1. Python_Learn
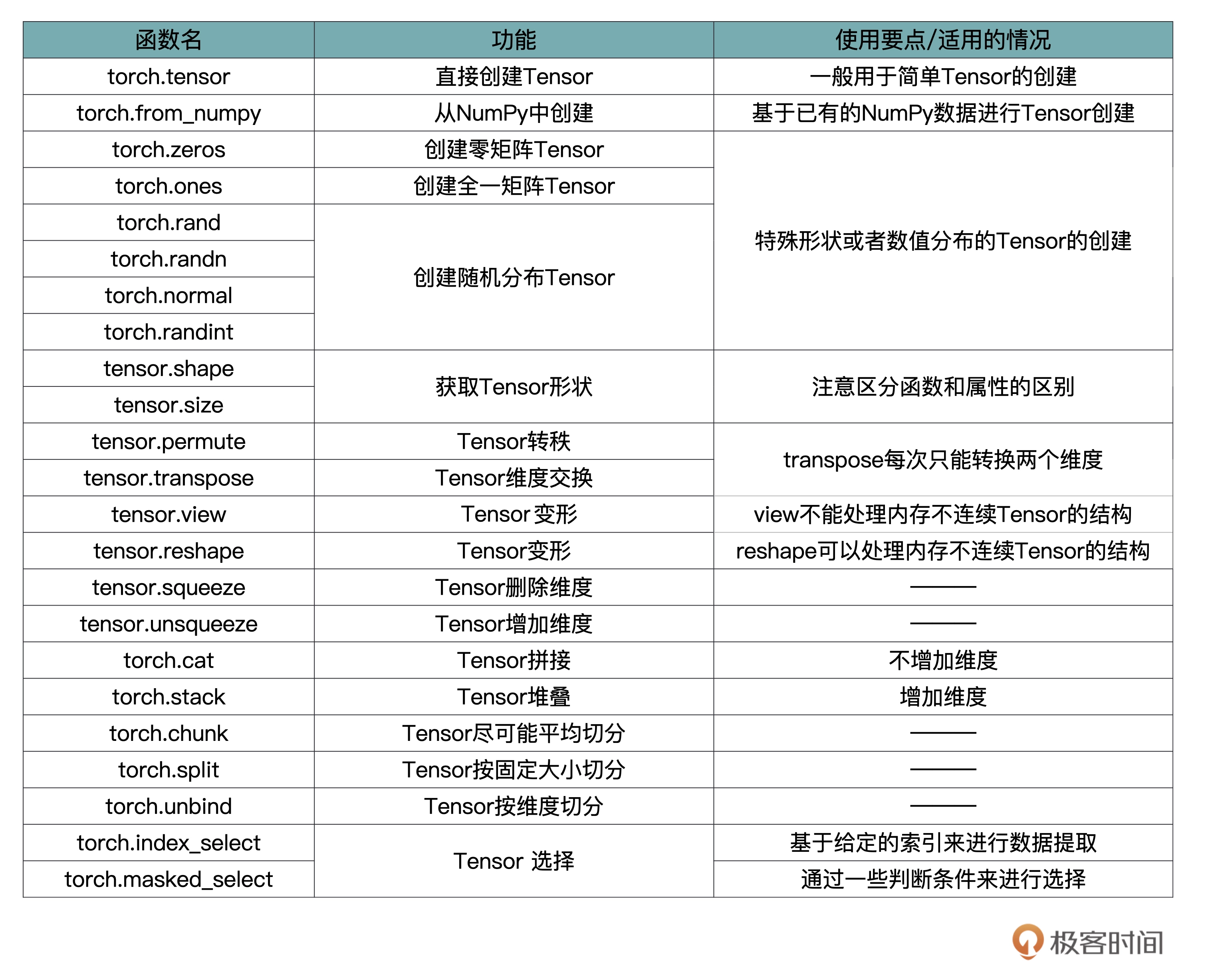
1.1 常见函数(未说明为内置)
-
hasattr() 函数用于判断对象是否包含对应的属性。
-
os.path.join() 函数用于路径拼接文件路径,可以传入多个路径。如果不存在以‘’/’开始的参数,则函数会自动加上
1 2 3>>> import os >>> print(os.path.join('path','abc','yyy')) path\abc\yyy -
tqdm模块是python进度条库, 主要分为两种运行模式。需要安装tqdm包。
1.2 Pytorch_Learn
-
self参数——关于
torch.nn -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25import torch import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() # 输入图像channel:1;输出channel:6;5x5卷积核 self.conv1 = nn.Conv2d(1, 6, 5) self.conv2 = nn.Conv2d(6, 16, 5) # an affine operation: y = Wx + b self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): # 2x2 Max pooling x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # 如果是方阵,则可以只使用一个数字进行定义 x = F.max_pool2d(F.relu(self.conv2(x)), 2) x = x.view(-1, self.num_flat_features(x)) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x -
我们在定义自已的网络的时候,需要继承nn.Module类,并重新实现构造函数__init__构造函数和forward这两个方法。但有一些注意技巧:
(1)一般把网络中具有可学习参数的层(如全连接层、卷积层等)放在构造函数__init__()中,当然我也可以把不具有参数的层也放在里面;
(2)一般把不具有可学习参数的层(如ReLU、dropout、BatchNormanation层)可放在构造函数中,也可不放在构造函数中,如果不放在构造函数__init__里面,则在forward方法里面可以使用nn.functional来代替。 (3)forward方法是必须要重写的,它是实现模型的功能,实现各个层之间的连接关系的核心。
-
卸载pytorch
-
