C语言知识点
|
|
-
char数据类型为一个字节大小
-
数据类型占内存的位数实际上与操作系统的位数和编译器(不同编译器支持的位数可能有所不同)都有关 ,具体某种数据类型占字节数得编译器根据操作系统位数两者之间进行协调好后分配内存大小。具体在使用的时候如想知道具体占内存的位数通过 sizeof(int) 可以得到准确的答案。
-
在GCC编译器下32位机器和64位机器各个类型变量所占字节数:
| 变量类型 | 32 | 64 |
|---|---|---|
| char | 1 | 1 |
| short int | 2 | 2 |
| int | 4 | 4 |
| long | 4 | 8 |
| long long int | 8 | 8 |
| char*——即指针 | 4 | 8 |
| float | 4 | 4 |
| double | 8 | 8 |
需要说明一下的是指针类型存储的是所指向变量的地址,所以32位机器只需要32bit,而64位机器需要64bit。
- sizeof() 以字节为单位返回运算对象的大小,返回值类型为size_t,在C语言的定义为,即无符号短整型。char []数组的末尾有一个'\0',包括最后的
\0。typedef unsigned int size_t;
- 1字节(byte) = 8位(bit)
- 在16位的系统中(比如8086微机) 1字 (word)= 2字节(byte)= 16(bit)
- 在32位的系统中(比如win32) 1字(word)= 4字节(byte)=32(bit)
- 在64位的系统中(比如win64)1字(word)= 8字节(byte)=64(bit)
- strlen() 返回字符数组的字符长度,但是数组里面末尾的空字符'\0',不算进去
|
|
|
|
- getchar()和putchar()函数
- getchar:该函数以无符号 char 强制转换为 int 的形式返回读取的字符,如果到达文件末尾或发生读错误,则返回 EOF
- putchar:该函数以无符号 char 强制转换为 int 的形式返回写入的字符,如果发生错误则返回 EOF。
|
|
c++语言基础
cout
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15#include <iostream> #include <iomanip>//注意加这个头文件,才能设置格式 using namespace std; int main() { float a = 3.1434727443475; cout << setprecision(9) << a << endl; cout << setiosflags(ios::fixed) << setprecision(9) << a << endl; //输出16进制、8进制 int b = 158; cout << hex << b << endl; cout << oct << b << endl; cout << dec << b << endl; return 0; } -

printf
| %d | 以十进制形式输出有符号整数 |
|---|---|
| %u | 以十进制形式输出无符号整数 |
| %o | 以八进制形式输出无符号整数 |
| %x | 以十六进制输出无符号整数 |
| %s | 输出字符串 |
| %f | 以小数形式输出浮点型数据 |
递归-hanoi-tower
-
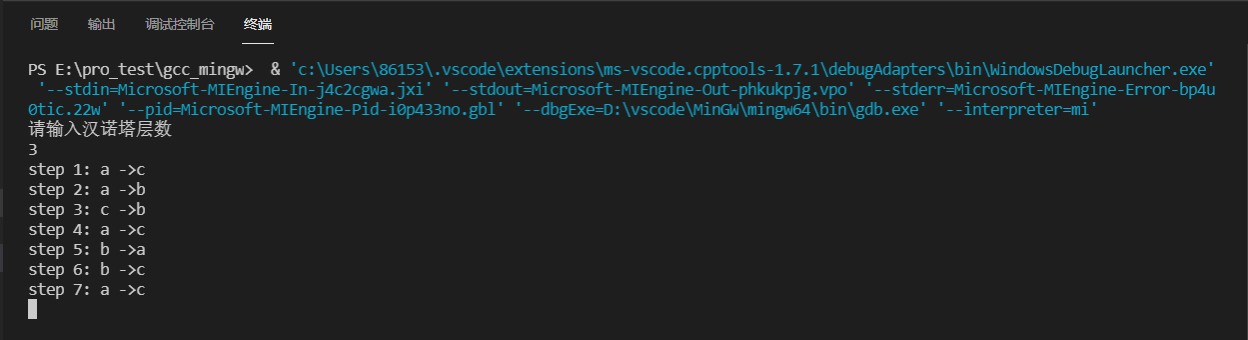
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38#include <iostream> #include <iomanip> using namespace std; long step; /* param @amount:移动的层数 param @a b c:从a移动到c,b为辅助杆 */ void move_Hanoi(int amount, char a, char b, char c) { if (amount == 1) { cout << "step " << ++step << ": " << a << " ->" << c << endl; } else { //将n-1从a移动到b,借助没有任何东西的c move_Hanoi(amount - 1, a, c, b); //移动最后一个大的从a到c cout << "step " << ++step << ": " << a << " ->" << c << endl; //将n-1从b移动到c,借助没有任何东西的b move_Hanoi(amount - 1, b, a, c); } } int main() { cout << "请输入汉诺塔层数" << endl; int height; cin >> height; char a, b, c; a = 'a'; b = 'b'; c = 'c'; step = 0; move_Hanoi(height, a, b, c); return 0; } -
本质是两层塔的移动
编码问题——乱码根源
- 字节:字节(byte) = 8位(bit)
- 字符:字符是指计算机中使用的字母、数字、字和符号,是数据结构中最小的数据存取单位。如a、A、B、b、大、+、*、%等都表示一个字符;
|
|
- 字符集:字符集是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同。常见字符集名称:
|
|
-
乱码产生的原因主要有两个,
- 一是文本字符编码过程与解码过程使用了不同的编码方式。
- 二是使用了缺少某种字体库的字符集引起的乱码。
-
