbb;后面的-ltbb经过搜索得知链接规则,想链接其他库只需要保留 -l,然后加上去掉想链接的 lib*.so 中的 * 部分即可。 -
实验结果
-

-
由代码可知,调用 Libevent 库的主要逻辑如下:
-
- 调用 event_init 函数创建 event_base 对象。一个 event_base 相当于一个 Reactor 实例;
-
- 创建具体的事件处理器,并设置它们所从属的 Reactor 实例。evsignal_new 和 evtimer_new 分别用于创建信号事件处理器和定时事件处理器;
-
- 调用 event_add 函数,将事件处理器添加到注册事件队列中,并将该事件处理器对应的事件添加到事件多路分发器中。event_add 函数相当于 Reactor 中的 register_handler 方法。
-
- 调用 event_base_dispatch 函数来执行事件循环。
-
- 事件循环结束后,使用 *_free 系列函数来释放系统资源。
-
(2)浅析
-
Reactor模型是一种事件驱动机制,所有事情都当做事件来处理(例如:Libevent的I/O、定时和信号),应用为事件注册一个回调函数到Reactor上,当事件发生时Reactor调用注册的回调函数以处理相应的事件。
-
Libevent是开源社区一款高性能的I/O框架库,其具有如下特点:
1、跨平台支持。Libevent支持Linux、UNIX和Windows。
2、统一事件源。libevent对i/o事件、信号和定时事件提供统一的处理。
3、线程安全。libevent使用libevent_pthreads库来提供线程安全支持。
4、基于reactor模式的实现。
5、轻量级,专注于网络,没有ACE那么臃肿庞大
6、可以注册事件优先级
-
Libevent的三个重要的结构体是
event_base结构体、event结构体和eventop结构体。 -
event_base结构体就是 Reactor。 -
event结构体:Libevent 是基于事件驱动(event-driven)的,从名字也可以看到 event 是整个库的核心。 event 就是 Reactor 框架中的事件处理程序组件;它提供了函数接口,供 Reactor 在事件发生时调用,以执行相应的事件处理,通常它会绑定一个有效的句柄。 -
eventop结构体:Libevent支持多种I/O多路复用技术的关键就在于结构体eventop,这个结构体的成员是一系列的函数指针,包括初始化和释放evnt_base,注册、删除和分发事件等5个接口函数,所有I/O多路复用机制(Epoll、Select、Poll、KQueue、DevPoll等)都必须实现这5个接口函数,并在初始化的时候将eventop的这5个接口函数指针指向设置的I/O多路复用(如Epoll)实现的5个函数。
(3)事件处理主循环
-
Libevent 的事件主循环主要是通过 event_base_loop () 函数完成的,其主要操作如下面的流程图所示。
-
-
源码如下所示
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102int event_base_loop(struct event_base *base, int flags) { const struct eventop *evsel = base->evsel; struct timeval tv; struct timeval *tv_p; int res, done, retval = 0; /* Grab the lock. We will release it inside evsel.dispatch, and again * as we invoke user callbacks. */ EVBASE_ACQUIRE_LOCK(base, th_base_lock); if (base->running_loop) { event_warnx("%s: reentrant invocation. Only one event_base_loop" " can run on each event_base at once.", __func__); EVBASE_RELEASE_LOCK(base, th_base_lock); return -1; } base->running_loop = 1; clear_time_cache(base); if (base->sig.ev_signal_added && base->sig.ev_n_signals_added) evsig_set_base_(base); done = 0; #ifndef EVENT__DISABLE_THREAD_SUPPORT base->th_owner_id = EVTHREAD_GET_ID(); #endif base->event_gotterm = base->event_break = 0; while (!done) { base->event_continue = 0; base->n_deferreds_queued = 0; /* Terminate the loop if we have been asked to */ if (base->event_gotterm) { break; } if (base->event_break) { break; } tv_p = &tv; if (!N_ACTIVE_CALLBACKS(base) && !(flags & EVLOOP_NONBLOCK)) { timeout_next(base, &tv_p); } else { /* * if we have active events, we just poll new events * without waiting. */ evutil_timerclear(&tv); } /* If we have no events, we just exit */ if (0==(flags&EVLOOP_NO_EXIT_ON_EMPTY) && !event_haveevents(base) && !N_ACTIVE_CALLBACKS(base)) { event_debug(("%s: no events registered.", __func__)); retval = 1; goto done; } event_queue_make_later_events_active(base); clear_time_cache(base); res = evsel->dispatch(base, tv_p); if (res == -1) { event_debug(("%s: dispatch returned unsuccessfully.", __func__)); retval = -1; goto done; } update_time_cache(base); timeout_process(base); if (N_ACTIVE_CALLBACKS(base)) { int n = event_process_active(base); if ((flags & EVLOOP_ONCE) && N_ACTIVE_CALLBACKS(base) == 0 && n != 0) done = 1; } else if (flags & EVLOOP_NONBLOCK) done = 1; } event_debug(("%s: asked to terminate loop.", __func__)); done: clear_time_cache(base); base->running_loop = 0; EVBASE_RELEASE_LOCK(base, th_base_lock); return (retval); } -
(a)I/O 和 Timer 事件的统一
-
Libevent 将 Timer 和 Signal 事件都统一到了系统的 I/O 的 demultiplex 机制中了。
-
首先将 Timer 事件融合到系统 I/O 多路复用机制中,还是相当清晰的,因为系统的 I/O 机制像 select()和 epoll_wait()都允许程序制定一个最大等待时间(也称为最大超时时间) timeout,即使没有 I/O 事件发生,它们也保证能在 timeout 时间内返回。
-
那么根据所有 Timer 事件的最小超时时间来设置系统 I/O 的 timeout 时间;当系统 I/O 返回时,再激活所有就绪的 Timer 事件就可以了,这样就能将 Timer 事件完美的融合到系统 的 I/O 机制中了。
-
这是在 Reactor 和 Proactor 模式中处理 Timer 事件的经典方法了。
-
Libevent中Timer事件的管理是时间堆。
-
(b)I/O 和 Signal 事件的统一
-
Signal 是异步事件的经典事例,将 Signal 事件统一到系统的 I/O 多路复用中就不像 Timer 事件那么自然了,Signal 事件的出现对于进程来讲是完全随机的,进程不能只是测试一个变量来判别是否发生了一个信号,而是必须告诉内核“在此信号发生时,请执行如下的操作”。
-
如果当 Signal 发生时,并不立即调用 event 的 callback 函数处理信号,而是设法通知系统的 I/O 机制,让其返回,然后再统一和 I/O 事件以及 Timer 一起处理,不就可以了嘛。是的,这也是 libevent 中使用的方法。
-
如何通知,在 libevent 中这是通过 socket pair 完成的。 Socket pair 就是一个 socket 对,包含两个 socket,一个读 socket,一个写 socket。
-

第13章 多进程编程

13.1 fork 系统调用
-
函数原型如下
-
1 2 3#include <sys/types.h> #include <unistd.h> pid_t fork(void); -
该函数为Linux下创建新进程的系统调用。
-
函数调用返回两次,父进程返回子进程的PID,子进程返回0。调用失败返回-1并设置errno。
-
根据返回值判断是在子进程还是父进程
-
fork函数复制当前进程,在内核进程表中创建一个新的进程表项。复制了堆指针、栈指针和标志寄存器的值。但是信号位图被清除,原进程设置的信号处理函数不再对新进程起作用。
-
子进程代码与父进程完全一致,会复制父进程的数据(包括缓冲区),这个复制是写时复制(copy on write,COW),也就是只有在任一进程对数据执行写操作时候,复制才会发生。
-
创建子进程后,父进程中打开的文件描述符默认在子进程中也是打开的,而且文件描述符的引用计数+1。父进程的用户根目录、当前工作目录等变量的引用计数均会加1。
-
这里说明一下什么叫写时复制。
-
当发出fork( )系统调用时,内核原样复制父进程的整个地址空间并把复制的那一份分配给子进程。这种行为是非常耗时的,因为它需要:
- 为子进程的页表分配页面
- 为子进程的页分配页面
- 初始化子进程的页表
- 把父进程的页复制到子进程相应的页中
-
写时拷贝是一种可以推迟甚至避免拷贝数据的技术。内核此时并不复制整个进程的地址空间,而是让父子进程共享同一个地址空间。只用在需要写入的时候才会复制地址空间,从而使各个进行拥有各自的地址空间。也就是说,资源的复制是在需要写入的时候才会进行,在此之前,只有以只读方式共享。这种技术使地址空间上的页的拷贝被推迟到实际发生写入的时候。在页根本不会被写入的情况下---例如,fork()后立即执行exec(),地址空间就无需被复制了。
13.2 exec系列系统调用
-
exec系列中的系统调用都完成相同的功能(只是参数不同而已),它们把一个新程序装入调用进程的内存空间,来改变调用进程的执行代码,从而形成新进程。如果exec调用成功,调用进程将被覆盖,然后从新程序的入口开始执行,这样就产生了一个新的进程,但是它的进程标识符与调用进程相同。这就是说,exec没有建立一个与调用进程并发的新进程,而是用新进程取代了原来的进程。所以,在exec调用成功后,没有任何数据返回,这与fork()不同。
-
进程调用通常使用exec的函数,当调用该函数时,进程的代码和数据将被新进程所替代,其实通俗的话将就是将磁盘上的新程序加载到物理内存原来指向的位置上,这样就会替换掉原来进程所有的代码和数据。但同时页表和进程地址空间没有发生变化。值得注意的是在调用exec函数之前的旧进程的代码还是会实现的,因为这个时候进程还没有进行替换。
-
函数定义
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17#include <unistd.h> extern char **environ; // 在子进程中执行其他程序,即替换当前进程映像 // path指定执行文件的完整路径 // file接受文件名,该文件的具体位置则在环境变量PATH中搜寻 // arg接受可变参数 // argv接受参数数组 // envp用于设置新程序的环境变量 int execl(const char *path, const char *arg, ...); int execlp(const char *file, const char *arg, ...); int execle(const char *path, const char *arg, ..., char *const envp[]); int execv(const char *path, char *const argv[]); int execvp(const char *file, char *const argv[]); int execve(const char *path, char *const argv[], char *const envp[]); // 一般情况下,exec函数不返回,除非出错时返回-1,并设置errno // 若调用无误,则源程序中exec调用之后的代码都不会执行,源程序已经被exec参数指定的程序完全代替 -
需要注意,exec函数不会关闭原程序打开的文件描述符,除非该文件描述符被设置了类似SOCK_CLOEXEC的属性。
-

-
实际一般可以这样调用
execl(program_path, program_path, arg1, NULL);- 在Linux系统中,
argv[0](即命令行参数列表的第一个元素)通常是程序的名称,而exec系列函数在执行新程序时,会将新程序的名称设置为argv[0]。因此,将program_path传递给execl的第一个和第二个参数是为了保持一致性。
- 在Linux系统中,
13.3 处理僵尸进程
13.3.1 三个特殊进程(孤儿、僵尸、守护)
-
Linux 中有pid 0, pid 1 和 pid 2 三个特定的进程。
pid 0,即 “swapper” 进程,是 pid 1 和 pid 2 的父进程。 pid 1,即 “init” 进程,所有用户空间的进程均派生自该进程。 pid 2,即 “kthreadd” 进程,是内核空间所有进程的父进程。
-
这里先说明孤儿进程、僵尸进程和守护进程的区别。
-
(1)孤儿进程(Orphan Process):父进程先于子进程退出,子进程被init进程(pid为1)收养,成为一个准守护进程,无害。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17#include <stdio.h> #include <sys/types.h> #include <unistd.h> // 特殊进程:孤儿进程、僵尸进程、守护进程 // 孤儿进程:父进程先于子进程退出,子进程被init进程(一号进程)收养,无害 int main() { pid_t pid = fork(); if (pid < 0) { perror("fork error\n"); } else if (pid == 0) { sleep(8); printf("child pro pid is:%d ppid is:%d\n", getpid(), getppid()); } else if (pid > 0) { printf("parent pro pid is:%d\n", getpid()); } return 0; } -

-
(2)僵尸进程(Zombie Process):子进程退出时没有通知父进程,父进程未能及时回收子进程所占用的资源,是有害进程。
-
父进程fork()出来的子进程结束之后,内核会给父进程发送一个SIGCHLD信号。这个SIGCHLD信号的作用是及时通知父进程子进程的退出让父进程通过一系列手段将他回收。回收的意义:1.避免僵尸进程的产生,内存泄漏;2.且使得父进程能拿到子进程的退出状态,进行相应处理。
-
如果父进程没有忽略这个信号(设置SIG_IGN)或handler捕捉这个信号,也没有等待(wait)子进程,而且结束的比子进程晚(不能托管被init1号进程领养),那子进程就会进入僵尸状态;维护着自己的task_struct(即PCB)开销,这也是一种内存泄露。
-
孤儿进程结束后会被 init 进程善后,并没有危害;而僵尸进程则会一直占着进程号,操作系统的进程数量有限则会受影响。
-
一般僵尸进程的产生都是因为父进程的原因,则可以通过 kill 父进程解决,这时候僵尸进程就变成了孤儿进程,被 init 进程接收善后处理。
-
可以使用top命令查找,当zombie前的数量不为0时,即系统内存在相应数量的僵尸进程。
-

-
然后可以使用如下命令,定位僵尸进程及其父进程。
-
ps -A -ostat,ppid,pid,cmd |grep -e ‘^[Zz]’ -
(3)守护进程(Daemon):一种运行在后台的特殊进程,独立于控制终端,去完成某些周期性的事件,或者等待某些特定事件处理的过程。 通常以
d结尾, 随系统启动, 其父进程通常是init进程(pid为1)。
13.3.2 处理方式
-
可以使用以下这对函数在父进程中调用,以等待子进程的借宿,并获取子进程的返回信息,从而避免僵尸进程的产生,或者使子进程的僵尸态立即结束。
-
1 2 3 4 5 6 7 8 9#include <sys/types.h> #include <sys/wait.h> // 阻塞进程,直到该进程的某个子进程结束运行 pid_t wait(int *stat_loc); // 返回子进程的PID,将其推出信息存储于stat_loc指向的内存中 // 只等由pid参数指定的子进程,pid=-1时,与wait函数相同 pid_t waitpid(pid_t pid, int *stat_loc, int options); -
返回的子进程状态信息如下所示。
-

-
之前说过,要在事件已经发生的情况下执行非阻塞调用才能提高程序的效率,显然wait函数的阻塞特性不是服务器程序期望的,好在waitpid函数解决了这个问题。
-
waitpid只等待由pid参数指定的子进程。如果pid取值为-1,那么它就和wait函数相同,即等待任意一个子进程结束。
- stat_loc参数的含义和wait函数的stat_loc参数相同。
- options参数可以控制waitpid函数的行为。该参数最常用的取值是WNOHANG。当options的取值是WNOHANG时,waitpid调用将是非阻塞的;
-
如果pid指定的目标子进程还没有结束或意外终止,则waitpid立即返回0;如果目标子进程确实正常退出了,则waitpid返回该子进程的PID。waitpid调用失败时返回-1并设置emo。
-
因此,为了提高效率,我们可以结合SIGCHLD信号和waitpid函数避免僵尸进程。
-
当一个子进程结束时,它将给其父进程发送一个SIGCHLD信号。因此,我们可以在父进程中捕获SIGCHLD信号,并在信号处理函数中调用waitpid函数以“彻底结束”一个子进程,代码如下所示。
-
1 2 3 4 5 6 7static void handle_child(int sig){ pid_t pid; int stat; while((pid=waitpid(-1, &stat, WNOHANG))>0){ // 对子进程进行善后处理 } }
13.4 管道
- 管道pipe能在父、子进程之间传递信息,利用fork调用之后两个管道文件描述符都保持打开。一对这样的文件描述符只能保证父、子进程间一个方向的数据传输,因此父进程和子进程必须有一个关闭fd[0],另一个关闭fd[1]。
- 若要实现父、子进程之间实现双向数据传输,就必须使用两个管道,可利用socketpair创建全双工管道的系统调用。
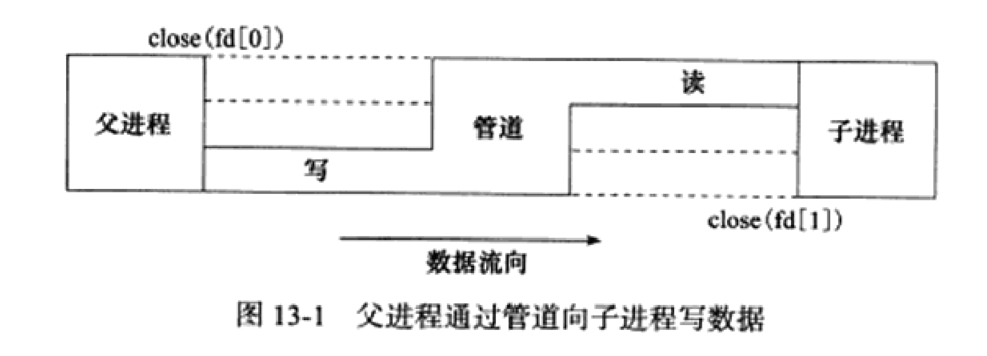
- pipe创建的匿名管道只能用于有关联的两个进程(比如父子进程)之间的通信。
- 要实现无关联的多个进程之间的通信,有以下两种方法
- System V IPC的3种方式(System V消息队列、System V信号量和System V共享内存);System V是一个出现时间较早的通信标准,在现在使用的并不多,原因就是它关注的是**“本地进程通信”**。
- 命名管道,FIFO(First In First Out,先进先出)。
- 命名管道在服务器编程用的很少,了解一下,使用的函数是
int mkfifo(const char *pathname, mode_t mode);
13.5 System V 信号量
(1)信号量原语
-
当多个进程同时访问系统上的某个资源的时候,比如同时写一个数据库的某条记录,或者同时修改某个文件,就需要考虑进程的同步问题,以确保任一时刻只有一个进程可以拥有对资源的独占式访问。通常,程序对共享资源的访问的代码只是很短的一段,但就是这一段代码引发了进程之间的竞态条件。我们称这段代码为关键代码段,或者临界区。
-
对进程同步,也就是确保任一时刻只有一个进程能进人关键代码段。
-
要编写具有通用目的的代码,以确保关键代码段的独占式访问是非常困难的。有两个名为Dekker算法和Peterson算法的解决方案,它们试图从语言本身(不需要内核支持)解决并发问题。但它们依赖于忙等待,即进程要持续不断地等待某个内存位置状态的改变。这种方式下CPU利用率太低,显然是不可取的,且都存在一定的问题(操作系统课有讲)。
-
Dijkstra提出的信号量(Semaphore)概念是并发编程领域迈出的重要一步。信号量是一种特殊的变量,它只能取自然数值并且只支持两种操作:等待(wait)和信号(signal)。不过在Linux/UNIX中,“等待”和“信号”都已经具有特殊的含义,所以对信号量的这两种操作更常用的称呼是P、V操作。这两个字母来自于荷兰语单词passeren(传递,就好像进人临界区)和vrijgeven(释放,就好像退出临界区)。
-
P(SV):如果SV大于0,它就减一,如果SV等于0,则挂起进程的执行;
-
V(SV):如果有其他进程因为等待SV而挂起,则唤醒;如果没有,SV加一;
-
-
注意,PV操作是一种原子操作,信号量也不是普通变量。
-
Linux信号量的API都定义在
sys/sem.h头文件中,主要包含3个系统调用:semget、semop和semctl。它们都被设计为操作一组信号量,即信号量集,而不是单个信号量。 -
需要注意,信号量不仅可以实现进程互斥,也可以实现进程同步。
-
Linux中父子进程的执行顺序是否确定?通常是不确定的:
-
当父进程fork一个子进程时,两个进程(父进程和子进程)都是就绪的,等待被CPU执行。哪个进程先执行,取决于操作系统的调度算法。
-
在大数情况下,这个调度过程是不确定的,你无法预测哪个进程会先运行。有时候父进程会先运行,有时候子进程会先运行。这种不确定性是多任务操作系统中的常见特性,因为它们必须在许多不同的任务之间平衡CPU的使用。
-
如果你希望控制进程的执行顺序,可以使用一些同步机制,比如信号量。
-
-

(2)semget 系统调用
-
semget系统调用创建一个新的信号量集,或者获取一个已经存在的信号量集。
-
1 2#include <sys/sem.h> int semget(key_t key, int num_sems, int sem_flags); -
函数参数如下所示:
-
参数 含义 key 用来标识一个全局唯一的信号量集(就像文件名全局唯一表示一个文件一样),要通过信号量通信的进行需要使用相同的键值来创建/获取信号量(就是一个整数) num_sems 指定要创建/获取的信号量集中信号量的数目。如果创建信号量集,则该值必须指定;要获取已经存在的信号量集的大小,则可以为0 sem_flags 指定一组标志,其低端的9个比特是该信号量的权限(分三组),类似open系统调用的mode,比如0644表示-rw-r--r--。可以和IPC_CREAT做按位或以创建新的信号量集。也联合IPC_CREAT和IPC_EXCL来确保创建一组新的唯一的信号量集。 -
sem_flags用来标识信号量结合的权限。如0700。此外还可以附加以下ipc参数:
-
宏名 描述 IPC_CREAT 如果key不存在,则创建*(类似open函数的O_CREAT)* IPC_EXCL 如果key存在,则返回失败*(类似open函数的O_EXCL)* IPC_NOWAIT 如果需要等待,则直接返回错误
-
-
可以通过检查
IPC_CREAT和IPC_EXCL标志位的组合来确定是创建的还是获取已有的信号量集。 -
semget不会因为信号量已经存在产生错误,但是如果我们使用IPC_CREAT和IPC_EXCL来确保创建一组新的唯一的信号量集时,如果信号量集已经存在,会返回-1并设置errno为EEXIST。
-
semget成功时返回一个正整数值,表示信号量集的标识符;失败是返回-1并设置errno。
-
使用semget创建信号量集,则与之关联的内核数据结构体semid_ds也会被创建并初始化。其定义如下:
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15#include <sem.h> struct ipc_perm{ key_t key; /*键值*/ uid_t uid; /*所有者的有效用户ID*/ gid_t gid; /*所有者的有效组ID*/ uid_t cuid; /*创建者的有效用户ID*/ gid_t cgid; /*创建者的有效组ID*/ mode_t mode;/*访问权限*/ }; struct semid_ds{ struct ipc_perm sem_perm; /*信号量的操作权限*/ unsigned long int sem_nsems; /*该信号集中的信号量数目*/ time_t sem_otime; /*最后一次调用semop的时间*/ time_t sem_ctime; /*最后一次调用semctl的时间*/ }; -
semget对semid_ds结构体的初始化包括:
- 将sem_perm.cuid和sem_perm.uid设置为调用进程的有效用户ID。
- 将sem_perm.cgid和sem_perm.gid设置为调用进程的有效组ID。
- 将sem_perm.mode的最低9位设置为sem_flags参数的最低9位。
- 将sem_nsems设置为num_sems。
- 将sem_otime设置为0。
- 将sem_ctime设置为当前系统时间。
(3)semop 系统调用
-
semop函数的作用是改变信号量的值,即执行P、V操作。
-
semop操作的是下面是一些与信号量关联的内核变量:
-
1 2 3 4unsigned short semval; /*信号量的值*/ unsigned short semzcnt; /*等待信号量值变为0的进程数量*/ unsigned short semncnt; /*等待信号量值增加的进程数量*/ pid_t sempid; /*最后一次执行semop操作的进程ID*/ -
semop的函数定义如下:
-
1 2#include <sys/sem.h> int semop(int sem_id, struct sembuf* sem_ops, size_t num_sem_ops); -
1、sem_id是由semget调用返回的信号量集标识符,用于指定被操作的目标信号量集。
-
2、sem_ops指向一个sembuf类型的数组,其定义为:
-
1 2 3 4 5 6 7 8struct sembuf{ /*sem_num指的是信号量集中信号量的编号,0代表第一个信号量*/ unsigned short int sem_num; /*sem_op指定操作类型,可选值为正整数,0,负整数*/ short int sem_op; /*sem_flg可选值为IPC_NOWAIT和SEM_UNDO*/ short int sem_flg; };-
sem_num为信号量的编号;
-
sem_op是要进行的操作(PV操作):
-
- 如果为正整数,表示增加信号量的值(若为3,则加上3)
- 如果为负整数,表示减小信号量的值
- 如果为0,表示对信号量当前值进行是否为0的测试
-
sem_flg为操作标识:
- IPC_NOWAIT的含义是,无论信号量操作是否成功,semop调用都将立即返回,这类似于非阻塞I/O操作。
- SEM_UNDO的含义是,当进程退出时取消正在进行的semop操作。
SEM_UNDO标志用于支持系统在进程意外终止时自动释放由该进程占用的信号量资源。
-
sem_op和sem_flg相互影响。具体来说如下:(可通过man semop查看)
-
-
3、num_sem_ops指定要执行操作的个数,即sem_ops数组中元素的个数。semop对数组sem_ops中的每个成员按照数组顺序依次执行操作,并且该过程为原子操作,主要是为了避免出现竞态条件。
-
semop成功时返回0,失败返回-1并设置errno,失败的时候,sem_ops数组中指定的所有操作都不被执行。


