数据结构概述
- 数组和链表是物理结构
- 顺序表、栈、队列、树、图是逻辑结构
数组
-
list内置类
-
list可以是任何对象
-
常见函数
-
增加元素
|
|
- 删除元素
|
|
- 查找、修改
|
|
链表
-
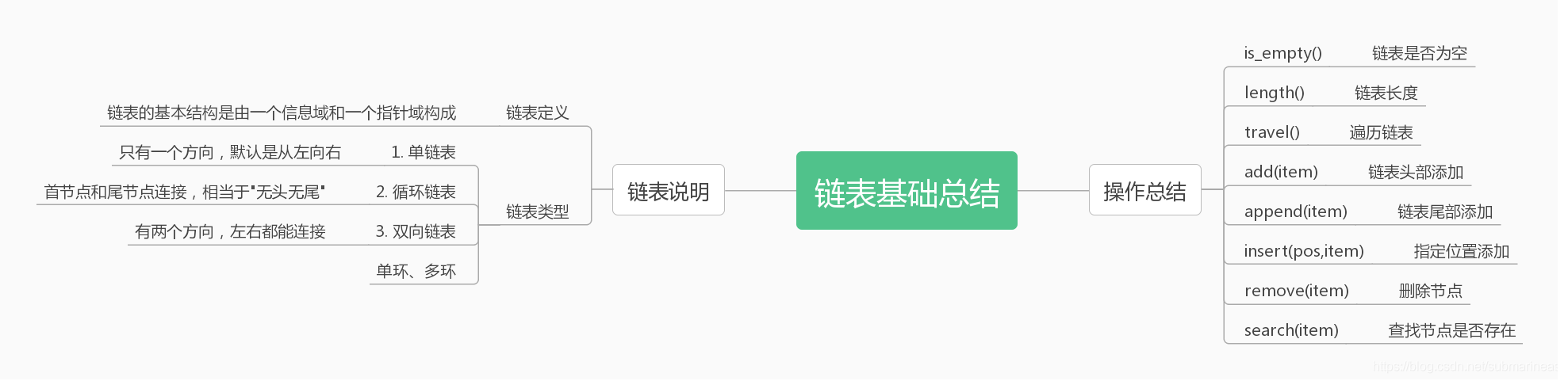
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96# 单链表 class Node(object): def __init__(self, data): # 数据域 self.data = data # 向后的引用域 self.next = None class SingleLinkList(object): def __init__(self): self.head = None # is_empty() 链表是否为空 def is_empty(self): return not self.head # add(data) 链表头部添加元素 # O(1) def add(self, data): node = Node(data) node.next = self.head self.head = node # show() 遍历整个链表 # O(n) def show(self): cur = self.head while cur != None: # cur是一个有效的节点 print(cur.data, end=' --> ') cur = cur.next print() # append(item) 链表尾部添加元素 # O(n) def append(self, data): cur = self.head while cur.next != None: cur = cur.next # cur指向的就是尾部节点 node = Node(data) cur.next = node # length() 链表长度 # O(n) def length(self): count = 0 cur = self.head while cur != None: # cur是一个有效的节点 count += 1 cur = cur.next return count # search(item) 查找节点是否存在 # O(n) def search(self, data): cur = self.head while cur != None: if cur.data == data: return True cur = cur.next return False # remove(data) 删除节点 # O(n) def remove(self, data): cur = self.head pre = None while cur != None: if cur.data == data: if cur == self.head: self.head = self.head.next return pre.next = cur.next return pre = cur cur = cur.next # insert(index, data) 指定位置添加元素 # O(n) def insert(self, index, data): if index <= 0: self.add(data) return if index > self.length() - 1: self.append(data) return cur = self.head for i in range(index-1): cur = cur.next # cur指向的是第index节点第前置节点 node = Node(data) node.next = cur.next cur.next = node -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122# 双链表 class Node(object): #节点的类 def __init__(self,item): self.item = item self.prev = None self.next = None class DLinkList(object): #双向链表的类 def __init__(self): #指向链表的头节点 self.head = None def is_empty(self): #链表是否为空 return self.head == None def length(self): #链表长度 cur = self.head #计数器 count = 0 while cur != None: count += 1 cur = cur.next return count def travel(self): #遍历链表 cur = self.head while cur != None: print(cur.item) cur = cur.next def add(self,item): #链表头部添加 node = Node(item) if self.is_empty(): #如果是空链表,将head指向node #给链表添加第一个元素 self.head = node else: #如果链表不为空,在新的节点和原来的首节点之间建立双向链接 node.next = self.head self.head.prev = node #让head指向链表的新的首节点 self.head = node def append(self,item): #链表尾部添加 #创建新的节点 node = Node(item) if self.is_empty(): #空链表, self.head = node else: #链表不为空 cur = self.head while cur.next != None: cur = cur.next #cur的下一个节点是node cur.next = node #node的上一个节点是 node.prev = cur