[ UTF-8 ] 和「带 BOM 的 UTF-8」的区别就是有没有 BOM,即文件开头有没有U+FEFF。
-
UTF-8 BOM
UTF-8 BOM又叫UTF-8 签名,UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。当文本程序读取到以 EF BB BF开头的字节流时,就知道这是UTF-8编码了。Windows就是使用BOM来标记文本文件的编码方式的,总的来说,UTF-8 BOM就是微软的习惯,如果在windows编写了xml、SQL文件,编码为带BOM的UTF-8,在linux上读取一般会出问题。
-
BOM即Byte Order Mark字节序标记。BOM是为UTF-16和UTF-32准备的,用户标记字节序(byte order)。所以编码一定要坚持用UTF-8,但是在windows,使用VS,一般要用936或者65001。
-
在windows上编程C/C++程序,常用的IDE为visual studio和clion以及Qt Creator,但是
- windows控制台的默认编码方式跟随系统,即GBK 936;
- visual要更改编码为GBK 936或者utf-8带BOM,控制台程序跟随系统,同样是GBK 936;
- clion默认编码为utf-8,但是控制台输出为跟随系统的GBK,所以才会有控制台输出中文乱码的问题;
- Qt Createor的默认编码是utf-8。
-
pycharm默认设置均为utf-8,包括输出台,所以不存在乱码现象。
-
windows操作系统,在Visual Studio 编写C++/C#/C程序时,默认是应该是utf-8不带签名,但是控制台是GBK,所以为了可以正常输出,应该把默认编码改为utf-8带BOM或者936GBK,此时输出不会报错。但是输出txt或者其他数据文件的时候,应该要注意输出为utf-8(不带签名)的格式。
-
MSVC: 即Microsoft Visual C++ Compiler,即微软自己的编译器。我们下载Windows下的OpenCV时,会带两个文件夹VC14,VC15(分别与Visual Studio的版本有对应关系),这两个文件夹下的库可以直接运行不需要编译,将VS作为Qt的开发环境也是使用这个编译器的缘故。
-
MinGW: 我们都知道GNU在Linux下面鼎鼎大名的gcc/g++,MinGW则是指Minimalist GNU for Windows的缩写。它是将GNU开发工具移植到Win32平台下的产物,即一套Windows上的GNU工具集。用其开发的程序不需要额外的第三方DLL支持就可以在Windows下运行,相对地,不使用动态库导致的就是编译出来的程序大很多,所以也是可以设置使用静态库的。
更改windows控制台编码方式(治本)
-
打开cmd,输入chcp,可以查看编码方式
- 936:GBK编码
- 65001:utf-8
-
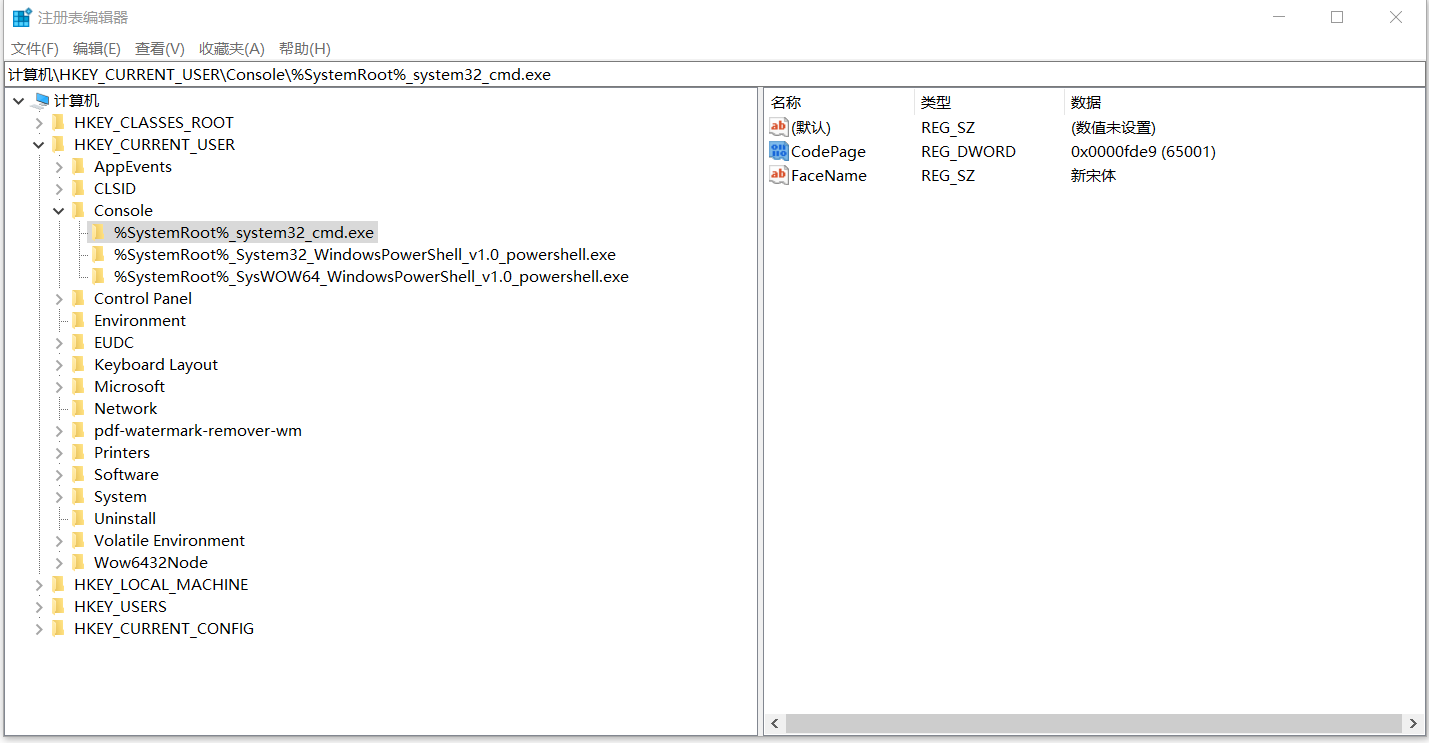
win+R,输入regedit,打开注册表,打开地址
- 计算机\HKEY_CURRENT_USER\Console%SystemRoot%_system32_cmd.exe
- 点击CodePage,更改数值,即可更改cmd控制台的编码方式
指针
- *和&的运算符的应用
|
|
- 动态内存的申请
|
|
- C++的是new,但是c语言的是malloc;注意两者之间有很大的区别。
结构体struct
|
|
类
-
变量类别private public protected
-
成员函数
-
构造函数
- 带默认参数的
- 没有默认参数的
- 重载的构造函数
- 包含初始化列表的
-
析构函数
-
每一个对象都能通过 this 指针来访问自己的地址。this 指针是所有成员函数的隐含参数
面向对象编程
1.继承和多继承
2.虚函数和纯虚函数和抽象类
3.模板和STL
常见的小问题
- 二维数组实际上是一维指针,涉及内存分配的连续性问题
- 指针数组才是二维指针
- 局部变量来说,是存储在桟内存中,桟内存是程序结束后自动释放的,而堆内存需要显式释放。new申请的就是堆内存,delete的作用是释放之前用new在堆申请的内存,这段代码原本申请了一个内存,然后用指针a指向该内存,可以接下来却直接用a指向了j,这样一来,就没有指针指向之前用new申请的内存了,也就是说你再也没有办法释放之前申请的内存了,即内存泄漏了。正确做法是在将a指向新地址前把它delete。
|
|
-
以后写可以偏向于share_ptr<类型> 名称。智能指针
-
没看到有动态二维智能指针,可以先看看,其实一维即二维
-
vector更适合在类里面做数组,因为这样就没有了内存泄漏的问题了,在一定程度上可以解决我们调用指针的麻烦和困扰。
-
子函数调用动态分配内存
- 采用全局变量指针,但是增大开销
- 参考网址设置新的函数格式,采用二级指针,或者指针的引用,即函数的输入参数
- 使用智能指针,不过好像不支持动态数组,unique需要自己手动释放;share在C++17后支持。但是不能引用到fread函数中。
- 直接返回一个指针变量,但注意,返回后应该把类中原函数指针设为NULL,不然会变成野指针。
- 静态变量也可以。
-
NULL即是(void *)0;对于c语言才是。
-
C++最大的坑就是内存管理问题。
-
头文件可以using namespace std;但最后还是直接使用命名空间
std::,防止多次引用编译错误。 -
vector访问允许下标,但是中间数据的删除会有很大的时间复杂度,且浪费空间。
-
堆栈溢出的问题,先在项目设置为200000000吧,四个设置项,单位是字节
-
tab右移,shift+tab左移
-
0x0F43B87C (ucrtbased.dll)处引发的异常: 0xC0000005:怎么解决?