(4)semctl 系统调用
-
semctl系统调用允许调用者对信号量进行直接控制,定义如下:
-
1 2#include <sys/sem.h> int semctl(int sem_id, int sem_num, int command, ...); -
1、sem_id是由semget调用返回的信号量集标识符,用以被指定的信号量集。
-
2、sem_num指定被操作的信号量在信号量中的编号。
-
3、command参数指定要执行的命令。
-
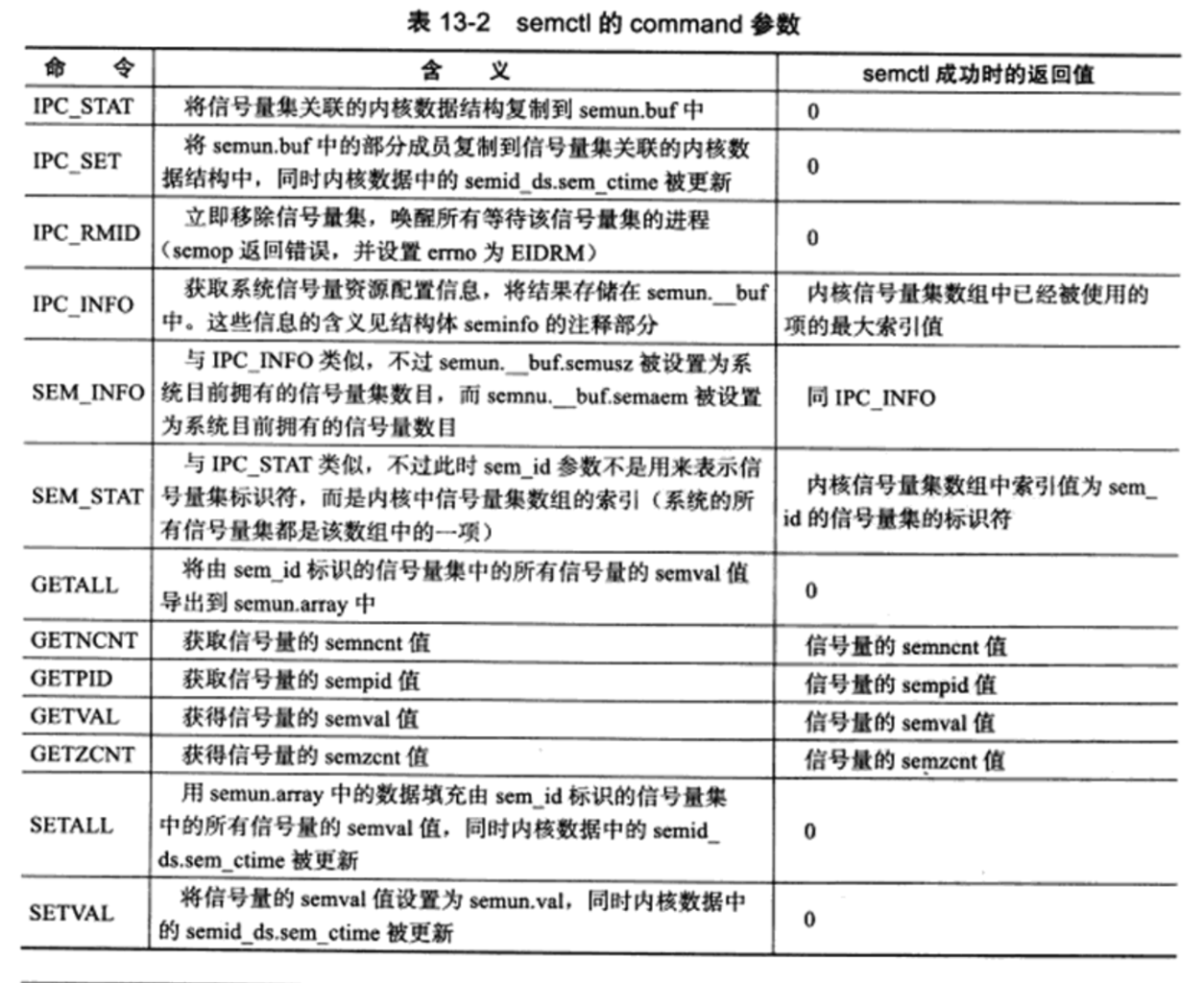
-

-
4、有时需要第四个参数,这取决于command,sys/sem.h推荐的格式如下:(This function has three or four arguments, depending on cmd. When there are four, the fourth has the type union semun. The calling program must define this union as follows:)
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19union semun{ int val; /*用于SETVAL命令*/ struct semid_ds* buf; /*用于IPC_STAT和IPC_SET命令*/ unsigned short* array; /*用于GETALL和SETALL命令*/ struct seminfo* __buf; /*用于IPC_INFO命令*/ }; struct seminfo{ int semmap;/*Linux内核没有使用*/ int semmni;/*系统最多可以拥有的信号量集数目*/ int semmns;/*系统最多可以拥有的信号量数目*/ int semmnu;/*Linux内核没有使用*/ int semmsl;/*一个信号量集最多允许包含的信号量数目*/ int semopm;/*semop一次最多能执行的sem_op操作数目*/ int semume;/*Linux内核没有使用*/ int semusz;/*sem_undo结构体的大小*/ int semvmx;/*最大允许的信号量值*/ /*最多允许的UNDO次数(带SEM_UNDO标志的semop操作的次数)*/ int semaem; }; -
5、semctl成功时的返回值取决于command参数。semctl失败时返回-1,并设置errno。
(5)特殊键值IPC_PREVATE 及实验
-
semget的调用者可以给其key参数传递一个特殊的键值IPC_PRIVATE(值为0),这样无论该信号量是否已经存在,semget都将创建一个新的信号量,注意的是,使用该键值创建的信号量并非是私有的。
-
其他进程,尤其是子进程,也有方法来访问这个信号量。所以semget的man手册的BUGS部分上说,使用名字IPC_PRIVATE有些误导(历史原因)。
-
下面的代码就在父、子进程间使用一个IPC_PRIVATE信号量来同步。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54#include <stdio.h> #include <stdlib.h> #include <sys/sem.h> #include <sys/wait.h> #include <unistd.h> union semun { int val; struct semid_ds *buf; unsigned short int *array; struct seminfo *__buf; }; // op为-1执行P操作取资源;+1执行V操作退出资源 void pv(int sem_id, int op) { struct sembuf sem_b; sem_b.sem_num = 0; sem_b.sem_op = op; sem_b.sem_flg = SEM_UNDO; semop(sem_id, &sem_b, 1); } int main(int argc, char *argv[]) { // 创建信号量 int sem_id = semget(IPC_PRIVATE, 1, 0666); union semun sem_un; sem_un.val = 1; // 编号0信号量置为1 semctl(sem_id, 0, SETVAL, sem_un); pid_t id = fork(); if (id < 0) { return 1; } else if (id == 0) { printf("child try to get binary sem\n"); pv(sem_id, -1); printf("child get the sem and would release it after 5 seconds\n"); sleep(5); pv(sem_id, 1); exit(0); } else { printf("parent try to get binary sem\n"); pv(sem_id, -1); printf("parent get the sem and would release it after 5 seconds\n"); sleep(5); pv(sem_id, 1); } // 阻塞等待子进程完成 waitpid(id, NULL, 0); semctl(sem_id, 0, IPC_RMID, sem_un); // 删除信号量 return 0; } -

13.6 System V 共享内存
- 共享内存是最高效的IPC(进程间通信)机制,因为它不涉及进程之间的任何数据传输,但是我们也必须用其他辅助手段来同步进程对共享内存的访问以避免竞态条件的产生。因此,共享内存通常和其他进程间通信方式一起使用。
- 这里注意,共享内存本身是没有同步互斥的能力的,是一种IPC机制。
- Linux共享内存的API都定义在
sys/shm.h头文件中,包括4个系统调用:shmget、shmat、shmdt和shmctl。
(1)shmget 系统调用
-
shmget系统调用创建一段新的共享内存,或者获得一段已经存在的共享内存。其定义如下:
-
1 2#include <sys/shm.h> int shmget(key_t key, size_t size, int shmflg); -
具体参数如下:
-
参数 类型 说明 keykey_t共享内存区段的关键字,用于在多个进程间标识同一个共享内存区段。用来表示一段全局唯一的共享内存。 sizesize_t共享内存区段的大小,以字节为单位。如果是创建新的共享内存,则size的值必须指定,如果是获取已经存在的共享内存,可以把size设置为0。 shmflgint共享内存区段的访问权限和行为属性。和 semget 的参数sem_flags类似。 -
shmflg支持两种额外的标志:
- SHM_HUGETLB,类似于mmap的MAP_HUGETLB标志,系统将使用大页面来为共享内存分配空间。
- SHM_NORESERVE,类似于mmap的MAP_NORESERVE标志,不为共享内存保留交换分区(swap空间),这样,当物理内存不足时,对该共享内存执行写操作将触发SIGSEGV信号。
-
shmget成功将返回一个正整数,表示共享内存的标识符,失败返回-1,并设置errno。
-
使用shmget创建共享内存,则这段共享内存的所有字节都会被初始化为0,与之关联的内核数据结构shmid_ds将会创建并被初始化,其定义如下:
-
1 2 3 4 5 6 7 8 9 10struct shmid_ds{ struct ipc_perm shm_perm; /*共享内存的操作权限*/ size_t shm_segsz; /*共享内存大小,单位是字节*/ __time_t shm_atime; /*对这段内存最后一次调用shmat的时间*/ __time_t shm_dtime; /*对这段内存最后一次调用shmdt的时间*/ __time_t shm_ctime; /*对这段内存最后一次调用shmctl的时间*/ __pid_t shm_cpid; /*创建者的PID*/ __pid_t shm_lpid; /*最后一次执行shmat或shmdt操作的进程的PID*/ shmatt_t shm_nattach; /*目前关联到此共享内存的进程数量*/ }; -
初始化包括:
- 将shm_perm.cuid和shm_perm.uid设置为调用进程的有效用户ID;
- 将shm_perm.cgid和shm_perm.gid设置为调用进程的有效组ID;
- 将shm_perm.mode的最低9位设置为shmflg参数的最低9位;
- 将shm_segsz设置为size;
- 将shm_lpid、shm_nattach、shm_atime、shm_dtime设置为0;
- 将shm_ctime设置为当前系统时间。
(2)shmat 系统调用
-
共享内存被创建/获取之后,我们不能立即访问它,而是需要先将它关联到进程的地址空间中。
-
使用
shmat系统调用关联共享内存到进程的地址空间。 -
1 2#include <sys/shm.h> void* shmat(int shm_id, const void* shm_addr, int shmflg); -
具体参数如下:
参数 类型 说明 shmidint共享内存区段的标识符,用于标识已创建或已打开的共享内存区段。 shmaddrconst void*共享内存区段连接到当前进程地址空间的起始地址,如果为 NULL,则由系统自动选择一个地址。 shmflgint标志参数,指定共享内存区段的访问权限和行为属性。 -

-

-
shamt成功时返回共享内存被关联到的地址,失败返回(void*)-1并设置errno。
-
shmat成功时,将修改内核数据结构shmid_ds的部分字段如下:
- 将shm_nattach加1;
- 将shm_lpid设置为调用进程的PID;
- 将shm_atime设置为当前时间
(3)shmdt 系统调用
-
使用完共享内存后,我们需要将它从进程地址空间中分离,这里使用shmdt函数。
-
1int shmdt(const void *shmaddr); -
用于断开进程与共享内存区段的连接,具体参数如下:
参数 类型 说明 shmaddrconst void*共享内存区段连接到当前进程地址空间的起始地址。 函数返回值为 0 表示成功,-1 表示失败并设置errno。
-
shmdt成功调用时将修改内核数据结构shmid_ds的部分字段如下:
- 将shm_nattach减1;
- 将shm_lpid设置为调用进程的PID;
- 将shm_dtime设置为当前的时间。
(4)shmctl 系统调用
-
shmctl系统调用控制共享内存的某些属性。
-
1 2#include <sys/shm.h> int shmctl(int shmid, int cmd, struct shmid_ds *buf); -
用于控制共享内存区段的行为,如删除、获取、设置共享内存区段的属性等,具体参数如下:
参数 类型 说明 shmidint共享内存区段的标识符,用于标识已创建或已打开的共享内存区段。 cmdint控制命令,指定对共享内存区段的操作类型。 bufstruct shmid_ds*指向共享内存区段属性结构体的指针,用于获取或设置共享内存区段的属性。 -
常用的
cmd参数包括:- IPC_STAT:获取共享内存的状态信息,并将该信息存储在
buf参数指向的结构体中。 - IPC_SET:设置共享内存的状态信息,
buf参数指向要设置的新值。 - IPC_RMID:删除共享内存。
- IPC_STAT:获取共享内存的状态信息,并将该信息存储在
-
-
shmctl成功时的返回值取决于command参数,失败返回-1并设置errno。
(5)实验
-
以下是一个示例代码,其中一个程序用于写入共享内存,另一个程序用于读取共享内存。
-
写入代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54/* write.cpp */ #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/shm.h> #include <unistd.h> #define SHM_SIZE 1024 int main() { int shmid; char *shmaddr; char write_buf[SHM_SIZE]; // 创建共享内存段 shmid = shmget((key_t)1234, SHM_SIZE, 0666 | IPC_CREAT); if (shmid == -1) { perror("shmget failed"); exit(EXIT_FAILURE); } // 将共享内存段连接到当前进程 shmaddr = (char *)shmat(shmid, NULL, 0); if (shmaddr == (void *)-1) { perror("shmat failed"); exit(EXIT_FAILURE); } // 从标准输入读取数据并将其写入共享内存 while (1) { fgets(write_buf, SHM_SIZE, stdin); strncpy(shmaddr, write_buf, SHM_SIZE); if (strncmp(write_buf, "exit", 4) == 0) { break; } } // 断开共享内存连接 if (shmdt(shmaddr) == -1) { perror("shmdt failed"); exit(EXIT_FAILURE); } // 删除共享内存段 if (shmctl(shmid, IPC_RMID, 0) == -1) { perror("shmctl failed"); exit(EXIT_FAILURE); } printf("write exit\n"); return 0; } -
读取代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50/* read.cpp */ #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/shm.h> #include <unistd.h> #define SHM_SIZE 1024 int main() { int shmid; char *shmaddr; char read_buf[SHM_SIZE]; // 获取共享内存段 shmid = shmget((key_t)1234, SHM_SIZE, 0666 | IPC_CREAT); if (shmid == -1) { perror("shmget failed"); exit(EXIT_FAILURE); } // 将共享内存段连接到当前进程 shmaddr = (char *)shmat(shmid, NULL, 0); if (shmaddr == (void *)-1) { perror("shmat failed"); exit(EXIT_FAILURE); } // 从共享内存读取数据并输出到标准输出 while (1) { strncpy(read_buf, shmaddr, SHM_SIZE); printf("Received message: %s\n", read_buf); if (strncmp(read_buf, "exit", 4) == 0) { printf("Received exit\n"); break; } sleep(1); } // 断开共享内存连接 if (shmdt(shmaddr) == -1) { perror("shmdt failed"); exit(EXIT_FAILURE); } printf("read exit\n"); return 0; } -
实验结果如下所示。
-
-
从实验也可以看出,使用共享内存需要注意以下几点:
-
同步问题:由于多个进程可以同时访问共享内存,因此必须要使用同步机制来保证数据的一致性和正确性。
-
内存泄漏:如果一个进程崩溃或者没有及时解除共享内存映射,就有可能导致内存泄漏的问题。
-
安全问题:共享内存是多个进程共享的,因此必须要注意数据的安全性和隐私性,避免敏感数据泄露。
-
-
以下是共享内存的使用技巧
-
分配内存时使用
shmget()系统调用中的IPC_PRIVATE标记,可以确保共享内存的键值在系统中是唯一的,避免冲突和安全问题。 -
在读写共享内存之前,使用信号量或互斥锁等同步机制来保证数据的一致性和正确性。
-
在使用共享内存时,可以将共享内存区域按照固定大小进行分块,避免多个进程同时访问同一块内存区域的冲突。
-
(6)POSIX标准的共享内存方法
-
System V 共享内存使用上述(1-4)的系统调用。
-
在Linux上,也提供了POSIX标准的共享内存的创建和操作的函数。一般涉及以下几个函数。
- 1、shm_open: 用于打开或创建一个共享内存对象。
- 2、ftruncate: 用于设置共享内存对象的大小。
- 3、mmap: 用于将共享内存对象映射到进程的地址空间中。
- 4、munmap: 用于解除映射。
- 5、shm_unlink: 用于删除共享内存对象。
-

-

13.7 System V 消息队列
- 消息队列是在两个进程之间传递二进制块数据的一种简单有效的方式。每个数据块都有一个特定的类型,接收方可以根据类型来有选择地接收数据,而不一定像管道和命名管道那样必须以先进先出的方式接收数据。
- Linux消息队列的API都定义在
sys/msg.h头文件中,包括4个系统调用:msgget、msgsnd、msgrev和msgctl。
(1)msgget 系统调用
-
msgget系统调用创建一个消息队列,或者获取一个已有的消息队列,定义如下:
-
1 2#include <sys/msg.h> int msgget(key_t key, int msgflg); -
key参数是消息队列的键值,它唯一地标识一个消息队列。 -
msgflg参数是一组标志,用于指定消息队列的创建和访问方式,和semget 系统调用的 sem_flags 的参数相同。- 如果使用
msgget来创建消息队列,需要设置msgflg中的IPC_CREAT标志,还可以使用IPC_EXCL标志来确保不重复创建同样的消息队列。如int msgflg = IPC_CREAT | IPC_EXCL | 0666; // 创建标志和权限 - 如果要访问已经存在的消息队列,只需要设置
msgflg中的访问权限。如int msgflg = 0666; // 访问权限
- 如果使用
-
msgget成功时返回一个正整数,它是消息队列的标识符,msgget失败时返回-1并设置errno。
-
使用msgget创建消息队列,则与之相关的内核数据结构 msqid_ds 也会被创建并初始化。 msqid_ds 其定义如下:
-
1 2 3 4 5 6 7 8 9 10 11struct msqid_ds{ struct ipc_perm msg_perm; /*消息队列的操作权限*/ time_t msg_stime; /*最后一次调用msgsnd的时间*/ time_t msg_rtime; /*最后一次调用msgrcv的时间*/ time_t msg_ctime; /*最后一次被修改的时间*/ unsigned long __msg_cbytes;/*消息队列中已有的字节数*/ msgqnum_t msg_qnum; /*消息队列中已有的消息数*/ msglen_t msg_qbytes; /*消息队列允许的最大字节数*/ pid_t msg_lspid; /*最后执行msgsnd的进程PID*/ pid_t msg_lrpid; /*最后执行msgrcv的进程PID*/ };
(2)msgsnd 系统调用
-
msgsnd系统调用将一条消息添加到消息队列中,定义如下:
-
1 2#include <sys/msg.h> int msgsnd(int msqid, const void* msg_ptr, size_t msg_sz, int msgflg); -
msqid是消息队列的标识符,由msgget函数返回。 -
msgp是指向消息缓冲区的指针,存放待发送的消息。其定义必须如下(长度可自定义,一般设置为512):-
1 2 3 4struct msgbuf{ long mtype; /*消息类型*/ char mtext[512]; /*消息数据*/ }; -

-
-
msgsz是消息的大小,以字节为单位。 -
msgflg是消息标志,用于指定发送消息的方式。它通常仅支持IPC_NOWAIT标志,以非阻塞方式发送消息。但是如果消息队列满了,则msgsnd阻塞,此时若IPC_NOWAIT标志被指定,msgsnd立即返回-1并设置errno为EAGAIN。 -
处于阻塞状态的msgsnd调用可能被以下两种异常情况所中断:
- 消息队列被移除,此时msgsnd调用将立即返回并设置errno为EIDRM。
- 程序接收到信号产生中断,此时msgsnd调用将立即返回并设置errno为EINRT。
-
msgsnd成功时返回0,失败时返回-1并设置errno。
-
msgsnd成功时将修改内核数据结构msqid_ds的部分字段,如下所示:
- 将msg_qnum加1。
- 将msg_lspid设置为调用进程的PID。
- 将msg_stime设置为当前的时间。
(3)msgrcv 系统调用
-
msgrcv系统调用从消息队列中获取消息。其定义为:
-
1 2#include <sys/msg.h> int msgrcv(int msqid, void* msg_ptr, size_t msg_sz, long int msqtype, int msgflg); -
msqid是由msgget调用返回的消息队列标识符。
-
msg_ptr用于存储接收的消息,msg_sz是消息数据部分的长度。
-
msgtype指定接收何种类型的数据,由以下几个方式:
- msgtype等于0。读取消息队列中的第一个消息。
- msgtype大于0。读取消息队列中第一个类型为msgtype的消息。
- msgtype小于0。读取消息队列中第一个类型值比msgtype的绝对值小的消息。
-
msgflg控制msgrcv函数的行为,它可以是以下一些标志的按位或:
- IPC_NOWAIT,如果消息队列中没有消息,则msgrcv调用立即返回并设置errno为ENOMSG。
- MSG_EXCEPT,如果msgtype大于0,则接收消息队列中第一个非msgtype类型的消息。
- MSG_NOERROR,如果消息数据部分的长度超过了msg_sz,就将它截断。
-
处于阻塞状态的msgrcv调用还可能被以下两种异常情况中断:
- 消息队列被移除。此时msgrcv调用将立即返回并设置errno为EIDRM。
- 程序接收到信号。此时msgrcv调用 将立即返回并设置errno为EINTR。
-
msgrcv成功时返回0,失败则返回-1并设置errno。
-
msgrcv成功时修改内核数据结构msqid_ds的部分字段如下:
- 将msg_qnum减1;
- 将msg_lrpid设置为调用进程的PID;
- 将msg_rtime设置为当前时间。
(4)msgctl 系统调用
-
msgctl系统调用控制消息队列的属性。
-
1 2#include <sys/msg.h> int msgctl(int msqid, int command, struct msqid_ds* buf); -
msqid是消息队列的标识符,由msgget函数返回。 -
cmd是控制命令,用于指定执行什么样的操作。常见的命令有:IPC_STAT:获取消息队列的状态信息。IPC_SET:设置消息队列的状态信息。IPC_RMID:从系统中删除消息队列。
-
buf是指向msqid_ds结构体的指针,用于存储或传递消息队列的状态信息。 -
msgctl成功时的返回值取决于command参数,失败时返回-1并设置errno。
(5)实验
-
在Linux中使用消息队列进行进程间通信时,需要一些机制来判断何时消息队列中的消息已被读取完。以下是一些方法:
- 消息类型标记:
- 在消息结构体中添加一个字段,例如
mtype,用于标记消息的类型。你可以约定一种特殊的消息类型,表示消息队列的结束。读取进程可以在收到这种特殊类型的消息时知道消息队列的结束。
- 在消息结构体中添加一个字段,例如
- 消息内容长度标记:
- 在消息结构体中添加一个字段,表示消息内容的长度。当消息内容长度为零时,表示消息队列的结束。
- 消息类型标记:
-
以下是一个简单的示例,展示如何使用消息队列进行进程间通信。假设有两个进程,一个发送进程和一个接收进程,它们之间需要传递一些数据。我们通过消息队列来实现进程间通信。
-
发送进程
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33// sendmsg.cpp #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/msg.h> typedef struct { long type; char text[512]; } message_t; int main() { key_t key = ftok("/tmp", 'a'); // 创建一个唯一的key int msgid = msgget(key, 0666 | IPC_CREAT); // 创建消息队列 if (msgid == -1) { perror("msgget"); exit(EXIT_FAILURE); } message_t message; message.type = 1; strcpy(message.text, "Hello, World!"); int result = msgsnd(msgid, &message, sizeof(message.text), 0); if (result == -1) { perror("msgsnd"); exit(EXIT_FAILURE); } printf("消息发送成功,text=%s\n", message.text); return 0; } -
接收进程
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31// rsvmsg.cpp #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/msg.h> typedef struct { long type; char text[512]; } message_t; int main() { key_t key = ftok("/tmp", 'a'); // 创建一个唯一的key int msgid = msgget(key, 0666 | IPC_CREAT); // 创建消息队列 if (msgid == -1) { perror("msgget"); exit(EXIT_FAILURE); } message_t message; int result = msgrcv(msgid, &message, sizeof(message.text), 1, 0); if (result == -1) { perror("msgrcv"); exit(EXIT_FAILURE); } printf("消息接收成功,text=%s\n", message.text); return 0; } -
实验结果:
-
先打开接收进程阻塞等待,然后运行发送进程,有如下结果。
-

