数组 vector
-
找出数组中重复的数字。在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。
-
思路1:使用哈希表,时间复杂度
O(n),空间复杂度也是O(n)。 -
思路2:原地交换,一直往前走,当i与之前的重复了,说明重复了,退出。时间复杂度
O(n),空间复杂度是O(1)。 -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19class Solution { public: int findRepeatNumber(vector<int>& nums) { int i = 0; int n = nums.size(); while(i<n){ if(nums[i]==i){ ++i;//只有这一步才加 continue; } if(nums[i]==nums[nums[i]]){ return nums[i]; } //否则固定i,持续交换 swap(nums[i],nums[nums[i]]); } return 0; } };
杨辉三角
-
给定一个非负整数 *
numRows,*生成「杨辉三角」的前numRows行。在「杨辉三角」中,每个数是它左上方和右上方的数的和
-
思路:暴力迭代
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17class Solution { public: vector<vector<int>> generate(int numRows) { vector<vector<int>> ret(numRows); ret[0]={1}; for(int i=1;i<numRows;++i){ vector<int> row(i+1); row[0]=1; row[i]=1; for(int j =1;j<i;++j){ row[j]=ret[i-1][j]+ret[i-1][j-1]; } ret[i]=row; } return ret; } };
螺旋矩阵
-
给你一个正整数
n,生成一个包含1到n2所有元素,且元素按顺时针顺序螺旋排列的n x n正方形矩阵matrix。 -
思路:因为返回一个正矩阵,只需要模拟一直螺旋下去就好了
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49class Solution { public: vector<vector<int>> generateMatrix(int n) { vector<vector<int>> ret(n,vector<int>(n,0)); int stratRow = 0; int startCol = 0; int count = n/2;//圈数,循环次数 int mid = n/2;//最中间的值 int offset = 1;//偏移量 int k = 1;//赋值的数 while(count--){ int i = stratRow; int j = startCol; //1,从左到右 while(j<n-offset){ ret[i][j]=k; ++k; ++j; } //2.从上到下 while(i<n-offset){ ret[i][j]=k; ++k; ++i; } //3.从右往左 while(j>=offset){ ret[i][j]=k; ++k; --j; } //4.从上往下 while(i>=offset){ ret[i][j]=k; ++k; --i; } offset+=1; stratRow+=1; startCol+=1; } if(n%2!=0){ ret[mid][mid]=k; } return ret; } }; -
给你一个
m行n列的矩阵matrix,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。 -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64class Solution { public: vector<int> spiralOrder(vector<vector<int>>& matrix) { vector<int> ret; int rows = matrix.size(); int cols = matrix[0].size(); int startrow = 0; int startcol = 0; int offset = 1; int mid = rows/2; int n = min((rows+1)/2,(cols+1)/2);//循环次数,注意要+1除以2,多加一次 while(n--){ int i = startrow; int j = startcol; //可以不加判断单行或者单列,但是需要付出一个矩阵的空间判断是否已经读取这个数据了 //判断只有一列 if(j==cols-offset){ //从上到下 while(i<=rows-offset){ ret.emplace_back(matrix[i][j]); ++i; } break; } //判断只有一行 if(i==rows-offset){ //从左到右 while(j<=cols-offset){ ret.emplace_back(matrix[i][j]); ++j; } break; } //从左到右 while(j<cols-offset){ ret.emplace_back(matrix[i][j]); ++j; } //从上到下 while(i<rows-offset){ ret.emplace_back(matrix[i][j]); ++i; } //从右到左 while(j>=offset){ ret.emplace_back(matrix[i][j]); --j; } //从下到上 while(i>=offset){ ret.emplace_back(matrix[i][j]); --i; } offset++; startcol++; startrow++; } return ret; } }; -
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
说明:
你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
- 思路:优化算法是位运算——异或
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36class Solution { public: int singleNumber(vector<int>& nums) { // //思路1:使用哈希表记录个数,最后遍历哈希找次数为1 // unordered_map<int,int> record; // for(auto &i:nums){ // record[i]++; // } // for(auto &i:record){ // if(i.second==1){ // return i.first; // } // } // return nums[nums.size()-1]; // //思路2:使用哈希,不过不记录数组,如果包含就去除,最后剩下的数就是了 // unordered_set<int> record; // for(auto &i:nums){ // if(record.count(i)){ // record.erase(i); // }else{ // record.insert(i); // } // } // return *record.begin(); //思路3:使用异或运算 int ret=0; for(auto&i:nums){ ret^=i; } return ret; } }; -
给定一个大小为 n 的数组,找到其中的多数元素。多数元素是指在数组中出现次数 大于
⌊ n/2 ⌋的元素。你可以假设数组是非空的,并且给定的数组总是存在多数元素。
-
存在三种思路:
-
哈希表计数
-
排序之后的n/2个元素,下标从0开始
-
Boyer-Moore 投票算法

证明:当存在大于n/2个元素的众数:当候选人不是众数时,会和其他非候选人一起反对候选人,所以候选人一定会下台(count==0时发生换届选举;候选人是众数,会支持自己,因为自己大于n/2,一定会当选成功。
注意,只能有一个大于n/2,如果有多个,会宣传其中一个。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41class Solution { public: int majorityElement(vector<int>& nums) { // //思路1:哈希表计数 // int n=nums.size(); // unordered_map<int,int> record; // for(auto &i:nums){ // record[i]++; // if(record[i]>n/2){ // return i; // } // } // return nums[n-1]; // //思路2:排序之后第n/2个元素就是多数,下标从0开始 // int n=nums.size(); // sort(nums.begin(),nums.end()); // return nums[int(n/2)]; //思路3:莫尔投票算法 int candidate=nums[0]; int count=1; for(int i=1;i<nums.size();++i){ if(count==0){ candidate=nums[i]; count++; continue; } if(nums[i]==candidate){ count++; continue; } if(nums[i]!=candidate){ count--; continue; } } return candidate; } }; -
-
给定一个包含红色、白色和蓝色,一共
n个元素的数组,**原地**对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。此题中,我们使用整数
0、1和2分别表示红色、白色和蓝色。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35class Solution { public: //思路1:依次交换01、02、12 void sort_child(vector<int>&nums, int a, int b){ int n=nums.size(); int left=0; int right=n-1; while(left < right){ while(nums[left]!=a&&left<right){ ++left; } if(left>right){ break; } while(nums[right]!=b&&left<right){ --right; } if(left>right){ break; } int temp=nums[left]; nums[left]=nums[right]; nums[right]=temp; ++left;--right; } } void sortColors(vector<int>& nums) { sort_child(nums, 2, 0); sort_child(nums, 2, 1); sort_child(nums, 1, 0); } };1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21class Solution { public: //思路2:首先把0放到数组首位,然后把1放到后尾 void sortColors(vector<int>& nums) { int n=nums.size(); int ptr=0; for(int i=0;i<n;++i){ if(nums[i]==0){ swap(nums[i], nums[ptr]); ++ptr; } } for(int i=ptr;i<n;++i){ if(nums[i]==1){ swap(nums[i],nums[ptr]); ++ptr; } } } };1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22class Solution { public: //思路3:采用双指针,注意当指向0的时候,如果覆盖了1,要进一步割舍 void sortColors(vector<int>& nums) { int p0=0,p1=0; int n=nums.size(); for(int i=0;i<n;++i){ if(nums[i]==1){ swap(nums[i],nums[p1]); ++p1; }else if(nums[i]==0){ swap(nums[i],nums[p0]); if(p0<p1){ swap(nums[i],nums[p1]); } //不论是否覆盖1,p0和p1都要加1 ++p0; ++p1; } } } }; -
以数组
