1. 概述
-
由侯捷老师讲解。
-
Generic Programming 泛型编程:就是使用template(模板)为主要工具来编写程序。
-

-
C++ 标准库——C++ Standard Library。
-
标准模板库STL——Standard Template Library
-
STL包含六大部件,C++标准库包含STL,同时还包括其他的小东西。从范围上来讲,C++标准库大于STL。
-

-
所有新式的标准库组件都放在了namespace std命名空间里面。
-
引入了头文件,还需要引入命名空间namespace,防止命名重定义。
2. STL 体系结构基础介绍
-
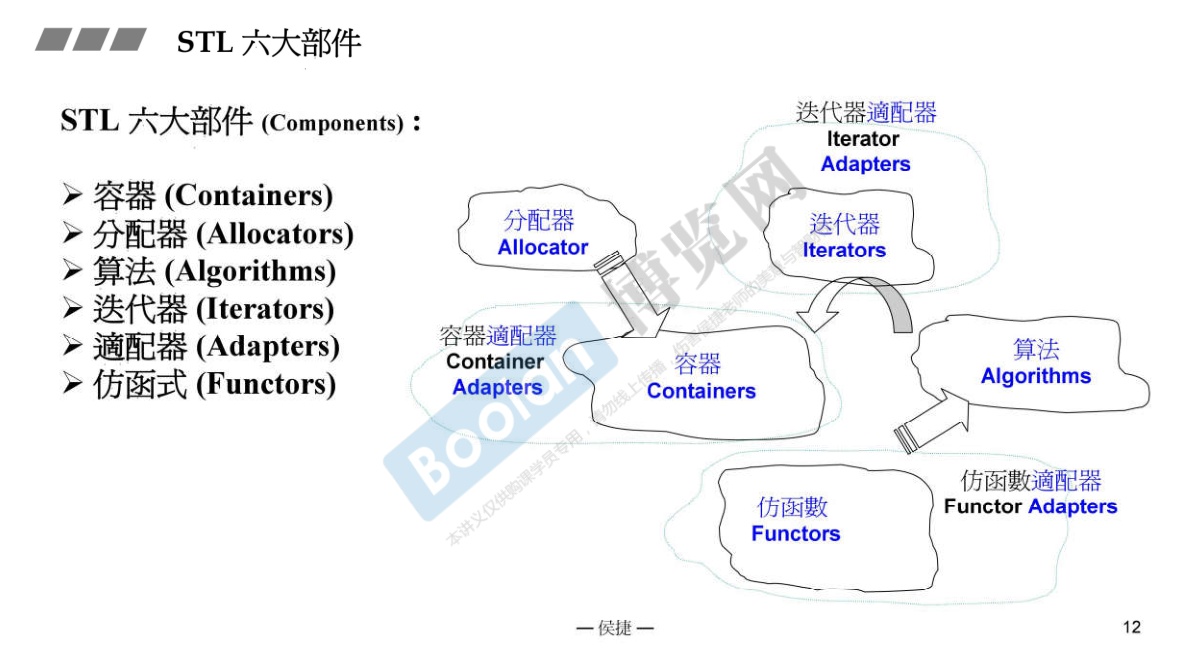
STL六大部件(Components)
- 容器 Containers
- 分配器 Allocators
- 算法 Algorithms
- 迭代器 Iterators
- 适配器 Adapters
- 仿函数 Functors
-
-
示例:计算大于大于40的元素的个数。
-
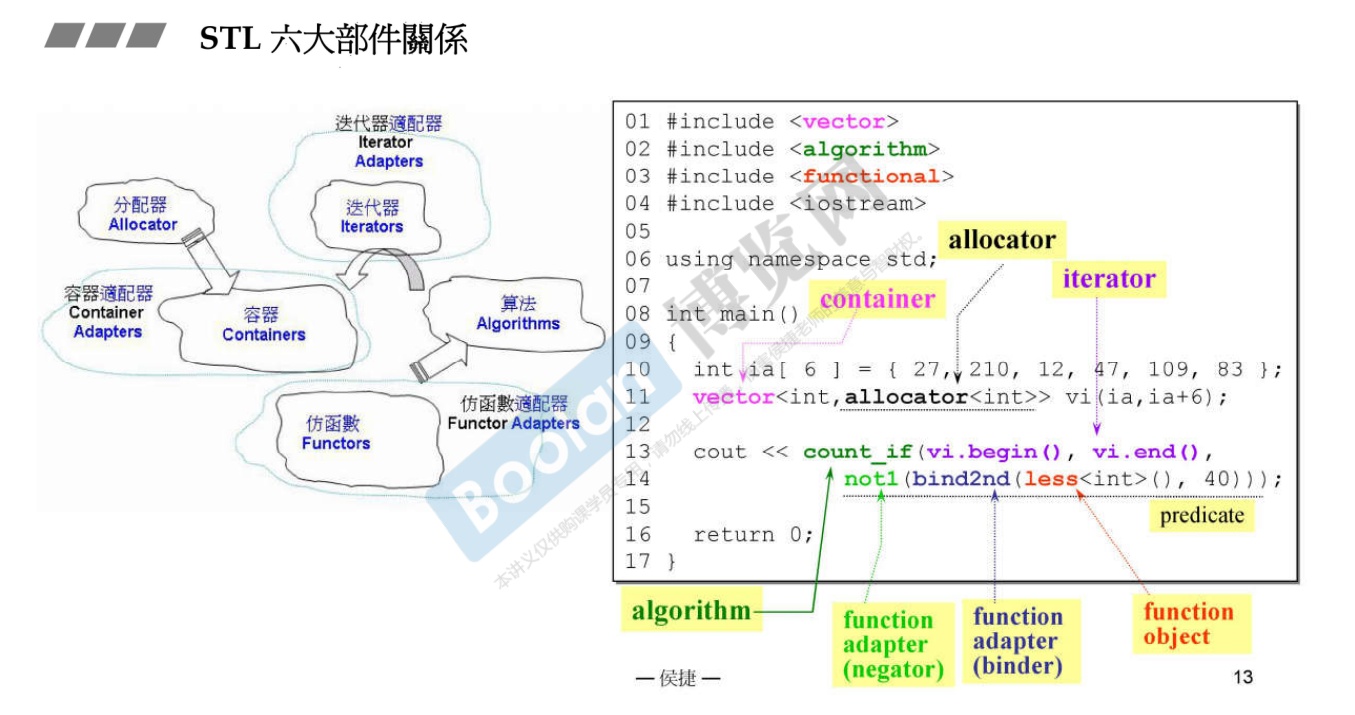
-
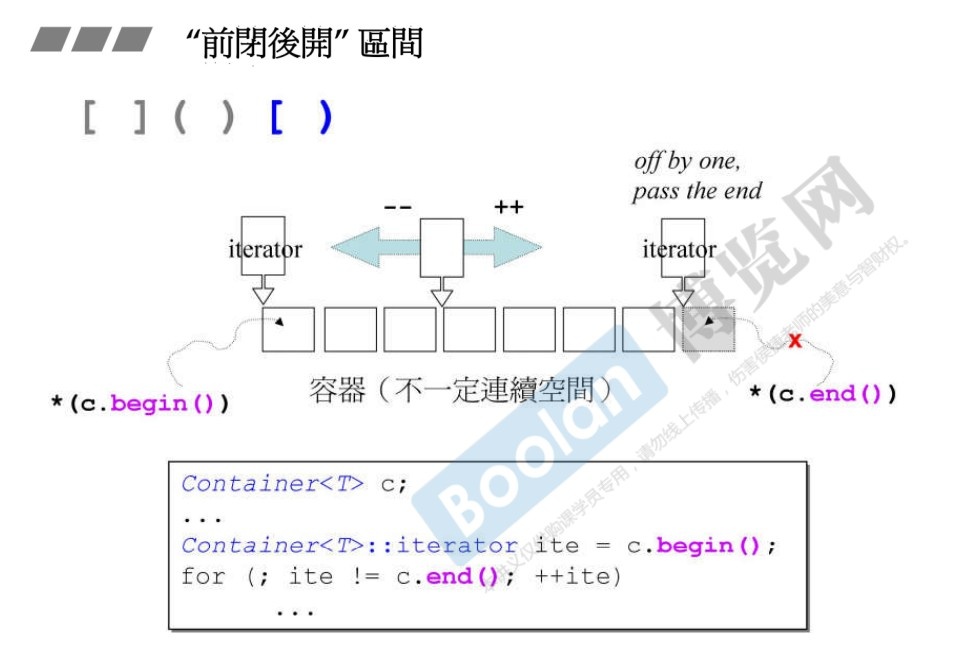
标准库规定,所有的容器的区间都是
前闭后开 [...)。 -
3. 容器分类与测试
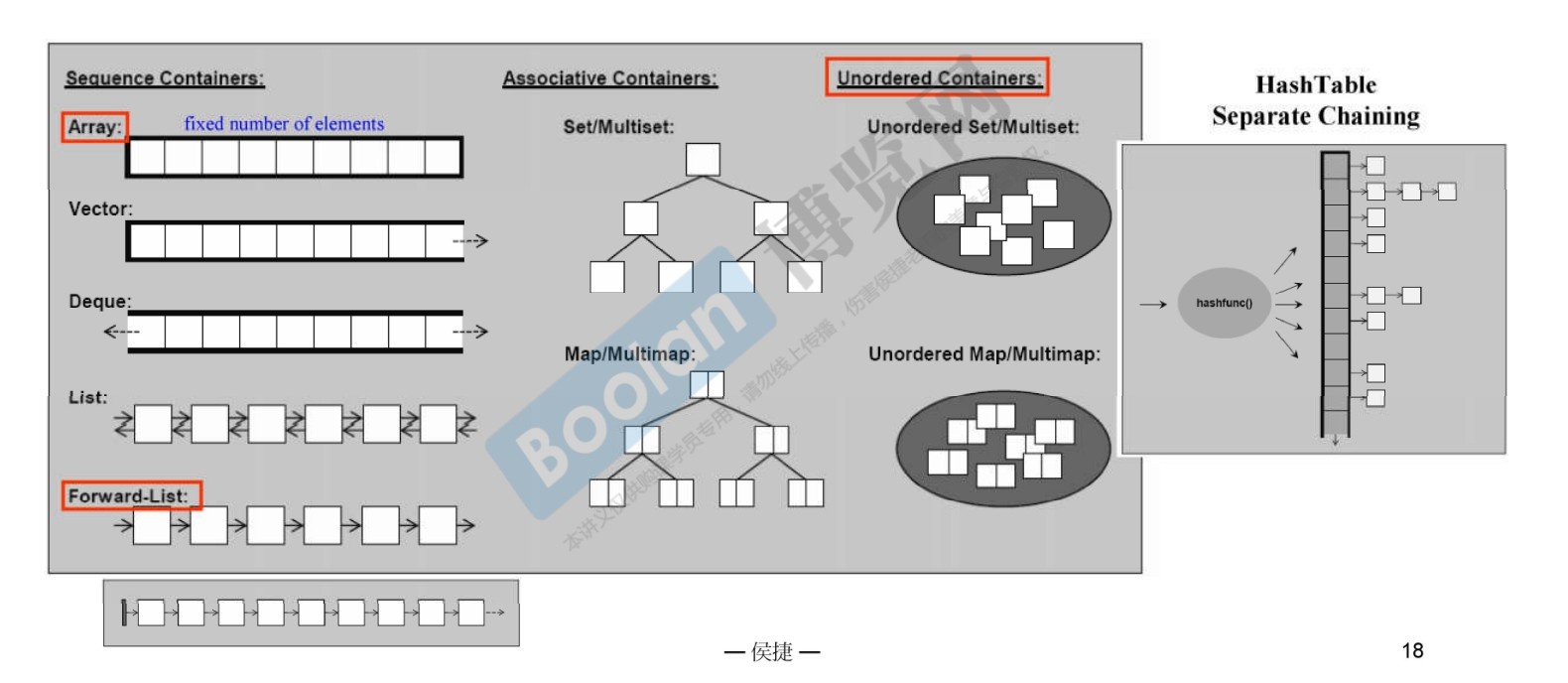
- 大分类可以分为两组
- Sequence Containers :序列式容器
- Associative Containers:关联式容器——适合做快速的查找
- c++11后推出了 Unordered Containers——其实就是散列表,哈希表。从本质上来说,也属于关联式容器。
- 下图中的红色方框,是在C++11以后再加入容器的概念的。
3.1 关于C的标准库及其相关函数
-
snprintf函数
-
#include <cstdio> //snprintf() -
C 库函数 int snprintf(char *str, size_t size, const char *format, ...) 设将可变参数**(...)**按照 format 格式化成字符串,并将字符串复制到 str 中,size 为要写入的字符的最大数目,超过 size 会被截断。
-
参数1为字符数组的内存空间,参数2为大小,参数3是格式。
-
1 2 3 4 5 6 7long target = 525; char buf[10]; snprintf(buf, 10, "%d", target); string s0 = string(buf); //to_string函数 string s1 = to_string(target); -
其实功能和
<string>的to_string函数没有很大区别。实际上,to_string的源码就是基于snprintf。
-
-
Qsort函数
-
函数原型:
-
1 2 3 4 5 6 7void qsort (void* base, size_t num, size_t size,int(*compar)(const void*, const void*)); base —— 就是要排序数组的起始地址,如对arr[5]排序,则arr就是数组的起始地址 num —— 数组元素的个数 size —— 就是数组中每一个元素的所占字节数,用sizeof(arr[0])来计算 int(*compar)(const void*, const void*)) —— compar这是一个函数指针,指向的是 int 函数名(const void* e1,const void *e2) 头文件: #include<cstdlib> -
关键点在于比较函数compar的书写问题。
- 如果e1大于e2,就返回大于0的数(函数的返回类型为整形)
- 如果e1小于e2,就返回小于0的数
- 如果e1等于e2,就返回等于0的数
-
常见比较函数形式,都是传入void*指针然后强转,最后返回正负值即可。
-
1 2 3 4 5 6 7int compare1(const void* e1, const void *e2) { //将void*类型的指针e1和e2强制类型转换成int*型 return *((int*)e1) - *((int *)e2); //一定要强制类型转换,因为e1和e2都是void*指针,没有类型的指针 //如果不想要升序排列,想要按降序排列,就可以return *((int*)e2) - *((int *)e1); } -
1 2 3 4 5 6 7 8 9 10// qsort的比较汉萨胡,输入类型为string * int compareStrings(const void *a, const void *b) { if (*(string *)a > *(string *)b) return 1; else if (*(string *)a < *(string *)b) return -1; else return 0; }
-
-
bsearch函数
-
C语言里面的二分查找函数
-
如果查找成功,该函数返回一个指向数组中匹配元素的指针,否则返回空指针NULL。
-
函数原型
-
1void* bsearch (const void* key, const void* base, size_t num, size_t size, int (*compar)(const void*,const void*)); -
参数 含义 key pointer to the element to search for(要搜索的目标元素target的指针) ptr pointer to the array to examine(要检查的数组的指针) count number of element in the array(数组中的元素数量) size size of each element in the array in bytes(数组中每个元素的大小) comp comparison function which returns a negative integer value if the first argument is less than the second, a positive integer value if the first argument is greater than the second and zero if the arguments are equivalent. key is passed as the first argument, an element from the array as the second.(比较函数,如果第一个参数小于第二个参数,则返回负整数值;如果第一个参数大于第二个参数,则返回正整数值;如果参数相等,则返回零。键作为第一个参数传递,数组中的元素作为第二个参数传递。) -
示例
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25#include <iostream> #include <cstdlib> using namespace std; int Compare(const void *a, const void *b) { return *(int *)a > *(int *)b; } int main() { const int Num = 8; int arr[Num] = {1, 2, 3, 4, 5, 6, 7, 8}; int target = 12; void *ret = bsearch(&target, arr, Num, sizeof(arr[0]), Compare); if (!ret) { cout << "not found!" << endl; } else { cout << "find num = " << *(int *)ret << endl; } return 0; }
-
3.2 array
-
STL 的 array是一个固定大小的数组,支持任意类型。
-
array 并不支持(也就是不允许你指定)分配器(allocator)。
-
函数 功能 begin(),end() ,cbegin(),cend() 提供正向迭代器支持 rbegin(),rend(),crbegin(),crend() 提供反向迭代器支持 size() 返回数组大小 max_size() 返回数组最大大小(由于array为固定序列,该函数返回值与size()相同) empty() 判断数组是否为空 (几乎没用) at(),operator[] 获取数组元素 front() 返回数组第一个元素的引用 back() 返回数组最后一个元素的引用 data() 返回指向数组对象包含的数据的指针,相当于 &arr[0]fill() 用值填充数组 swap() 交换两个数组元素 get(array) 返回某一个数组元素的引用 -
std::array<int, 110> arr{}; //将数组所有元素初始化为0 -
std::array<int,110> arr{1,2,3,4};*//将数组前4个元素分别初始化为1,2,3,4,其余全部为0* -
1 2std::array<int, 100> arr{1, 2}; //将数组所有元素初始化为0 cout << *(arr.data() + 0) << endl; //获取元素, 下标从0开始 -
示例,需要注意的是,下面的例子的排序使用的是C语言的qsort,其实可以使用STL的sort函数(sort(a.begin(),a.end())。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107#include <iostream> #include <cstdio> //snprintf() #include <cstring> //strlen(), memcpy() #include <string> #include <array> #include <iostream> #include <ctime> #include <cstdlib> //qsort, bsearch, NULL, rand, RAND_MAX using std::array; using std::cin; using std::cout; using std::endl; using std::string; const long ASIZE = 500000L; // 测试容器效率的相关函数 // 获取测试值,类型为int long get_a_target_long() { long target = 0; cout << "target (0~" << RAND_MAX << "): "; cin >> target; return target; } // 获取测试值,类型为string string get_a_target_string() { long target = 0; char buf[10]; cout << "target (0~" << RAND_MAX << "): "; cin >> target; snprintf(buf, 10, "%d", target); return string(buf); } // qsort的比较函数,输入类型long * int compareLongs(const void *a, const void *b) { return (*(long *)a - *(long *)b); } // qsort的比较汉萨胡,输入类型为string * int compareStrings(const void *a, const void *b) { if (*(string *)a > *(string *)b) return 1; else if (*(string *)a < *(string *)b) return -1; else return 0; } namespace tyc01 { void test_array() { cout << "\ntest_array().......... \n"; array<long, ASIZE> c; clock_t timeStart = clock(); for (long i = 0; i < ASIZE; ++i) { c[i] = rand(); } cout << "milli-seconds : " << (clock() - timeStart) << endl; //用的时间 cout << "array.size()= " << c.size() << endl; cout << "array.front()= " << c.front() << endl; cout << "array.back()= " << c.back() << endl; cout << "array.data()= " << c.data() << endl; //第一个元素的指针 long target = get_a_target_long(); timeStart = clock(); ::qsort(c.data(), ASIZE, sizeof(long), compareLongs); long *pItem = (long *)::bsearch(&target, (c.data()), ASIZE, sizeof(long), compareLongs); cout << "qsort()+bsearch(), milli-seconds : " << (clock() - timeStart) << endl; // if (pItem != NULL) cout << "found, " << *pItem << endl; else cout << "not found! " << endl; } } int main() { srand(time(NULL)); //随机数作种 tyc01::test_array(); return 0; } /*输出结果 test_array().......... milli-seconds : 8 array.size()= 500000 array.front()= 9471 array.back()= 27056 array.data()= 0x447950 target (0~32767): 20000 qsort()+bsearch(), milli-seconds : 62 found, 20000 */ -
需要注意的是,array和一般的数组区别不大
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24array<long, ASIZE> c; for (long i = 0; i < ASIZE; ++i) { c[i] = rand(); } cout << "array.size()= " << c.size() << endl; cout << "array.front()= " << c.front() << endl; cout << "array.back()= " << c.back() << endl; cout << "array.data()= " << c.data() << endl; //第一个元素的指针 cout << "array.data()+1= " << c.data() + 1 << endl; //字节数+4 cout << "arrar add = " << &c << endl; //整个数组的地址 cout << "arrar add +1 = " << &c + 1 << endl; //加整个数组的字节 cout << "arrar[0] add = " << &c[0] << endl; //第一个元素的地址 cout << "arrar[0] add +1 = " << &c[0] + 1 << endl; //第一个元素地址+4字节 /*输出结果 array.size()= 500000 array.front()= 20103 array.back()= 30162 array.data()= 0x447950 array.data()+1= 0x447954 arrar add = 0x447950 arrar add +1 = 0x62fdd0 arrar[0] add = 0x447950 arrar[0] add +1 = 0x447954 -
与数组的唯一区别就是,数组名a可以作为数组第一个元素的指针。我们由数组和指针的关系知道,a代表这个地址数值,它相当于一个指针,指向第一个元素(&a[0]),即指向数组的首地址。数组中的其他元素可以通过a的位移得到,此时的进阶是以数组中单个的元素类型为单位的,即a+i= & a[i]。但是array的名字不能代替第一个元素的地址,会报错。
3.3 vector
-
vector扩容原理
- vector通过一个连续的数组存放元素,如果集合已满,在新增数据的时候,就要分配一块更大的内存,将原来的数据复制过来,释放之前的内存,在插入新增的元素;
- 对vector的任何操作,一旦引起空间重新配置,指向原vector的所有迭代器就都失效了 ;
- 不同的编译器实现的扩容方式不一样,VS2019中以1.5倍扩容,GCC以2倍扩容。
-
扩容总结
- vector在push_back以成倍增长可以在均摊后达到O(1)的事件复杂度,相对于增长指定大小的O(n)时间复杂度更好。
- 为了防止申请内存的浪费,现在使用较多的有2倍与1.5倍的增长方式,而1.5倍的增长方式可以更好的实现对内存的重复利用。因为2倍的话每一次申请的内存都大于前面的内存的总和,不能重复利用,但是1.5倍的话是可以的。
-
vector的data函数,返回数据第一个元素的指针。
-
1 2 3vector<int> cc{1,2,3}; auto dd = cc.data();//dd的类似是int* *dd = 5; -
示例
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146#include <iostream> #include <cstdio> //snprintf() #include <cstring> //strlen(), memcpy() #include <string> #include <array> #include <iostream> #include <ctime> #include <cstdlib> //qsort, bsearch, NULL, rand, RAND_MAX #include <vector> #include <algorithm> //sort using std::cin; using std::cout; using std::endl; using std::string; using std::vector; const long ASIZE = 500000L; // 测试容器效率的相关函数 // 获取测试值,类型为int long get_a_target_long() { long target = 0; cout << "target (0~" << RAND_MAX << "): "; cin >> target; return target; } // 获取测试值,类型为string string get_a_target_string() { long target = 0; char buf[10]; cout << "target (0~" << RAND_MAX << "): "; cin >> target; snprintf(buf, 10, "%d", target); return string(buf); } // qsort的比较函数,输入类型long * int compareLongs(const void *a, const void *b) { return (*(long *)a - *(long *)b); } // qsort的比较汉萨胡,输入类型为string * int compareStrings(const void *a, const void *b) { if (*(string *)a > *(string *)b) return 1; else if (*(string *)a < *(string *)b) return -1; else return 0; } namespace tyc02 { void test_vector(long &value) { cout << "\ntest_vector().......... \n"; vector<string> c; char buf[10]; clock_t timeStart = clock(); for (long i = 0; i < value; ++i) { try { snprintf(buf, 10, "%d", rand()); c.push_back(string(buf)); } catch (std::exception &p) { cout << "i=" << i << " " << p.what() << endl; //曾經最高 i=58389486 then std::bad_alloc abort(); } } cout << "milli-seconds : " << (clock() - timeStart) << endl; cout << "vector.max_size()= " << c.max_size() << endl; // 1073747823 cout << "vector.size()= " << c.size() << endl; cout << "vector.front()= " << c.front() << endl; cout << "vector.back()= " << c.back() << endl; cout << "vector.data()= " << c.data() << endl; //第一个元素的地址 cout << "vector.capacity()= " << c.capacity() << endl << endl; string target = get_a_target_string(); { timeStart = clock(); auto pItem = find(c.begin(), c.end(), target); //返回的是迭代器,暴力寻找 cout << "std::find(), milli-seconds : " << (clock() - timeStart) << endl; if (pItem != c.end()) cout << "found, " << *pItem << endl << endl; else cout << "not found! " << endl << endl; } { timeStart = clock(); sort(c.begin(), c.end()); cout << "sort(), milli-seconds : " << (clock() - timeStart) << endl; timeStart = clock(); string *pItem = (string *)::bsearch(&target, (c.data()), c.size(), sizeof(string), compareStrings); cout << "bsearch(), milli-seconds : " << (clock() - timeStart) << endl; if (pItem != NULL) cout << "found, " << *pItem << endl << endl; else cout << "not found! " << endl << endl; } c.clear(); } } int main() { srand(time(NULL)); //随机数作种 long count = 1000000; tyc02::test_vector(count); return 0; } /*输出结果 test_vector().......... milli-seconds : 143 vector.max_size()= 576460752303423487 vector.size()= 1000000 vector.front()= 27075 vector.back()= 19914 vector.data()= 0x47f6040 vector.capacity()= 1048576 */
3.4 list
-
list是双向链表。
-
list 容器具有一些 vector 和 deque 容器所不具备的优势,它可以在常规时间内,在序列已知的任何位置插入或删除元素。这是我们使用 list,而不使用 vector 或 deque 容器的主要原因。
-
list 的缺点是无法通过位置来直接访问序列中的元素,也就是说,不能索引元素。为了访问 list 内部的一个元素,必须一个一个地遍历元素,通常从第一个元素或最后一个元素开始遍历。
-
常见函数 内容 end() 列表的末尾 begin() 列表的开头 push_back(); 从列表后面在列表中加入一个元素 push_front(); 从列表前面加入一个元素 pop_back(); 从列表后面pop出一个元素 pop_front(); 从列表前面pop出一个元素 clear(); 清空列表 remove(data); 删除列表中与data相同的数据 unique(); 删除列表当中的重复数据使之具有集合的性质 size(); 输出列表中元素的个数 sort() 将列表中的元素排序,按升序来。注意list没有全局的sort,因为不适用;所以才内置了一个sort函数。 reverse() 将列表中的元素排是降序 max_size(); 返回列表能容纳的最大长度 insert(Position,Counts,data); Position是迭代器的位置,Counts是插入元素的个数,data是需要插入的元素,即重复Counts次 -
示例
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127#include <iostream> #include <cstdio> //snprintf() #include <cstring> //strlen(), memcpy() #include <string> #include <array> #include <iostream> #include <ctime> #include <cstdlib> //qsort, bsearch, NULL, rand, RAND_MAX, abort() #include <algorithm> //sort #include <list> #include <stdexcept> using std::cin; using std::cout; using std::endl; using std::list; using std::string; const long ASIZE = 500000L; // 测试容器效率的相关函数 // 获取测试值,类型为int long get_a_target_long() { long target = 0; cout << "target (0~" << RAND_MAX << "): "; cin >> target; return target; } // 获取测试值,类型为string string get_a_target_string() { long target = 0; char buf[10]; cout << "target (0~" << RAND_MAX << "): "; cin >> target; snprintf(buf, 10, "%d", target); return string(buf); } // qsort的比较函数,输入类型long * int compareLongs(const void *a, const void *b) { return (*(long *)a - *(long *)b); } // qsort的比较汉萨胡,输入类型为string * int compareStrings(const void *a, const void *b) { if (*(string *)a > *(string *)b) return 1; else if (*(string *)a < *(string *)b) return -1; else return 0; } namespace tyc03 { void test_list(long &value) { cout << "\ntest_list().......... \n"; list<string> c; char buf[10]; clock_t timeStart = clock(); for (long i = 0; i < value; ++i) { try { snprintf(buf, 10, "%d", rand()); c.push_back(string(buf)); } catch (std::exception &p) { cout << "i=" << i << " " << p.what() << endl; abort(); } } cout << "milli-seconds : " << (clock() - timeStart) << endl; cout << "list.size()= " << c.size() << endl; cout << "list.max_size()= " << c.max_size() << endl; // 357913941 cout << "list.front()= " << c.front() << endl; cout << "list.back()= " << c.back() << endl; string target = get_a_target_string(); timeStart = clock(); auto pItem = find(c.begin(), c.end(), target); cout << "std::find(), milli-seconds : " << (clock() - timeStart) << endl; if (pItem != c.end()) cout << "found, " << *pItem << endl; else cout << "not found! " << endl; timeStart = clock(); c.sort(); //按升序排序 cout << "c.sort(), milli-seconds : " << (clock() - timeStart) << endl; c.clear(); } } int main() { srand(time(NULL)); //随机数作种 long count = 1000000; tyc03::test_list(count); return 0; } /*输出结果 test_list().......... milli-seconds : 567 list.size()= 1000000 list.max_size()= 384307168202282325 list.front()= 28426 list.back()= 12152 target (0~32767): 20000 std::find(), milli-seconds : 2 found, 20000 c.sort(), milli-seconds : 1089 */ -
最简单的单链表/双链表并不适合二分查找;
-
skiplist即跳表可以进行二分查找。
-
list的遍历
-
与vector不同,list的遍历不能使用下标遍历,因为他是链表。
-
但我们可以使用迭代器进行遍历,这里的迭代器是双向迭代器,双向迭代器的构造使其可以进行++等访问操作,在底层实际上就是操作符重载。注意这里的迭代器没有
+1操作,只有++操作。 -
1 2 3 4 5 6 7 8 9 10 11 12 13//迭代器遍历 list<int>::iterator it = l3.begin(); while (it != l3.end()) { cout << *it<<" "; it++; } //ranged-base for 遍历 for (auto& e : l3) { cout << e << " "; }
-
-

3.5 forward_list
-
单向链表
-

-
如上图所示,只有push_front(),即每一次都插入头结点。上图中左侧为哨兵节点,右侧为末尾。
-
与
list相比,有以下几点不同- forward_list只提供前向迭代器,因此不支持反向迭代器,比如rbegin()等成员函数。
- forward_list不提供size()成员函数。
- forward_list没有指向最末元素的锚点,因此不提供back()、push_back()和pop_back()。
- forward_list不提供随机访问,这一点跟list相同
-
-
示例
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121#include <iostream> #include <cstdio> //snprintf() #include <cstring> //strlen(), memcpy() #include <string> #include <ctime> #include <cstdlib> //qsort, bsearch, NULL, rand, RAND_MAX #include <forward_list> #include <stdexcept> #include <algorithm> //sort using std::cin; using std::cout; using std::endl; using std::forward_list; using std::string; const long ASIZE = 500000L; // 测试容器效率的相关函数 // 获取测试值,类型为int long get_a_target_long() { long target = 0; cout << "target (0~" << RAND_MAX << "): "; cin >> target; return target; } // 获取测试值,类型为string string get_a_target_string() { long target = 0; char buf[10]; cout << "target (0~" << RAND_MAX << "): "; cin >> target; snprintf(buf, 10, "%d", target); return string(buf); } // qsort的比较函数,输入类型long * int compareLongs(const void *a, const void *b) { return (*(long *)a - *(long *)b); } // qsort的比较汉萨胡,输入类型为string * int compareStrings(const void *a, const void *b) { if (*(string *)a > *(string *)b) return 1; else if (*(string *)a < *(string *)b) return -1; else return 0; } namespace tyc04 { void test_forward_list(long &value) { cout << "\ntest_forward_list().......... \n"; forward_list<string> c; char buf[10]; clock_t timeStart = clock(); for (long i = 0; i < value; ++i) { try { snprintf(buf, 10, "%d", rand()); c.push_front(string(buf)); } catch (std::exception &p) { cout << "i=" << i << " " << p.what() << endl; abort(); } } cout << "milli-seconds : " << (clock() - timeStart) << endl; cout << "forward_list.max_size()= " << c.max_size() << endl; // 536870911 cout << "forward_list.front()= " << c.front() << endl; string target = get_a_target_string(); timeStart = clock(); auto pItem = find(c.begin(), c.end(), target); cout << "std::find(), milli-seconds : " << (clock() - timeStart) << endl; if (pItem != c.end()) cout << "found, " << *pItem << endl; else cout << "not found! " << endl; timeStart = clock(); c.sort(); cout << "c.sort(), milli-seconds : " << (clock() - timeStart) << endl; c.clear(); } } int main() { srand(time(NULL)); //随机数作种 long count = 1000000; tyc04::test_forward_list(count); return 0; } /*输出结果 test_forward_list().......... milli-seconds : 658 forward_list.max_size()= 461168601842738790 forward_list.front()= 13904 target (0~32767): 12345 std::find(), milli-seconds : 1 found, 12345 c.sort(), milli-seconds : 1315 */ -
遍历和
list的遍历区别不大,可以看到下面都是从头插入的。 -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15forward_list<int> cc(5, 70); cc.push_front(55); cc.push_front(66); for (auto i = cc.begin(); i != cc.end(); ++i) { cout << *i << " "; } cout << endl; for (auto &j : cc) { cout << j << " "; } /*输出结果 66 55 70 70 70 70 70 66 55 70 70 70 70 70
3.6 slist
-
顾名思义,single list 单链表
-
SGI STL另提供了一个单向链表,叫做slist。需要注意的是,这个容器并不在c++11标准规范(即std命名空间)之内,是c++11之前即存在了的。
-
常规操作。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45//必要的头文件以及命名空间 #include <ext\slist> __gnu_cxx::slist<int> cc; //定义单链表 slist<Type> s; //容器大小 size(); //链表的第一个元素 begin(); //指向最后一个元素的下一个位置 end(); //判断容器是否为空 empty(); //两个slist互换,只要将head交换互指即可 swap(slist& L); //取头部元素 front(); //在开头的位置插入元素 push_front(); //从头部取走元素(删除之),修改head pop_front(); //在某个位置前面插入一个元素 insert(iterator it, const T& x); //在某个位置后面插入一个元素 insert_after(iterator it, const T& x); //任意位置删除一个元素 erase(iterator it); //删除任意位置后面的一个元素 erase_after(iterator it); //清空链表 clear(); -
示例中,插入不花时间,但是最后的清空花了近80s,效率不高,个人感觉比 forward_list 效率低 。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47#include <ext\slist> #include <stdexcept> #include <string> #include <cstdlib> //abort() #include <cstdio> //snprintf() #include <iostream> #include <ctime> namespace tyc10 { void test_slist(long &value) { cout << "\ntest_slist().......... \n"; __gnu_cxx::slist<string> c; char buf[10]; clock_t timeStart = clock(); for (long i = 0; i < value; ++i) { try { snprintf(buf, 10, "%d", rand()); c.push_front(string(buf)); } catch (std::exception &p) { cout << "i=" << i << " " << p.what() << endl; abort(); } } cout << "milli-seconds : " << (clock() - timeStart) << endl; timeStart = clock(); c.clear(); cout << "clear milli-seconds : " << (clock() - timeStart) << endl; } } int main() { srand(time(NULL)); //随机数作种 long count = 1000000; tyc10::test_slist(count); return 0; } /*输出结果 test_slist().......... milli-seconds : 668 clear milli-seconds : 80552 -
遍历方式和
forward_list区别不是很大 -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16__gnu_cxx::slist<int> c(3, 2); c.push_front(5); c.push_front(6); for (auto &i : c) { cout << i << " "; } cout << endl; for (auto i = c.begin(); i != c.end(); ++i) { cout << *i << " "; } /*输出结果 6 5 2 2 2 6 5 2 2 2 */
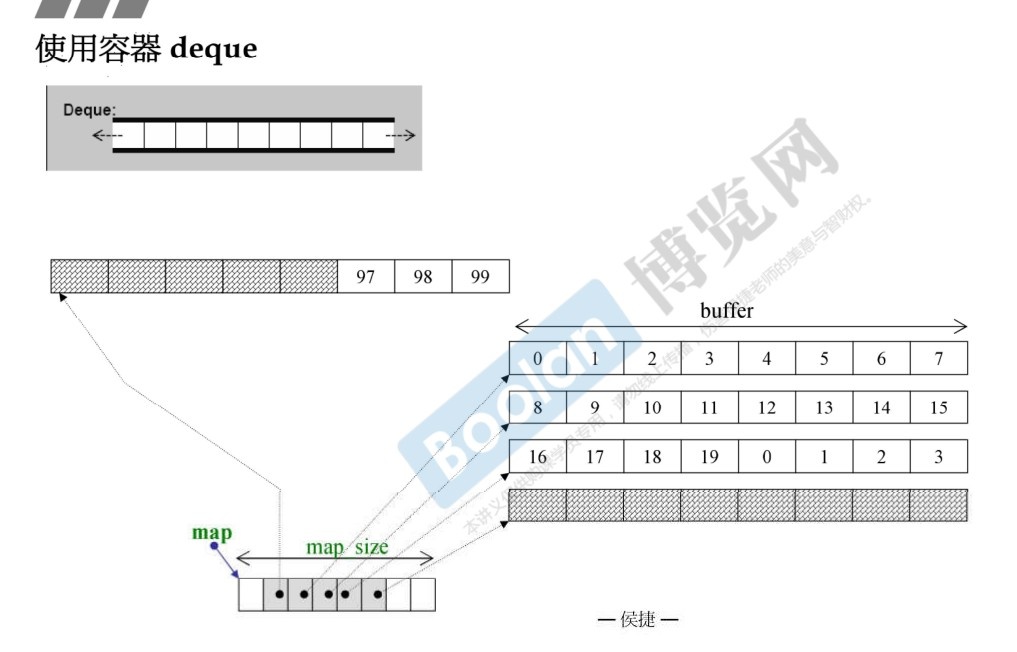
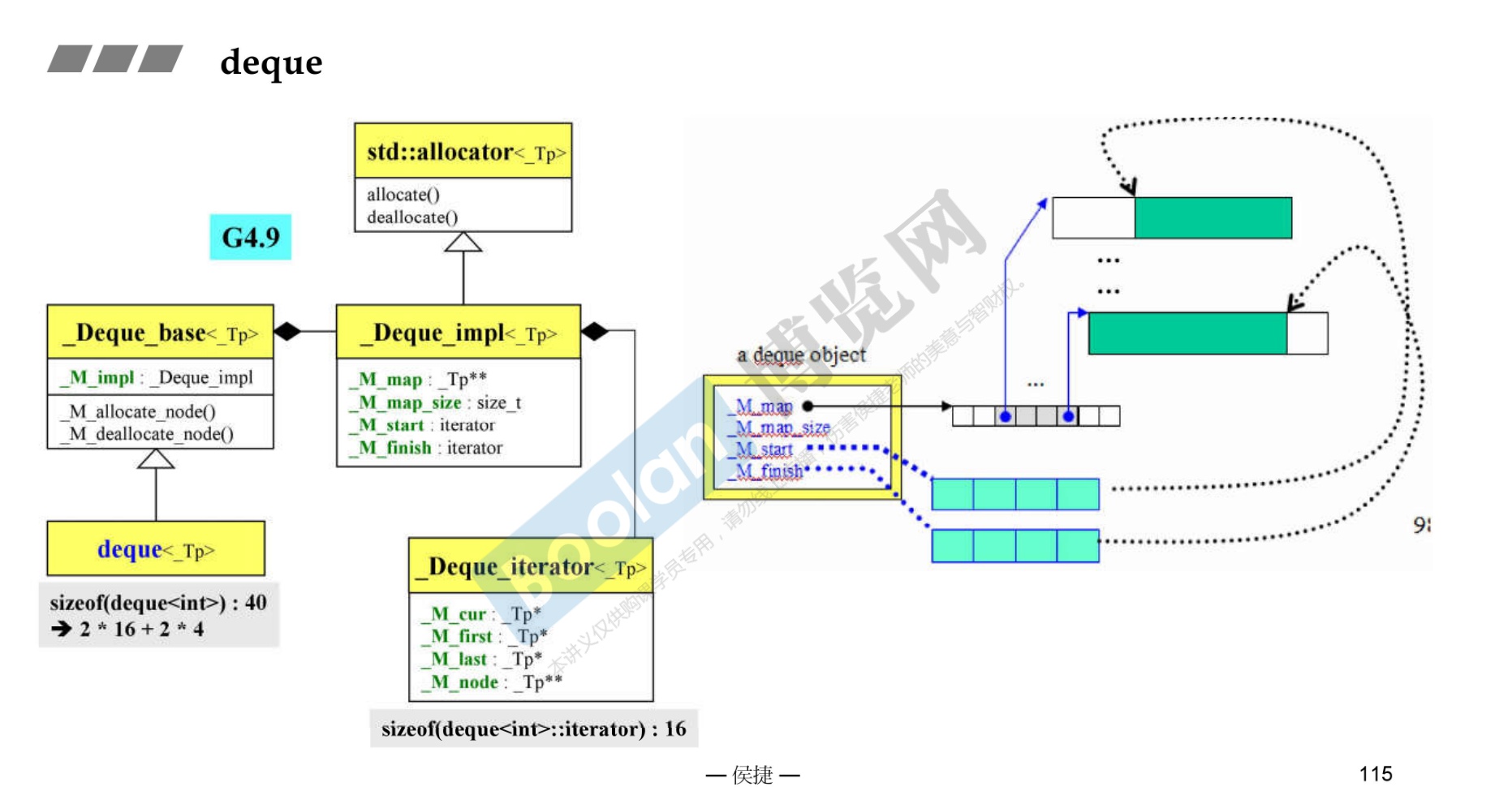
3.7 deque
-
双端队列
-
与vector的区别
- 每次扩充一个buffer。vector是每次扩充两倍。
- vector对于头部的插入删除效率低,数据量越大效率越低。
- deque相对而言,对头部的插入删除速度会比vector块。
- vector访问元素时的速度会比deque快,这和两者的内部实现有关。
-
注意,deque也是支持随机访问的。
-
内部实现如下图所示。
-
-
deque内部有一个中控器,维护每段缓冲区中的内容,缓冲区中存放真实数据。
-
中控器维护的是每个缓冲区的地址,使得使用deque时像一片连续的内存空间。
-
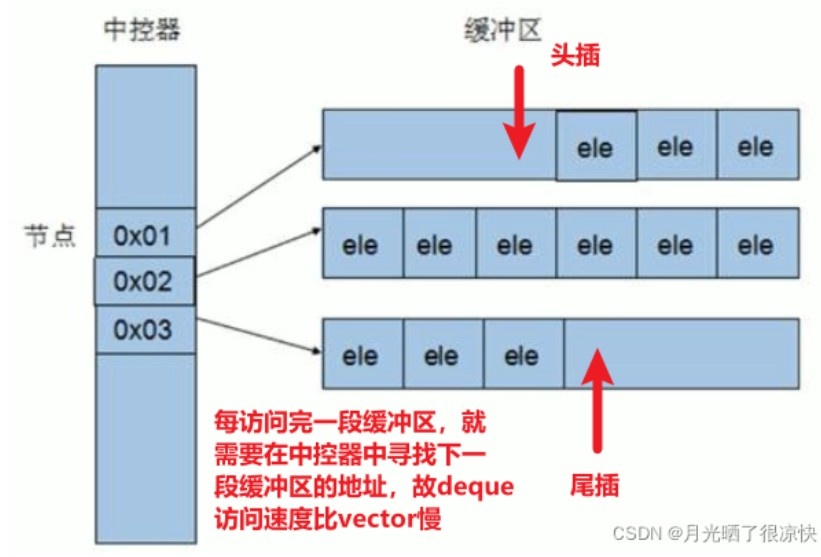
-
可以使用全局sort对deque进行排序处理。
-
常规操作
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21deque<int> dq; //定义一个储存整型变量的双端队列dq //deque双端插入和删除操作 push_back(elem);//在容器尾部添加一个数据 push_front(elem);//在容器头部插入一个数据 pop_back();//删除容器最后一个数据 pop_front();//删除容器第一个数据 //deque数据存取 at(idx);//返回索引idx所指的数据,如果idx越界,抛出out_of_range。 operator[];//返回索引idx所指的数据,如果idx越界,不抛出异常,直接出错。 front();//返回第一个数据。 back();//返回最后一个数据 //deque插入操作 ,在pos位置插入一个elem d2.insert(d2.begin()+pos, elem); //deque大小操作 deque.size();//返回容器中元素的个数 deque.empty();//判断容器是否为空 deque.resize(num);//重新指定容器的长度为num,若容器变长,则以默认值填充新位置。如果容器变短,则末尾超出容器长度的元素被删除。 -
例子
-
1 2 3 4 5 6deque<int> dd(5, 3); // 5个3 dd.insert(dd.begin() + 2, 4); for (auto &i : dd) cout << i << " "; /*输出 3 3 4 3 3 3 -
调试示例
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128#include <iostream> #include <cstdio> //snprintf() #include <cstring> //strlen(), memcpy() #include <string> #include <ctime> #include <cstdlib> //qsort, bsearch, NULL, rand, RAND_MAX #include <forward_list> #include <stdexcept> #include <deque> #include <algorithm> //sort using std::cin; using std::cout; using std::deque; using std::endl; using std::forward_list; using std::string; const long ASIZE = 500000L; // 测试容器效率的相关函数 // 获取测试值,类型为int long get_a_target_long() { long target = 0; cout << "target (0~" << RAND_MAX << "): "; cin >> target; return target; } // 获取测试值,类型为string string get_a_target_string() { long target = 0; char buf[10]; cout << "target (0~" << RAND_MAX << "): "; cin >> target; snprintf(buf, 10, "%d", target); return string(buf); } // qsort的比较函数,输入类型long * int compareLongs(const void *a, const void *b) { return (*(long *)a - *(long *)b); } // qsort的比较汉萨胡,输入类型为string * int compareStrings(const void *a, const void *b) { if (*(string *)a > *(string *)b) return 1; else if (*(string *)a < *(string *)b) return -1; else return 0; } namespace tyc05 { void test_deque(long &value) { cout << "\ntest_deque().......... \n"; deque<string> c; char buf[10]; clock_t timeStart = clock(); for (long i = 0; i < value; ++i) { try { snprintf(buf, 10, "%d", rand()); c.push_back(string(buf)); } catch (std::exception &p) { cout << "i=" << i << " " << p.what() << endl; abort(); } } cout << "milli-seconds : " << (clock() - timeStart) << endl; cout << "deque.size()= " << c.size() << endl; cout << "deque.front()= " << c.front() << endl; cout << "deque.back()= " << c.back() << endl; cout << "deque.max_size()= " << c.max_size() << endl; // 1073741821 string target = get_a_target_string(); timeStart = clock(); auto pItem = find(c.begin(), c.end(), target); cout << "std::find(), milli-seconds : " << (clock() - timeStart) << endl; if (pItem != c.end()) cout << "found, " << *pItem << endl; else cout << "not found! " << endl; timeStart = clock(); sort(c.begin(), c.end()); cout << "sort(), milli-seconds : " << (clock() - timeStart) << endl; c.clear(); } } //--------------------------------------------------- int main() { srand(time(NULL)); //随机数作种 long count = 1000000; tyc05::test_deque(count); return 0; } /*输出结果 test_deque().......... milli-seconds : 283 deque.size()= 1000000 deque.front()= 25532 deque.back()= 25315 deque.max_size()= 576460752303423487 target (0~32767): 20000 std::find(), milli-seconds : 4 found, 20000 sort(), milli-seconds : 728 */
3.8 stack
-
先进后出,底层容器是deque。
-
从技术上来讲,因为不是底层的,所以一般不叫容器,而叫容器适配器(Container Adapter)。
-
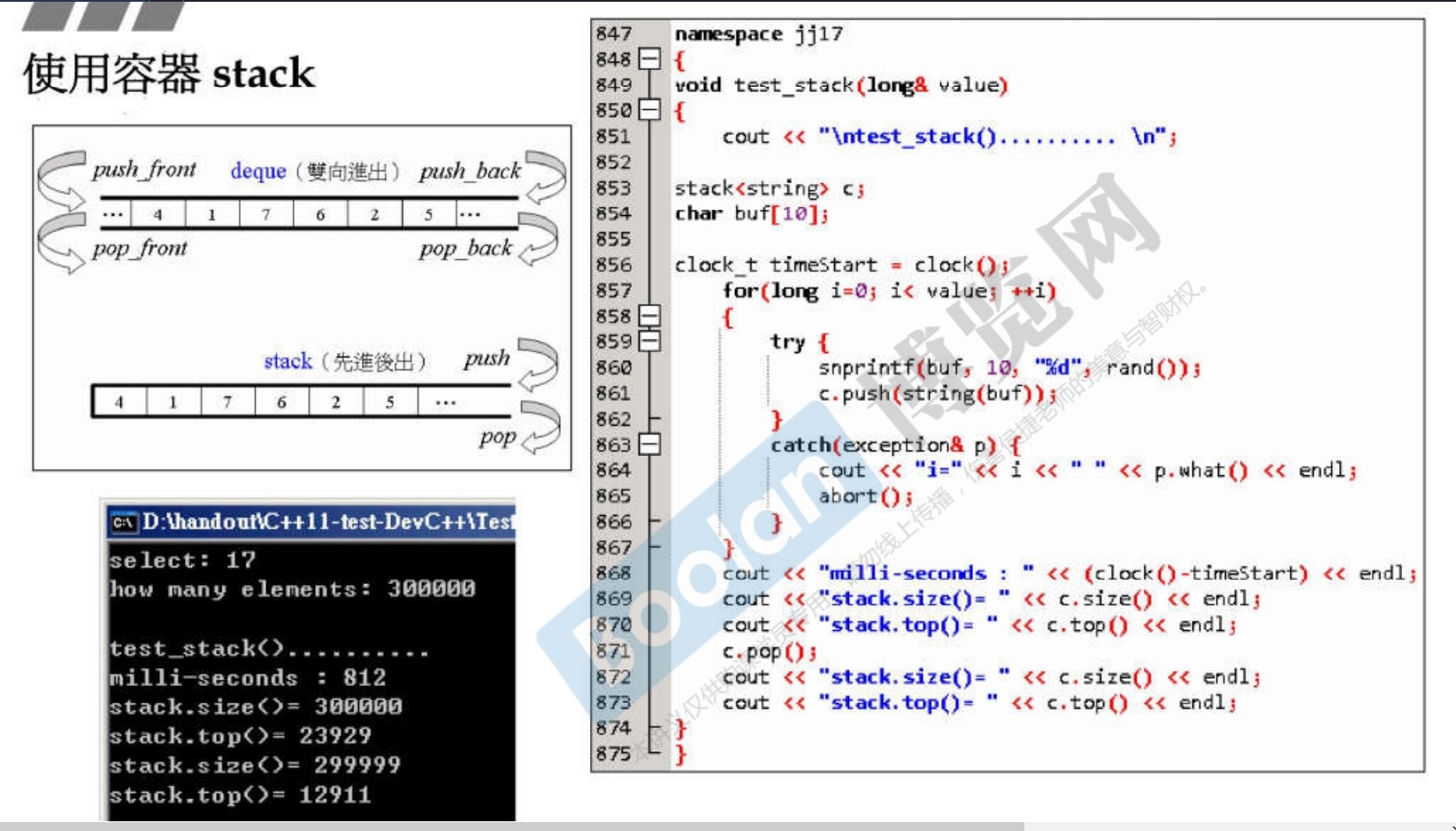
-
stack不提供 Iterator 迭代器。
-
因为stack是先进后出,有了迭代器会破坏这种特性。
3.9 queue
-
队列的特性是先进先出。底层容器仍然是deque。
-
与stack一样,从技术上来讲,因为不是底层的,queue所以一般不叫容器,而叫容器适配器(Container Adapter)。
-
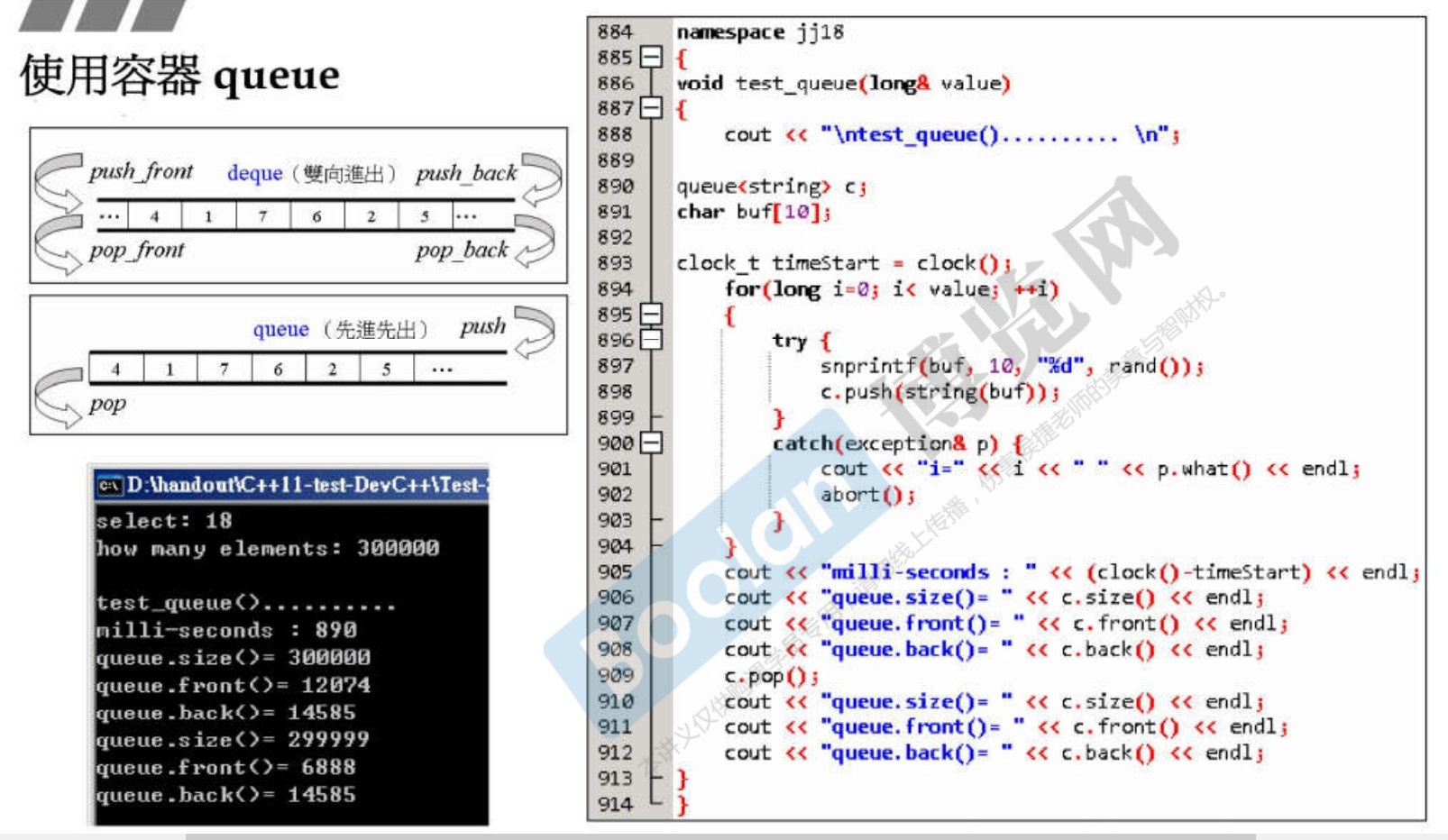
-
和stack一样,
-
queue不提供 Iterator 迭代器。
-
因为queue是先进先出,有了迭代器会破坏这种特性。
3.10 multiset
- 底层实现为红黑树。可重复。
3.11 multimap
- 底层实现仍然是红黑树,key可重复(value本来就可以重复)。
- 注意multimap的插入不可以使用
[]运算符,因为key可重复。 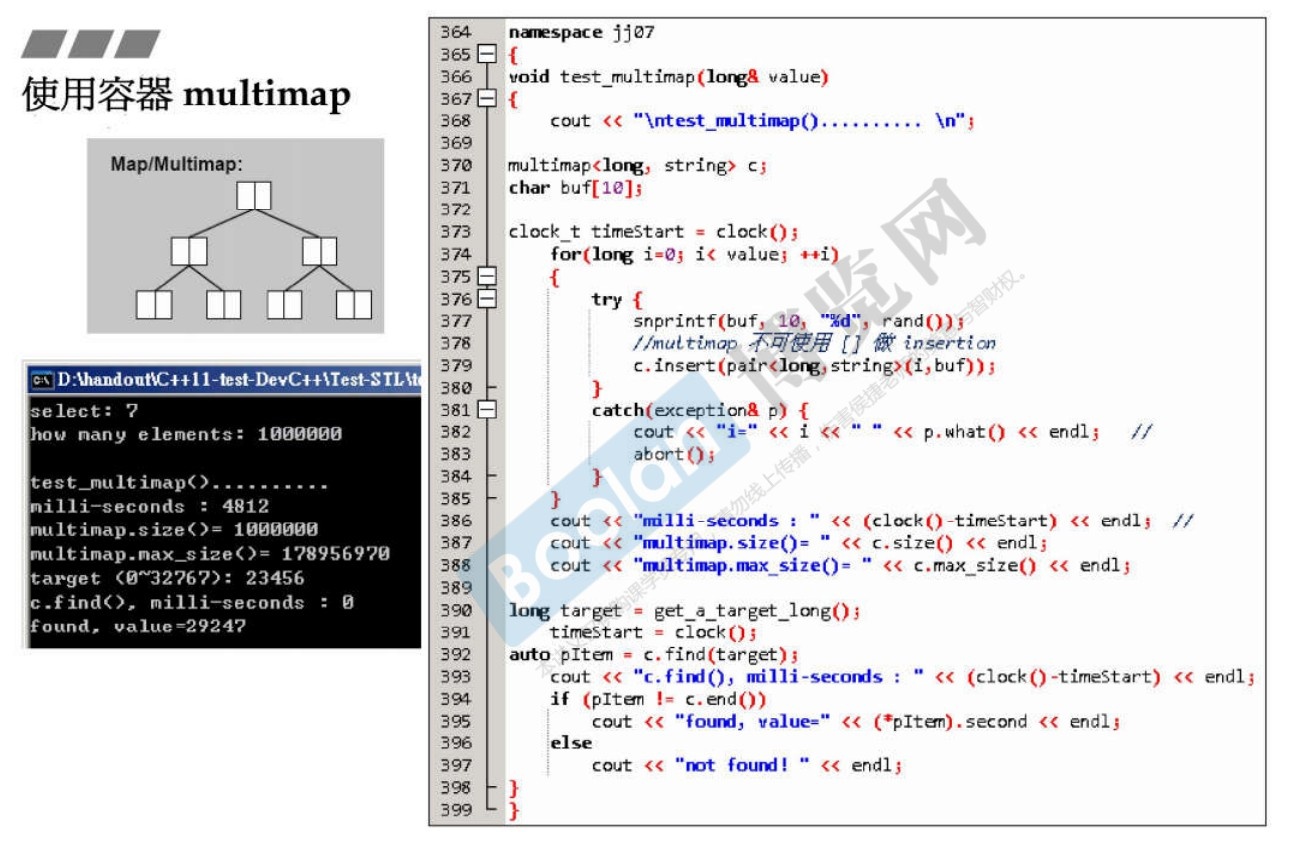
3.12 unordered_multiset
-
底层实现为哈希表hash table。没有数学推导,其实很大部分是偏经验。
-
注意有一个
bucket_count()函数,计算哈希表分配的篮子个数。一般来说,篮子个数都会比元素个数多。 -
还有一个
load_factor()函数,是C++ STL中的内置函数,该函数返回在unordered_multiset容器中返回当前负载因子。负载因子是容器中元素数量(其大小)与存储桶数量(bucket_count)之间的比率:$$ load\_factor = size / bucker\_count $$ -
负载因子会影响哈希表中发生冲突的概率(即,两个元素位于同一存储桶中的概率)。通过在每次需要扩展时进行一次重新哈希处理,容器会自动增加存储桶的数量,以将负载系数保持在特定阈值(其max_load_factor)以下。
-