13.8 IPC 命令
-
上述3种System V IPC进程间通信方式都使用一个全局唯一的键值(key)来描述一个共享资源。当程序调用semget、shmget或者msgget时,就创建了这些共享资源的一个实例。
-
Linux 提供了
ipcs命令用于显示系统中的IPC资源的信息,包括消息队列、信号量和共享内存。 -
1sudo ipcs -
Linux 也提供了
ipcrm命令,用于从系统中删除IPC资源,包括消息队列、信号量和共享内存。 -
1 2 3sudo ipcrm -q <message_queue_id> # 删除消息队列 sudo ipcrm -s <semaphore_id> # 删除信号量 sudo ipcrm -m <shared_memory_id> # 删除共享内存 -
Linux 也提供了
ipcmk命令,用于创建IPC资源,包括消息队列、信号量和共享内存。这些命令可以用来创建新的IPC资源,并返回相应的ID。 -
1 2 3sudo ipcmk -Q # 创建消息队列 sudo ipcmk -S # 创建信号量 sudo ipcmk -M # 创建共享内存 -
-

13.9 利用UNIX域socket在进程间传递文件描述符
-
由于fork调用之后,父进程中打开的文件描述符在子进程中仍然保持打开,所以文件描述符可以很方便地从父进程传递到子进程。
- 需要注意的是,传递一个文件描述符并不是传递一个文件描述符的值,而是要在接收进程中创建一个新的文件描述符,并且该文件描述符和发送进程中被传递的文件描述符指向内核中相同的文件表项。
-
那么如何把子进程中打开的文件描述符传递给父进程呢?或者更通俗地说,如何在两个不相干的进程之间传递文件描述符呢?在Liux下,我们可以利用UNIX域socket在进程间传递特殊的辅助数据,以实现文件描述符的传递。
-
使用
sendmsg和recvmsg函数传递文件描述符的机制是通过辅助数据(ancillary data)来实现的,因为传递文件描述符需要额外的信息来确保文件描述符的正确传递和接收。辅助数据的主要目的是传递文件描述符之外的其他信息,例如控制信息和权限信息等。 -
以下代码给出了一个实例,它在子进程中打开一个文件描述符,然后将它通过UNTX域socket传递给父进程,父进程则通过读取该文件描述符来获得文件的内容。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88#include <assert.h> #include <fcntl.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/socket.h> #include <unistd.h> static const int CONTROL_LEN = CMSG_LEN(sizeof(int)); // 发送文件描述符,fd参数用来传递UNINX域socket,fd_to_send是待发送的文件描述符 void send_fd(int fd, int fd_to_send) { struct iovec iov[1]; struct msghdr msg; char buf[0]; iov[0].iov_base = buf; iov[0].iov_len = 1; msg.msg_name = NULL; msg.msg_namelen = 0; msg.msg_iov = iov; msg.msg_iovlen = 1; cmsghdr cm; cm.cmsg_len = CONTROL_LEN; cm.cmsg_level = SOL_SOCKET; cm.cmsg_type = SCM_RIGHTS; *(int *)CMSG_DATA(&cm) = fd_to_send; // 设置辅助数据 msg.msg_control = &cm; msg.msg_controllen = CONTROL_LEN; // 使用通用方式发送 sendmsg(fd, &msg, 0); } int recv_fd(int fd) { struct iovec iov[1]; struct msghdr msg; char buf[0]; iov[0].iov_base = buf; iov[0].iov_len = 1; msg.msg_name = NULL; msg.msg_namelen = 0; msg.msg_iov = iov; msg.msg_iovlen = 1; cmsghdr cm; msg.msg_control = &cm; msg.msg_controllen = CONTROL_LEN; recvmsg(fd, &msg, 0); int fd_to_read = *(int *)CMSG_DATA(&cm); return fd_to_read; } int main() { int pipefd[2]; int fd_to_pass = 0; // 创建本地socket对通信,使用数据报 int ret = socketpair(PF_UNIX, SOCK_DGRAM, 0, pipefd); assert(ret != -1); pid_t pid = fork(); assert(pid >= 0); if (pid == 0) { close(pipefd[0]); fd_to_pass = open("test.txt", O_RDWR, 0666); // 子进程通过管道将文件描述符发送到父进程 // 如果文件test.txt打开失败,则子进程将标准输入文件描述符发送到父进程 send_fd(pipefd[1], (fd_to_pass > 0) ? fd_to_pass : 0); close(fd_to_pass); exit(0); } close(pipefd[1]); fd_to_pass = recv_fd(pipefd[0]); // 父进程从管道接受目标文件描述符 char buf[1024]; memset(buf, '\0', 1024); // 读取文件描述符的内容 read(fd_to_pass, buf, 1024); printf("I got fd %d and data is: [%s]\n", fd_to_pass, buf); close(fd_to_pass); return 0; } -
实验结果,和test.txt的内容对上了。
-

第14章 多线程编程

14.1 Linux 线程概述

14.1.1 进程和线程
-
(1)进程
-
进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元,在传统的操作系统中,进程既是基本的分配单元,也是基本的执行单元。进程的概念主要有两点:第一,进程是一个实体。每一个进程都有它自己的地址空间,一般情况下,包括文本区域(text region)、数据区域(data region)和堆栈(stack region)。文本区域存储处理器执行的代码;数据区域存储变量和进程执行期间使用的动态分配的内存;堆栈区域存储着活动过程调用的指令和本地变量。第二,进程是一个“执行中的程序”。程序是一个没有生命的实体,只有处理器赋予程序生命时(操作系统执行之),它才能成为一个活动的实体,我们称其为进程。
-
(2)线程
-
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。在Unix System V及SunOS中也被称为轻量级进程(lightweight processes),但轻量进程更多指内核线程(kernel thread),而把用户线程(user thread)称为线程。
-
进程与线程之间的关系:同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等等。但同一进程中的多个线程有各自的调用栈(call stack),自己的寄存器环境(register context),自己的线程本地存储(thread-local storage)。
-
(3)两者的内核区别
-
linux内核中,进程与线程它们虽然都是任务,但是应该加以区分。其中,pid 是 process id 进程标识符,tgid 是 thread group ID 线程组标识符。
-
任何一个进程,如果只有主线程,那 pid 是自己,tgid 是自己,group_leader 指向的还是自己。
-
但是,如果一个进程创建了其他线程,那就会有所变化了。线程有自己的 pid(一直都是),tgid 就是进程的主线程的 pid,group_leader 指向的就是进程的主线程**。所以有了 tgid**,我们就知道 tast_struct 代表的是一个进程还是代表一个线程了。
-
关系如下:
-
-
(4)共享资源的区别
-
多线程:
- 线程间共享进程的内存空间,包括代码区、堆区、全局变量和静态变量.
- 每个线程有自己的栈空间,用于存储局部变量和函数调用的上下文.
- 线程之间的同步相对复杂,因为它们共享大部分资源,所以需要使用互斥锁、信号量等同步机制来防止数据竞争和保证线程安全.
-
多进程:
- 进程间的内存空间是独立的,每个进程都有自己的代码区、堆区、全局变量等.
- 进程间的数据共享很复杂,通常需要使用进程间通信(IPC)机制,如管道、消息队列、共享内存等.
- 同步相对简单,因为进程间不共享内存空间,所以不会出现多线程中的数据竞争问题.
14.1.2 线程模型
-
线程是程序中完成一个独立任务的完整执行序列,即一个可调度的实体。根据运行环境和调度者的身份,线程可分为内核线程和用户线程。
-
内核线程,在有的系统上也称为LWP(Light Weight Process,轻量级进程),运行在内核空间,由内核来调度;
-
用户线程运行在用户空间,由线程库来调度。
-
当进程的一个内核线程获得CPU的使用权时,它就加载并运行一个用户线程。可见,内核线程相当于用户线程运行的“容器”。
-
一个进程可以拥有M个内核线程和N个用户线程,其中M≤N。并且在一个系统的所有进程中,M和N的比值都是固定的。按照M:N的取值,线程的实现方式可分为三种模式:完全在用户空间实现、完全由内核调度和双层调度(two level scheduler)。
-
完全在用户空间实现的线程无须内核的支持,内核甚至根本不知道这些线程的存在。线程库负责管理所有执行线程,比如线程的优先级、时间片等。线程库利用longjmp来切换线程的执行,使它们看起来像是“并发”执行的。但实际上内核仍然是把整个进程作为最小单位来调度的。换句话说,一个进程的所有执行线程共享该进程的时间片,它们对外表现出相同的优先级。因此,对这种实现方式而言,M=1,即N个用户空间线程对应1个内核线程,而该内核线程实际上就是进程本身。完全在用户空间实现的线程的优点是:创建和调度线程都无须内核的干预,因此速度相当快。并且由于它不占用额外的内核资源,所以即使一个进程创建了很多线程,也不会对系统性能造成明显的影响。其缺点是:对于多处理器系统,一个进程的多个线程无法运行在不同的CPU上,因为内核是按照其最小调度单位来分配CPU的。此外,线程的优先级只对同一个进程中的线程有效,比较不同进程中的线程的优先级没有意义。早期的伯克利UNIX线程就是采用这种方式实现的。
-
完全由内核调度的模式将创建、调度线程的任务都交给了内核,运行在用户空间的线程库无须执行管理任务,这与完全在用户空间实现的线程恰恰相反。二者的优缺点也正好互换。完全由内核调度的这种线程实现方式满足M:N=1:1,即1个用户空间线程被映射为1个内核线程。
-
双层调度模式是前两种实现模式的混合体:内核调度M个内核线程,线程库调度N个用户线程。这种线程实现方式结合了前两种方式的优点:不但不会消耗过多的内核资源,而且线程切换速度也较快,同时它可以充分利用多处理器的优势。这种模式就是典型的M个内核线程和N个用户线程,其中M≤N。
-
14.1.3 Linux线程前世今生
-
(1) LinuxThreads
-
在 Linux 创建的初期,内核一直就没有实现“线程”这个东西。后来因为实际的需求,便逐步产生了LinuxThreads 这个项目,其主要的贡献者是Xavier Leroy。LinuxThreads项目使用了 clone() 这个系统调用对线程进行了模拟,按照《Linux内核设计与实现》的说法,调用 clone() 函数参数是
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0),即创建一个新的进程,同时让父子进程共享地址空间、文件系统资源、文件描述符、信号处理程序以及被阻断的信号等内容。也就是说,此时在内核看来,没有所谓的“线程”,我们所谓的“线程”其实在内核看来不过是和其他进程共享了一些资源的进程罢了。 -
通过以上的描述,我们可以得到以下结论:
- 此时的内核确实不区分进程与线程,内核没有“线程”这个意识。
- 在不同的“线程”内调用 getpid() 函数,打印的肯定是不同的值,因为它们在内核的进程链表中有不同的 task_struct 结构体来表示,有各自不同的进程标识符PID。
-
值得一提的是,内核不区分线程,那么在用户态的实现就必须予以区分和处理。所以 LinuxThreads 有一个非常出名的特性就是管理线程(manager thread)(这也是为什么实际创建的线程数比程序自己创建的多一个的原因)。管理线程必须满足以下要求:
- 系统必须能够响应终止信号并杀死整个进程。
- 以堆栈形式使用的内存回收必须在线程完成之后进行。因此,线程无法自行完成这个过程。终止线程必须进行等待,这样它们才不会进入僵尸状态。
- 如果主线程先于其他工作线程退出,则管理线程将阻塞它,直到所有其他工作线程都结束之后才唤醒它。
- 线程本地数据的回收需要对所有线程进行遍历;这必须由管理线程来进行。
-
管理线程的引人,增加了额外的系统开销。并且由于它只能运行在一个CPU上,所以LinuxThreads线程库也不能充分利用多处理器系统的优势。
-
LinuxThreads 这个项目固然在一定程度上模拟出了“线程”,而且看起来实现也是如此的优雅。所以常常有人说,Linux 内核没有进程线程之分,其实就是这个意思。但这个方法也有问题,尤其是在信号处理、调度和进程间同步原语方面都存在问题。而且, 一组线程并不仅仅是引用同一组资源就够了, 它们还必须被视为一个整体。
-
对此,POSIX标准提出了如下要求:
- 查看进程列表的时候,相关的一组 task_struct 应当被展现为列表中的一个节点;
- 发送给这个”进程”的信号(对应 kill 系统调用),将被对应的这一组 task_struct 所共享, 并且被其中的任意一个”线程”处理;
- 发送给某个”线程”的信号(对应 pthread_kill ),将只被对应的一个 task_struct 接收,并且由它自己来处理;
- 当”进程”被停止或继续时(对应 SIGSTOP/SIGCONT 信号), 对应的这一组 task_struct 状态将改变;
- 当”进程”收到一个致命信号(比如由于段错误收到 SIGSEGV 信号),对应的这一组 task_struct 将全部退出;
- 等等
-
后来就有了各种各样的尝试,其中既包括用户级线程库,也包括核心级和用户级配合改进的线程库。知名的有 RedHat 公司牵头研发的 NPTL(Native Posix Thread Library),另一个则是IBM投资开发的 NGPT(Next Generation Posix Threading),二者都是围绕完全兼容POSIX 1003.1c,同时在核内和核外做工作以而实现多对多线程模型。这两种模型都在一定程度上弥补了 LinuxThreads 的缺点,且都是重起炉灶全新设计的。
-
现代Linux上默认使用的线程库是NPTL,用户可以使用如下命令查看当前系统上的线程库版本。
-
1getconf GNU_LIBPTHREAD_VERSION -

-
(2) NPTL
-
要解决LinuxThreads线程库的一系列问题,不仅需要改进线程库,最主要的是需要内核提供更完善的线程支持。因此,Liux内核从2.6版本开始,提供了真正的内核线程。新的NPTL线程库也应运而生。相比LinuxThreads,NPTL的主要优势在于:
- 内核线程不再是一个进程,因此避免了很多用进程模拟内核线程导致的语义问题。
- 摒弃了管理线程,终止线程、回收线程堆栈等工作都可以由内核来完成。
- 由于不存在管理线程,所以一个进程的线程可以运行在不同的CPU上,从而充分利用了多处理器系统的优势。
- 线程的同步由内核来完成。隶属于不同进程的线程之间也能共享互斥锁,因此可实现跨进程的线程同步。
-
NPTL是一个1×1的线程模型,即一个线程对于一个操作系统的调度进程,优点是非常简单。
-
在2.4内核中,不存在线程组的概念,当运行一个多线程得程序时,使用ps命令,可以看到有许多个进程,在ps命令看来,线程基本上是等同于进程,在信号处理中,情况也是如此,只有指定进程号的线程,才可以接收到信号。
-
在2.6内核中引入了线程组的概念,在2.6内核中,如果使用ps命令看,一个多线程的进程,只会显示一个进程,在给线程组中的任何一个线程发送信号的时候,整个线程组中的进程都能收到信号。
-
在内核task_struct中相关字段如下
-
1 2 3 4 5 6 7 8 9 10struct task_struct { // ... pid_t pid; pid_t tgid; // ... struct task_struct *group_leader; /* threadgroup leader */ // ... struct list_head thread_group; // ... }; -
pid,从字面上是process id。 tgid,从字面上是thread group id。
-
早些的获取进程或线程的pid的实现是这样:
-
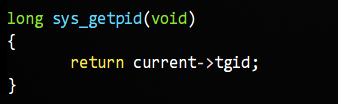
-
可以看到,返回的是 TGID 这个成员,而 current 是一个宏,代表当前的程序。这个 TGID 又是何许人也?这个东西的全称是”Thread Group ID”的意思,即线程组ID的意思,其值等于进程的 PID。所以在一个进程的各个线程中调用getpid()函数的话得到的值是一样的。NPTL 通过这样的一个途径实现了之前的线程库没有解决的线程组的问题。
-
实质上到今天,Linux 内核依旧没有区分进程与线程。这和 Microsoft Windows、或是Sun Solaris等操作系统的实现差异非常大。
-
那如何获取线程的实际的pid呢,可以使用
syscall()函数或gettid()函数(部分系统支持)获取线程ID。其中gettid()函数的早期实现如下所示,可以看到,返回的实际的pid。 -
1 2 3 4asmlinkage long sys_gettid(void) { return current->pid; } -
总结:
- 在Linux中,每个线程都有一个唯一的线程ID(Thread ID),而整个进程(包括主线程和所有子线程)也有一个唯一的进程ID(Process ID)。线程ID和进程ID可以通过相应的系统调用来获取。
- 在C/C++中,可以使用
getpid()函数获取进程ID,而使用syscall()函数或gettid()函数(部分系统支持)获取线程ID。如下是示例代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29#include <iostream> #include <sys/syscall.h> #include <unistd.h> void *threadFunction(void *arg) { // 获取子线程的线程ID // pid_t tid = syscall(SYS_gettid); pid_t tid = gettid(); std::cout << "Child Thread ID: " << tid << std::endl; pid_t pid = getpid(); std::cout << "Child process ID: " << pid << std::endl; return nullptr; } int main() { // 获取主线程的线程ID pid_t mainThreadId = getpid(); std::cout << "Main Thread ans process ID: " << mainThreadId << std::endl; // 创建子线程 pthread_t thread; pthread_create(&thread, nullptr, threadFunction, nullptr); // 等待子线程结束 pthread_join(thread, nullptr); return 0; } -

14.2 创建线程和结束线程
-
进程是 CPU 分配资源的最小单位,线程是操作系统调度执行的最小单位。
线程是轻量级进程(LWP:Light Wight Process),在 Linux 环境下线程的本质仍是进程。
查看指定进程的 LWP 号:
ps -Lf pid -

-
下面我们讨论创建和结束线程的基础API。在Linux系统上,它们都定义在
pthread.h头文件中。 -
(1)pthread_create 创建线程
-
函数原型
-
1 2 3#include <pthread.h> int pthread_create(pthread_t *thread, count pthread_attr_t *attr, void *(*start_routine)(void *), void *arg); -
thread参数是新线程的标识符,后续pthread_*等函数通过它来引用新线程。其类型如下,可见其为一个整数类型
-
1 2#include <bits/pthreadtypes.h> typedef unsignde long int ptherad_t; -
attr参数用于设置线程属性,传递NULL表示使用默认线程属性。
-
start_routine和arg参数指定新线程运行的函数指针和其参数。
-
pthread_create成功返回0,失败返回错误码。
-

-
(2)pthread_exit 结束线程
-
线程函数在结束时候最好调用以下函数,确保安全干净退出。
-
1 2#include <pthread.h> void pthread_exit(void* retval); -
retval参数向线程的回收这传递其退出信息,它执行完毕后不会返回到调用者,且永远不会失败。
-
需要注意一点,pthread_exit返回的retval指针所指向的内存单元必须是全局的或者是用malloc分配的,不能在线程函数的栈上分配,因为当其它线程得到这个返回指针时线程函数已经退出了,栈空间就会被回收。
-
在线程中禁止调用exit函数,否则会导致整个进程退出,取而代之的是调用pthread_exit函数,这个函数是使一个线程退出,如果主线程调用pthread_exit函数也不会使整个进程退出,不影响其他线程的执行。
-
如果在主线程中使用pthread_exit函数,会导致子线程还在,内存无法被回收,成为僵尸进程。因此也就引入pthread_join函数。
-
(3)pthread_join 回收线程
-
一个进程中所有线程,都可以用pthread_join来回收其他线程(前提是该目标线程可回收),即等待其他线程结束。
-
类似于回收进程的wait和waitpid。
-
其函数定义如下
-
1 2#include <pthread.h> int pthread_join(pthread_t thread, void** retval); -
thread参数是目标线程id;
-
retval是目标线程返回的退出信息,整个指针和pthread_exit的参数是同一块内存地址
-
该函数会一直阻塞,直到线程结束。
-
成功返回0,失败返回错误码。
-

-
(4)pthread_cancel 取消线程
-
有时候我们希望异常终止一个线程,即取消线程,它是通过如下函数实现的:
-
1 2#include <ptrhead.h> int pthread_cancel(pthread_t thread); -
thread是目标线程的标识符
-
成功返回0,失败返回错误码(非0值)
-
接受到取消请求的目标线程可以决定是否允许被取消以及如何取消。因此发送成功并不意味着thread会终止。
-
是否允许被取消由如下函数完成。
-
1 2#include <pthread.h> int pthread_setcancelstate(int state, int *oldstate); -
state参数有两个可选值:
- PTHREAD_CANCEL_ENABLE:允许线程被取消,是线程创建时的默认状态
- PTHREAD_CANCEL_DISABLE:禁止取消,这是线程收到后会挂起信息,直到线程允许被取消。
-
oldstate如果不为NULL则存入原来的cancel状态以便恢复。
-
如何取消由如下函数完成:
-
1 2#include <pthread.h> int pthread_setcanceltype(int type, int *oldtype); -
type参数有两个可选值:
- PTHREAD_CANCEL_ASYNCHRONOUS:线程随时可以被取消,接收到取消请求的目标线程立刻采取行动。
- PTHREAD_CANCEL_DEFERRED:允许目标线程推迟行动,直到它调用了下边几个所谓取消点函数中的一个:pthread_join、pthread_testcancel、pthread_cond_wait、pthread_cond_timewait、sem_wait、sigwait。建议是调用thread_testcancel设置取消点。
-
oldtype如果不为NULL则存入原来的取消动作类型值。
-
这两个函数成功返回0,失败返回错误码。
-

-
(5)pthread_detach 分离线程
-
该函数用于分离线程。
-
1 2#include <pthread.h> int pthread_detach(pthread_t thread); -
成功返回0;失败返回错误号(非0)。
-
①线程分离状态:指定该状态,线程主动与主控线程断开关系。线程结束后,其退出状态不由其他线程获取,而直接自己自动释放。网络、多线程服务器常用。
-
②不能对一个已经处于detach状态的线程调用pthread_join,这样的调用将返回EINVAL错误。也就是说,如果已经对一个线程调用了pthread_detach就不能再调用pthread_join了。
-
总结:一般情况下,线程终止后,其终止状态一直保留到其它线程调用pthread_join获取它的状态为止。但是线程也可以被置为detach状态,这样的线程一旦终止就立刻回收它占用的所有资源,而不保留终止状态。因此不能对一个已经处于detach状态的线程调用pthread_join,这样的调用将返回EINVAL错误。
14.3 线程属性
-
线程属性是通过pthread_attr_t结构体来定义的,其各种线程属性全部包含在一个字符数组中。
-
1 2 3 4 5 6 7 8 9 10 11#include <bits/pthreadtypes.h> #define __SIZEOF_PTHREAD_ATTR_T 56 union pthread_attr_t { char __size[__SIZEOF_PTHREAD_ATTR_T]; long int __align; }; #ifndef __have_pthread_attr_t typedef union pthread_attr_t pthread_attr_t; # define __have_pthread_attr_t 1 #endif -
在Linux系统中,线程属性是通过pthread库(POSIX线程库)来管理的。pthread库提供了一些函数,可以用来设置和获取线程的属性。以下函数都在头文件
#include <pthread.h>有定义。 -
pthread_attr_init:初始化线程属性对象。
1int pthread_attr_init(pthread_attr_t *attr); -
pthread_attr_destroy:销毁线程属性对象。被销毁的线程属性对象只有再次初始化之后才能继续使用。
1int pthread_attr_destroy(pthread_attr_t *attr); -
pthread_attr_getdetachstate 和 pthread_attr_setdetachstate:获取和设置线程的分离状态。一个分离状态的线程在退出时会自动释放其资源。
1 2int pthread_attr_getdetachstate(const pthread_attr_t *attr, int *detachstate); int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate); -
pthread_attr_getstackaddr 和 pthread_attr_setstackaddr:获取和设置线程的栈地址。
1 2int pthread_attr_getstackaddr(const pthread_attr_t *attr, void **stackaddr); int pthread_attr_setstackaddr(pthread_attr_t *attr, void *stackaddr); -
pthread_attr_getstacksize 和 pthread_attr_setstacksize:获取和设置线程栈的大小。
cCopy codeint pthread_attr_getstacksize(const pthread_attr_t *attr, size_t *stacksize); int pthread_attr_setstacksize(pthread_attr_t *attr, size_t stacksize); -
pthread_attr_getschedparam 和 pthread_attr_setschedparam:获取和设置线程的调度参数。
1 2int pthread_attr_getschedparam(const pthread_attr_t *attr, struct sched_param *param); int pthread_attr_setschedparam(pthread_attr_t *attr, const struct sched_param *param);调度参数包括线程的优先级等信息。
-
pthread_attr_setschedpolicy 和 pthread_attr_getschedpolicy:设置和获取线程调度策略。
1 2int pthread_attr_setschedpolicy(pthread_attr_t *attr, int policy); int pthread_attr_getschedpolicy(const pthread_attr_t *attr, int *policy); -
pthread_attr_getinheritsched 和 pthread_attr_setinheritsched:获取和设置线程是否继承调度属性。
1 2int pthread_attr_getinheritsched(const pthread_attr_t *attr, int *inheritsched); int pthread_attr_setinheritsched(pthread_attr_t *attr, int inheritsched); -
pthread_attr_getscope 和 pthread_attr_setscope:获取和设置线程的竞争范围。
1 2int pthread_attr_getscope(const pthread_attr_t *attr, int *scope); int pthread_attr_setscope(pthread_attr_t *attr, int scope);竞争范围包括PTHREAD_SCOPE_SYSTEM和PTHREAD_SCOPE_PROCESS。
-
pthread_attr_getstack 和 pthread_attr_setstack:获取和设置线程的栈地址和大小。
1 2int pthread_attr_getstack(const pthread_attr_t *attr, void **stackaddr, size_t *stacksize); int pthread_attr_setstack(pthread_attr_t *attr, void *stackaddr, size_t stacksize); -
pthread_attr_getguardsize 和 pthread_attr_setguardsize:获取和设置线程栈的警戒区大小。警戒区是用于检测栈溢出的额外空间。
1 2int pthread_attr_getguardsize(const pthread_attr_t *attr, size_t *guardsize); int pthread_attr_setguardsize(pthread_attr_t *attr, size_t guardsize); -