intervals表示若干个区间的集合,其中单个区间为intervals[i] = [starti, endi]。请你合并所有重叠的区间,并返回一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间。- 思路:区间排序,按区间开头进行排序,相等的话取一个为大,记得最后加还没加上的区间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30class Solution { public: vector<vector<int>> merge(vector<vector<int>>& intervals) { //按区间开始排序,相等取第一个为最大区间 sort(intervals.begin(),intervals.end(),[](auto &a,auto &b){ return (a[0]<b[0])||(a[0]==b[0]&&a[1]>b[1]); }); vector<vector<int>> ret; int n=intervals.size(); int left; int right; vector<int> path(2); path[0]=intervals[0][0]; path[1]=intervals[0][1]; for(int i=1;i<n;++i){ if(path[0]==intervals[i][0]){ continue; }else if(path[0]<intervals[i][0]&&path[1]>=intervals[i][0]){ path[1]=max(path[1],intervals[i][1]); }else if(path[0]<intervals[i][0]&&path[1]<intervals[i][0]){ ret.push_back(path); path[0]=intervals[i][0]; path[1]=intervals[i][1]; } } //加上最后一个区间 ret.push_back(path); return ret; } };
快慢指针
-
给你一个数组
nums和一个值val,你需要 原地 移除所有数值等于val的元素,并返回移除后数组的新长度。不要使用额外的数组空间,你必须仅使用
O(1)额外空间并 原地 修改输入数组。元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
-
思路:快慢指针,当不等于目标时,快指针覆盖慢指针的数,同时快慢指针都向前;否则,只是快指针加1。
-
如果不用快慢指针,使用erase的话,时间复杂度会达到
O(n^2)。 -

-

-

-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15class Solution { public: int removeElement(vector<int>& nums, int val) { int fastIdx = 0; int slowIdx = 0; while(fastIdx<nums.size()){ if(nums[fastIdx]!=val){ nums[slowIdx]=nums[fastIdx]; ++slowIdx; } ++fastIdx; } return slowIdx; } }; -
给定字符串列表
strs,返回 它们中 最长的特殊序列 。如果最长特殊序列不存在,返回-1。最长特殊序列 定义如下:该序列为某字符串 独有的最长子序列(即不能是其他字符串的子序列)。
s的 子序列可以通过删去字符串s中的某些字符实现。- 例如,
"abc"是"aebdc"的子序列,因为您可以删除"aebdc"中的下划线字符来得到"abc"。"aebdc"的子序列还包括"aebdc"、"aeb"和 "" (空字符串)。
- 例如,
-
思路:排序之后,依次暴力比较,使用哈希表进行比较判断
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81class Solution { public: //注意返回false表示不是子序列 bool Check_equal(string &s1, string &s2, int n1, int n2,vector<unordered_map<char,int>> &check){ unordered_map<char,int> temp1 = check[n1]; unordered_map<char,int> temp2 = check[n2]; int t1 = s1.size(); int t2 = s2.size(); int start1 = 0; int start2 = 0; while(start2<t2&&start1<t1){ if(!temp1.count(s2[start2])){ return false; break; } if(temp2[s2[start2]]> temp1[s2[start2]]){ return false; break; } while( start1<t1 && s1[start1]!=s2[start2]){ temp1[s1[start1]]--; ++start1; } if(start1==t1){ return false; break; } temp2[s2[start2]]--; ++start2; temp1[s1[start1]]--; ++start1; } if(start2==t2){ return true; } return false; } int findLUSlength(vector<string>& strs) { int n = strs.size(); sort(strs.begin(),strs.end(),[](string &a1,string &a2)->bool{ return a1.size()>a2.size(); }); if(strs[0].size()>strs[1].size()){ return strs[0].size(); } //初始化哈希 vector<unordered_map<char,int>> check(n); for(int i =0;i<n;++i){ string temp =strs[i]; for(int j =0;j<temp.size();++j){ check[i][temp[j]]++; } } //依次遍历 int last =0; for(int i =0;i<n;++i){ while(last<n&&strs[last].size()==strs[i].size()){ ++last; } bool tet=false; for(int j=0;j<last;++j){ if(j==i){ continue; } bool tet1 = Check_equal(strs[j], strs[i], j, i, check); tet=tet||tet1; if(tet){ break; } } if(!tet){ return strs[i].size(); } } return -1; } };
链表 ListNode
-
定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。
-
思路1:迭代法
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode(int x) : val(x), next(NULL) {} * }; */ class Solution { public: ListNode* reverseList(ListNode* head) { //双指针 if(!head){ return head; } ListNode *pre = nullptr; ListNode *curr = head; while(curr){ ListNode * temp = curr->next; curr->next = pre; pre = curr; curr = temp; } return pre; } }; -
思路2:递归法——确定递归返回值、递归结束函数。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode(int x) : val(x), next(NULL) {} * }; */ class Solution { public: ListNode* reverse(ListNode *pre, ListNode* curr){ if(!curr){ return pre; } ListNode* temp = curr->next; curr->next = pre; pre = curr; curr = temp; return reverse(pre,curr); } ListNode* reverseList(ListNode* head) { //虚拟头结点 //双指针 ListNode *pre = nullptr; ListNode *curr = head; return reverse(pre, curr); } }; -
给你一个链表的头节点
head和一个整数val,请你删除链表中所有满足Node.val == val的节点,并返回 新的头节点 。 -
思路1:设置虚拟头结点,迭代
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ class Solution { public: ListNode* removeElements(ListNode* head, int val) { ListNode* curr; ListNode* pre; ListNode* vlPtr = new ListNode(0,head); curr = head; pre = vlPtr; while(curr){ if(curr->val==val) pre->next=curr->next; else pre = curr; curr = curr->next; } curr = vlPtr->next; delete vlPtr; vlPtr = nullptr; return curr; } }; -
思路2:递归。判断头结点是否为空,空则返回,然后递归得出next指针。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ class Solution { public: ListNode* removeElements(ListNode* head, int val) { if(head==nullptr){ return head; } head->next = removeElements(head->next, val); if(head->val == val){ return head->next; }else{ return head; } } }; -
设计链表的实现。您可以选择使用单链表或双链表。单链表中的节点应该具有两个属性:
val和next。val是当前节点的值,next是指向下一个节点的指针/引用。如果要使用双向链表,则还需要一个属性prev以指示链表中的上一个节点。假设链表中的所有节点都是 0-index 的。在链表类中实现这些功能:
- get(index):获取链表中第
index个节点的值。如果索引无效,则返回-1。 - addAtHead(val):在链表的第一个元素之前添加一个值为
val的节点。插入后,新节点将成为链表的第一个节点。 - addAtTail(val):将值为
val的节点追加到链表的最后一个元素。 - addAtIndex(index,val):在链表中的第
index个节点之前添加值为val的节点。如果index等于链表的长度,则该节点将附加到链表的末尾。如果index大于链表长度,则不会插入节点。如果index小于0,则在头部插入节点。 - deleteAtIndex(index):如果索引
index有效,则删除链表中的第index个节点。
- get(index):获取链表中第
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94struct LinkNode{ int val; LinkNode * next; LinkNode(){ val = 0; next = nullptr; } LinkNode(int val1){ val = val1; next = nullptr; } LinkNode(int val1,LinkNode* input){ val = val1; next = input; } }; class MyLinkedList { private: int m_len; LinkNode *dummmyNode;//哨兵 public: MyLinkedList() { m_len = 0; dummmyNode = new LinkNode; } int get(int index) { if(index>=m_len||index<0){ return -1; } index++; LinkNode * curr = dummmyNode; while(index--){ curr = curr->next; } return curr->val; } void addAtHead(int val) { LinkNode * tmp = new LinkNode(val); LinkNode * pre = dummmyNode->next; dummmyNode->next = tmp; tmp->next = pre; ++m_len; } void addAtTail(int val) { LinkNode * tmp = new LinkNode(val); LinkNode * pre = dummmyNode; while(pre->next != nullptr){ pre = pre->next; } pre->next = tmp; ++m_len; } void addAtIndex(int index, int val) { if(index<=0){ addAtHead(val); } else if(index==m_len){ addAtTail(val); } else if(index>0&&index<m_len){ LinkNode * tmp = new LinkNode(val); LinkNode * curr = dummmyNode; int count = index; while(count--){ curr=curr->next; } LinkNode * tmp2 = curr->next; curr->next = tmp; tmp->next = tmp2; ++m_len; } } void deleteAtIndex(int index) { if(index>=0&&index<m_len){ m_len--; LinkNode * pre; LinkNode * curr; curr = dummmyNode; while(index--){ curr = curr->next; } pre = curr->next; curr->next = curr->next->next; delete pre; } } }; -
