打包exe过程及其解决方案
-
可以使用anaconda创建一个比较简洁的虚拟环境,这样打包出来的文件比较小
-
安装 pyinstaller——pip install pyinstaller(或者anaconda图形化安装)
-
win+R->cmd进入命令行
-
1 2 3 4 5 6 7conda env list activate env_name pyinstaller -F --icon=my.ico test.py #打包成exe,并设置图标 #或者 pyinstaller -F -w yourfilename.py #打包成exe,且不包含控制台,打包pyqt #或者 pyinstaller -F -c yourfilename.py #打包成exe,使用控制台,无界面(默认)
|
|
-
有时候用pyinstaller 打包的时候会遇到:
RecursionError: maximum recursion depth exceeded 这个递归错误,大概率是自己调用自己太多次导致的。解决办法:pyinstaller 之后会生成一个和xxx.py文件对一个的 xxx.spec 文件。打开xxx.spec文件,在行首导入sys包,然后设置一下递归调用的限制次数,可以尽量大一点,设置100万次后就没有报错了,代码如下:
|
|
Anaconda换源
|
|
Jupyter Notebook切换虚拟环境
有两个方法
-
方法一:直接在anaconda的base环境安装自动关联包(简单)
1conda install nb_conda-
假设打开jupyter的时候,弹出错误
EnvironmentLocationNotFound: Not a conda environmen
-
解决办法:
找到以下两个文件夹,打开envmanager.py文件
- D:\Anaconda\install\pkgs\nb_conda-2.2.1-py37_0\Lib\site-packages\nb_conda
- D:\Anaconda\install\Lib\site-packages\nb_conda
找到以下代码
1 2 3 4return { "environments": [root_env] + [get_info(env) for env in info['envs']] }修改为
1 2 3 4 5return { "environments": [root_env] + [get_info(env) for env in info['envs'] if env != root_env['dir']] } -
重启Jupyter即可
-
-
方法二:
1 2 3 4 5 6 7 8 9//1,列出环境 conda env list //2,激活环境 activate xxx //3,安装依赖 conda install ipykernel //4,设置虚拟环境 python -m ipykernel install --user --name xxx --display-name "xxx" 例如python -m ipykernel install --user --pytorch2 --display-name "pytorch2"此方式有点问题,假如不行,打开