1 2 3 4 5 6# 使用conda卸载Pytorch conda uninstall pytorch conda uninstall libtorch # 使用pip卸载Pytorch pip uninstall torch
-
1.3 opencv
安装
-
使用国内源pip安装,conda没有
-
1 2pip install opencv-python -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com pip install opencv-contrib-python -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
读取视频并处理
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26import cv2 def op_one_img(src): imgret = cv2.flip(src,1); return imgret def makevideo(): videoinpath = 'test.mp4' videooutpath = 'videoname_out.avi' capture = cv2.VideoCapture(videoinpath) fourcc = cv2.VideoWriter_fourcc(*'DIVX') writer = cv2.VideoWriter(videooutpath ,fourcc, 30.0, (1080,1920),True) if capture.isOpened(): while True: ret,img_src=capture.read() if not ret:break img_out = op_one_img(img_src) # 自己写函数op_one_img()逐帧处理 writer.write(img_out) else: print('视频打开失败!') # writer.release() print("finish deal!") if __name__ == '__main__': makevideo() -
注意
VideoWriter这个函数,其中frame的大小是先宽后高,如果搞错了,视频打不开。
1.4 numpy
-
axis轴的概念,从0开始。
-
形状为 (a, b, c) 的数组,沿着 0 轴聚合后,形状变为 (b, c);沿着 1 轴聚合后,形状变为 (a, c);即第一个数是axis0,依次往下。
-
1 2 3 4 5 6 7In[25]: print(interest_score) [[9 8 9] [1 0 0] [7 6 1] [8 7 0]] In[26]: np.sum(interest_score, axis=0) Out[26]: array([25, 21, 10]) -

-

-
浅拷贝和深拷贝