给你单链表的头节点
head,请你反转链表,并返回反转后的链表。 -
1.迭代法
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ class Solution { public: ListNode* reverseList(ListNode* head) { ListNode * pre = nullptr; ListNode * curr = head; ListNode * tmp; while(curr){ tmp = curr->next; curr->next = pre; pre = curr; curr = tmp; } return pre; } }; -
2.递归法
-

-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ class Solution { public: ListNode* reverseList(ListNode* head) { if(!head || !head->next){ return head; } ListNode * newHead = reverseList(head->next); //修改指针 head->next->next = head; head->next = nullptr;//避免链中有环 return newHead;//递归到底部的新链表头 } }; -
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
-
-
1.迭代法
-
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ class Solution { public: ListNode* swapPairs(ListNode* head) { ListNode *dummyNode = new ListNode(0); dummyNode->next = head; ListNode *curr = dummyNode; while(curr->next && curr->next->next){ ListNode * tmp1 = curr->next; ListNode * tmp2 = curr->next->next->next; //更改三个指向 curr->next = tmp1->next; tmp1->next->next = tmp1; tmp1->next = tmp2; //下一次迭代,后移两位 curr = curr->next->next; } return dummyNode->next; } }; -
2.递归法
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24* Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ class Solution { public: ListNode* swapPairs(ListNode* head) { if(!head || !head->next){ return head;//只有一个或者没有,递归结束 } //先保留当前链表下一个节点 ListNode *newHead = head->next; //递归连接两个分开的部分 head->next = swapPairs(newHead->next); //更改指向 newHead->next = head; return newHead; } }; -
给你一个链表,删除链表的倒数第
n个结点,并且返回链表的头结点。 -
思路:使用快慢指针。但是为了代码更加简洁,使用哨兵节点。同时fast和slow走n+1步,最后删除slow的下一个节点即可。返回哨兵节点的下一个节点。
-
拓展其他思路:①遍历两次,第一次读取长度,第二次才是删除操作;②使用栈,后进先出,完全入栈后弹出n个节点即可。和遍历两次大同小异。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ class Solution { public: ListNode* removeNthFromEnd(ListNode* head, int n) { ListNode *dummyNode = new ListNode(0);//哨兵节点 dummyNode->next = head; ListNode* fast = dummyNode; ListNode* slow = dummyNode; //先走n+1步 int count = n+1; while(count--){ fast = fast->next; } while(fast){ slow = slow->next; fast = fast->next; } //删除slow下一个节点 ListNode* tmp = slow->next; slow->next = slow->next->next; delete tmp; tmp = nullptr; return dummyNode->next; } }; -
给你两个单链表的头节点
headA和headB,请你找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回null。图示两个链表在节点
c1开始相交**:** -
-
思路1:使用哈希表判断是否存在重复的链表节点。
-
题意简单来说,就是求两个链表交点节点的指针。 这里需要注意,交点不是数值相等,而是指针相等。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode(int x) : val(x), next(NULL) {} * }; */ class Solution { public: ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) { //似乎c++有默认的针对链表struct的哈希函数、相等判断函数,后期再实验一下 unordered_set<ListNode*> us; ListNode * tmp = headA; while(tmp){ us.insert(tmp); tmp = tmp->next; } ListNode* tmp2 = headB; while(tmp2){ if(us.count(tmp2)){ return tmp2; break; } tmp2 = tmp2->next; } return nullptr; } }; -
思路2:使用双指针,因为如果有交点的话那么末尾一定会相同,那么长的部分先走。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode(int x) : val(x), next(NULL) {} * }; */ class Solution { public: ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) { int lenA = 0; int lenB = 0; ListNode *tmp1 = headA; ListNode *tmp2 = headB; while(tmp1){ ++lenA; tmp1 = tmp1->next; } while(tmp2){ ++lenB; tmp2 = tmp2->next; } tmp1 = headA; tmp2 = headB; //lenA是最长的 if(lenB>lenA){ swap(lenA,lenB); swap(tmp1,tmp2); } int grab = lenA-lenB; while(grab--){ tmp1 = tmp1->next; } while(tmp1){ if(tmp1==tmp2){ return tmp1; break; } tmp1 = tmp1->next; tmp2 = tmp2->next; } return nullptr; } }; -
给定一个链表的头节点
head,返回链表开始入环的第一个节点。 如果链表无环,则返回null。如果链表中有某个节点,可以通过连续跟踪
next指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数pos来表示链表尾连接到链表中的位置(索引从 0 开始)。如果pos是-1,则在该链表中没有环。注意:pos不作为参数进行传递,仅仅是为了标识链表的实际情况。不允许修改 链表。
-
思路:使用floyd判环法
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode(int x) : val(x), next(NULL) {} * }; */ class Solution { public: ListNode *detectCycle(ListNode *head) { ListNode *fast = head; ListNode *slow = head; do{ if(!fast || !fast->next){ return nullptr; } fast = fast->next->next; slow = slow->next; }while(fast!=slow); fast = head; while(fast!=slow){ fast = fast->next; slow = slow->next; } return fast; } };
栈 stack 与 队列 queue
-
输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)。
-
思路1:直接反正数组
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode(int x) : val(x), next(NULL) {} * }; */ class Solution { public: vector<int> reversePrint(ListNode* head) { vector<int> ret; while(head){ ret.push_back(head->val); head=head->next; } reverse(ret.begin(),ret.end()); return ret; } }; -
思路2:递归法
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode(int x) : val(x), next(NULL) {} * }; */ class Solution { public: vector<int> ret; vector<int> reversePrint(ListNode* head) { ret.clear(); dfs(head); return ret; } void dfs(ListNode* head){ if(!head){ return; } dfs(head->next); ret.push_back(head->val); } }; -
思路3:直接使用栈——说明递归的本质就是栈
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode(int x) : val(x), next(NULL) {} * }; */ class Solution { public: vector<int> reversePrint(ListNode* head) { vector<int> ret; stack<int> curr; while(head){ curr.push(head->val); head = head->next; } while(!curr.empty()){ ret.push_back(curr.top()); curr.pop(); } return ret; } }; -
请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(
push、pop、peek、empty):实现
MyQueue类:void push(int x)将元素 x 推到队列的末尾int pop()从队列的开头移除并返回元素int peek()返回队列开头的元素boolean empty()如果队列为空,返回true;否则,返回false
说明:
- 你 只能 使用标准的栈操作 —— 也就是只有
push to top,peek/pop from top,size, 和is empty操作是合法的。 - 你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
-
思路:使用两个栈,一个入栈,一个出栈;出栈为空的时候倒入栈,不为空就继续操作