-

3.13 unordered_multimap
-
底层实现为哈希表。
-
需要注意的是,
multimap都是不可以使用[]操作符 的。 -
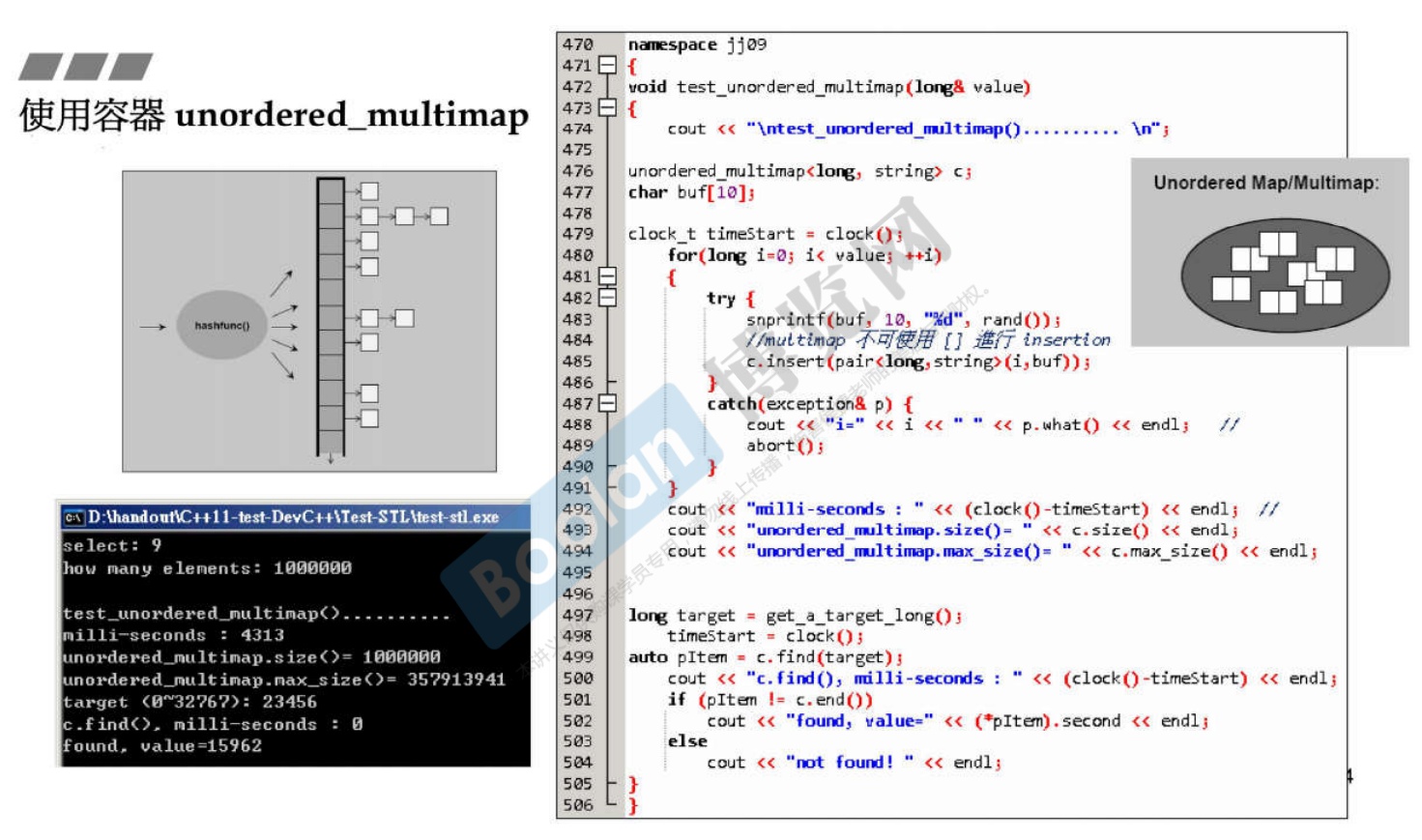
3.14 set
- 底层实现为红黑树。

3.15 map
- 底层实现为红黑树。
- 注意
map是可以使用[]操作符添加元素的。 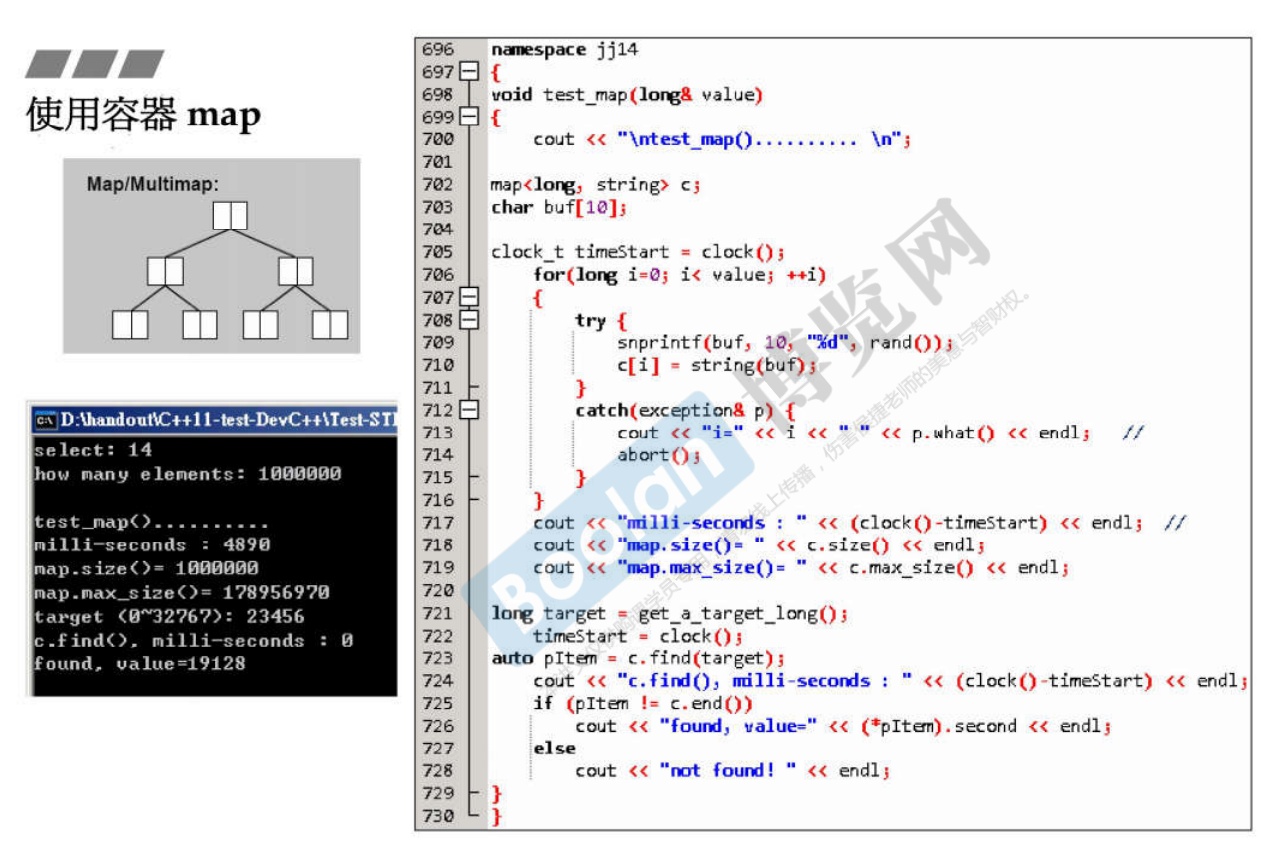
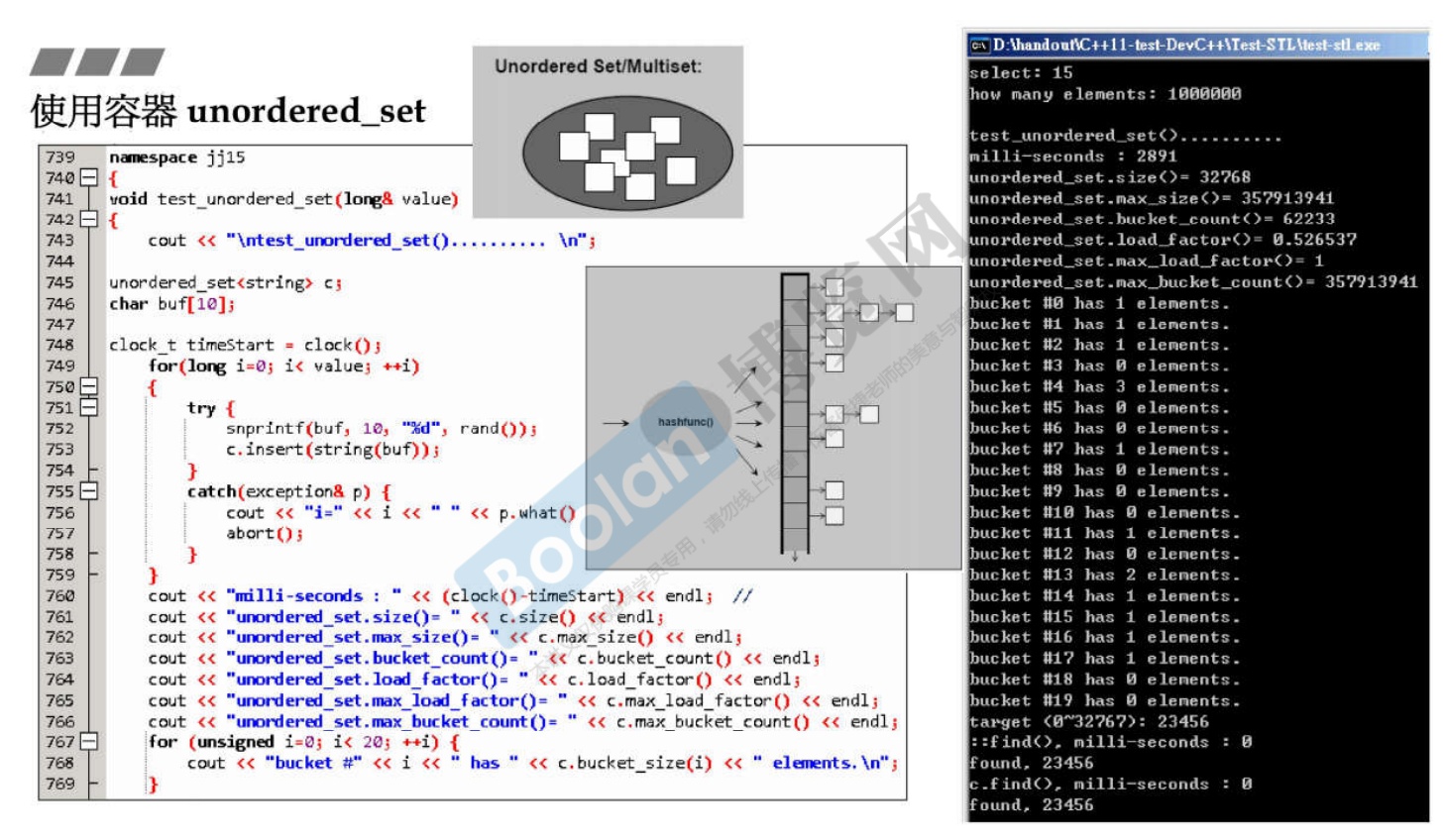
3.16 unordered_set
-
底层实现为哈希表。
-
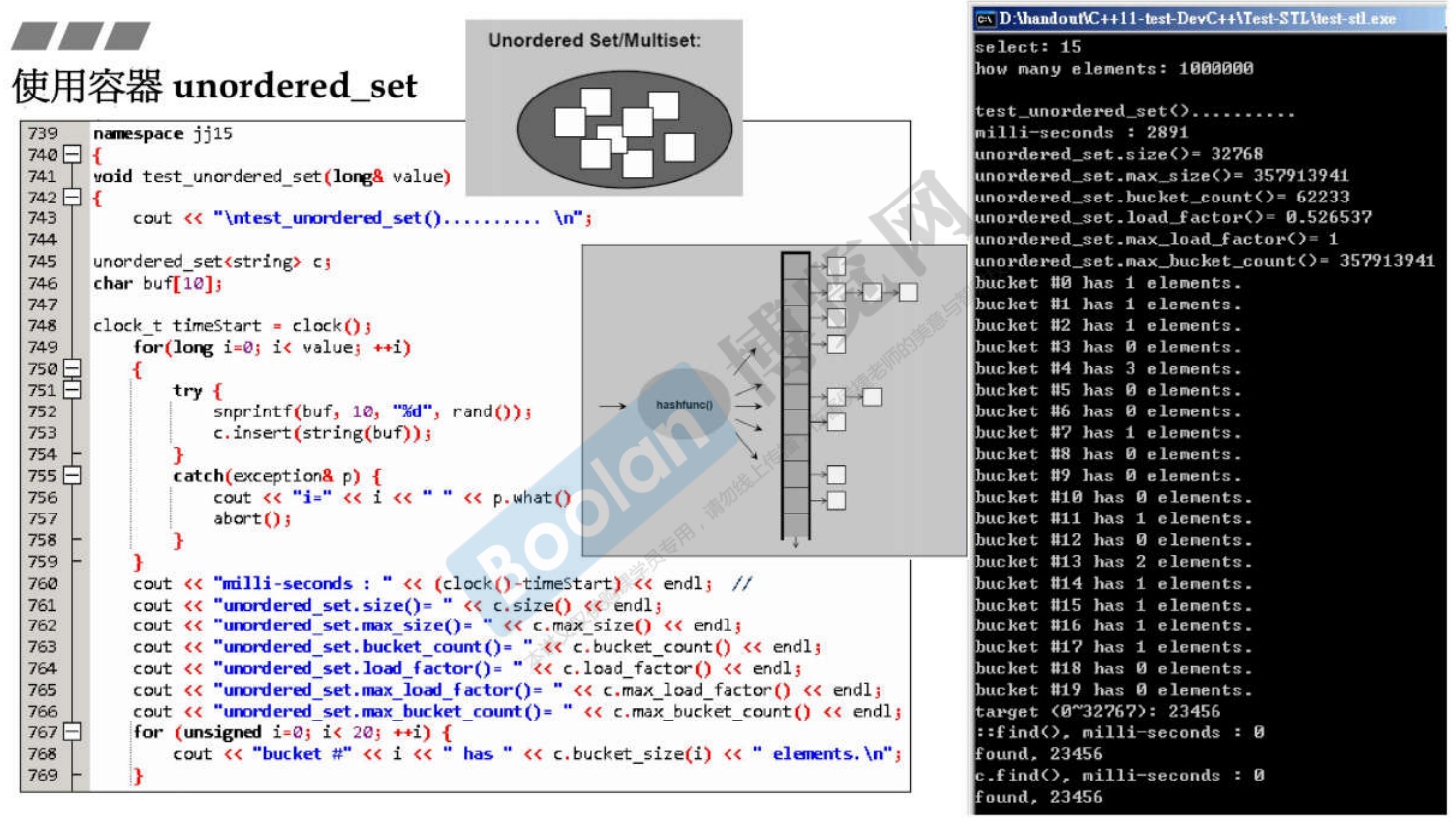
-

3.17 unordered_map
- 底层实现为哈希表。
- 需要注意的是,
map是可以使用[]操作符的。 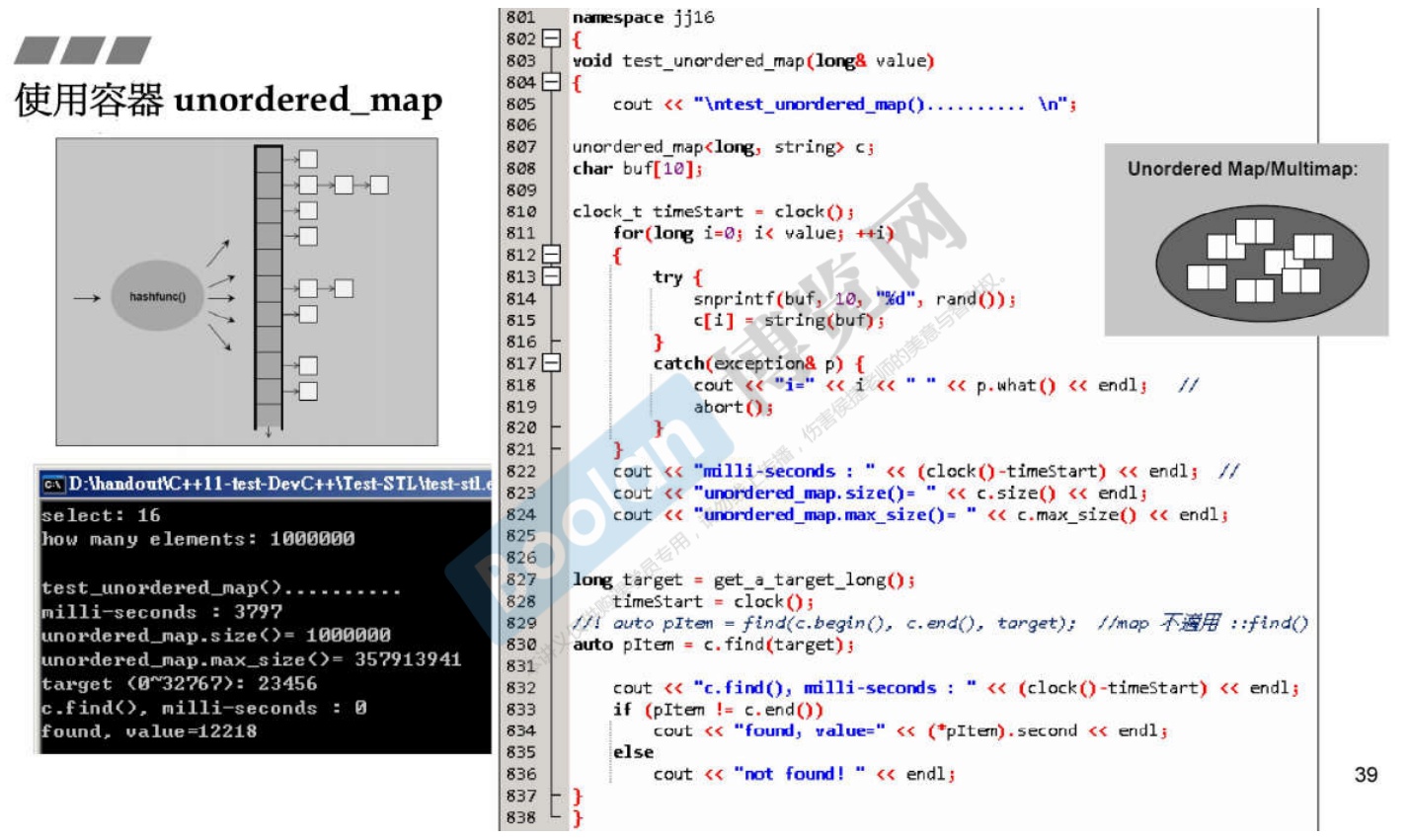
3.18 关于heap和priority_queue
-
其实heap和priority_queue都不能称为容器,而是容器适配器。
-
关于heap 堆
-
heap并不属于STL容器组件,它分为 max heap(大顶堆) 和min heap(小顶堆),在缺省情况下,max-heap是优先队列(priority queue)的底层实现机制。
-
而这个实现机制中的max-heap实际上是以一个vector实现的完全二叉树(complete binary tree)。
-
STL在<algorithm.h>中实现了对存储在vector/deque 中的元素进行堆操作的函数,包括make_heap, pop_heap, push_heap, sort_heap,对不愿自己写数据结构堆的C++选手来说,这几个算法函数很有用。
-
详细解释可以参见: http://www.cplusplus.com/reference/algorithm/make_heap/
-
下面的
_First与_Last为可以随机访问的迭代器(指针),_Comp为比较函数(仿函数),其规则——如果函数的第一个参数小于第二个参数应返回true,否则返回false。 -
1.make_heap():
make_heap(_First, _Last)
make_heap(_First, _Last, _Comp)
默认是建立最大堆的。对int类型,可以在第三个参数传入greater< int>()得到最小堆。
-
2.push_heap(_First, _Last):
新添加一个元素在末尾,然后重新调整堆序。也就是把元素添加在底层vector的end()处。
该算法必须是在一个已经满足堆序的条件下,添加元素。该函数接受两个随机迭代器,分别表示first,end,区间范围。
关键是我们执行一个siftup()函数,上溯函数来重新调整堆序。具体的函数机理很简单,可以参考我的编程珠玑里面堆的实现的文章。
-
3.pop_heap(_First, _Last):
这个算法跟push_heap类似,参数一样。不同的是我们把堆顶元素取出来,放到了数组或者是vector的末尾,用原来末尾元素去替代,然后end迭代器减1,执行siftdown()下溯函数来重新调整堆序。
注意算法执行完毕后,最大的元素并没有被取走,而是放于底层容器的末尾。如果要取走,则可以使用底部容器(vector)提供的pop_back()函数。
-
4.sort_heap(_First, _Last):
既然每次pop_heap可以获得堆中最大的元素,那么我们持续对整个heap做pop_heap操作,每次将操作的范围向前缩减一个元素。当整个程序执行完毕后,我们得到一个非降的序列。注意这个排序执行的前提是,在一个堆上执行。
-
下面是这几个函数操作vector中元素的例子。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46#include <iostream> #include <vector> #include <algorithm> using namespace std; int main() { int a[] = {15, 1, 12, 30, 20}; vector<int> ivec(a, a + 5); for (vector<int>::iterator iter = ivec.begin(); iter != ivec.end(); ++iter) cout << *iter << " "; cout << endl; make_heap(ivec.begin(), ivec.end()); //建堆 for (vector<int>::iterator iter = ivec.begin(); iter != ivec.end(); ++iter) cout << *iter << " "; cout << endl; pop_heap(ivec.begin(), ivec.end()); //先pop,然后在容器中删除 ivec.pop_back(); for (vector<int>::iterator iter = ivec.begin(); iter != ivec.end(); ++iter) cout << *iter << " "; cout << endl; ivec.push_back(99); //先在容器中加入,再push push_heap(ivec.begin(), ivec.end()); for (vector<int>::iterator iter = ivec.begin(); iter != ivec.end(); ++iter) cout << *iter << " "; cout << endl; //通过不断的pop_heap进行排序,从小到大。 sort_heap(ivec.begin(), ivec.end()); for (vector<int>::iterator iter = ivec.begin(); iter != ivec.end(); ++iter) cout << *iter << " "; cout << endl; return 0; } /*输出结果 15 1 12 30 20 30 20 12 1 15 20 15 12 1 99 20 12 1 15 1 12 15 20 99 */ -
关于priority_queue
-
优先队列。
-
优先队列(priority_queue)首先是一个queue,那就是必须在末端推入,必须在顶端取出元素。除此之外别无其他存取元素的途径。内部元素按优先级高低排序,优先级高的在前。缺省情况下,priority_heap利用一个max-heap完成,后者是一个以vector表现的完全二叉树。
-
主要函数包括:
-
1 2 3 4 5 6 7 8bool empty() const size_type size() const const_reference top() const 返回顶端元素。不取走。 void push(const value_type& x) 内部调用push_back(x)和push_heap() void pop() 内部调用pop_heap()和pop_back();
3.19 其他非标准容器
- 这几个容器不在std里面,但是c++11有提供
unodrdered_set等等的替代品。从根本上来说,这些是民间的高手造的轮子,了解如何设计即可,实际不常使用。 
4. 关于分配器allocator
-

-

-
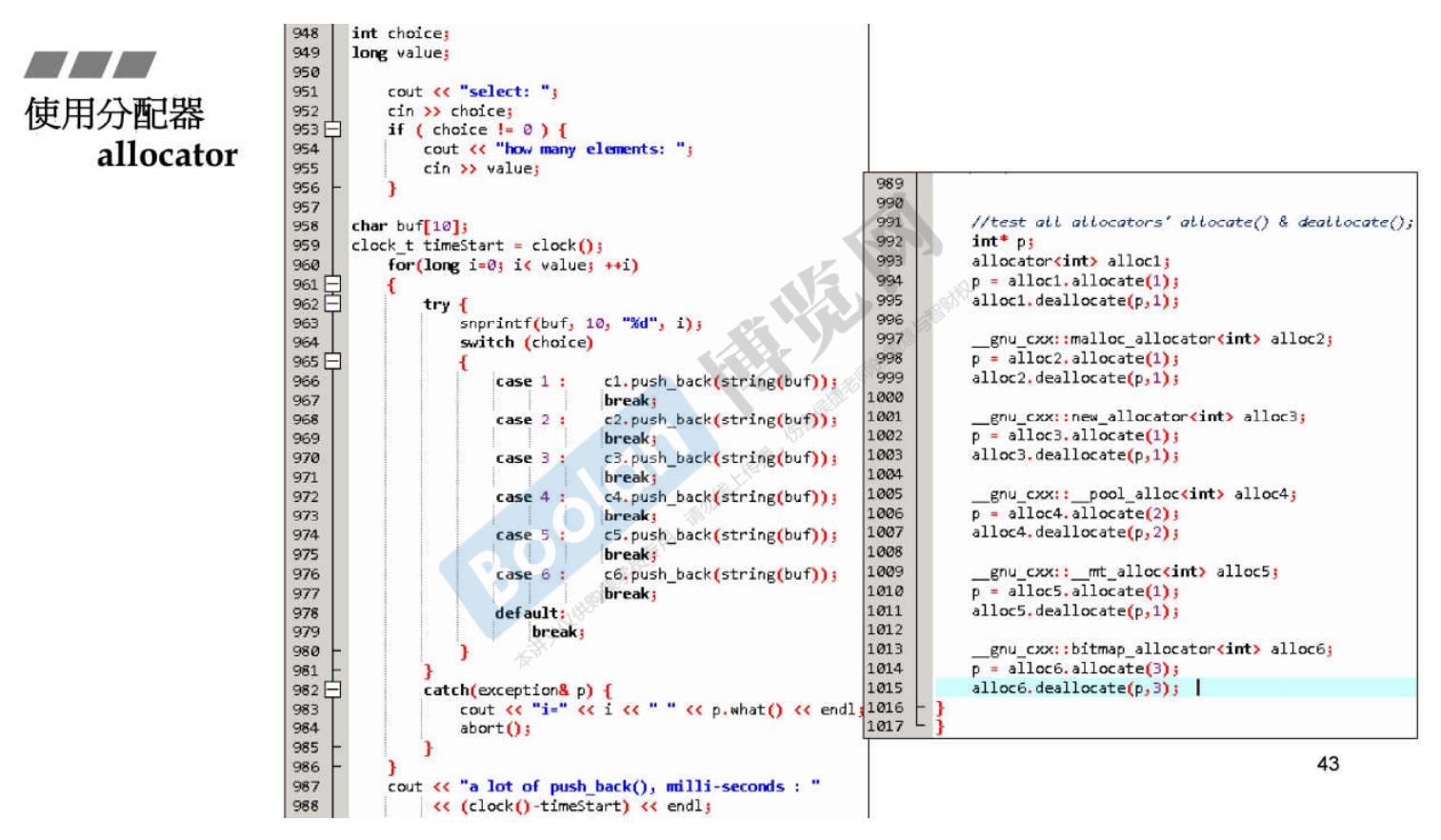
-
allocator 分配器默认都用
std::allocator,当然还有其他的种类。 -
但是如果单纯使用分配,你回收内存需要指明回收的大小,这明显不是个好设计。
-
就像
malloc free,你最后free不用说明释放多大的内存,这才是好的代码。 -
所以,就像侯捷老师说的,最好不要用allocator,而更多的使用container容器,真的需要分配内存,使用
new / malloc进行。
5. OOP(面向对象编程) VS GP(泛型编程)
-
OOP的核心概念是(datas)数据和(methods)函数联系在一起。
-
下图显示为什么list链表为什么无法用全局sort函数。因为list的内存不是连续的,无法像vector一样进行随机访问,所以必须要内置的sort函数。
-

-
但是GP(Generic Programming)的核心概念是datas和methods分开。
-
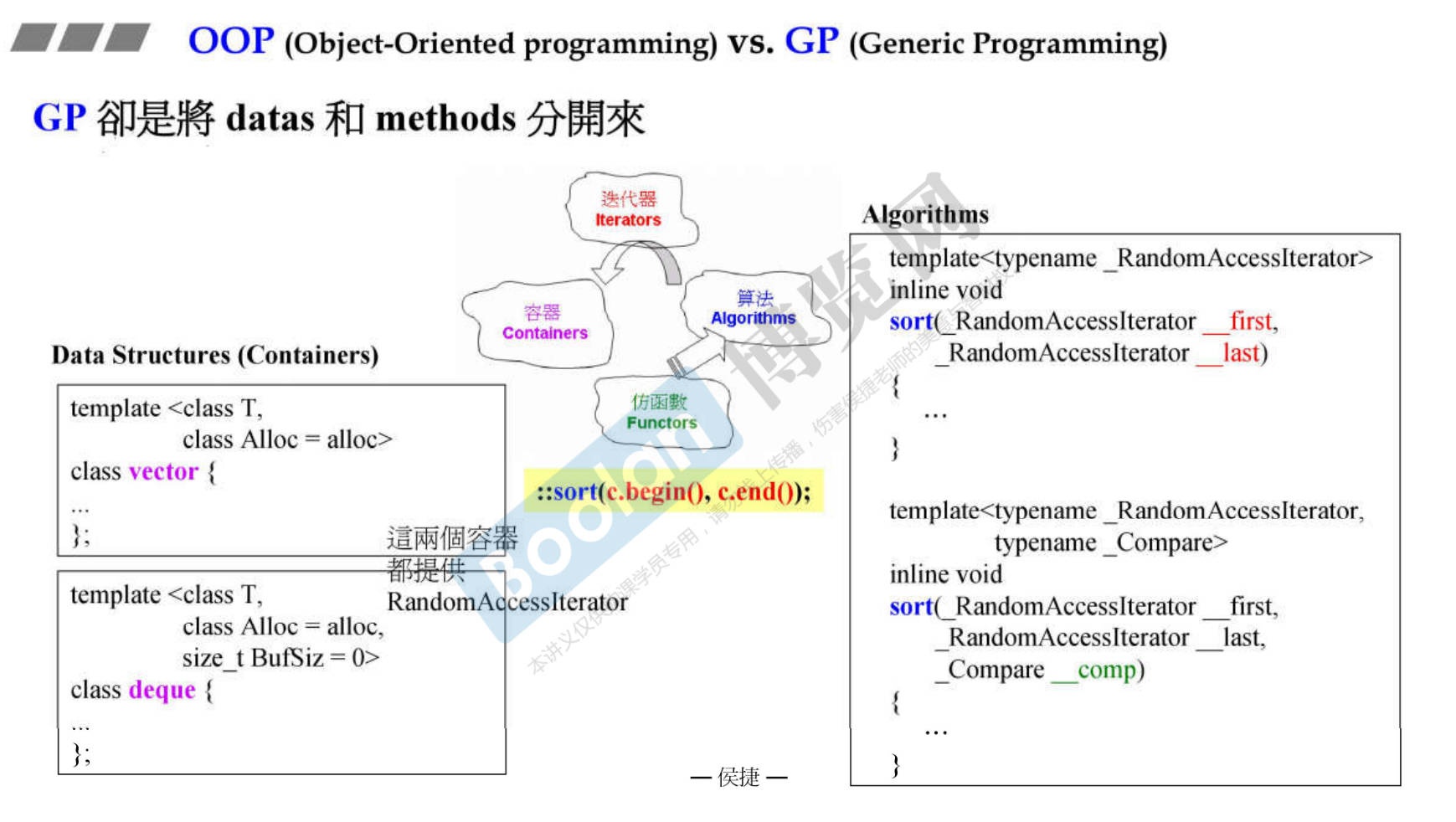
-
怎么分开处理呢,通过迭代器Iterator。容器定义好数据,算法定义好如何处理,两者通过迭代器连接。
-
GP有什么好处呢?
- 容器和算法可以分开设计,闭门造车。
- 最后两者通过迭代器完成功能的实现。
-

-

6. 技术基础:操作符重载 and 模板(泛化、全特化、偏特化)
6.1 operator overloading 操作符重载
-
用的时候学会查阅文档。
-

-

-

6.2 模板
-
模板分为三大类。
-
第一种——类模板。
-

-
第二类——函数模板
-

-
函数模板不需要
<>尖括号显示出来,因为有编译器对函数模板进行实参推导。 -
第三类——成员模板。
-

6.3 specialization 特化
-
也称为全特化。
-
语法标志为
-
1 2 3 4template<> class{ ... } -
或者看到源代码为
__STL_TEMPLATE_NULL即为特化。
-
-

-

-

6.4 parital specialization 偏特化
- 个数上的偏 / 范围上(const或者指针)的偏。

7. Allocators 分配器
-
分配器在日常使用中扮演的是一个默默付出的幕后英雄的角色,即使你可以使用并修改他,但实际建议都不要使用。因为分配器是给容器使用的。分配器的优劣关系到容器的效率,在时间以及内存的使用的效率上都有很大的关系。
-
在高级语言层面,所有的内存分配最终都归结到C语言的
malloc函数里面。
7.1 关于 operator new() 和 malloc()
- 如下图所示,operator new内部会调用malloc函数分配内存。右图的内存分配示意图中,浅蓝色为你需要的内存,灰色的debug添加的调试信息,绿色的内存是为了内存对齐,红色是内存的大小标志cookie(以便后期回收确定内存的大小)。

7.2 VC6 STL 中 allocators 的使用和实现
-
任何allocator,最重要的两个函数都是
allocate:分配内存的成员函数deallocate:回收内存的成员函数
-

-
具体实现。根据侯捷老师所讲,这种设计没有任何特殊之处,右下角的例子很明显的说明了alllocator的难以使用,因为调用deallocate需要传入分配的内存的大小,这在日常开发是不可能的事。同时也暴露一个问题,当容器不断分配的内存的时候,会带来很多的开销overhead(包括cookie+其他调试信息+内存对齐),有可能多余的内存开销比要分配的内存还大(当分配的内存很小的时候)。
-