-

14.4 线程同步之 POSIX 信号量
-
和多进程程序一样,多线程程序也必须考虑同步问题。pthread join可以看作一种简单的线程同步方式,不过很显然,它无法高效地实现复杂的同步需求,比如控制对共享资源的独占式访问,又抑或是在某个条件满足之后唤醒一个线程。
-
在Linux上常见有3种专门用于线程同步的机制:POSIX信号量、互斥锁和条件变量。
-
在Linux上,信号量API有两组。一组是System V IPC信号量,另外一组是POSX信号量。这两组接口很相似,但不保证能互换。
-
POSIX信号量函数的名字都以
sem_开头,并不像大多数线程函数那样以pthread_开头。常用的POSIX信号量函数是下面5个: -
1 2 3 4 5 6#include <semaphore.h> int sem_init(sem_t *sem, int pshared, unsigned int value); int sem_destory(sem_t *sem); int sem_wait(sem_t *sem); int sem_trywait(sem_t *sem); int sem_post(sem_t *sem); -

-
POSIX 信号量,即可用于线程同步,也可以用于线程互斥。
14.5 线程同步之互斥锁
- 并发:在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行。其中两种并发关系分别是同步和互斥。其中并发又有伪并发和真并发,伪并发是指单核处理器的并发,真并发是指多核处理器的并发。
- 互斥:进程间相互排斥的使用临界资源的现象,就叫互斥。互斥可以看成是一种特殊的同步。
- 同步:进程之间的关系不是相互排斥临界资源的关系,而是相互依赖的关系。进一步的说明:就是前一个进程的输出作为后一个进程的输入,当第一个进程没有输出时第二个进程必须等待。具有同步关系的一组并发进程相互发送的信息称为消息或事件。
- 并行:在单处理器中多道程序设计系统中,进程被交替执行,表现出一种并发的外部特种;在多处理器系统中,进程不仅可以交替执行,而且可以重叠执行。在多处理器上的程序才可实现并行处理。从而可知,并行是针对多处理器而言的。并行是同时发生的多个并发事件,具有并发的含义,但并发不一定并行,也亦是说并发事件之间不一定要同一时刻发生。"并发"强调的是任务的执行顺序和交替执行,而"并行"强调的是同时执行多个任务。
14.5.1 互斥锁基础 API
-
POSIX互斥锁关键函数主要有以下5个:
-
1 2 3 4 5 6#include <pthread.h> int pthread_mutex_init(pthread_mutex_t* mutex, const pthread_mutexattr_t* mutexattr); int pthread_mutex_destory(pthread_mutex_t* mutex); int pthread_mutex_lock(pthread_mutex_t* mutex); int pthread_mutex_trylock(pthread_mutex_t* mutex); int pthread_mutex_unlock(pthread_mutex_t* mutex); -
这些函数的第一个参数mutex指向要操作的目标互斥锁,互斥锁的类型是
pthread_mutex_t结构体。返回值成功时返回0,失败则返回错误码。 -
(1)pthread_mutex_init 函数用于初始化互斥锁,mutexattr参数指定互斥锁的属性,如果置为NULL,则表示使用默认属性。除了这个函数外,我们还可以使用如下方式初始化一个互斥锁:
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;- 实际上只是把互斥锁的各个字段都初始化为0。
-
(2)pthread_mutex_destory 函数用于销毁互斥锁,以释放其占用的内核资源。销毁一个已经加锁的互斥锁将导致不可预期的后果。
-
(3)pthread_mutex_lock 函数用于以原子操作方式加锁互斥锁。如果互斥锁已经被其他线程锁住,调用线程将被阻塞,直到锁被解除。
-
(4)pthread_mutex_trylock 用于尝试加锁互斥锁,但如果互斥锁已经被其他线程锁住,它不会阻塞,而是返回一个错误码EBUSY。这里讨论的 pthread_mutex_lock 和pthread_mutex_trylock 的行为是针对普通锁而言的,对于其他类型的锁(如检错锁、嵌套锁等)而言,这两个加锁函数会有不同的行为。
-
(5)pthread_mutex_unlock 函数以原子操作的方式给一个互斥锁解锁。如果此时有其他线程正在等待这个互斥锁,则这些线程中的某一个将获得它。
14.5.2 互斥锁属性
-
我们可以使用
pthread_mutexattr_t结构体来设置互斥锁的属性,然后将该对象传递给pthread_mutex_init函数以初始化互斥锁。 -
以下是常见的函数
-
1 2 3 4 5 6 7 8 9 10 11#include <pthread.h> //初始化互斥锁属性对象 int pthread_mutexattr_init(pthread_mutexattr_t* attr); //销毁互斥锁属性对象 inrt pthread_mutexattr_destroy(pthread_mutexattr_t* attr); //获取和设置互斥锁的pshared属性 int pthread_mutexattr_getpshared(const pthread_mutexattr_t* attr, int* pshared); int pthread_muextattr_setpshared(pthread_mutexattr_t* attr, int* pshared); //获取和设置互斥锁的type属性 int pthread_mutexattr_gettype(const pthread_mutexattr_t* attr, int* type); int pthread_mutexattr_settype(pthread_mutexattr_t* attr, int* type); -
pshared:- 用于指定互斥锁是否在进程间共享。如果设置为PTHREAD_PROCESS_PRIVATE,互斥锁只在创建它的进程内共享。如果设置为PTHREAD_PROCESS_SHARED,互斥锁可在进程间共享。
- 默认值为PTHREAD_PROCESS_PRIVATE。

-
type:- 用于指定互斥锁的类型。可选值包括PTHREAD_MUTEX_NORMAL(普通锁)、PTHREAD_MUTEX_ERRORCHECK(检错锁,检测同一线程是否重复加锁)、PTHREAD_MUTEX_RECURSIVE(递归锁/嵌套锁,同一线程可以多次加锁)和PTHREAD_MUTEX_DEFAULT(默认锁)。
- 默认值为PTHREAD_MUTEX_NORMAL。

14.6 线程同步之条件变量
-
互斥对象是线程程序必需的工具,但它们并非万能的。例如,如果线程正在等待共享数据内某个条件出现,那需要怎么实现呢?最简单的做法就是反复对互斥对象锁定和解锁,以检查共享数据值的任何变化。同时,还要快速将互斥对象解锁,以便其它线程能够进行任何必需的更改。这是一种非常可怕的方法,因为线程需要在合理的时间范围内频繁地循环检测变化。而且使用忙查询的方法非常浪费时间和资源,效率非常低。比如,线程2的任务是输出“Hello World”,但是必须满足条件iCount等于100。使用互斥锁的实现如下,这是很复杂的,线程2需要不断地开锁、检查、解锁,浪费了很多的系统资源。
-

-
解决这个问题的最好方法是使用pthread_cond_wait() 调用来等待特殊条件发生。当线程在等待满足某些条件时使线程进入睡眠状态。一旦条件满足,还需要一种方法以唤醒因等待满足特定条件而睡眠的线程。如果能够做到这一点,线程代码将是非常高效的,并且不会占用宝贵的互斥对象锁。这正是 POSIX 条件变量能做的事!
-
通常在程序里,我们使用条件变量来表示等待”某一条件”的发生。虽然名叫”条件变量”,但是它本身并不保存条件状态,本质上条件变量仅仅是一种通讯机制:当有一个线程在等待(pthread_cond_wait)某一条件变量的时候,会将当前的线程挂起,直到另外的线程发送信号(pthread_cond_signal)通知其解除阻塞状态。由于要用额外的共享变量保存条件状态(这个变量可以是任何类型比如bool),由于这个变量会同时被不同的线程访问,因此需要一个额外的互斥锁pthread_mutex_t保护它。
-
条件变量(Condition Variable)是一种用于多线程编程的同步机制,通常与互斥锁一起使用,用于在线程之间传递信息和实现线程的等待和通知。
-
条件变量提供了一种线程间的通知机制:当某个共享数据达到某个值时,唤醒等待这个共享数据的线程。
-
条件变量的相关函数主要有以下5个:
-
1 2 3 4 5 6 7 8 9 10 11#incldue <pthread.h> //初始化条件变量 int pthread_cond_init(pthread_cond_t* cond, const pthread_condattr_t* cond_attr); //销毁条件变量 int pthread_cond_destroy(pthread_cond_t* cond); //以广播方式唤醒所有等待目标条件的线程 int pthread_cond_broadcast(pthread_cond_t* cond); //唤醒一个等待目标条件变量的线程 int pthread_cond_signal(pthread_cond_t* cond); //等待目标条件变量 int pthread_cond_wait(ptread_cond_t* cond, pthread_mutex_t* mutex); -
这些函数的第一个参数cond指向要操作的目标条件变量,条件变量的类型是pthread_cond_t结构体。成功时返回0,失败则返回错误码。
-
(1)pthread_cond_init 函数用于初始化条件变量。cond_attr 参数指定条件变量的属性。如果将它设置为ULL,则表示使用默认属性。除了这种方法外,我们还可以使用如下方式来初始化一个条件变量:
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;。- 宏PTHREAD_COND_INITIALIZER实际上只是把条件变量的各个字段都初始化为0。
-
(2)pthread_cond_destroy 函数用于销毁条件变量,以释放其占用的内核资源。销毁一个正在被等待的条件变量将失败并返回EBUSY 错误码。
-
(3)pthread_cond_broadcast 函数以广播的方式唤醒所有等待目标条件变量的线程。pthread_cond_signal 函数用于唤醒一个等待目标条件变量的线程。至于哪个线程将被唤醒,则取决于线程的优先级和调度策略。有时候我们可能想唤醒一个指定的线程,但pthread 没有对该需求提供解决方法。不过我们可以间接地实现该需求:定义一个能够唯一表示目标线程的全局变量,在唤醒等待条件变量的线程前先设置该变量为目标线程,然后采用广播方式唤醒所有等待条件变量的线程,这些线程被唤醒后都检查该变量以判断被唤醒的是否是自己,如果是就开始执行后续代码,如果不是则返回继续等待。
-
(4)pthread_cond_wait 函数用于等待目标条件变量。mutex参数是用于保护条件变量的互斥锁,以确保pthread_cond_wait操作的原子性。在调用pthread_cond_wait前,必须确保互斥锁mutex已经加锁,否则将导致不可预期的结果。pthread_cond_wait 函数执行时,首先把调用线程放人条件变量的等待队列中,然后将互斥锁mutex解锁。可见,从pthread_cond_wait 开始执行到其调用线程被放入条件变量的等待队列之间的这段时间内,pthread_cond_signal 和 pthread_cond_broadcast等函数不会修改条件变量。换言之,pthread_cond_wait 函数不会错过目标条件变量的任何变化。当pthread_cond_wait函数成功返回时,互斥锁mutex将再次被锁上。
-
这里说明一下pthread_cond_wait的内部操作:
-
前提:在调用之前需要锁定互斥锁,然后再调用pthread_cond_wait。
-
1> pthread_cond_wait所做的第一件事就是同时对互斥对象解锁(这样其它线程就可以修改共享对象了)。
-
2> 等待条件是一个阻塞操作,这意味着线程将睡眠,在它苏醒之前不会消耗cpu周期(这正是我们想要的)。线程阻塞直到有人叫它,比如:另一个2号线程锁定了mutex,并对共享对象对了某个动作,在对互斥对象解锁之后,2号线程会立即调用函数pthread_cond_broadcast(&cond)。
-
3> 调用pthread_cond_wait的线程被叫醒之后,将重新锁定mutex,之后才返回。
-
调用伪码如下所示:
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16lock(mutex) ----------------a.lock pthread_cond_wait() { unlock(mutex)-------------a.unlock if ( 条件不满足) 睡觉 else { lock(mutex)-------------a.lock return } } dosomething(); unlock(mutex);---------------a.unlock -

-
pthread_cond_wait 是阻塞的。当一个线程调用 pthread_cond_wait 函数时,它会释放互斥锁并阻塞在等待队列里,直到被其他线程使用 pthread_cond_signal 或 pthread_cond_broadcast 唤醒。当 pthread_cond_wait 被唤醒时,它会尝试重新获取互斥锁。因此,pthread_cond_wait 通常在一个循环里使用,以处理可能的假唤醒。这个在生产者-消费者模型里面可以很明显的看到。
-
14.7 线程同步机制包装类
-
封装信号量、互斥锁、条件变量成如下3个类。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109#ifndef LOCKER_H #define LOCKER_H #include <exception> #include <pthread.h> #include <semaphore.h> /* 封装信号量的类 */ class sem { public: sem() { if( sem_init( &m_sem, 0, 0 ) != 0 ) { throw std::exception(); } } ~sem() { sem_destroy( &m_sem ); } bool wait() { return sem_wait( &m_sem ) == 0; } bool post() { return sem_post( &m_sem ) == 0; } private: sem_t m_sem; }; /* 封装互斥锁的类 */ class locker { public: locker() { if( pthread_mutex_init( &m_mutex, NULL ) != 0 ) { throw std::exception(); } } ~locker() { pthread_mutex_destroy( &m_mutex ); } bool lock() { return pthread_mutex_lock( &m_mutex ) == 0; } bool unlock() { return pthread_mutex_unlock( &m_mutex ) == 0; } private: pthread_mutex_t m_mutex; }; /* 封装条件变量的类 */ class cond { public: cond() { if( pthread_mutex_init( &m_mutex, NULL ) != 0 ) { throw std::exception(); } if ( pthread_cond_init( &m_cond, NULL ) != 0 ) { pthread_mutex_destroy( &m_mutex ); throw std::exception(); } } ~cond() { pthread_mutex_destroy( &m_mutex ); pthread_cond_destroy( &m_cond ); } bool wait() { int ret = 0; pthread_mutex_lock( &m_mutex ); ret = pthread_cond_wait( &m_cond, &m_mutex ); pthread_mutex_unlock( &m_mutex ); return ret == 0; } bool signal() { return pthread_cond_signal( &m_cond ) == 0; } private: pthread_mutex_t m_mutex; pthread_cond_t m_cond; }; #endif
14.8 多线程环境
(1)可重入函数
-
如果一个函数能被多个线程同时调用且不发生竞态条件,则我们称它是线程安全的(thread safe),或者说它是可重入函数。
-
一个可重入的函数简单来说就是可以被中断的函数,也就是说,可以在这个函数执行的任何时刻中断它,转入OS调度下去执行另外一段代码,而返回控制时不会出现什么错误;而不可重入的函数由于使用了一些系统资源,比如全局变量区,中断向量表等,所以它如果被中断的话,可能会出现问题,这类函数是不能运行在多任务环境下的。
-
满足下列条件的函数多数是不可重入(不安全)的:
1)函数体内使用了静态的数据结构;
2)函数体内调用了malloc() 或者 free() 函数;
3)函数体内调用了标准 I/O 函数。
-
Linux库函数只有一小部分是不可重入的,比如
inet_ntoa函数、getservbyname函数、getservbyport函数等。以下是一些示例:printf和fprintf: 这些函数是不可重入的,因为它们使用全局变量来管理输出缓冲区,而在信号处理程序中调用它们可能导致不确定的行为。malloc和free:malloc和free函数在内部使用数据结构来管理堆内存,而这些数据结构可能会被信号处理程序中断,导致不一致性。getenv和setenv: 这些函数使用全局变量来管理环境变量,因此在信号处理程序中调用它们可能导致问题。rand:rand函数使用全局状态来生成伪随机数,因此在信号处理程序中调用它可能导致不确定的结果。- 文件 I/O 函数: 一些文件 I/O 函数,如
fopen、fclose、fread、fwrite等,可能由于文件缓冲区的使用而不可重入。 sleep和usleep: 这些函数可能不是可重入的,因为它们可能会引起不一致性,特别是在多线程环境中。
-
这些库函数之所以不可重入,主要是因为其内部使用了静态变量。
-
不过Linux对很多不可重人的库函数提供了对应的可重入版本,这些可重人版本的函数名是在原函数名尾部加上
_r。比如,函数localtime对应的可重人函数是localtime_r。在多线程程序中调用库函数,一定要使用其可重入版本,否则可能导致预想不到的结果。
(2)线程和fork
-
思考这样一个问题:如果一个多线程程序的某个线程调用了fork函数,那么新创建的子进程是否将自动创建和父进程相同数量的线程呢?答案是“否”,正如我们期望的那样。
-
子进程只拥有一个执行线程,它是调用fok的那个线程的完整复制。并且子进程将自动继承父进程中互斥锁(条件变量与之类似)的状态。也就是说,父进程中已经被加锁的互斥锁在子进程中也是被锁住的。(注意这里是复制了多一个互斥锁)
-
这就引起了一个问题:子进程可能不清楚从父进程继承而来的互斥锁的具体状态(是加锁状态还是解锁状态)。这个互斥锁可能被加锁了,但并不是由调用fork函数的那个线程锁住的,而是由其他线程锁住的。如果是这种情况,则子进程若再次对该互斥锁执行加锁操作就会导致死锁,为什么会死锁,因为这个复制过来的互斥锁是由原本的其他线程锁住的,但是新创建的子进程并没有创建和父进程相同数量的线程,也就是说没有解锁的那个线程,所有会一直无法解锁,再次加锁会一直阻塞形成死锁。
-
形成死锁的示例代码如下:
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40#include <pthread.h> #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <wait.h> pthread_mutex_t mutex; void *another(void *arg) { printf("in child thread, lock the mutex\n"); pthread_mutex_lock(&mutex); sleep(5); pthread_mutex_unlock(&mutex); return NULL; } int main() { pthread_mutex_init(&mutex, NULL); pthread_t id; pthread_create(&id, NULL, another, NULL); sleep(2); int pid = fork(); if (pid < 0) { pthread_join(id, NULL); pthread_mutex_destroy(&mutex); return 1; } else if (pid == 0) { printf("I anm in the child, want to get the lock\n"); pthread_mutex_lock(&mutex); // 以下代码无法执行到,因为形成了死锁 printf("I can not run to here, oop...\n"); pthread_mutex_unlock(&mutex); exit(0); } else { wait(NULL); } pthread_join(id, NULL); pthread_mutex_destroy(&mutex); return 0; } -
-
为了避免这个问题,一般来说,在调用
fork之前,我们需要确保没有任何线程持有互斥锁。 -
不过,pthread 提供了一个专门的函数
pthread_atfork,以确保fork调用后父进程和子进程都拥有一个清楚的锁状态。该函数的定义如下: -
1int pthread_atfork(void (*prepare)(void), void (*parent)(void), void (*child)(void)); -
该函数通过3个不同阶段的回调函数来处理互斥锁状态。参数如下:
-
prepare:将在fork调用创建出子进程之前被执行,它可以给父进程中的互斥锁对象明明确确上锁。这个函数是在父进程的上下文中执行的,正常使用时,我们应该在此回调函数调用 pthread_mutex_lock 来给互斥锁明明确确加锁,这个时候如果父进程中的某个线程已经调用 pthread_mutex_lock 给互斥锁加上了锁,则在此回调中调用 pthread_mutex_lock 将迫使父进程中调用fork 的线程处于阻塞状态,直到prepare能给互斥锁对象加锁为止。(合理的)
-
parent:是在fork调用创建出子进程之后,而fork返回之前执行,在父进程上下文中被执行。它的作用是释放所有在prepare函数中被明明确确锁住的互斥锁。
-
child:是在fork调用创建出子进程之后,而fork返回之前执行,在子进程上下文中被执行。和parent处理函数一样,child函数也是用于释放所有在prepare函数中被明明确确锁住的互斥锁。
-
函数成功返回0, 错误返回错误码。
-
-
因此,可修改为如下代码,方可避免死锁正常工作。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47#include <pthread.h> #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <wait.h> pthread_mutex_t mutex; void *another(void *arg) { printf("in child thread, lock the mutex\n"); pthread_mutex_lock(&mutex); sleep(7); pthread_mutex_unlock(&mutex); return NULL; } void prepare() { pthread_mutex_lock(&mutex); } void infork() { pthread_mutex_unlock(&mutex); } int main() { pthread_mutex_init(&mutex, NULL); pthread_t id; pthread_create(&id, NULL, another, NULL); sleep(2); // fork前确定互斥锁状态 pthread_atfork(prepare, infork, infork); int pid = fork(); if (pid < 0) { pthread_join(id, NULL); pthread_mutex_destroy(&mutex); return 1; } else if (pid == 0) { printf("I anm in the child, want to get the lock\n"); pthread_mutex_lock(&mutex); // 以下代码已经可正常执行 printf("I can not run to here, oop...\n"); pthread_mutex_unlock(&mutex); exit(0); } else { wait(NULL); } pthread_join(id, NULL); pthread_mutex_destroy(&mutex); return 0; } -
(3)线程和信号
-
这里说的信号是Linux的信号,信号是由用户、系统或者进程发送给目标进程的信息,以通知目标进程某个状态的改变或系统异常。
-
之前我们讲过设置进程信号掩码的函数 sigprocmask,但在多线程环境下,我们应该使用pthread版本的线程信号掩码设置函数
pthread_sigmask。 -
1 2 3#include <pthread.h> #include <signal.h> int pthread_sigmask(int how, const sigset_t *set, sigset_t *oldset); -
_set参数指定新的信号掩码,_oset参数则输出原来的信号掩码(如果不为NULL的话),how参数指定设置线程信号掩码的方式。- 如果
_set参数不为NULL,则how参数指定设置线程信号掩码的方式,其可选值如下所示。 - 如果
_set为NULL,则线程信号掩码不变,此时我们仍然可以利用_ost参数来获得线程当前的信号掩码。此时how参数无作用。
- 如果
-
函数成功调用返回0,失败返回-1并设置errno。
-
可以看到,函数
pthread_sigmask和函数 sigprocmask的参数完全相同。 -
由于进程中的所有线程共享该进程的信号,所以线程库将根据线程掩码决定把信号发送给哪个具体的线程。因此,如果我们在每个子线程中都单独设置信号掩码,就很容易导致逻辑错误。此外,所有线程共享信号处理函数。也就是说,当我们在一个线程中设置了某个信号的信号处理函数后,它将覆盖其他线程为同一个信号设置的信号处理函数。这两点都说明,我们应该定义一个专门的线程来处理所有的信号。
-
定义一个专门的线程来处理所有的信号可以通过如下两个步骤来实现:
- (a)在主线程创建出其他子线程之前就调用pthread_sigmask来设置好信号掩码,所有新创建的子线程都将自动继承这个信号掩码。这样做之后,实际上所有线程都不会响应被屏蔽的信号了。
- (b)在某个专门线程中调用 sigwait 函数来等待信号并处理之。
-
1 2#include <signal.h> int sigwait(const sigset_t *set, int *sig); -
其中,set 表示要等待的信号集,sig 是一个指针,用于返回收到的信号编号。成功时返回0,失败则返回错误码。
-
很显然,如果我们使用了sigwait,就不应该再为信号设置信号处理函数了。这是因为当程序接收到信号时,二者中只能有一个起作用。
-
线程在调用sigwait之前,必须阻塞那些它正在等待的信号(即屏蔽该信号),sigwait函数会自动取消信号集的阻塞状态。在返回之前,sigwait将恢复线程的信号屏蔽字。如果信号在sigwait调用的时候没有被阻塞,在完成对sigwait调用之前会出现一个时间窗,在这个窗口期,某个信号可能在线程完成sigwait调用之前就被递送了。
-
因此,set一般指定为第一步中创建的被屏蔽的信号掩码。
-
以下代码实现了在一个线程中统一处理所有信号。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66#include <errno.h> #include <pthread.h> #include <signal.h> #include <stdio.h> #include <stdlib.h> #include <unistd.h> /* Simple error handling functions */ #define handle_error_en(en, msg) \ do { \ errno = en; \ perror(msg); \ exit(EXIT_FAILURE); \ } while (0) static void *sig_thread(void *arg) { int s, sig; sigset_t *set = (sigset_t *)arg; for (;;) { s = sigwait(set, &sig); if (s != 0) handle_error_en(s, "sigwait"); printf("Signal handling thread got signal %d\n", sig); if (sig == 10) { break; } } return NULL; } int main(int argc, char *argv[]) { pthread_t thread; sigset_t set; int s; // 第一步:在主线程中设置屏蔽信号掩码 sigemptyset(&set); sigaddset(&set, SIGQUIT); sigaddset(&set, SIGUSR1); s = pthread_sigmask(SIG_BLOCK, &set, NULL); if (s != 0) handle_error_en(s, "pthread_sigmask"); // 创建子线程 s = pthread_create(&thread, NULL, &sig_thread, (void *)&set); if (s != 0) handle_error_en(s, "pthread_create"); printf("sub thread with id: %ld\n", thread); /* Main thread carries on to create other threads and/or do * other work */ sleep(3); printf("main thread send SIGQUIT : 3\n"); pthread_kill(thread, SIGQUIT); sleep(1); printf("main thread send SIGUSR1 : 10\n"); pthread_kill(thread, SIGUSR1); // 等待子线程结束 pthread_join(thread, NULL); return 0; } -
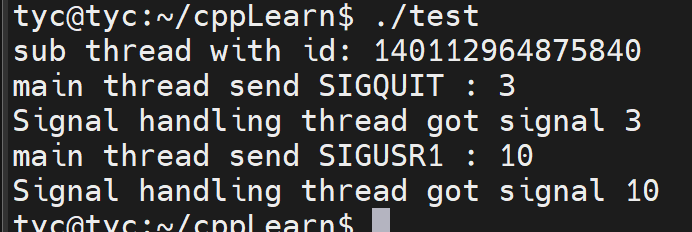
-
从结果可以看出,确实处理了相关信号。
-
上述代码使用了
pthread_kill函数来明确地将一个信号发送给指定的线程。 -
1 2#include <signal.h> int pthread_kill(pthread_t thread, int sig); -
其中,thread参数指定目标线程,sig参数指定待发送的信号。如果sig为0,则pthread_kill不发送信号,但它任然会执行错误检查。我们可以利用这种方式来检测目标线程是否存在。pthread_kill成功时返回0,失败则返回错误码。
第 15 章 进程池和线程池
15.1 查看cpu的物理处理核心个数和逻辑线程个数
-
CPU核心数指物理上,也就是硬件上存在着几个核心。比如,双核就是包括2个相对独立的CPU核心单元组,四核就包含4个相对独立的CPU核心单元组,等等,依次类推。
-
线程数是一种逻辑的概念,简单地说,就是模拟出的CPU核心数。比如,可以通过一个CPU核心数模拟出2线程的CPU,也就是说,这个单核心的CPU被模拟成了一个类似双核心CPU的功能(超线程技术)。我们从任务管理器的性能标签页中看到的是两个CPU
-
(1)对于windows,可以通过
wmic cpu get NumberOfCores命令查看物理处理核心个数,wmic cpu get NumberOfLogicalProcessors命令查看逻辑线程个数。 -
-
(2)对于ubuntu,可以通过
nproc命令查看逻辑线程个数,lscpu查看物理处理核心个数。 -
15.2 线程数量设置为多少
-
CPU密集型任务:
- CPU密集型任务是指需要大量计算能力的任务,例如数学运算、图形处理、数据分析、编码和解码视频等。
- 这些任务通常会占用大量的CPU资源,因为它们需要处理大量的计算操作,而与硬盘或网络通信的频率相对较低。
- 通常情况下,提高CPU性能(如提高CPU时钟频率或使用多核CPU)可以改善CPU密集型任务的执行性能。
-
IO密集型任务:
- IO密集型任务是指需要大量的输入/输出操作(例如读取文件、数据库查询、网络通信)的任务。
- 这些任务通常不需要大量的计算能力,但需要等待IO操作完成,因此它们可能会占用大量的时间。
- 对于IO密集型任务,提高CPU性能通常不会显著提高性能,因为瓶颈通常是在IO操作上。
- 优化IO密集型任务的关键在于减少等待时间,例如使用异步IO、多线程或多进程等技术。
-
假设机器有N个CPU(逻辑线程个数),那么
- 对于计算密集型的任务,应该设置线程数为N+1;
- 对于IO密集型的任务,应该设置线程数为2N;
- 对于同时有计算工作和IO工作的任务,应该考虑使用两个线程池,一个处理计算任务,一个处理IO任务,分别对两个线程池按照计算密集型和IO密集型来设置线程数。
-
以上结果是一种粗略的经验公式,近似公式,《Java 并发编程实战》介绍了一个线程数计算的公式:
-