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52class MyQueue { private: stack<int> InSrc; stack<int> OutSrc; public: MyQueue() { while(!InSrc.empty()){ InSrc.pop(); } while(!OutSrc.empty()){ OutSrc.pop(); } } void push(int x) { InSrc.push(x); } int pop() { if(OutSrc.empty()){ while(!InSrc.empty()){ int temp = InSrc.top(); OutSrc.emplace(temp); InSrc.pop(); } } int temp = OutSrc.top(); OutSrc.pop(); return temp; } int peek() { if(OutSrc.empty()){ while(!InSrc.empty()){ int temp = InSrc.top(); OutSrc.emplace(temp); InSrc.pop(); } } int temp = OutSrc.top(); return temp; } bool empty() { if(InSrc.empty() && OutSrc.empty()){ return true; } return false; } }; -
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
-
这是一道栈的模板题。
-
注意编程技巧——哨兵思路,即在开头末尾都加一个节点减少判断的条件,增强代码可读性和理解性。
-
思路一:暴力解法:固定高度,查找底的大小进而推出面积
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42class Solution { public: //思路:暴力解法,底乘高,固定高 void FindBoard(vector<int> &dp,int target, int &left, int &right){ for(int i=target-1;i>=0;--i){ if(dp[i]<dp[target]){ left=i; break; } } for(int i=target+1;i<dp.size();++i){ if(dp[i]<dp[target]){ right=i; break; } } } int largestRectangleArea(vector<int>& heights) { int n=heights.size(); vector<int> dp(n+2,-1); //初始化,前后加哨兵 for(int i=1;i<=n;++i){ dp[i]=heights[i-1]; } //计算面积 int out=0; for(int i=1;i<=n;++i){ if(i>1&&dp[i]==dp[i-1]){ continue; } int left=0; int right=0; FindBoard(dp, i, left, right); int wid=right-left-1; int area=wid*dp[i]; out=max(out,area); } return out; } };
-
-
思路二:使用栈stack,单调栈
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38class Solution { public: int largestRectangleArea(vector<int>& heights) { stack<pair<int,int>> dp;//1:高度;2:位置 int n=heights.size(); vector<int> srcHeight(n+2,-1);//头尾加入哨兵 int ret=0; for(int i=1;i<n+1;++i){ srcHeight[i]=heights[i-1]; } dp.emplace(srcHeight[0],0); int idx=1; while(!dp.empty()&&idx<n+2){ auto temp=dp.top(); //如果是等于,更新idx if(srcHeight[idx]==temp.first){ //更新idx dp.pop(); dp.emplace(srcHeight[idx],idx); ++idx; } //大于栈顶元素,入栈 else if(srcHeight[idx]>temp.first){ dp.emplace(srcHeight[idx],idx); ++idx; } //小于栈顶元素,出栈,计算面积 else if(srcHeight[idx]<temp.first){ dp.pop(); //前后的长度相加就是底部的宽度 int area1=temp.first*((idx-temp.second)+(temp.second-dp.top().second)-1); ret=max(ret,area1); } } return ret; } };
-
-
给定一个仅包含
0和1、大小为rows x cols的二维二进制矩阵,找出只包含1的最大矩形,并返回其面积。-
思路:单调栈;每一行都是一个单调栈。
-
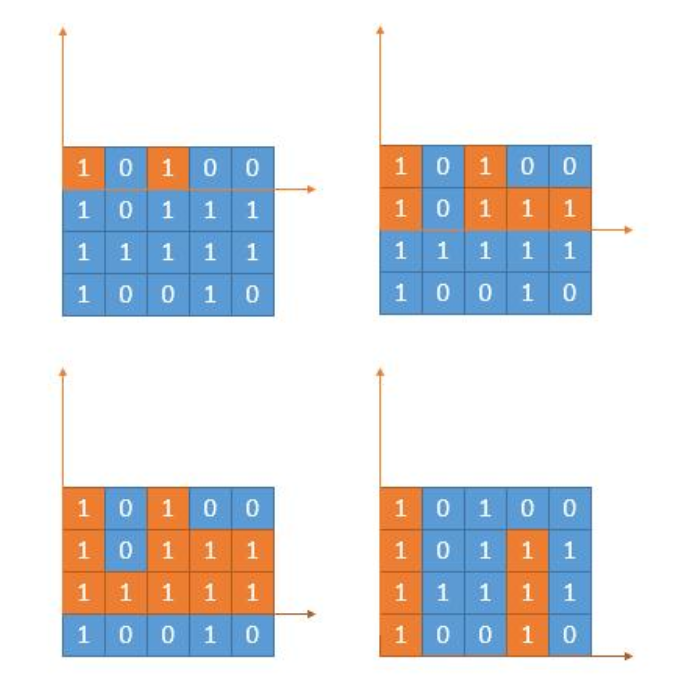
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61class Solution { public: int FindArea(vector<vector<int>> &dp, int targetRow, int cols){ vector<int> now(cols+2,-1); for(int i=1;i<cols+1;++i){ now[i]=dp[targetRow][i-1]; } stack<pair<int,int>> area;//1:高度;2:idx area.emplace(-1,0); int idx=1; int ret=0; while(!area.empty()&&idx<cols+2){ auto temp=area.top(); //高度相等,更新序号 if(temp.first==now[idx]){ area.top().second=idx; ++idx; } //高度大于,入栈 else if(temp.first<now[idx]){ area.emplace(now[idx],idx); ++idx; } //高度小于,出栈,求面积 else if(temp.first>now[idx]){ area.pop(); int calArea=temp.first*((idx-temp.second)+(temp.second-area.top().second)-1); ret=max(ret,calArea); } } return ret; } int maximalRectangle(vector<vector<char>>& matrix) { int rows=matrix.size(); int cols=matrix[0].size(); vector<vector<int>> dp(rows,vector<int>(cols,0)); //初始化柱状图 for(int i=0;i<cols;++i){ if(matrix[0][i]=='1'){ dp[0][i]=1; } } for(int i=1;i<rows;++i){ for(int j=0;j<cols;++j){ if(matrix[i][j]=='1'){ dp[i][j]=dp[i-1][j]+1; } } } //单调栈 int out=0; for(int i=0;i<rows;++i){ int ret=FindArea(dp,i,cols); out=max(out,ret); } return out; } };
-
-
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(
push、top、pop和empty)。实现
MyStack类:void push(int x)将元素 x 压入栈顶。int pop()移除并返回栈顶元素。int top()返回栈顶元素。boolean empty()如果栈是空的,返回true;否则,返回false。
注意:
- 你只能使用队列的基本操作 —— 也就是
push to back、peek/pop from front、size和is empty这些操作。 - 你所使用的语言也许不支持队列。 你可以使用 list (列表)或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51class MyStack { public: queue<int> m_in; queue<int> m_out; MyStack() { } void push(int x) { if(m_out.empty()){ m_in.push(x); }else{ m_out.push(x); } } int pop() { int ret; if(m_out.empty()){ while(m_in.size()!=1){ m_out.push(m_in.front()); m_in.pop(); } ret = m_in.front(); m_in.pop(); return ret; }else{ while(m_out.size()!=1){ m_in.push(m_out.front()); m_out.pop(); } ret = m_out.front(); m_out.pop(); return ret; } } int top() { if(m_out.empty()){ return m_in.back(); }else{ return m_out.back(); } } bool empty() { return m_in.empty()&&m_out.empty(); } }; -
给你一个整数数组
nums,有一个大小为k的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的k个数字。滑动窗口每次只向右移动一位。返回 滑动窗口中的最大值 。
-
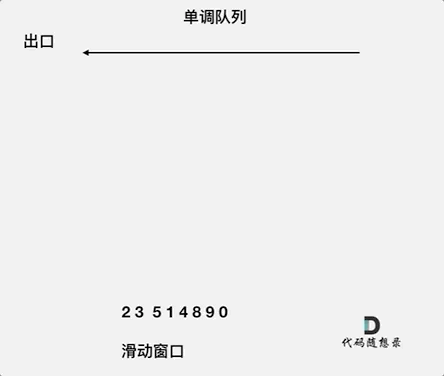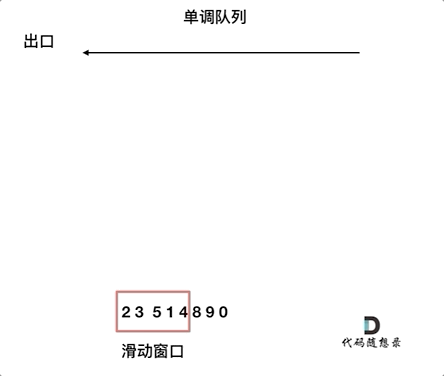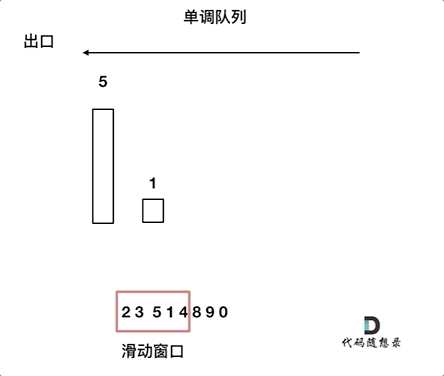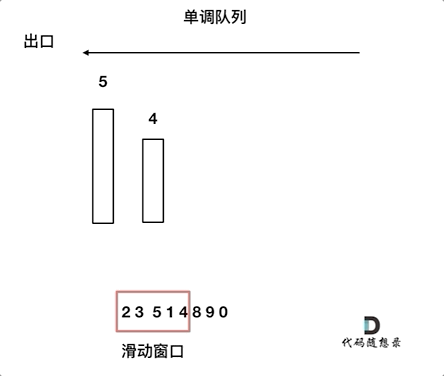
思路:使用双端队列,生成单调队列
-
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30class Solution { public: vector<int> maxSlidingWindow(vector<int>& nums, int k) { //使用单调队列 deque<int> qe; for(int i = 0;i<k;++i){ //一直删除 while(!qe.empty() && nums[i]>qe.back()){ qe.pop_back(); } qe.push_back(nums[i]); } vector<int> ret; ret.push_back(qe.front()); int n = nums.size(); for(int i = k;i<n;++i){ //先删除 if(nums[i-k]==qe.front()){ qe.pop_front(); } //然后插入 while((!qe.empty()) && (nums[i]>qe.back())){ qe.pop_back(); } qe.push_back(nums[i]); ret.push_back(qe.front()); } return ret; } }; -
给你一个整数数组
nums和一个整数k,请你返回其中出现频率前k高的元素。你可以按 任意顺序 返回答案。 -
思路:使用哈希表计数,优先队列弹出k个
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28struct cmp{ //大顶堆 bool operator()(const pair<int,int> &a1, const pair<int,int> &a2){ return a1.second<a2.second; } }; class Solution { public: vector<int> topKFrequent(vector<int>& nums, int k) { vector<int> ret; unordered_map<int,int> um; for(auto &i:nums){ um[i]++; } //使用优先队列是最优的 priority_queue<pair<int,int>,vector<pair<int,int>>,cmp> qp; for(auto &i:um){ qp.emplace(pair<int,int>(i.first,i.second)); } for(int i = 0;i<k;++i){ auto k = qp.top(); qp.pop(); ret.push_back(k.first); } return ret; } };
哈希表 set/map
-
给定两个字符串
*s*和*t*,编写一个函数来判断*t*是否是*s*的字母异位词。注意: 若
*s*和*t*中每个字符出现的次数都相同,则称*s*和*t*互为字母异位词。 -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19class Solution { public: bool isAnagram(string s, string t) { int sret[26]; memset(sret,0,26*sizeof(int)); for(auto &i:s){ sret[i-'a']++; } for(auto &i:t){ sret[i-'a']--; } for(auto &i:sret){ if(i!=0){ return false; } } return true; } }; -