7.3 BC5 STL 中 allocators 的使用和实现
-
和VC6 的实现基本相同,区别在于,提供了默认的指针,不需要你提供
(int*)0。 -

-
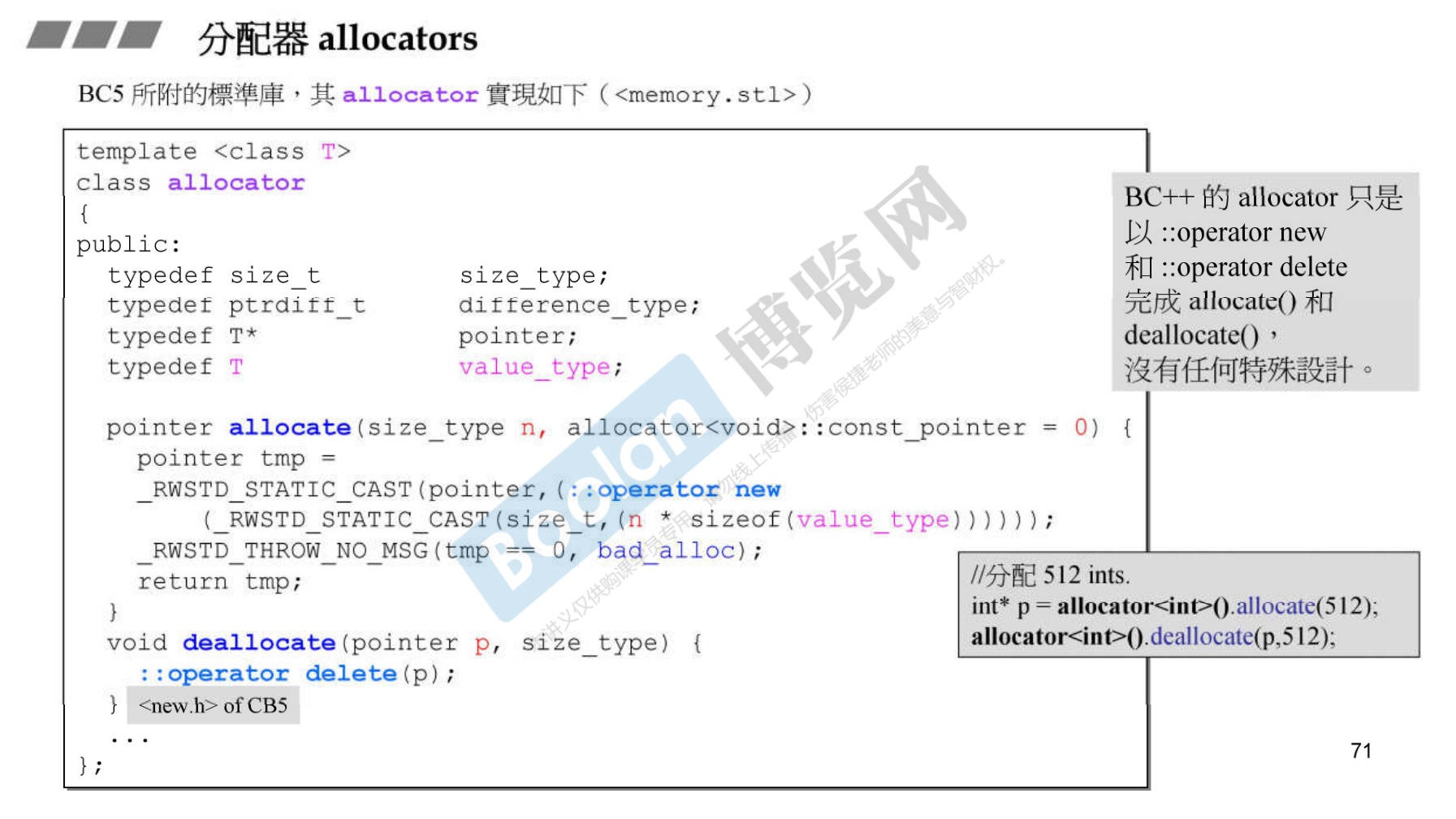
7.3 GCC2.9 STL 中 allocators 的使用和实现
-
GCC2.9按照标准自定义了allocator,但是其内部容器不用这个,用的是SGI实现的另外一种分配器接口。而GCC2.9定义的分配器和上面两者(VC和BC5)的分配器没什么区别。
-

-
GCC2.9的容器实际使用的都是
alloc这个分配器。 -

-
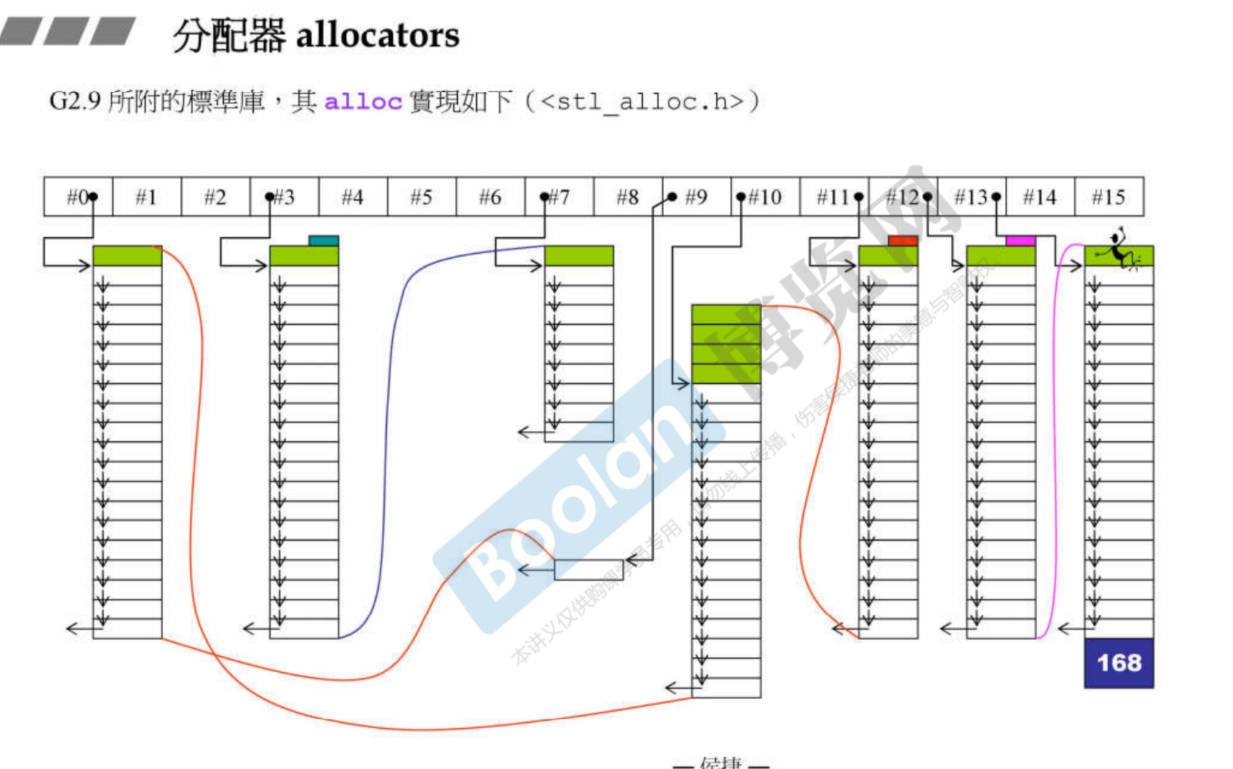
-
alloc这个分配器的实现基础是链表,目的是为了减少每次分配的内存附加的cookie(记录着整块分配的内存的大小)的开销,即减少malloc的次数。
-
设计了16条链表,每条链表负责8个字节*count的大小。所有容器都跟分配器的管理要内存,如果不够,就malloc一大块内存,然后切块,因为分块所以以后的容器内的对象都不需要额外的cookie。(注意容器的数据会被向上增长为8的倍数)。
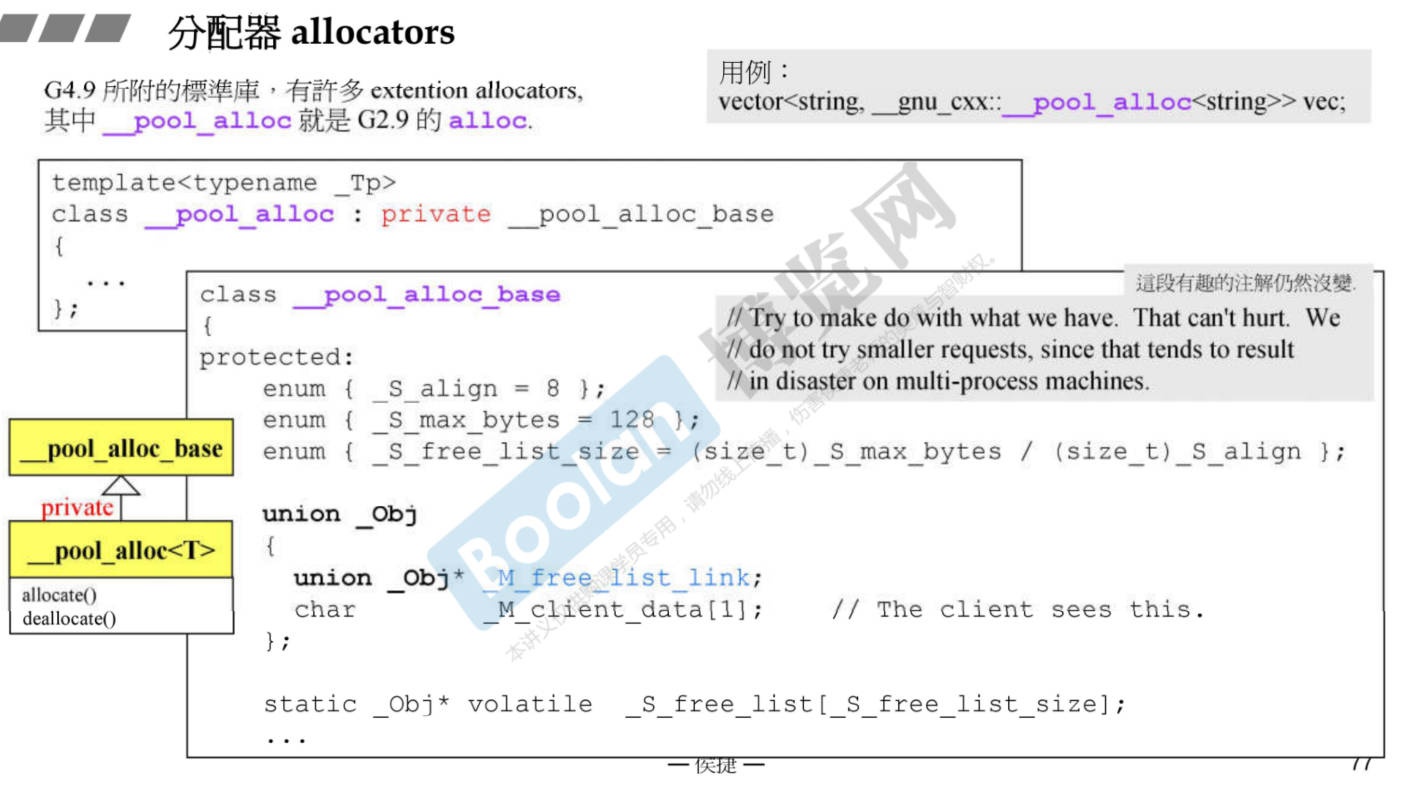
7.4 GCC4.9 STL 中allocators 的使用和实现
-
到了GCC4.9,容器使用的分配器不再是很棒的2.9版本的alloc,而是标准的自定义的allocator(与VC,BC没什么区别)的那个分配器。
-
2.9版本的分配器仍然存在,但是名称改变了。
-
为什么,侯捷老师说不出来。我个人看来,是因为alloc有一部分小缺陷,而随着科技进步,内存不断增大,不用再这么费尽心思节省内存。
-

-

-
2.9版本的alloc改名称了。
-
7.5 关于分配器的sizeof
-
先看示例
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38#include <iostream> #include <ext/malloc_allocator.h> #include <ext/new_allocator.h> #include <ext/pool_allocator.h> #include <ext/bitmap_allocator.h> #include <ext/array_allocator.h> #include <ext/debug_allocator.h> #include <ext/mt_allocator.h> using namespace std; int main() { cout << "sizeof(std::allocator<string>) = " << sizeof(std::allocator<string>) << endl; cout << "sizeof(__gnu_cxx::malloc_allocator<string>) = " << sizeof(__gnu_cxx::malloc_allocator<string>) << endl; cout << "sizeof(__gnu_cxx::new_allocator<string>) = " << sizeof(__gnu_cxx::new_allocator<string>) << endl; cout << "sizeof(__gnu_cxx::__pool_alloc<string>) = " << sizeof(__gnu_cxx::__pool_alloc<string>) << endl; cout << "sizeof(__gnu_cxx::bitmap_allocator<string>) = " << sizeof(__gnu_cxx::bitmap_allocator<string>) << endl; cout << "sizeof(__gnu_cxx::__mt_alloc<string>) = " << sizeof(__gnu_cxx::__mt_alloc<string>) << endl; cout << "sizeof(__gnu_cxx::array_allocator<string>) = " << sizeof(__gnu_cxx::array_allocator<int>) << endl; //已经被弃用了 cout << "sizeof(__gnu_cxx::debug_allocator<std::allocator<double>>) = " << sizeof(__gnu_cxx::debug_allocator<std::allocator<double>>) << endl; cout << "sizeof(size_t) = " << sizeof(size_t) << endl; // 8个字节 int *checkPtr = new int(8); cout << "pointer size = " << sizeof(checkPtr) << endl; // 8 个字节 return 0; } /*输出结果 sizeof(std::allocator<string>) = 1 sizeof(__gnu_cxx::malloc_allocator<string>) = 1 sizeof(__gnu_cxx::new_allocator<string>) = 1 sizeof(__gnu_cxx::__pool_alloc<string>) = 1 sizeof(__gnu_cxx::bitmap_allocator<string>) = 1 sizeof(__gnu_cxx::__mt_alloc<string>) = 1 sizeof(__gnu_cxx::array_allocator<string>) = 16 sizeof(__gnu_cxx::debug_allocator<std::allocator<double>>) = 16 sizeof(size_t) = 8 pointer size = 8 -
输出1的,理论都是0,但是实际会有一个字节的开销。
-
为什么理论是0,以
std::allocator<>为例。 -
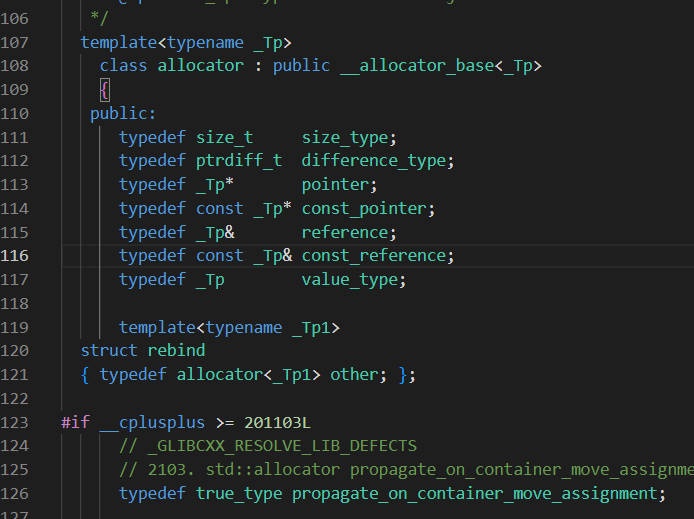
-
很明显啊,都是typedef,没有一个具体的变量,所以没有空间开销。
-
至于后面两个为什么是16,以
array_allocator为例(虽然已经被弃用了,实验用的gcc8.1) -
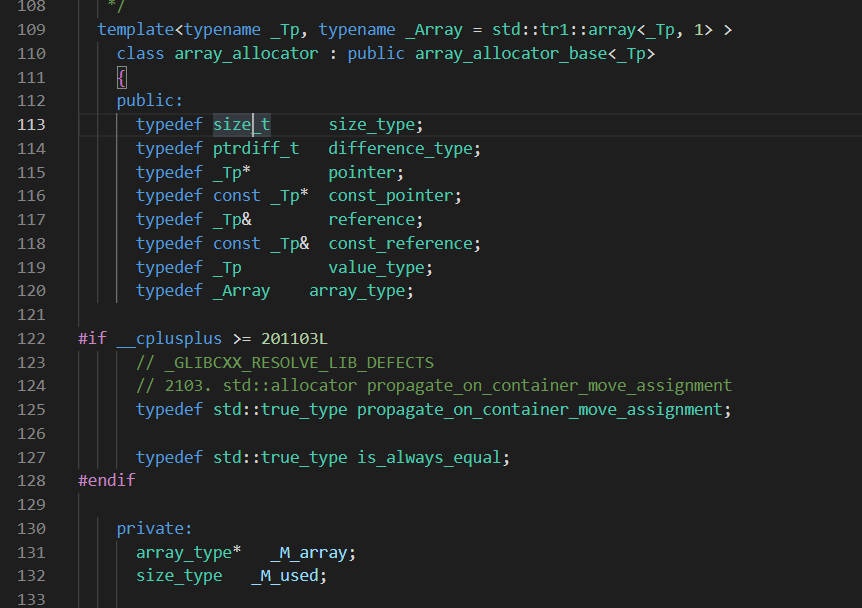
-
可以看到,定义了两个数据,一个是指针,一个是
size_t。都是8个字节,加起来就是16个字节(64位win11)。 -
侯捷老师的总结,和实验结果出入不大。
-

8. 容器及其迭代器的sizeof
-

-
上图中,以缩进关系表示复合(不是继承),因为你想要其中一个类的所有功能,有两种方法
- 复合
- 继承
-
上图中的方式都是复合。
-
容器的size要看内部定义了多少变量;迭代器的大小就是指针的大小。
-
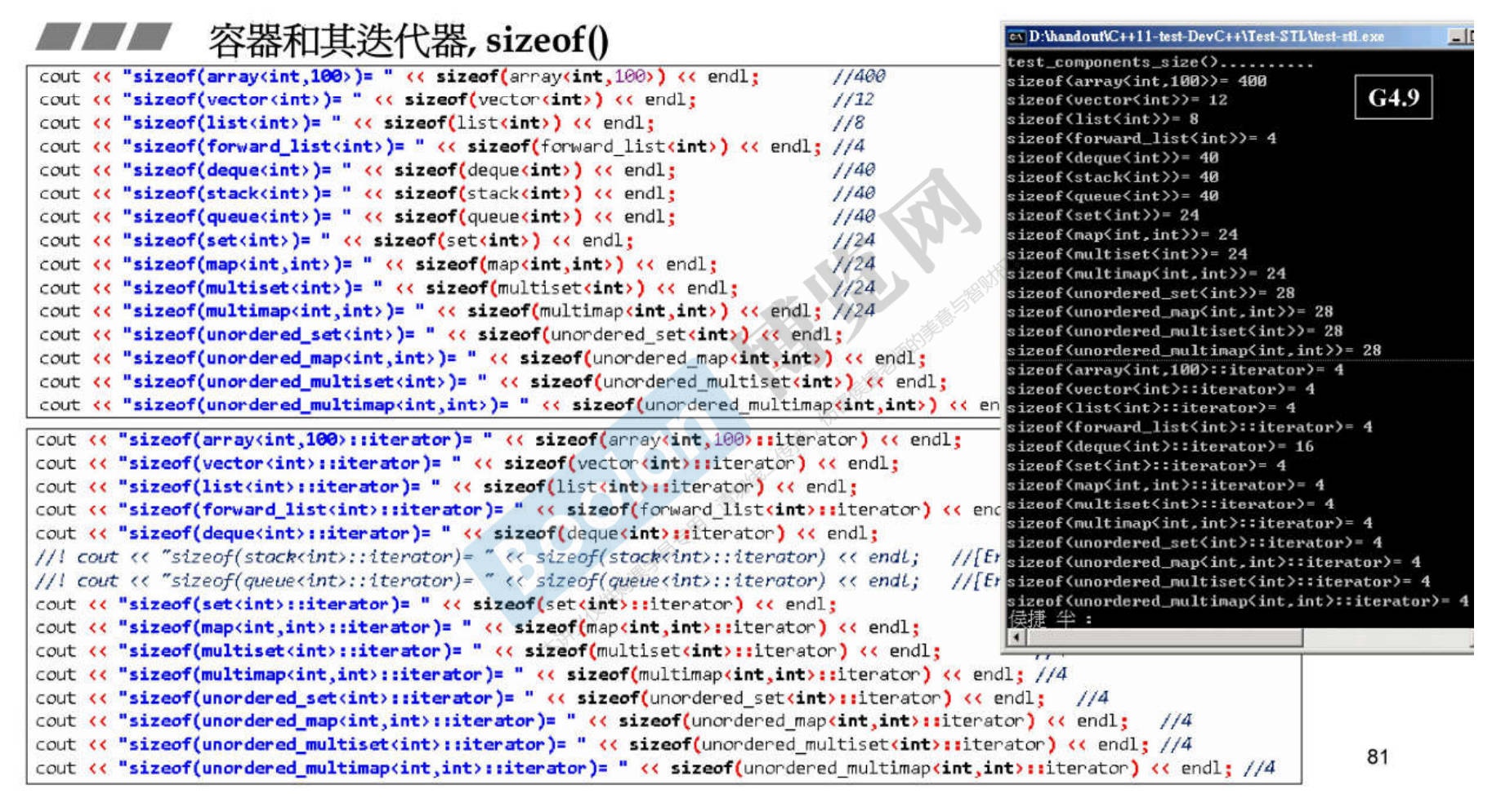
-
1 2 3 4 5cout << sizeof(std::vector<int>) << endl; cout << sizeof(vector<int>::iterator) << endl; /*输出结果 24 8
9. 深度探索 list
-
关于list的内部设计
-
是一个双向链表。
-
list的数据只有一个
list_node*指针,即大小为8字节(64位)。 -
同时typedef 了迭代器。
-
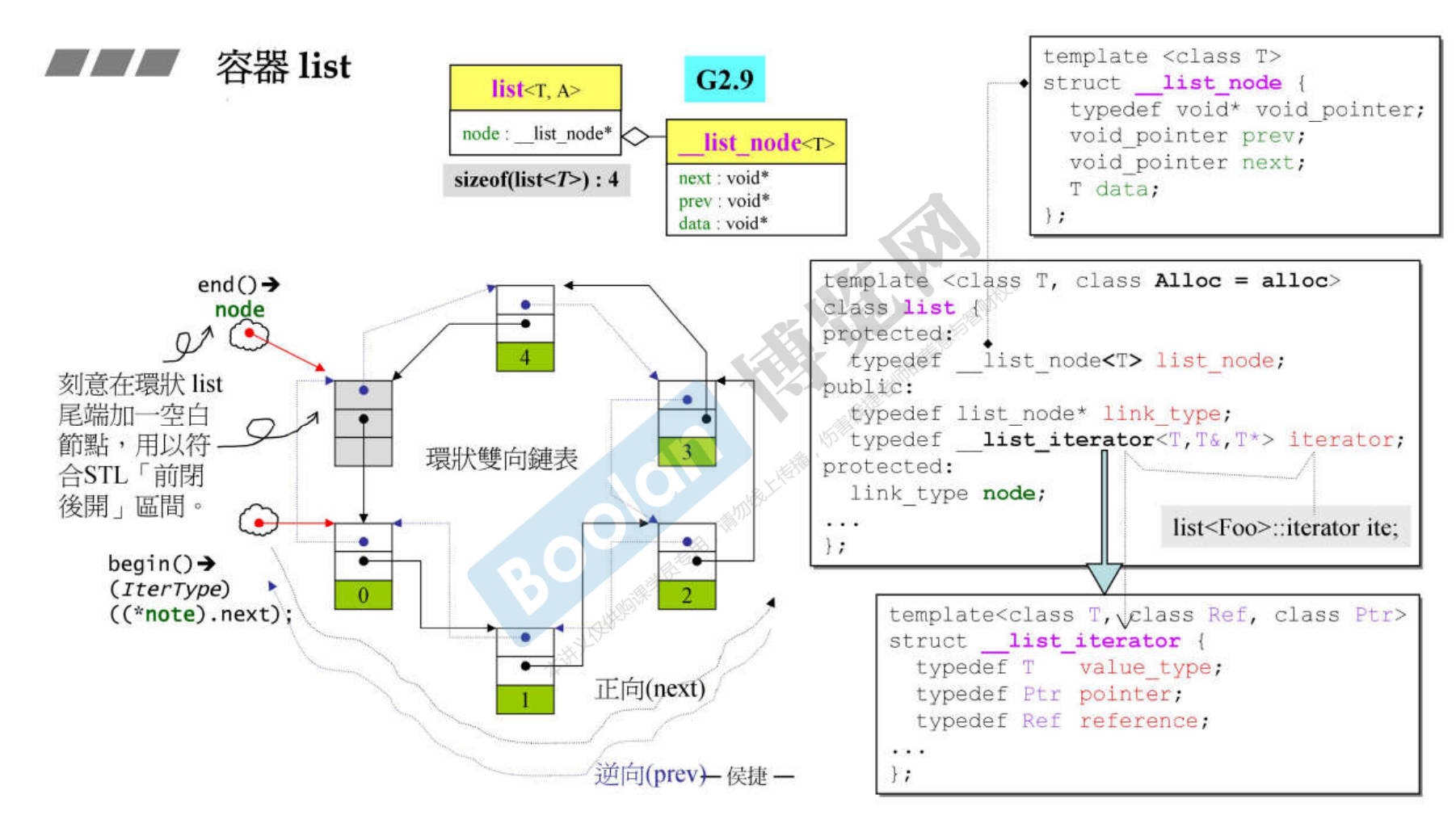
-
关于Iterator
-
Iterator是一个聪明的指针,必须是一个class。
-
几乎所有的Iterator都定义了5个typedef,如下图标注的(1)(2)等等。
-

-
同时对各种操作符进行了重载。
-
关于前置++ 和 后置++
-
操作符重载关于++都是一样的,那如何区分是前置++(prefix)还是后置++(postfix)呢。
-
c++规定添加了参数(无意义)的为后置++,无参数的为前置++。
-
1 2 3 4 5 6 7self& operator++(){ ...//前置++ } self operator++(int){ ...//后置++ } -
为什么后置++不返回引用,而前置++返回引用呢。是为了致敬int以及对齐int的操作。对于整数类型来说,
-
1 2 3int i = 0; ++++i;//是允许的 i++++;//是不允许的 -
所以为了防止迭代器后置++两次,所以不返回引用,杜绝此类行为。
-
-
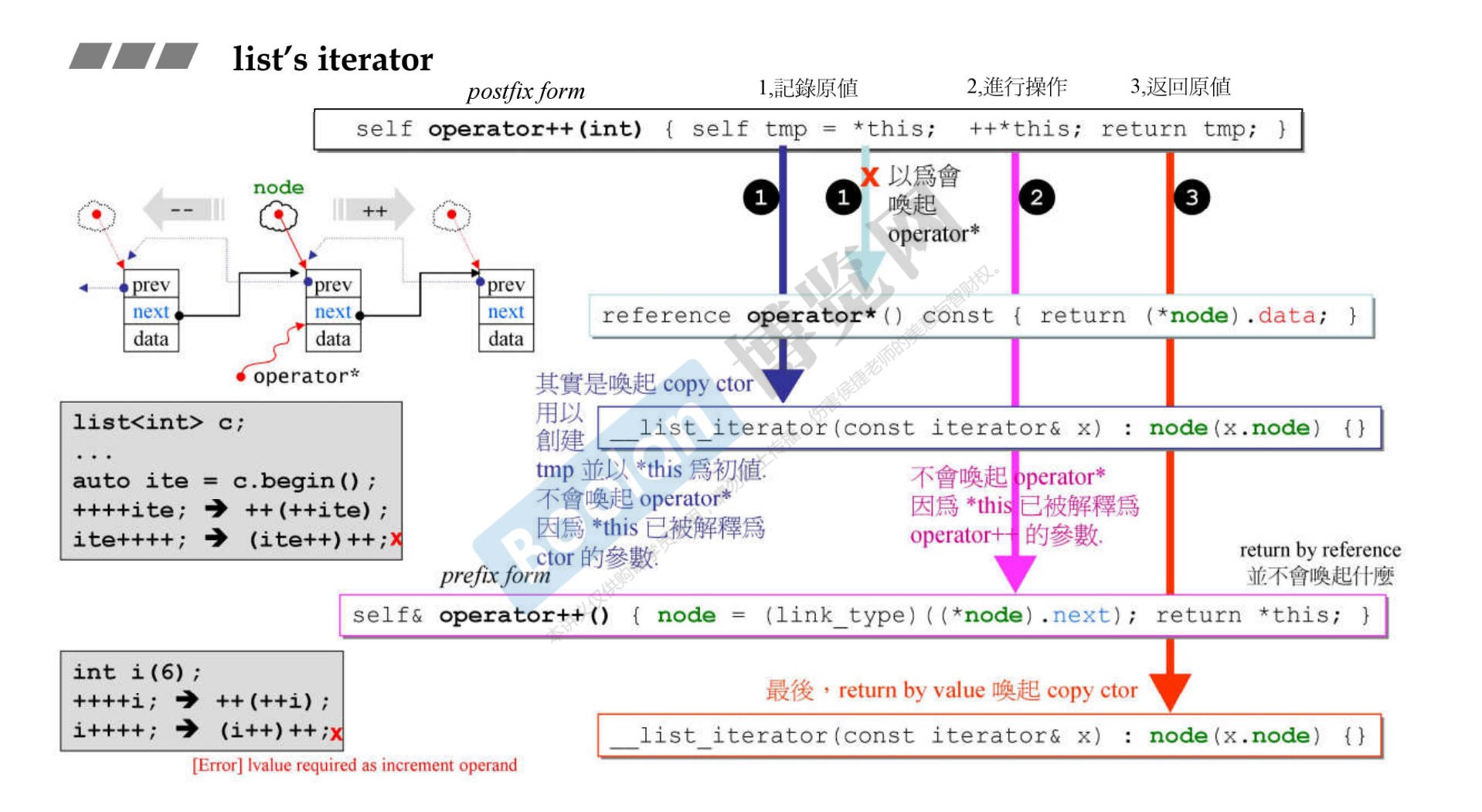
-
如上图所示,先分析前置++的细节
- 直接把内置数据node指向下一个,没有其他的唤起。
- 返回的是引用值。
-
再讨论后置++的细节
- 首先记录原值。注意*this并不会调用
*重载运算符函数,因为前面有=,先调用拷贝构造函数,此时*表示为解引用,当成拷贝构造函数的初值。 - 然后调用前置++重载函数。
- 最后返回原值,再次唤起拷贝构造函数。
- 返回的不是引用。
- 首先记录原值。注意*this并不会调用
-
关于
*和->运算符的重载 -
值得一提的是,
->运算符重载会一直调用->直到返回需要的函数/数据。其内部实现调用的是*重载函数。 -
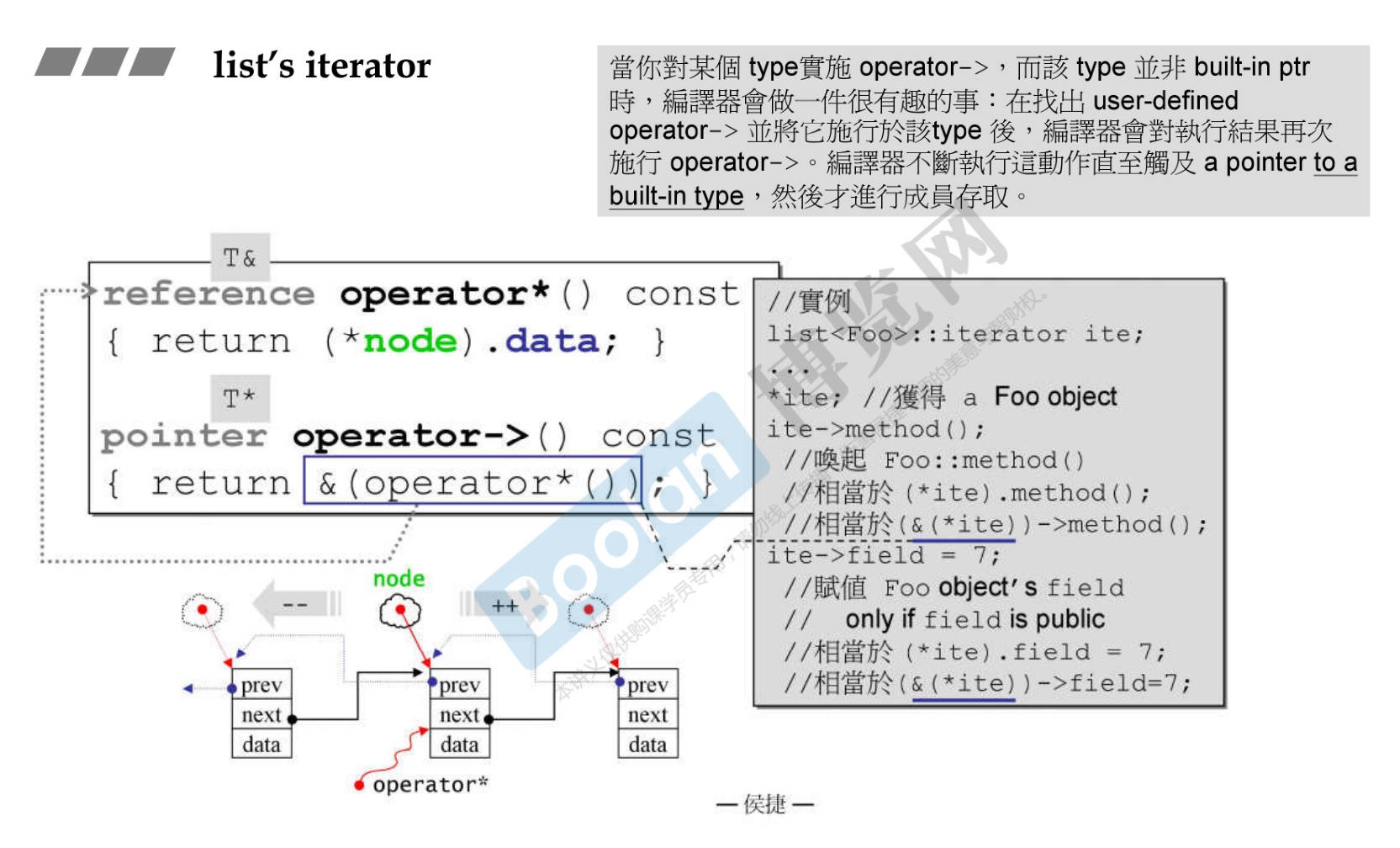
-
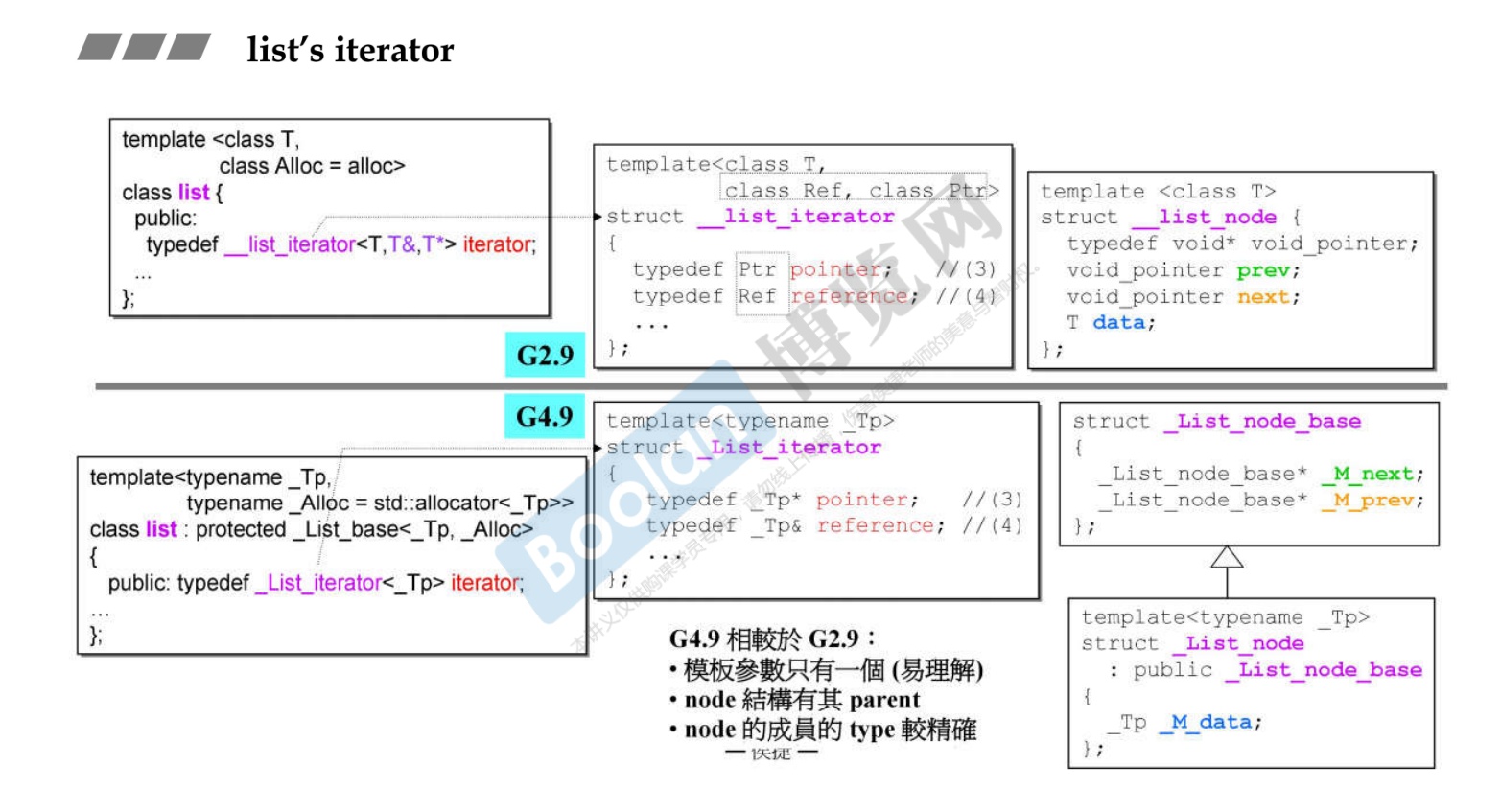
关于GCC2.9到GCC4.9的改进
-
上面的所有涉及都是GCC2.9版本的。可以看出有以下两个问题。
- 1.模板参数竟然需要三个,但是这三个都是同一个基本结构,只是一个是指针,一个是引用。
- 2.链表结构的设计问题,链表前后的指针怎么是
void*,应该是他本身才对。
-
-
所以GCC4.9对2.9进行了改进,如上所示。
-
GCC4.9 对list的实现
-
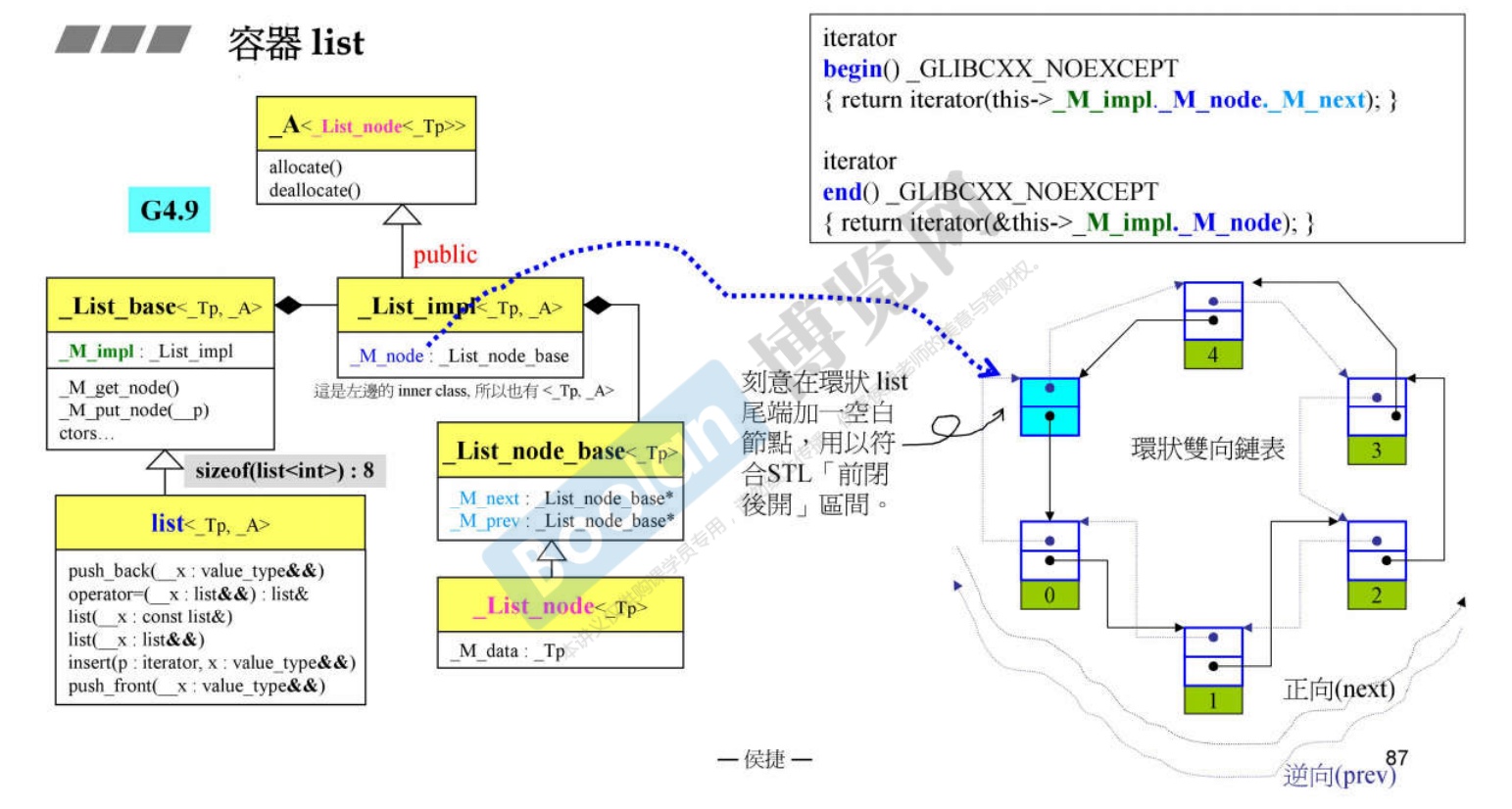
-
GCC4.9 的list 实现比较复杂,空间比2.9多了一个指针的大小。
-
关于 forward_list
-

10. Iterator 必须遵循的5个准则 以及 Traits
10.1 五个准则
-
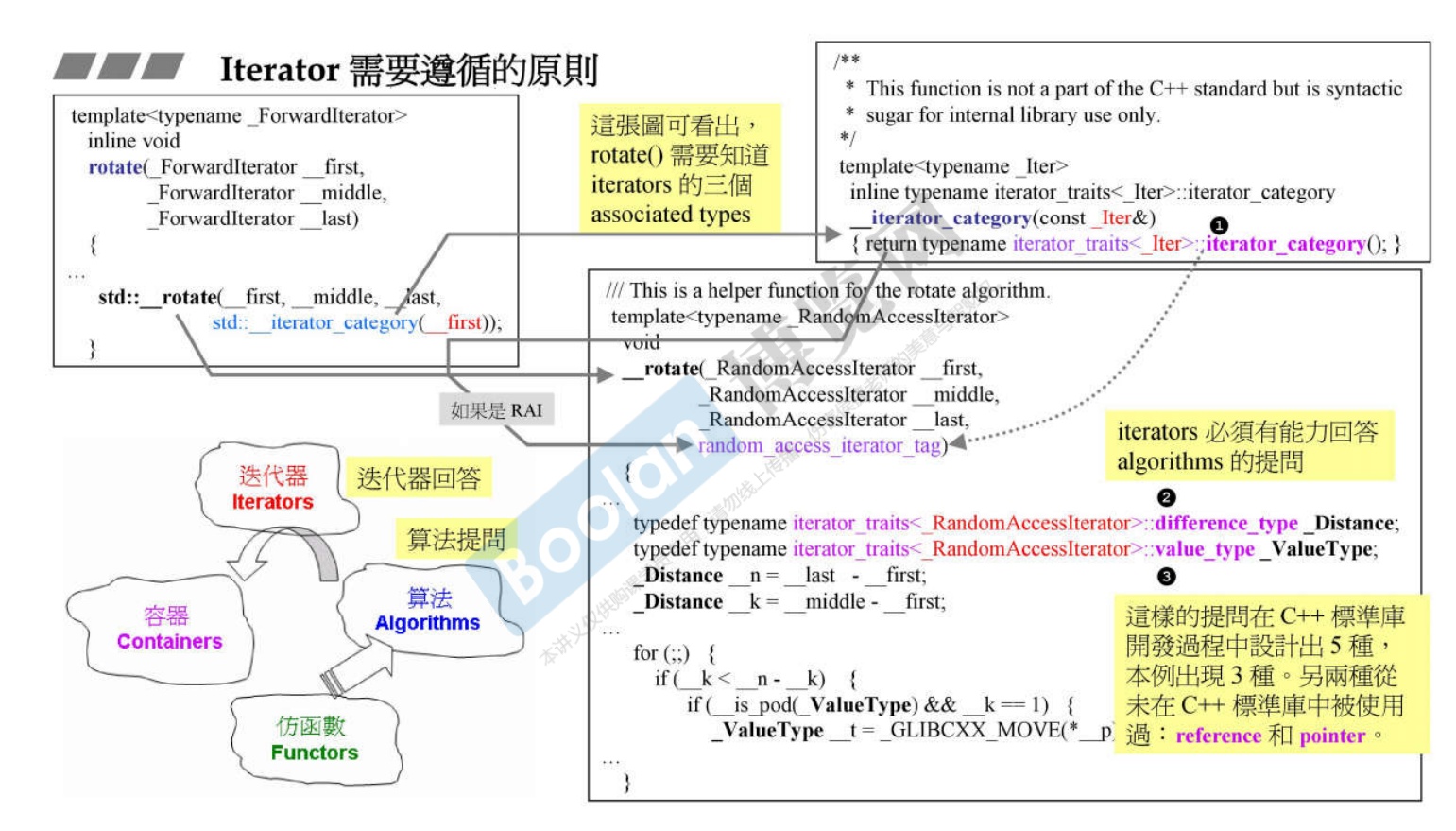
-
Traits:人为设计制造的萃取机。设计一个traits,就是你丢一个东西给他,你希望这个traits能够萃取出你想要的特征。标准库里有很多Traits。比如Iterator Traits;Type Traits;Character Traits;Pointer Traits等等。
-
迭代器本身需要定义出来5个
associated types,以便能够回答算法的提问。-
category:分类
-
difference_type:距离,difference_type表示两个迭代器之间的距离。对于原生指针,c++内建了
ptrdiff_t(位于头文件内)作为原生指针的difference_type(在iterator_traits<(const) T*>中使用)。当需要迭代器I的
difference_type,可以写typename iterator_traits<I>::difference_type。 -
values_type:所指的对象的类型
-
reference
-
pointer
-
-
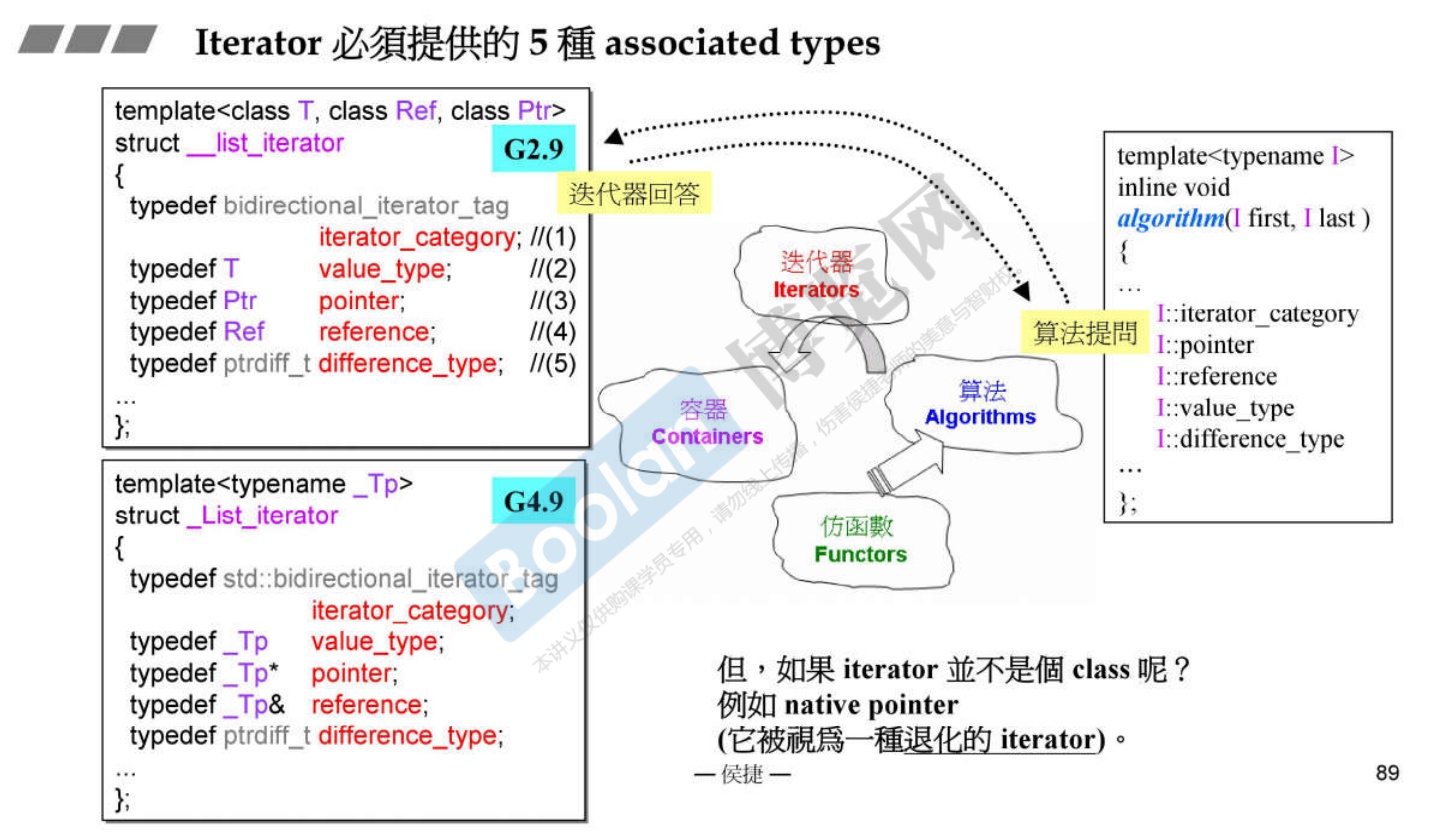
-
指针是一种退化的Iterator;Iterator也称为泛化的指针。
-
那么问题来了,类可以定义以上五种associated types,可以正确回答算法的问题;但是指针是不能够回答的,那么如何解决这个问题呢。
-
答案是使用萃取技术——Traits。