-
Pillow 读入后通道的顺序就是 R、G、B,而 OpenCV 读入后顺序是 B、G、R。
-
读取图片的内存表示如下。
-

-
先行数,后列数,最后是通道数
-
1 2 3 4 5 6In[3]: import numpy as np In[4]: a = cv.imread("1.png") In[5]: a.size Out[5]: 1283400 In[6]: a.shape Out[6]: (300, 1426, 3) -

实例
-
a.ravel() #用ravel()方法将数组a拉成一维数组 -
1 2 3 4 5# 广播,复制 np.broadcast_to( np.expand_dims(np.eye(3), axis=0),#shape为1,3,3的单位三维张量 (self.R.shape[0] - 1, 3, 3) ) -
numpy.vstack函数: 将参数元素数组按轴0合并,即行,要保证其他轴相同,否则报错,下面同理 -
np.hstack:将参数元组的元素数组按轴1合并,即列 -
np.dstack自然是说deep stack了,它是轴2合并。dstack([a,b])把a和b摞在一起,像一摞扑克牌一样。
1.5 tensor
- 标量,也称 Scalar,是一个只有大小,没有方向的量,比如 1.8、e、10 等。
- 向量,也称 Vector,是一个有大小也有方向的量,比如 (1,2,3,4) 等。
- 矩阵,也称 Matrix,是多个向量合并在一起得到的量,比如[(1,2,3),(4,5,6)]等。
- 通过查阅文档,torch.Tensor是默认tensor类型的torch.FloatTensor别名, 可以直接从给定数据中创建出FloatTensor的tensor, 而torch.tensor是创建会根据输入的数据类型判断。 也就是说,如果我传入的是int类型,那么torch.Tensor输出的是FloatTensor数据格式,而torch.tensor输出的torch.int32。
1.6 Torchvision
-
今天起我们进入模型训练篇的学习。如果将模型看作一辆汽车,那么它的开发过程就可以看作是一套完整的生产流程,环环相扣、缺一不可。这些环节包括数据的读取、网络的设计、优化方法与损失函数的选择以及一些辅助的工具等。未来你将尝试构建自己的豪华汽车,或者站在巨人的肩膀上对前人的作品进行优化。
-
1.Dataset类
-
PyTorch 中的 Dataset 类是一个抽象类,它可以用来表示数据集。我们通过继承 Dataset 类来自定义数据集的格式、大小和其它属性,后面就可以供 DataLoader 类直接使用。其实这就表示,无论使用自定义的数据集,还是官方为我们封装好的数据集,其本质都是继承了 Dataset 类。
-
而在继承 Dataset 类时,至少需要重写以下几个方法:
__init__():构造函数,可自定义数据读取方法以及进行数据预处理;__len__():返回数据集大小;__getitem__():索引数据集中的某一个数据。
-
2.DataLoader类
-
在实际项目中,如果数据量很大,考虑到内存有限、I/O 速度等问题,在训练过程中不可能一次性的将所有数据全部加载到内存中,也不能只用一个进程去加载,所以就需要多进程、迭代加载,而 DataLoader 就是基于这些需要被设计出来的。
-
DataLoader 是一个迭代器,最基本的使用方法就是传入一个 Dataset 对象,它会根据参数 batch_size 的值生成一个 batch 的数据,节省内存的同时,它还可以实现多进程、数据打乱等处理。
-
结合代码,我们梳理一下 DataLoader 中的几个参数,它们分别表示:
- dataset:Dataset 类型,输入的数据集,必须参数;
- batch_size:int 类型,每个 batch 有多少个样本;
- shuffle:bool 类型,在每个 epoch 开始的时候,是否对数据进行重新打乱;
- num_workers:int 类型,加载数据的进程数,0 意味着所有的数据都会被加载进主进程,默认为 0。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68import torch from torch.utils.data import Dataset from torch.utils.data import DataLoader class MyDataset(Dataset): # 构造函数 def __init__(self, data_tensor, target_tensor): self.data_tensor = data_tensor self.target_tensor = target_tensor # 返回数据集大小 def __len__(self): return self.data_tensor.size(0) # 返回索引的数据与标签 def __getitem__(self, index): return self.data_tensor[index], self.target_tensor[index] # 生成数据 data_tensor = torch.randn(10, 3) target_tensor = torch.randint(2, (10,)) # 标签是0或1 # 将数据封装成Dataset my_dataset = MyDataset(data_tensor, target_tensor) # 查看数据集大小 print('Dataset size:', len(my_dataset)) ''' 输出: Dataset size: 10 ''' # 使用索引调用数据 print('tensor_data[0]: ', my_dataset[0]) ''' 输出: tensor_data[0]: (tensor([ 0.4931, -0.0697, 0.4171]), tensor(0)) ''' print("\n") tensor_dataloader = DataLoader(dataset=my_dataset, # 传入的数据集, 必须参数 batch_size=1, # 输出的batch大小 shuffle=True, # 数据是否打乱 num_workers=0) # 进程数, 0表示只有主进程 # 以循环形式输出 for data, target in tensor_dataloader: print(data, target) ''' 输出: tensor([[-0.1781, -1.1019, -0.1507], [-0.6170, 0.2366, 0.1006]]) tensor([0, 0]) tensor([[ 0.9451, -0.4923, -1.8178], [-0.4046, -0.5436, -1.7911]]) tensor([0, 0]) tensor([[-0.4561, -1.2480, -0.3051], [-0.9738, 0.9465, 0.4812]]) tensor([1, 0]) tensor([[ 0.0260, 1.5276, 0.1687], [ 1.3692, -0.0170, -1.6831]]) tensor([1, 0]) tensor([[ 0.0515, -0.8892, -0.1699], [ 0.4931, -0.0697, 0.4171]]) tensor([1, 0]) ''' # 输出一个batch print('One batch tensor data: ', iter(tensor_dataloader).next()) ''' 输出: One batch tensor data: [tensor([[ 0.9451, -0.4923, -1.8178], [-0.4046, -0.5436, -1.7911]]), tensor([0, 0])] ''' -
3.Torchvision
-
Torchvision 是一个和 PyTorch 配合使用的 Python 包。它不只提供了一些常用数据集,还提供了几个已经搭建好的经典网络模型,以及集成了一些图像数据处理方面的工具,主要供数据预处理阶段使用。简单地说,Torchvision 库就是常用数据集 + 常见网络模型 + 常用图像处理方法。
-
1 2pip install torchvision pip install pillow -
Torchvision 中默认使用的图像加载器是 PIL,因此为了确保 Torchvision 正常运行,我们还需要安装一个 Python 的第三方图像处理库——Pillow 库。Pillow 提供了广泛的文件格式支持,强大的图像处理能力,主要包括图像储存、图像显示、格式转换以及基本的图像处理操作等。