给定两个数组
nums1和nums2,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。 -
1 2 3 4 5 6 7 8 9 10 11 12 13 14class Solution { public: vector<int> intersection(vector<int>& nums1, vector<int>& nums2) { vector<int> ret; unordered_set<int> numsrc1(nums1.begin(),nums1.end()); unordered_set<int> numsrc2(nums2.begin(),nums2.end()); for(auto &i:numsrc2){ if(numsrc1.count(i)){ ret.emplace_back(i); } } return ret; } }; -
编写一个算法来判断一个数
n是不是快乐数。「快乐数」 定义为:
- 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。
- 然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。
- 如果这个过程 结果为 1,那么这个数就是快乐数。
如果
n是 快乐数 就返回true;不是,则返回false。 -
思路1:使用哈希表判断进入循环。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24class Solution { public: int retHappy(int n){ int ret = 0; while(n>0){ int tmp = n%10; ret += tmp*tmp; n/=10; } return ret; } bool isHappy(int n) { unordered_set<int> us; while(n!=1){ if(us.count(n)){ return false; } us.insert(n); n = retHappy(n); } return true; } }; -
思路2:使用floyd判环法
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28class Solution { public: int retHappy(int n){ int ret = 0; while(n>0){ int tmp = n%10; ret += tmp*tmp; n/=10; } return ret; } bool isHappy(int n) { int fast = n; int slow = n; do{ if(fast == 1){ return true; } fast = retHappy(retHappy(fast)); slow = retHappy(slow); }while(fast!=slow); if(fast == 1){ return true; } return false; } }; -
给定一个整数数组
nums和一个整数目标值target,请你在该数组中找出 和为目标值target的那 两个 整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18class Solution { public: vector<int> twoSum(vector<int>& nums, int target) { vector<int> ret; unordered_map<int,int> um; for(int i = 0;i<nums.size();++i){ if(um.count(nums[i])){ ret.push_back(i); ret.push_back(um[nums[i]]); return ret; } //添加减数 um[target-nums[i]] = i; } return ret; } }; -
给你四个整数数组
nums1、nums2、nums3和nums4,数组长度都是n,请你计算有多少个元组(i, j, k, l)能满足:0 <= i, j, k, l < nnums1[i] + nums2[j] + nums3[k] + nums4[l] == 0
-
分一半,哈希表,时间复杂度最低。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20class Solution { public: int fourSumCount(vector<int>& nums1, vector<int>& nums2, vector<int>& nums3, vector<int>& nums4) { unordered_map<int,int> um; for(int &i:nums1){ for(int &j:nums2){ um[i+j]++; } } int count = 0; for(int &i:nums3){ for(int &j:nums4){ if(um.count(-(i+j))){ count += um[-(i+j)]; } } } return count; } }; -
给你两个字符串:
ransomNote和magazine,判断ransomNote能不能由magazine里面的字符构成。如果可以,返回
true;否则返回false。magazine中的每个字符只能在ransomNote中使用一次。 -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18class Solution { public: bool canConstruct(string ransomNote, string magazine) { int src[26]; memset(src,0,26*sizeof(int)); for(auto &i:magazine){ src[i-'a']++; } for(auto &i:ransomNote){ src[i-'a']--; if(src[i-'a']<0){ return false; } } return true; } }; -
给你一个包含
n个整数的数组nums,判断nums中是否存在三个元素 a,b,c , 使得 a + b + c = 0 ?请你找出所有和为0且不重复的三元组。注意: 答案中不可以包含重复的三元组。
-
思路:这种情况不适于使用哈希表。使用排序+双指针。注意去重。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51class Solution { public: vector<vector<int>> threeSum(vector<int>& nums) { vector<vector<int>> ret; if(nums.size()<3){ return ret; } sort(nums.begin(),nums.end()); int len = nums.size()-1; for(int i = 0;i<nums.size()-2;++i){ if(nums[i]>0){ break; } //去除a重复 if(i>0&&nums[i]==nums[i-1]){ continue; } int left = i+1; int right = len; while(left<right){ if(nums[i]+nums[left]+nums[right]==0){ vector<int> tmp{nums[i],nums[left],nums[right]}; ret.emplace_back(tmp); ++left; //去重b重复 while(nums[left]==nums[left-1]&&left<right){ ++left; } --right; //去重c重复 while(nums[right]==nums[right+1]&&left<right){ --right; } }else if(nums[i]+nums[left]+nums[right]>0){ --right; //去重c重复 while(nums[right]==nums[right+1]&&left<right){ --right; } }else{ ++left; //去重b重复 while(nums[left]==nums[left-1]&&left<right){ ++left; } } } } return ret; } }; -
给你一个由
n个整数组成的数组nums,和一个目标值target。请你找出并返回满足下述全部条件且不重复的四元组[nums[a], nums[b], nums[c], nums[d]](若两个四元组元素一一对应,则认为两个四元组重复):0 <= a, b, c, d < na、b、c和d互不相同nums[a] + nums[b] + nums[c] + nums[d] == target
你可以按 任意顺序 返回答案 。
-
类似的双指针,但是注意数据溢出,同时注意问题。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52class Solution { public: vector<vector<int>> fourSum(vector<int>& nums, int target) { vector<vector<int>> ret; int len = nums.size(); if(len<4){ return ret; } sort(nums.begin(),nums.end()); for(int i = 0;i<=len-4;++i){ //a除重 if(i>0 && nums[i]==nums[i-1]){ continue; } for(int j = i+1;j<=len-3;++j){ //b除重 if(j>i+1&&nums[j]==nums[j-1]){ continue; } int left = j+1; int right = len-1; while(left<right){ //该条件判断会溢出 //nums[left]+nums[right]+nums[j]+nums[i]==target if((long)nums[left]+nums[right]+nums[j]+nums[i]==target){ ret.emplace_back(vector<int>{nums[left],nums[right],nums[i],nums[j]}); ++left; while(left<right&&nums[left]==nums[left-1]){ ++left; } --right; while(left<right&&nums[right]==nums[right+1]){ --right; } } else if((long)nums[left]+nums[right]+nums[j]+nums[i]<target){ ++left; while(left<right&&nums[left]==nums[left-1]){ ++left; } }else{ --right; while(left<right&&nums[right]==nums[right+1]){ --right; } } } } } return ret; } }; -
请你判断一个
9 x 9的数独是否有效。只需要 根据以下规则 ,验证已经填入的数字是否有效即可。- 数字
1-9在每一行只能出现一次。 - 数字
1-9在每一列只能出现一次。 - 数字
1-9在每一个以粗实线分隔的3x3宫内只能出现一次。(请参考示例图)
注意:
- 一个有效的数独(部分已被填充)不一定是可解的。
- 只需要根据以上规则,验证已经填入的数字是否有效即可。
- 空白格用
'.'表示。
- 数字
-
思路1:直接遍历3次,哈希判断
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50class Solution { public: bool isValidSudoku(vector<vector<char>>& board) { //先横 for(int i =0;i<9;++i){ unordered_set<char> check; for(int col = 0;col<9;++col){ if(board[i][col]=='.'){ continue; }else if(check.count(board[i][col])){ return false; }else{ check.insert(board[i][col]); } } } //后竖 for(int i =0;i<9;++i){ unordered_set<char> check; for(int row = 0;row<9;++row){ if(board[row][i]=='.'){ continue; }else if(check.count(board[row][i])){ return false; }else{ check.insert(board[row][i]); } } } //小 for(int i=0;i<9;++i){ unordered_set<char> check; int rows = 3*(i/3+1); int cols=3*(i%3+1); for(int row = rows-3;row<rows;++row){ for(int col = cols-3;col<cols;++col){ if(board[row][col]=='.'){ continue; }else if(check.count(board[row][col])){ return false; }else{ check.insert(board[row][col]); } } } } return true; } }; -