10.2 Traits 概述
-
我们知道,在 STL 中,容器与算法是分开的,彼此独立设计,容器与算法之间通过迭代器联系在一起。那么,算法是如何从迭代器类中萃取出容器元素的类型的?没错,这正是我们要说的 traits classes 的功能。
-
个人理解就是使用偏特化技术,给不是类的迭代器(即是个单纯的指针)加个包装,以适应算法。
-
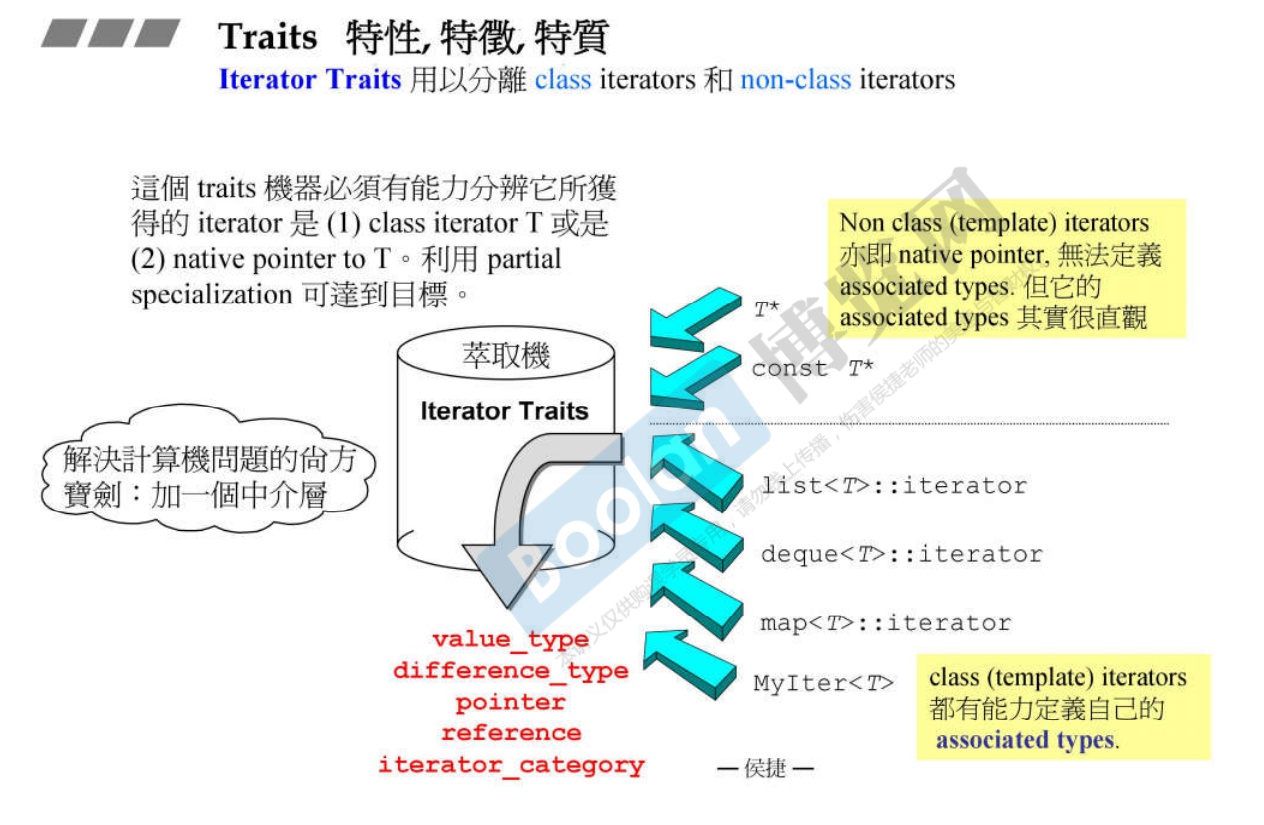
-

-

-

10.3 typename 的 两种用法
-
第一种:普通模板声明中typename和class的用法一样,如下:
-
1 2 3 4 5 6 7template<typename T> class test_typename{ }; template<class T> class testclass{ }; -
第二种:用来指定相应名称为类型。
-
例如,如下代码会报编译错误。
-
1 2 3 4 5 6template<typename visitor> class test{ public: /*编译器无法判断visitor::type是成员变量还是类型,而typedef只能用于类型*/ typedef visitor::type type; } -
在typedef后面添加typename表面为类型,即可编译成功。广泛运用到STL里面。
-
1 2 3 4 5template<typename visitor> class test{ public: typedef typename visitor::type type; }
10.4 Traits小实验
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50#include <iostream> #include <vector> #include <algorithm> using namespace std; template <class IterT> struct my_iterator_traits { typedef typename IterT::value_type value_type; }; //偏特化版本 template <class IterT> struct my_iterator_traits<IterT *> { typedef IterT value_type; }; void fun(int a) { cout << "fun(int) is called" << endl; } void fun(double a) { cout << "fun(double) is called" << endl; } void fun(char a) { cout << "fun(char) is called" << endl; } int main() { my_iterator_traits<vector<int>::iterator>::value_type test1; fun(test1); // 输出 fun(int) is called my_iterator_traits<vector<double>::iterator>::value_type test2; fun(test2); // 输出 fun(double) is called my_iterator_traits<char *>::value_type test3; fun(test3); // 输出 fun(char) is called return 0; } /*输出 fun(int) is called fun(double) is called fun(char) is called */ -
可以看到,
char *会转为输出char类型,可以正确运行。
11. 深度探索 vector
11.1 GCC 2.9 版本
-
关于设计
-
2.9 版本的定义比较简洁明了,同时需要注意的是定义的迭代器 Iterator 是一个指针!这表明了需要借助 Traits 进行类型萃取。
-

-
GNU的vector是以两倍方式增长的,但是VC是以1.5倍增长的。
-
关于扩容
-
为什么下图中的
insert_aux又做一次检查,那是因为insert_aux不止被push_back调用,还有其他的函数也调用了 -

-

-
分配好足够空间之后,把原来的拷贝到新的空间,同时释放原来的空间,调用析构函数。
-
关于迭代器
-
之前的双向链表list的迭代器是一个单独的类,那是因为链表的节点在内存上是分离的。
-
但是vector的内存是连续的,从本质上来讲,vector的iterator并不需要单独的class,指针即可完成功能,只需要traits提供给算法的包装即可。
-
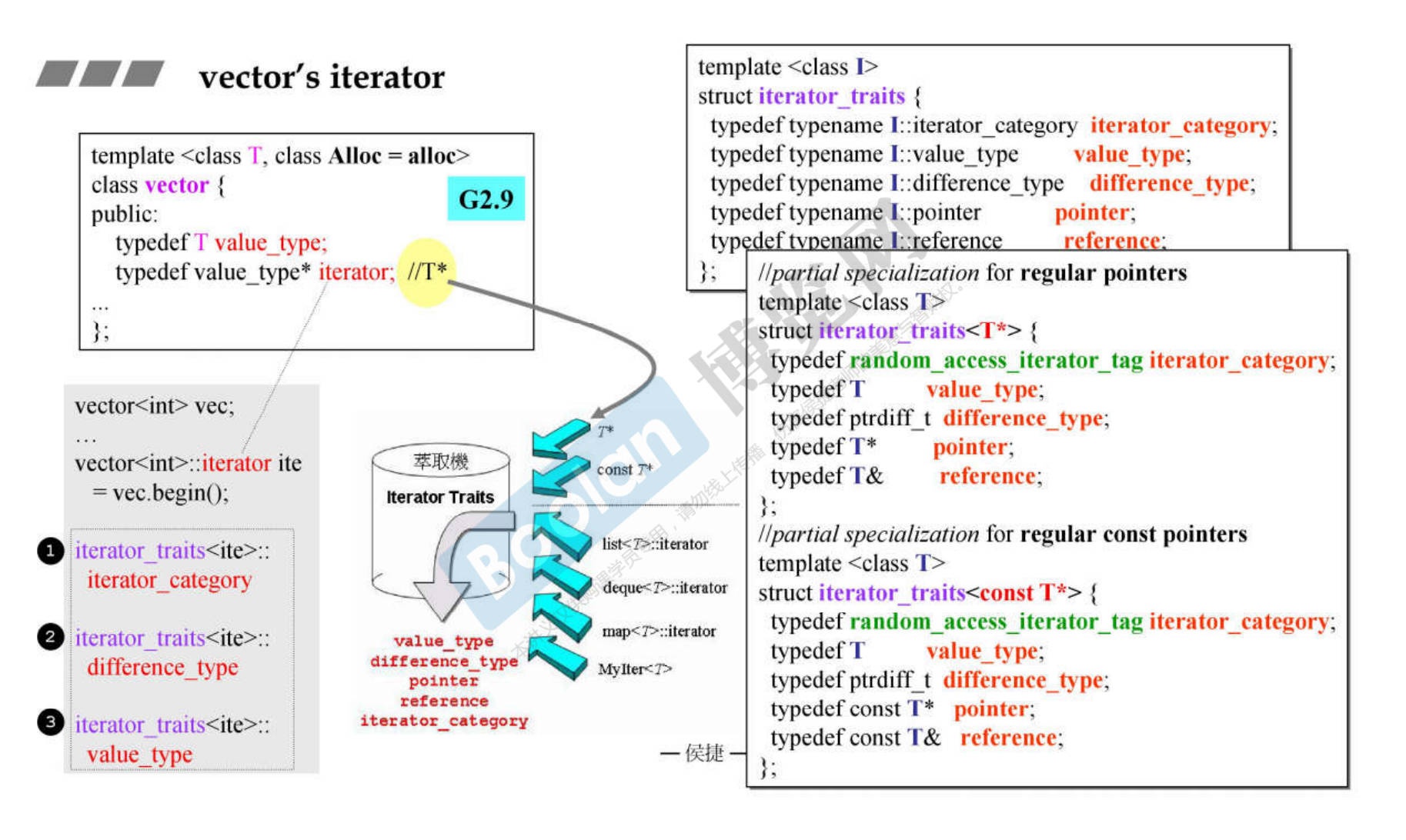
11.2 GCC 4.9 版本
-
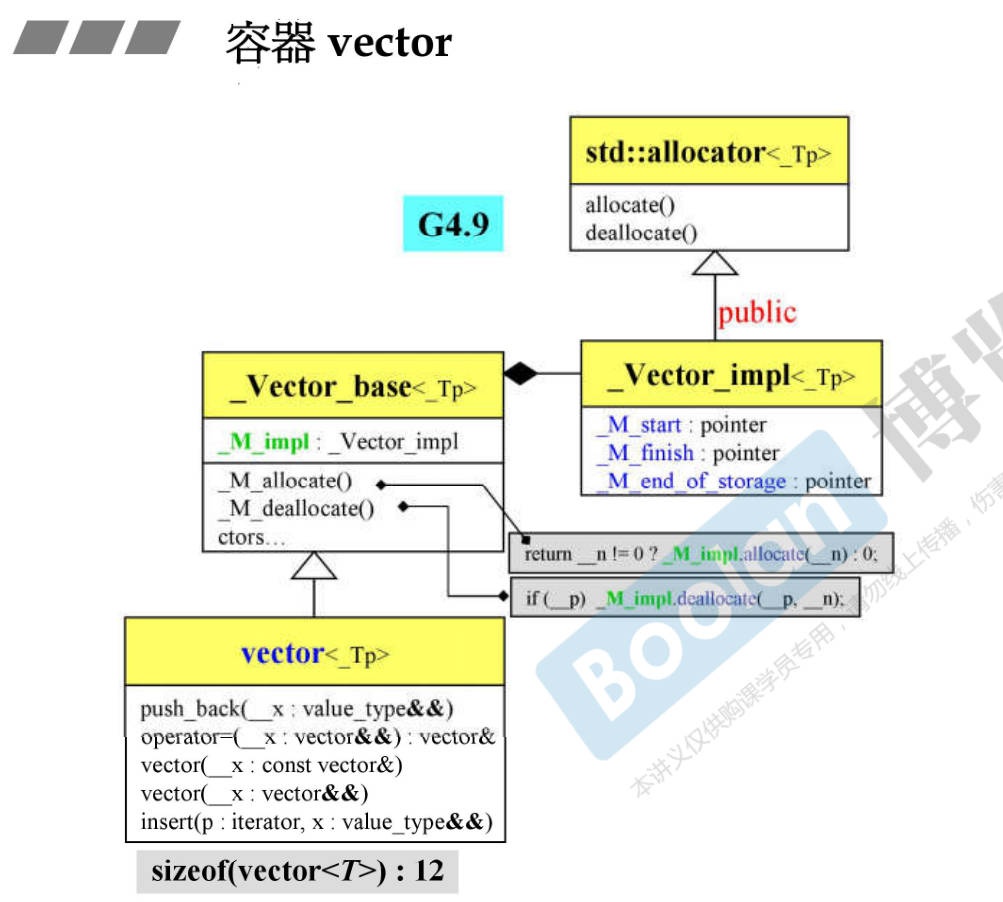
-
2.9版本只是一个单纯的类,4.9的话就做了多重包装,源码阅读性很低。
-
同时,新版本的迭代器是一个单独的class。
-
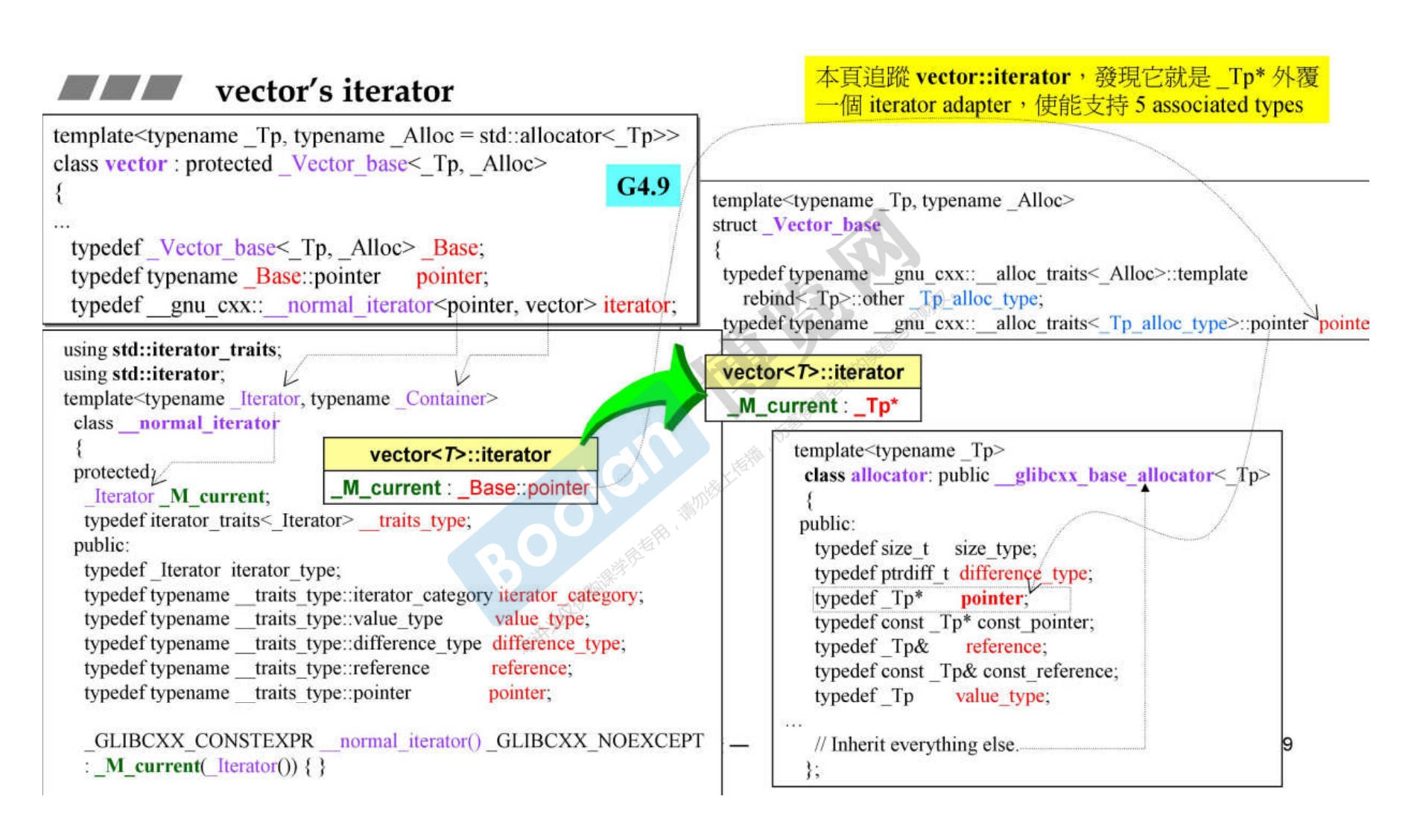
-
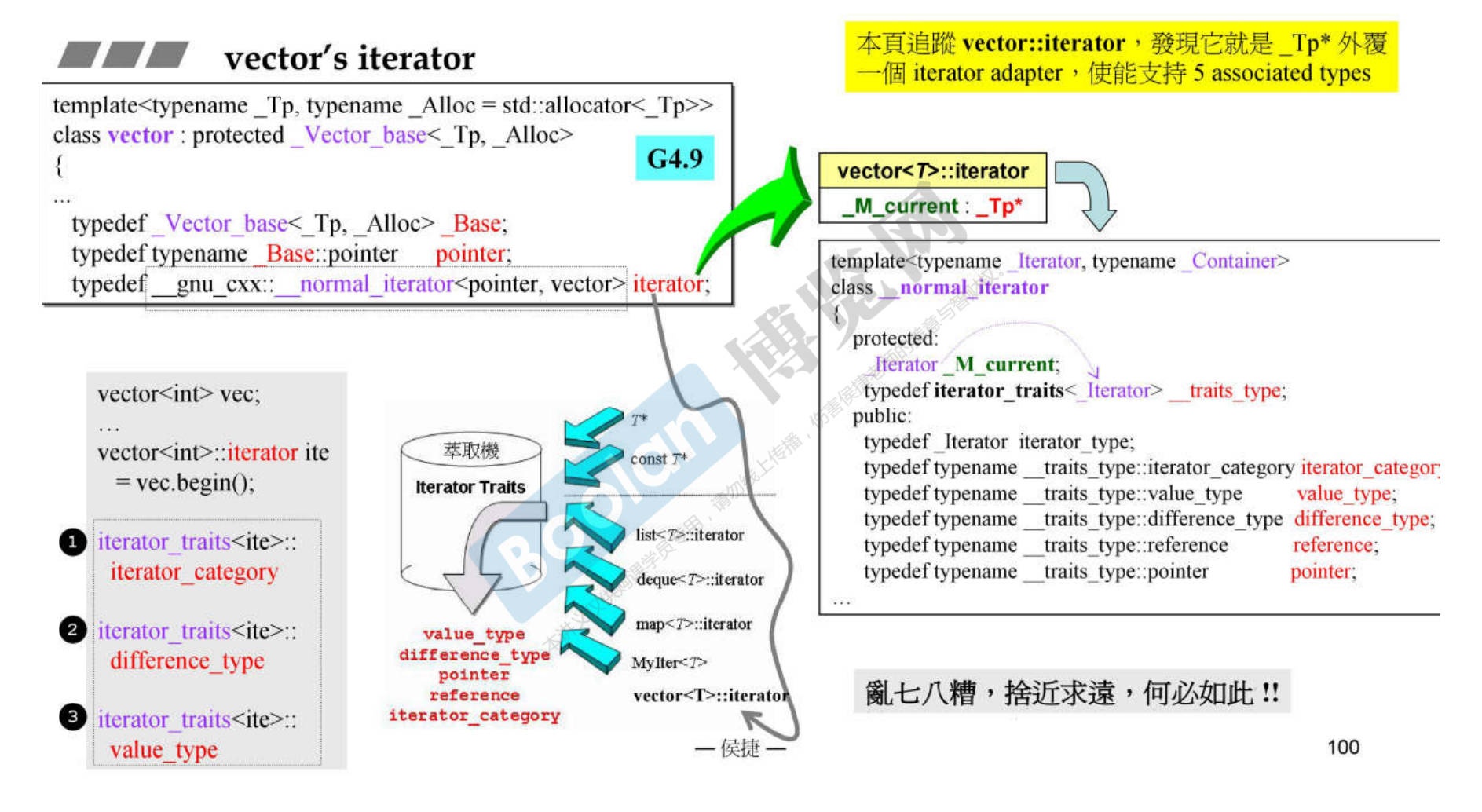
12. 深度探索 array
- 为什么要把array设计成容器呢,因为变成容器后array就要遵循容器的相关规则,例如要提供迭代器,迭代器要提供5中
associate_types来适应相对应的仿函数、算法等等。 - array没有构造函数,也没有析构函数,直接用指针当成迭代器。通过萃取机适应算法。
12.1 GCC 2.9 版本
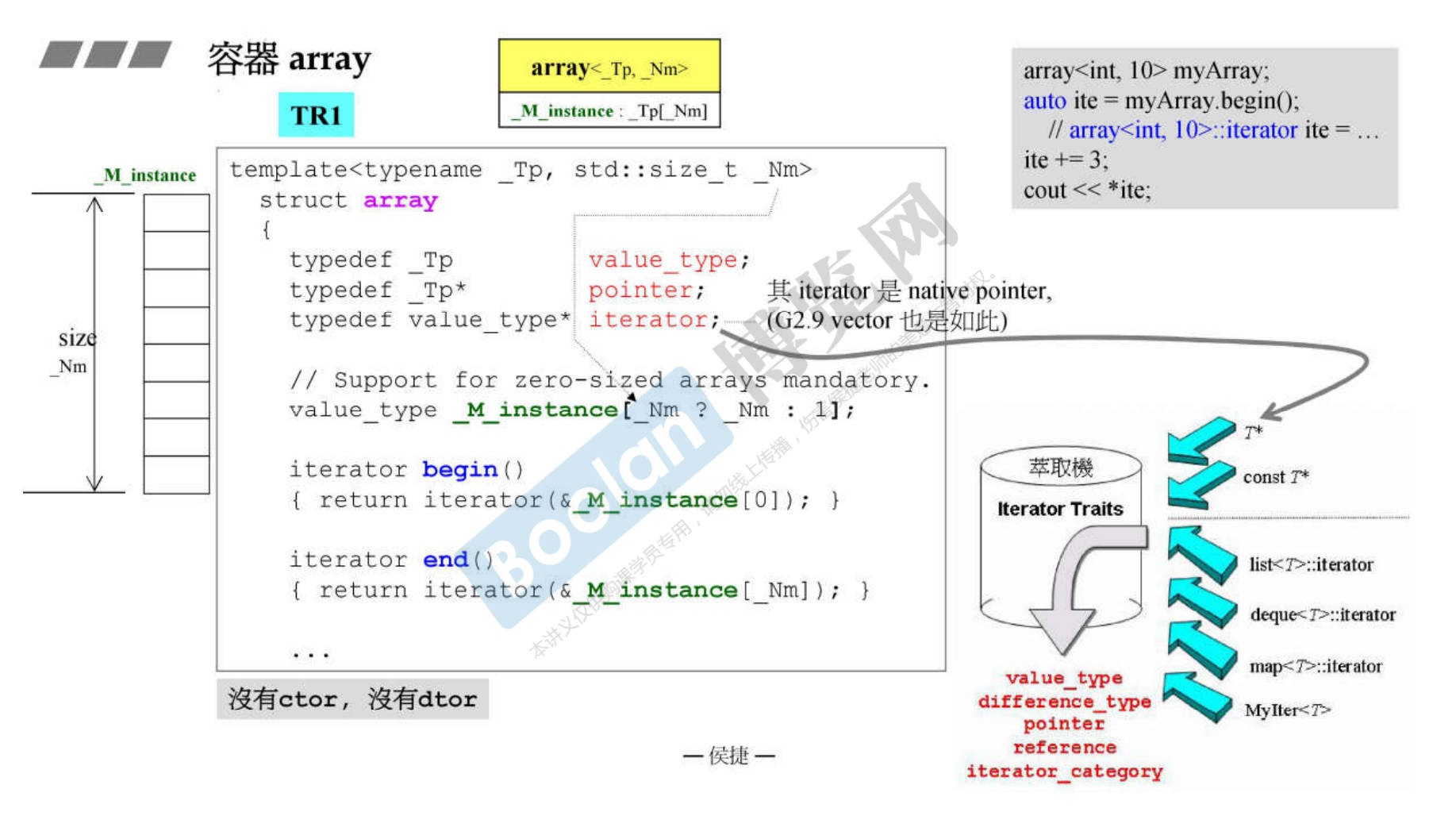
12.2 GCC 4.9 版本
-
源码需要不断查看在哪,比较复杂。但是基本思想和2.9区别不大,迭代器仍然是指针。
-
需要说明的是,可以typedef 一个数组名,如下所示
-
1 2 3 4 5 6 7 8 9 10 11 12 13int main() { typedef int T[5]; T c; for (int i = 0; i < 5; ++i) { c[i] = i; } return 0; } /* 但是 int[100] b;//是不可以的 -