C:\Users"你的用户名"\AppData\Roaming\jupyter\kernels\
里面创建的虚拟环境,打开对应的.json文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15{ "language": "python", "display_name": "tensorflow", "argv": [ "C:\\ProgramData\\Anaconda3\\envs\\pytorch\\python.exe", "-m", "ipykernel_launcher", "-f", "{connection_file}" ] } //****************************************** 上面的"C:\\ProgramData\\Anaconda3\\envs\\pytorch\\python.exe"设置为 你实际虚拟python.exe的位置
基本知识
字符串
- 单引号和双引号没区别
- 字符串和tuple差不多,不可以直接更改,但是可以和list互换
- 字符串的拼接直接用+号即可
|
|
yield
- 在 Python 中,使用了 yield 的函数被称为生成器(generator)。
- 跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
- 在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下 一次执行 next() 方法时从当前位置继续运行。
- 调用一个生成器函数,返回的是一个迭代器对象。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28def myGun(): print("生成器") yield 1 yield 2 mygun=myGun() for each in mygun: print(each) def libs(n): a = 0 b = 1 while True: a, b = b, a + b if a > n: return yield a for each in libs(100): print(each, end=' ') 结果: 生成器 1 2 1 1 2 3 5 8 13 21 34 55 89
Numpy函数
import numpy as np
1.numpy.random.normal
-
函数原型:numpy.random.normal(loc=0.0, scale=1.0, size=None)
-
从正态(高斯)分布中抽取随机样本。
-
参数:
- loc 浮点型数据或者浮点型数据组成的数组 分布的均值(中心)
- scale 浮点型数据或者浮点型数据组成的数组 分布的标准差(宽度)
- size 整数或者整数组成的元组,可选参数 输出值的维度。如果给定的维度为(m, n, k),那么就从分布中抽取m * n * k个样本。如果size为None(默认值)并且loc和scale均为标量,那么就会返回一个值。否则会返回np.broadcast(loc, scale).size个值
-
返回值:n维数组
-