def insert(self,pos,item): #指定位置添加 if pos <=0: self.add(item) elif pos > self.length()-1: self.append() else: node = Node(item) cur = self.head count = 0 #把cur移动到指定位置的前一个位置 while count < (pos - 1): count+=1 cur = cur.next #node的prev指向cur node.prev = cur #node的next指向cur的next node.next = cur.next cur.next.prev = node cur.next = node def remove(self,item): #删除节点 if self.is_empty(): return else: cur = self._head if cur.item == item: #首节点是要删除的节点 if cur.next == None: #说明链表中只有一个节点 self.head = None else: #链表多于一个节点的情况 cur.next.prev = None self.head = cur.next else: # 首节点不是要删除的节点 while cur != None: if cur.item == item: cur.prev.next = cur.next cur.next.prev = cur.prev break cur = cur.next def search(self,item): #查找节点是否存在 cur = self._head while cur != None: if cur.item == item: return True cur = cur.next return False
栈
-
直接使用list创建stack即可
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16>>> stack=[] >>> stack.append(1) >>> stack.append(2) >>> stack.append(3) >>> stack [1, 2, 3] >>> stack.pop() # 弹出栈顶元素 3 >>> stack.pop() 2 >>> stack [1] >>> stack.pop() 1 >>> stack []
队列
- 单向队列
|
|
- 双向队列
- deque.append
- deque.appendleft
- deque.pop
- deque.popleft
|
|
哈希表——dict字典
-
数值、字符和元组 都能被哈希,因此它们是不可变类型。
-
列表、集合、字典不能被哈希,因此它是可变类型。
-
用 hash(X) ,只要不报错,证明 X 可被哈希,即不可变,反过来不可被哈希,即可变。
-
字典以"关键字"为索引,关键字可以是任意不可变类型,通常用字符串或数值。
-
字典 是无序的 键:值( key:value )对集合,键必须是互不相同的(在同一个字典之内)。
- dict 内部存放的顺序和 key 放入的顺序是没有关系的。
- dict 查找和插入的速度极快,不会随着 key 的增加而增加,但是需要占用大量的内存。 字典 定义语法为 {元素1, 元素2, ..., 元素n}
- 其中每一个元素是一个「键值对」-- 键:值 ( key:value )
- 关键点是「大括号 {}」,「逗号 ,」和「冒号 :」
- 大括号 -- 把所有元素绑在一起
- 逗号 -- 将每个键值对分开
- 冒号 -- 将键和值分开
-
1 2 3 4 5 6dic = dict() dic['a'] = 1 dic['b'] = 2 dic['c'] = 3 print(dic) # {'a': 1, 'b': 2, 'c': 3}
二叉树的前序、中序、后序遍历(深度优先遍历)
|
|
二叉树的层序遍历(广度优先遍历)
|
|
二叉堆
-
二叉堆是一个完全二叉树,储存方式为顺序存储,即存储在数组里,python里面即列表list
-
如何定位左右孩子,依靠数组下标实现,从0开始,左孩子下标为2*parent+1,右孩子为2*parent+2。
-
最大堆:任何一个父节点的值,都大于或等于左孩子和右孩子的节点的值,堆顶为最大值
-
最小堆:任何一个父节点的值,都小于或等于左孩子和右孩子的节点的值,堆顶为最小值
-
三种操作:
- 尾结点插入——上浮
- 堆顶删除——下沉
- 二叉堆的构建(依次从最大非叶子节点下沉)
|
|
优先队列
- 二叉堆的变形
- 最大优先队列:无论入队顺序如何,当前最大元素都会优先出队,基于最大堆实现的
- 最小优先队列:无论入队顺序如何,当前最小元素都会优先出队,基于最小堆实现的
- 入队:即二叉堆的尾结点上浮
- 出队:即二叉堆的堆顶删除,尾结点替代堆顶,然后下沉操作
排序算法
- 主流十大排序,分成三类
- 时间复杂度为O(N^2^)的排序算法:
- 冒泡排序——稳定
- 选择排序——不稳定
- 插入排序——稳定
- 希尔排序(性能略优于O(N^2^),但比不上O(nlogn))——不稳定
- 时间复杂度为O(nlogn))的排序算法:
- 快速排序——不稳定
- 归并排序——稳定
- 堆排序——不稳定
- 时间复杂度为线性的排序算法:(均为非比较排序)
- 计数排序——稳定
- 桶排序——稳定
- 基数排序——稳定
- 时间复杂度为O(N^2^)的排序算法:
- 稳定排序和不稳定排序:值相同的元素排序前后位置是否改变判定
冒泡排序
- 最简单的冒泡排序:思路,两层for循环
|
|
- 冒泡算法优化1:
- 思路:利用标记判断是否已经有序,是的话退出循环
|
|
- 冒泡算法优化2:设立有序边界
- 思路:每次交换后的index保存,在下一次大循环的时候重新设立截止边界
|
|
- 鸡尾酒排序
- 冒泡排序的进阶
- 思路:左右进行排序,初始设置的有序边界都是i(即递增的0,1,2...)