13. 深度探索 deque
- deque 是一个双端队列。
- 特点
- 支持快速随机访问(支持索引取值)
- 在头尾插入/删除速度很快
- deque是非常复杂的数据结构,由多个vector组成,迭代器使用时会在不同的区间跳转
- 存取元素的时候,deque的内部结构会多出一个间接过程,相比vector操作会慢一些
- 对内存有限制的系统中,deque比vector可以包含更多元素,因为它不止使用一块内存
13.1 GCC 2.9 版本
-
关于设计
-
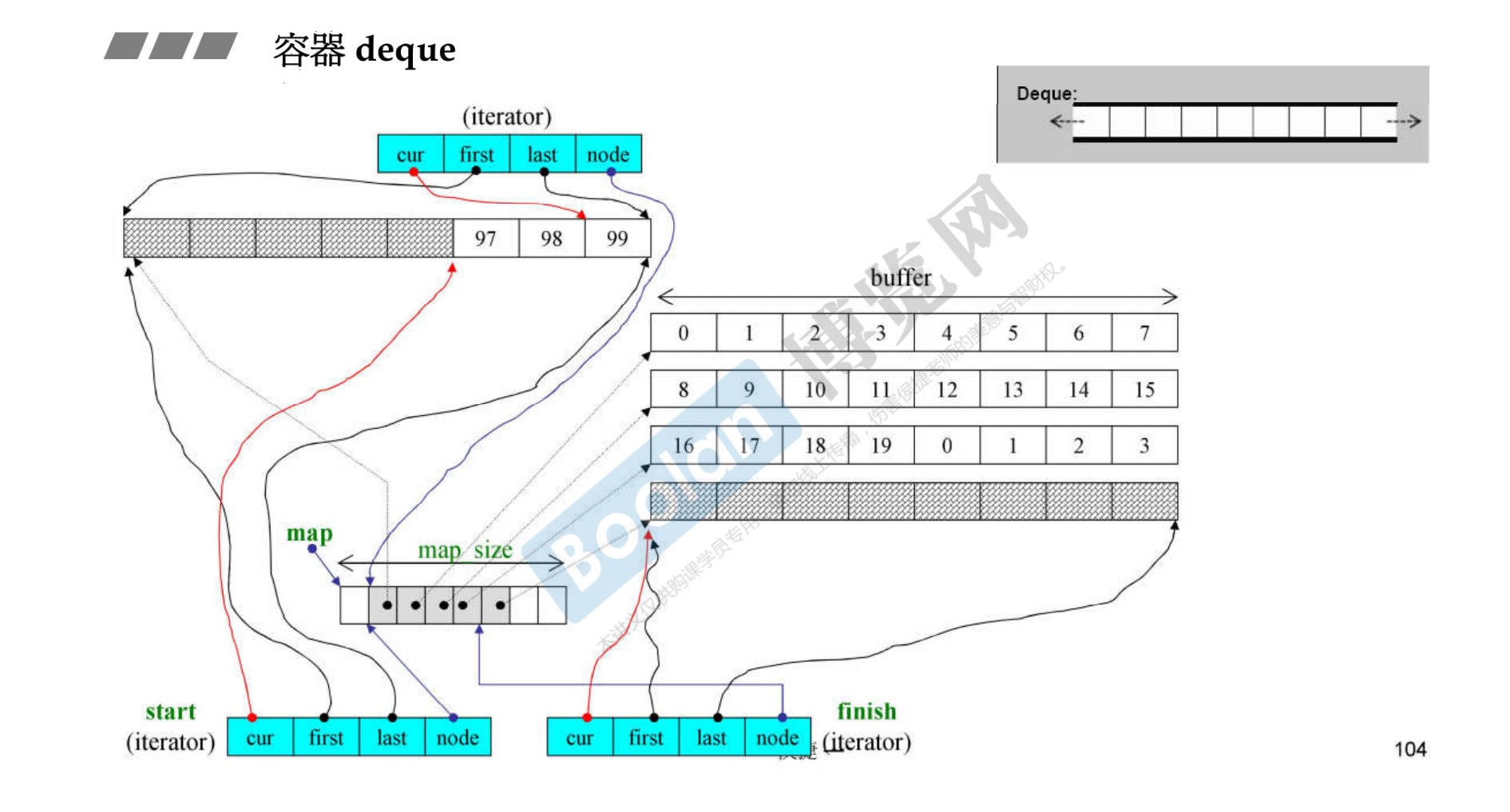
-
如上图所示,两段式内存。一个是控制中心map,一个是实际对象存放的内存buffer。可以简单理解为vector的vector,区别在于,内存不是连续的。
-
-
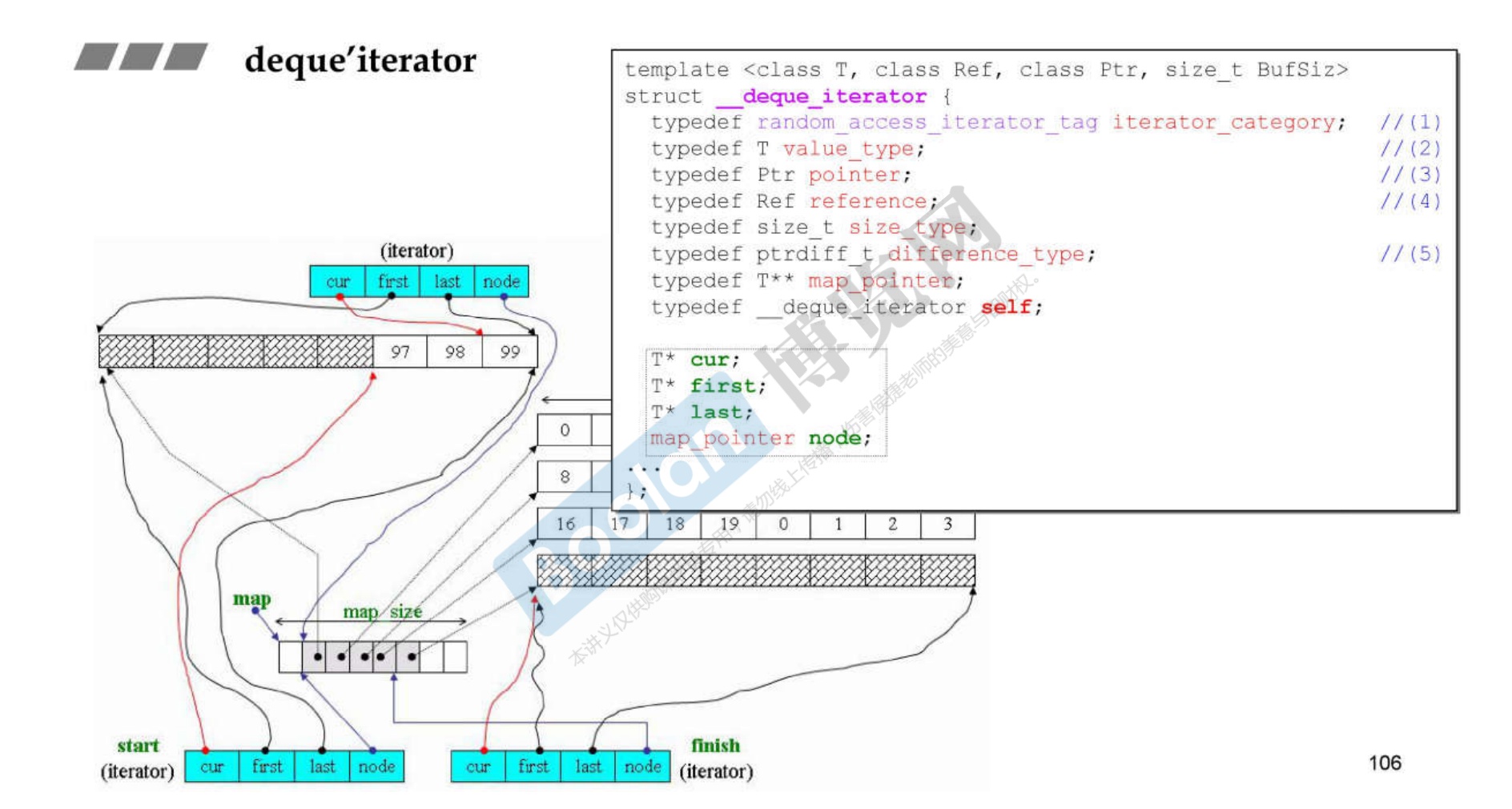
-
可以看到,deque的内存分布主要是
- start Iterator(迭代器大小)
- finish Iterator(迭代器大小)
- map_size(size_t,unsigned long long)
- map_pointer(指针的指针,实际还是一个指针的大小)
-
其中迭代器Iterator的内部数据大小又分为(4个都是指针)
- curr:当前buffer的位置
- first:当前buffer的首位置
- last:当前buffer的末尾位置
- node:当前buffer在map中的位置
-
所以,在32位机器上,deque的大小为40字节;在64位电脑上,deque的大小为80字节(
8*4*2+8+8) -
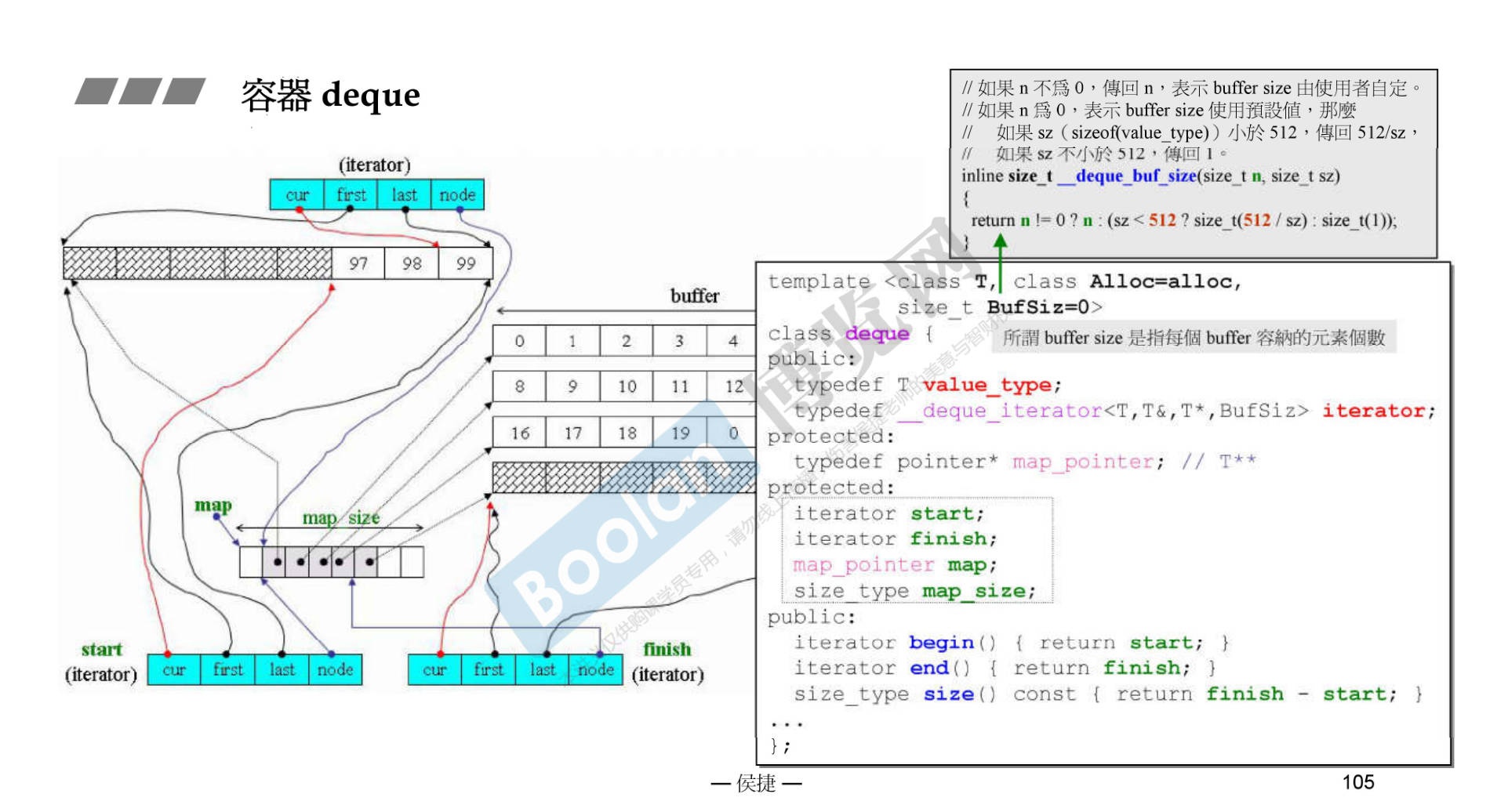
需要注意的是,缓冲区buffer的大小在2.9版本是可以自定义的。默认是512字节,分配的块 = 512/对象的大小;如果对象大于512字节,那么就分配一个块。
__deque_buf_size()函数。- deque采用一块所谓的map(注意,不是STL的map容器)做为主控
- 这里所谓map是一小块连续空间,其中每个元素(此处称为节点,node)都是指针, 指向另一段(较大的)连续线性空间,称为缓冲区
- 缓冲区才是deque 的储存空间主体。SGI STL允许我们指定缓冲区大小,默认值0表示将使用512 bytes缓冲区
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17template <class T, class Alloc = alloc, size_t BufSiz = 0> class deque { public: //Basic types typedef T value_type; typedef value_type* pointer; ... protected: //Internal typedefs //元素的指针的指针(pointer of pointer of T) typedef pointer* map_pointer; protected: // Data members map_pointer map; //指向 map,map是块连续空间,其内的每个元素 //都是一个指标(称为节点),指向一块缓冲区 size_type map_size; //map内可容纳多少指针 ... }; -
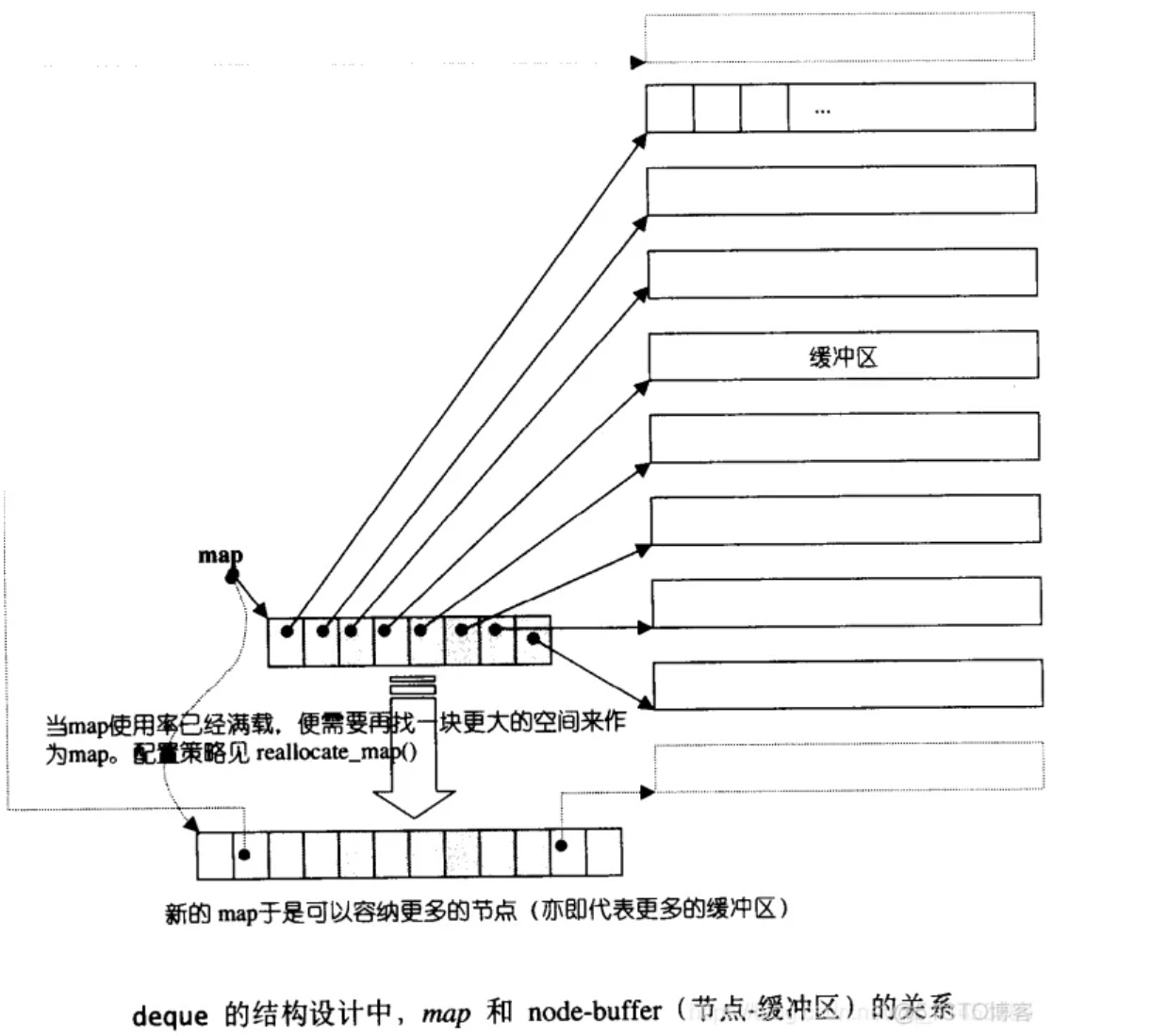
-
而map的扩容是基于
reallocate_map()函数的,类似于vector,都是2倍扩容。 -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31template <class T, class Alloc, size_t BufSize> void deque<T, Alloc, BufSize>::reallocate_map(size_type nodes_to_add,bool add_at_front) { size_type old_num_nodes = finish.node - start.node + 1; size_type new_num_nodes = old_num_nodes + nodes_to_add; map_pointer new_nstart; if (map_size > 2 * new_num_nodes) { new_nstart = map + (map_size - new_num_nodes) / 2+ (add_at_front ? nodes_to_add : 0); if (new_nstart < start.node) copy(start.node, finish.node + 1, new_nstart); else copy_backward(start.node, finish.node + 1, new_nstart + old_num_nodes); } else { //新的内存大小,可以看到是2倍+2 size_type new_map_size = map_size + max(map_size, nodes_to_add) + 2; // 配置一块空间,准备给新 map使用。 map_pointer new_map = map_allocator::allocate(new_map_size); new_nstart = new_map + (new_map_size - new_num_nodes) / 2+ (add_at_front ? nodes_to_add : 0); //把原map内容拷贝过来 copy(start.node, finish.node + 1, new_nstart); //释放原map map_allocator::deallocate(map, map_size); //设定新map的起始地址与大小 map = new_map; map_size = new_map_size; } // 重新设定迭代器 start 和 finish start.set_node(new_nstart); finish.set_node(new_nstart + old_num_nodes - 1); } -
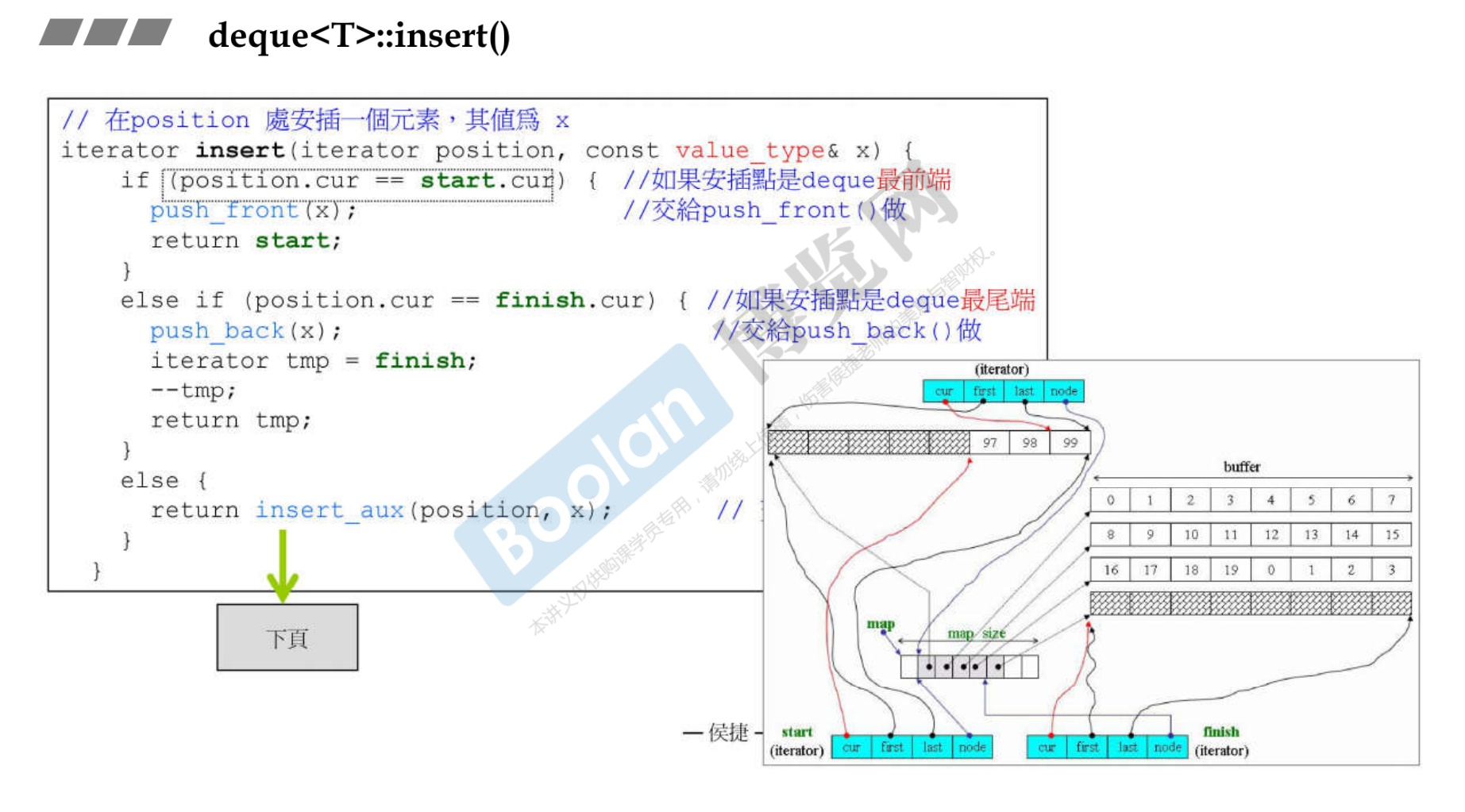
关于 insert 函数
-
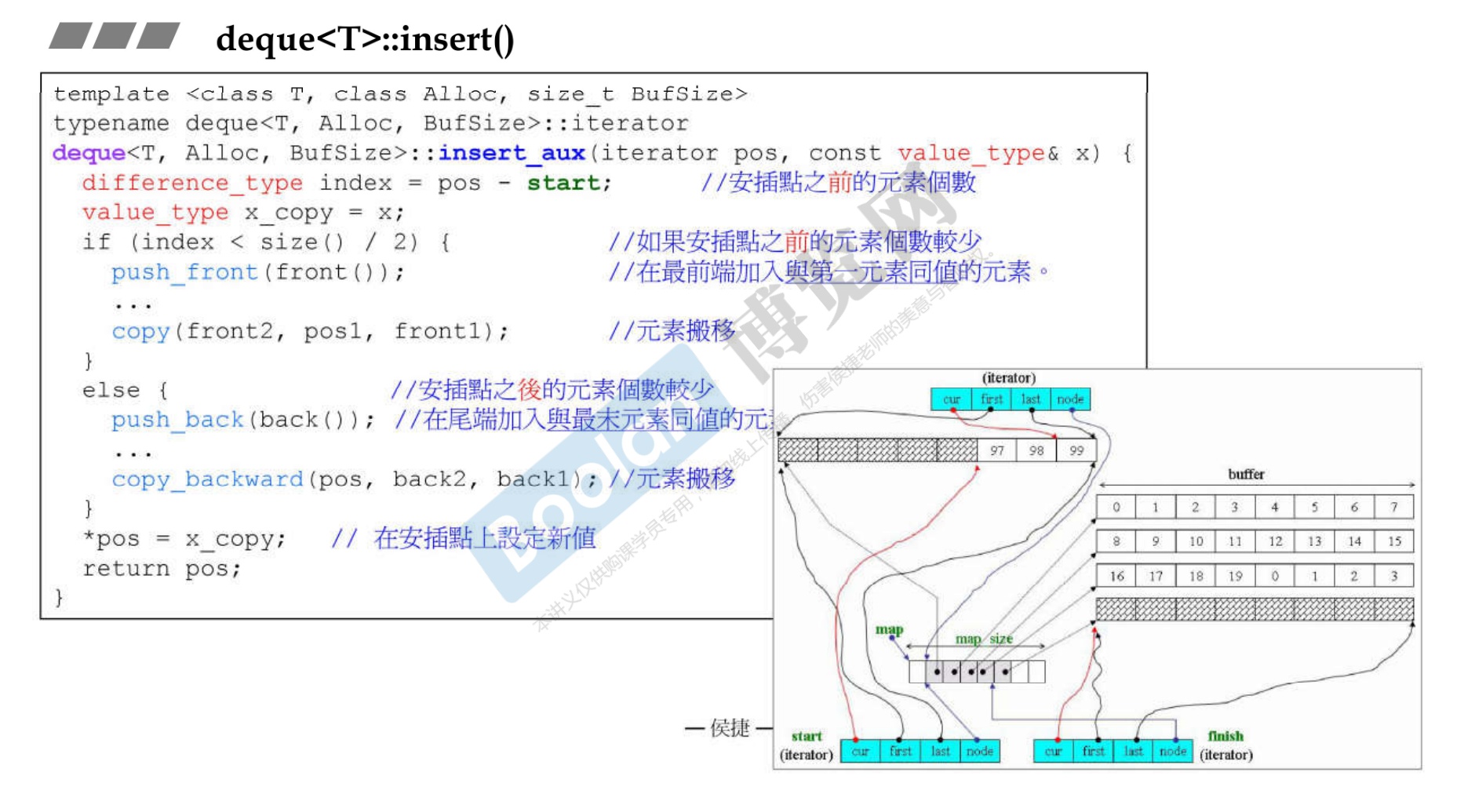
-
-
可以看到,是通过看头尾哪一边元素少,就往那一边插入。
-
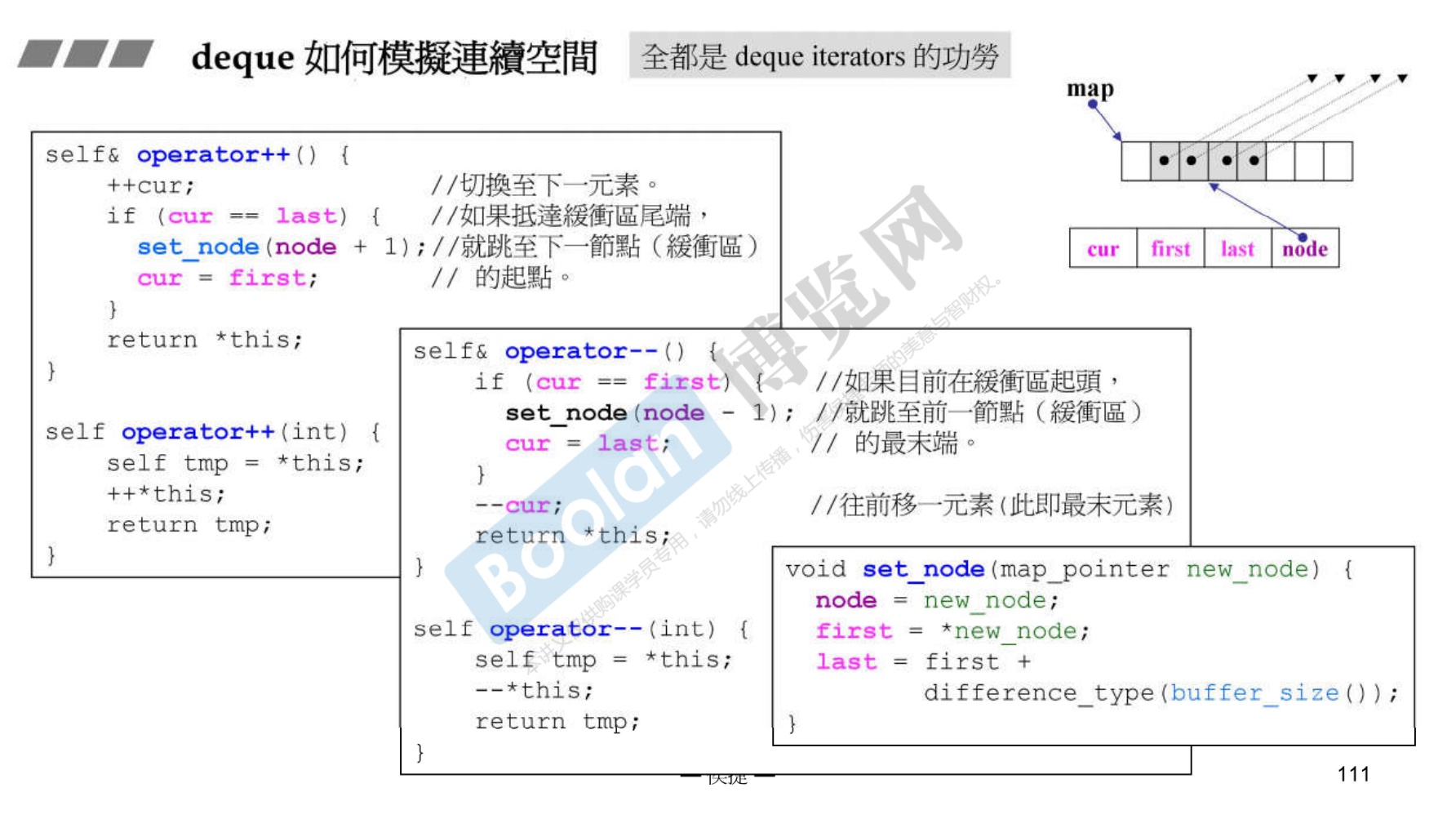
关于如何模拟连续空间
-
通过一系列操作符重载,同时复用操作符重载。注意区间是前开后闭。
-
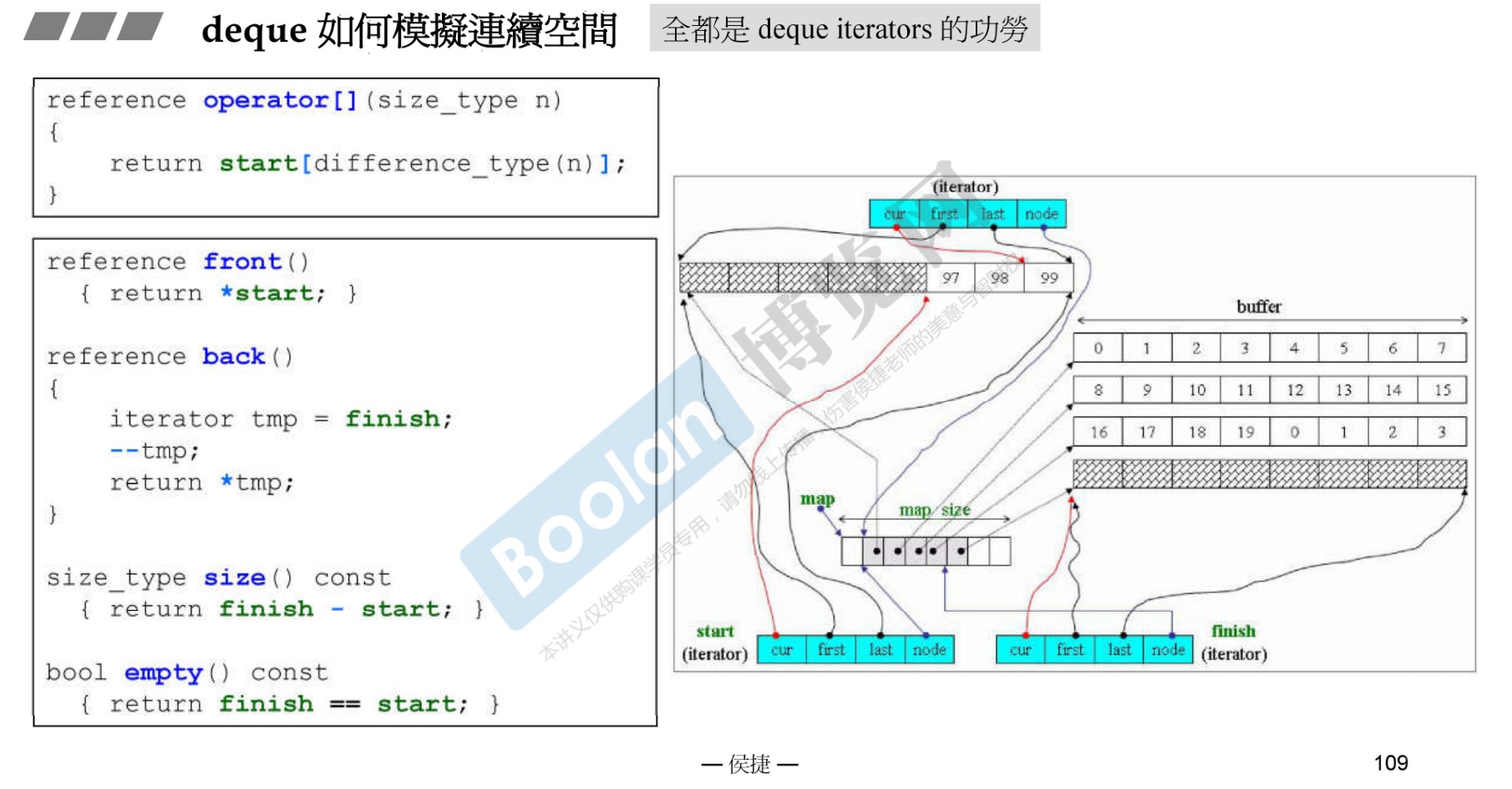
-
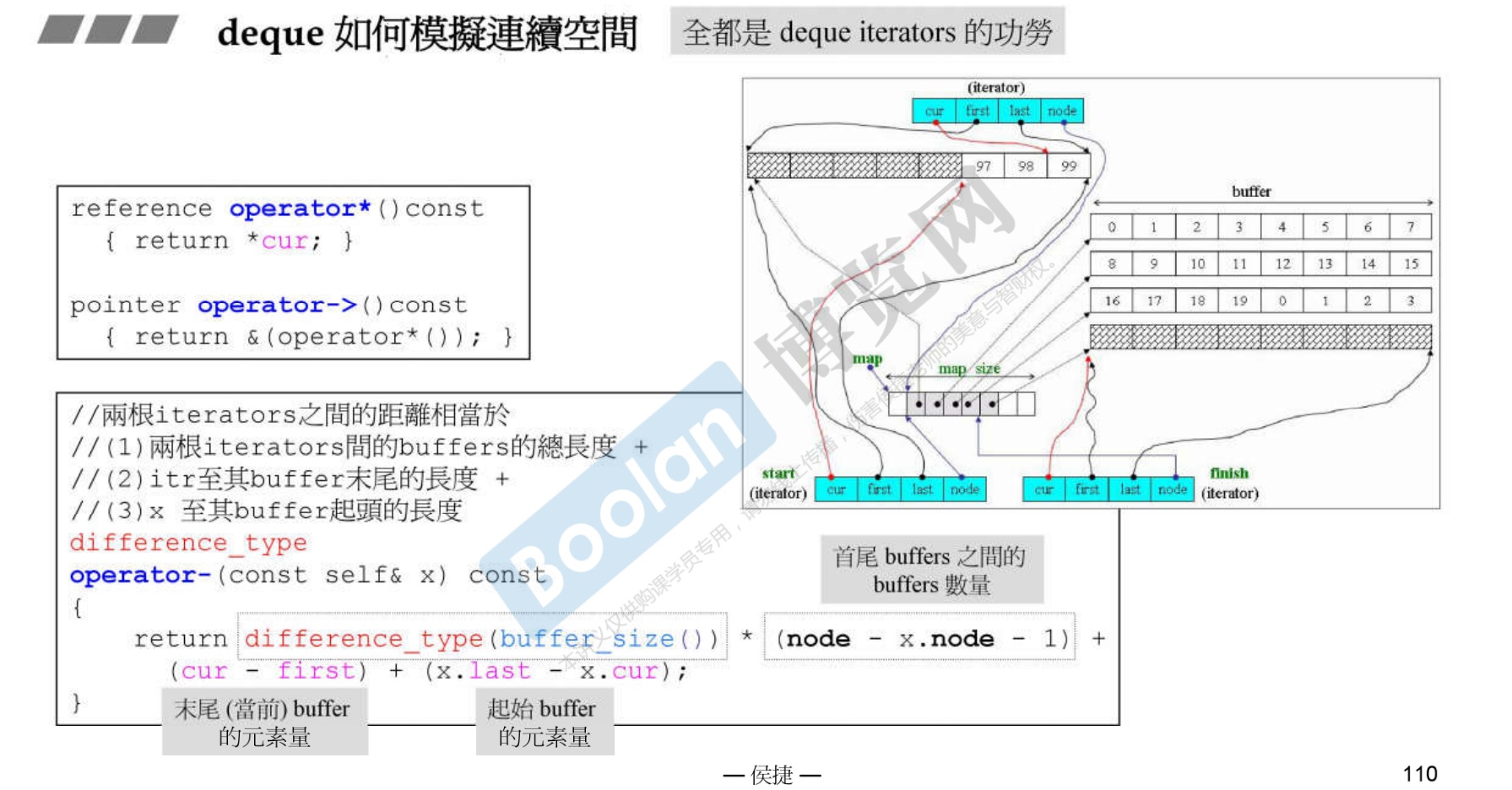
-
-

-
关于
operator--还有-=,复用的++ / +=操作符,只是传递的参数变为负数即可 。 -

13.2 GCC 4.9 版本
-
相比2.9版本的改变是,不能够自定义buffer_size了,又deque完全指定。
-
而且同vector一样,都设计了复杂的继承和复合。
-
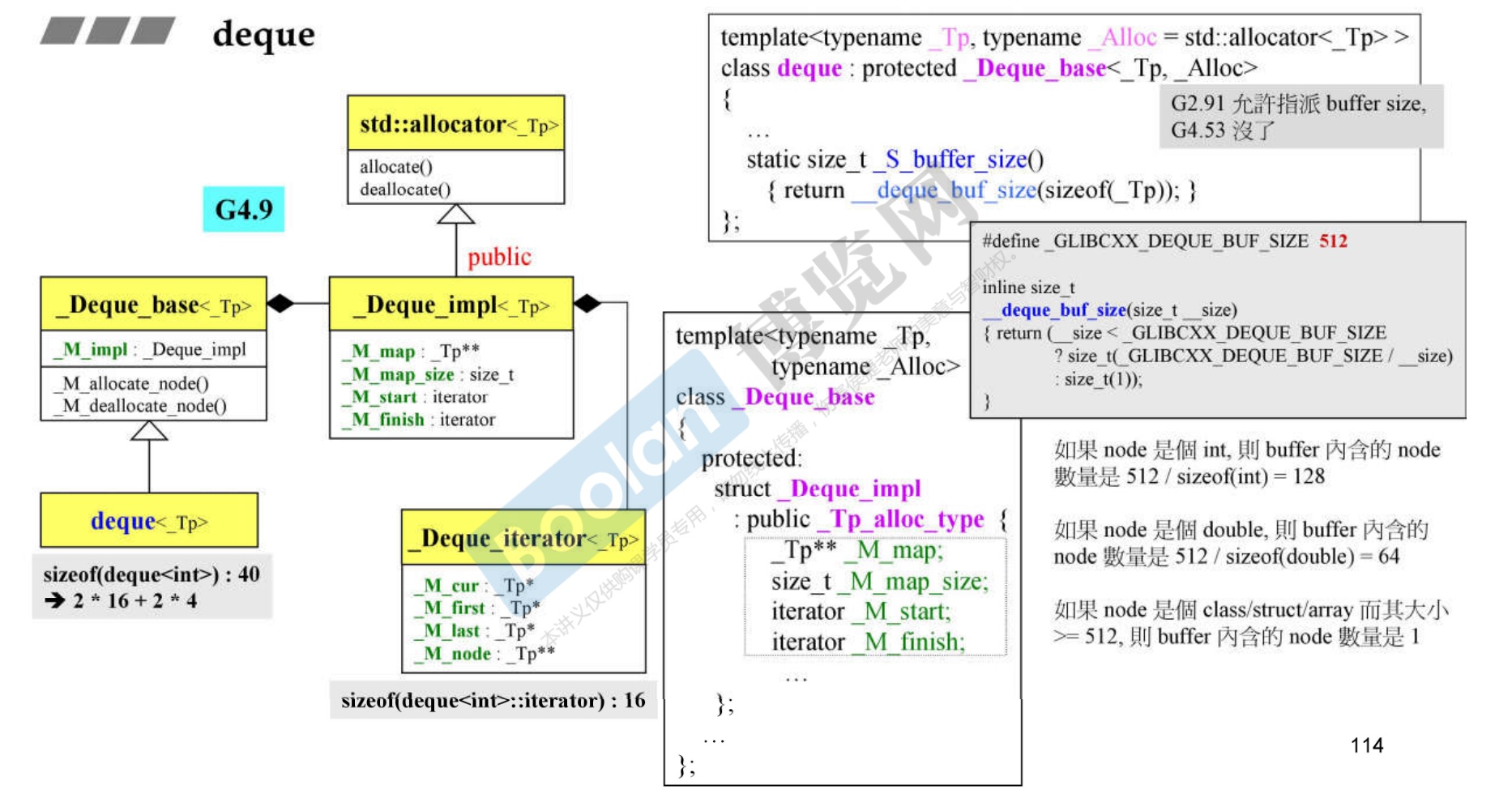
-
14. stack 和 queue
-
queue,默认采用deque为底层容器。
-

-
stack同理,仍然以deque为底层容器。
-

-
stack 和 queue 都不提供迭代器,同时,两者都可以把底层容器更改为
list双向链表。 -

-
queue 不能用vector为底层容器,但是stack可以,具体原因是vector不能提供queue 的某些接口。
-

-
stack 和 queue 都不能采用set、map作为底层容器。
-

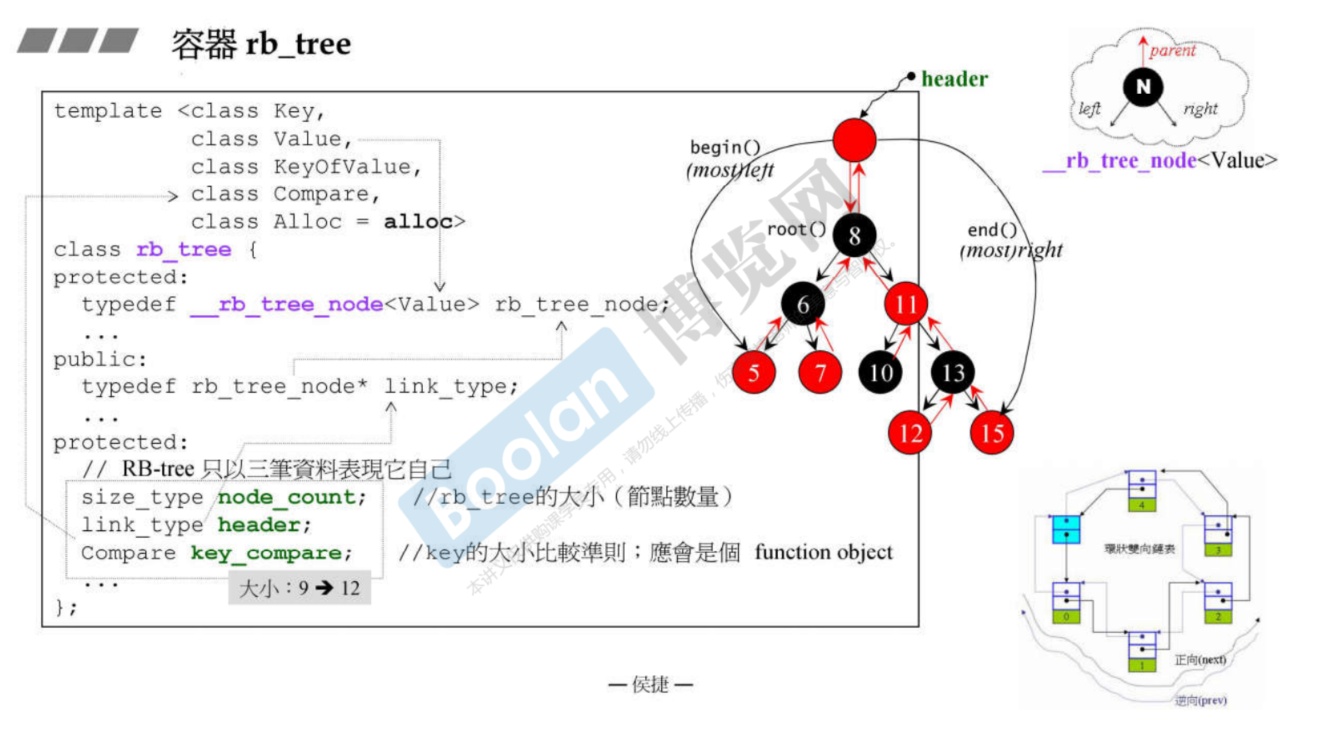
15. 深度探索 RB-Tree
-
RB-Tree:red-black-tree,红黑树,平衡二叉搜索树的一种。实现很复杂,这里仅介绍接口。
-

-
不要用
*解引用迭代器修改key值,因为这样你改了,但是实际的树结构并没有改变,会造成搜索错误,尽管这样编译器并不会报错。 -
rb-tree提供两种接口插入元素。
insert_unique:插入独特的元素,即如果树中已有这个元素,那么不会插入成功,也不会返回失败。insert_equal:插入重复元素。
15.1 GCC 2.9 版本
-
这里需要说明的是,关于枚举类型的大小。
-
“枚举类型的尺寸是以能够容纳最大枚举子的值的整数的尺寸”,同时标准中也说名了:“枚举类型中的枚举子的值必须要能够用一个int类型表述”,也就是说,枚举类型的尺寸不能够超过int类型的尺寸,但是是不是必须和int类型具有相同的尺寸呢?上面的标准已经说得很清楚了,只要能够容纳最大的枚举子的值的整数就可以了。
- 所以,一个bool类型的大小是1个字节,但是在内存对齐的影响下,会变成4个字节。
- 而默认的int,大小本身就是4个字节。
-
而关于仿函数的大小。
- 仿函数大小是0,但是任何编译器对于仿函数创造的大小都是1字节。
-
-
所以为什么上面说是9个字节大小——4(size_type)+4(指针)+1(函数),而由于内存对齐(4),会变成12个字节。
-
gcc默认对齐为4字节。
-
关于使用
-
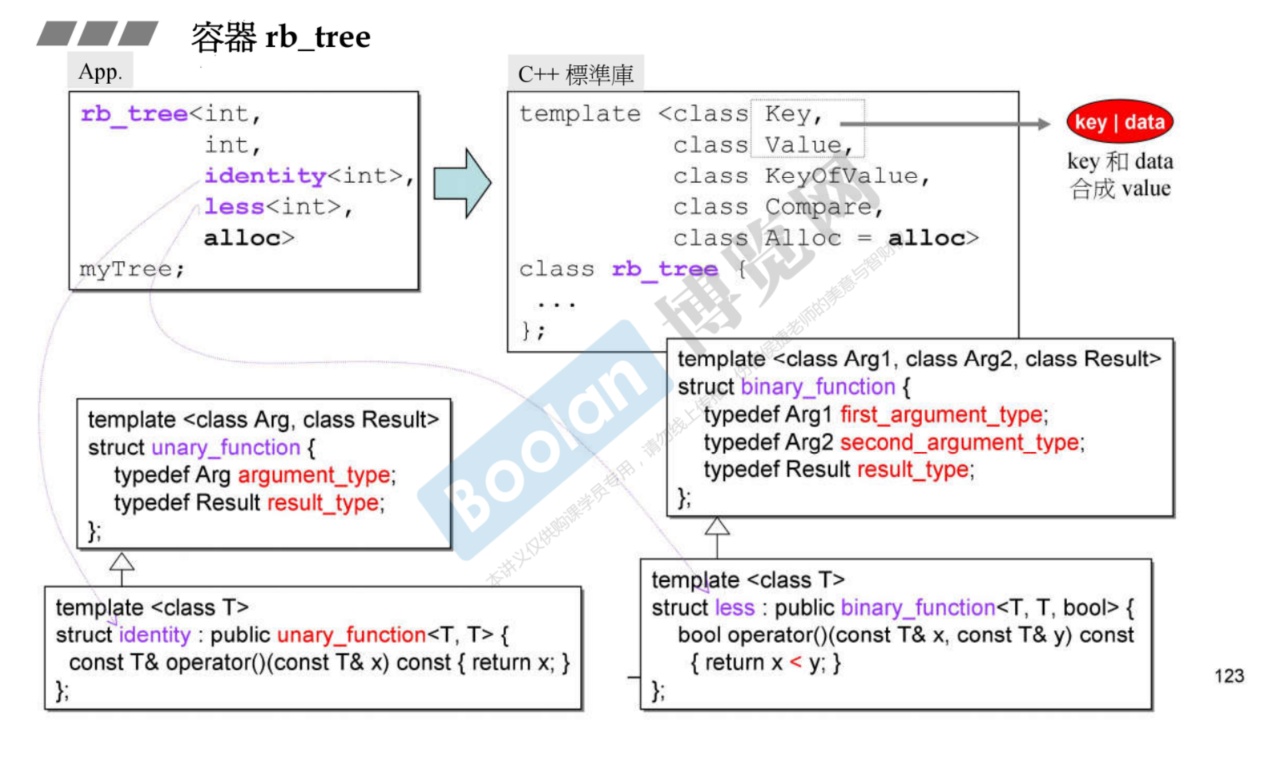
-
需要注意的是,Value是Key+data的结合体;而KeyOfValue则定义了如何从Value中提取Key的仿函数。
-

-
上图的
identity<int>表示key和value一样,没有data。
15.2 GCC 8.1 版本(4.9升级)
-
与4.9内存分布差不多。
-
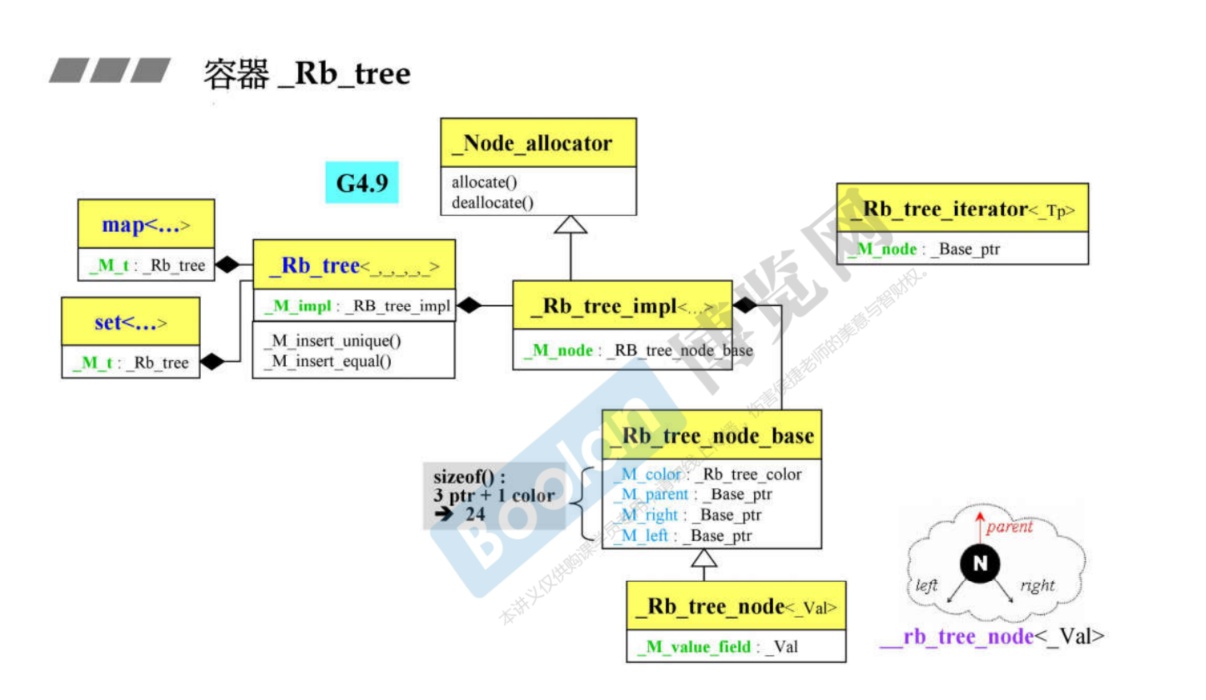
-
这里简单说一下,
_Rb_tree定义了一个句柄_M_impl,为了满足handle-body的设计方法。 -
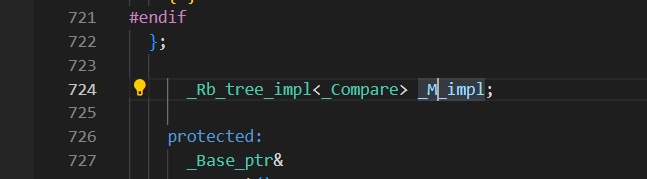
-
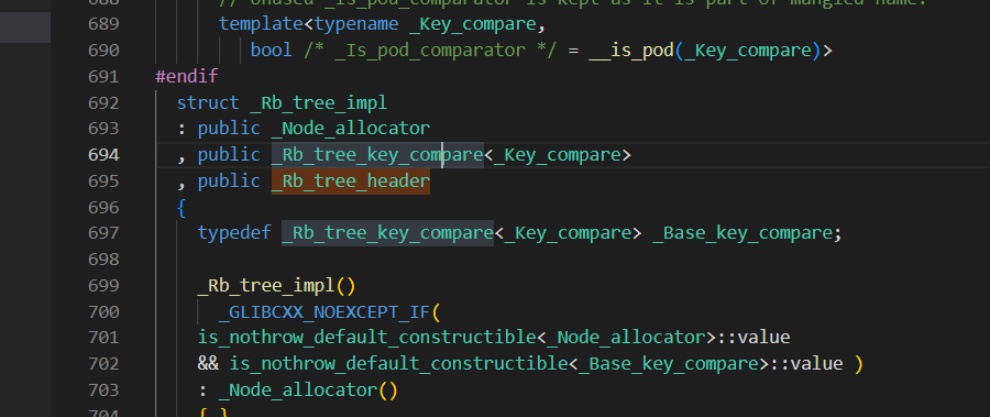
而其类的实现为
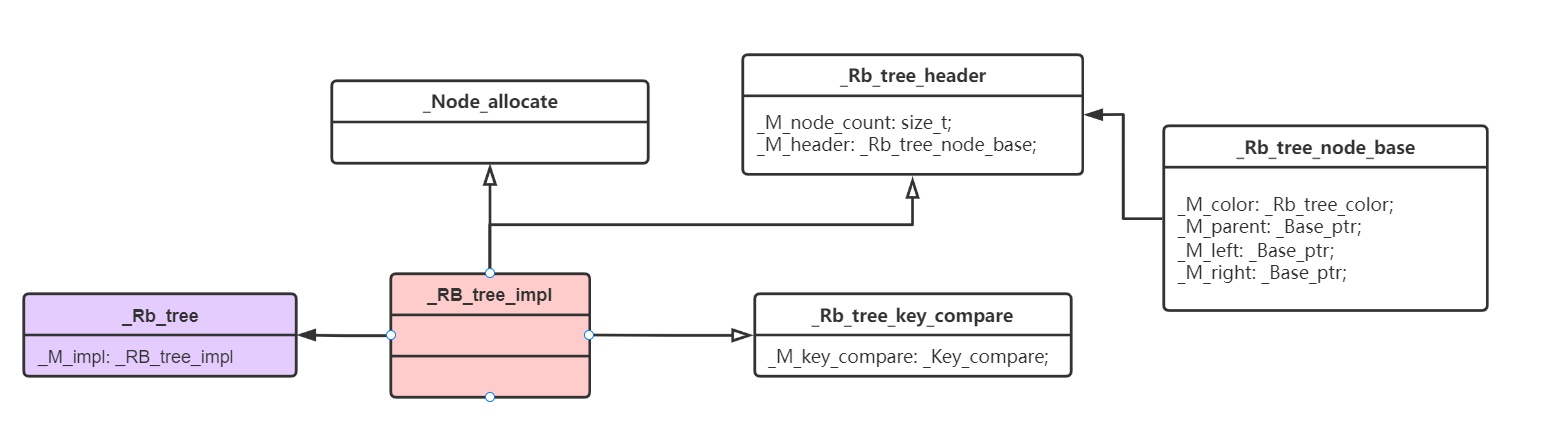
_Rb_tree_impl,如下所示。 -
-
可以看到其实多重继承,继承了分配器+比较仿函数+
_Rb_tree_header。里面没有数据定义,所以查看其继承的类的数据。 -
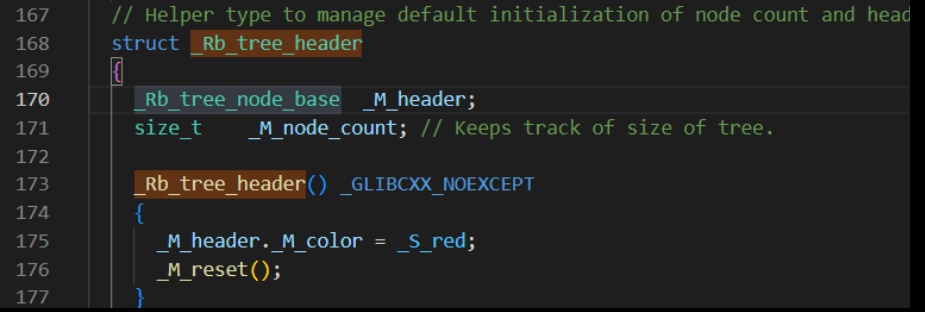
首先是
_Rb_tree_header -
-
其数据类型为
size_t和_Rb_tree_node_base,其类定义如下。 -
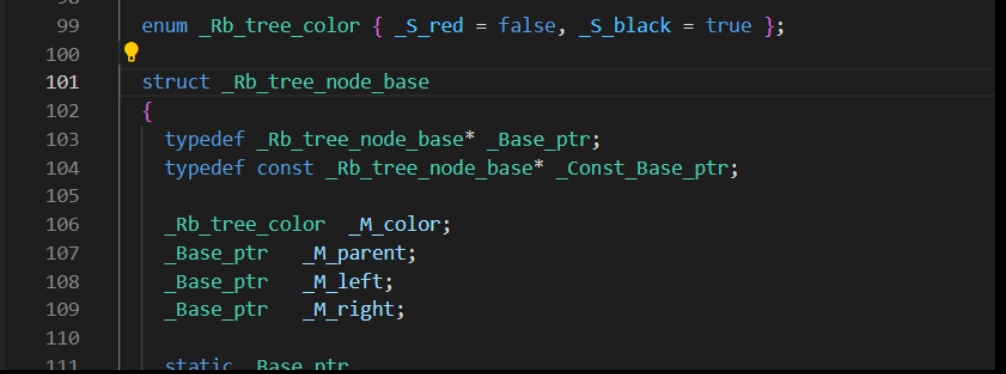
-
可以看到其有三个指针+一个枚举类型。
-
再看仿函数类,定义了仿函数,大小应为0,但编译器会变成1个字节。
-
-
最终绘制的UML图如下所示。
-
-
所以最终的数据类型是(存疑?)
- 一个size_t:8字节
- 三个base_ptr指针:24字节
- 一个仿函数:1字节(内存对齐8字节)
- 一个enum枚举:4字节(int),(内存对齐8字节)
-
所以在64位电脑上位48字节。
-
而32位则是24字节(4字节对齐)。
15.3 rb_tree 测试
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51#include <bits/stdc++.h> using namespace std; class base1 { public: virtual void func1() { cout << "func1 of base1 class!" << endl; } virtual void func2() { cout << "func2 of base1 class!" << endl; } }; class child1 : public base1 { public: void func1() { cout << "func1 of child1 class!" << endl; } void func2() { cout << "func2 of child1 class!" << endl; } }; int main() { _Rb_tree<int, int, _Identity<int>, less<int>> my_tree; cout << "rbtree size = " << sizeof(my_tree) << endl; cout << my_tree.empty() << endl; cout << my_tree.size() << endl; for (int i = 10; i >= 1; --i) { my_tree._M_insert_unique(i); my_tree._M_insert_unique(i); } cout << "now " << my_tree.empty() << endl; cout << "now " << my_tree.size() << endl; for (auto i = my_tree.begin(); i != my_tree.end(); ++i) { cout << *i << " "; //中序遍历 } cout << endl; my_tree._M_insert_equal(4); for (auto i = my_tree.begin(); i != my_tree.end(); ++i) { cout << *i << " "; //中序遍历 } return 0; } /*输出结果 rbtree size = 48 1 0 now 0 now 10 1 2 3 4 5 6 7 8 9 10 1 2 3 4 4 5 6 7 8 9 10 */
16. 深度探索 set / multiset
-
因为set的所有操作都转为Rb_tree,这么看来,set未必不是一个容器适配器。
-

-
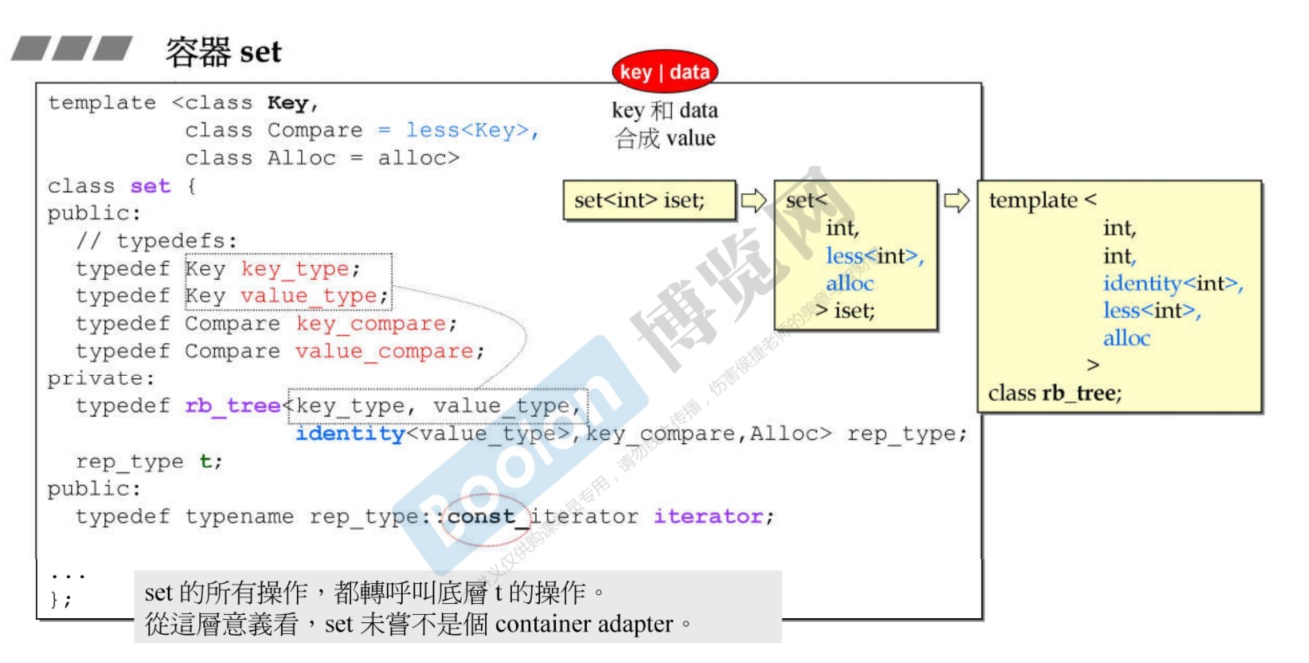
-
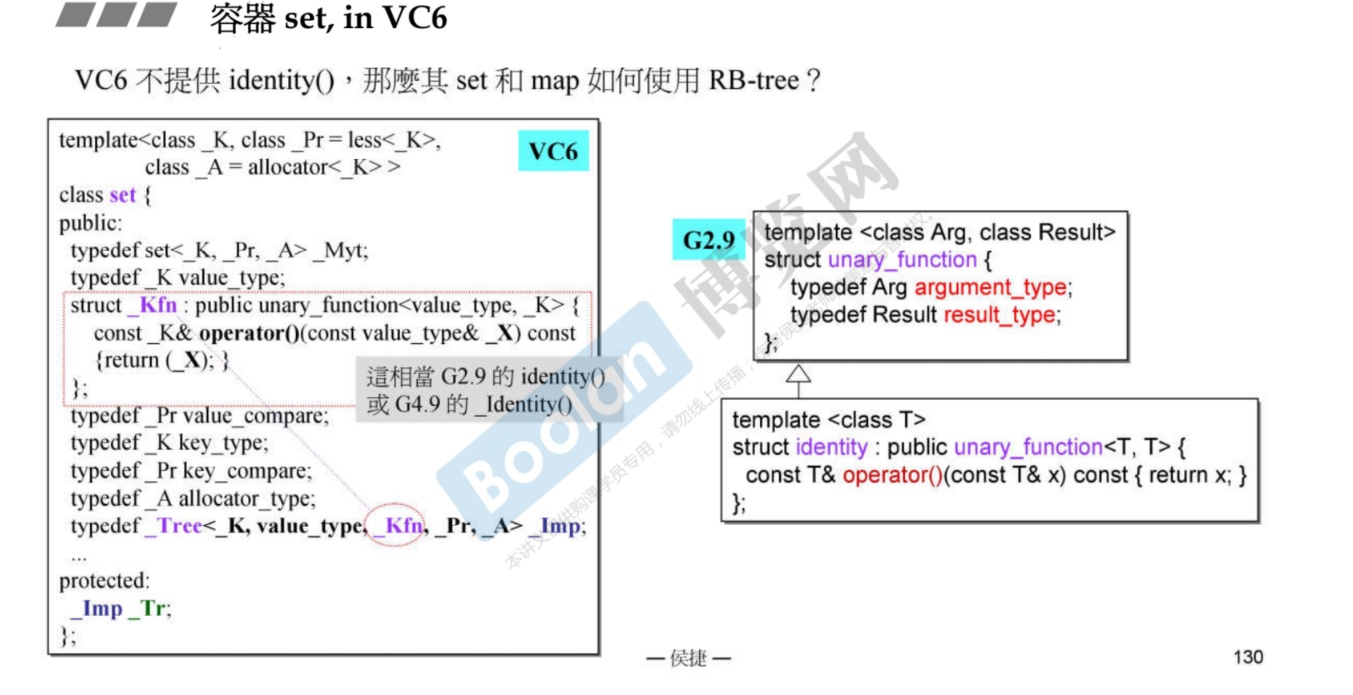
VC不提供
identity()函数,那么如何使用红黑树呢? -
17. 深度探索 map / multimap
-