1 2 3 4num_inputs = 2 num_examples = 1000 np.random.normal(0, 1, (num_examples,num_inputs)) #返回二维数组,每组1000个随机点
2.random.shuffle/permutation()
- permutation、shuffle,对给定序列实现随机排列;
- 前者返回一个新数组,后者是 inplace 操作,即改变原数组
pyqt5 使用
1. 搭建环境
- 添加pyqt5
以下添加示例上网自查
- 添加QtDesigner——在拓展工具
- 添加PyUIC——在拓展工具
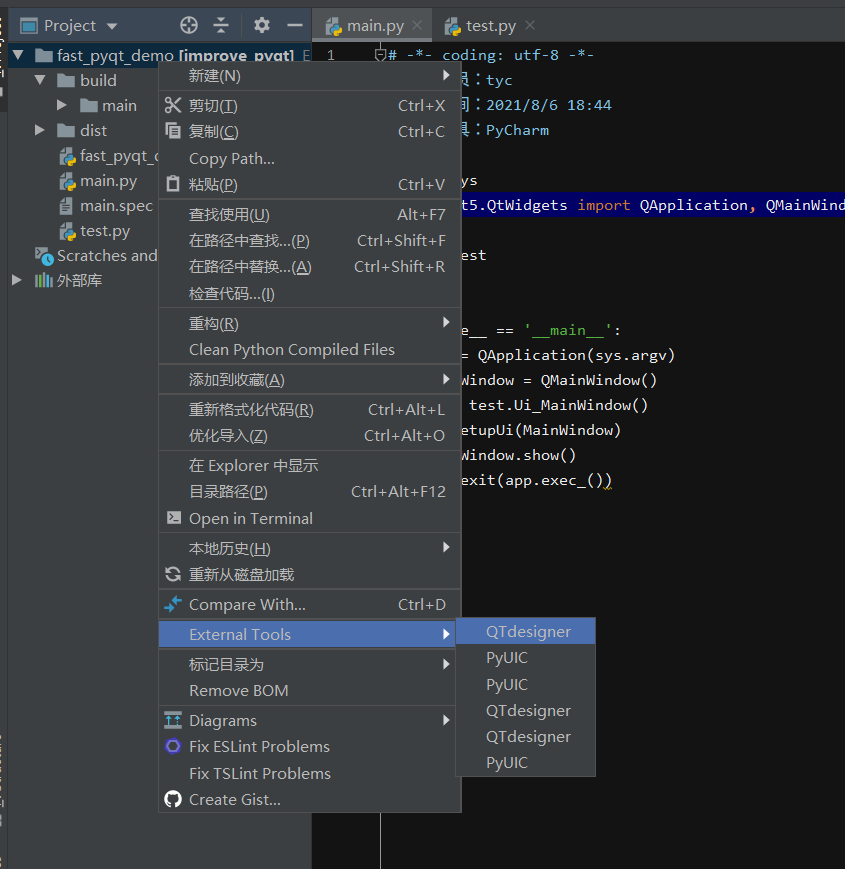
- 参考https://www.cnblogs.com/beyang/p/9504581.html
2. 快速使用
-
用QT designer制作的界面为.ui文件,通过命令可以编译为.py文件,但此时如果对.py文件作修改,下一次使用.ui生成的.py文件不会存在这些修改,这就是没有将界面实现与逻辑分离开,因此我们需要实现将界面与逻辑分离开来。
-
做法很简单,就是新建一个.py文件,继承界面文件的主窗口类即可,具体的逻辑实现也应该在这个.py文件中实现。
-
ui生成的py文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17from PyQt5 import QtCore, QtGui, QtWidgets class Ui_Form(object): def setupUi(self, Form): Form.setObjectName("Form") Form.resize(869, 607) Form.setWindowTitle("ID_CARD_Det") self.test = QtWidgets.QPushButton(Form) self.test.setGeometry(QtCore.QRect(160, 100, 93, 28)) self.test.setObjectName("test") self.retranslateUi(Form) QtCore.QMetaObject.connectSlotsByName(Form) def retranslateUi(self, Form): _translate = QtCore.QCoreApplication.translate self.test.setText(_translate("Form", "test")) -
自己写的MainWindow类
1 2 3 4 5 6 7 8 9 10 11 12from PyQt5 import QtCore, QtGui, QtWidgets from idcard import Ui_Form class MainWindow(QtWidgets.QMainWindow, Ui_Form): def __init__(self, parent=None): super(MainWindow, self).__init__(parent) self.setupUi(self) #信号和槽的实现函数 self.test.clicked.connect(self.on1click) def on1click(self): print("hello world") QtWidgets.QMessageBox.warning(self,"警告头","警告信息") -