-
scanf_s在录入字符串的时候都要指定缓冲区的大小:
1scanf_s("%s", card_name, 2);
-
迭代器(STL迭代器)iterator
- 要访问顺序容器和关联容器中的元素,需要通过“迭代器(iterator)”进行。迭代器是一个变量,相当于容器和操纵容器的算法之间的中介。迭代器可以指向容器中的某个元素,通过迭代器就可以读写它指向的元素。从这一点上看,迭代器和指针类似。
- 可以参考这个介绍网站
- vetor.begin 返回第一个元素的迭代器
- vetor.end 返回最后一个元素的迭代器
- vetor.front 返回第一个元素的引用
- vetor.back 返回当前vector容器中末尾元素的引用
- vec1.size() 就是二维数组”的行数
- vec1[0].size() 就是”二维数组”的列
函数值返回的机制
return这一段中,可以看到z中计算好的数据移到eax寄存器中,由eax寄存器将值带给调用该函数的函数变量。
在返回这些类型时,系统将该函数所要返回的值移到寄存器中,栈顶指针下移,栈中的局部变量都死亡,寄存器中的数据再返回给调用该函数的函数所要接收的变量。
|
|
堆和栈的区别
|
|
这条短短的一句话就包含了堆与栈,看到new,我们首先就应该想到,我们分配了一块堆内存,那么指针p呢?他分配的是一块栈内存,所以这句话的意思就是:在栈内存中存放了一个指向一块堆内存的指针p。在程序会先确定在堆中分配内存的大小,然后调用operator new分配内存,然后返回这块内存的首地址,放入栈中。
C++变量储存位置
-
栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数等。
-
堆,就是那些由malloc分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个malloc就要对应一个free。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
-
自由存储区 free store,就是那些由new等分配的内存块,他和堆是十分相似的,不过它是用delete来结束自己的生命的。不是操作系统的内存概念,是c++自定义的抽象概念。看编译器,自由存储区可以是堆,甚至可以是静态存储区。
-
全局/静态存储区,全局变量和静态变量被分配到同一块内存中,在以前的C语言中,全局变量又分为初始化的和未初始化的,在C++里面没有这个区分了,他们共同占用同一块内存区。
-
常量存储区,这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改(当然,你要通过非正当手段也可以修改)。
-
所有的函数都是存放在代码区的,不管是全局函数,还是成员函数。静态函数也不例外。
-
1 2 3 4 5 6一个由C/C++编译的程序占用的内存分为以下几个部分: 1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。 2、堆区(heap)— 由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。 3、全局区(静态区)(static)— 全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后由系统释放。 4、文字常量区 — 常量字符串就是放在这里的,程序结束后由系统释放 。 5、程序代码区 — 存放函数体的二进制代码。
C++变量存储方法
在C++中变量除了有数据类型的属性之外,还有存储类别(storage class) 的属性。存储类别指的是数据在内存中存储的方法。存储方法分为静态存储和动态存储两大类。具体包含4种:自动的(auto)、静态的(static)、寄存器的(register)和外部的(extern)。根据变量的存储类别,可以知道变量的作用域和存储期。
-
自动变量auto
- 储存在栈中
- 默认都是自动变量,可省略,注意和auto关键字不同
- auto char c='s';
-
静态变量static
-
生命周期为整个程序运行时间
-
编译器会为静态局部变量赋值为0
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14//静态局部变量 #include<iostream> using namespace std; int add(int b){ static int n=0; n=n+b; return n; } int main(){ for(int i=1;i<4;++i){ cout<<i<<"次:"<<add(i)<<endl; } return 0; } -

-
-
外部变量extern
- 作用:声明其他源文件的全局变量
VS中的空项目报错处理
|
|
- 处理方式
- 在项目属性\CC++\预处理器\预处理器定义\里添加
_WINDOWS - 在项目属性\链接\系统\里选择 窗口
(/SUBSYSTEM:WINDOWS)
- 在项目属性\CC++\预处理器\预处理器定义\里添加
C++语言“_T”是什么意思
-
Visual C++里边定义字符串的时候,用_T来保证兼容性,VC支持ascii和unicode两种字符类型,用_T可以保证从ascii编码类型转换到unicode编码类型的时候,程序不需要修改。
-
如果将来你不打算升级到unicode,那么也不需要_T,例如_T("hello world"):
- 在ansi的环境下,它是ansi的;
- 如果在unicode下,那么它将自动解释为双字节字符串,既unicode编码。
- 这样做的好处,不管是ansi环境,还是unicode环境,都适用。
MFC编码问题
-
TCHAR 就是当你的字符设置为什么就是什么
- 例如:程序编译为 ANSI, TCHAR 就是相当于 CHAR
- 当程序编译为 UNICODE, TCHAR 就相当于 WCHAR
-
char :单字节变量类型,最多表示256个字符,
-
wchar_t :宽字节变量类型,用于表示Unicode字符。
-
所以,MFC中一般使用TCHAR和_T()描述字符串,当使用unicode字符编码时。
预编译头:stdafx.h头文件是干什么用的
- 预编译是为了提高编译速度!