-
GCC 2.9 使用
select1st仿函数 -
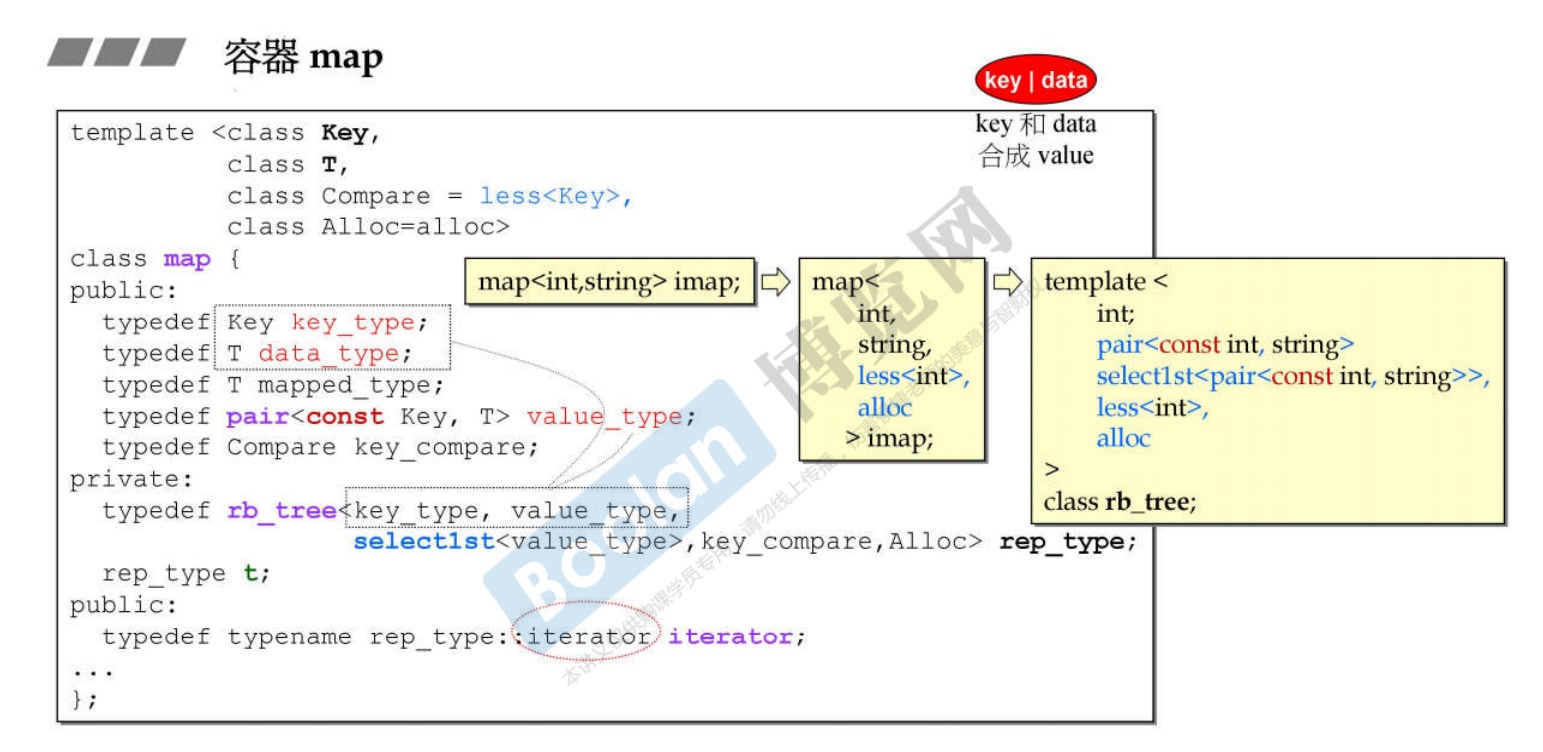
-
在VC6,因为没有
select1st,所以重写了一个仿函数。 -

-
map独特的
[]操作符。- 返回选择键值key的关联data,如何不存在这个key,则会常见这个key并赋默认值,然后返回。
- 使用的是二分查找。
-
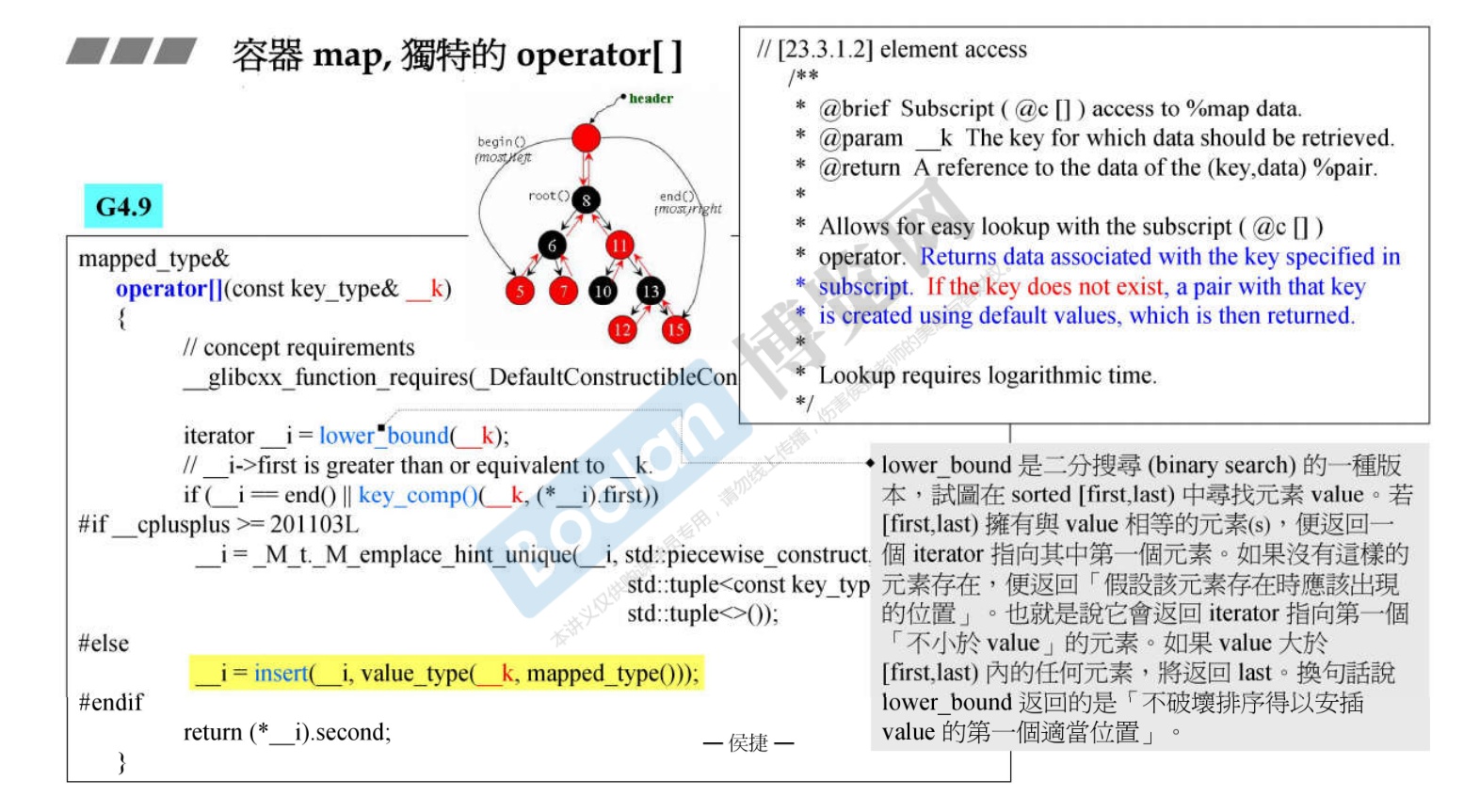
18. 容器 hashtable
-
散列表,没有很多的数学公式,更多的是一种经验。
-
如何解决哈希冲突,一般有四种方法
-
1.开放定址法
-

-
其中 m 为表的长度 对增量di有三种取法 1:线性探测再散列 di = 1 , 2 , 3 , … , m-1 2:平方探测再散列 di = 1 , -1 , 2, -2 , 3 , -3 , … , k , -k(取相应数的平方) 3:随机探测再散列 di 是一组伪随机数列
-
-
2.链地址法
-
即重复的元素放在链表里。
-

-
c++的
unodrdered_set就是这种基本方式,但有所改进以防链表过长。
-
-
3.再哈希法
- 产生冲突是计算另外一个哈希函数,一直计算直到没有冲突为止。
-
4.建立公共溢出区
- 建立一个公共溢出区域,就是把冲突的都放在另一个地方,不在表里面。
-
关于 Separate Chaining——即链地址法
-
buckets:篮子、桶子。
-
放到什么时候会认为链表过长会导致搜寻过慢呢。当元素总数大于篮子个数的时候,经验认为会造成搜寻过慢;需要把哈希表重新打算rehashing,篮子个数变为扩大2倍后的数的附近的质数。比如开始是53,扩容之后的质数就是97。
-
rehashing 是一件相当花时间的事情。
-
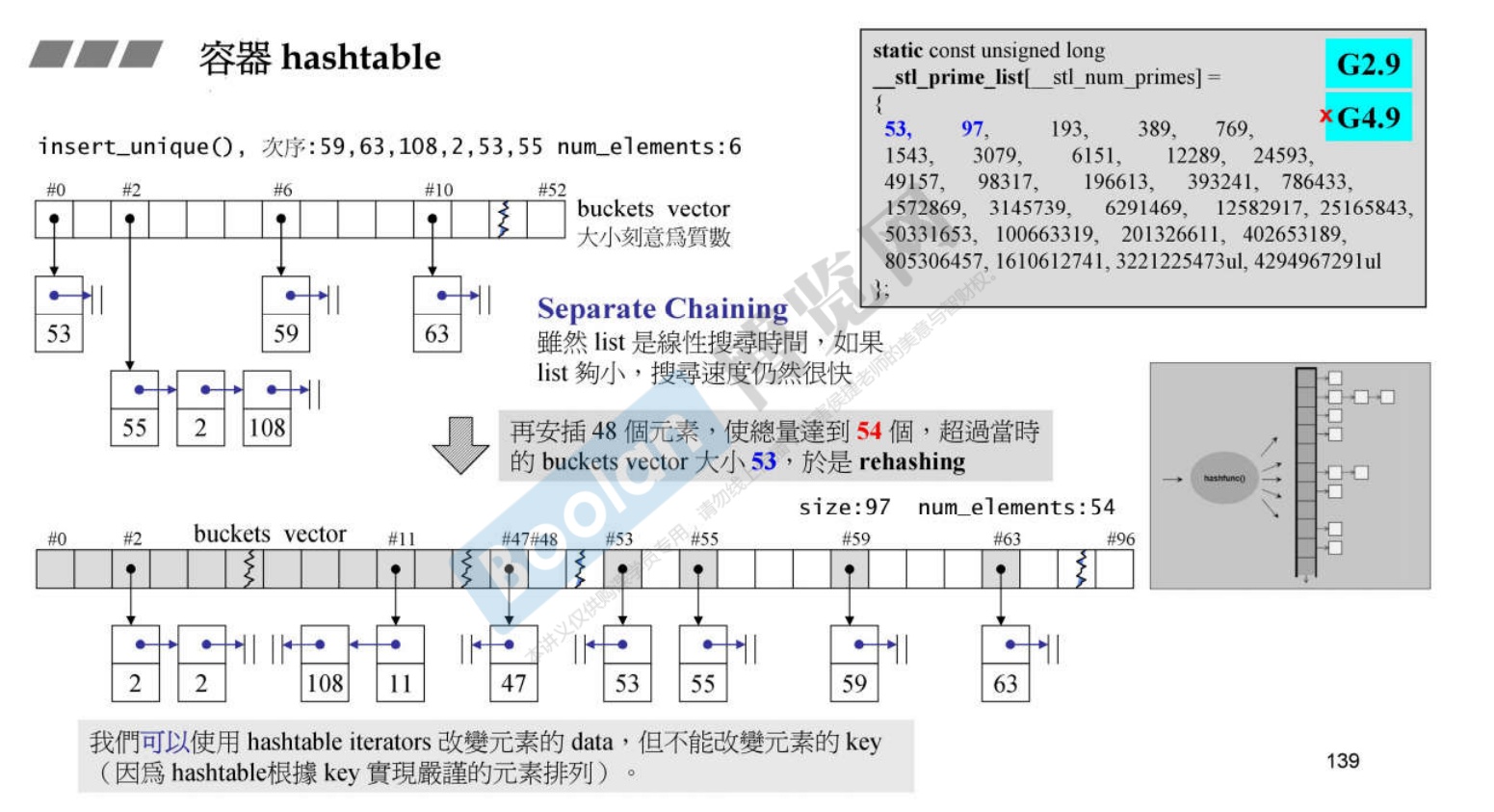
-
关于GNU如何设计hashtable
-
本文所引用的代码是 gcc-2.95版。
-
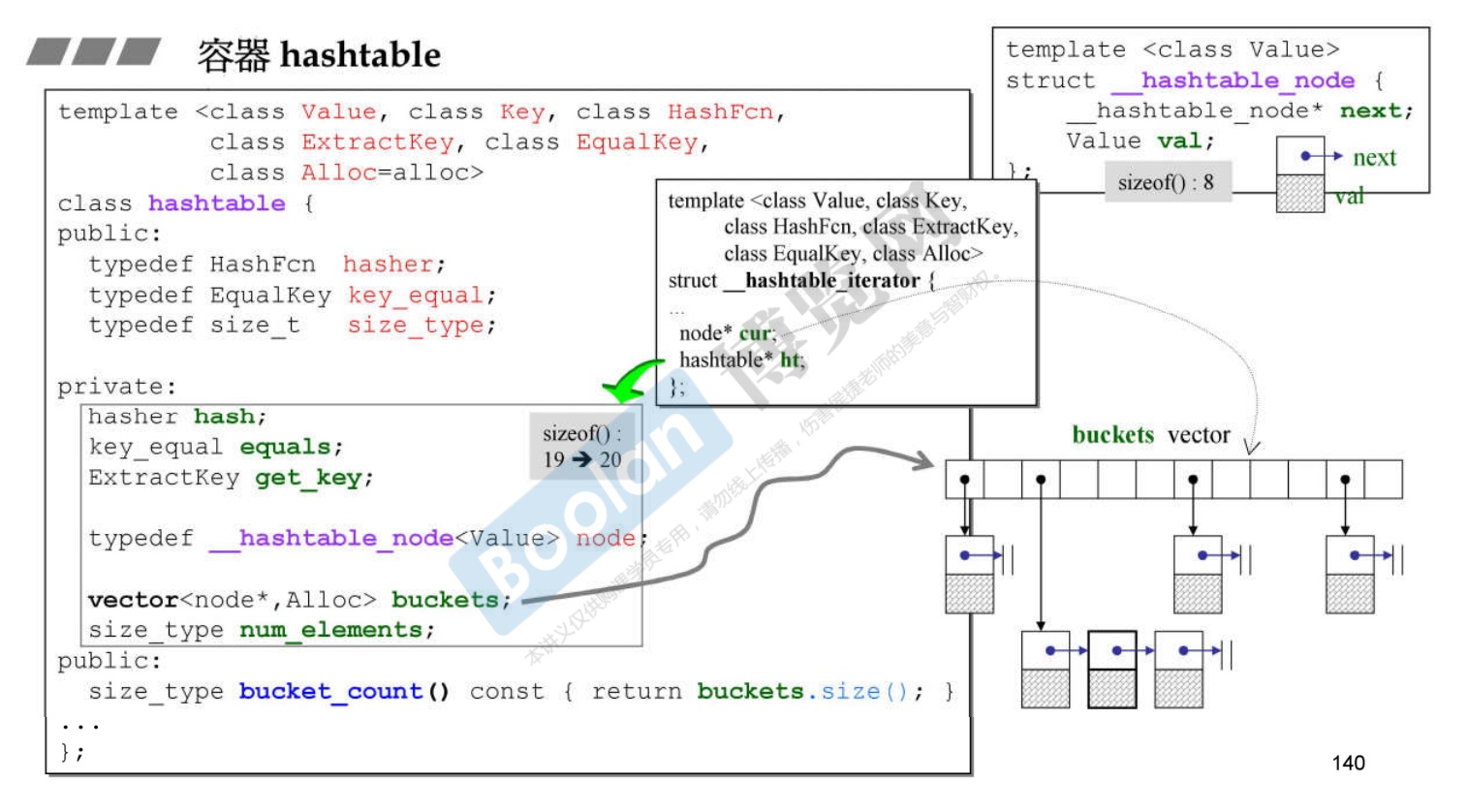
-
hashtable的参数很多
- Value:节点的data的类型;
- Key:节点的键值类型;
- HashFcn:哈希函数,计算哈希值;
- ExtractKey:从节点中取出键值的方法(函数或仿函数);
- EqualKey:判断键值相同与否的方法;
- Alloc:分配器
-
上面hashtable为什么大小是19个字节
- vector:3*4=12个字节(3个指针)
- 三个仿函数+3字节
- size_type:4字节
- 最后内存对齐
-
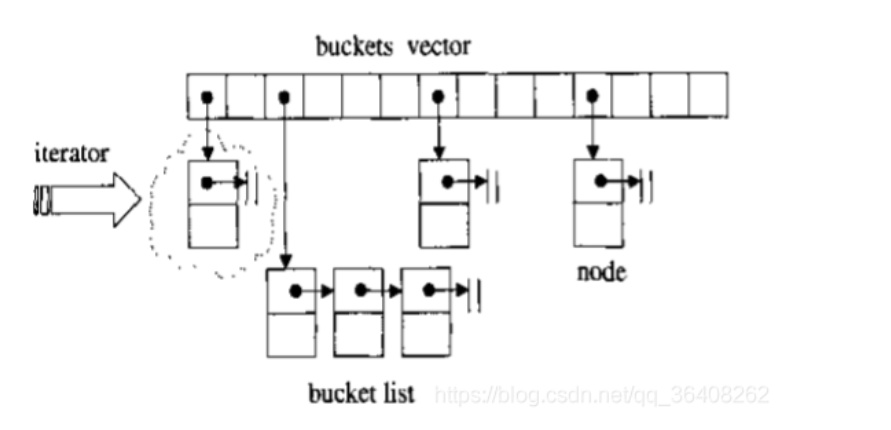
-
hashtable的主干部分使用vector来实现的,vector上的每一个元素被称为bucket,即桶,而每一个bucket都指向一个list。这里的list并不是 stl 中的list,而是自行维护的
__hashTable_node。(GNU是单向链表,VC里面是双向链表) -
hashtable的迭代器(如图中所示,cur和ht)有两个指针,指针cur指向当前节点,ht指向hashtable。当cur后移时,首先判断它的下一个节点是不是为null(即末尾),不是则cur直接++;否则就需要先通过哈希函数计算出cur在vector中的位置(设为i),然后返回vector[i + 1]的头节点。需要注意的是,hashtable的迭代器中没有--的操作,也没有定义逆向迭代器(reverse iterator)。
-
关于HashFcn
-
就是把对象转为一个hashcode,一个数。
-

-

-
如上图所示,就是计算出一个hash code。
-
计算出的值都是为了取余计算,就是下面的modules函数(hashtable定义的取模运算函数)
-

-
例子:计算如下的hash code
-

-
关于测试
-
GCC 2.9 版本(hashtable模板只需要5个模板参数)是可以编译通过的。但是对于GCC 4.9 及以上版本的hashtable变化了,需要10个模板参数。所以GCC4.9之后自行调用就比较有困难。
-

-

-
关于 unordered 容器
-
注意,篮子个数一定大于元素个数。
-

-
19. 迭代器的分类 category
-
从这一节开始标准模板库的算法的学习。
-
STL六大部件,除了算法,其他都是类模板;而算法则是函数模板。
-

-
关于分类——分为5种迭代器
-

-
注意5种迭代器的继承关系,这关系到后面的函数调用问题。
-

-
测试之前的容器的迭代器的种类,注意以下版本是GCC 8.1。VC版本的unordered_set的迭代器为双向迭代器,与GCC不同。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73#include <bits/stdc++.h> using namespace std; //五个函数重载 void _disp_child(random_access_iterator_tag) { cout << "random_access_iterator_tag" << endl; } void _disp_child(bidirectional_iterator_tag) { cout << "bidirectional_iterator_tag" << endl; } void _disp_child(input_iterator_tag) { cout << "input_iterator_tag" << endl; } void _disp_child(output_iterator_tag) { cout << "output_iterator_tag" << endl; } void _disp_child(forward_iterator_tag) { cout << "forward_iterator_tag" << endl; } template <typename I> void disp(I itr) { typename iterator_traits<I>::iterator_category cate; _disp_child(cate); } int main() { //小括号是为了生成临时对象 disp(array<int, 10>::iterator()); // random_access_iterator_tag disp(vector<int>::iterator()); // random_access_iterator_tag disp(deque<int>::iterator()); // random_access_iterator_tag disp(list<int>::iterator()); // bidirectional_iterator_tag disp(forward_list<int>::iterator()); // forward_iterator_tag disp(set<int>::iterator()); // bidirectional_iterator_tag disp(map<int, int>::iterator()); // bidirectional_iterator_tag disp(multiset<int>::iterator()); // bidirectional_iterator_tag disp(multimap<int, int>::iterator()); // bidirectional_iterator_tag disp(unordered_set<int>::iterator()); // forward_iterator_tag disp(unordered_map<int, int>::iterator()); // forward_iterator_tag disp(unordered_multiset<int>::iterator()); // forward_iterator_tag disp(unordered_multimap<int, int>::iterator()); // forward_iterator_tag disp(istream_iterator<int>()); // input_iterator_tag disp(ostream_iterator<int>(cout, "")); // output_iterator_tag return 0; } /*输出结果 random_access_iterator_tag random_access_iterator_tag random_access_iterator_tag bidirectional_iterator_tag forward_iterator_tag bidirectional_iterator_tag bidirectional_iterator_tag bidirectional_iterator_tag bidirectional_iterator_tag forward_iterator_tag forward_iterator_tag forward_iterator_tag forward_iterator_tag input_iterator_tag output_iterator_tag */ -

-
使用typeid显示迭代器的分类的名字。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104#include <bits/stdc++.h> using namespace std; //五个函数重载 void _disp_child(random_access_iterator_tag) { cout << "random_access_iterator_tag" << endl; } void _disp_child(bidirectional_iterator_tag) { cout << "bidirectional_iterator_tag" << endl; } void _disp_child(input_iterator_tag) { cout << "input_iterator_tag" << endl; } void _disp_child(output_iterator_tag) { cout << "output_iterator_tag" << endl; } void _disp_child(forward_iterator_tag) { cout << "forward_iterator_tag" << endl; } template <typename I> void disp(I itr) { typename iterator_traits<I>::iterator_category cate; _disp_child(cate); cout << "typeid = " << typeid(itr).name() << endl << endl; } int main() { //小括号是为了生成临时对象 disp(array<int, 10>::iterator()); // random_access_iterator_tag disp(vector<int>::iterator()); // random_access_iterator_tag disp(deque<int>::iterator()); // random_access_iterator_tag disp(list<int>::iterator()); // bidirectional_iterator_tag disp(forward_list<int>::iterator()); // forward_iterator_tag disp(set<int>::iterator()); // bidirectional_iterator_tag disp(map<int, int>::iterator()); // bidirectional_iterator_tag disp(multiset<int>::iterator()); // bidirectional_iterator_tag disp(multimap<int, int>::iterator()); // bidirectional_iterator_tag disp(unordered_set<int>::iterator()); // forward_iterator_tag disp(unordered_map<int, int>::iterator()); // forward_iterator_tag disp(unordered_multiset<int>::iterator()); // forward_iterator_tag disp(unordered_multimap<int, int>::iterator()); // forward_iterator_tag disp(istream_iterator<int>()); // input_iterator_tag disp(ostream_iterator<int>(cout, "")); // output_iterator_tag return 0; } /*输出结果 random_access_iterator_tag typeid = Pi random_access_iterator_tag typeid = N9__gnu_cxx17__normal_iteratorIPiSt6vectorIiSaIiEEEE random_access_iterator_tag typeid = St15_Deque_iteratorIiRiPiE bidirectional_iterator_tag typeid = St14_List_iteratorIiE forward_iterator_tag typeid = St18_Fwd_list_iteratorIiE bidirectional_iterator_tag typeid = St23_Rb_tree_const_iteratorIiE bidirectional_iterator_tag typeid = St17_Rb_tree_iteratorISt4pairIKiiEE bidirectional_iterator_tag typeid = St23_Rb_tree_const_iteratorIiE bidirectional_iterator_tag typeid = St17_Rb_tree_iteratorISt4pairIKiiEE forward_iterator_tag typeid = NSt8__detail14_Node_iteratorIiLb1ELb0EEE forward_iterator_tag typeid = NSt8__detail14_Node_iteratorISt4pairIKiiELb0ELb0EEE forward_iterator_tag typeid = NSt8__detail14_Node_iteratorIiLb1ELb0EEE forward_iterator_tag typeid = NSt8__detail14_Node_iteratorISt4pairIKiiELb0ELb0EEE input_iterator_tag typeid = St16istream_iteratorIicSt11char_traitsIcExE output_iterator_tag typeid = St16ostream_iteratorIicSt11char_traitsIcEE */ -
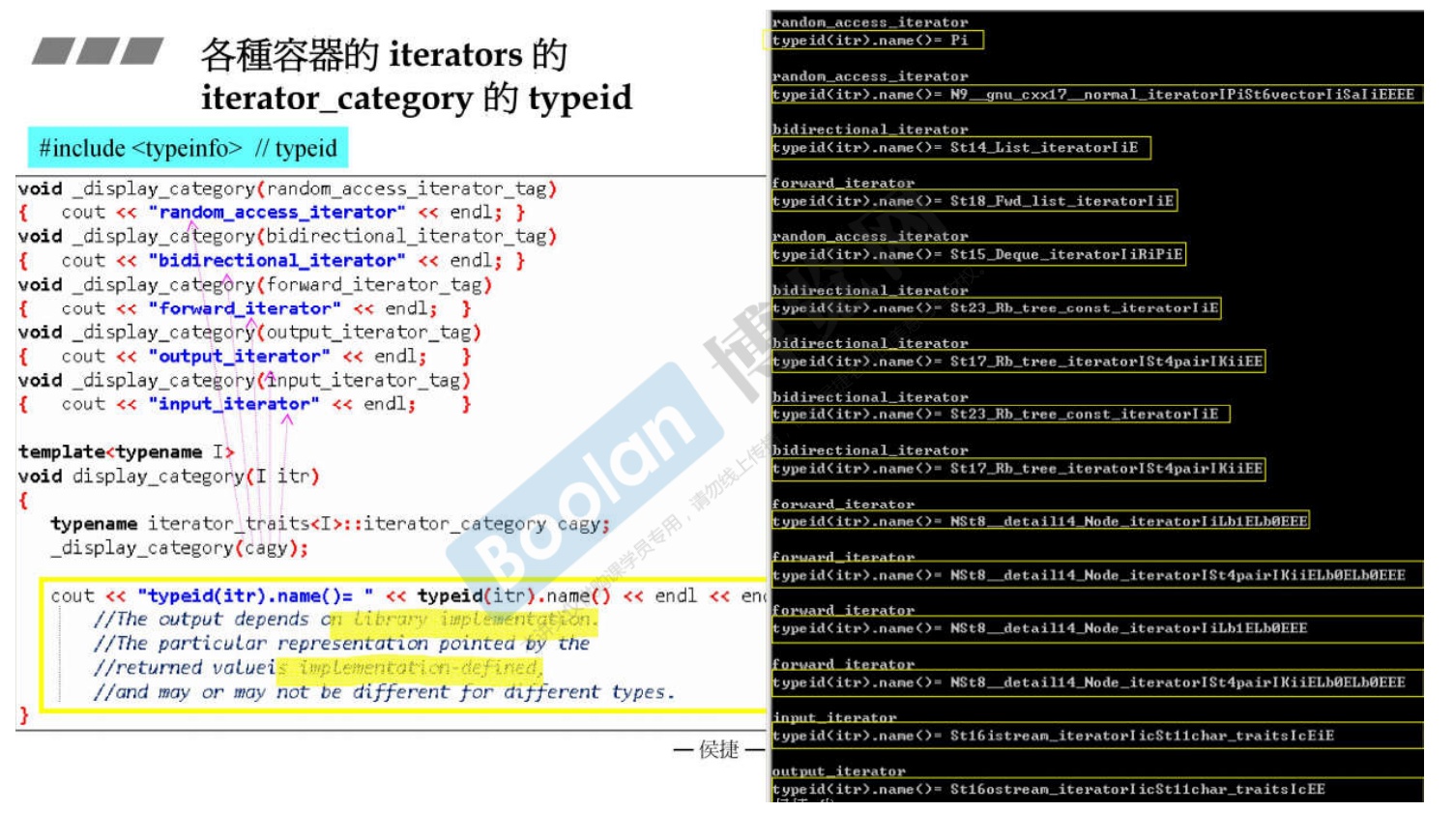
-
关于 istream_iterator 的 iterator_category
-
如下图所示的2.9 、3.3、 4.9 版本的关于iterator_category的定义。
-
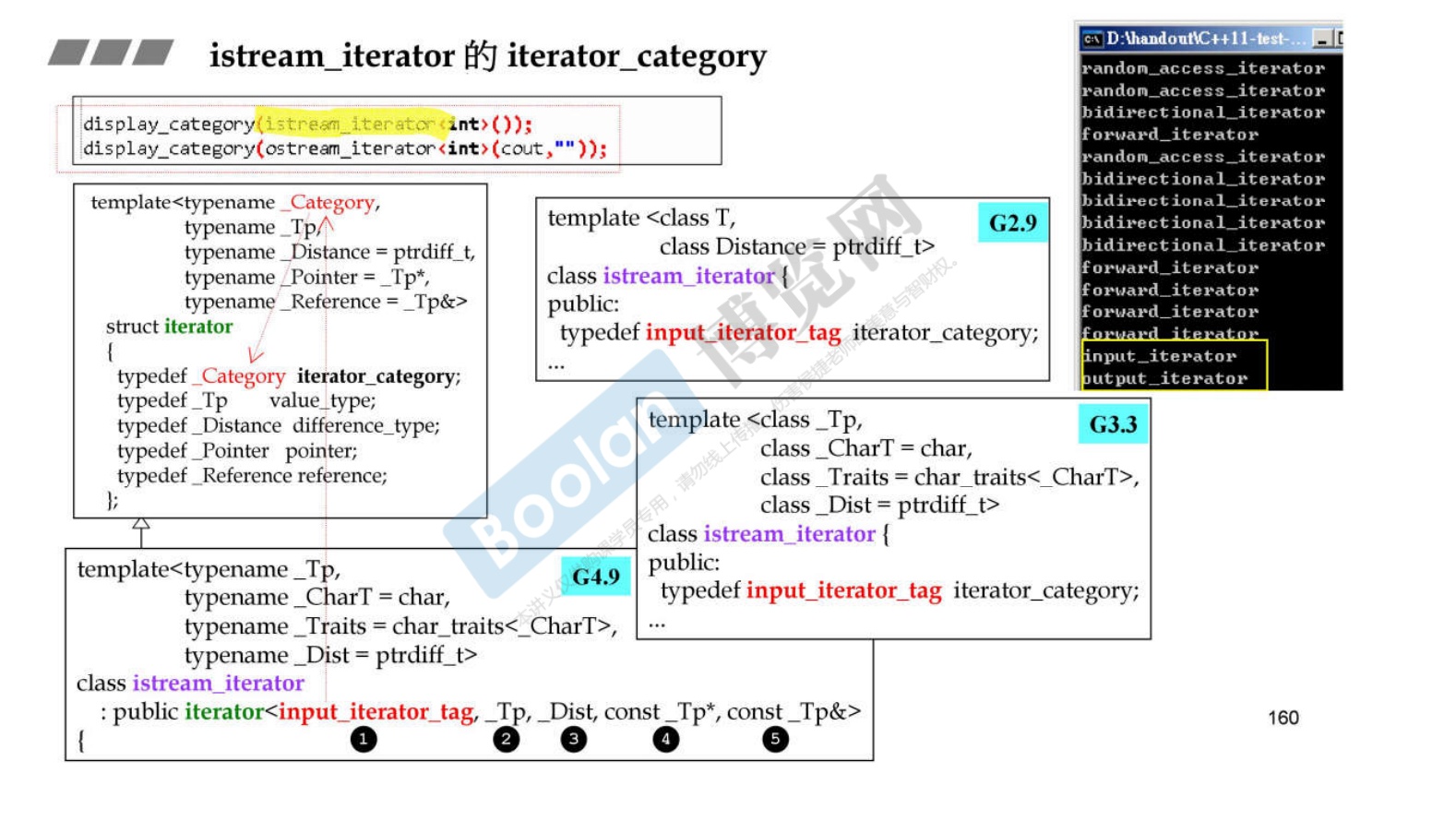
-
关于 ostream_iterator 的 iterator_category
-

20. 迭代器分类(iterator_category) 对算法的影响
-
以 distance 函数为例
-
distance 函数返回两个迭代器的距离。很直观的想法是直接相减,但是这个只对连续的迭代器有效,对于跳转的迭代器是无效的。所以对于非random迭代器,不能直接用迭代器的
-运算符。 -
注意distance的返回值是
difference_type。 -
下图所示就是distance的函数重载。可以明显看到两者的效率差异。对于非连续迭代器,时间成本会高很多。
-
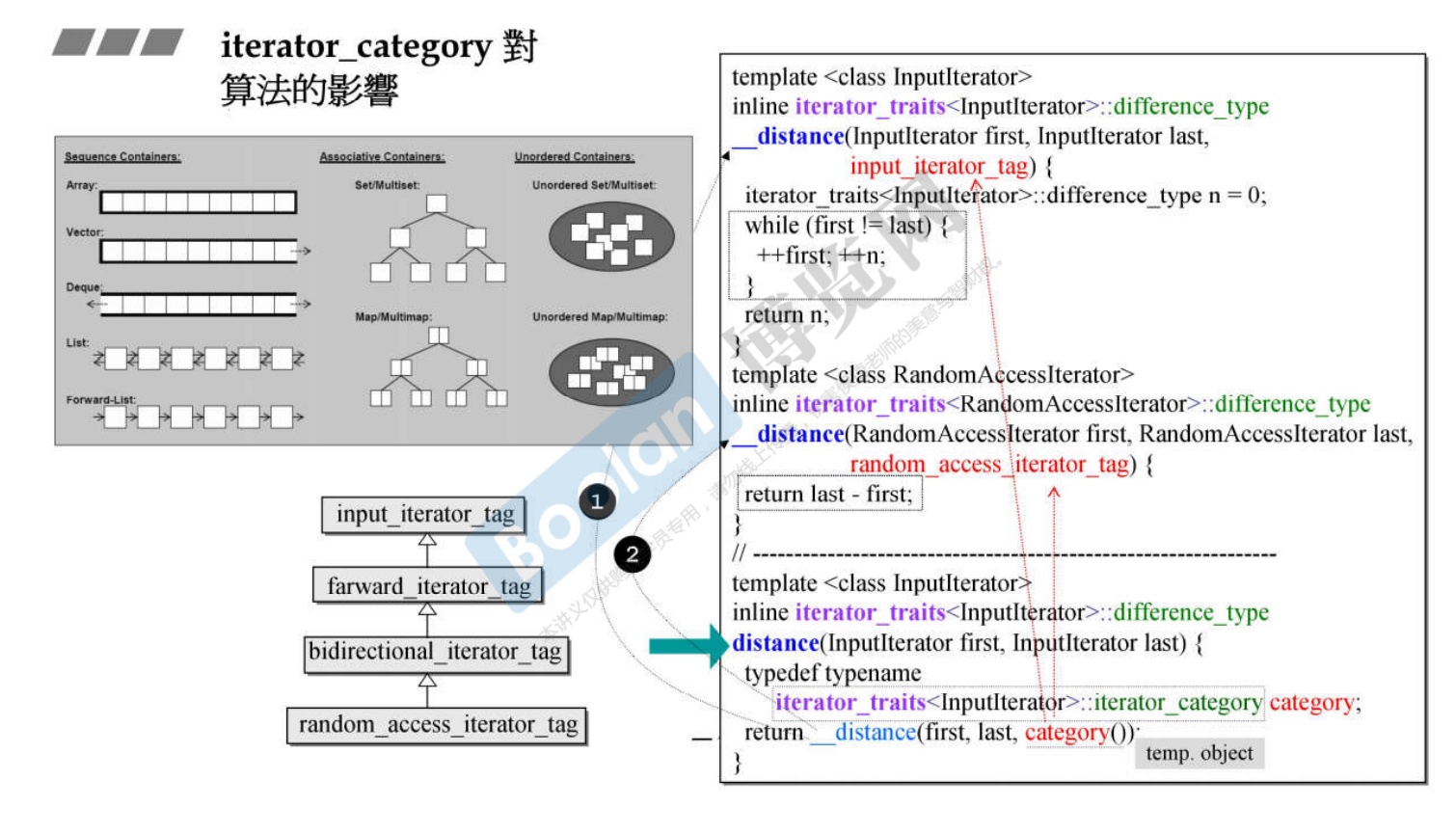
-
以 advance 函数为例
-
advance的意思就是前进,代表着迭代器向前。
-
为什么下图只分成三类但是能用四类呢——因为继承。
-
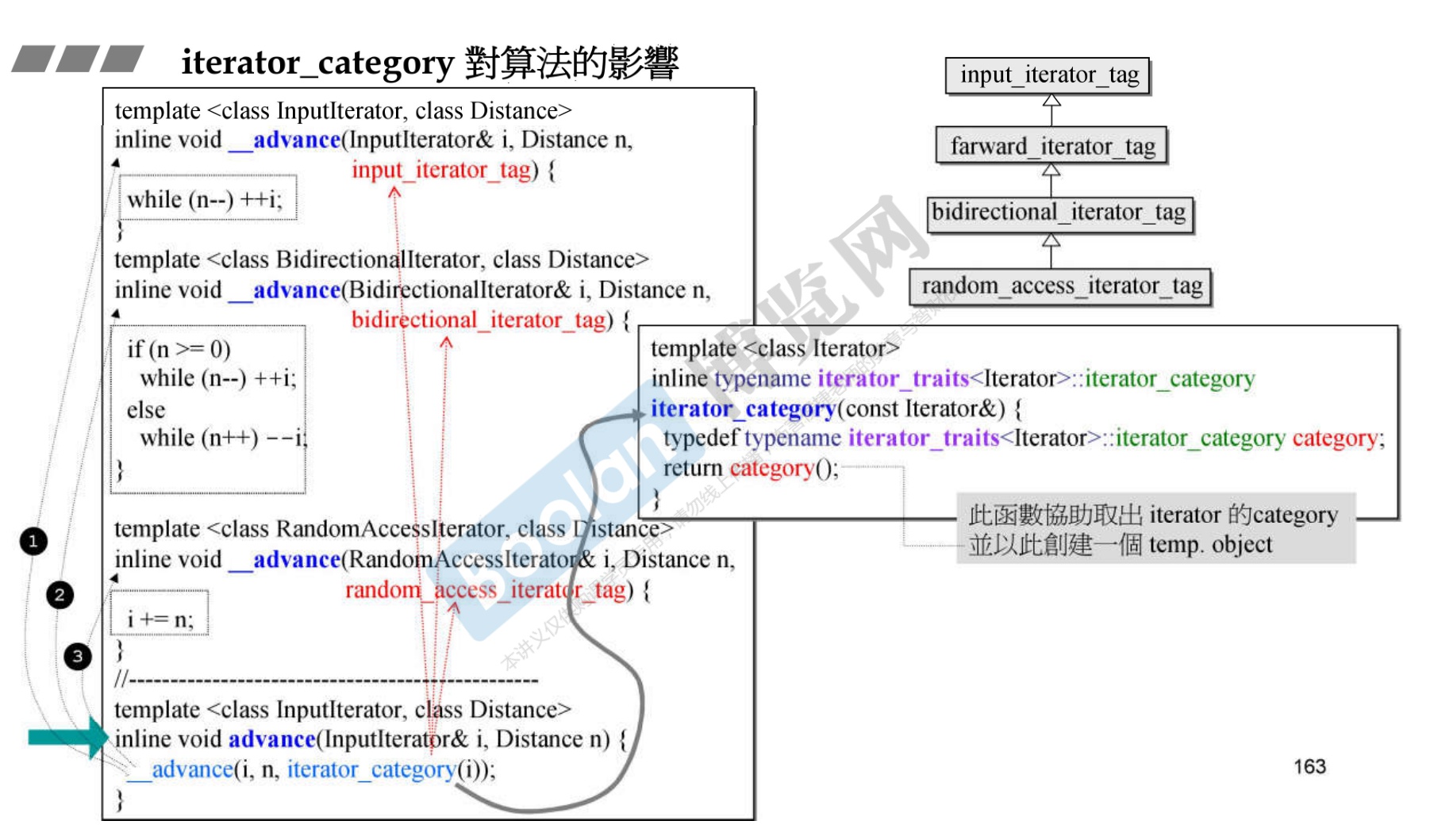
-
关于 copy 函数
-
从源码上看,copy的实现的基本思想如下:
-
1 2 3 4 5 6 7 8 9template<class InputIterator, class OutputIterator> OutputIterator copy (InputIterator first, InputIterator last, OutputIterator result) { while (first!=last) { *result = *first; ++result; ++first; } return result; } -
然后上面仅仅是基本思路,对于不同类型的迭代器,标准库定义了不同的重载函数来提高拷贝效率。
-