-
Torchvision 库中的torchvision.datasets包中提供了丰富的图像数据集的接口。常用的图像数据集,例如 MNIST、COCO 等,这个模块都为我们做了相应的封装。各个数据集的说明与接口,详见链接https://pytorch.org/vision/stable/datasets.html。
-
torchvision.datasets这个包本身并不包含数据集的文件本身,它的工作方式是先从网络上把数据集下载到用户指定目录,然后再用它的加载器把数据集加载到内存中。最后,把这个加载后的数据集作为对象返回给用户。
-

-

-

1.7 卷积
-
在开篇的例子中,输入只有 1 个通道,现在有多个通道了,那我们该如何计算呢?其实计算方式类似,输入特征的每一个通道与卷积核中对应通道的数据按我们之前讲过的方式进行卷积计算,也就是输入特征图中第 i 个特征图与卷积核中的第 i 个通道的数据进行卷积。这样计算后会生成 m 个特征图,然后将这 m 个特征图按对应位置求和即可,求和后 m 个特征图合并为输出特征中一个通道的特征图。
-
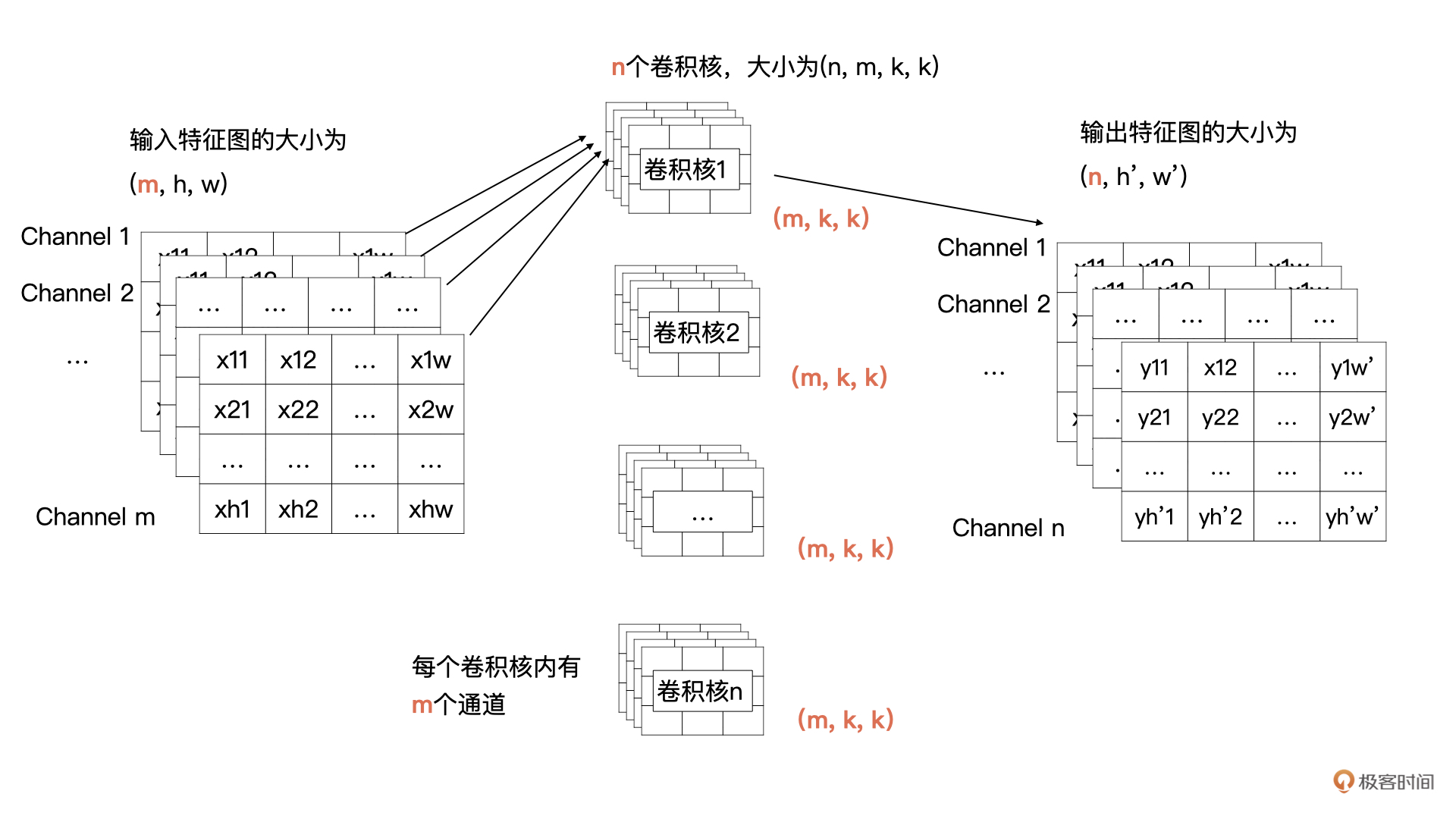
-
卷积背后的理论比较复杂,但在 PyTorch 中实现却很简单。在卷积计算中涉及的几大要素:输入通道数、输出通道数、步长、padding、卷积核的大小,分别对应的就是 PyTorch 中 nn.Conv2d 的关键参数。
-
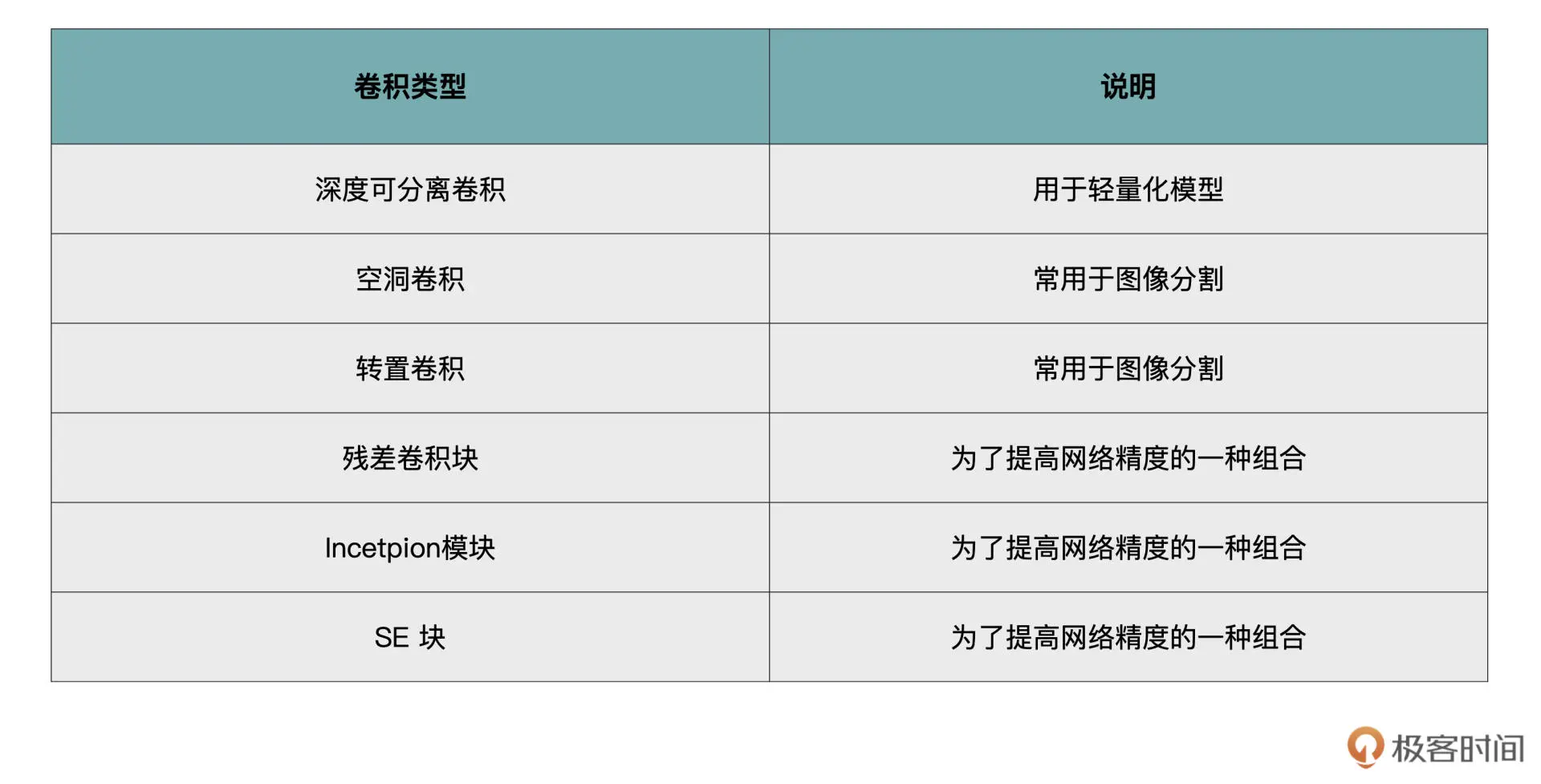
-

-
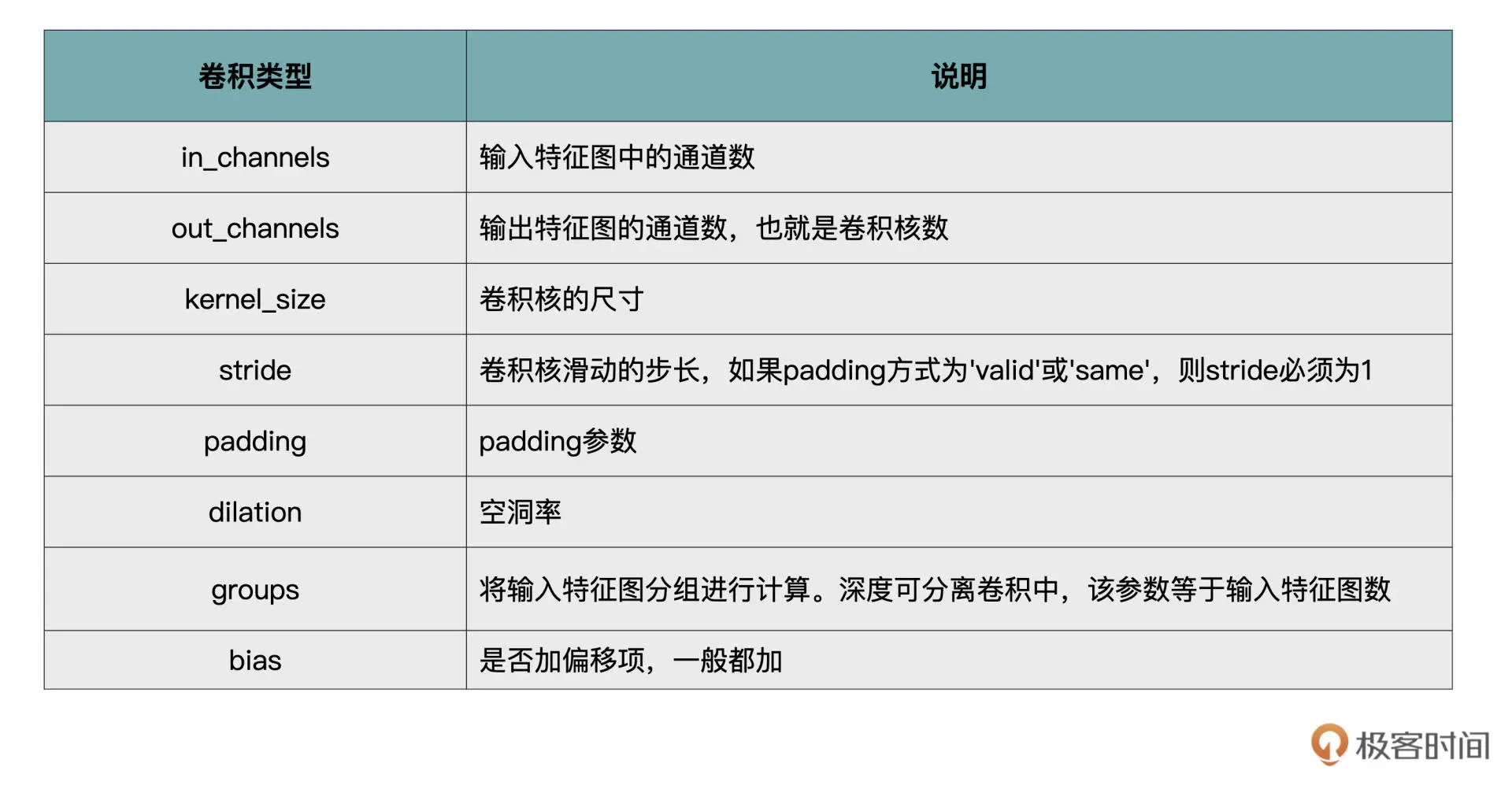
1.8 损失函数
-
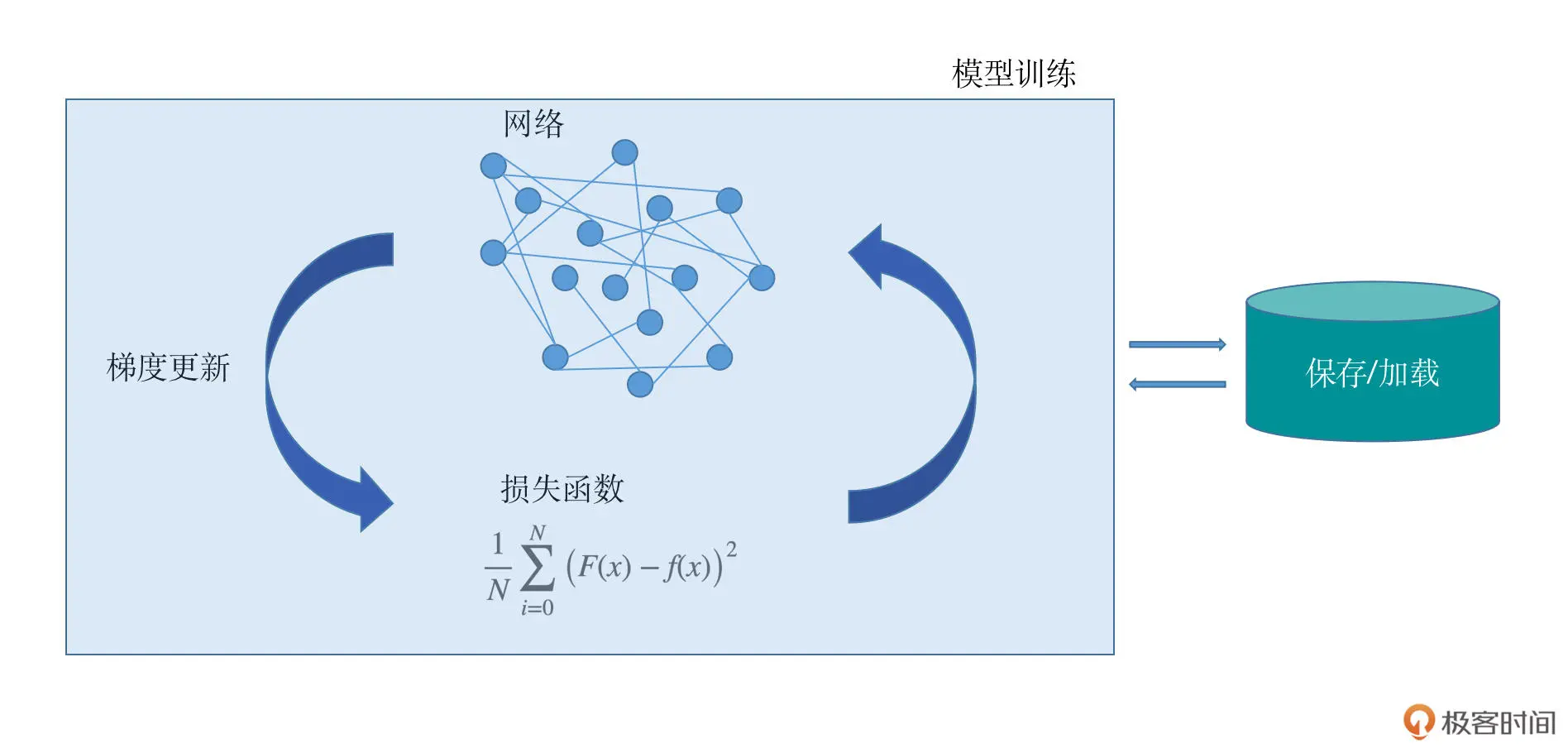
-
模型拿到数据之后就要有一个非常重要的环节:把模型自己的判断结果和数据真实的情况做比较。如果偏差或者差异特别大,那么模型就要去纠正自己的判断,用某种方式去减少这种偏差,然后反复这个过程,直到最后模型能够对数据进行正确的判断。衡量这种偏差的方式很重要,也是模型学习进步的关键所在。这种减少偏差的过程,我们称之为拟合。接下来我们一同看看拟合的几种情况。
1.9 model.train() 和 model.eval()
1.10 tensorboard使用问题
tensorboard --logdir="C:\Users\cdfgh\Desktop\train_example\tensorboard"- TensorBoard的最全使用教程
1.11 图像预处理——归一化、标准化
-
标准化 Standardization:input表示输入的图像像素值;mean(input)表示输入图像的像素均值。std表示输入图像像素的标准差。经过标准化,图像像素被调整到[-1,1]区间内。