main函数
1 2 3 4 5 6 7 8 9from PyQt5 import QtCore, QtGui, QtWidgets from mainwindow import MainWindow import sys if __name__ == "__main__": app = QtWidgets.QApplication(sys.argv) mainWindow = MainWindow() mainWindow.show() sys.exit(app.exec_()) -
效果展示
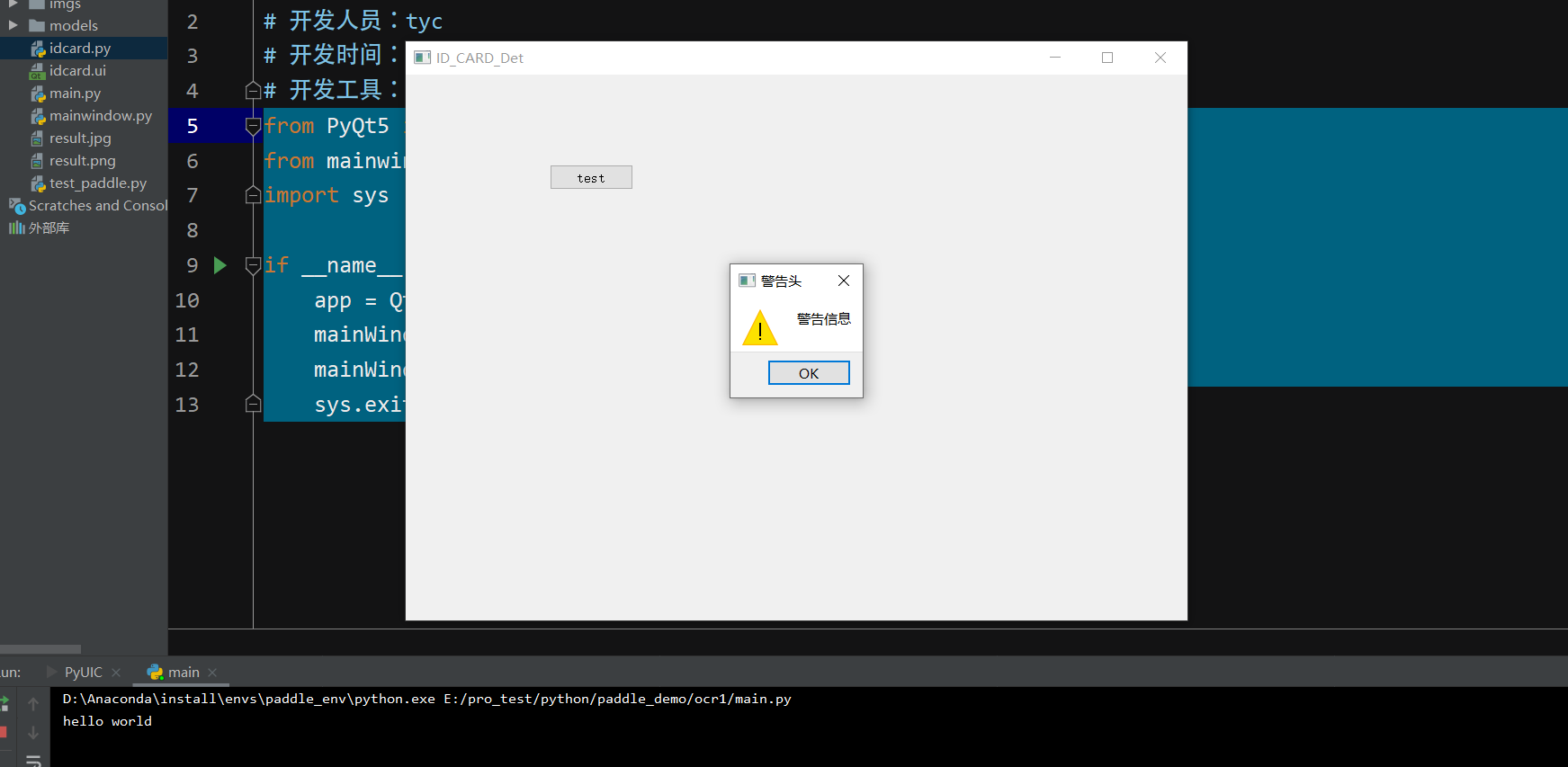
绘图步骤
-
from matplotlib import pyplot as plt
-
创建画板
-
plt.figure,主要接收一个元组作为 figsize 参数设置图形大小,返回一个 figure 对象用于提供画板
-
plt.axes,接收一个 figure 或在当前画板上添加一个子图,返回该 axes 对 象,并将其设置为"当前"图,缺省时会在绘图前自动添加
-
plt.subplot,主要接收 3 个数字或 1 个 3 位数(自动解析成 3 个数字,要 求解析后数值合理)作为子图的行数、列数和当前子图索引,索引从 1 开始(与 MATLAB 保存一致),返回一个 axes 对象用于绘图操作。这里,可以理解成是 先隐式执行了 plt.figure,然后在创建的 figure 对象上添加子图,并返回当前子 图实例
-
plt.subplots,主要接收一个行数 nrows 和列数 ncols 作为参数(不含第三 个数字),创建一个 figure 对象和相应数量的 axes 对象,同时返回该 figure 对 象和 axes 对象嵌套列表,并默认选择最后一个子图作为"当前"图
-
1 2 3 4 5 6plt.figure() plt.subplot(2,2,1) plt.plot([1,2]) plt.subplot(2,2,2) plt.plot([2,1]) plt.show() -
绘制图表
- plot,折线图或点图,实际是调用了 line 模块下的 Line2D 图表接口
- scatter,散点图,常用于表述两组数据间的分布关系,也可由特殊形式下 的 plot 实现
- bar/barh,条形图或柱状图,常用于表达一组离散数据的大小关系,比如 一年内每个月的销售额数据;默认竖直条形图,可选 barh 绘制水平条形图
- hist,直方图,形式上与条形图很像,但表达意义却完全不同:直方图用 于统计一组连续数据的分区间分布情况,比如有 1000 个正态分布的随机抽样, 那么其直方图应该是大致满足钟型分布;条形图主要是适用于一组离散标签下 的数量对比
- pie,饼图,主要用于表达构成或比例关系,一般适用于少量对比
- imshow,显示图像,根据像素点数据完成绘图并显示
-
配置比例:
- title,设置图表标题
- axis/xlim/ylim,设置相应坐标轴范围,其中 axis 是对后 xlim 和 ylim 的集 成,接受 4 个参数分别作为 x 和 y 轴的范围参数