-

-
虽然公式很好,但在真实的程序中,一般很难获得准确的等待时间和计算时间,因为程序很复杂,不只是“计算”。一段代码中会有很多的内存读写,计算,I/O 等复合操作,精确的获取这两个指标很难,所以光靠公式计算线程数过于理想化。
-
那么在实际的程序中,或者说一些Java的业务系统中,线程数(线程池大小)规划多少合适呢?
-
结论:没有固定答案,先设定预期,比如我期望的CPU利用率在多少,负载在多少,GC频率多少之类的指标后,再通过测试不断的调整到一个合理的线程数。
15.3 用进程池实现简单的 CGI 服务器 (高效的半同步/半异步模式)
-
实现的 CGI 服务器为:客户端连接后,发送想要打开的应用程序名称,后接换行符表示结束。客户端查看若该程序存在,则新建子进程运行该程序,否则重新接收。
-
当然实现的比较简陋。
-
采用基本模型如下所示。
-

-
-
为了避免在父子进程之间传递文件描述符,将accept操作放到子进程中。
-
总体流程如下所示。**本质上也属于一种高效的半同步/半异步模式。**对于这种实现,一个客户连接上的所有任务始终是由一个子进程来处理的。
-

-
进程池头文件如下所示。命名为
processpool.h。 -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384#ifndef PROCESSPOOL_H #define PROCESSPOOL_H #include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <signal.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/epoll.h> #include <sys/socket.h> #include <sys/stat.h> #include <sys/types.h> #include <sys/wait.h> #include <unistd.h> /*描述一个子进程的类,m_pid是目标子进程的PID,m_pipefd是父进程和子进程通信用的管道*/ class process { public: process() : m_pid(-1) {} public: pid_t m_pid; int m_pipefd[2]; }; /*进程池类,将它定义为摸板类是为了代码复用。其模板参数是处理逻辑任务的类; 模板参数必须实现两个函数 process() init(); */ template <typename T> class processpool { private: // 构造函数私有化 processpool(int listenfd, int process_number = 8); public: // 单例模式,保证程序最多创建一个进程池 static processpool<T> *create(int listenfd, int process_number = 8) { if (!m_instance) { m_instance = new processpool<T>(listenfd, process_number); } return m_instance; } ~processpool() { delete[] m_sub_process; } // 启动进程池 void run(); private: void setup_sig_pipe(); void run_parent(); void run_child(); private: static const int MAX_PROCESS_NUMBER = 16; // 进程池允许的最大子进程数量 static const int USER_PER_PROCESS = 65536; // 每个子进程最多能处理的客户数量,文件描述符总数 static const int MAX_EVENT_NUMBER = 10000; // epoll最多能处理的事件数 int m_process_number; // 进程池中进程总数 int m_idx; // 子进程在池中的序号,从0开始,-1为父进程 int m_epollfd; // 每个进程都有一个epoll内核事件表用m_epollfd标识,每个进程都是多路复用 int m_listenfd; // 监听socket int m_stop; // 子进程通过m_stop来决定是否停止运行 process *m_sub_process; // 保存所有子进程描述信息 static processpool<T> *m_instance; // 进程池静态实例 }; template <typename T> processpool<T> *processpool<T>::m_instance = NULL; static int sig_pipefd[2]; static int setnonblocking(int fd) { int old_option = fcntl(fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl(fd, F_SETFL, new_option); return old_option; } static void addfd(int epollfd, int fd) { epoll_event event; event.data.fd = fd; event.events = EPOLLIN | EPOLLET; epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event); setnonblocking(fd); } /*从epollfd标识的epol1内被事件表中剩除fd上的所有注册事件*/ static void removefd(int epollfd, int fd) { epoll_ctl(epollfd, EPOLL_CTL_DEL, fd, 0); close(fd); } // 信号处理函数,传递到管道 static void sig_handler(int sig) { int save_errno = errno; int msg = sig; send(sig_pipefd[1], (char *)&msg, 1, 0); errno = save_errno; } static void addsig(int sig, void(handler)(int), bool restart = true) { struct sigaction sa; memset(&sa, '\0', sizeof(sa)); sa.sa_handler = handler; if (restart) { sa.sa_flags |= SA_RESTART; } sigfillset(&sa.sa_mask); assert(sigaction(sig, &sa, NULL) != -1); } // 进程池构造函数,父进程m_idx为-1 // listenfd 是监听sokcet,必须在创建进程前被创建 // process_number指定进程池中子进程数量 template <typename T> processpool<T>::processpool(int listenfd, int process_number) : m_listenfd(listenfd), m_process_number(process_number), m_idx(-1), m_stop(false) { assert((process_number > 0) && (process_number <= MAX_PROCESS_NUMBER)); m_sub_process = new process[process_number]; assert(m_sub_process); // 使用管道实现了父进程与多个子进程之间的双向通信 for (int i = 0; i < process_number; ++i) { int ret = socketpair(PF_UNIX, SOCK_STREAM, 0, m_sub_process[i].m_pipefd); assert(ret == 0); m_sub_process[i].m_pid = fork(); assert(m_sub_process[i].m_pid >= 0); // 父子进程管道都只留一个口,可读可写 if (m_sub_process[i].m_pid > 0) { // 父进程默认从m_pipefd[0]读写 close(m_sub_process[i].m_pipefd[1]); continue; } else { // 子进程默认从m_pipefd[1]读写 close(m_sub_process[i].m_pipefd[0]); // 每个子进程拥有自己的m_idx m_idx = i; break; } } } // 统一事件源 template <typename T> void processpool<T>::setup_sig_pipe() { // 创建epoll事件监听表和信号管道,5只是提示无实际意义。 m_epollfd = epoll_create(5); assert(m_epollfd != -1); int ret = socketpair(PF_UNIX, SOCK_STREAM, 0, sig_pipefd); assert(ret != -1); setnonblocking(sig_pipefd[1]); // 信号处理函数->epoll addfd(m_epollfd, sig_pipefd[0]); // 设置信号处理函数 addsig(SIGCHLD, sig_handler); addsig(SIGTERM, sig_handler); addsig(SIGINT, sig_handler); addsig(SIGPIPE, SIG_IGN); } /*父进程中m_idx值为-1,子进程中m_idx值大于等于0,我们据此判斯接下来要运行的是父进程代码还是子进程代码*/ template <typename T> void processpool<T>::run() { if (m_idx != -1) { run_child(); return; } run_parent(); } template <typename T> void processpool<T>::run_child() { // 创建epoll,统一事件源 setup_sig_pipe(); // 每个子进程都通过其在进程池中的序号值m_idx找到与父进程通信的管道 int pipefd = m_sub_process[m_idx].m_pipefd[1]; // 子进程需要监听管道文件描述符 pipefd, // 因为父进程将通过它来通知子进程accept新连接 addfd(m_epollfd, pipefd); epoll_event events[MAX_EVENT_NUMBER]; T *users = new T[USER_PER_PROCESS]; assert(users); int number = 0; int ret = -1; while (!m_stop) { number = epoll_wait(m_epollfd, events, MAX_EVENT_NUMBER, -1); if ((number < 0) && (errno != EINTR)) { printf("epoll failure\n"); break; } for (int i = 0; i < number; i++) { int sockfd = events[i].data.fd; // 存在新的连接 if ((sockfd == pipefd) && (events[i].events & EPOLLIN)) { int client = 0; // 从父子进程之间的管道读取数据,并保存在变量client中。 // 如果成功,表示有新客户连接到来 ret = recv(sockfd, (char *)&client, sizeof(client), 0); if (((ret < 0) && (errno != EAGAIN)) || ret == 0) { continue; } else { struct sockaddr_in client_address; socklen_t client_addrlength = sizeof(client_address); int connfd = accept(m_listenfd, (struct sockaddr *)&client_address, &client_addrlength); if (connfd < 0) { printf("errno is: %d\n", errno); continue; } addfd(m_epollfd, connfd); // 模板类T必须实现init方法,这里是连接类 users[connfd].init(m_epollfd, connfd, client_address); } } // 处理子进程接收到的信号 else if ((sockfd == sig_pipefd[0]) && (events[i].events & EPOLLIN)) { int sig; char signals[1024]; ret = recv(sig_pipefd[0], signals, sizeof(signals), 0); if (ret <= 0) { continue; } else { for (int i = 0; i < ret; ++i) { switch (signals[i]) { case SIGCHLD: { pid_t pid; int stat; while ((pid = waitpid(-1, &stat, WNOHANG)) > 0) { continue; } break; } case SIGTERM: case SIGINT: { m_stop = true; break; } default: { break; } } } } } // 若是其他可读数据,必然是客户请求到来,调用处理逻辑处理对象的process方法处理即可 else if (events[i].events & EPOLLIN) { users[sockfd].process(); } else { continue; } } } delete[] users; users = NULL; close(pipefd); // close( m_listenfd ); // 哪个创建的listenfd,应该由哪个函数销毁 // ,后面cgi服务器程序中销毁,而不是在子进程这里 close(m_epollfd); } template <typename T> void processpool<T>::run_parent() { // 设置信号管道,统一信号源 setup_sig_pipe(); // 父进程监听m_listenfd addfd(m_epollfd, m_listenfd); epoll_event events[MAX_EVENT_NUMBER]; int sub_process_counter = 0; int new_conn = 1; int number = 0; int ret = -1; while (!m_stop) { number = epoll_wait(m_epollfd, events, MAX_EVENT_NUMBER, -1); if ((number < 0) && (errno != EINTR)) { printf("epoll failure\n"); break; } for (int i = 0; i < number; i++) { int sockfd = events[i].data.fd; if (sockfd == m_listenfd) { // 若有新连接到来,就用Round Robin方式将其分配给一个子进程处理 int j = sub_process_counter; do { if (m_sub_process[j].m_pid != -1) { break; } j = (j + 1) % m_process_number; } while (j != sub_process_counter); if (m_sub_process[j].m_pid == -1) { m_stop = true; break; } // 递增轮询 sub_process_counter = (j + 1) % m_process_number; send(m_sub_process[j].m_pipefd[0], (char *)&new_conn, sizeof(new_conn), 0); printf("send request to child %d\n", j); } // 处理父进程接收到的信号 else if ((sockfd == sig_pipefd[0]) && (events[i].events & EPOLLIN)) { int sig; char signals[1024]; ret = recv(sig_pipefd[0], signals, sizeof(signals), 0); if (ret <= 0) { continue; } else { for (int i = 0; i < ret; ++i) { switch (signals[i]) { case SIGCHLD: { pid_t pid; int stat; // 如果进程池中第i个子进程退出了,则主进程关闭相应的通信管道 // 并设置相应的m_pid为-1,标记该子进程退出 while ((pid = waitpid(-1, &stat, WNOHANG)) > 0) { for (int i = 0; i < m_process_number; ++i) { if (m_sub_process[i].m_pid == pid) { printf("child %d join, pid is %d\n", i, pid); close(m_sub_process[i].m_pipefd[0]); m_sub_process[i].m_pid = -1; } } } // 若所有子进程都退出了,则父进程也退出 m_stop = true; for (int i = 0; i < m_process_number; ++i) { if (m_sub_process[i].m_pid != -1) { m_stop = false; } } break; } case SIGTERM: case SIGINT: { // 若父进程收到终止信号,那么就杀死所有子进程 // 并等待它们全部结束。当然,通知子进程结束更好的方法是 // 向父子进程间的通信管道发送特殊数据。 printf("kill all the clild now\n"); for (int i = 0; i < m_process_number; ++i) { int pid = m_sub_process[i].m_pid; if (pid != -1) { kill(pid, SIGTERM); } } break; } default: { break; } } } } } else { continue; } } } // close( m_listenfd ); //由创建者关闭这个文件描述符 close(m_epollfd); } #endif -
主程序如下所示
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141#include <arpa/inet.h> #include <assert.h> #include <errno.h> #include <fcntl.h> #include <netinet/in.h> #include <signal.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/epoll.h> #include <sys/socket.h> #include <sys/stat.h> #include <sys/types.h> #include <unistd.h> #include "processpool.h" // 用于处理客户CGI请求的类,可作为processpool类的模板参数 class cgi_conn { public: cgi_conn() {} ~cgi_conn() {} // 初始化客户连接,清空读缓冲区 void init(int epollfd, int sockfd, const sockaddr_in &client_addr) { m_epollfd = epollfd; m_sockfd = sockfd; m_address = client_addr; memset(m_buf, '\0', BUFFER_SIZE); } void process() { int idx = 0; int ret = -1; m_read_idx = 0; memset(m_buf, '\0', BUFFER_SIZE); // 循环读取和分析客户数据 while (true) { idx = m_read_idx; ret = recv(m_sockfd, m_buf + idx, BUFFER_SIZE - 1 - idx, 0); // 若是暂时无数据可读,则退出循环 if (ret < 0) { // 读操作错误,关闭客户连接 if (errno != EAGAIN && errno != EWOULDBLOCK) { removefd(m_epollfd, m_sockfd); } break; } // 如果对方关闭连接,则服务器也关闭连接 else if (ret == 0) { removefd(m_epollfd, m_sockfd); break; } else { pid_t pid = getpid(); printf("Current process PID: %d\n", pid); m_read_idx += ret; // 修改已读到的最后位置 printf("user content is: %s\n", m_buf); // 若遇到"\r\n",则开始处理客户请求 for (; idx < m_read_idx; ++idx) { if ((idx >= 1) && (m_buf[idx - 1] == '\r') && (m_buf[idx] == '\n')) { break; } } // 若没遇到"\r\n",则需要读取更多客户端数据 if (idx == m_read_idx) { continue; } m_buf[idx - 1] = '\0'; char *file_name = m_buf; // 判断客户要运行的CGI程序是否存在 if (access(file_name, F_OK) == -1) { removefd(m_epollfd, m_sockfd); break; } // 创建子进程来执行CGI程序 ret = fork(); if (ret == -1) { // 将对m_sockfd事件监视从epoll内核事件表移除 removefd(m_epollfd, m_sockfd); } else if (ret > 0) { // 父进程只需要关闭连接 removefd(m_epollfd, m_sockfd); break; } else { // 子进程将标准输出定向到m_sockfd,并执行CGI程序 printf("open CGI Program is : %s\n", m_buf); close(STDOUT_FILENO); dup(m_sockfd); execl(m_buf, m_buf, "this is send msg!", NULL); exit(0); } } } } private: // 读缓冲的大小 static const int BUFFER_SIZE = 1024; static int m_epollfd; int m_sockfd; sockaddr_in m_address; char m_buf[BUFFER_SIZE]; // 标记读缓冲已经读入客户数据的最后一个字节的下一个位置 int m_read_idx; }; int cgi_conn::m_epollfd = -1; int main(int argc, char *argv[]) { const char *ip = "192.168.141.128"; int port = 12345; int listenfd = socket(PF_INET, SOCK_STREAM, 0); assert(listenfd >= 0); int ret = 0; struct sockaddr_in address; memset(&address, 0, sizeof(address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); ret = bind(listenfd, (struct sockaddr *)&address, sizeof(address)); assert(ret != -1); ret = listen(listenfd, 5); assert(ret != -1); printf("Main process PID: %d\n", (int)getpid()); // 只能通过类的静态成员函数获得唯一的进程池实例 processpool<cgi_conn> *pool = processpool<cgi_conn>::create(listenfd); // 已经是多线程了 printf("Current process PID: %d\n", (int)getpid()); if (pool) { pool->run(); delete pool; } // 谁创建,谁关闭 close(listenfd); return 0; } -
测试的时候调用的cgi外部程序如下所示。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14#include <iostream> int main(int argc, char *argv[]) { // 检查是否有足够的参数 if (argc < 2) { std::cerr << "Usage: " << argv[0] << " <string>" << std::endl; return 1; // 返回错误码表示不成功 } // 输出命令行参数 std::cout << "hello client , recv msg is : " << argv[1] << std::endl; return 0; // 返回成功码 } -
测试结果如下
-
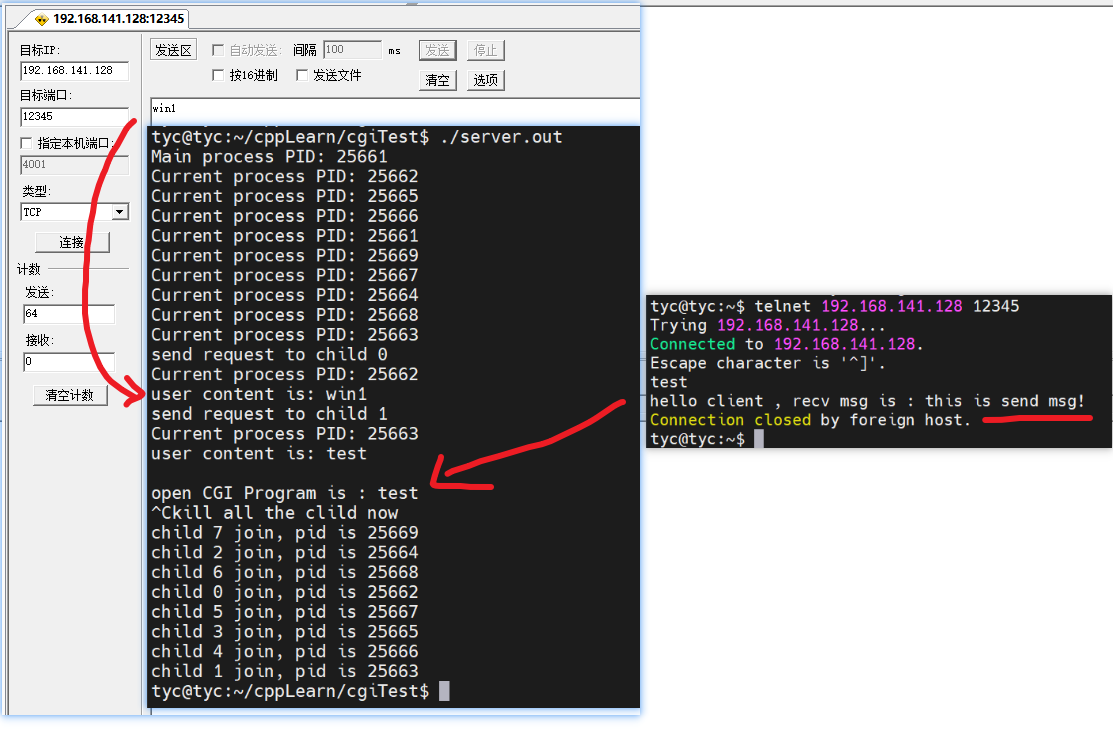
-
项目代码可见github EasyWebServer/CGI-Learn at master · Changtyc/EasyWebServer (github.com)
15.4 线程池实现简单的 Web 服务器
(1)类中使用 pthread_create 函数的注意点
- 在类的构造函数或普通成员函数使用
pthread_create创建线程时,线程的执行函数必须是一个静态函数或者是一个全局函数,而不能是类的普通成员函数。这是因为普通成员函数隐含地包含了一个this指针,而pthread_create的执行函数签名要求是void* (*)(void*),它不包含类实例指针。 - 但要在一个静态函数中使用类的动态成员(包括成员函数和成员变量),一般可以有以下两种方法
- 通过类的静态对象来调用。比如单例模式中,静态函数可以通过类的全局唯一实例来访问动态成员函数。
- 将类的对象作为参数(this指针)传递给该静态函数,然后在静态函数中引用这个对象,并调用其动态方法。
- 以下的线程池类的实现,使用就是传递this指针的方法。
(2)实现
-
总体框架如下
-