-
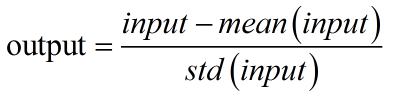
-
归一化 Normalization:input表示输入的图像像素值;max()、min()分别表示输入像素的最大值和最小值。output为输出图像像素值。经过归一化,图像像素被调整到[0,1]区间内。
-
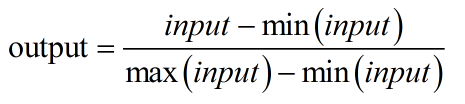
1.12 多卡GPU训练
-
pytorch中to(device) 和cuda()有什么区别?如何使用? | w3c笔记 (w3cschool.cn)
-
1 2 3 4 5# 限定gpu索引 os.environ["CUDA_VISIBLE_DEVICES"] = "1,0" def main(args): device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu') cliff_model = cliff(constants.SMPL_MEAN_PARAMS).to(device) -
1 2 3 4 5 6# 限定gpu索引 os.environ["CUDA_VISIBLE_DEVICES"] = "1,0" self.model=torch.nn.DataParallel(self.model) self.model.cuda() # Set the model in evaluation mode self.model.eval()
2. CUDA && Cudnn 下载与安装
-
cudnn下载地址cuDNN Archive | NVIDIA Developer
-
注意cudnn下载需要注册NVIDIA账号。
-
注意查看自身可以下载的cuda最高版本。
nvidia-smi或者查看nvidia控制面板的组件信息 -
多个版本cuda的兼容方法【CUDA安装/多CUDA兼容】Windows深度学习环境配置
-
安装cuda前最好先安装VS2017。为了方便源码编译。
-
安装完成后可通过命令
nvcc -V查看是否已经完成安装。 -
watch -n 5 nvidia-smi 隔5秒查看一次 gpu使用情况。
nvidia-smi查看gpu的进程
-
或者安装一个python包,通过
gpustat --w查看pip install gpustatgpustat --w
-
CTRL-Z和CTRL-C区别?
- CTRL-Z和CTRL-C都是中断命令,但是他们的作用却不一样;
- CTRL-C是强制中断程序的执行;
- CTRL-Z的是将任务中断,但是此任务并没有结束,他仍然在进程中他只是维持挂起的状态,用户可以使用fg/bg操作继续前台或后台的任务,fg命令重新启动前台被中断的任务,bg命令把被中断的任务放在后台执行.