- grid,添加图表网格线
- legend,在图表中添加 label 图例参数后,通过 legend 进行显示
- xlabel/ylabel,分别用于设置 x、y 轴标题
- xticks/yticks,分别用于自定义坐标轴刻度显示
- text/arrow/annotation,分别在图例指定位置添加文字、箭头和标记,一 般很少用
-
还有设置子图位置的
-
plt.axes 可通过接收尺寸参数实现多子图绘制:在添加子图时传入 一个含有 4 个数值的元组,分别表示子图的底坐标和左坐标(设置子图原点位置)、 宽度和高度(设置子图大小),从而间接实现子图仅占据画板的一块子区域。相应 的方法接口在面向对象接口中是 fig.add_axes(),仅仅是接口名字不同,但参数和原理 是一致的。
-
1 2 3 4 5 6 7plt.figure() x=np.linspace(0,10,100) plt.axes((0.1,0.5,0.8,0.4)) plt.plot(np.sin(x)) plt.axes((0.1,0.1,0.8,0.4)) plt.plot(np.cos(x)) plt.show()
-
paddleOCR
1. 安装
-
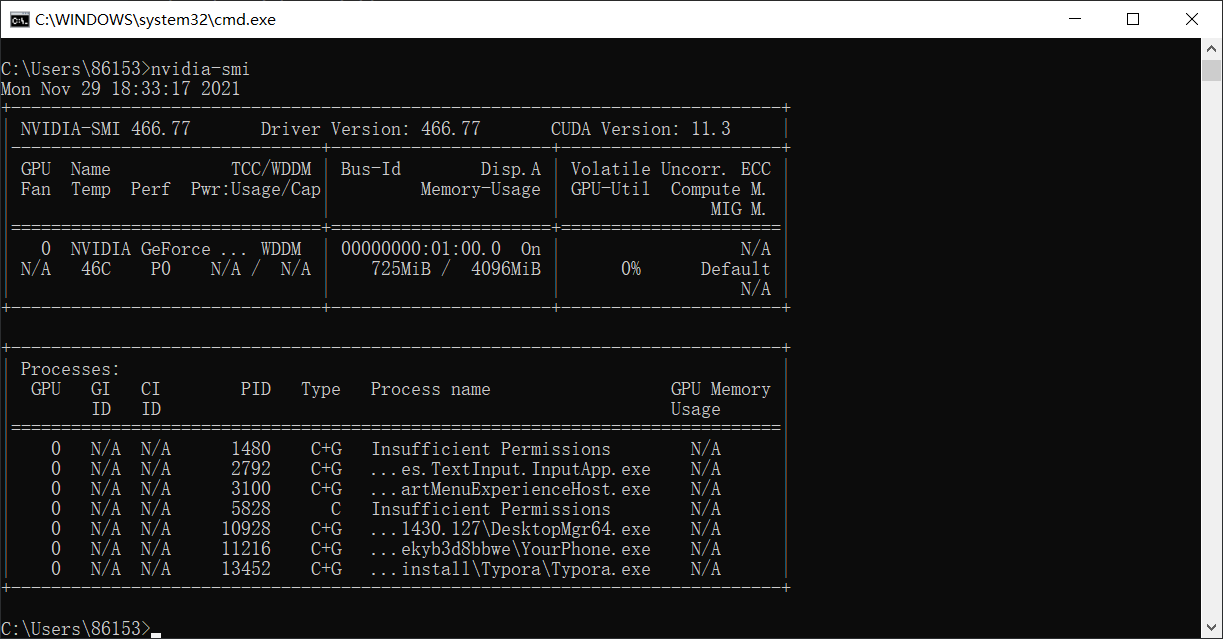
查看cuda版本
-
nvidia-smi
-
-
pip安装记得把梯子拆下来,不然安装出错
-
安装参考https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/pip/windows-pip.html
-
个人安装命令参考
1 2 3 4 5 6 7 8 9 10conda env list activate paddle_env # 安装cpu版本的paddlepaddle python -m pip install paddlepaddle==2.2.0 -i https://mirror.baidu.com/pypi/simple #安装完成后您可以使用 python 进入python解释器,输入import paddle ,再输入 paddle.utils.run_check() #如果出现PaddlePaddle is installed successfully!,说明您已成功安装。 # 安装paddleocr pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本 -
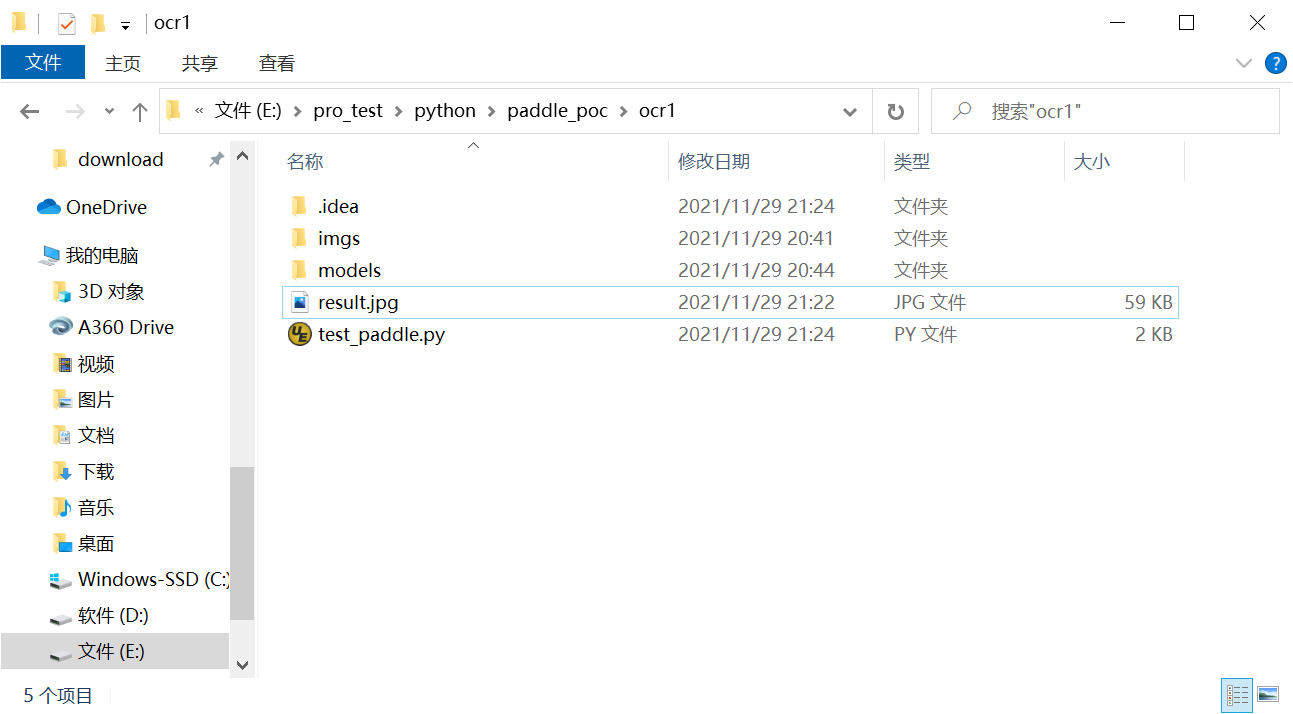
下载三个推理模型

- 然后放在python同一工程文件名下新建一个models文件夹,注意文件目录在工程目录里面
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22from paddleocr import PaddleOCR, draw_ocr from PIL import Image # Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换 # 例如`ch`, `en`, `fr`, `german`, `korean`, `japan` img_path = './imgs/1.png' # 记得传入三个推理模型:检测、定位、识别 ocr = PaddleOCR(use_angle_cls=True, lang="ch",use_gpu=False, rec_model_dir='./models/ch_PP-OCRv2_rec_infer/', cls_model_dir='./models/ch_ppocr_mobile_v2.0_cls_infer/', det_model_dir='./models/ch_PP-OCRv2_det_infer/') result = ocr.ocr(img_path, cls=True) for line in result: print(line) # 保存显示结果 image = Image.open(img_path).convert('RGB') boxes = [line[0] for line in result] txts = [line[1][0] for line in result] scores = [line[1][1] for line in result] im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf') im_show = Image.fromarray(im_show) im_show.save('result.jpg') -
文件目录
-
2. 和Opencv联调
|
|
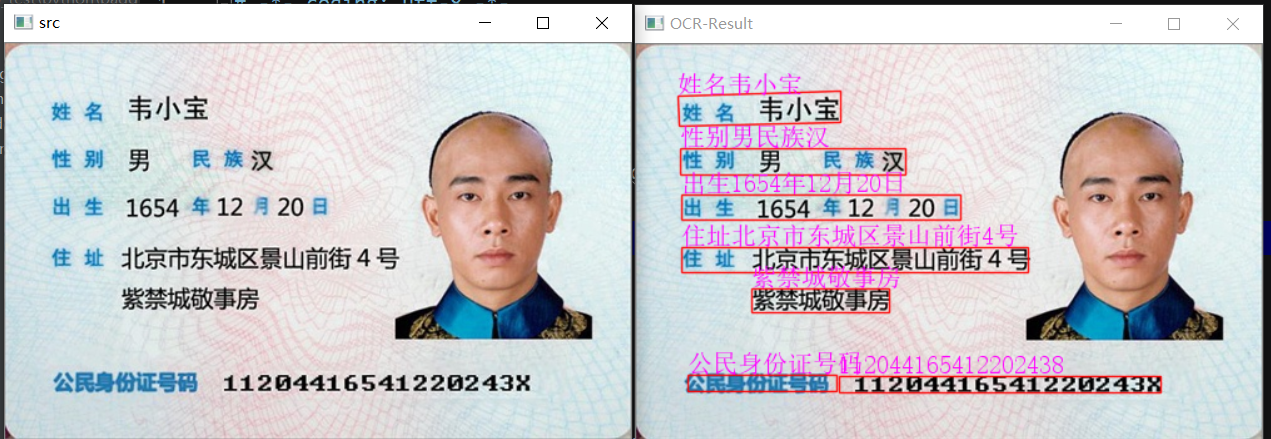
Opencv函数
cv2.findContours
-
1counter,hier=cv2.findContours(can.copy(),cv2.RETR_LIST,cv2.CHAIN_APPROX_SIMPLE)opencv的轮廓定义细分为两种,
- 外黑内白的边界为外轮廓(external);
- 外白内黑的边界为孔轮廓(hole)
关于轮廓的获取算法 opencv应用的是suzuki85轮廓跟踪算法。
寻找轮廓,参数解析
- 第一个输入图片,注意会在原图上修改
- 第二个为轮廓搜索方式
- cv.RETE_LIST: 提取所有轮廓但不建立任何层次关系
- cv.RETE_EXTERNAL: 只提取外轮廓(可能有多个外轮廓,只是不提取孔轮廓
- cv.RETE_TREE: 树形结构表示轮廓的从属关系
- cv.RETE_CCOMP: 提取所有轮廓,把它们组织成两级结构。第一级是连通域的外边界(external boundaries),第二级是孔边界(boundaries of holes)。如果在孔中间还有另外的连通域,则被当成另一个外边界。
- 第三个为近似方法。即轮廓如何呈现的方法,有三种可选的方法:
- cv::CHAIN_APPROX_NONE:将轮廓中的所有点的编码转换成点;
- cv::CHAIN_APPROX_SIMPLE:压缩水平、垂直和对角直线段,仅保留它们的端点;
- cv::CHAIN_APPROX_TC89_L1 or cv::CHAIN_APPROX_TC89_KCOS:应用Teh-Chin链近似算法中的一种风格
- 返回值第一个是轮廓位置,第二个是拓扑信息
cv2.drawContous
-