- 编译入预编译头的.h,.c,.cpp文件在整个编译过程中,只编译一次,如预编译头所涉及的部分不发生改变的话,在随后的编译过程中此部分不重新进行编译。进而大大提高编译速度,且便于对头文件进行管理,也有助于杜绝重复包含问题。
- 在MFC项目中,一般都会包含stdafx.h和stdafx.cpp文件,MFC项目要使用的头文件比如windows.h等都比较大,如果每个.cpp文件都要包含这些头文件的话,编译的时候速度就会很慢。
- 所以微软采取了这样一个策略。在stdafx.h中默认包含了这些头文件,在编译之前会采用预编译的方法。也就是先把这些头文件所包含的信息编译成二进制文件储存起来,储存的文件后缀名为.pch。所以这个文件通常比较大,因为包含的信息较多。
- 有stdafx.h头文件,还会有一个stdafx.cpp文件,这样编译器在遇到这个文件时,就会先进行预编译处理。这样其他cpp文件只需要包含stdafx.h头文件就可以使用MFC的头文件了。
- 生成的.pdb文件,即为预编译头,一般在debug或者release文件夹下面。
- 使用方式:
-
添加一个stdafx.h文件(名字随便取, 这里用了VS默认提供的名称), 在这个.h文件里include要使用的头文件(一般是外部的库, 自己写的不常变的头文件也可以加进来)
-
添加一个stdafx.cpp文件, 并include "stdafx.h"
-
项目属性-->c/c++-->Precompiled设置为"使用/Y", stdafx.h
-
stdafx.cpp属性-->c/c++->Precompiled设置为”创建“, stdafx.h
debug和release的区别
C/C++编译器编译有各种优化级别,编译器优化级别大体如下:
- O0(默认选项):不开启优化,方便功能调试
- Og:方便调试的优化选项(比O1更保守)
- O1:保守的优化选项,打开了四十多个优化选项
- O2:常用的发布优化选项,在O1的基础上额外打开了四十多个优化选项,包括自动内联等规则
- Os:产生较小代码体积的优化选项(比O2更保守)
- O3:较为激进的优化选项(对错误编码容忍度最低),在O2的基础上额外打开了十多个优化选项
- Ofast:打开可导致不符合IEEE浮点数等标准的性能优化选项。
编译器有这么多优化级别,Debug版本和Release版本其实就是优化级别的区别,Debug称为调试版本,编译的结果通常包含有调试信息,没有做任何优化,方便开发人员进行调试,Release称为发布版本,不会携带调试信息,同时编译器对代码进行了很多优化,使代码更小,速度更快,发布给用户使用,给用户使用以更好的体验。但Release模式编译比Debug模式花的时间也会更多。
Debug模式下在内存分配上有所区别,在我们申请内存时,Debug模式会多申请一部分空间,分布在内存块的前后,用于存放调试信息。
对于未初始化的变量,Debug模式下会默认对其进行初始化,而Release模式则不会,所以就有个常见的问题,局部变量未初始化时,Debug模式和Release模式表现有所不同。
Debug模式以32字节为单位分配内存,例如当申请24字节内存时,Release模式下是正常的分配24字节,Debug模式会分配32字节,多了8字节,所以有些数组越界问题在Debug模式下可以安全运行,Release模式下就会出问题。
Debug模式下可以使用assert,运行过程中有异常现象会及时crash,Release模式下模式下不会编译assert,遇到不期望的情况不会及时crash,稀里糊涂继续运行,到后期可能会产生奇奇怪怪的错误,不易调试,殊不知其实在很早之前就出现了问题。编译器在Debug模式下定义_DEBUG宏,Release模式下定义NDEBUG宏,预处理器就是根据对应宏来判断是否开启assert的。
数据溢出问题,在一个函数中,存在某些从未被使用的变量,且函数内存在数据溢出问题,在Debug模式下可能不会产生问题,因为不会对该变量进行优化,它在栈空间中还是占有几个字节,但是Release模式下可能会出问题,Release模式下可能会优化掉此变量,栈空间相应变小,数据溢出就会导致栈内存损坏,有可能会产生奇奇怪怪的错误。
常见VS调试错误
-
warning: C4819: 该文件包含不能在当前代码页(936)中表示的字符。请将该文件保存为 Unicode 格式以防止数据丢失
- 注意,以上错误是因为使用微软自带的windows的编译器MSVC才导致的错误
- 解决办法:
- 如果是 Qt Creator,设置【项目编辑器】,【文件编码】为:UTF-8,【UTF-8 BOM】:如果编码是UTF-8则添加。最后随便改动一下出现警告的文件保存,就会保存为:UTF-8 带BOM 格式。
- 如果是 VS IDE,打开有该warning的文件,点击【文件】选【高级保存选项】,改变编码格式为【简体中文(GB2312)- 代码页936】或【Unicode(UTF-8 带签名)-代码页65001】,保存。
-
error LNK2019: 无法解析的外部符号
- 解决办法,添加附加库目录和附加依赖项,即.lib文件
-
LINK : warning LNK4098: 默认库“MSVCRT”与其他库的使用冲突;请使用 /NODEFAULTLIB:library
- 解决办法:
- 1、【项目】->【属性】->【配置属性】->【C/C++】->【代码生成】->【运行时库】,设置为“多线程DLL(/MD)
- 2、【项目】->【属性】->【配置属性】->【链接器】->【输入】->【忽略指定库】,输入:msvcrt.lib
- 解决办法:
C++数学计算
|
|
2、双曲函数 Hyperbolic functions
|
|
3、指数函数与对数函数 Exponential and logarithmic functions
|
|
4、幂函数 Power functions
|
|
5、误差与伽马函数 Error and gamma functions
|
|
6、四舍五入与余数函数Rounding and remainder functions
|
|