-
需要注意的是,这里采用的都是epoll的ET模式,效率更高。
-
解析HTTP报文采用主从两个有限状态机实现,主状态机实现HTTP报文的请求行、请求头和请求体的状态转换,主状态机在内部调用从状态机;从状态机实现解析http请求报文一行的任务,状态转换如下。
-
-
以下是测试结果,本地浏览器访问
http://192.168.141.128:12345/index.html,前提是服务器的网站根目录确实存在该index.html文件。 -
-
源码编译的架构如下所示
-
-
源码地址 EasyWebServer/GET-WebServer at master · Changtyc/EasyWebServer (github.com)
15.5 Linux最多能创建多少TCP连接
-
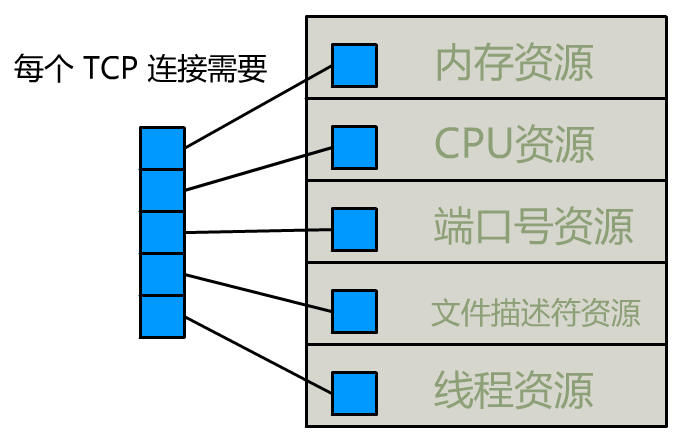
-
以下是一些总结
-
资源 一台Linux服务器的资源 一个TCP连接占用的资源 占满了会发生什么 CPU 看你花多少钱买的 看你用它干嘛 电脑卡死 内存 看你花多少钱买的 取决于缓冲区大小 OOM 临时端口号 ip_local_port_range 1 cannot assign requested address 文件描述符 fs.file-max 1 too many open files 进程\线程数 ulimit -n 看IO模型 系统崩溃 -
(1)端口号
-
Linux 对可使用的端口范围是有具体限制的,具体可以用如下命令查看。
-
1cat /proc/sys/net/ipv4/ip_local_port_range -

-
显示结果表示端口号限制范围为 32768-60999。
-
这种是针对一个四元组而言的,即源 IP 地址:源端口号 <----> 目标 IP 地址:目标端口号,若目标IP和目标端口始终不变,那么本地临时端口号就只能使用上述端口范围。
-
但如果不同IP或不同端口,那么又是新的一组了,又可以重新使用上述的端口号范围了。
-
也就是说,只要源端口号不用够用了,就不断变换目标 IP 和目标端口号,保证四元组不重复,就能创建好多好多 TCP 连接啦!这也证明了有人说最多只能创建 65535 个TCP连接是多么荒唐。
-
(2)文件描述符
-
每建立一个TCP连接,操作系统就得分配给你一个文件描述符,linux 对可打开的文件描述符的数量分别作了三个方面的限制。
系统级:当前系统可打开的最大数量,通过 cat /proc/sys/fs/file-max 查看
用户级:指定用户可打开的最大数量,通过 cat /etc/security/limits.conf 查看
进程级:单个进程可打开的最大数量,通过 cat /proc/sys/fs/nr_open 查看
-
(3)线程/进程数
-
存在 C10K 问题,就是当服务器连接数达到 1 万且每个连接都需要消耗一个线程资源时,操作系统就会不停地忙于线程的上下文切换,最终导致系统崩溃。
-
可以通过IO多路复用稍微解决这种问题。每建一个TCP连接就创建一个线程的方式,是最传统的多线程并发模型,早期的操作系统也只支持这种方式。但现在的操作系统还支持 IO 多路复用的方式,简单说就是一个线程可以管理多个 TCP 连接的资源,这样就可以用少量的线程来管理大量的 TCP 连接了。
第 16 章 socket server服务器开发的并发模型总结
16.1 概述
-
服务器程序通常需要处理三类事件:I/O 事件、信号及定时事件。有两种高效的事件处理模式:Reactor和 Proactor,同步 I/O 模型通常用于实现Reactor 模式,异步 I/O 模型通常用于实现 Proactor 模式。
-
无论是 Reactor,还是 Proactor,都是一种基于「事件分发」的网络编程模式,区别在于 Reactor 模式是基于「待完成」的 I/O 事件,而 Proactor 模式则是基于「已完成」的 I/O 事件。
-
同步IO实现reactor模式:主线程只负责监听lfd,accept成功之后把新创建的cfd交给子线程。子线程再通过IO多路复用去监听cfd的读写数据,并且处理客户端业务。(主线程把已被触发但是还未完成的事件分发给子线程)
-
同步IO模拟proactor模式:主线程accpet监听lfd,并且lfd读事件触发时,建立连接并创建cfd,并且通过epoll_ctl把cfd注册到内核的监听树中,等到该socket的读事件就绪时,主线程进行读操作,把读到的内容交给子线程去进行业务处理,然后子线程处理完业务之后把该socketfd又注册为写时间就绪,并且把数据交回给主线程,由主线程写回给客户端。(主线程模拟真实Proactor模式中的异步线程,把已完成的事件分发给子线程)
-
Linux基本上逐步实现了POSIX兼容,但并没有参加正式的POSIX认证。由于Linux下的异步IO不完善,aio_read,aio_write系列函数是由POSIX定义的异步操作接口,不是真正操作系统级别支持的,而是在用户空间模拟出来的异步,并且仅支持本地文件的aio异步操作,网络编程中的socket是不支持的。
- Linux 下的 Posix AIO 是由 glibc 在 user space 用多线程+同步阻塞 IO 模拟的,效率还远不如 epoll。FreeBSD 倒是有原生支持 Posix AIO 的 Kernel Mod。
- 真正意义上的异步 IO 是比 epoll 等多路复用的非阻塞 IO 机制性能更好的通信方式,也是最贴近现代硬件 DMA + 中断工作方式的 IO 编程模型,可以做到内存零拷贝等非阻塞 IO 做不到的性能优化。
- Linux 自己其实也有 Kernel 级的 AIO ABI(io_submit),不过跟 Posix AIO API 不兼容,而且还有很多问题,比如:只支持以指定标识(O_DIRECT)打开的文件,不支持 socket 句柄等等。
-
IOCP (Input/Output Completion Ports) 是 Windows 操作系统提供的一种高性能、可扩展的异步 I/O 模型,是真正的异步I/O。
-
为什么要用同步IO模拟proactor模式呢? 理论上 Proactor 比 Reactor 效率要高一些,异步 I/O 能够充分利用 DMA 特性,让 I/O 操作与计算重叠,但要实现真正的异步 I/O,操作系统需要做大量的工作。目前 Windows 下通过 IOCP 实现了真正的异步 I/O,而在 Linux 系统下的 AIO 并不完善,因此在 Linux 下实现高并发网络编程时都是以 Reactor 模式为主。所以即使 Boost.Asio 号称实现了 Proactor 模型,其实它在 Windows 下采用 IOCP,而在 Linux 下是用 Reactor 模式(采用 epoll)模拟出来的异步模型。
16.2 模型一:单线程accept(无IO复用)
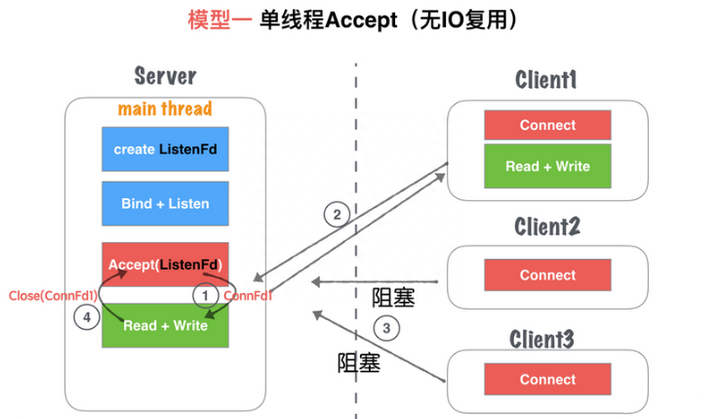
- ①主线程执行阻塞accept,每次客户端connect请求连接过来,主线程中的accept响应并建立连接
- ②创建连接成功之后,得到新的套接字文件描述符cfd(用于与客户端通信),然后在主线程串行处理套接字读写,并处理业务。
- ③在②的处理业务时,如果有新的客户端发送请求连接,会被阻塞,服务器无响应,直到当前的cfd全部业务处理完毕,重新回到accept阻塞监听状态时,才会从请求队列中选取第一个lfd进行连接。
- 优点:
- socket编程流程清晰且简单,适合学习使用,了解socket基本编程流程。
- 缺点:
- 该模型并非并发模型,是串行的服务器,同一时刻,监听并响应最大的网络请求量为1。即并发量为1。
- 仅适合学习基本socket编程,不适合任何服务器Server构建。
16.3 模型二:单线程accept + 多线程读写业务(无IO复用)
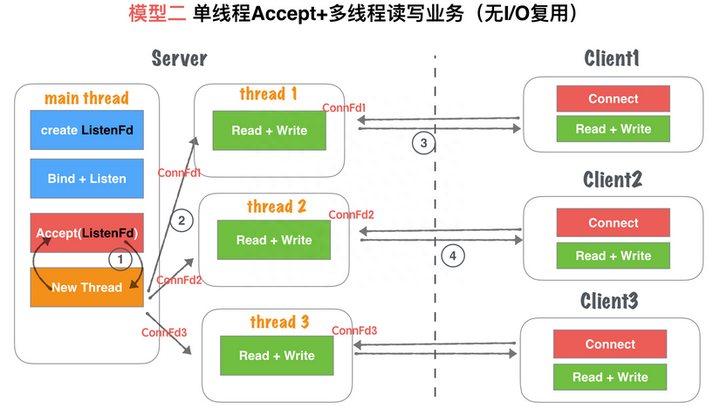
- ①主线程执行accept阻塞监听,每当有客户端connect连接请求过来,主线程中的accept响应并且与客户端建立连接
- ②创建连接成功后得到新的cfd,然后再thread_create一个新的线程用来处理客户端的读写业务,并且主线程马上回到accept阻塞监听继续等待新客户端的连接请求
- ③这个新的线程通过套接字cfd与客户端进行通信读写
- ④服务器在②处理业务中,如果有新客户端发送申请连接过来,主线程accept依然会响应并且简历连接,重复②过程。
- 优点:
- 基于模型一作了改进,支持了并发
- 使用灵活,一个client对应一个thread单独处理,server处理业务的内聚程度高(一个好的内聚模块应当恰好做一件事)。客户端无论如何写,服务端都会有一个线程做资源响应。
- 缺点:
- 随着客户端的数量增多,需要开辟的线程也增加,客户端与服务端线程数量是1:1正比关系。因此对于高并发场景,线程数量收到硬件的瓶颈制约。线程过多也会增加CPU的切换成本,降低CPU的利用率。
- 对于长连接,客户端一旦没有业务读写操作,只要客户端不关闭,服务端的对应线程就必须要保持连接(心跳包、健康监测等机制),占用连接资源和线程的开销。
- 仅适合客户端数量不大,并且是可控的场景来使用。
16.4 模型三:单线程多路IO复用

- ①主线程main thread 创建 lfd之后,采用多路IO复用机制(如select和epoll)进行IO状态阻塞监听。有client1客户端 connect 请求, IO复用机制检测到lfd触发事件读写,则进行accept建立连接,并将新生成的cfd1加入到监听IO集合中。
- ②client1 再次进行正常读写业务请求,主线程的多路IO复用机制阻塞返回,主线程与client1进行读写通信业务。等到读写业务结束后,会再次返回多路IO复用的地方进行阻塞监听。
- ③如果client1正在进行读写业务时,server依然在主线程执行流程中继续执行,此时如果有新的客户端申请连接请求,server将没有办法及时响应(因为是单线程,server正在读写),将会把这些还没来得及响应的请求加入阻塞队列中。
- ④等到server处理完一个客户端连接的读写操作时,继续回到多路IO复用机制处阻塞,其他的连接如果再发送连接请求过来的话,会继续重复②③流程。
- 优点:
- 单线程/单进程解决了可以同时监听多个客户端读写状态的模型,不需要1:1与客户端的线程数量关系。而是1:n;
- 多路IO复用阻塞(使用epoll),不需要一直轮询,所以不会浪费CPU资源,CPU利用效率较高。
- 缺点:
- 因为是单线程/单线程,虽然可以监听多个客户端的读写状态,但是在同一时间内,只能处理一个客户端的读写操作,实际上读写的业务并发为1;
- 多客户端访问服务器,但是业务为串行执行,大量请求会有排队延迟现象。如图中⑤所示,当client3占据主线程流程时, client1和client2流程会卡在IO复用,等待下次监听触发事件。
- 该模型编写代码较简单,虽然有延迟现象,但是毕竟多路IO复用机制阻塞,不会占用CPU资源,如果并发请求量比较小,客户端数量可数,允许信息有一点点延迟,可以使用该模型。
- 比如Redis就是采用该单线程多路IO复用模型设计的,因为Redis的性能瓶颈通常不在CPU上,而是其他因素(如磁盘I/O和网络请求等)限制了系统的性能。
- Redis 是一种内存数据库,其单线程模型是其高并发支持的关键因素之一。Redis内幕揭秘:探索Redis基础知识及应用场景,挖掘出高效的缓存技术 - 知乎 (zhihu.com)
16.5 模型四:单线程多路IO复用 + 多线程业务工作池 (同步IO模拟proactor模式)
- 实际上就是:同步IO模拟proactor模式+半同步/半反应堆模式。
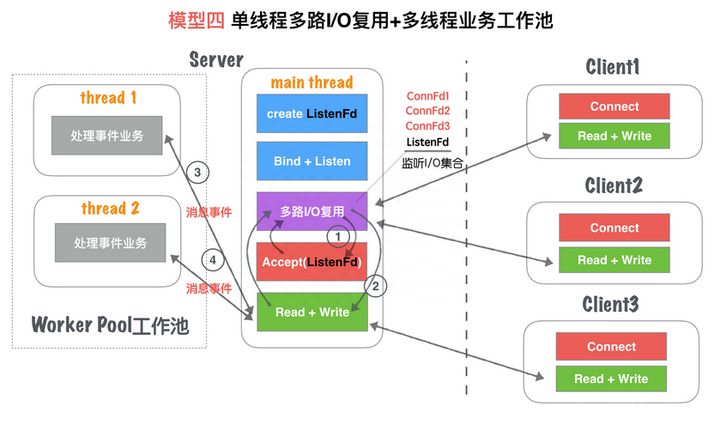
- ①主线程main thread 创建 lfd之后,采用多路IO复用机制(如select和epoll)进行IO状态阻塞监听。有client1客户端 connect 请求, IO复用机制检测到lfd触发事件读写,则进行accept建立连接,并将新生成的cfd1加入到监听IO集合中。
- ②当cfd1有可读消息,触发读事件,并且进行读写消息。
- ③主线程按照固定的协议读取消息,并且交给worker pool工作线程池,工作线程池在server启动之前就已经开启固定数量的线程,里面的线程只处理消息业务,不进行套接字读写操作。
- ④工作池处理完业务,触发cfd1写事件,将要回发客户端的数据消息通过主线程写回给客户端。
- 优点:
- 相比于模型三而言,设计了一个worker pool业务线程池,将业务处理部分从主线程抽离出来,为主线程分担了业务处理的工作,减少了因为单线程的串行执行业务机制的多客户端对server的大量请求造成排队延迟的时间。就是说主线程读完数据之后马上就丢给了线程池去处理,然后马上回到多路IO复用的阻塞监听状态。缩短了其他客户端的等待连接时间。
- 由于是单线程,实际上读写的业务并发还是为1,但是业务流程的并发数为worker pool线程池里的线程数量,加快了业务处理并行效率。
- 缺点:
- 读写依然是主线程单独处理,最高的读写并行通道依然是1,导致当前服务器的并发性能依然没有提升,只是响应任务的速度快了。每个客户端的排队时间短了,但因为还是只有一个通道进行读写操作,因此总体的完成度跟模型三是差不多的。
- 虽然多个worker线程池处理业务,但是最后返回给客户端依旧也需要排队。因为出口还是只有read+write 这1个通道。因此业务是可以并行了,但是总体的效率是不变的。
- 业务处理前后的读写操作需要排队。
- 可以看到,模型四是同步IO模拟proactor模式,如果客户端数量不多,并且各个客户端的逻辑业务有并行需求的话适合用该模型。
16.6 模型五:单线程多路IO复用连接 + 多线程多路IO复用处理(线程池)(高效的半同步/半异步模式)
- 实际上就是之前讲的相对高效的半同步/半异步模式。
- 这种模型在Linux的服务器开发中最常用。

- ①server在启动监听之前,需要创建固定数量N的线程,作为thread pool线程池。
- ②主线程创建lfd之后,采用多路IO复用机制(如select、epoll)进行IO状态阻塞监听。有client1客户端 connect请求,IO复用机制检测到lfd触发读事件,则进行accept建立连接,并且将新创建的cfd1分发给thread pool线程池中的某个线程监听。
- ③thread pool中的每个thread都启动多路IO复用机制,用来监听主线程建立成功并且分发下来的socket套接字(cfd)。
- ④如图,thread1监听cfd1、cfd2,thread2监听cfd3,thread3监听cfd4。线程池里的每一个线程相当于它们所监听的客户端所对应的服务端。当对应的cfd有读写事件时,对应的线程池里的thread会处理相应的读写业务。
- 优点:
- 将主线程的单流程读写,分散到线程池完成,这样增加了同一时刻的读写并行通道,并行通道数量等于线程池的thread数量N;
- server同时监听cfd套接字数量几乎成倍增大,之前的全部监控数量取决于主线程的多路IO复用机制的最大限制(select默认1024,epoll默认与内存有关,约3~6w不等)。所以该模型的理论单点server最高的响应并发数量为N*(3 ~ 6w)。(N为线程池thread的数量,建议与cpu核心数一致)
- 如果良好的线程池数量和CPU核心数适配,那么可以尝试CPU核心与thread绑定,从而降低cpu的切换频率,提高了每个thread处理业务的效率。
- 缺点:
- 虽然监听的并发数量提升,但是最高读写并行通道依然为N,而且多个身处被同一个thread所监听的客户端也会出现延迟读写现象。
- 可以满足实际开发,当前主流的线程池框架就是模型五,其中有 Netty (一个用于快速开发高性能网络应用程序的事件驱动框架)和 Memcache (一个开源的分布式内存对象缓存系统)。
16.7 模型六:单线程多路IO复用 + 多进程多路IO复用(进程池)(高效的半同步/半异步模式)
- 模型五的多进程版本。
- 与模型五线程池版没有太大的差异。需要在服务器启动之前先创建一些守护进程在后台运行。
- 与模型五存在的不同之处:
- ①进程间资源不共享,而线程是共享资源的。进程和线程的内存布局不同导致主进程不再进行accept操作,而是将accept过程分散到每一个子进程中。
- ②主进程只是监听listenFd状态,一旦触发读事件或者有新连接请求,通过IPC进程间通信(信号量、共享内存、消息队列、管道等方式)让所有的子进程们进行竞争,抢到lfd读事件资源的子进程会进行accpet操作,监听他们自己所创建出来的套接字cfd。(自己创建的cfd,由自己监听cfd的读写事件)
- 优点:
- 由于进程间的资源独立,尽管是父子进程,也是读时共享,写时复制。因此多进程模型安全稳定性较强,各自进程互不干扰。Nginx就是使用进程池的框架实现的。Nginx 的架构包括一个主进程(Master)和多个工作进程(Worker)。主进程负责启动、管理 Worker 进程以及处理一些全局的任务。每个 Worker 进程负责处理实际的客户端请求,包括接受连接、处理请求、发送响应等。Nginx 使用了事件驱动的模型,这意味着它不会为每个连接创建一个新的线程或者进程,而是使用非阻塞的 I/O 操作和事件循环来处理大量并发连接。
- 缺点:
- 多进程内存资源空间占用得稍微大一些
第 17 章 HTTP 协议演进与各版本特性
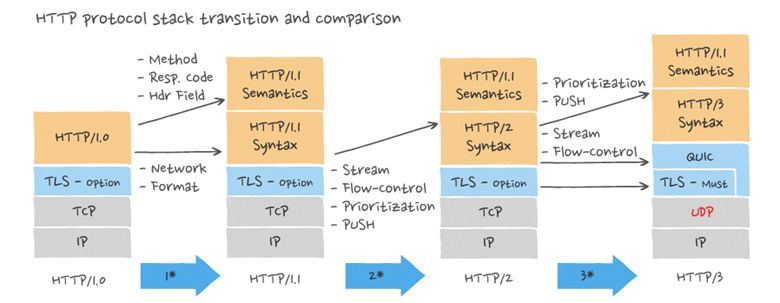
17.1 请求报文
- HTTP 请求报文(request)由 3 大部分组成:
- 请求行(必须在 HTTP 请求报文的第一行)
- 请求头(从第二行开始,到第一个空行结束。请求头和请求体之间存在一个空行)
- 请求体(非必须)


- 请求方法的作用在于可以指定请求的资源按照期望产生某种行为,即使用方法给服务器下命令。包括(HTTP 1.1):GET、POST、PUT、HEAD、DELETE、OPTIONS、CONNECT、TRACE、PATCH。当然,我们在开发中最常见也最常使用的就只有前面2个。

17.2 响应报文
- HTTP 的响应报文也由三部分组成:
- 响应行(必须在 HTTP 响应报文的第一行)
- 响应头(从第二行开始,到第一个空行结束。响应头和响应体之间存在一个空行)
- 响应体