1cv2.drawContours(src,counter,-1,(0,255,0),3) -
作用是绘制轮廓
-
第一个参数是输入图像,注意会修改,最好是RGB图像
-
第二个参数是轮廓值
-
第三个参数是int contourIdx, // 需要绘制的轮廓的指数 (-1 表示 "all")
-
第四个参数是颜色
-
第五个参数是线宽
cv2.arcLength(cnt, True)
- 参数说明:cnt为输入的单个轮廓值,第二个是轮廓是否闭合
- 作用是计算轮廓的周长
多边形拟合cv2.approxPolyDP(curve, 0.018 * peri, True)
-
approxPolyDP()函数是opencv中对指定的点集进行多边形逼近的函数,其逼近的精度可通过参数设置。
对应的函数为: void approxPolyDP(InputArray curve, OutputArray approxCurve, double epsilon, bool closed);
例如:approxPolyDP(contourMat, approxCurve, 10, true);//找出轮廓的多边形拟合曲线
第一个参数 InputArray curve:输入的点集 第二个参数double epsilon:指定的精度,也即是原始曲线与近似曲线之间的最大距离。 第三个参数bool closed:若为true,则说明近似曲线是闭合的;反之,若为false,则断开。
x, y, w, h = cv2.boudingrect(cnt)
- 作用是获得外接矩形
- 参数说明:x,y, w, h 分别表示外接矩形的x轴和y轴的坐标,以及矩形的宽和高, cnt表示输入的轮廓值
pytorch函数
-
注意:tensor是一个类,torch是一个包。
-
torch.index_select(input, dim, index, out=None)
-
第一个参数是索引的对象,
-
第二个参数为索引维度,0表示按行索引,1表示按列进行索引,
-
第三个参数是一个tensor,就是索引的序号,比如b里面tensor[0, 2]表示第0行和第2行,c里面tensor[1, 3]表示第1列和第3列。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21a = torch.linspace(1, 12, steps=12).view(3, 4) print(a) b = torch.index_select(a, 0, torch.tensor([0, 2])) print(b) print(a.index_select(0, torch.tensor([0, 2]))) c = torch.index_select(a, 1, torch.tensor([1, 3])) print(c) //结果 tensor([[ 1., 2., 3., 4.], [ 5., 6., 7., 8.], [ 9., 10., 11., 12.]]) tensor([[ 1., 2., 3., 4.], [ 9., 10., 11., 12.]]) tensor([[ 1., 2., 3., 4.], [ 9., 10., 11., 12.]]) tensor([[ 2., 4.], [ 6., 8.], [10., 12.]])