- 适用于内部很多已经排好序的数组
|
|
- 鸡尾酒排序的进阶:增加有序边界
|
|
选择排序
- 算法思想:
- A.在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
- B.从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾
- C.以此类推,直到所有元素均排序完毕
- 与冒泡排序不同的是,选择排序是先找到最小值,然后交换位置。冒泡排序是每一次都交换,最后一定是最小值。
|
|
插入排序
- 它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
- 和冒泡排序的区别在于,冒泡排序是拿一个元素和无序序列去遍历比较,比较得到整个无序序列中最值,然后放入有序序列,而一旦放入有序序列,就不再碰了。
- 插入排序是拿一个元素和有序的数列去比,从单一元素的假有序一个一个加,拿一个元素进入有序序列,碰到比自己大或小的就即刻坐下,不再继续比较,插入排序的当前元素是无论如何不会触摸无序序列的。
|
|
希尔排序
- 希尔排序(Shell's Sort)是插入排序的一种又称“缩小增量排序”(Diminishing Increment Sort),是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。
- 分组依次插入排序,设置依次整除2
|
|
快速排序
-
思路:分治法
-
基准元素的选择:一般选择第一个元素,也可以随机选取之后和第一个元素调换,避免极端情况
-
双边循环递归法查找分界索引位置
- 使用双指针
|
|
- 单边循环递归法
- 使用mark标志,左边比基准元素小,右边比基准元素大
|
|
- 非递归方法
- 使用栈
- 输入的是哈希表,包含读取的头和尾
|
|
归并排序
- 思路:分治法
- 先分解,后归并
- 采用递归方式
|
|
堆排序
- 无序数组构建二叉堆
- 从小到大排序,用最大堆
- 从大到小排序,用最小堆
- 循环删除堆顶元素,替换到二叉堆的末尾,堆顶下沉产生新的堆顶。
- 注意点,二叉堆的创建函数,输入参数要多加一个长度,避免array[:i]创建了新的数组输入,没有在原数组上更改
|
|
计数排序
- 是一种非比较排序,是按数组下标来进行排序
- 步骤:(以下是优化版本,得出的排序是一种稳定排序)
- 求数组最大最小值,得出数组长度max-min+1
- 创建统计数组,统计对应元素个数,注意min作为偏移量
- 统计数组变形,后面元素等于前面元素之和
- 倒序遍历原始数组,从统计数组找到正确位置,输出排序数组
|
|
桶排序
- 可以进行小数的排序,克服计数排序只能进行整数排序的缺点
- 重点在于标号的计算,向下取整得出桶的序号
- 我们这种分法:
- 桶的数量等于原数组元素的数量
- 最后一个桶只有最大值
- 区间跨度=(max-min)/(桶的数量-1)
- 例如
- [0.5,1.5), [1.5,2.5), [2.5,3.5), [3.5,4.5), [4.5,4.5]
|
|
基数排序
-
思路:整数按位数切割成不同的数字,然后按每个位数分别比较。基数排序的方式可以采用LSD(Least significant digital)或MSD(Most significant digital),LSD的排序方式由键值的最右边开始,而MSD则相反,由键值的最左边开始。
-
MSD:先从高位开始进行排序,在每个关键字上,可采用计数排序(计数排序其实也是桶排序)
-
LSD:先从低位开始进行排序,在每个关键字上,可采用桶排序
-
注意,内部排序的方式一定是稳定排序,不然结果会出错,所以用计数排序和桶排序
-
MSD的方式由高位数为基底开始进行分配,但在分配之后并不马上合并回一个数组中,而是在每个“桶子”中建立“子桶”,将每个桶子中的数值按照下一数位的值分配到“子桶”中。在进行完最低位数的分配后再合并回单一的数组中。
-
LSD:不需要子桶排序
|
|
-
MSD:最高位优先法通常是一个递归的过程:
<1>先根据最高位关键码K1排序,得到若干对象组,对象组中每个对象都有相同关键码K1。
<2>再分别对每组中对象根据关键码K2进行排序,按K2值的不同,再分成若干个更小的子组,每个子组中的对象具有相同的K1和K2值。
<3>依此重复,直到对关键码Kd完成排序为止。
<4>最后,把所有子组中的对象依次连接起来,就得到一个有序的对象序列。
|
|