-
关于 destroy 函数
-
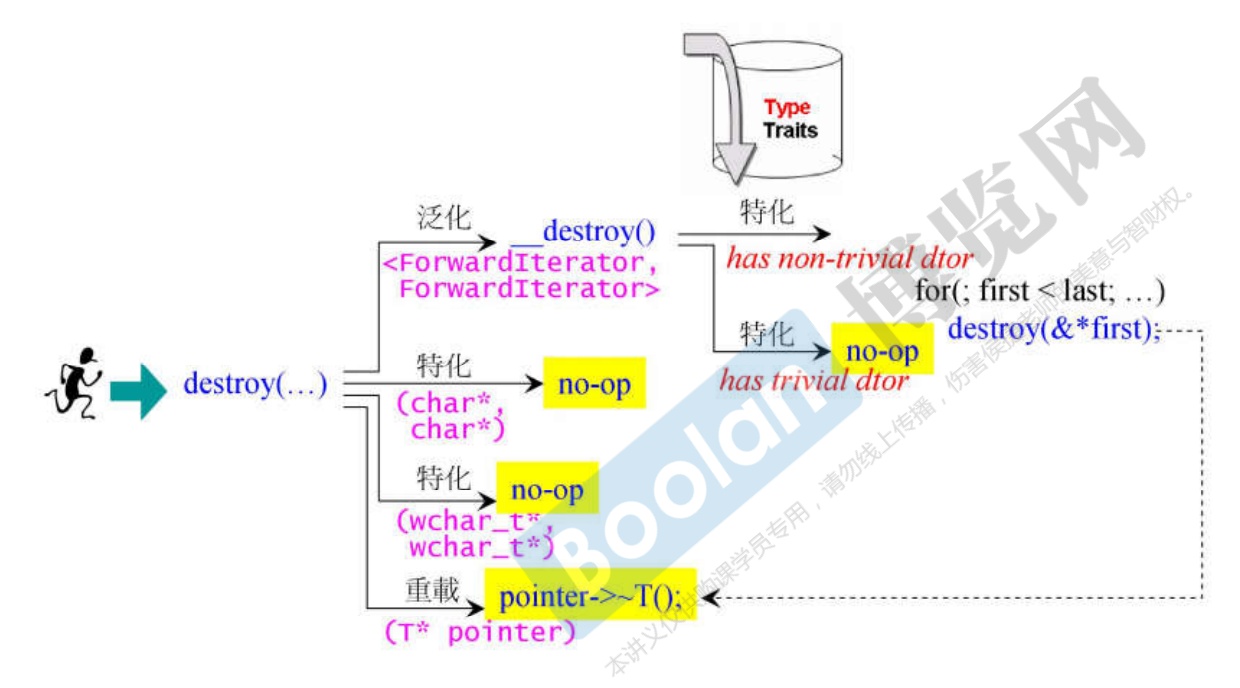
-
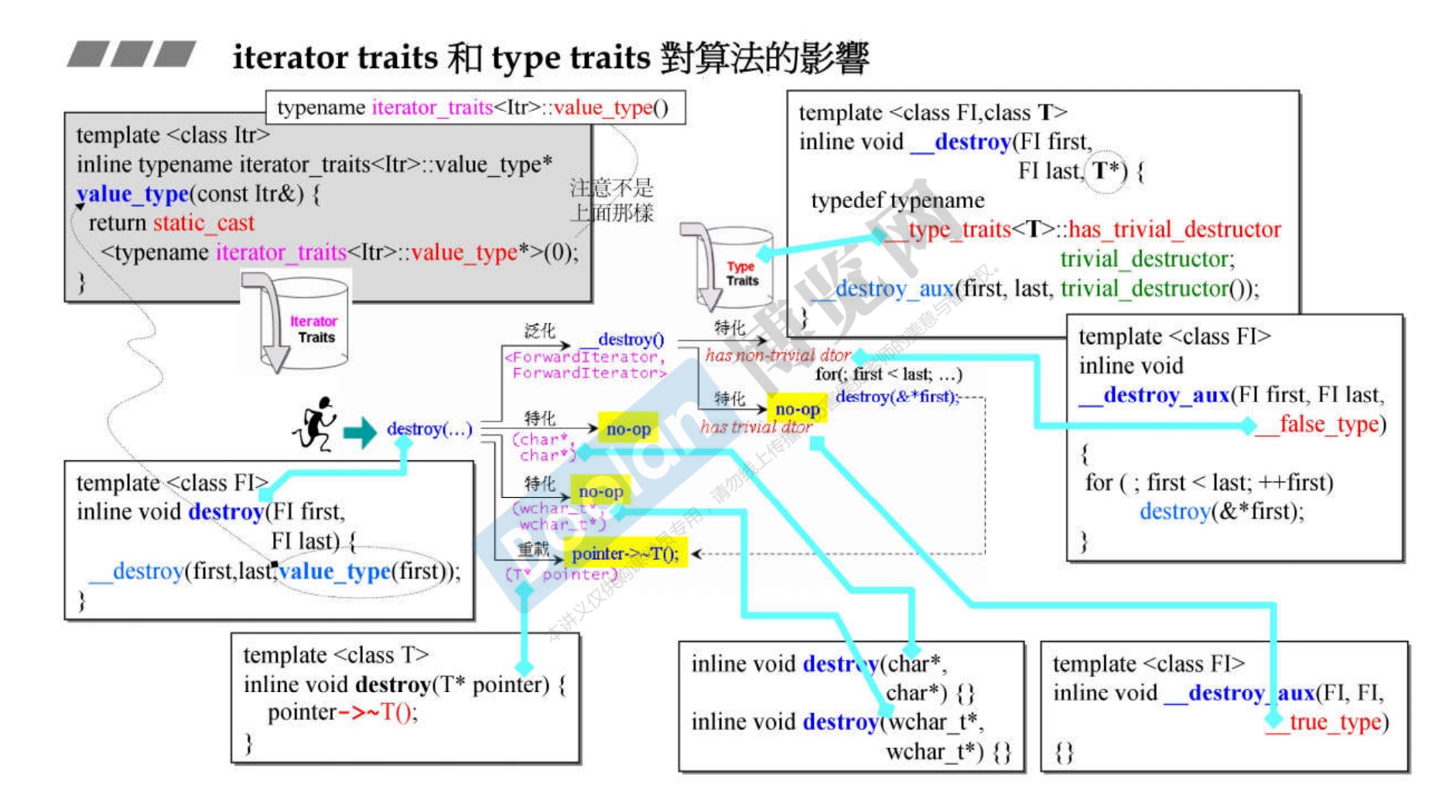
-
关于 unique_copy 函数
-
函数的作用是用于去除相邻的重复元素后,把元素复制到结果容器中去。
-
可以自定义判断重复的仿函数。
-
使用自定义的判断函数的函数原型
-
1 2template< class InputIt, class OutputIt > OutputIt unique_copy( InputIt first, InputIt last, OutputIt d_first ); -
使用自定义的判断函数的函数原型
-
1 2template< class InputIt, class OutputIt, class BinaryPredicate > OutputIt unique_copy( InputIt first, InputIt last, OutputIt d_first, BinaryPredicate p ); -
示例
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16#include <string> #include <iostream> #include <algorithm> #include <iterator> int main() { std::string s1 = "The string with many spaces!"; std::cout << "before: " << s1 << '\n'; std::string s2; std::unique_copy(s1.begin(), s1.end(), std::back_inserter(s2), [](char c1, char c2){ return c1 == ' ' && c2 == ' '; }); std::cout << "after: " << s2 << '\n'; } -
内部实现因为output_iterator 无法直接读,所以需要重载。
-
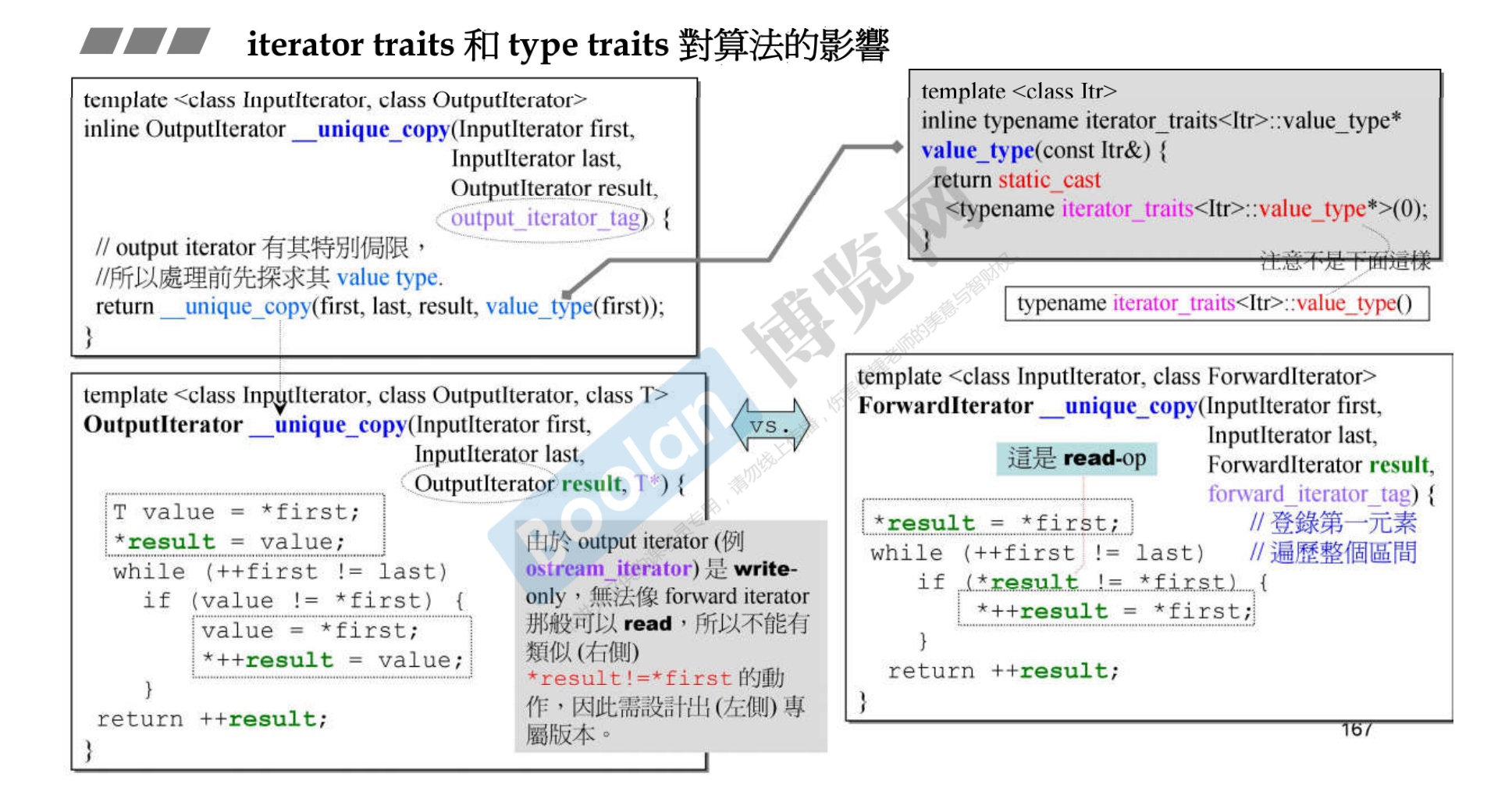
-
关于算法中对 iterator_category 的暗示
-
下图中的红色标红字体即为暗示,编译器没有对迭代器的种类有强制要求,只能在源码上进行提示。
-

21. 关于11 个算法的源码剖析
- 注意,算法一定要有两个迭代器,通过迭代器和容器进行连接。

21.1 accumulate 函数
-
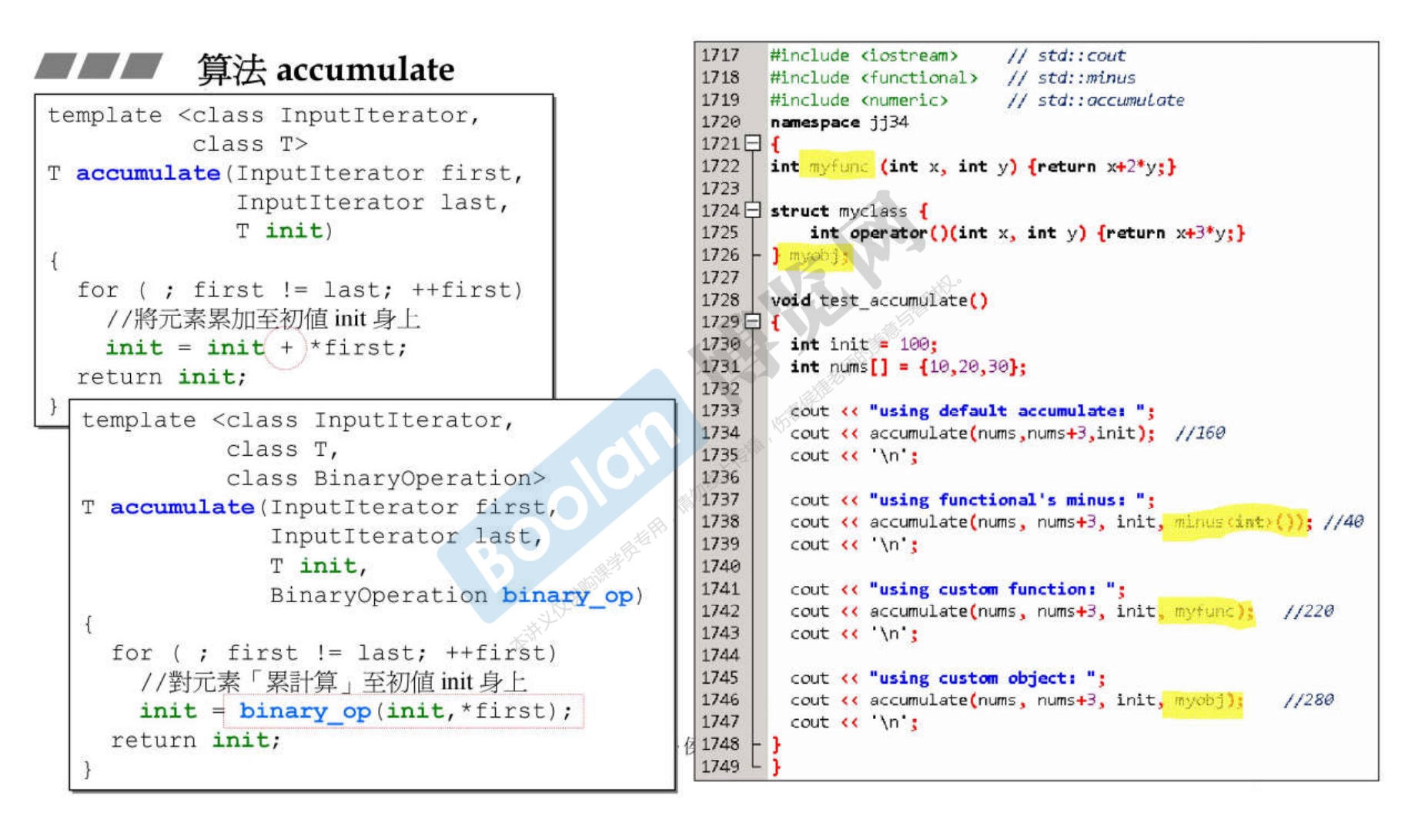
-
从上图可以看到,accumulate有两个重载函数,可以自定义相加的规则,以下例子可以看出。
-
示例
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25#include <bits/stdc++.h> using namespace std; int myfun1(int a, int b) { return a + 2 * b; } struct myfun2 { int operator()(int a, int b) const { return a + 3 * b; } }; int main() { int test[3] = {10, 20, 30}; int ret = accumulate(test, test + 3, 0); //60 int ret2 = accumulate(test, test + 3, 0, minus<int>());//-60 int ret3 = accumulate(test, test + 3, 0, myfun1);//120 int ret4 = accumulate(test, test + 3, 0, myfun2()); //一定要添加小括号生产临时对象,180 return 0; }
21.2 for_each 函数

- 其实在c++11之后,可以使用range-based for执行相同的功能。大差不差。
- 示例
22.2 repalce相关函数
-

-
关于 replace 函数
-
把old的值变为新的值
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18// replace algorithm example #include <iostream> // std::cout #include <algorithm> // std::replace #include <vector> // std::vector int main () { int myints[] = { 10, 20, 30, 30, 20, 10, 10, 20 }; std::vector<int> myvector (myints, myints+8); // 10 20 30 30 20 10 10 20 std::replace (myvector.begin(), myvector.end(), 20, 99); // 10 99 30 30 99 10 10 99 std::cout << "myvector contains:"; for (std::vector<int>::iterator it=myvector.begin(); it!=myvector.end(); ++it) std::cout << ' ' << *it; std::cout << '\n'; return 0; } -
关于 repalce_if 函数
-
满足条件的时候才替换。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36#include <bits/stdc++.h> using namespace std; struct myfun2 { bool operator()(int a) const { return a % 2 == 0; } }; int main() { vector<int> check(10); iota(check.begin(), check.end(), 0); cout << "src = " << endl; for (auto &i : check) { cout << i << " "; } cout << endl; cout << "replace = " << endl; replace_if(check.begin(), check.end(), myfun2(), 18); for (auto &i : check) { cout << i << " "; } cout << endl; return 0; } /*输出结果 src = 0 1 2 3 4 5 6 7 8 9 replace = 18 1 18 3 18 5 18 7 18 9 */ -
关于 replace_copy 函数
-
赋值到新的空间,不在原空间上修改。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20// replace_copy example #include <iostream> // std::cout #include <algorithm> // std::replace_copy #include <vector> // std::vector int main () { int myints[] = { 10, 20, 30, 30, 20, 10, 10, 20 }; std::vector<int> myvector (8); std::replace_copy (myints, myints+8, myvector.begin(), 20, 99); std::cout << "myvector contains:"; for (std::vector<int>::iterator it=myvector.begin(); it!=myvector.end(); ++it) std::cout << ' ' << *it; std::cout << '\n'; return 0; } /*输出结果 myvector contains: 10 99 30 30 99 10 10 99
22.3 count 和 count_if 函数
-

-
需要注意的是,关联式容器是自带count函数的,切记!内置的函数往往比全局的函数效率更高。
22.4 find 和 find_if 函数
-

-
需要注意的是,关联式容器内部也是自带 find 函数,效率比全局的find高很多。
22.5 sort 函数
-

-
链表有内置的sort函数,无法使用全局的sort函数;至于关联式容器,底层为红黑树的遍历即为排序状态;但是底层为哈希表的无法进行排序。
-
1 2 3 4 5 6 7 8int main(){ list<string> ls = {"one", "two", "three"}; ls.sort([](const string& a, const string& b){ return a < b; }); for(string item: ls) cout << item << " "; return 0; } -

22.6 关于 rbegin 和 rend
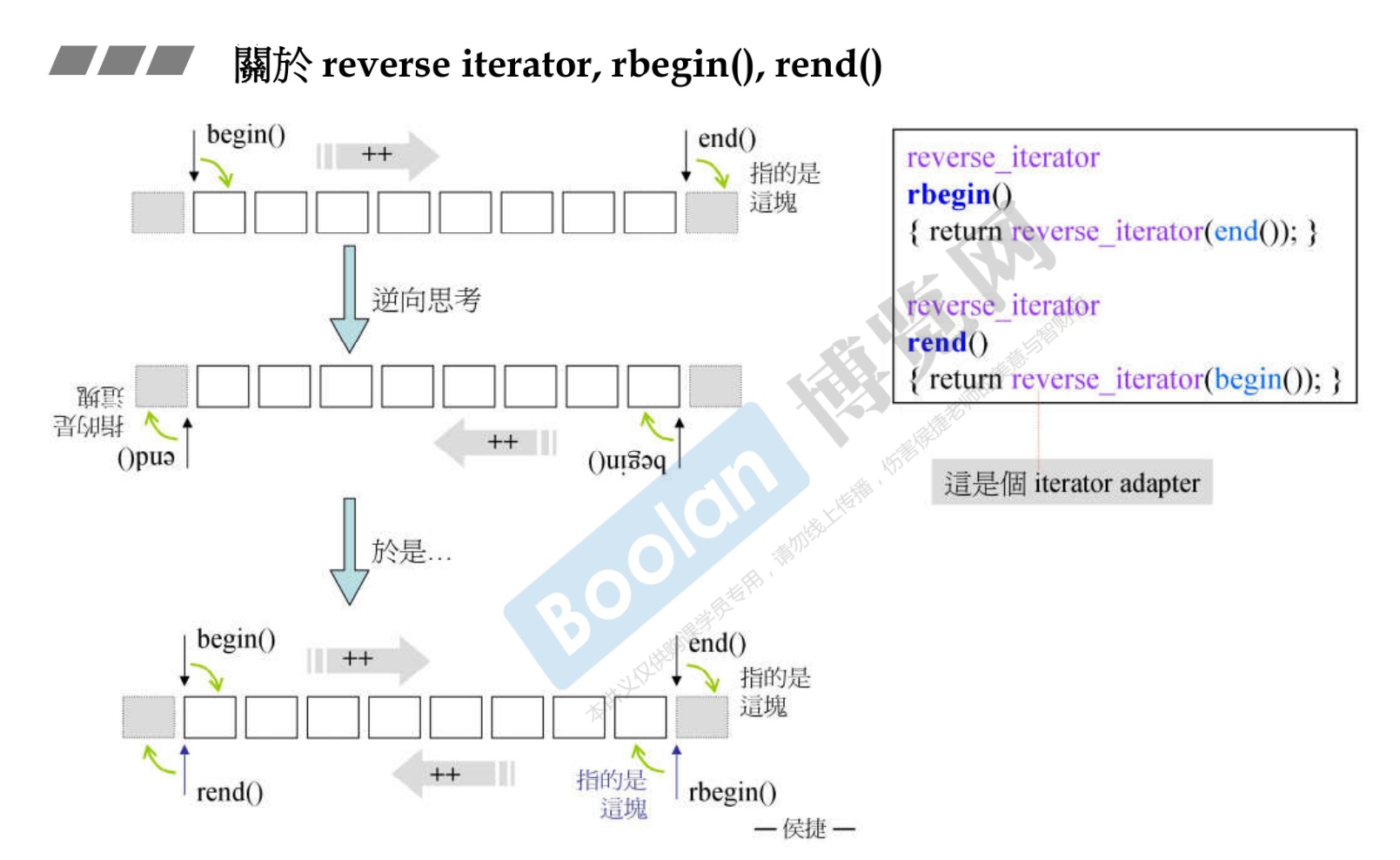
-
采用的的容器适配器,
reverse_iterator。 -

-
22.7 关于 binary_search
-
1 2 3 4 5 6template <class ForwardIterator, class T> bool binary_search (ForwardIterator first, ForwardIterator last, const T& val) { first = std::lower_bound(first,last,val); return (first!=last && !(val<*first)); } -
返回布尔类型,使用的是 lower_bound。
-

-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32// binary_search example #include <iostream> // std::cout #include <algorithm> // std::binary_search, std::sort #include <vector> // std::vector using namespace std; bool myfunction(int i, int j) { return (i < j); } int main() { int myints[] = {1, 2, 3, 4, 5, 4, 3, 2, 1}; std::vector<int> v(myints, myints + 9); // 1 2 3 4 5 4 3 2 1 // using default comparison: std::sort(v.begin(), v.end()); std::cout << "looking for a 3... "; if (std::binary_search(v.begin(), v.end(), 3)) std::cout << "found!\n"; else std::cout << "not found.\n"; //返回最适合安插的位置,第一个相等的位置之前,而upper_bound则是最后相等的位置的后一个 auto it = lower_bound(v.begin(), v.end(), 3); int idx = it - v.begin(); cout << idx << endl; return 0; } /*输出结果 looking for a 3... found! 4 */
22. 仿函数 functors
-
仿函数是最简单的一个部件,也是个人开发者最可能增添融入到STL里面的部分。
-
只有继承了unary_function 或者 binary_function 或者直接写出相对应的第一参数、第二参数以及result类型,才算一个真正的仿函数;才可以调用相对应的仿函数适配器。
-
为函数提供一些独特的准则。
-
仿函数一定要重载小括号运算符,
(),是一个类。 -

-

-
类名后面添加小括号
(),创建临时对象 -

-
为什么上图说没有融入STL体系结构呢——因为没有继承unary_function 或者 binary_function。因为没有继承,后面就没有适配改造的机会(被适配器改造)。(unary_function 或者 binary_function 是c++98才有的)
-
被适配器adapter改造的时候,适配器会问一些固定的问题,比如
second_argument_type是什么等等。所以下面就是可适配的条件。 -

23. 适配器 Adapters
概述
- 存在多种adapters
- 迭代器适配器
- 容器适配器
- 仿函数适配器
- 适配器要改造某种东西的时候,例如A 改造 B,一般是A要取用B的功能,一般有两种方式:
- 一个是继承方式,A继承B;
- 一种是复合关系,A拥有一个B;
- 以下所有的适配器都是内涵一个,即复合关系。
- 类似迭代器一定要有5个准则一样,所以仿函数适配器有3个准则。
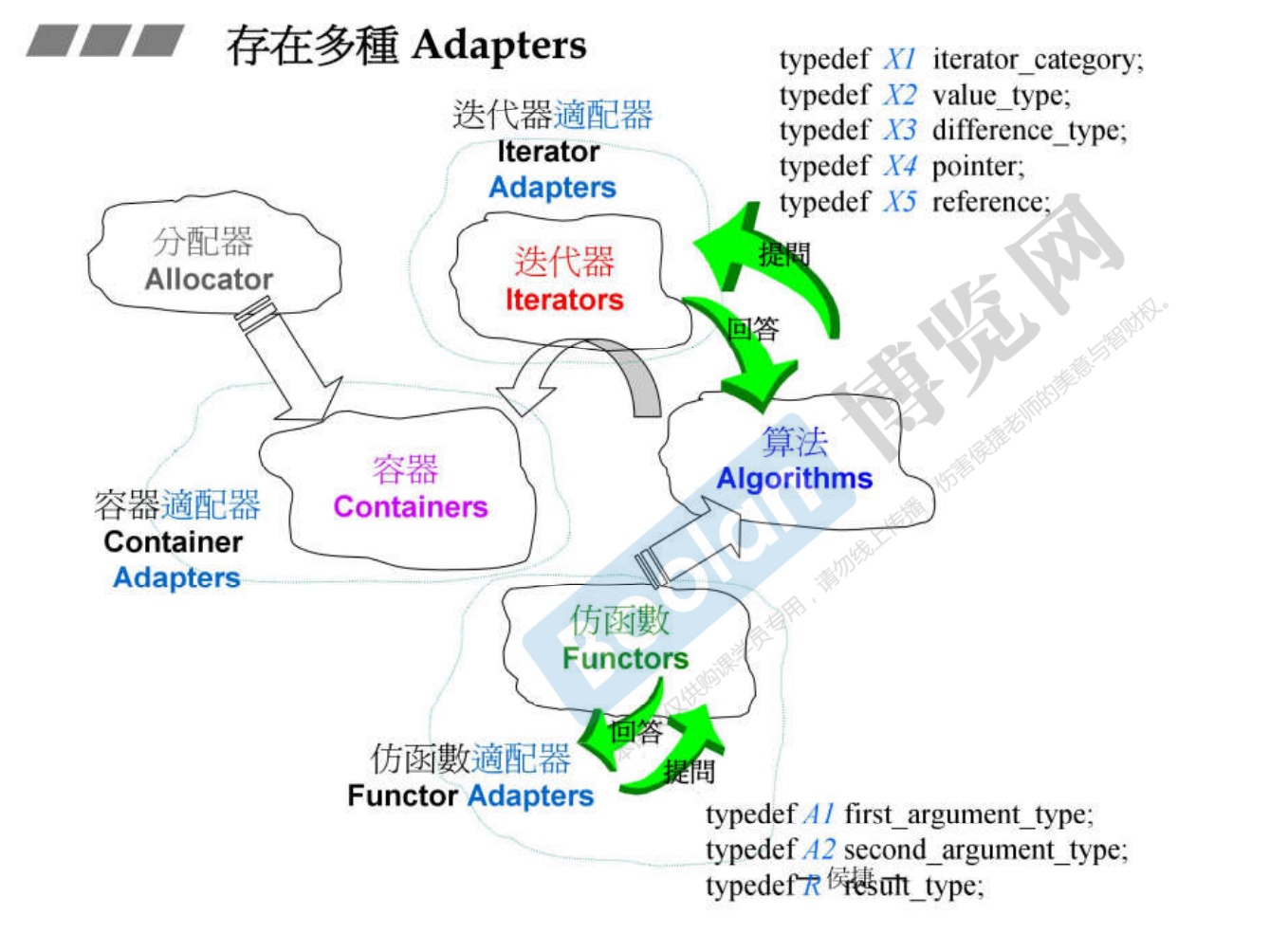
关于 Container Adapters
-
容器适配器 stack、queue都内含一个deque。
-

关于 Functor Adapters
-
1. binder2nd 函数适配器
-
作用:绑定函数的第二个参数。但是对外接口是
bind2nd函数。 -
1 2 3 4 5 6 7 8 9 10 11 12 13 14// binder2nd example #include <iostream> #include <functional> #include <algorithm> using namespace std; int main () { binder2nd < less<int> > IsNegative (less<int>(),0); int numbers[] = {10,-20,-30,40,-50}; int cx; cx = count_if (numbers,numbers+5,IsNegative); cout << "There are " << cx << " negative elements.\n"; return 0; } -
可以看到,binder2nd 需要添加仿函数类型,但是对外接口 bind2nd 并不需要我们显式传入 仿函数类型。
-
1 2 3 4 5 6 7 8 9 10 11 12 13// bind2nd example #include <iostream> #include <functional> #include <algorithm> using namespace std; int main () { int numbers[] = {10,-20,-30,40,-50}; int cx; cx = count_if ( numbers, numbers+5, bind2nd(less<int>(),0) ); cout << "There are " << cx << " negative elements.\n"; return 0; } -
关于less的定义,具备仿函数的是三个原则定义。
-
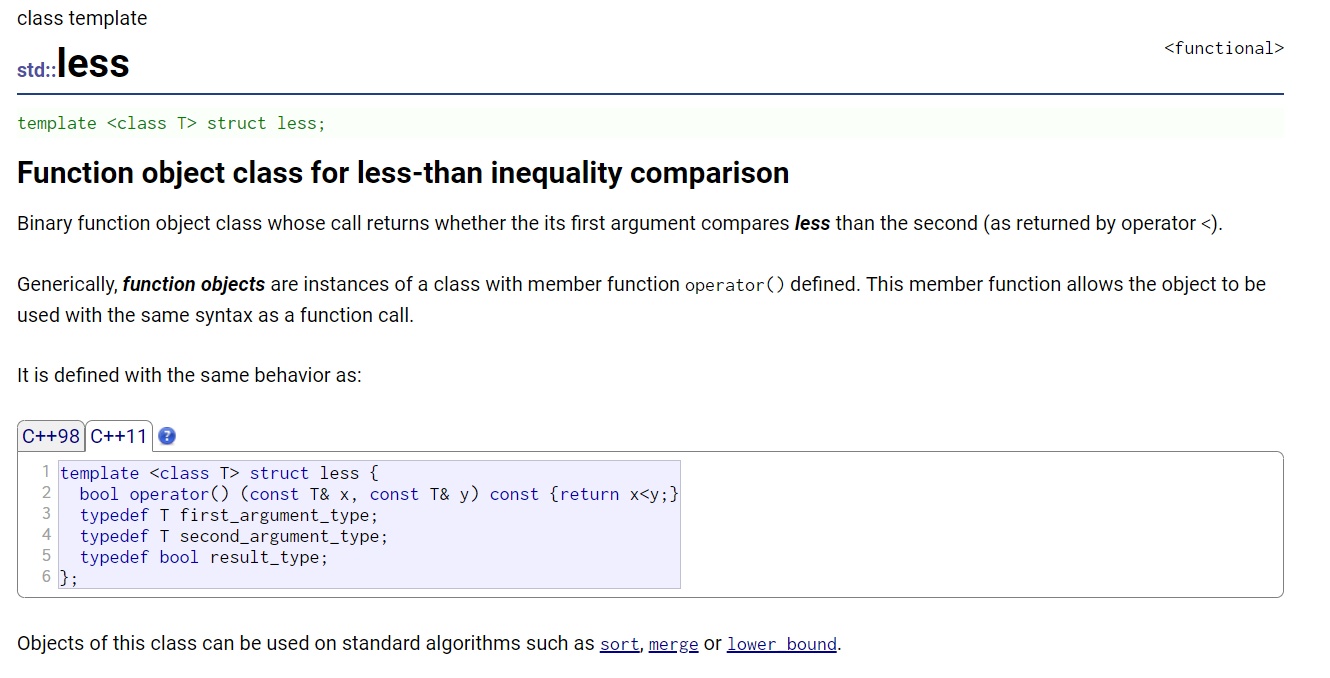
-

-
2. not1 函数适配器
-
作用:对函数的结果取反。
-
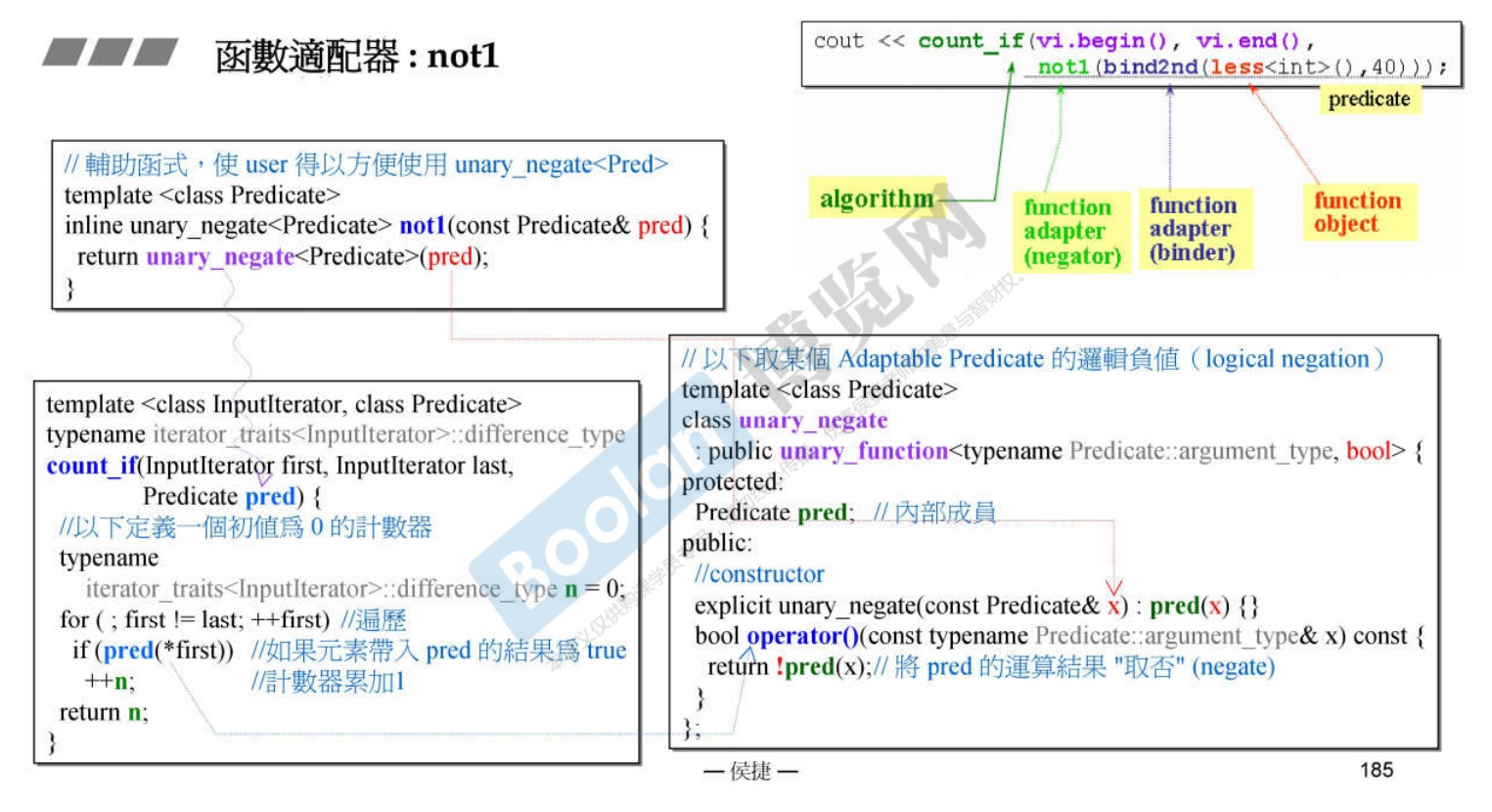
-
3. 新型适配器 bind
-
c++11 的新标准。
-
bind可以直接绑定函数,而不必须是函数对象。但是如果只是函数,因为不满足类以及三个准则,无法进一步调用如
not1等的其他适配器。 -
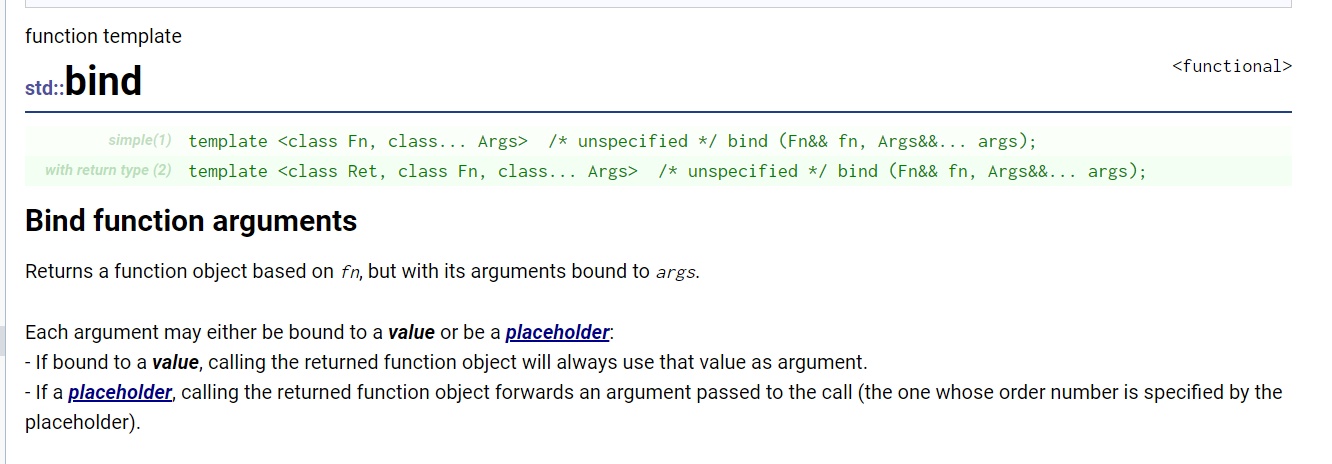
-

-

-
需要命名空间
std::placeholders来说明绑定第几个参数。 -
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62#include <bits/stdc++.h> using namespace std; // a function: (also works with function object: std::divides<double> my_divide;) double my_divide(double x, double y) { return x / y; } bool myLess(int a, int b) { return a < b; } struct MyPair { double a, b; double multiply() { return a * b; } }; int main() { using namespace std::placeholders; // adds visibility of _1, _2, _3,... // binding functions: auto fn_five = std::bind(my_divide, 10, 2); // returns 10/2 std::cout << fn_five() << '\n'; // 5 auto fn_half = std::bind(my_divide, _1, 2); // returns x/2 std::cout << fn_half(10) << '\n'; // 5 auto fn_invert = std::bind(my_divide, _2, _1); // returns y/x std::cout << fn_invert(10, 2) << '\n'; // 0.2 auto fn_rounding = std::bind<int>(my_divide, _1, _2); // returns int(x/y) std::cout << fn_rounding(10, 3) << '\n'; // 3 MyPair ten_two{10, 2}; // binding members: auto bound_member_fn = std::bind(&MyPair::multiply, _1); // returns x.multiply(),传入this指针 std::cout << bound_member_fn(ten_two) << '\n'; // 20 auto bound_member_data = std::bind(&MyPair::a, ten_two); // returns ten_two.a std::cout << bound_member_data() << '\n'; // 10 //个人测试 vector<int> mv{10, 20, 50, 2, 8, 9, 60}; auto less40 = bind(myLess, _1, 40); cout << "less 40 = " << count_if(mv.begin(), mv.end(), less40) << endl; //错误用法,因为没有使用类,而且类也要满足仿函数的三个准则 // cout << "less 40 = " << count_if(mv.begin(), mv.end(), bind2nd(myLess, 40)) << endl; //不是类 // cout << "less 40 = " << count_if(mv.begin(), mv.end(), not1(less40)) << endl; //没有满足仿函数的三个准则 return 0; } /* 输出结果 5 5 0.2 3 20 10 less 40 = 5 */
关于 Iterator Adpaters
-
1. reverse_iterator
-
难点在于——reverse_interator 的指针位置对应的是 正向迭代器 iterator的退一步的指针位置,切记!
-

-
2. inserter
-
插入迭代器总共有三种,能实现在给定的容器中给定的位置插入元素,而不覆盖之前的元素。
- back_inserter:尾部插入迭代器,back_inserter函数返回值是指向给定容器尾部的迭代器。再进行插入操作时调用了push_back函数,在尾部迭代器之前进行插入操作,不会改变插入元素的顺序。
- front_inserter:首部插入迭代器,front_inserter函数返回值是指向给定容器首部的迭代器。调用了push_front函数,在容器的首元素之前进行插入操作,每一个插入之后,新插入的元素变成首元素,最终插入的元素顺序会颠倒。
- inserter:调用了inserter函数,之前的两种迭代器默认了插入的位置,只需要输入一个参数(容器),但是inserter迭代器需要输入两个参数,一个是容器,一个是指向给定容器的迭代器,最终新元素会插入到给定迭代器之前。
-
查看源码可以看出,inserter迭代器,是因为重载了赋值操作符
=,把赋值的过程变为的insert函数,即可完成插入。 -
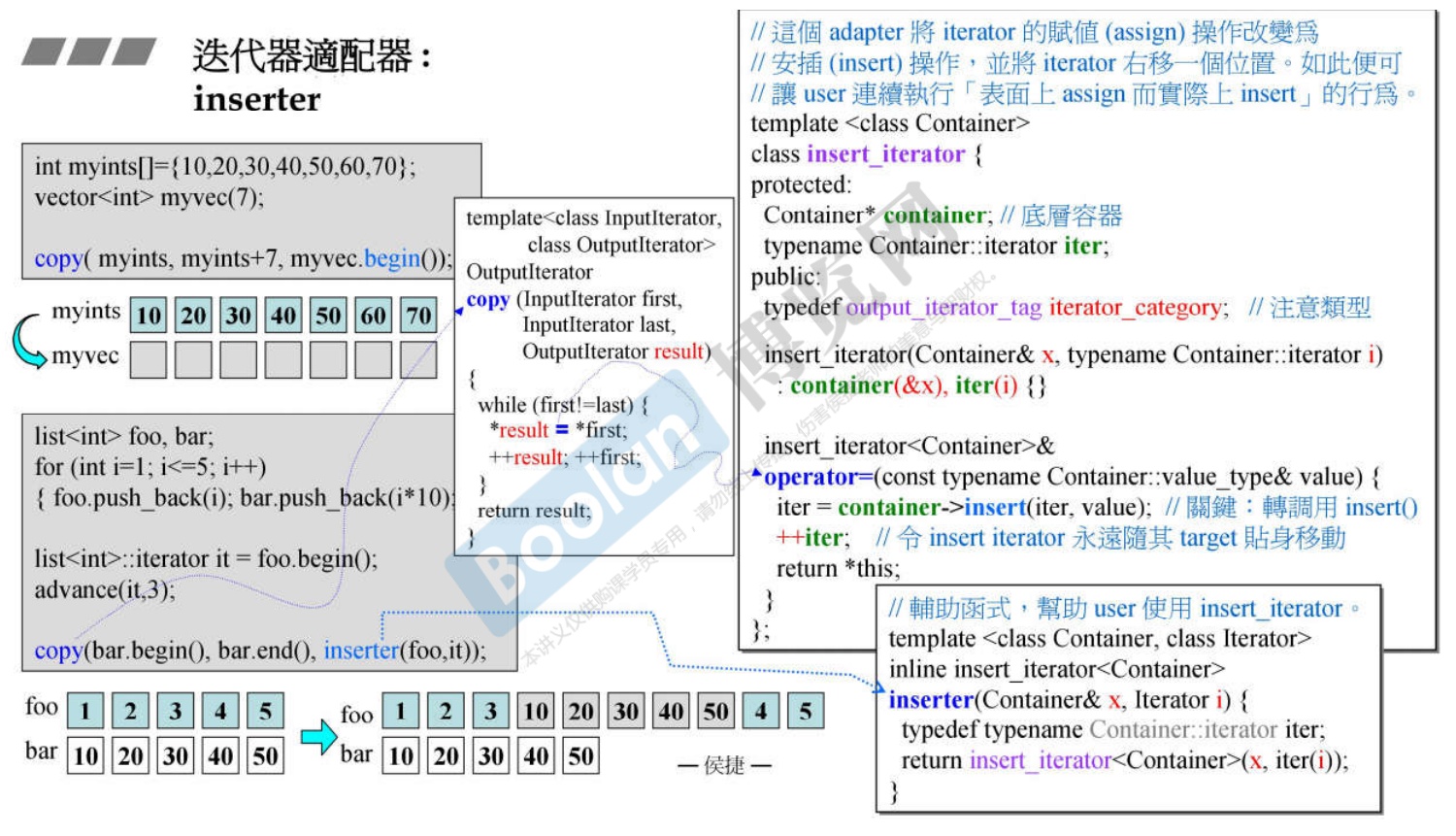
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27// inserter example #include <iostream> // std::cout #include <iterator> // std::front_inserter #include <list> // std::list #include <algorithm> // std::copy int main () { std::list<int> foo,bar; for (int i=1; i<=5; i++) { foo.push_back(i); bar.push_back(i*10); } std::list<int>::iterator it = foo.begin(); advance (it,3); std::copy (bar.begin(),bar.end(),std::inserter(foo,it)); std::cout << "foo contains:"; for ( std::list<int>::iterator it = foo.begin(); it!= foo.end(); ++it ) std::cout << ' ' << *it; std::cout << '\n'; return 0; } /* 输出结果 foo contains: 1 2 3 10 20 30 40 50 4 5 */
关于 X 适配器
-
X的意思表示未知。
-
1. ostream_iterator
-
cout是一个对象,object。
-

-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17// ostream_iterator example #include <iostream> // std::cout #include <iterator> // std::ostream_iterator #include <vector> // std::vector #include <algorithm> // std::copy int main () { std::vector<int> myvector; for (int i=1; i<10; ++i) myvector.push_back(i*10); std::ostream_iterator<int> out_it (std::cout,", "); std::copy ( myvector.begin(), myvector.end(), out_it ); return 0; } /*输出结果 10, 20, 30, 40, 50, 60, 70, 80, 90, */ -
2. istraem_iterator
-
创建cin(或者其他isteam对象)的时候,已经开始读取数据了。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20// istream_iterator example #include <iostream> // std::cin, std::cout #include <iterator> // std::istream_iterator int main () { double value1, value2; std::cout << "Please, insert two values: "; std::istream_iterator<double> eos; // end-of-stream iterator std::istream_iterator<double> iit (std::cin); // stdin iterator,以及开始读数据了 if (iit!=eos) value1=*iit; ++iit; if (iit!=eos) value2=*iit; std::cout << value1 << "*" << value2 << "=" << (value1*value2) << '\n'; return 0; } -

-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21#include <bits/stdc++.h> using namespace std; int main() { cout << "输入数据" << endl; vector<int> mv; istream_iterator<int> iit(cin), eos; copy(iit, eos, inserter(mv, mv.begin())); for (auto &i : mv) { cout << i << " "; } return 0; } /*输出结果 输入数据 1 2 3 4 5 6 7 8 9 10 eos 1 2 3 4 5 6 7 8 9 10 */ -
使用inserter适配器无需创建数组空间,因为会自动插入。
-