-
-
torch.mm
- torch.mm(mat1, mat2, out=None) → Tensor
- 对矩阵 mat1 和 mat2 进行相乘。 如果 mat1 是一个 n×m 张量,mat2 是一个 m×p 张 量,将会输出一个 n×p 张量 out。
-
tensor.item
-
另外一个常用的函数就是 item() , 它可以将⼀一个标量量 Tensor 转换成⼀一个Python number
-
1 2 3x = torch.randn(1) print(x) print(x.item())
-
-
tensor.data()
-
tensor.data 返回和 x 的相同数据 tensor, 而且这个新的tensor和原来的tensor是共用数据的,一者改变,另一者也会跟着改变,而且新分离得到的tensor的requires_grad = False, 即不可求导的。(这一点其实detach是一样的)。
-
常用于梯度计算
-
1param.data -= lr * param.grad / batch_size # 注意这⾥更改param时用的param.data
-
-
torch.set_default_tensor_type(t)
-
将默认
torch.Tensor类型设置为浮点张量类型 t -
1 2 3 4 5>>> torch.tensor([1.2, 3]).dtype # initial default for floating point is torch.float32 torch.float32 >>> torch.set_default_tensor_type(torch.DoubleTensor) >>> torch.tensor([1.2, 3]).dtype # a new floating point tensor torch.float64
-
-
tensor.to()
-
更换tensor的类型,最好从下往上提升,避免出错
-
1 2 3 4 5 6 7 8 9import torch a=torch.empty(5,3,dtype=torch.float64) print(a.dtype) a=a.to(dtype=torch.float) print(a.dtype) #输出 torch.float64 torch.float32
-
-
torch.utils.data
1 2 3 4 5 6 7 8 9 10 11 12# 读取样本数据的包 import torch.utils.data as Data # 批量个数 batch_size = 10 # 将训练数据的特征和标签组合,加载数据,第一个参数为X变量(样本),第二个参数为y输出(标签) dataset = Data.TensorDataset(features, labels) # 随机读取⼩批量,第一个参数为数据,第二个为批量个数,第三个设置为 True 时会在每个 epoch 重新打乱数据(默认: False),返回值为迭代器 data_iter = Data.DataLoader(dataset, batch_size, shuffle=True) # 迭代读取 for X, y in data_iter: print(X, y) break