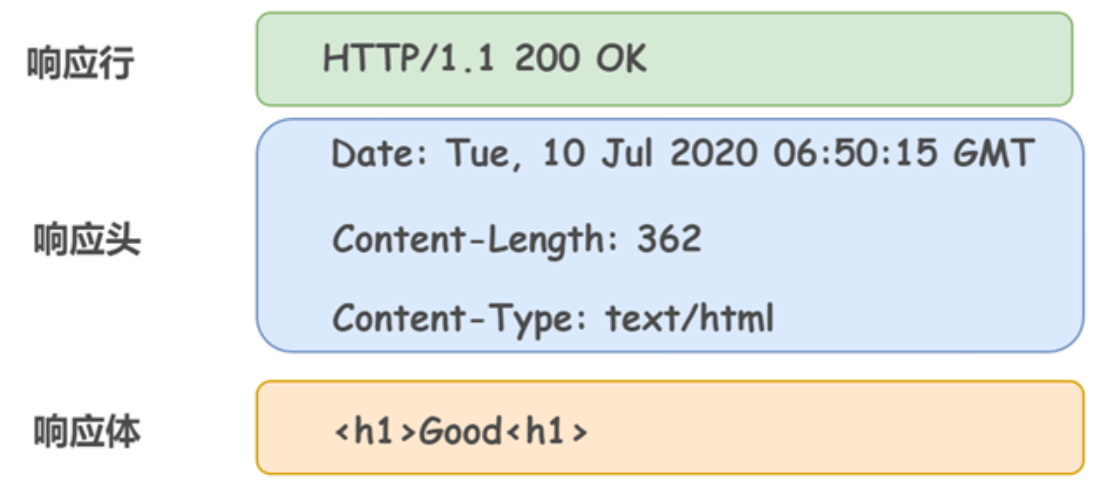
- 在响应行开头的 HTTP 1.1 表示服务器对应的 HTTP 版本。紧随的 200 OK 表示请求的处理结果的“状态码”和“原因短语”。
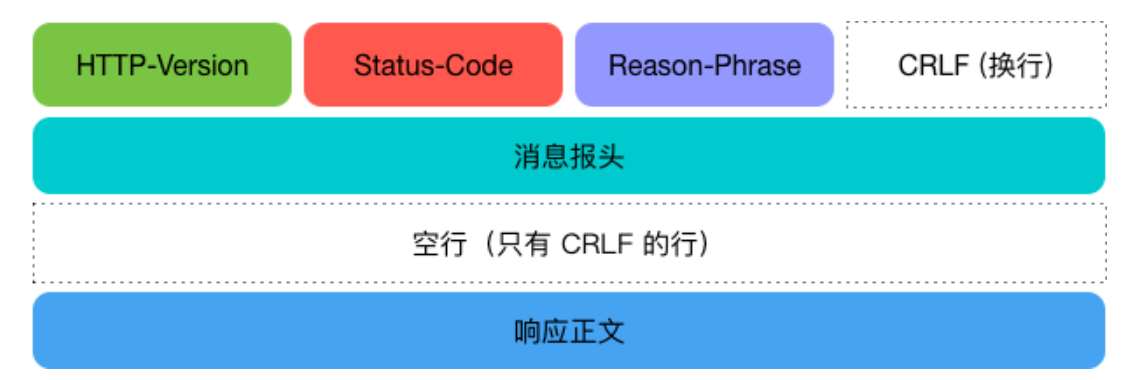
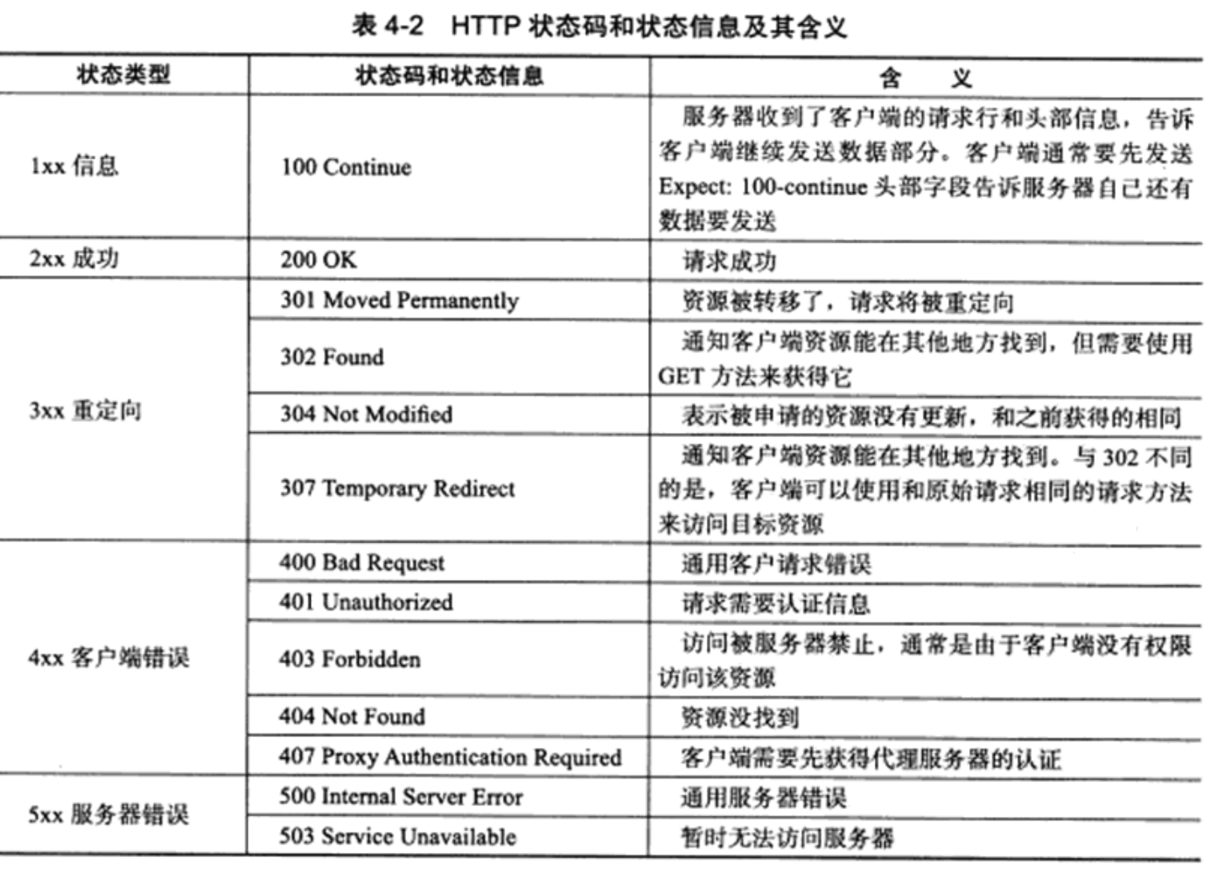
17.3 无状态的 HTTP
- HTTP 协议是无状态协议。 也就是说他不对之前发生过的请求和响应的状态进行管理,即无法根据之前的状态进行本次的请求处理。这样就会带来一个明显的问题,如果 HTTP 无法记住用户登录的状态,那岂不是每次页面的跳转都会导致用户需要再次重新登录?
- 当然,不可否认,无状态的优点也很显著,由于不必保存状态,自然就减少了服务器的 CPU 及内存资源的消耗。另一方面,正式由于 HTTP 简单,所以才会被如此广泛应用。
- 在保留无状态协议这个特征的同时,又要解决无状态导致的问题。方案有很多种,其中比较简单的方式就是使用 Cookie 技术。
- Cookie 通过在请求和响应报文中写入 Cookie 信息来控制客户端的状态。具体来说,Cookie 会根据从服务器端发送的响应报文中的一个叫作 Set-Cookie 的首部字段信息,通知客户端保存 Cookie。当下次客户端再往服务器发送请求时,客户端会自动在请求报文中加入 Cookie 值发送出去。服务器端收到客户端发来的 Cookie 后,会去检查究竟是哪一个客户端发来的连接请求,然后对比服务器上的记录,最后得到之前的状态信息。