7、绝对值、最小、最大 Absolute、Minimum, maximum
|
|
|
|
VS包含目录、库目录、附加包含目录、附加库目录、附加依赖项
-
以上均在 “项目->属性->配置属性"下进行配置
-
配置属性->VC++目录:
- 包含目录:寻找#include<xxxx.h>中的xxxx.h的搜索目录
- 库目录:寻找.lib文件的搜索目录
-
配置属性->C/C++->常规->附加包含目录:
- 寻找#include<xxxx.h>中的xxxx.h的搜索目录(每一项对应一个文件夹XXXX,文件夹中包含了编译时所需的头文件,使用时直接#include
即可)
- 寻找#include<xxxx.h>中的xxxx.h的搜索目录(每一项对应一个文件夹XXXX,文件夹中包含了编译时所需的头文件,使用时直接#include
-
配置属性->链接器->常规->附加库目录:
- 寻找.lib文件的搜索目录
-
配置属性->链接器->输入->附加依赖项:
- lib库(C++的库会把函数、类的声明放在.h中,实现放在.cpp或.cc中。编译之后,.cpp,.cc,.c会被打包成一个.lib文件,这样可以保护源代码)
-
包含目录和附加包含目录(库目录和附加库目录)的区别:
-
包含目录:修改了系统的include宏的值,是全局的;
-
附加包含目录:用于当前项目,对其他项目没有影响。
-
(库目录和附加库目录的区别同上)
-
可知包含目录和附加包含目录(库目录和附加库目录)的区别主要在于全局还是当前,那么当需要对某工程添加这些目录时,通常情况下,都是在附加包含目录和附加库目录中添加的
-
-
要使用一个库,除了要include其头文件以外(或添加附加包含目录),还要在链接过程中把lib加进去(附加库目录、附加依赖项)。
-
添加方法:
-
附加包含目录---添加工程的头文件目录:
- 项目->属性->配置属性->C/C++->常规->附加包含目录:加上头文件的存放目录;
-
附加库目录---添加文件引用的lib静态库路径:
- 项目->属性->配置属性->链接器->常规->附加库目录:加上lib文件的存放目录;
-
附加依赖项---添加工程引用的lib文件名:
- 项目->属性->配置属性->链接器->输入->附加依赖项:加上lib文件名。
-
-
当需要向项目中添加.dll动态链接库时,直接将需要添加的.dll文件拖拽到项目生成的.exe所在的文件夹下即可(项目->属性->配置属性->链接器->输出文件,可以看到.exe生成在哪个目录下)。
-
添加上述几个目录的路径的时候,可以看到$(xxxx),此即为宏定义,可以点开看到代表的位置。
-
一般的x86(win32)生成的文件在release和debug文件下。
-
而x64生成的现有x64文件夹,然后里面再有release和debug两个文件夹。
-
源代码下的此处的Debug/release(或者x64里面的两个Debug/release文件夹)仅仅存放中间编译结果obj,不存放exe和dll之类的东西,打开此处的Debug文件夹,可以看到主要生成了三类文件:
- 日志文件 Project1.tlog和Project1.log为日志文件;
- obj文件 项目中的每个cpp文件都会生成对应的obj文件;
- idb文件 这是最小生成使用的文件,保存之前的编译结果,可以极大缩短编译时间。
动态链接库和静态链接库
-
首先,介绍下动态链接库和静态链接库的概念,两者都是代码共享的方式。
-
静态库:在链接步骤中,链接器将从库文件中取得代码,复制到可执行文件中,此种称为静态库。其特点是可执行文件中包含了库代码的一份完整拷贝;缺点就是被多次使用就会有多份冗余拷贝。即静态库中的指令都全部被直接包含在最终生成的 EXE 文件中了。在vs中新建生成静态库的工程,编译生成成功后,只产生一个.lib文件
-
动态库:动态链接库是一个包含可由多个程序同时使用的代码和数据的库,DLL不是可执行文件。动态链接提供了一种方法,使进程可以调用不属于其可执行代码的函数。函数的可执行代码位于一个 DLL 中,该 DLL 包含一个或多个已被编译、链接并与使用它们的进程分开存储的函数。在vs中新建生成动态库的工程,编译成功后,产生一个.lib文件和一个.dll文件
-
-
静态库和动态库的LIB文件有什么区别呢?
-
静态库中的LIB:该LIB包含函数代码本身(即包括函数的索引,也包括实现),在编译时直接将代码加入程序当中。
-
动态库中的LIB:该LIB包含了函数所在的DLL文件和文件中函数位置的信息(索引),函数实现代码由运行时加载在进程空间中的DLL提供。
-
备注:LIB是编译时用到的,DLL是运行时用到的。如果要完成源代码的编译,只需要LIB;如果要使动态链接的程序运行起来,只需要DLL。
-
-
参考链接csdn_blog
VS配置opencv(x86版本)
-
1:系统环境变量配置:path添加路径
- 我的电脑—〉属性—〉高级系统设置—〉环境变量—〉path中添加“...opencv\build\x86\vc15\bin”

-
2:添加包含目录
- 视图->属性管理器->Debug|Win32->右键Microsoft.Cpp.Win32.user属性
- VC++目录->包含目录(添加)
- D:\opencv\build\include
- D:\opencv\build\include\opencv2
- VC++目录->库目录(添加)
- D:\opencv\build\x86\vc15\lib
- VC++目录->包含目录(添加)
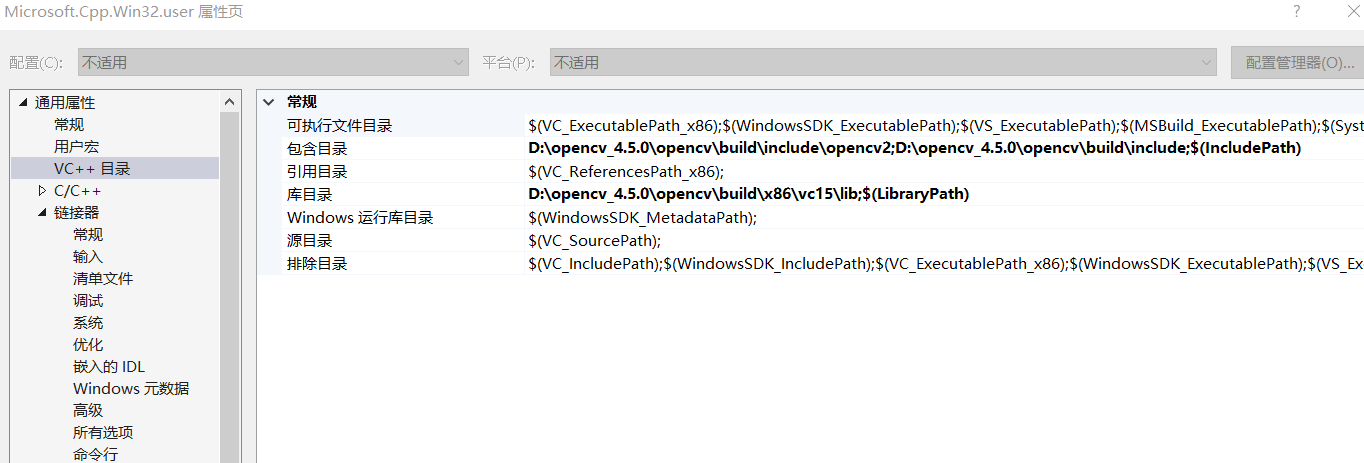
- 视图->属性管理器->Debug|Win32->右键Microsoft.Cpp.Win32.user属性
-
3:添加附加依赖项
- 视图->属性管理器->Debug|Win32->右键Microsoft.Cpp.Win32.user属性
- 链接器->输入->附加依赖项
- 添加opencv_world450d.lib(debug版本)
- 添加opencv_world450.lib(release版本)
- 注意不同的调试要更换依赖项。切记!!!