思路2:只遍历一次,每个1-9的数字设置数组,记录个数,个数 >1 即为错误。
-

-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27class Solution { public: bool isValidSudoku(vector<vector<char>>& board) { int rows[9][9]; int columns[9][9]; int subboxes[3][3][9]; memset(rows,0,sizeof(rows)); memset(columns,0,sizeof(columns)); memset(subboxes,0,sizeof(subboxes)); for (int i = 0; i < 9; i++) { for (int j = 0; j < 9; j++) { char c = board[i][j]; if (c != '.') { int index = c - '0' - 1; rows[i][index]++; columns[j][index]++; subboxes[i / 3][j / 3][index]++; if (rows[i][index] > 1 || columns[j][index] > 1 || subboxes[i / 3][j / 3][index] > 1) { return false; } } } } return true; } }; -
给你两个数组,
arr1和arr2,arr2中的元素各不相同,arr2中的每个元素都出现在arr1中。对
arr1中的元素进行排序,使arr1中项的相对顺序和arr2中的相对顺序相同。未在arr2中出现过的元素需要按照升序放在arr1的末尾。 -
思路1:使用哈希判断个数,不能哈希的按原本大小排序
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40class Solution { public: vector<int> relativeSortArray(vector<int>& arr1, vector<int>& arr2) { int n1 = arr1.size(); int n2 = arr2.size(); vector<int> end1; unordered_map<int,int> checkn1; unordered_set<int> checkn2; for(int i=0;i<n2;++i){ checkn2.insert(arr2[i]); } for(int i =0;i<n1;++i){ int temp = arr1[i]; if(checkn2.count(temp)){ checkn1[temp]++; }else{ end1.push_back(temp); } } vector<int> ret(n1); int count =0; for(int i =0;i<n2;++i){ int flag = arr2[i]; if(checkn1.count(flag)){ int nn = checkn1[flag]; while(nn>0){ ret[count] = flag; ++count; --nn; } } } sort(end1.begin(), end1.end()); for(auto &a1:end1){ ret[count]=a1; ++count; } return ret; } }; -
思路2,自定义排序函数,分三种情况
- 都在哈希表里面,使用映射小的
- 都不在哈希表里面,按原本大小排序
- 其他情况,哈希的在前面
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25class Solution { public: vector<int> relativeSortArray(vector<int>& arr1, vector<int>& arr2) { int n1 = arr1.size(); int n2 = arr2.size(); unordered_map<int,int> checkn1; for(int i = 0;i<n2;++i){ checkn1[arr2[i]] = i; } sort(arr1.begin(),arr1.end(),[&](int &a1, int &a2)->bool{ if(checkn1.count(a1)&&checkn1.count(a2)){ return checkn1[a1]<checkn1[a2]; }else if(!checkn1.count(a1)&&!checkn1.count(a2)){ return a1<a2; }else{ if(checkn1.count(a1)){ return true; }else{ return false; } } }); return arr1; } }; -
设计一个数字容器系统,可以实现以下功能:
- 在系统中给定下标处 插入 或者 替换 一个数字。
- 返回 系统中给定数字的最小下标。
请你实现一个
NumberContainers类:NumberContainers()初始化数字容器系统。void change(int index, int number)在下标index处填入number。如果该下标index处已经有数字了,那么用number替换该数字。int find(int number)返回给定数字number在系统中的最小下标。如果系统中没有number,那么返回-1。
-
难点是想好用两个map,重点是数据结构的问题。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36class NumberContainers { public: unordered_map<int,set<int>> m_numbers;//保存数字的所有下标,set排序 unordered_map<int,int> m_index;//某一下标的数字,类似数组 NumberContainers() { } void change(int index, int number) { if(m_index.count(index)){ //erase之后,count还是存在,只是size等于0了 m_numbers[m_index[index]].erase(index); m_index[index] = number; m_numbers[number].insert(index); }else{ m_index[index] = number; m_numbers[number].insert(index); } } int find(int number) { //一定要用size,不能用count,因为erase后,还是可以count,只是size==0了 if(m_numbers[number].size()){ return *(m_numbers[number].begin()); }else{ return -1; } } }; /** * Your NumberContainers object will be instantiated and called as such: * NumberContainers* obj = new NumberContainers(); * obj->change(index,number); * int param_2 = obj->find(number); */ -
给你一个下标从 0 开始、大小为
n x n的整数矩阵grid,返回满足Ri行和Cj列相等的行列对(Ri, Cj)的数目*。*如果行和列以相同的顺序包含相同的元素(即相等的数组),则认为二者是相等的。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33class Solution { public: int equalPairs(vector<vector<int>>& grid) { int n = grid.size(); int ret = 0; //用哈希表进行查找是最优选择 unordered_map<string,int> um; for(int row=0;row<n;++row){ string s; for(int j=0;j<n;++j){ string tmp = to_string(grid[row][j]); s+=tmp; s+=","; } s.pop_back(); um[s]++; } //求列 for(int row=0;row<n;++row){ string s; for(int j=0;j<n;++j){ string tmp = to_string(grid[j][row]); s+=tmp; s+=","; } s.pop_back(); if(um.count(s)){ ret+=um[s]; } } return ret; } }; -

-
哈希表,可以使用
set<pair<int,string>>进行排序。 -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34class FoodRatings { public: unordered_map<string,pair<int,string>> food2cui2rat;//食物对应的评分及烹饪方式 unordered_map<string,set<pair<int,string>>> cur2rat2food;//烹饪方式对应的评分及食物。 FoodRatings(vector<string>& foods, vector<string>& cuisines, vector<int>& ratings) { int n = foods.size(); for(int i=0;i<n;++i){ food2cui2rat[foods[i]] = pair<int,string>{ratings[i],cuisines[i]}; //注意添加负号,因为是从小到大 cur2rat2food[cuisines[i]].insert(pair<int,string>{-ratings[i],foods[i]}); } } void changeRating(string food, int newRating) { auto &i = food2cui2rat[food]; int tmp = i.first; string tmp2 = i.second; food2cui2rat[food] = pair<int,string>{newRating,tmp2}; //注意添加负号 cur2rat2food[tmp2].erase(pair<int,string>{-tmp,food}); cur2rat2food[tmp2].insert(pair<int,string>{-newRating,food}); } string highestRated(string cuisine) { return cur2rat2food[cuisine].begin()->second; } }; /** * Your FoodRatings object will be instantiated and called as such: * FoodRatings* obj = new FoodRatings(foods, cuisines, ratings); * obj->changeRating(food,newRating); * string param_2 = obj->highestRated(cuisine); */
字符串 string
-
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组
s的形式给出。不要给另外的数组分配额外的空间,你必须**原地修改输入数组**、使用 O(1) 的额外空间解决这一问题。
-
1 2 3 4 5 6 7 8 9 10 11 12 13class Solution { public: void reverseString(vector<char>& s) { int len = s.size(); int left = 0; int right = len -1; while(left<right){ swap(s[left],s[right]); ++left; --right; } } }; -

-
给定一个字符串
s和一个整数k,从字符串开头算起,每计数至2k个字符,就反转这2k字符中的前k个字符。- 如果剩余字符少于
k个,则将剩余字符全部反转。 - 如果剩余字符小于
2k但大于或等于k个,则反转前k个字符,其余字符保持原样。
- 如果剩余字符少于