3. Winodows配置常见问题
- windows运行bash命令——安装git
- openpose gpu内参溢出解决办法
.\bin\OpenPoseDemo.exe --model_pose BODY_25 --image_dir .\lsp500 --write_json .\result --net_resolution 320x176- OpenPose报错:error == cudaSuccess (2 vs. 0) out of memory
4. Linux配置常见问题
-
查看cuda版本
-
1ls -l /usr/local/ | grep cuda
-
-
cuda与GPU版本关系
-
cuda10.x的最高支持GPU的算力是7.5,GPU算力8.x要用cuda11.1或以上。然鹅,软链接设置为cuda10.2,pytorch安装10.2会报错,安装11.1就完美运行。
-
cuda10只支持到RTX 2080,RTX 3080 Ti 最低的cuda是 11.1
-
-
利用vscode对python代码做Debug,无法调试的解决方案 ——版本问题我淦,22.8.1之前的都可以debug。
-
vscode利用argparser添加调试参数
-
ubuntu的GPU使用 python运行程序设置指定GPU(查看GPU使用情况)
-
wget代理下载
-
1 2 3 4 5 6# They will override the value in the environment. https_proxy = http://127.0.0.1:8087/ http_proxy = http://127.0.0.1:8087/ ftp_proxy = http://127.0.0.1:8087/ wget -c -r -np -k -L -p -e "http_proxy=http://127.0.0.1:7891" http://www.subversion.org.cn/svnbook/1.4/
-
df -hl /home/...查看当前目录剩余空间 -
kill -9 pid强制关闭进程 -
按照pytorch可以使用离线安装whl文件,避免安装失败
-
GPU显存泄漏解决方法——
fuser -v /dev/nvidia*用于发现gpu僵尸进程 -
防止ssh断开连接训练中断的解决方法
- 安装screen
screen的使用方法
-
安装——
sudo apt-get install screen -
创建一个窗口——
screen -S screen_name -
显示运行的窗口——
screen -ls,断开连接后attach变为detached,但是仍在后台运行 -
-
重新查看——
screen -D -r 65141或者screen -r 65141:65141是pid号 -
当不用这个子窗口了,可以
kill 65141杀死进程。 -
杀死进程后,还在screen列表里面,需要使用
screen -wipe清空死去的窗口进程。 -
退出当前子窗口的按键——
ctrl + a d。注意按两次,一次a,一次d,ctrl不松开。
5. 2D 数据集
-
LSP
- 地址:http://sam.johnson.io/research/lsp.html
- 样本数:2K
- 关节点个数:14
- 全身,单人
-
FLIC
- 地址:https://bensapp.github.io/flic-dataset.html
- 样本数:2W
- 关节点个数:9
- 全身,单人
-
MPII
- 地址:http://human-pose.mpi-inf.mpg.de/
- 样本数:25K
- 关节点个数:16
- 全身,单人/多人,40K people,410 human activities
- MPII数据集解析_
-
COCO
- 地址:http://cocodataset.org/#download
- 样本数:>= 30W
- 关节点个数:18
- 全身,多人,keypoints on 10W people
-
AI Challenge
- 地址:https://challenger.ai/competition/keypoint/subject
- 样本数:21W Training, 3W Validation, 3W Testing
- 关节点个数:14
- 全身,多人,38W people
6. 3D 数据集
-
Human3.6M :有32个关键点的2D坐标,存在一些看似冗余的标注点,这些冗余的一部分是为了满足表达旋转向量的需要的。我们只研究关节点的2d位置时,不需要考虑全部的32个关键点,只需要提取出有效表示对应关节的关键点即可。
- Human3.6M数据集有360万个3D人体姿势和相应的图像,共有11个实验者(Subject)(6男5女,论文一般选取1,5,6,7,8作为train,9,11作为test),和17个动作场景(Scenario),诸如讨论、吃饭、运动、问候等动作。该数据由4个数字摄像机,1个时间传感器,10个运动摄像机捕获。
- 官网Human3.6M Dataset (imar.ro)
- 2D人体姿态识别-对Human3.6M数据集预处理
-
3DPW 数据集是一个 3D 人体姿态识别数据集
- 其相关的网站为:3DPW | Real Virtual Humans
- 3DPW 数据集简介及解析
- 这个数据集比较新
-
MPI-INF-3DHP 数据集
- Human3.6M 尽管数据量大,但场景单一。为了解决这一问题,MPI-INF-3DHP 在数据集中加入了针对前景和背景的数据增强处理。具体来说,其训练集的采集是借助于多目相机在室内绿幕场景下完成的,对于原始的采集数据,先对人体、背景等进行分割,然后用不同的纹理替换背景和前景,从而达到数据增强的目的。测试集则涵盖了三种不同的场景,包括室内绿幕场景、普通室内场景和室外场景。因此,MPI-INF-3DHP 更有助于评估算法的泛化能力。
- Monocular 3D Human Pose Estimation In The Wild Using Improved CNN Supervision, 3DV 2017 (mpg.de)——官网