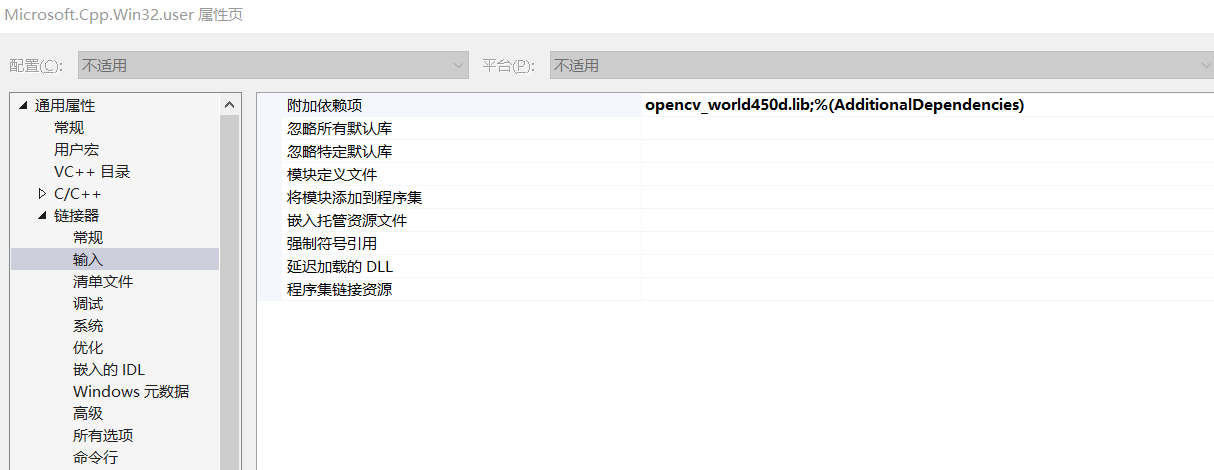
- 视图->属性管理器->Debug|Win32->右键Microsoft.Cpp.Win32.user属性
-
对于X64版本的opencv配置大同小异,与上面的步骤基本一致。
Opencv源码编译x86版本
-
下载源码安装
-
cmake进行configure(注意选好vs配置,默认平台是win32)
- 同时BUILD里面一定要勾选BUILD_opencv_world
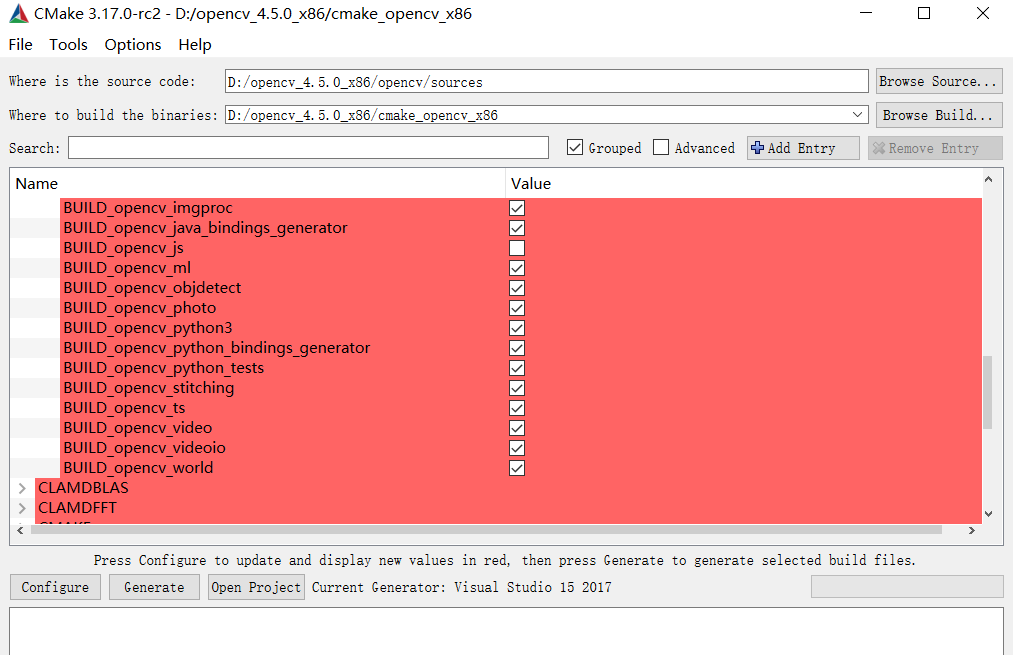
-
一定要翻墙之后再点击Configure;没有错误出现Configure Done后,再点击Generate;Generate成功后点击Open Project
-
VS中选择debug和win32进行生成
-
点击生成->批生成,选择INSTALL,生成
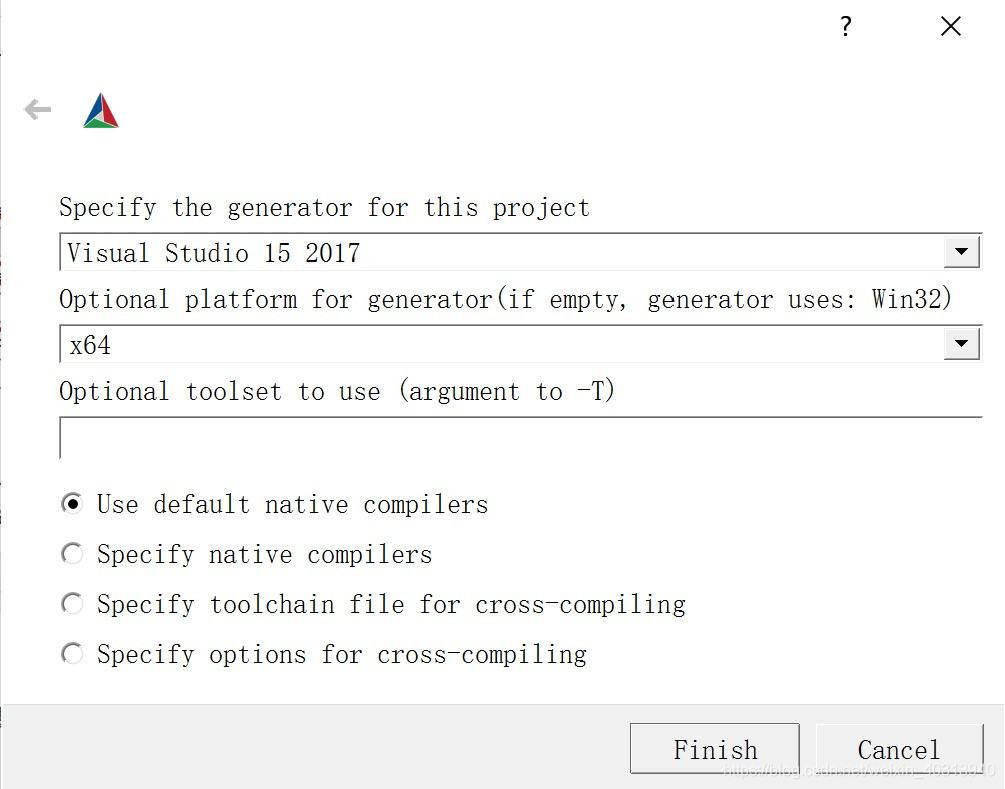
-
对于配置X64来说,cmake的配置选x64平台,批生成也有所区别



Win32、x86、x64的区别
- win32是指windows 32位的操作系统,顾名思义是支持32位CPU的操作系统。
- x86是指CPU的位,X86是指32位的CPU。
- x64是指64位CPU。
- 一个是指操作系统,一个是指CPU,x86的范围比win32的范围要广。
- 在VS中,同一个解决方案里可以同时存在不同的工程,他们可以分别配置为win32、x86等不同的配置。其中,x86是C++的叫法,而win32是C#的叫法。是不同编程语言对平台的名称描述。这种配置取决于编译器,如果有一个普通项目,它将生成 x86/x64 代码,对于智能设备项目是另外一回事。
C++头文件顺序问题
-
综合来看,我们应该以这样的方式来#include头文件: 从最特殊到最一般,也就是, #include "本类头文件" #include "本目录头文件" #include "自己写的工具头文件" #include "第三方头文件" #include "平台相关头文件" #include "C++库头文件" #include "C库头文件" 头文件包含顺序有最特殊到最一般:使用短路编译以加快编译出错的过程。
参考: 《C++编程思想第二版》p432
-
google风格
-
使用标准的头文件包含顺序可增强可读性, 避免隐藏依赖:
- 相关头文件(cpp对应的h)
- C 库,
- C++ 库,
- 其他库的 .h,
- 本项目内的 .h。
-
举例来说,
google-awesome-project/src/foo/internal/fooserver.cc的包含次序如下:1 2 3 4 5 6 7 8 9 10 11#include "foo/public/fooserver.h" // 优先位置 #include <sys/types.h> #include <unistd.h> #include <hash_map> #include <vector> #include "base/basictypes.h" #include "base/commandlineflags.h" #include "foo/public/bar.h"
-
volatile
-
volatile 是一个类型修饰符。volatile 的作用是作为指令关键字,确保本条指令不会因编译器的优化而省略
-
volatile 的特性:
- 保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。(实现可见性)
- 禁止进行指令重排序。(实现有序性)
- volatile 只能保证对单次读/写的原子性。i++ 这种操作不能保证原子性。
- 关于volatile 原子性可以理解为把对volatile变量的单个读/写,看成是使用同一个锁对这些单个读/写操作做了同步,就跟下面的SoWhat跟SynSoWhat功能类似。
c++的文件路径表示
-
c++中 \ 是一种转义字符,他表示一个 \ ,就像 \n 表示回车一样。
-
绝对路径表示相对容易,例如:
1 2pDummyFile = fopen("D:\\vctest\\glTexture\\texture\\dummy.bmp", "rb"); //给出了从盘符开始的全部路径,这里需要注意的是“\”要用双斜线"\\\\"或者反斜线“/” -
vc工程默认访问的目录是工程目录(即c++文件所在目录),相对路径有以下多种形式:
-