24. 一个万用的 Hash Function
24.1 使用仿函数来定义
-
可以有两种定义,仿函数或者普通函数,但是普通函数最后的调用方法有点复杂,因此在这推荐使用仿函数定义。
-
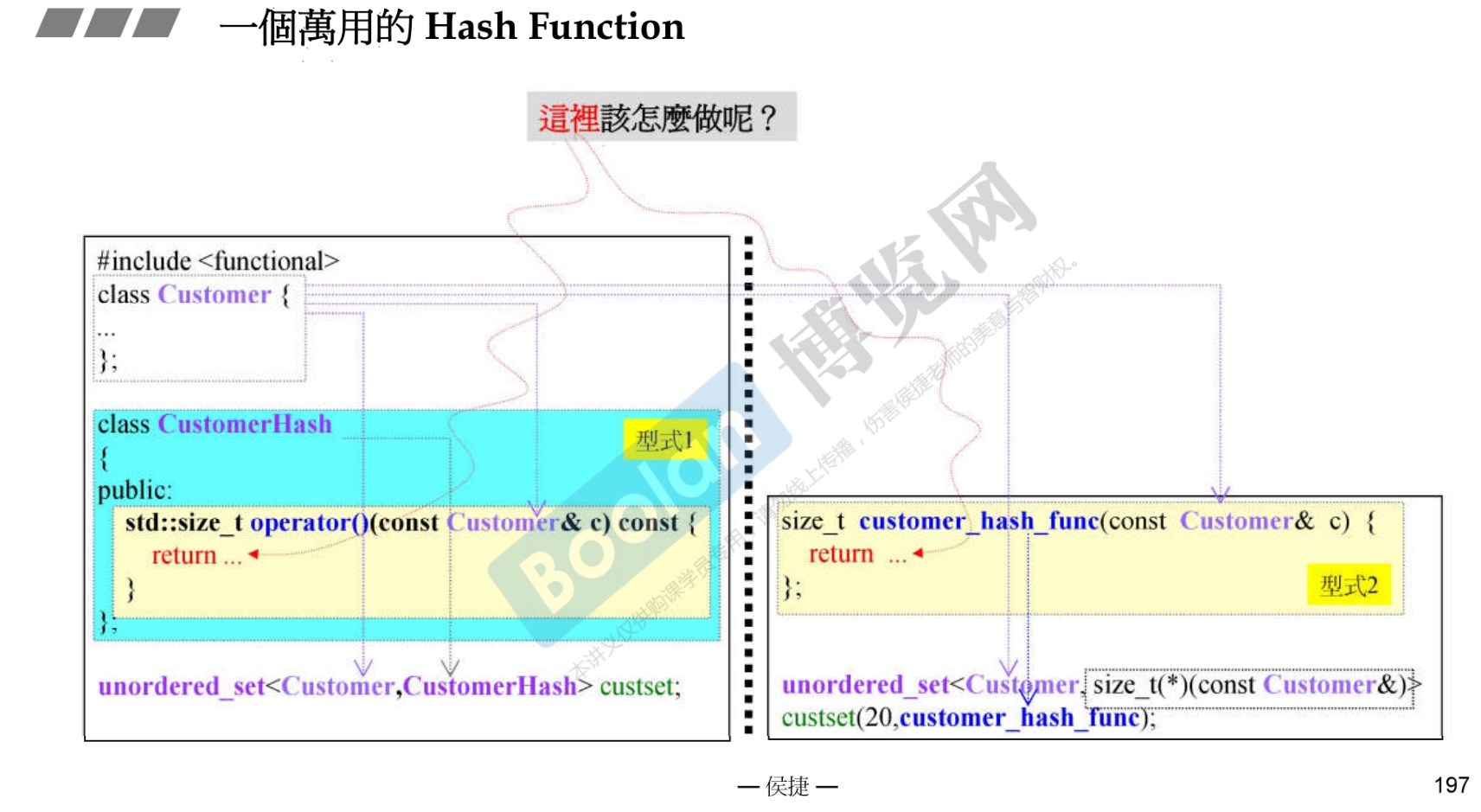
-
但是要如何计算hash code呢。boost库提供了一个万用的hash function——
hash_val。 -

-
其实现如上所示,利用了c++11的可变模板参数的特性
- 1.初始化种子seed;
- 2.递归调用上图的②函数;
- 值得注意的是,②函数里面调用④函数更改种子seed;
- 3.最后通过③函数结束递归,返回seed即为hash code。
-
至于关于那一串
0x9e3779b9,侯捷老师的讲法是黄金比例分割。 -

-
实际使用unordered_set的时候,还需要重载==运算符。
-
因此,实际调用的时候,需要自己重写相关的递归模板参数,hash_val 函数是原来boost库里面的,没有纳入STL标准库里面。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77#include <bits/stdc++.h> #include <functional> using namespace std; struct my_point { my_point(int x, int y) : m_x(x), m_y(y) {} int m_x; int m_y; bool operator==(const my_point &m_data) const { return m_x == m_data.m_x && m_y == m_data.m_y; } }; struct my_hashCode { //一定注意为常量成员函数,否则报错 size_t operator()(const my_point &src) const { return hash_val(src.m_x, src.m_y); } // 初始化种子,进入递归 template <typename... Types> size_t hash_val(const Types &...args) const { size_t seed = 0; hash_value(seed, args...); return seed; } //不断递归 template <typename T, typename... Types> void hash_value(size_t &seed, const T &firstArg, const Types &...args) const { hash_combine(seed, firstArg); hash_value(seed, args...); } //结束递归 template <typename T> void hash_value(size_t &seed, const T &val) const { hash_combine(seed, val); } //更改种子 template <typename T> void hash_combine(size_t &seed, const T &val) const { seed ^= std::hash<T>()(val) + 0x9e3779b9 + (seed << 6) + (seed >> 2); } }; int main() { unordered_set<my_point, my_hashCode> us; us.insert(my_point(3, 5)); us.insert(my_point(2, 5)); us.insert(my_point(7, 5)); us.insert(my_point(3, 5)); us.insert(my_point(1, 5)); cout << us.size() << endl; cout << us.bucket_count() << endl; cout << us.bucket_size(0) << endl; //第0个篮子存储的元素的个数 return 0; } /*输出 4 7 1 */ -

-

24.2 以偏特化形式重载 hash 函数
-
需要注意的是,必须在命名空间std里面进行重载,否则标准库找不到相应的函数。
-

-

-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46#include <bits/stdc++.h> #include <functional> using namespace std; struct my_point { my_point(int x, int y) : m_x(x), m_y(y) {} int m_x; int m_y; bool operator==(const my_point &m_data) const { return m_x == m_data.m_x && m_y == m_data.m_y; } }; // 必须放在命名空间std里面 namespace std { template <> struct hash<my_point> { size_t operator()(const my_point &src) const { return (src.m_x << 1) ^ (src.m_y << 2); } }; } int main() { unordered_set<my_point> us; us.insert(my_point(3, 5)); us.insert(my_point(2, 5)); us.insert(my_point(7, 5)); us.insert(my_point(3, 5)); us.insert(my_point(1, 5)); cout << us.size() << endl; cout << us.bucket_count() << endl; cout << us.bucket_size(1) << endl; //第0个篮子存储的元素的个数 return 0; } /*输出 4 7 1 */
25. tuple 用例
-
关于tuple的使用
-
好处就是可以定义多个不同的类集合到一个容器里面,和其他的容器大相径庭。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50// tuple example #include <iostream> // std::cout #include <tuple> // std::tuple, std::get, std::tie, std::ignore using namespace std; int main() { // tuple的创建 std::tuple<int, char> foo(10, 'x'); auto bar = std::make_tuple("test", 3.1, 14, 'y'); std::get<2>(bar) = 100; // access element。14 修改为 100 int myint; char mychar; int mint2; char mchar2; std::tie(myint, mychar) = foo; // unpack elements std::tie(std::ignore, std::ignore, mint2, mchar2) = bar; // unpack (with ignore) cout << "foo pack: " << myint << " ; " << mychar << endl; cout << "bar pack: " << mint2 << " ; " << mchar2 << endl; mychar = std::get<3>(bar); //修改原值或者获取某个数 std::get<0>(foo) = std::get<2>(bar); std::get<1>(foo) = mychar; std::cout << "修改后 foo contains: "; std::cout << std::get<0>(foo) << ' '; std::cout << std::get<1>(foo) << '\n'; //通过tuple提取其类型个数或类型来定义其他变量 typedef tuple<int, float, string> TupleType; cout << tuple_size<TupleType>::value << endl; //这个tuple有多少种类型 tuple_element<1, TupleType>::type testfloat = 1.0; //相当于float testfloat = 1.0 typedef tuple_element<2, TupleType>::type Tstring; Tstring checks = "tyc"; cout << checks << endl; return 0; } /*输出结果 foo pack: 10 ; x bar pack: 100 ; y 修改后 foo contains: 100 y 3 tyc */ -

-
关于tuple是如何设计的问题
-

-
本质就是利用c++11的新特性——可变模板参数,不断的调用父类构造函数插入数据。
-
设计十分的漂亮。
26. type_traits
-
之前我们有介绍
iterator_traits。迭代器萃取器。这里我们开始介绍type_traits。 -
iterator_traits负责萃取迭代器的特性,type_traits则负责萃取类(class、struct)的特性。
26.1 GCC 2.9 版本之前的 type_traits
-
首先需要说明类型萃取器的作用。
-
trivial:不重要的,平淡无奇的;所以has trivial 就是说没有重写该函数,使用的是编译器提供的默认函数;而has non-trivial代表的就是重写了该函数。 -
在我们需要在内存上填上一些数据时,我们可以先判断这个型别是否具有non-trivial default constructor?是否具有non-trivial copy constructor?是否具有non-trivial assignment operator?是否具有non-trivial deconstructor?如果没有的话,我们在对这个型别进行构造、析构、拷贝、赋值等操作时,就可以采用最有效(直接使用编译器的默认方法)的方式,不用去调用一些无用的构造函数。这对于大规模并且操作频繁的容器,有着显著的效率提升。
-

-
关于上图的
is_POD_type的简介。- POD(Plain Old Data,普通旧数据)类型是从 C++11 开始引入的概念,Plain 代表一个对象是一个普通类型,Old 代表一个对象可以与 C 兼容。通俗地讲,一个类、结构、共用体对象或非构造类型对象能通过二进制拷贝(如 memcpy())后还能保持其数据不变正常使用的就是POD类型的对象。严格来讲,一个对象既是普通类型(Trivial Type)又是标准布局类型(Standard-layout Type)那么这个对象就是 POD 类型。
- is pod参考
-
上面的设计是合理的,也是有效的,然后另开发者沮丧的是,这种萃取器只能适用STL的容器、类。对于自己定义的类,我们自己需要在STL里面写入我们自己的类的特化版本,才能适用type_traits来适应相对应的算法。
-
而到了c++11版本之后,有了一个新的type_traits。
26.2 C++ 11 后的 type_traits
-
不仅仅C++自带类可以自动提供自带的type traits,连我们自己编写的类都可以自动提供正确的type traits结果,不再需要我们自己编写。
-
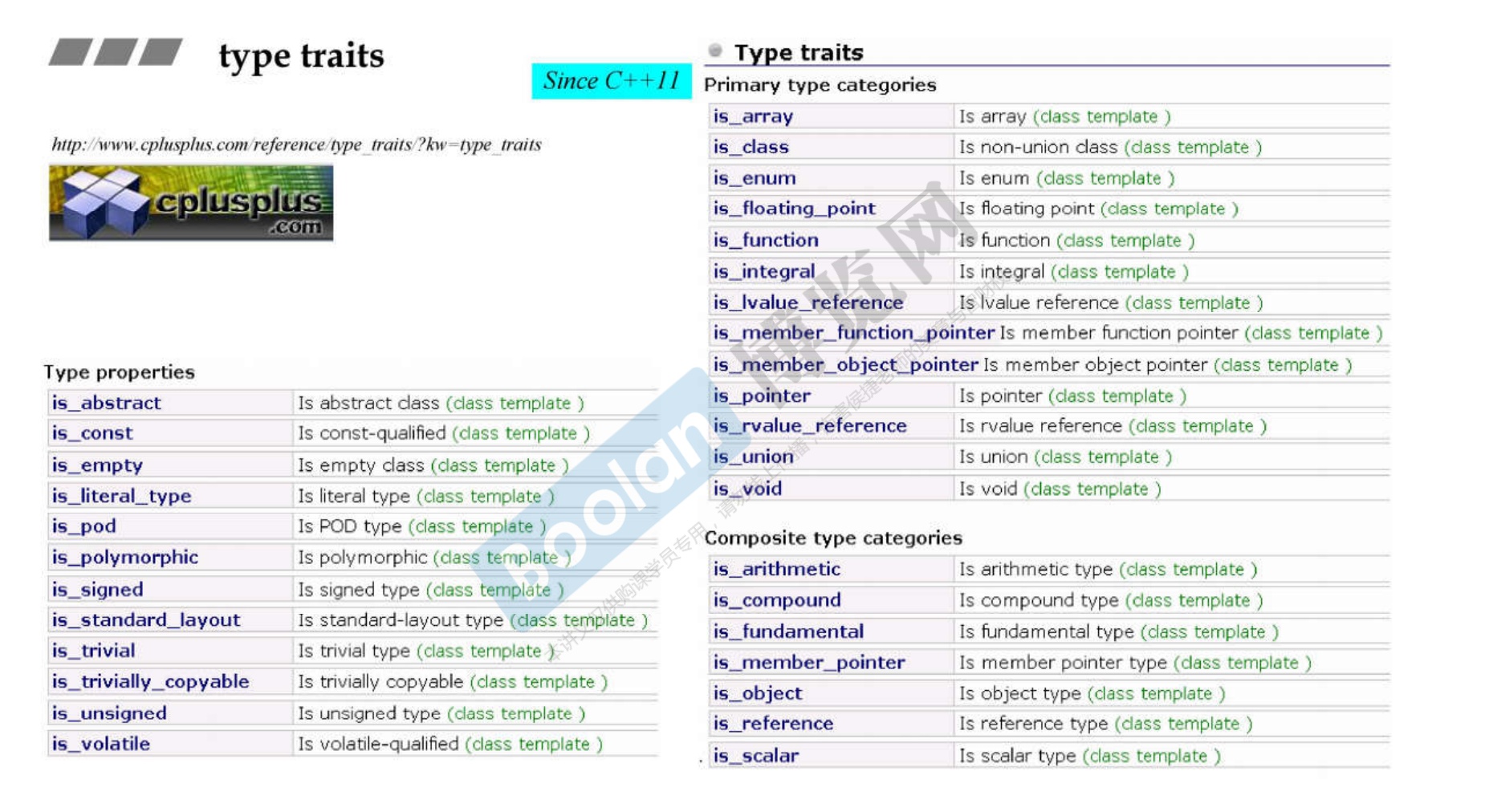
-

-

-

-

-

-
测试用例
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100#include <iostream> #include <type_traits> using namespace std; struct B { virtual ~B() {} }; struct C : B { }; template <typename T> void test_type_traits(const T &src) { cout << "\ntype traits for type : " << typeid(T).name() << endl; cout << "is void = \t" << is_void<T>::value << endl; cout << "is integral = \t" << is_integral<T>::value << endl; cout << "is_floating_point = \t" << is_floating_point<T>::value << endl; cout << "is_arithmetic = \t" << is_arithmetic<T>::value << endl; cout << "is_signed = \t" << is_signed<T>::value << endl; cout << "is_compound = \t" << is_compound<T>::value << endl; cout << "is_standard_layout = \t" << is_standard_layout<T>::value << endl; cout << "has_virtual_destructor = \t" << has_virtual_destructor<T>::value << endl; cout << "is_default_constructible = \t" << is_default_constructible<T>::value << endl; cout << "is_copy_constructible = \t" << is_copy_constructible<T>::value << endl; cout << "is_move_constructible = \t" << is_move_constructible<T>::value << endl; cout << "is_copy_assignable = \t" << is_copy_assignable<T>::value << endl; cout << "is_move_assignable = \t" << is_move_assignable<T>::value << endl; cout << "is_trivial = \t" << is_trivial<T>::value << endl; } class my_zo { public: my_zo(int i, int j) : m_date1(i), m_date2(j) {} // 拷贝构造 my_zo(const my_zo &) = delete; // 移动构造 my_zo(my_zo &&) = default; // 拷贝赋值 my_zo &operator=(const my_zo &) = default; // 移动赋值 my_zo &operator=(const my_zo &&) = delete; private: int m_date1; int m_date2; }; int main() { std::cout << std::boolalpha; cout << "测试虚函数-------------" << endl; test_type_traits(C()); cout << "---------------------" << endl; cout << "测试type_traits-----------" << endl; test_type_traits(my_zo(2, 2)); return 0; } /*输出结果 测试虚函数------------- type traits for type : 1C is void = false is integral = false is_floating_point = false is_arithmetic = false is_signed = false is_compound = true is_standard_layout = false has_virtual_destructor = true is_default_constructible = true is_copy_constructible = true is_move_constructible = true is_copy_assignable = true is_move_assignable = true is_trivial = false --------------------- 测试type_traits----------- type traits for type : 5my_zo is void = false is integral = false is_floating_point = false is_arithmetic = false is_signed = false is_compound = true is_standard_layout = true has_virtual_destructor = false is_default_constructible = false is_copy_constructible = false is_move_constructible = true is_copy_assignable = true is_move_assignable = false is_trivial = false */ -
26.3 关于 type_traits 的结构设计
-

-

-
实现的手法都是充分利用偏特化。
-
27. 关于cout
-

-

-
要想输出自定义的类,就要重写自定义类型的cout。
-
gcc 8.1 源码
-

-

-

-
28. move_ctor 对程序运行效率的影响
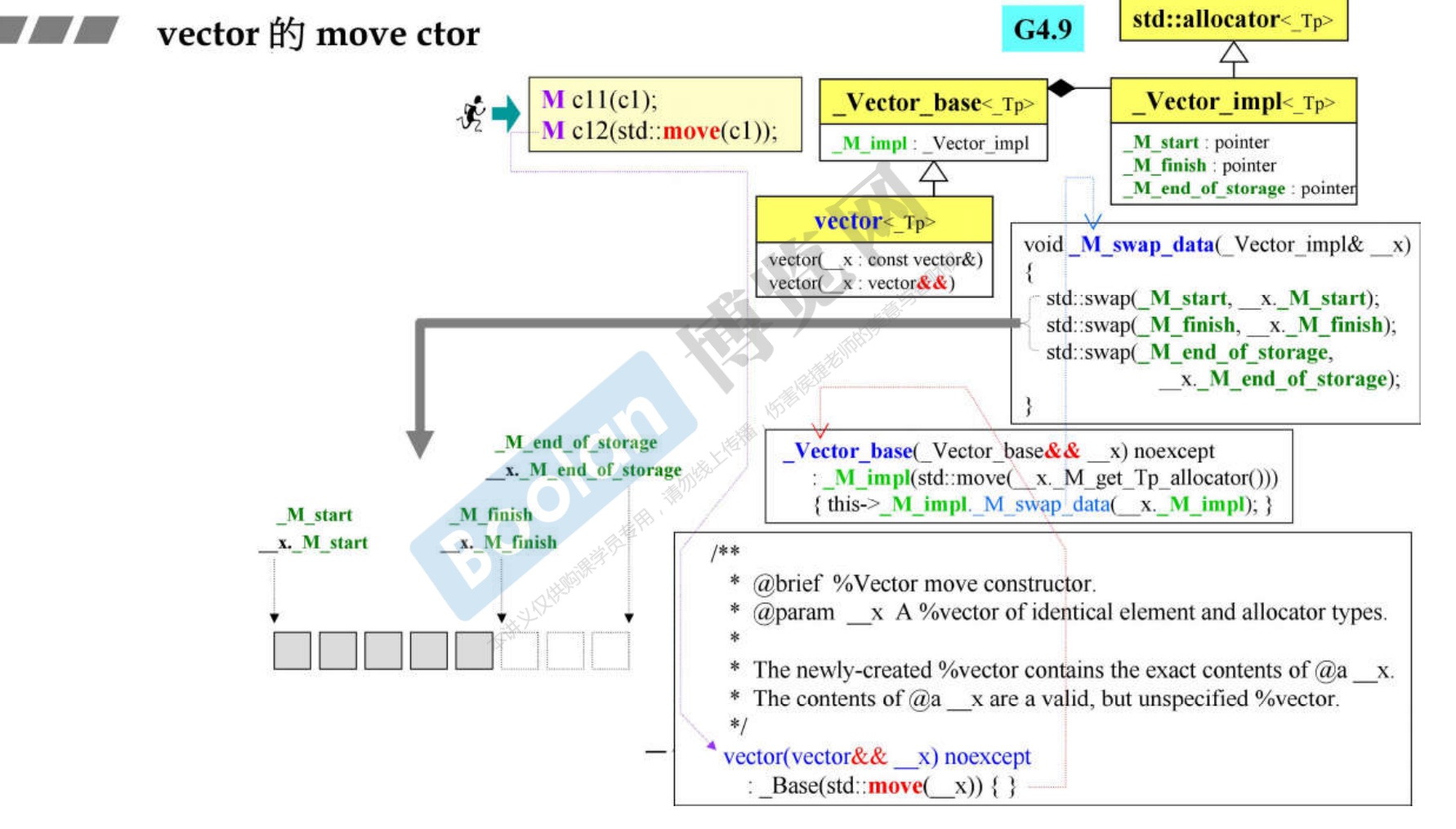
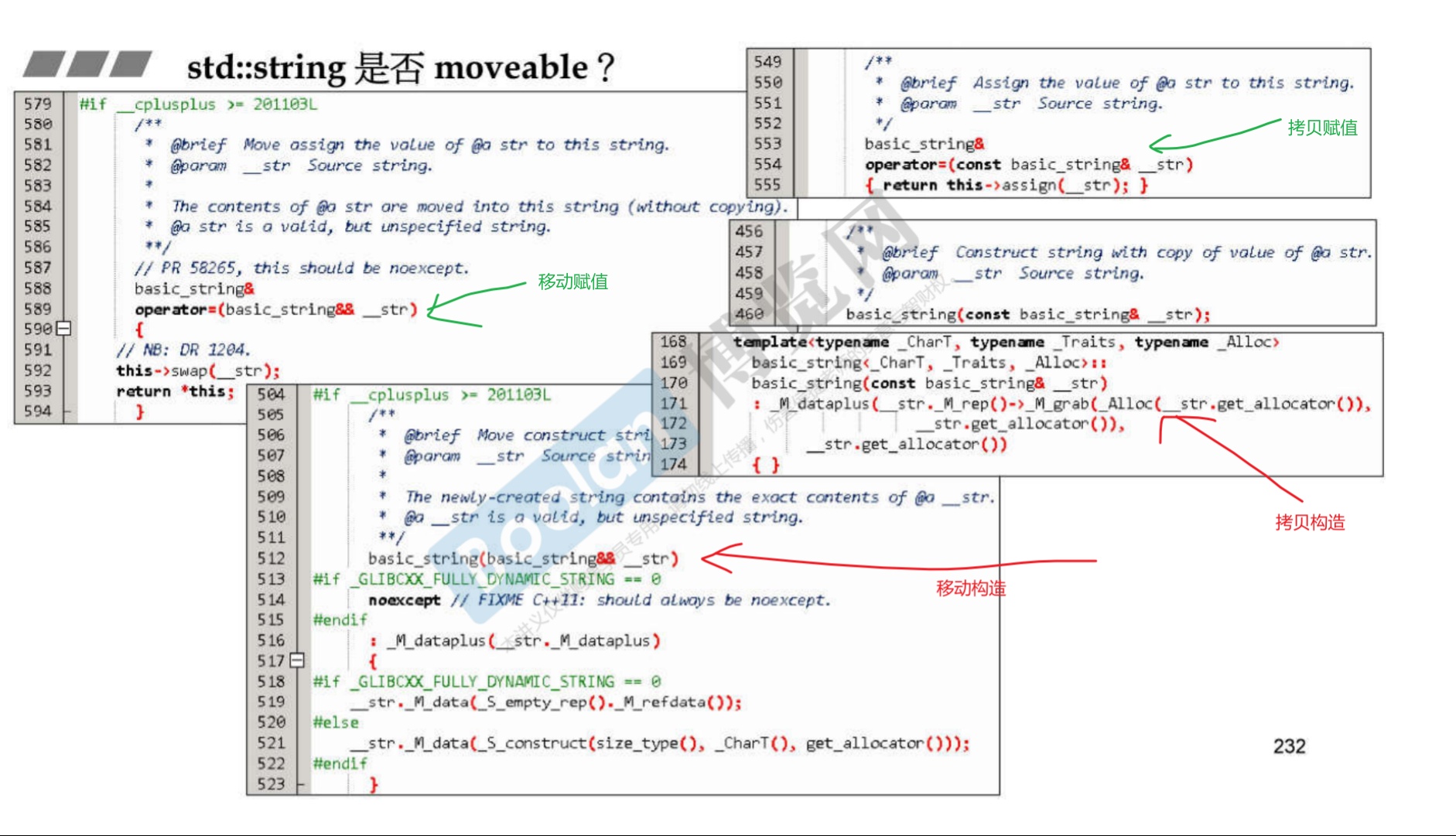
28.1 概述
-
根据侯捷老师所讲,分别在
- 构造插入的时候使用自定义类的移动构造函数
- 使用 std:move 来移动容器(例如vector,list等等) ,移动语义来比较移动构造和拷贝构造的区别
-
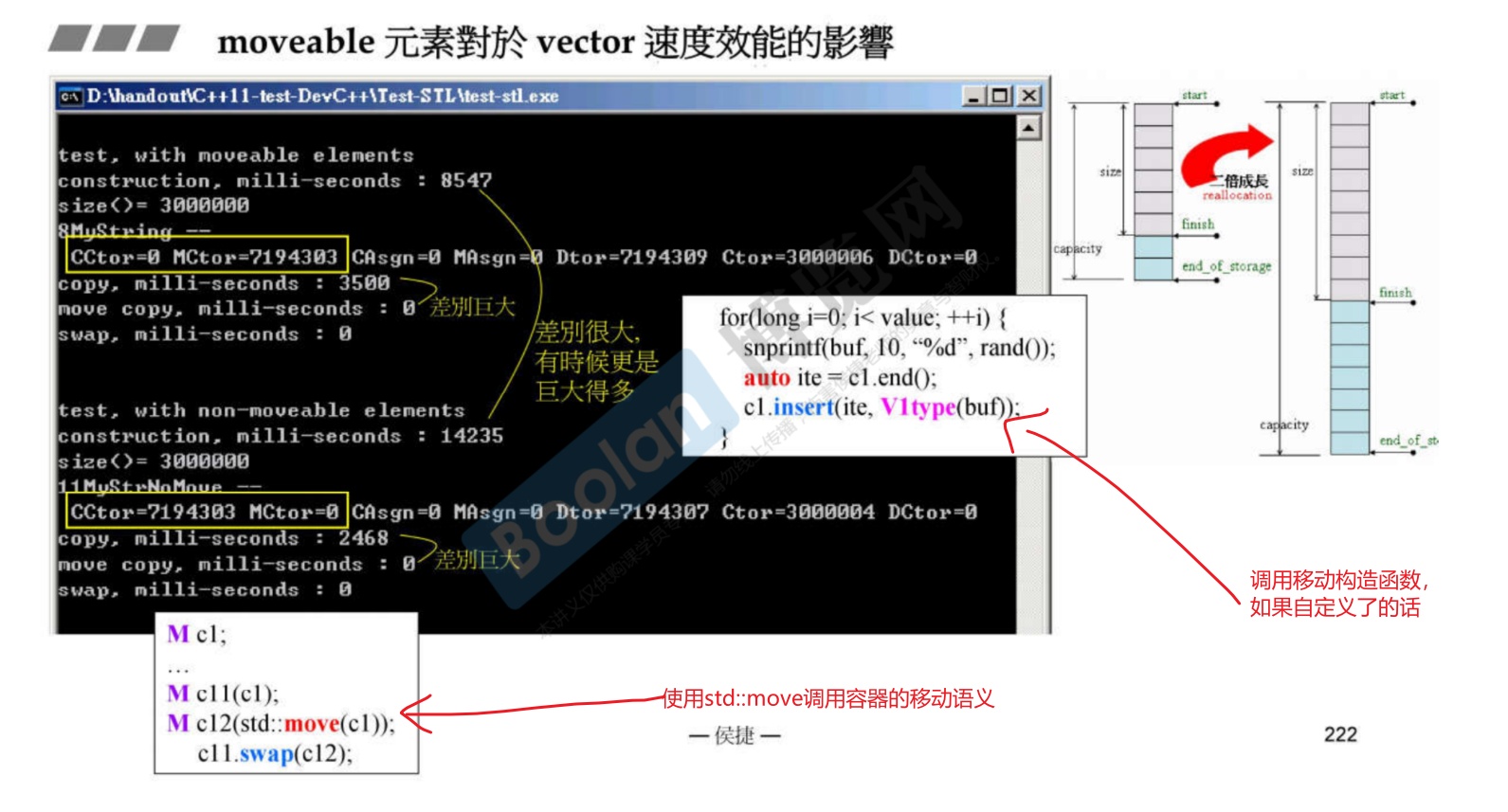
-
以vector为容器,自定义两个类,其中类A自定义了移动构造和移动赋值函数;类B没有。
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330#include <ctime> //clock_t, clock() #include <iostream> #include <cstdio> //snprintf() #include <cstdlib> //RAND_MAX #include <cstring> //strlen(), memcpy() #include <string> #include <iterator> //iterator_traits using std::cin; using std::cout; using std::endl; using std::string; using namespace std; // iterator_traits需要std的命名 #include <typeinfo> //typeid() template <typename T> void output_static_data(const T &myStr) { cout << typeid(myStr).name() << " -- " << endl; cout << " CCtor=" << T::CCtor << " MCtor=" << T::MCtor << " CAsgn=" << T::CAsgn << " MAsgn=" << T::MAsgn << " Dtor=" << T::Dtor << " Ctor=" << T::Ctor << " DCtor=" << T::DCtor << endl; } template <typename M, typename NM> void test_moveable(M c1, NM c2, long &value) { char buf[10]; //測試 move cout << "\n\ntest, with moveable elements" << endl; typedef typename iterator_traits<typename M::iterator>::value_type V1type; clock_t timeStart = clock(); for (long i = 0; i < value; ++i) { snprintf(buf, 10, "%d", rand()); auto ite = c1.end(); c1.insert(ite, V1type(buf)); } cout << "construction, milli-seconds : " << (clock() - timeStart) << endl; cout << "size()= " << c1.size() << endl; output_static_data(*(c1.begin())); timeStart = clock(); M c11(c1); cout << "copy, milli-seconds : " << (clock() - timeStart) << endl; timeStart = clock(); M c12(std::move(c1)); cout << "move copy, milli-seconds : " << (clock() - timeStart) << endl; timeStart = clock(); c11.swap(c12); cout << "swap, milli-seconds : " << (clock() - timeStart) << endl; //測試 non-moveable cout << "\n\ntest, with non-moveable elements" << endl; typedef typename iterator_traits<typename NM::iterator>::value_type V2type; timeStart = clock(); for (long i = 0; i < value; ++i) { snprintf(buf, 10, "%d", rand()); auto ite = c2.end(); c2.insert(ite, V2type(buf)); } cout << "construction, milli-seconds : " << (clock() - timeStart) << endl; cout << "size()= " << c2.size() << endl; output_static_data(*(c2.begin())); timeStart = clock(); NM c21(c2); cout << "copy, milli-seconds : " << (clock() - timeStart) << endl; timeStart = clock(); NM c22(std::move(c2)); cout << "move copy, milli-seconds : " << (clock() - timeStart) << endl; timeStart = clock(); c21.swap(c22); cout << "swap, milli-seconds : " << (clock() - timeStart) << endl; } //以下 MyString 是為了測試 containers with moveable elements 效果. class MyString { public: static size_t DCtor; //累計 default-ctor 的呼叫次數 static size_t Ctor; //累計 ctor 的呼叫次數 static size_t CCtor; //累計 copy-ctor 的呼叫次數 static size_t CAsgn; //累計 copy-asgn 的呼叫次數 static size_t MCtor; //累計 move-ctor 的呼叫次數 static size_t MAsgn; //累計 move-asgn 的呼叫次數 static size_t Dtor; //累計 dtor 的呼叫次數 private: char *_data; size_t _len; void _init_data(const char *s) { _data = new char[_len + 1]; memcpy(_data, s, _len); _data[_len] = '\0'; } public: // default ctor MyString() : _data(NULL), _len(0) { ++DCtor; } // ctor MyString(const char *p) : _len(strlen(p)) { ++Ctor; _init_data(p); } // copy ctor MyString(const MyString &str) : _len(str._len) { ++CCtor; _init_data(str._data); // COPY } // move ctor, with "noexcept" MyString(MyString &&str) noexcept : _data(str._data), _len(str._len) { ++MCtor; str._len = 0; str._data = NULL; //避免 delete (in dtor) } // copy assignment MyString &operator=(const MyString &str) { ++CAsgn; if (this != &str) { if (_data) delete _data; _len = str._len; _init_data(str._data); // COPY! } else { // Self Assignment, Nothing to do. } return *this; } // move assignment MyString &operator=(MyString &&str) noexcept { ++MAsgn; if (this != &str) { if (_data) delete _data; _len = str._len; _data = str._data; // MOVE! str._len = 0; str._data = NULL; //避免 deleted in dtor } return *this; } // dtor virtual ~MyString() { ++Dtor; if (_data) { delete _data; } } bool operator<(const MyString &rhs) const //為了讓 set 比較大小 { return std::string(this->_data) < std::string(rhs._data); //借用事實:string 已能比較大小. } bool operator==(const MyString &rhs) const //為了讓 set 判斷相等. { return std::string(this->_data) == std::string(rhs._data); //借用事實:string 已能判斷相等. } char *get() const { return _data; } }; size_t MyString::DCtor = 0; size_t MyString::Ctor = 0; size_t MyString::CCtor = 0; size_t MyString::CAsgn = 0; size_t MyString::MCtor = 0; size_t MyString::MAsgn = 0; size_t MyString::Dtor = 0; namespace std //必須放在 std 內 { template <> struct hash<MyString> //這是為了 unordered containers { size_t operator()(const MyString &s) const noexcept { return hash<string>()(string(s.get())); } //借用現有的 hash<string> (in ...\include\c++\bits\basic_string.h) }; } //----------------- //以下 MyStrNoMove 是為了測試 containers with no-moveable elements 效果. class MyStrNoMove { public: static size_t DCtor; //累計 default-ctor 的呼叫次數 static size_t Ctor; //累計 ctor 的呼叫次數 static size_t CCtor; //累計 copy-ctor 的呼叫次數 static size_t CAsgn; //累計 copy-asgn 的呼叫次數 static size_t MCtor; //累計 move-ctor 的呼叫次數 static size_t MAsgn; //累計 move-asgn 的呼叫次數 static size_t Dtor; //累計 dtor 的呼叫次數 private: char *_data; size_t _len; void _init_data(const char *s) { _data = new char[_len + 1]; memcpy(_data, s, _len); _data[_len] = '\0'; } public: // default ctor MyStrNoMove() : _data(NULL), _len(0) { ++DCtor; _init_data("jjhou"); } // ctor MyStrNoMove(const char *p) : _len(strlen(p)) { ++Ctor; _init_data(p); } // copy ctor MyStrNoMove(const MyStrNoMove &str) : _len(str._len) { ++CCtor; _init_data(str._data); // COPY } // copy assignment MyStrNoMove &operator=(const MyStrNoMove &str) { ++CAsgn; if (this != &str) { if (_data) delete _data; _len = str._len; _init_data(str._data); // COPY! } else { // Self Assignment, Nothing to do. } return *this; } // dtor virtual ~MyStrNoMove() { ++Dtor; if (_data) { delete _data; } } bool operator<(const MyStrNoMove &rhs) const //為了讓 set 比較大小 { return string(this->_data) < string(rhs._data); //借用事實:string 已能比較大小. } bool operator==(const MyStrNoMove &rhs) const //為了讓 set 判斷相等. { return string(this->_data) == string(rhs._data); //借用事實:string 已能判斷相等. } char *get() const { return _data; } }; size_t MyStrNoMove::DCtor = 0; size_t MyStrNoMove::Ctor = 0; size_t MyStrNoMove::CCtor = 0; size_t MyStrNoMove::CAsgn = 0; size_t MyStrNoMove::MCtor = 0; size_t MyStrNoMove::MAsgn = 0; size_t MyStrNoMove::Dtor = 0; namespace std //必須放在 std 內 { template <> struct hash<MyStrNoMove> //這是為了 unordered containers { size_t operator()(const MyStrNoMove &s) const noexcept { return hash<string>()(string(s.get())); } //借用現有的 hash<string> (in ...\4.9.2\include\c++\bits\basic_string.h) }; } #include <vector> using std::vector; int main() { long value = 1000000; test_moveable(vector<MyString>(), vector<MyStrNoMove>(), value); return 0; } -
输出结果
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18test, with moveable elements construction, milli-seconds : 1334 size()= 1000000 8MyString -- CCtor=0 MCtor=2048575 CAsgn=0 MAsgn=0 Dtor=2048575 Ctor=1000000 DCtor=0 copy, milli-seconds : 417 move copy, milli-seconds : 1 swap, milli-seconds : 0 test, with non-moveable elements construction, milli-seconds : 99705 size()= 1000000 11MyStrNoMove -- CCtor=2048575 MCtor=0 CAsgn=0 MAsgn=0 Dtor=2048575 Ctor=1000000 DCtor=0 copy, milli-seconds : 542 move copy, milli-seconds : 0 swap, milli-seconds : 0 -
可以看到单独插入效率相差90多倍,整体移动效率相比近与无穷大。
-
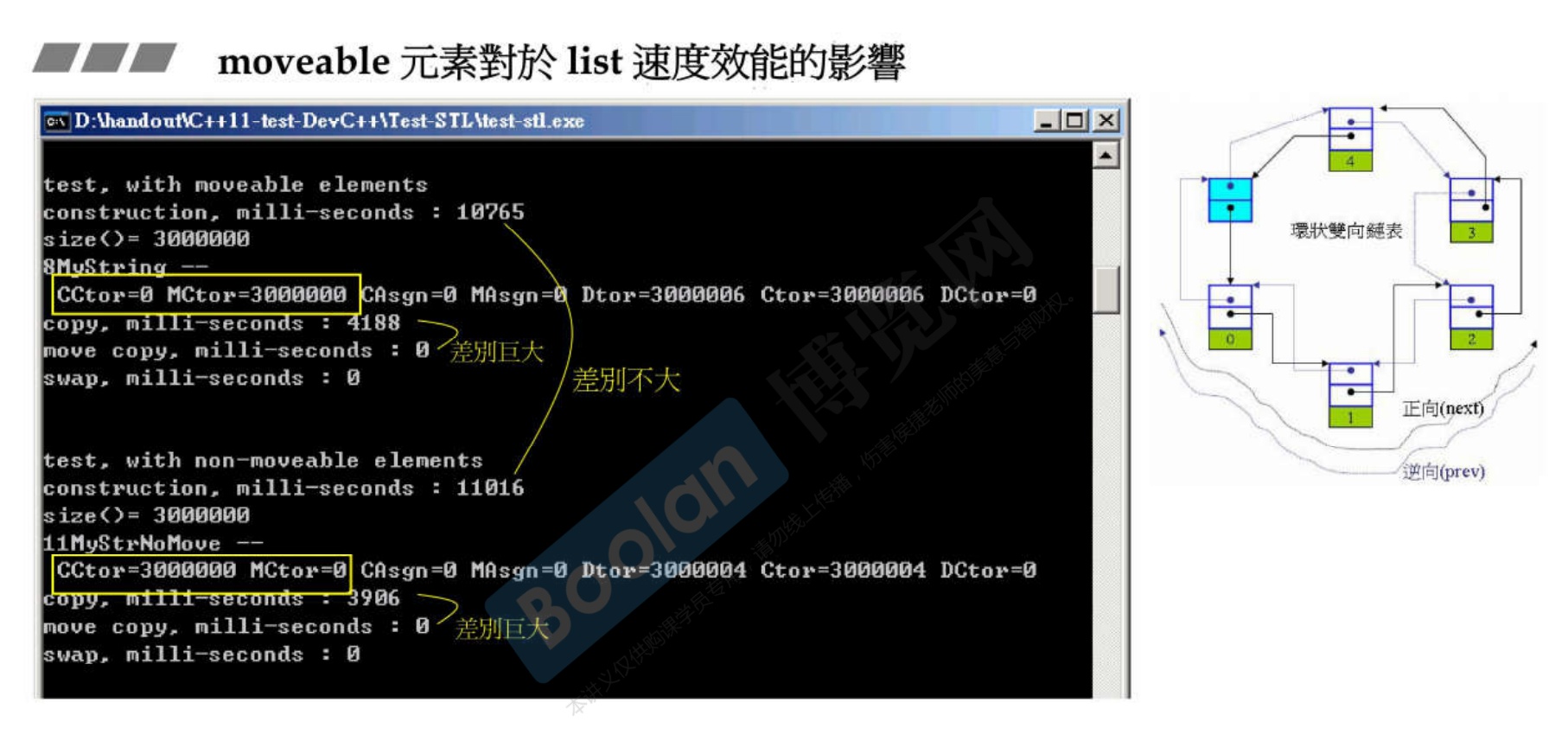
-

-
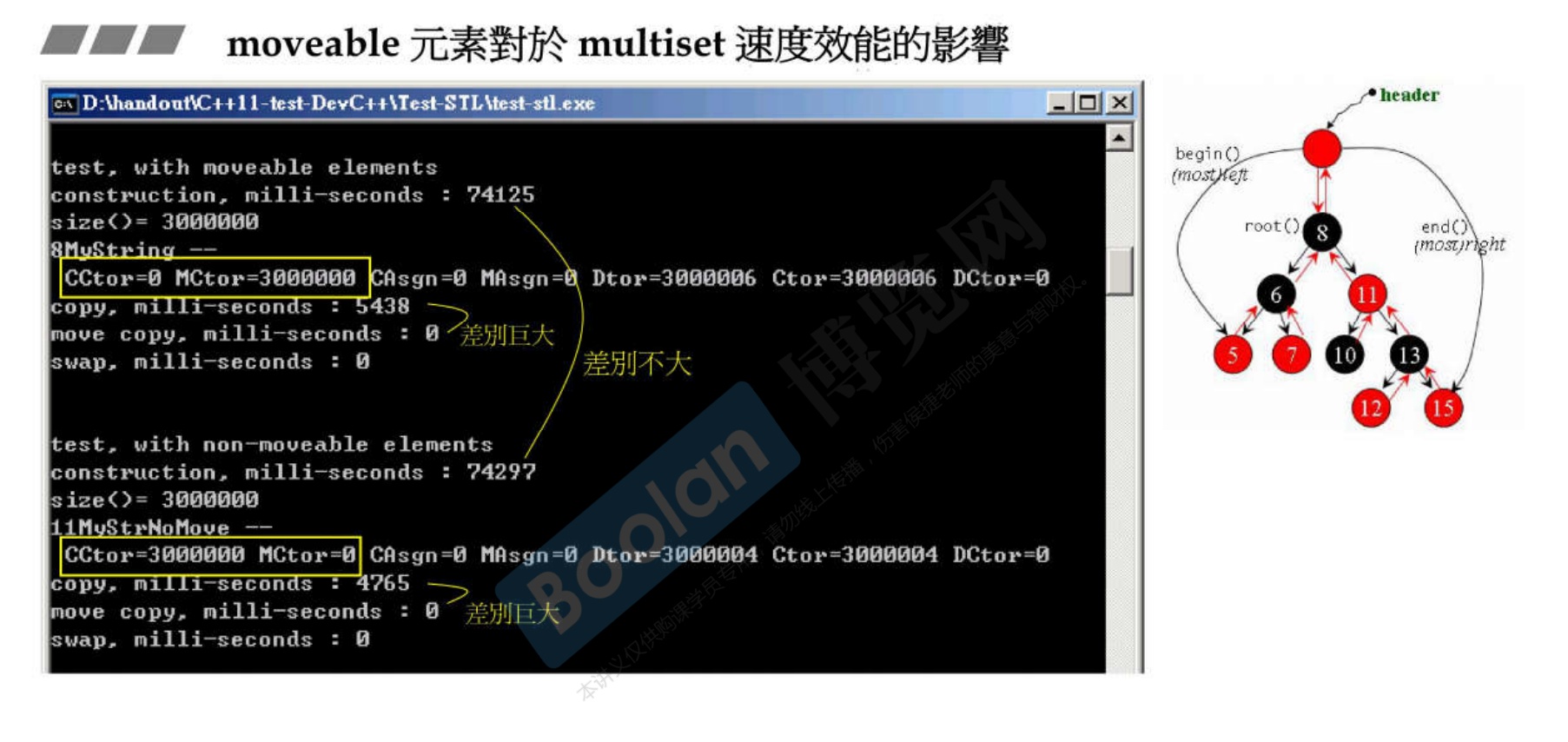
-
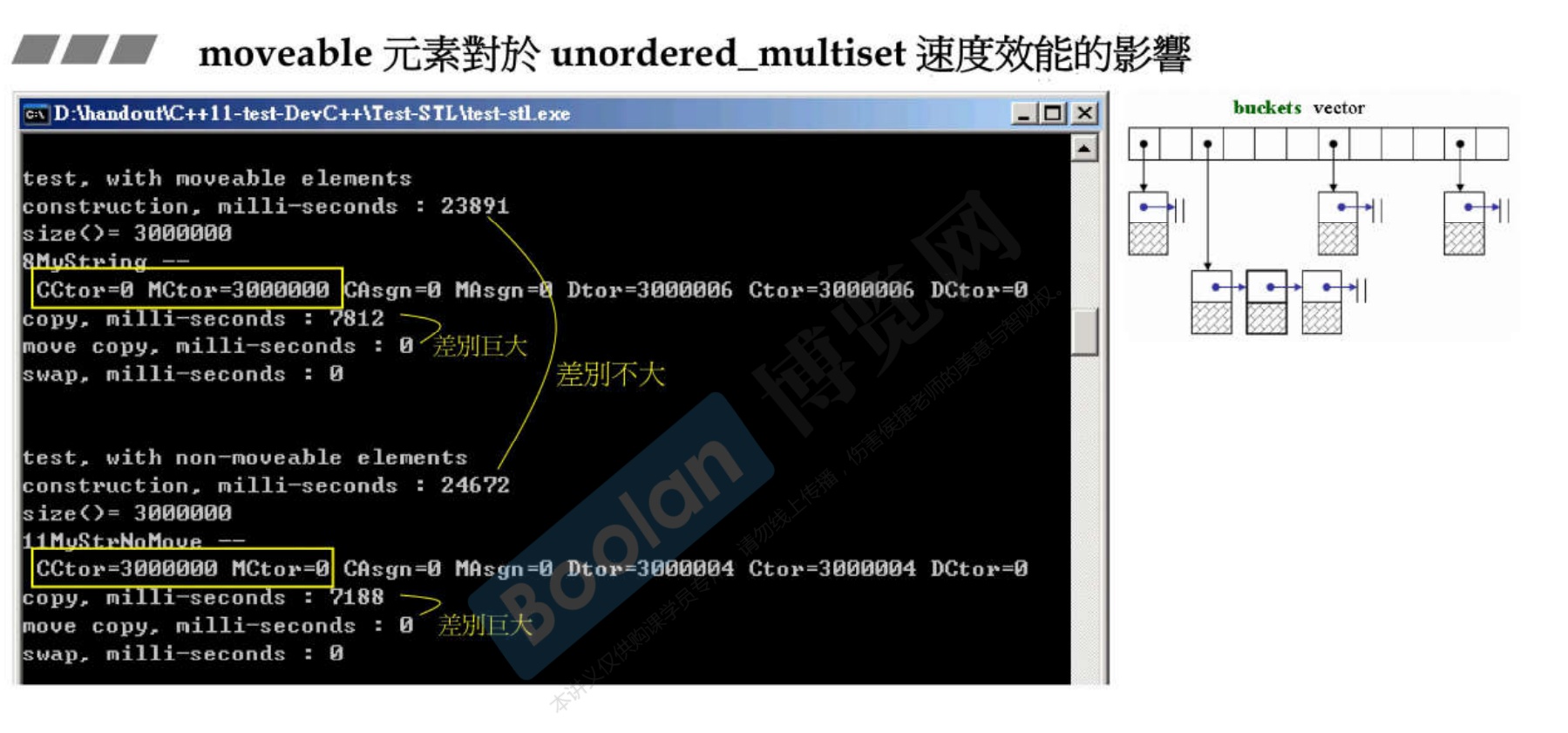
28.2 关于vector的拷贝构造和移动构造函数
-
可以看到,vector的移动构造只是进行了指针交换,所以速度极快。
-
所以,重中之重,移动构造之后原变量已经不可用了,切记!!!
-

-