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33class Solution { public: void reverseSS(string &s, int start, int end){ int left = start; int right = end; while(left<right){ swap(s[left],s[right]); ++left; --right; } } string reverseStr(string s, int k) { int n = s.size(); int count = n/2/k; int i = 0; string ret = s; while(count--){ //reverseSS(ret, i, i+k-1); reverse(ret.begin()+i,ret.begin()+i+k);//注意是前开后闭,所以,不用减1 i = i+2*k; n-=2*k; } if(n>=k){ reverse(ret.begin()+i,ret.begin()+i+k); // reverseSS(ret, i, i+k-1); }else{ reverse(ret.begin()+i,ret.end()); // reverseSS(ret, i, s.size()-1); } return ret; } }; -
请实现一个函数,把字符串
s中的每个空格替换成"%20"。 -
思路1:开辟新空间
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14class Solution { public: string replaceSpace(string s) { string ret; for(auto &i:s){ if(i==' '){ ret+="%20"; }else{ ret.push_back(i); } } return ret; } }; -
思路2:原地resize增加数组大小后,从后面开始双指针。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31class Solution { public: string replaceSpace(string s) { int count = 0; int lenOld = s.size(); for(auto &i:s){ if(i==' '){ ++count; } } s.resize(lenOld+2*count); int first = lenOld-1; int second = lenOld+2*count-1; while(first>=0){ if(s[first]!=' '){ s[second] = s[first]; --first; --second; }else{ s[second] = '0'; --second; s[second] = '2'; --second; s[second] = '%'; --second; --first; } } return s; } }; -
给你一个字符串
s,颠倒字符串中 单词 的顺序。单词 是由非空格字符组成的字符串。
s中使用至少一个空格将字符串中的 单词 分隔开。返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
**注意:**输入字符串
s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。 -
思路1:使用栈stack,同时遍历一遍,开辟新的内存空间。
-
在C++中string没有直接的分割函数,可以利用C语言的stroke函数封装一个分割方法;利用分割函数最后合并即可。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26class Solution { public: string reverseWords(string s) { stack<string> st; for(int i = 0;i<s.size();++i){ string tmp; while(i<s.size()&&s[i]!=' '){ tmp.push_back(s[i]); ++i; } if(!tmp.empty()){ st.push(tmp); } } string ret; ret += st.top(); st.pop(); while(!st.empty()){ ret += " "; ret += st.top(); st.pop(); } return ret; } }; -
思路2:原地修改,不用额外空间。解题思路如下:
- 移除多余空格
- 将整个字符串反转
- 将每个单词反转
举个例子,源字符串为:"the sky is blue "
- 移除多余空格 : "the sky is blue"
- 字符串反转:"eulb si yks eht"
- 单词反转:"blue is sky the"
-
不要用
erase删除多余空格,因为时间复杂度是O(n^2)。 -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49class Solution { public: void removeExtraEmpty(string &s){ int len = s.size(); int fast = 0; int slow = 0; //思路:快慢指针 //删除所有空格,同时在单词中间补上空格 while(fast<len){ //遇到非空格才处理 if(s[fast]!=' '){ //在单词前补上空格,非第一个 if(slow!=0){ s[slow] = ' '; ++slow; } //读完这一个单词 while(fast<len &&s[fast]!=' '){ s[slow] = s[fast]; ++slow; ++fast; } } ++fast; } //修改长度 s.resize(slow); } string reverseWords(string s) { //删除多余空格 removeExtraEmpty(s); //反转所有单词 reverse(s.begin(), s.end()); //反转单个单词 int start = 0; int len = s.size(); while(start<len){ int left =start; while(start<len&&s[start]!=' '){ ++start; } reverse(s.begin()+left, s.begin()+start); ++start; } return s; } }; -
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串"abcdefg"和数字2,该函数将返回左旋转两位得到的结果"cdefgab"。
-
思路1:开辟新的内存空间储存
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25class Solution { public: string reverseLeftWords(string s, int n) { int len = s.size(); string tmp; tmp.resize(n); for(int i =0;i<n;++i){ tmp[i] = s[i]; } int left = 0; int right = n; while(right<len){ s[left] = s[right]; ++left; ++right; } right =0; while(left<len){ s[left] = tmp[right]; ++left; ++right; } return s; } }; -
思路2:原地变换,多次反转。
-
具体步骤为:
- 反转区间为前n的子串
- 反转区间为n到末尾的子串
- 反转整个字符串
-
1 2 3 4 5 6 7 8 9class Solution { public: string reverseLeftWords(string s, int n) { reverse(s.begin(), s.begin()+n); reverse(s.begin()+n, s.end()); reverse(s.begin(), s.end()); return s; } };
KMP 算法
-
基本理论
-
KMP的经典思想就是:当出现字符串不匹配时,可以记录一部分之前已经匹配的文本内容,利用这些信息避免从头再去做匹配。
-
如何记录已经匹配的文本内容,是KMP的重点,也是next数组肩负的重任。
-
next数组本质上就是一个前缀表(prefix table)。
-
前缀表有什么作用呢?
前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。
-
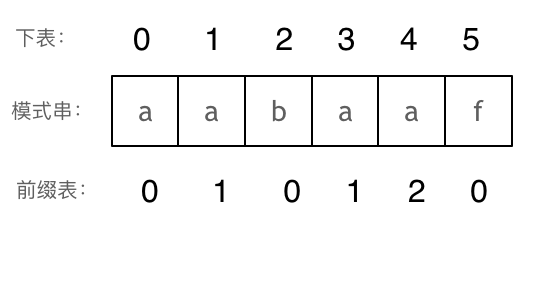
首先搞清楚前后缀的概念。注意不包括开头和结尾这一点。
- 前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串。
- 后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
-
前缀表:记录下标i之前(包括i)的字符串中,有多大长度的相同的前缀和后缀。
-
注意后缀的顺序和前缀的顺序都是从前往后的,而不是倒序,一定要清楚这个定义!
-
-
回到next数组上,很多书本next数组都是前缀表统一减1得出的值。为什么,这里简要总结一下。
- 统一减一,其实不是KMP算法的核心,是一个方便编程的操作。
- 统一减一之后,next数组的回退变成
j = next[j],并且j的初始值为-1。 - 不减1,同样可以实现KMP算法,但是回退的操作是
j = next[j - 1],j的初始值为0。
-
以后记住统一减1的写法。
-
时间复杂度分析
- 假定n为文本串长度,m为模式串长度,因为在匹配的过程中,根据前缀表不断调整匹配的位置,可以看出匹配的过程是O(n),之前还要单独生成next数组,时间复杂度是O(m)。所以整个KMP算法的时间复杂度是O(n+m)的。
- 暴力的解法显而易见是O(n × m),所以KMP在字符串匹配中极大的提高的搜索的效率。
-
生成next数组,统一减1。
-
1 2 3 4 5 6 7 8 9 10 11 12 13void getNext(int* next, const string& s) { int j = -1; next[0] = j; for(int i = 1; i < s.size(); i++) { // 注意i从1开始生成 while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了 j = next[j]; // 向前回退 } if (s[i] == s[j + 1]) { // 找到相同的前后缀 j++; } next[i] = j; // 将j(前缀的长度)赋给next[i] } } -
kmp例子1
-
实现 strStr() 函数。
给你两个字符串
haystack和needle,请你在haystack字符串中找出needle字符串出现的第一个位置(下标从 0 开始)。如果不存在,则返回-1。说明:
当
needle是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。对于本题而言,当
needle是空字符串时我们应当返回 0 。这与 C 语言的 strstr() 以及 Java 的 indexOf() 定义相符。 -
使用kmp算法
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38class Solution { public: void getNext(int* next, const string& s) { int j = -1; next[0] = j; for(int i = 1; i < s.size(); i++) { // 注意i从1开始生成 while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了 j = next[j]; // 向前回退 } if (s[i] == s[j + 1]) { // 找到相同的前后缀 j++; } next[i] = j; // 将j(前缀的长度)赋给next[i] } } int strStr(string haystack, string needle) { if (needle.size() == 0) { return 0; } int next[needle.size()]; //生成next数组 getNext(next, needle); //开始匹配 int j = -1; // // 因为next数组里记录的起始位置为-1 for (int i = 0; i < haystack.size(); i++) { // 注意i从0开始匹配 while(j >= 0 && haystack[i] != needle[j + 1]) { // 不匹配 j = next[j]; // j 寻找之前匹配的位置 } if (haystack[i] == needle[j + 1]) { // 匹配,j和i同时向后移动 j++; // i的增加在for循环里 } if (j == (needle.size() - 1) ) { // 文本串s里出现了模式串t,注意减1 return (i - needle.size() + 1); } } return -1; } }; -
kmp例子2
-
给定一个非空的字符串
s,检查是否可以通过由它的一个子串重复多次构成。 -
优化的KMP算法,只要next数组多余的数不断回退刚好到达末尾,即可由一个子串重复构成。
-
充分必要条件的证明。
-
思路1:采用拼接字符串判断子字符串的问题。利用语言库函数。
-
证明:长度为 n 的字符串 s 是字符串
t=s+s的子串,并且 s 在 t 中的起始位置不为 0 或 n ,当且仅当 s 满足题目的要求。 -
1 2 3 4 5 6 7 8 9 10class Solution { public: bool repeatedSubstringPattern(string s) { if(s.size()==0){ return false; } //在(1,n)这个区间里面 return (s+s).find(s,1)!=s.size(); } }; -