1 2 3 4 5 6 7 8 9 10 11- pDummyFile = fopen("dummy.bmp", "rb"); //bmp文件就在vc工程目录下,和dsw文件同属一个目录。 - pDummyFile = fopen("..\\texture\\dummy.bmp", "rb"); //表示bmp文件在工程目录的同级目录texture中,因此路径是先退出工程目录再进入texture目录访问到bmp文件。 “..”表示退到当前目录的上一级目录(父目录)。 - pDummyFile = fopen(".\\texture\\dummy.bmp", "rb"); //表示bmp文件就在工程目录的子目录texture中。 “.”表示当前默认目录,即工程目录,然后在进入其子目录texture访问到文件。 - pDummyFile = fopen("dummy.bmp", "rb"); //bmp文件就在vc工程目录下,和dsw文件同属一个目录。 - pDummyFile = fopen("..\\texture\\dummy.bmp", "rb"); //表示bmp文件在工程目录的同级目录texture中,因此路径是先退出工程目录再进入texture目录访问到bmp文件。 “..”表示退到当前目录的上一级目录(父目录)。 - pDummyFile = fopen(".\\texture\\dummy.bmp", "rb"); //表示bmp文件就在工程目录的子目录texture中。 “.”表示当前默认目录,即工程目录,然后在进入其子目录texture访问到文件。 -
注意,对相对路径而言,路径表示中的“\”也要用双斜线 "\\" 或者反斜线 “/”
指向函数的指针 ------ 函数指针(function pointer)
-
类型 (*指针变量名)(参数列表);
-
例如:
int (*p)(int i,int j);
p是一个指针,它指向一个函数,该函数有2个整形参数,返回类型为int。p首先和*结合,表明p是一个指针。然后再与()结合,表明它指向的是一个函数。指向函数的指针也称为函数指针。
-
1 2 3 4 5 6 7int get_max(int i,int j) { return i>j?i:j; } int (*p)(int,int); p = get_max; -
在QT开发中,遇到自定义信号和自定义槽函数重载冲突,需要函数指针。
指针函数——返回值是指针
- int *fun(int x,int y);
- 其返回值是一个 int 类型的指针,是一个地址。
- 与函数指针有很大区别。
C++类型强制转换
为了使潜在风险更加细化,使问题追溯更加方便,使书写格式更加规范,C++对类型转换进行了分类,并新增了四个关键字来予以支持,它们分别是:
| 关键字 | 说明 |
|---|---|
| static_cast | 用于良性转换,一般不会导致意外发生,风险很低。 |
| const_cast | 用于 const 与非 const、volatile 与非 volatile 之间的转换。 |
| reinterpret_cast | 高度危险的转换,这种转换仅仅是对二进制位的重新解释,不会借助已有的转换规则对数据进行调整,但是可以实现最灵活的 C++ 类型转换。 |
| dynamic_cast | 借助 RTTI,用于类型安全的向下转型(Downcasting)。 |
这四个关键字的语法格式都是一样的,具体为:
|
|
newType 是要转换成的新类型,data 是被转换的数据。例如,老式的C风格的 double 转 int 的写法为:
|
|
C++ 新风格的写法为:
|
|
static_cast 关键字
static_cast 只能用于良性转换,这样的转换风险较低,一般不会发生什么意外,例如:
- 原有的自动类型转换,例如 short 转 int、int 转 double、const 转非 const、向上转型等;
- void 指针和具体类型指针之间的转换,例如
void *转int *、char *转void *等; - 有转换构造函数或者类型转换函数的类与其它类型之间的转换,例如 double 转 Complex(调用转换构造函数)、Complex 转 double(调用类型转换函数)。
需要注意的是,static_cast 不能用于无关类型之间的转换,因为这些转换都是有风险的,例如:
- 两个具体类型指针之间的转换,例如
int *转double *、Student *转int *等。不同类型的数据存储格式不一样,长度也不一样,用 A 类型的指针指向 B 类型的数据后,会按照 A 类型的方式来处理数据:如果是读取操作,可能会得到一堆没有意义的值;如果是写入操作,可能会使 B 类型的数据遭到破坏,当再次以 B 类型的方式读取数据时会得到一堆没有意义的值。 - int 和指针之间的转换。将一个具体的地址赋值给指针变量是非常危险的,因为该地址上的内存可能没有分配,也可能没有读写权限,恰好是可用内存反而是小概率事件。
static_cast 也不能用来去掉表达式的 const 修饰和 volatile 修饰。换句话说,不能将 const/volatile 类型转换为非 const/volatile 类型。
static_cast 是“静态转换”的意思,也就是在编译期间转换,转换失败的话会抛出一个编译错误。
下面的代码演示了 static_cast 的正确用法和错误用法:
|
|
- 注意点
- ①用于类层次结构中基类(父类)和派生类(子类)之间指针或引用的转换。
- 进行上行转换(把派生类的指针或引用转换成基类表示)是安全的;
- 进行下行转换(把基类指针或引用转换成派生类表示)时,由于没有动态类型检查,所以是不安全的。
- ②用于基本数据类型之间的转换,如把int转换成char,把int转换成enum。
- ③把空指针转换成目标类型的空指针。