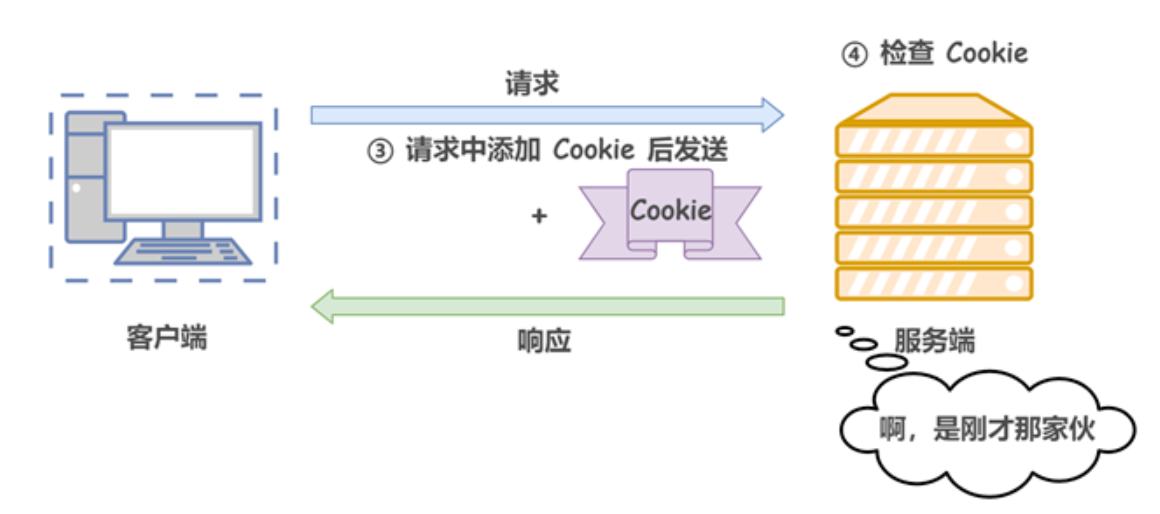
17.4 HTTP 和 HTTPS
- HTTPS 协议可以理解为 协议的升级,就是在 HTTP 的基础上增加了数据加密。在数据进行传输之前,对数据进行加密,然后再发送到服务器。这样,就算数据被第三者所截获,但是由于数据是加密的,所以你的个人信息仍然是安全的。这就是 HTTP 和 HTTPS 的最大区别。
- 互联网的通信安全,建立在 SSL/TLS 协议之上,SSL“安全套接层”协议,TLS“安全传输层”协议,都属于是加密协议,在其网络数据传输中起到保护隐私和数据的完整性。保证该网络传输的信息不会被未经授权的元素拦截或修改,从而确保只有合法的发送者和接收者才能完全访问并传输信息。
- SSL :(Secure Socket Layer,安全套接字层),位于可靠的面向连接的网络层协议和应用层协议之间的一种协议层。SSL 通过互相认证、使用数字签名确保完整性、使用加密确保私密性,以实现客户端和服务器之间的安全通讯。 该协议由两层组成:SSL 记录协议和 SSL 握手协议。
- TLS :(Transport Layer Security,传输层安全协议),用于两个应用程序之间提供保密性和数据完整性。 该协议由两层组成:TLS 记录协议和 TLS 握手协议。
HTTPS URL以https://开头,默认使用端口443,而HTTP URL以http://开头,默认使用端口80。HTTP未经加密,因此容易受到中间人攻击和窃听攻击,攻击者可以使攻击者获得对网站帐户和敏感信息的访问权,并可以修改网页以注入恶意软件或广告。
17.5 HTTP/0.9
- 最初版本的 HTTP 协议并没有版本号,后来它的版本号被定位在 0.9 以区分以后的版本。已过时的 HTTP/0.9 是 HTTP 协议的第一个版本,诞生于 1989 年。它的组成极其简单,只允许客户端发送 GET 这一种请求,而且不支持请求头。由于没有协议头,所以 HTTP/0.9 只能支持一种内容——纯文本。服务器只能回应 HTML 格式的字符串,不能回应别的格式。服务器发送完毕后,就会关闭 TCP 连接。HTTP/0.9 具有典型的无状态性,每个访问都独立处理,处理完成后就会断开连接。如果请求的页面不存在,也不会返回任何错误码。
17.6 HTTP/1.0
- 1996 年 11 月,一份新文档(RFC 1945)被发表出来,文档 RFC 1945 定义了 HTTP/1.0,但它是狭义的,并不是官方标准。HTTP 1.0 是 HTTP 协议的第二个版本,至今仍被广泛采用。它在 HTTP/0.9 的基础上做了大量的扩充和改进,包括:
- 1、支持 GET POST 和 HEAD
- 2、支持传入多种数据格式(视频、图片、二进制等)
- 3、新增状态码、缓存等
- 但1.0的缺点也很明显,即采用的是短连接(非持久连接)。
- 当客户端浏览器访问的某个 HTML 或其他类型的 Web 页中包含有其他的 Web 资源(如 JavaScript 文件、图像文件、CSS 文件等),每遇到这样一个 Web 资源,浏览器就会重新建立一个 HTTP 会话。这种方式称为短连接(也称非持久连接)。也就是说每次 HTTP 请求都要重新建立一次连接 。 由于 HTTP 是基于 TCP/IP 协议的,所以连接的每一次建立或者断开都需要 TCP 三次握手或者 TCP 四次挥手的开销 。
- 显然,这种方式存在巨大的弊端。 比如访问一个包含多张图片的 HTML 页面,每请求一张图片资源就会造成无谓的 TCP 连接的建立和断开,大大增加了通信量的开销。
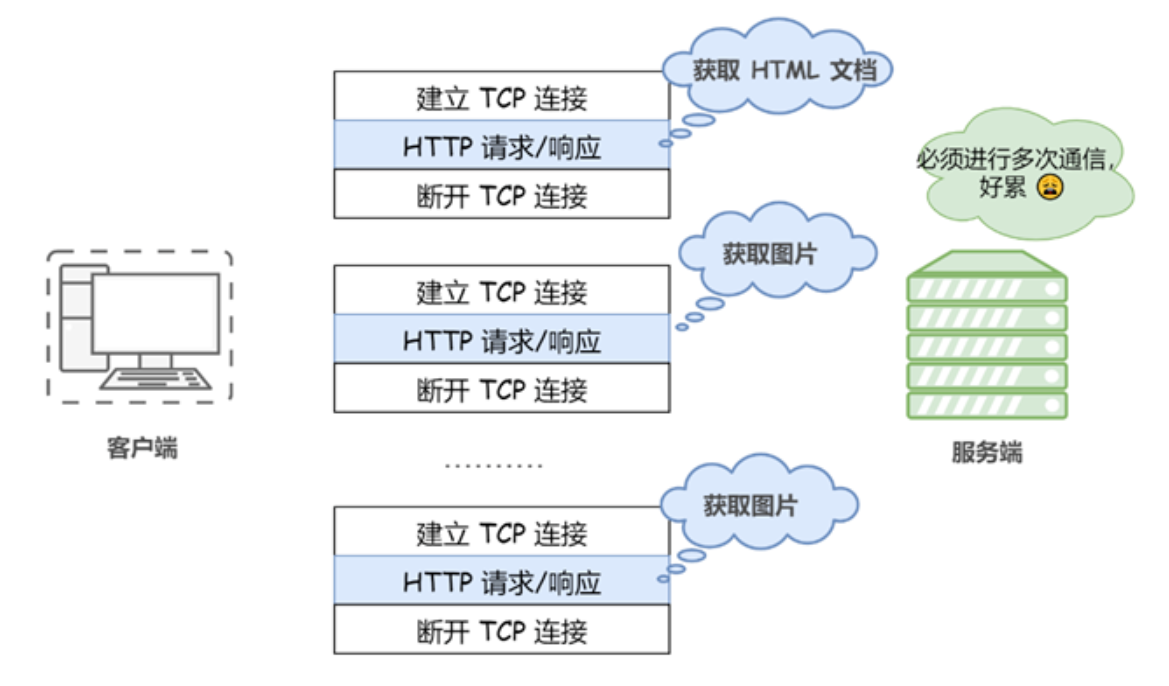
17.7 HTTP/1.1
-
HTTP协议的第三个版本是HTTP 1.1,HTTP 1.1 是在 1.0 发布之后的半年就推出了,完善了 1.0 版本。是目前使用最广泛的协议版本 。HTTP 1.1是目前主流的HTTP协议版本。
-
优点: 1、持久性连接,即 TCP 连接不关闭,可以被多个请求复用 2、管道(流水线)机制(同一个 TCP 连接,客户端可以同时发送多个请求) 3、新增了一些请求方法: PUT DELETE OPTIONS
-
缺点: 1、会造成队头阻塞问题(虽然同一个TCP 可以同时发送多个请求,但是服务端还是会一个一个请求进行处理进行返回,如果上一个返回延迟,会阻塞后面的流程)
-
(1)持久性连接
- 从 HTTP/1.1起,默认使用长连接也称持久连接 keep-alive。 使用长连接的 HTTP 协议,会在响应头加入这行代码:Connection:keep-alive。客户端如果想要关闭连接,可以在最后一个请求的请求头中,加上Connection:close来安全关闭这个连接。
- 在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输 HTTP 数据的 TCP 连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive 不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如 Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。
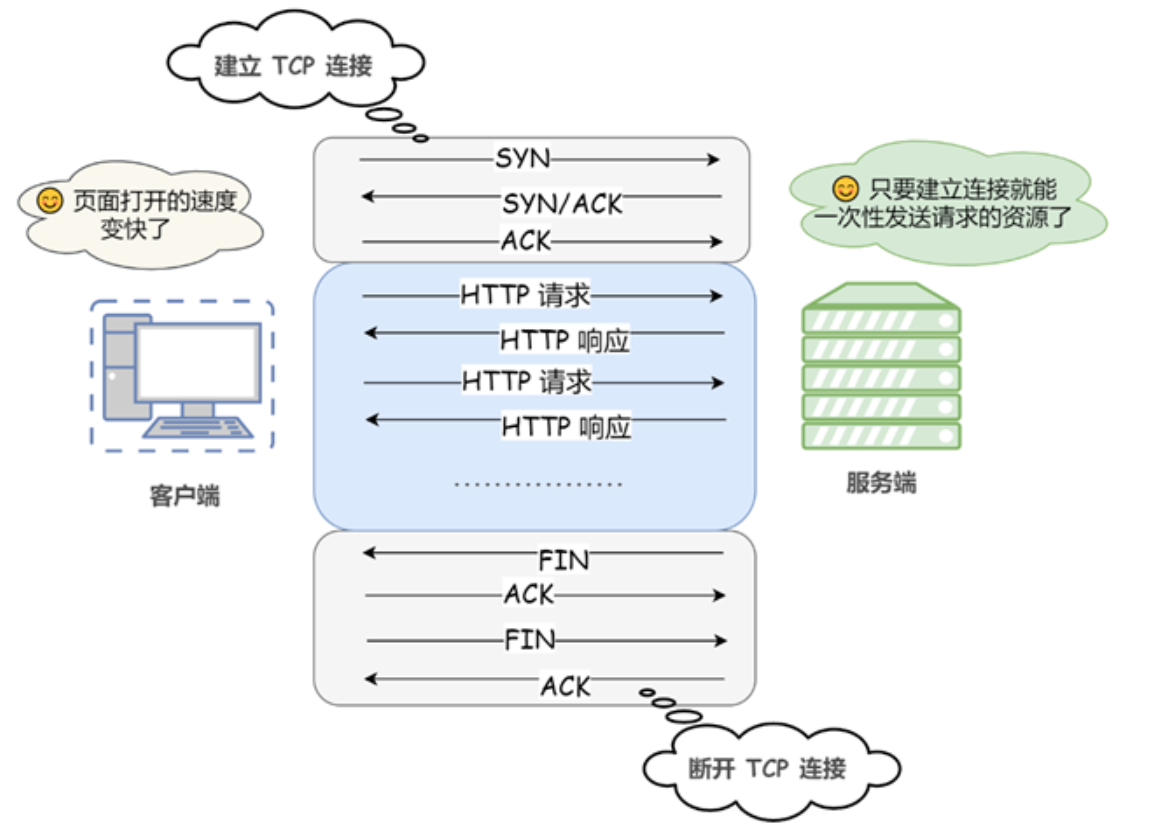
-
(2)流水线(管线化)
- 默认情况下, HTTP 请求是按顺序发出的,下一个请求只有在当前请求收到响应之后才会被发出。由于受到网络延迟和带宽的限制,在下一个请求被发送到服务器之前,可能需要等待很长时间。
- 持久连接使得多数请求以“流水线”(管线化 pipeline)方式发送成为可能,即在同一条持久连接上连续发出请求,而不用等待响应返回后再发送,这样就可以做到同时并行发送多个请求,而不需要一个接一个地等待响应了。
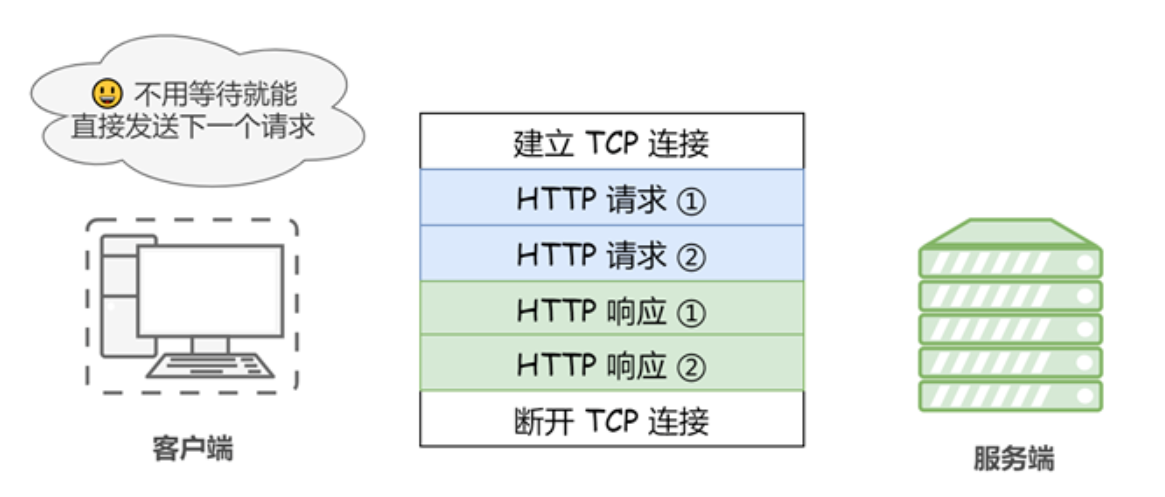
17.8 HTTP/2.0
- HTTP/2.0是HTTP协议自1999年HTTP/1.1发布后的首个更新,主要基于SPDY协议,于2015年2月17日被批准。主要特点:
- HTTP/2采用二进制格式而非文本格式
- HTTP/2是完全多路复用的,而非有序并阻塞的——只需一个连接即可实现并行
- HTTP/2使用报头压缩,降低了开销
- HTTP/2让服务器可以将响应主动“推送”到客户端缓存中
- HTTP/2相比HTTP/1.1的修改并不会破坏现有程序的工作,但是新的程序可以借由新特性得到更好的速度。
- HTTP/2保留了HTTP/1.1的大部分语义,例如请求方法、状态码乃至URI和绝大多数HTTP头部字段一致。而 HTTP/2 采用了新的方法来编码、传输客户端——服务器间的数据。
- HTTP2.0虽然性能已经不错了,但还是有很多不足:
- 建立连接时间长(本质上是TCP的问题)
- 队头阻塞问题
- 移动互联网领域表现不佳(弱网环境)
17.9 HTTP/3.0
- HTTP 3.0 又称为HTTP Over QUIC,其弃用TCP协议,改为使用基于UDP协议的QUIC协议来实现。
- HTTP 3.0 于 2022 年 6 月 6 日正式发布,IETF 把 HTTP 3.0 标准制定在了 RFC 9114 中,HTTP 3.0 其实相较于 HTTP 2.0 要比 HTTP 2.0 相较于 HTTP 1.1 的变化来说小很多,最大的提升就在于效率,替换 TCP 协议为 UDP 协议,HTTP 3.0 具有更低的延迟,它的效率甚至要比 HTTP 1.1 快 3 倍以上。
- QUIC其实是Quick UDP Internet Connections的缩写,直译为快速UDP互联网连接。
- 维基百科对于QUIC协议的一些介绍:QUIC协议最初由Google的Jim Roskind设计,实施并于2012年部署,在2013年随着实验的扩大而公开宣布,并向IETF进行了描述。QUIC提高了当前正在使用TCP的面向连接的Web应用程序的性能。它在两个端点之间使用用户数据报协议(UDP)建立多个复用连接来实现此目的。QUIC的次要目标包括减少连接和传输延迟,在每个方向进行带宽估计以避免拥塞。它还将拥塞控制算法移动到用户空间,而不是内核空间,此外使用前向纠错(FEC)进行扩展,以在出现错误时进一步提高性能。
- 这里说明一下,http2和http3这2个协议版本都是由谷歌主导的,并且第一个在chrome浏览器率先实现的。
- HTTP协议演进与各版本特性 (uml.org.cn)
17.10 GET 和 POST 的区别
-
GET方法 使用GET方法时,查询字符串(键值对)被附加在URL地址后面一起发送到服务器:
/test/demo_form.jsp?name1=value1&name2=value2
特点:
➤ GET请求能够被缓存
➤ GET请求会保存在浏览器的浏览记录中
➤ 以GET请求的URL能够保存为浏览器书签
➤ GET请求有长度限制
➤ GET请求主要用以获取数据
-
POST方法 使用POST方法时,查询字符串在POST信息中单独存在,和HTTP请求一起发送到服务器:
POST/test/demo_form.jsp HTTP/1.1
Host:w3schools.com
name1=value1&name2=value2
特点:
➤ POST请求不能被缓存下来
➤ POST请求不会保存在浏览器浏览记录中
➤ 以POST请求的URL无法保存为浏览器书签
➤ POST请求没有长度限制
-
GET POST 外观上 在地址上看到传递的参数和值 地址栏上看不到数据 提交数据大小 提交少量数据,不同的浏览器最大值不一样,IE是255个字符 提交大量数据,可以通过更改php,ini配置文件提交数据的最大值 安全性 低 高 提交原理 提交的数据和数据之间是独立的 将提交的数据变成XML格式提交 灵活性 很灵活,只要有页面的跳转就可以get传递数据 不灵活 TCP数据包 产生一个TCP数据包 产生两个TCP数据包 长度限制 对长度有限制 对数据长度没有要求 收藏书签 可以被收藏为书签 不能被收藏为书签 回退 在浏览器回退时是无害的 会再次提交请求 请求缓存 可被缓存 不被缓存 获取数据 一般用去请求获取数据 一般作为发送数据到后台时使用 Bookmark 产生的URL地址可以被Bookmark 不可以 编码 请求只能进行url编码 支持多种编码方式 参数数据类型 只接受ASCII字符 没有限制 请求设置 请求会被浏览器主动cache 不会,除非手动设置 请求数据是否保留 保留在浏览器历史记录中 不会保留在浏览器历史记录中 请求方式 比较常见的方式是通过url地址栏请求 最常见是通过form表单发送数据请求 请求数据 是从指定资源请求数据,请求参数在URL中 向指定资源提交要被处理的数据,请求参数封装在HTTP请求数据中 参数传递 参数通过URL传递 POST放在Request body中 幂等性 GET 请求是幂等的,即多次执行相同的请求,对资源的状态没有影响。 POST 请求一般不是幂等的,即多次执行相同的请求可能会导致不同的结果。 -
注意点:
-
(1)query参数是URL的一部分,而GET、POST等是请求方法的一种,不管是哪种请求方法,都必须有URL,而URL的query是可选的,可有可无。get是querystring(仅支持url编码),post是放在body(支持多种编码)。
-
(2)其实GET方法提交的url参数数据大小没有限制,在http协议中没有对url长度进行限制(不仅仅是querystring的长度),这个限制是特定的浏览器及服务器对他的限制。所以我们说GET对URL长度有限制也没大问题。
-
(3)关于:GET产生一个TCP数据包;POST产生两个TCP数据包。
- 具体来说:对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
- 也就是说,GET只需要跑一趟就送到了,而POST得跑两趟,第一趟,先去和服务器打个招呼“嗨,我等下要送一东西来,你们打开门迎接我”,然后再回头把东西送过去。
- 这个流程的目的是在浏览器发送大量数据之前,先征询服务器是否接受这些数据。如果服务器不支持或不接受这个机制,浏览器会在超时时间内发送数据,而不等待 100 Continue 状态。
- 这个机制并非所有情况下都会被使用。服务器可以选择不支持或不理会 Expect: 100-continue 请求头,这时浏览器会直接发送请求体。而且,并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次。
第 18 章 WebServer 项目实践
18.1 整体流程
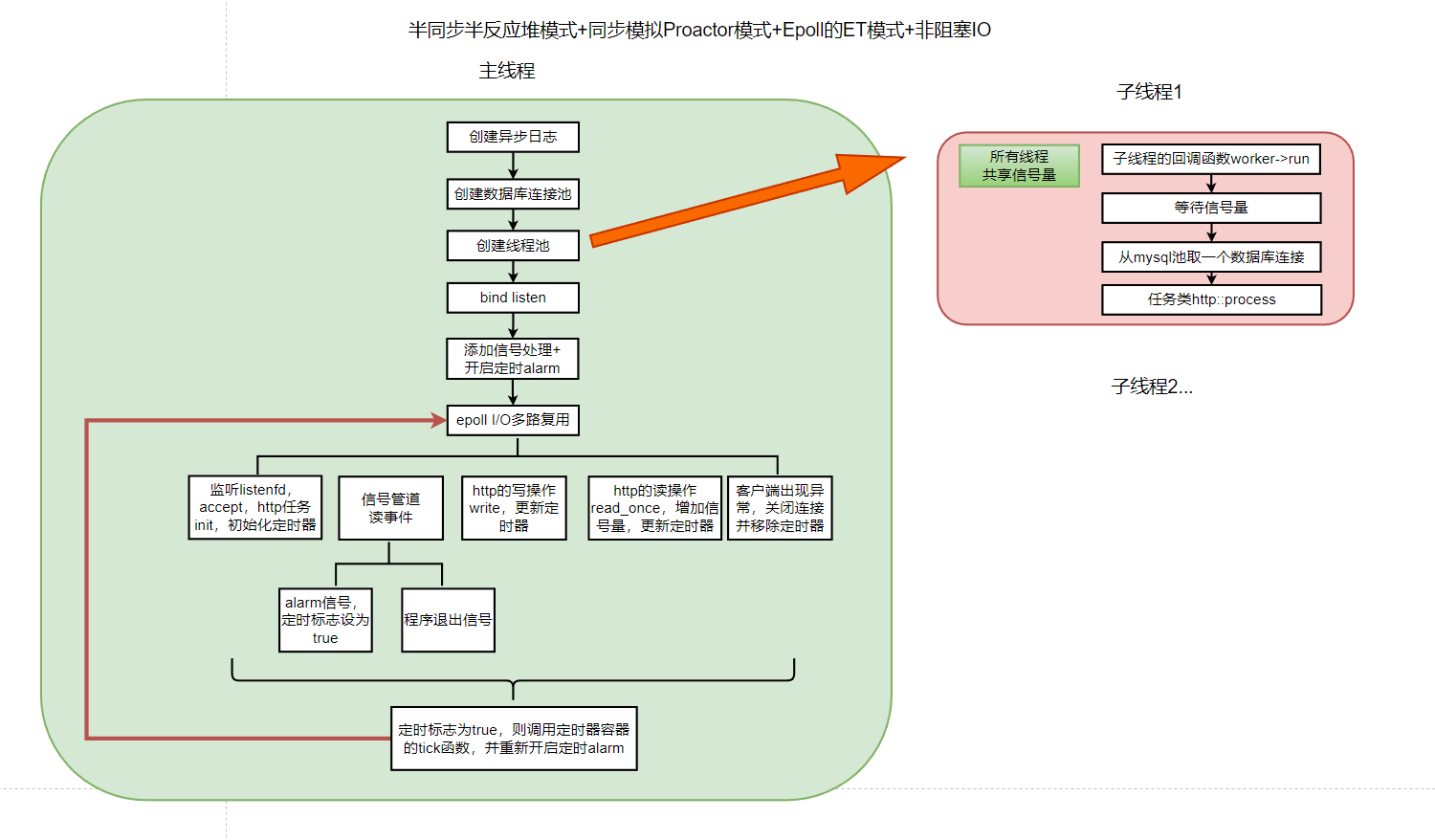
18.2 HTTP 请求与响应
- 流程如下
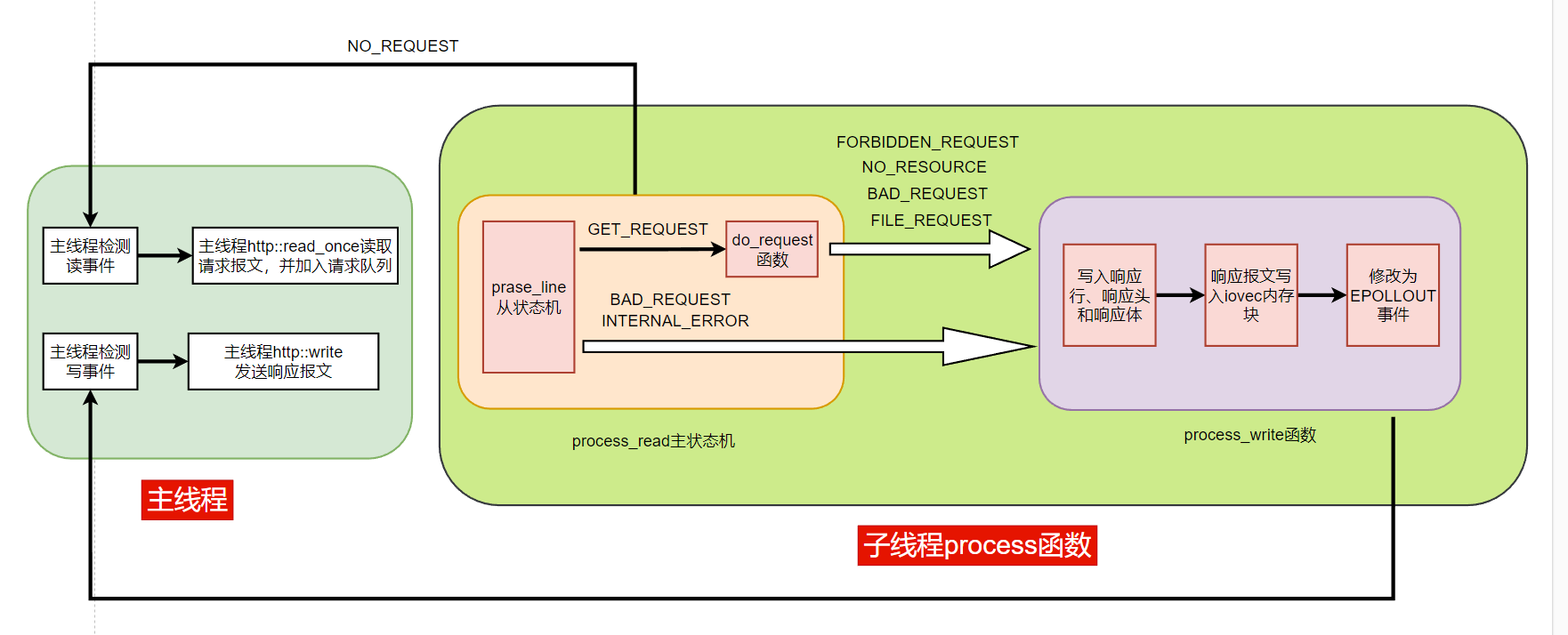
- 其中主从状态机,用于分析得到的HTTP报文。
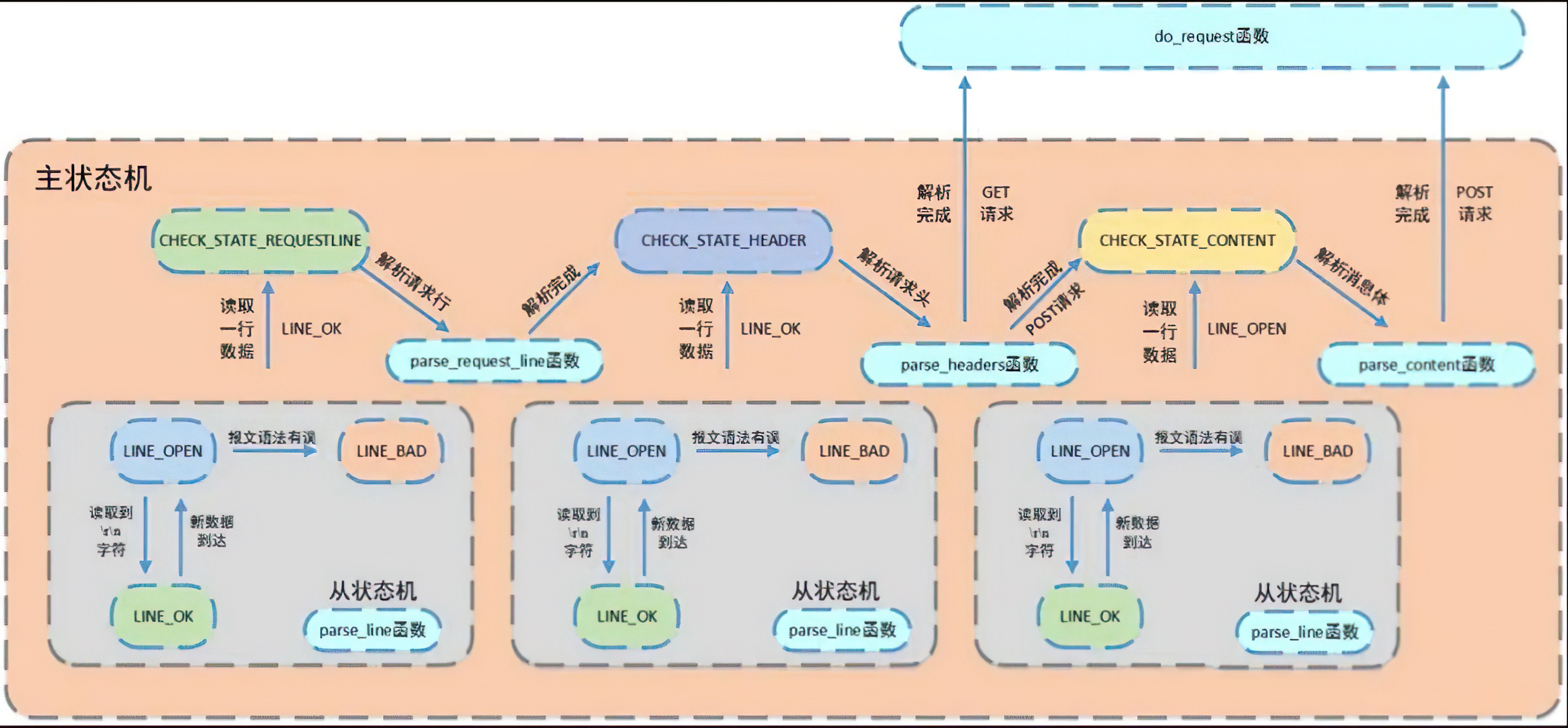
18.3 数据库连接池
(1)单例模式
-
(1)使用局部静态变量实现单例模式
-
静态局部变量有以下特点:
- 该变量在全局数据区分配内存;
- 静态局部变量在程序执行到该对象的声明处时被首次初始化,即以后的函数调用不再进行初始化;
- 静态局部变量一般在声明处初始化,如果没有显式初始化,会被程序自动初始化为 0;
- 它始终驻留在全局数据区,直到程序运行结束。但其作用域为局部作用域,当定义它的函数或语句块结束时,其作用域随之结束。
- 然而,尽管局部静态变量不能在外部直接访问,但是可以通过函数返回值或者指针等方式间接访问到这些变量。例如,如果一个函数返回一个指向局部静态变量的指针或引用,那么在函数外部就可以通过这个指针或引用来访问或修改这个局部静态变量
-
示例代码如下
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33#include <iostream> using namespace std; class Singleton { public: // 获取单例对象的函数 static Singleton *getInstance() { // 局部静态特性的对象 static Singleton instance; return &instance; } // 删除复制构造函数和赋值操作符 Singleton(const Singleton &) = delete; Singleton &operator=(const Singleton &) = delete; // 添加一个方法来测试 void testFunction() { cout << "Singleton instance: " << this << endl; } private: // 将构造函数和析构函数设为私有 Singleton() {} ~Singleton() {} }; int main() { // 获取单例对象并调用测试函数,这三个类的地址都一样,说明是单例 Singleton::getInstance()->testFunction(); Singleton::getInstance()->testFunction(); Singleton::getInstance()->testFunction(); return 0; }
(2)RAII 机制
-
(2)使用RAII机制实现数据库连接池的取连接和回收连接操作,避免忘记回收。
-
1 2 3 4 5 6 7 8 9 10 11 12// 以下是销毁的RAII机制 connectionRAII::connectionRAII(MYSQL **SQL, connection_pool *connPool) { *SQL = connPool->GetConnection(); // 保存变量 conRAII = *SQL; poolRAII = connPool; } connectionRAII::~connectionRAII() { // 析构调用数据库连接回收函数 poolRAII->ReleaseConnection(conRAII); }
18.4 日志系统
(1)概述
-
日志,由服务器自动创建,并记录运行状态,错误信息,访问数据的文件。 -
同步日志,日志写入函数与工作线程串行执行,由于涉及到I/O操作,当单条日志比较大的时候,同步模式会阻塞整个处理流程,服务器所能处理的并发能力将有所下降,尤其是在峰值的时候,写日志可能成为系统的瓶颈。 -
异步日志,当需要写日志消息时,只是将日志消息进行存储,当积累到一定量时或者达到时间间隔后,由后台线程自动将存储的所有日志进行数据;-
常见的实现思路就是,主线程写日志到队列,队列本身使用条件变量、或者管道、eventfd等通知机制,当有数据入队列就通知消费者线程去消费日志。
-
生产者-消费者模型,并发编程中的经典模型。以多线程为例,为了实现线程间数据同步,生产者线程与消费者线程共享一个缓冲区,其中生产者线程往缓冲区中push消息,消费者线程从缓冲区中pop消息。 -
阻塞队列,将生产者-消费者模型进行封装,使用循环数组实现队列,作为两者共享的缓冲区。 -
单例模式,最简单也是被问到最多的设计模式之一,保证一个类只创建一个实例,同时提供全局访问的方法。
-
-
本项目采用异步日志系统。
(2)单例模式
-
在C++中,常见的单例模式的实现方法有以下几种:
-
懒汉式(线程不安全):在第一次使用时初始化,但是多线程环境下可能创建多个实例,因此不推荐使用。
-
加锁的懒汉式(线程安全):使用互斥锁保证在多线程环境下只创建一个实例。可以返回普通指针或智能指针。
-
静态局部变量的懒汉式(C++11线程安全):利用C++11规定的线程安全的静态局部变量特性,推荐使用。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18class Singleton { public: // 获取单例对象的函数 static Singleton& getInstance() { // 局部静态特性的对象 static Singleton instance; return instance; } // 删除复制构造函数和赋值操作符 Singleton(const Singleton&) = delete; Singleton& operator=(const Singleton&) = delete; private: // 将构造函数和析构函数设为私有 Singleton() {} ~Singleton() {} }; -
饿汉式(线程安全):在程序启动时就创建实例,保证线程安全,但可能会浪费内存。
-
使用C++11 std::call_once 实现单例(C++11线程安全):利用C++11的 std::call_once 保证线程安全。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38#include <iostream> #include <memory> #include <mutex> class Singleton { public: static Singleton &GetInstance() { static std::once_flag s_flag; std::call_once(s_flag, [&]() { instance_.reset(new Singleton); }); return *instance_; } ~Singleton() = default; void PrintAddress() const { std::cout << this << std::endl; } private: Singleton() = default; Singleton(const Singleton &) = delete; Singleton &operator=(const Singleton &) = delete; private: static std::unique_ptr<Singleton> instance_; }; std::unique_ptr<Singleton> Singleton::instance_; int main() { Singleton &s1 = Singleton::GetInstance(); s1.PrintAddress(); Singleton &s2 = Singleton::GetInstance(); s2.PrintAddress(); return 0; }
-
(3)生产者消费者模式
-
C++的生产者消费者模式的模板
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38#include <pthread.h> struct msg { struct msg *m_next; /* value...*/ }; struct msg *workq; // 缓冲区 pthread_cond_t qready = PTHREAD_COND_INITIALIZER; pthread_mutex_t qlock = PTHREAD_MUTEX_INITIALIZER; // 消费者 void process_msg() { struct msg *mp; for (;;) { pthread_mutex_lock(&qlock); // 这里需要用while,而不是if while (workq == NULL) { pthread_cond_wait(&qread, &qlock); } mq = workq; workq = mp->m_next; pthread_mutex_unlock(&qlock); /* now process the message mp */ } } // 生产者 void enqueue_msg(struct msg *mp) { pthread_mutex_lock(&qlock); mp->m_next = workq; workq = mp; pthread_mutex_unlock(&qlock); /* 此时另外一个线程在signal之前,执行了process_msg,刚好把mp元素拿走*/ pthread_cond_signal(&qready); /* 此时执行signal, 在pthread_cond_wait等待的线程被唤醒, 但是mp元素已经被另外一个线程拿走,所以,workq还是NULL ,因此需要继续等待*/ }
-
-
以下是一个测试示例。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74#include <pthread.h> #include <queue> #include <iostream> #include <sys/syscall.h> #include <unistd.h> using namespace std; class Buffer { private: std::queue<int> queue_; pthread_mutex_t mutex_; pthread_cond_t cond_; public: Buffer() { pthread_mutex_init(&mutex_, NULL); pthread_cond_init(&cond_, NULL); } ~Buffer() { pthread_mutex_destroy(&mutex_); pthread_cond_destroy(&cond_); } void produce(int value) { pthread_mutex_lock(&mutex_); queue_.push(value); pthread_mutex_unlock(&mutex_); pthread_cond_signal(&cond_); std::cout << "Produced " << value << std::endl; } int consume() { pthread_mutex_lock(&mutex_); while (queue_.empty()) { pthread_cond_wait(&cond_, &mutex_); } int value = queue_.front(); queue_.pop(); pthread_mutex_unlock(&mutex_); std::cout << "Consumed " << value << std::endl; return value; } }; void *producer(void *arg) { Buffer *buffer = (Buffer *)arg; for (int i = 0; i < 3; ++i) { buffer->produce(i); } return NULL; } void *consumer(void *arg) { Buffer *buffer = (Buffer *)arg; buffer->consume(); pid_t tid = gettid(); std::cout << "Thread ID: " << tid << std::endl; return NULL; } int main() { Buffer buffer; pthread_t prodThread, consThread, consThread1; pthread_create(&prodThread, NULL, producer, (void *)&buffer); pthread_create(&consThread, NULL, consumer, (void *)&buffer); pthread_create(&consThread1, NULL, consumer, (void *)&buffer); pthread_join(prodThread, NULL); pthread_join(consThread, NULL); return 0; } -

(4)处理流程
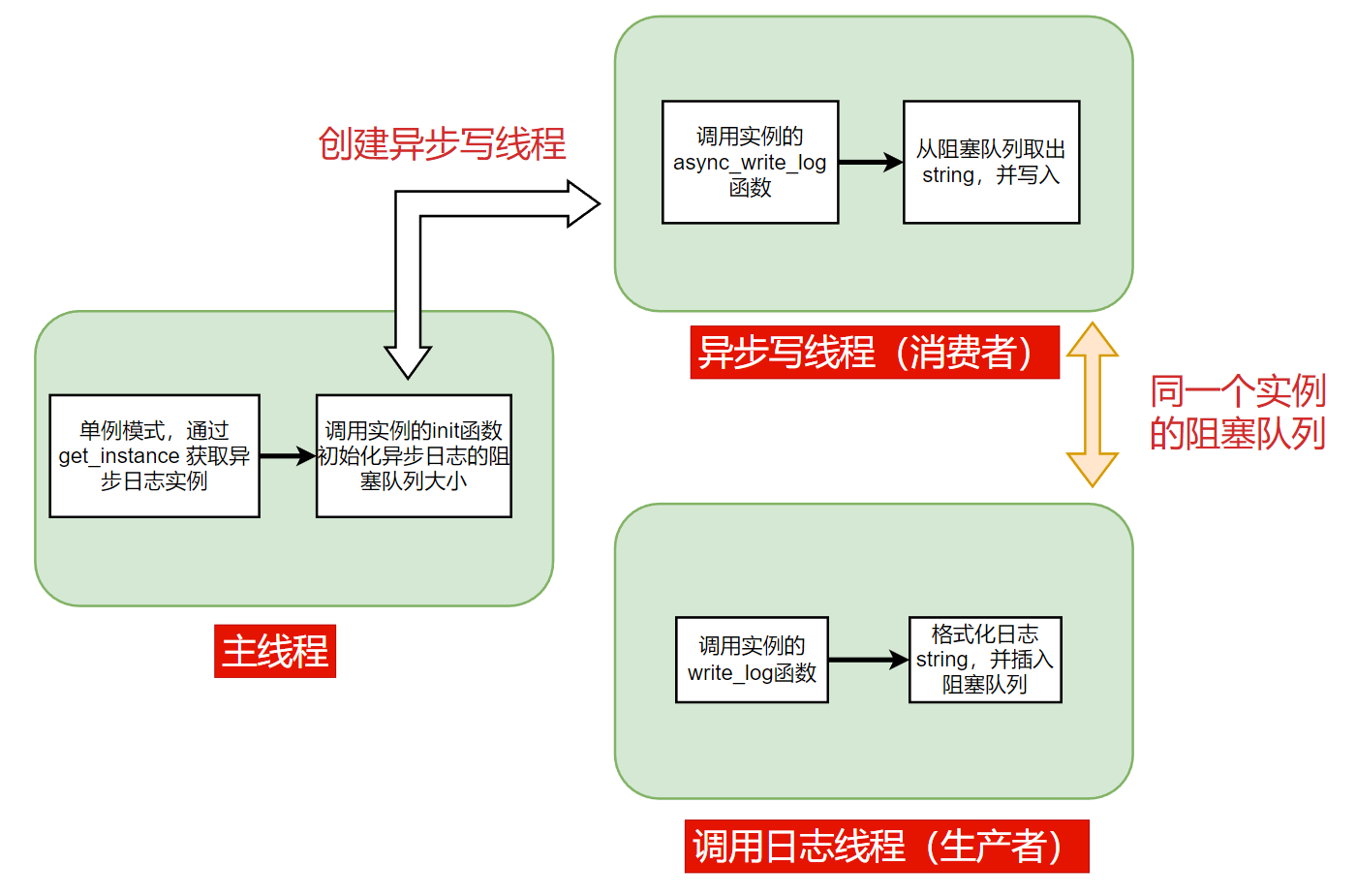
18.5 定时器处理非活动连接
- 注意三个概念的区分
- 定时器:开发者设计的类,主要记录超时的时间;
- 定时器容器:例如升序双向链表、小根堆等,用于管理串联定时器;
- 触发定时信号:利用alarm等系统调用,触发定时信号以陷入中断。
- 一般的定时器处理非活动连接的流程如下