思路2:手写KMP算法。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43class Solution { public: void getNext(int *next, const string &s){ next[0]=-1; int j = -1; for(int i = 1;i<s.size();++i){ while(j>=0&&s[i]!=s[j+1]){ j = next[j]; } if(s[i]==s[j+1]){ ++j; } next[i]=j; } } bool repeatedSubstringPattern(string s) { if(s.size()<=1){ return false; } string src = s+s; int next[s.size()]; getNext(next,s); //开始匹配 int j =-1; //从第1字符串开始匹配,特殊点,因为是在(1,n)区间内 for(int i =1;i<src.size()-1;++i){ while(j>=0&&src[i]!=src[j+1]){ j = next[j]; } //相等就加次数 if(src[i]==src[j+1]){ ++j; } //判断是否匹配完,注意统一减1 if(j==(s.size()-1)){ return true; } } return false; } }; -
思路3:优化的KMP算法。对next数组要有一定的理解。数组长度减去最长相同前后缀的长度相当于是第一个周期的长度,也就是一个周期的长度,如果这个周期可以被整除,就说明整个数组就是这个周期的循环。
-
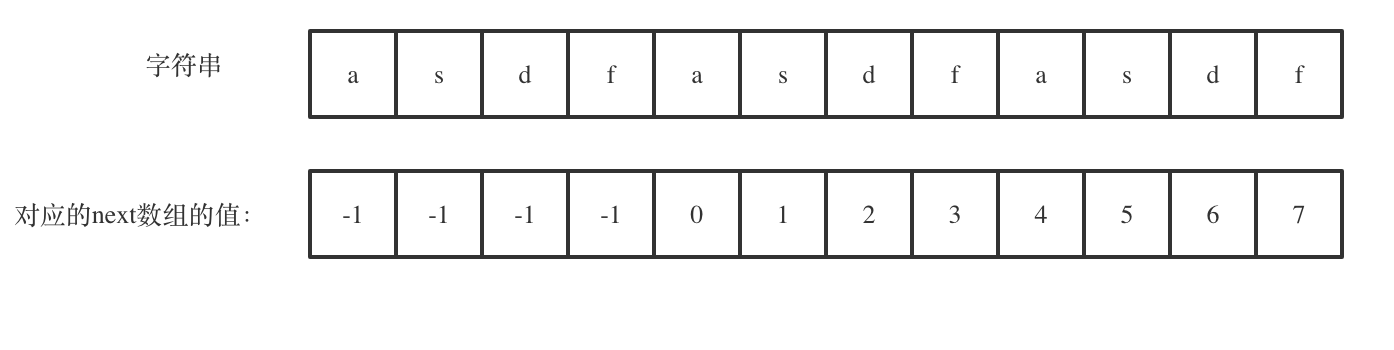
-
如上图所示,可以看出最长相等的前后缀是
asdfasdf。可以理解是一种翻滚操作。数组减去这部分得到的,可以看出是后缀的前半部分,通过等量代换,也可以看出前缀的后半部分,如果这部分长度可以被整个数组长度整除,说明里面存在这部分字符串的循环! -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33class Solution { public: void getNext(int *next, const string &s){ int j = -1; next[0] = -1; //从1开始 for(int i =1;i<s.size();++i){ //执行回退 while(j>=0 && s[i]!=s[j+1]){ j = next[j]; } //相等就+1 if(s[i]==s[j+1]){ ++j; } next[i] = j; } } bool repeatedSubstringPattern(string s) { if(s.size()==1){ return false; } int next[s.size()]; getNext(next, s); int grab = s.size()-(next[s.size()-1]+1); //一定是要小于总长度,同时剩余的长度又可以被取余,才可以 if(grab<s.size() && s.size()%grab==0){ return true; } return false; } };
AC自动机
-
AC自动机是一种用于字符串匹配的算法。它由Alfred V. Aho和Margaret J. Corasick在1975年提出。AC自动机是一种多模式自动机,可以同时匹配多个字符串。
AC自动机的构造如下:
- 首先构造一个前缀树(Trie树),其中每个节点存储一个字符串。
- 然后构造一个失败指针表,其中每个节点存储指向匹配该节点前缀的最大前缀的节点。
- 在匹配时,AC自动机从根节点开始,依次读取输入字符,并根据失败指针表转移到下一个节点。如果遇到一个不匹配的字符,则AC自动机会回退到失败指针指向的节点。
-
AC自动机的匹配时间复杂度为O(m+n),其中m为输入字符串的长度,n为待匹配字符串的数量。
-
KMP算法和AC自动机都是字符串匹配的算法,但它们有以下几个区别:
- KMP算法是基于字符串的模式串进行匹配,而AC自动机是基于前缀树进行匹配。
- KMP算法的时间复杂度为O(m+n),其中m为输入字符串的长度,n为模式串的长度。AC自动机的时间复杂度为O(m),其中m为输入字符串的长度。
- KMP算法只能匹配单个模式串,而AC自动机可以匹配多个模式串。
-
因此,AC自动机比KMP算法更快,也更灵活。但是,AC自动机的实现也更复杂。
-
一份示例代码
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98#include <cstring> #include <iostream> #include <queue> using namespace std; const int MAXN = 1000005; // 最大节点数 const int MAXC = 26; // 字符集大小 int ch[MAXN][MAXC]; // trie树的边 int fail[MAXN]; // fail指针 int val[MAXN]; // 节点的附加信息 int idx = 0; // trie树节点数量 void insert(char *s, int v) { int u = 0; for (int i = 0; s[i]; i++) { int c = s[i] - 'a'; if (!ch[u][c]) ch[u][c] = ++idx; u = ch[u][c]; } val[u] = v; } void build() { queue<int> q; for (int c = 0; c < MAXC; c++) { int u = ch[0][c]; if (u) { fail[u] = 0; q.push(u); } } while (!q.empty()) { int u = q.front(); q.pop(); for (int c = 0; c < MAXC; c++) { int v = ch[u][c]; if (!v) { ch[u][c] = ch[fail[u]][c]; continue; } q.push(v); int f = fail[u]; while (f && !ch[f][c]) f = fail[f]; fail[v] = ch[f][c]; } } } void query(char *s) { int u = 0; for (int i = 0; s[i]; i++) { int c = s[i] - 'a'; u = ch[u][c]; for (int j = u; j; j = fail[j]) { if (val[j]) { // 匹配到一个模式串,输出对应的附加信息 cout << "Matched pattern: " << val[j] << endl; } } } } int main() { char s[100]; int n; // 读入模式串 cin >> n; for (int i = 1; i <= n; i++) { cin >> s; insert(s, i); } // 构建AC自动机 build(); // 读入文本串并匹配 cin >> s; query(s); return 0; } /* 3 abc edf ghi abcabdghidffdfd 输出 Matched pattern: 1 Matched pattern: 3 */ -
github上ac自动机很多实现代码,oi-wiki也有实现。
最小表示法
-

-

-
给定两个字符串,
s和goal。如果在若干次旋转操作之后,s能变成goal,那么返回true。s的 旋转操作 就是将s最左边的字符移动到最右边。- 例如, 若
s = 'abcde',在旋转一次之后结果就是'bcdea'。
- 例如, 若
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35class Solution { public: string getMinstr(string &s){ int n = s.size(); s+=s; int i=0,j=1,k=0; while(i<n&&j<n){ k=0; while(k<n&&s[i+k]==s[j+k]){ ++k; } if(s[i+k]>s[j+k]){ i = i+k+1; }else{ j = j+k+1; } if(i==j){ ++i; } } k = min(i,j); return s.substr(k,n); }; bool rotateString(string s, string goal) { //比较两个字符串的最小表示法 int n1 = s.size(); int n2 = goal.size(); if(n1!=n2){ return false; } return getMinstr(s)==getMinstr(goal); } };
二叉树
前序遍历
-
递归法
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode() : val(0), left(nullptr), right(nullptr) {} * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} * }; */ class Solution { public: vector<int> ret; void preorderT(TreeNode* root){ if(!root){ return; } ret.push_back(root->val); preorderT(root->left); preorderT(root->right); } vector<int> preorderTraversal(TreeNode* root) { ret.clear(); preorderT(root); return ret; } }; -
迭代法
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode() : val(0), left(nullptr), right(nullptr) {} * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} * }; */ class Solution { public: vector<int> preorderTraversal(TreeNode* root) { vector<int> ret; if(!root){ return ret; } stack<TreeNode*> st; st.push(root); while(!st.empty()){ TreeNode* tmp = st.top(); st.pop(); ret.push_back(tmp->val); //先压右子树 if(tmp->right){ st.push(tmp->right); } if(tmp->left){ st.push(tmp->left); } } return ret; } };
后序遍历
-
迭代法
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode() : val(0), left(nullptr), right(nullptr) {} * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} * }; */ class Solution { public: vector<int> postorderTraversal(TreeNode* root) { //镜像前序遍历 stack<TreeNode*> st; vector<int> ret; if(!root){ return ret; } st.push(root); while(st.size()){ TreeNode* tmp = st.top(); st.pop(); ret.push_back(tmp->val); if(tmp->left){ st.push(tmp->left); } if(tmp->right){ st.push(tmp->right); } } reverse(ret.begin(),ret.end()); return ret; } };
中序遍历
-
迭代法
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode() : val(0), left(nullptr), right(nullptr) {} * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} * }; */ class Solution { public: vector<int> inorderTraversal(TreeNode* root) { vector<int> ret; if(!root){ return ret; } TreeNode *curr = root; stack<TreeNode*> st; while(st.size()||curr){ //疯狂压入左节点 while(curr){ st.push(curr); curr = curr->left; } TreeNode* tmp = st.top(); st.pop(); ret.push_back(tmp->val); //转为右子树 if(tmp->right){ curr = tmp->right; } } return ret; } };