- ④把任何类型的表达式转换成void类型。
- ①用于类层次结构中基类(父类)和派生类(子类)之间指针或引用的转换。
const_cast 关键字
const_cast 比较好理解,它用来去掉表达式的 const 修饰或 volatile 修饰。换句话说,const_cast 就是用来将 const/volatile 类型转换为非 const/volatile 类型。
下面我们以 const 为例来说明 const_cast 的用法:
|
|
&n用来获取 n 的地址,它的类型为const int *,必须使用 const_cast 转换为int *类型后才能赋值给 p。由于 p 指向了 n,并且 n 占用的是栈内存,有写入权限,所以可以通过 p 修改 n 的值。
有读者可能会问,为什么通过 n 和 *p 输出的值不一样呢?这是因为 C++ 对常量的处理更像是编译时期的#define,是一个值替换的过程,代码中所有使用 n 的地方在编译期间就被替换成了 100。换句话说,第 8 行代码被修改成了下面的形式:
cout<<"n = "<<100<<endl;
这样一来,即使程序在运行期间修改 n 的值,也不会影响 cout 语句了。
使用 const_cast 进行强制类型转换可以突破 C/C++ 的常数限制,修改常数的值,因此有一定的危险性;但是程序员如果这样做的话,基本上会意识到这个问题,因此也还有一定的安全性。
reinterpret_cast 关键字
reinterpret 是“重新解释”的意思,顾名思义,reinterpret_cast 这种转换仅仅是对二进制位的重新解释,不会借助已有的转换规则对数据进行调整,非常简单粗暴,所以风险很高。
reinterpret_cast 可以认为是 static_cast 的一种补充,一些 static_cast 不能完成的转换,就可以用 reinterpret_cast 来完成,例如两个具体类型指针之间的转换、int 和指针之间的转换(有些编译器只允许 int 转指针,不允许反过来)。
下面的代码代码演示了 reinterpret_cast 的使用:
|
|
可以想象,用一个 float 指针来操作一个 char 数组是一件多么荒诞和危险的事情,这样的转换方式不到万不得已的时候不要使用。将A*转换为int*,使用指针直接访问 private 成员刺穿了一个类的封装性,更好的办法是让类提供 get/set 函数,间接地访问成员变量。
dynamic_cast 关键字
dynamic_cast 用于在类的继承层次之间进行类型转换,它既允许向上转型(Upcasting),也允许向下转型(Downcasting)。向上转型(派生类转基类)是无条件的,不会进行任何检测,所以都能成功;向下转型(基类转派生类)的前提必须是安全的,要借助 RTTI 进行检测,所有只有一部分能成功。
dynamic_cast 与 static_cast 是相对的,dynamic_cast 是“动态转换”的意思,static_cast 是“静态转换”的意思。dynamic_cast 会在程序运行期间借助 RTTI 进行类型转换,这就要求基类必须包含虚函数;static_cast 在编译期间完成类型转换,能够更加及时地发现错误。
dynamic_cast 的语法格式为:
|
|
newType 和 expression 必须同时是指针类型或者引用类型。换句话说,dynamic_cast 只能转换指针类型和引用类型,其它类型(int、double、数组、类、结构体等)都不行。
对于指针,如果转换失败将返回 NULL;对于引用,如果转换失败将抛出std::bad_cast异常。
1) 向上转型(Upcasting)
向上转型时,只要待转换的两个类型之间存在继承关系,并且基类包含了虚函数(这些信息在编译期间就能确定),就一定能转换成功。因为向上转型始终是安全的,所以 dynamic_cast 不会进行任何运行期间的检查,这个时候的 dynamic_cast 和 static_cast 就没有什么区别了。
2) 向下转型(Downcasting)
向下转型是有风险的,dynamic_cast 会借助 RTTI 信息进行检测,确定安全的才能转换成功,否则就转换失败。那么,哪些向下转型是安全地呢,哪些又是不安全的呢?下面我们通过一个例子来演示:
|
|
这段代码中类的继承顺序为:A --> B --> C --> D。pa 是A*类型的指针,当 pa 指向 A 类型的对象时,向下转型失败,pa 不能转换为B*或C*类型。当 pa 指向 D 类型的对象时,向下转型成功,pa 可以转换为B*或C*类型。同样都是向下转型,为什么 pa 指向的对象不同,转换的结果就大相径庭呢?
在《C++ RTTI机制下的对象内存模型(透彻)》一节中,我们讲到了有虚函数存在时对象的真实内存模型,并且也了解到,每个类都会在内存中保存一份类型信息,编译器会将存在继承关系的类的类型信息使用指针“连接”起来,从而形成一个继承链(Inheritance Chain),也就是如下图所示的样子:
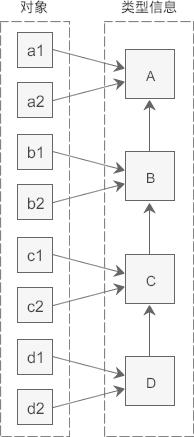
当使用 dynamic_cast 对指针进行类型转换时,程序会先找到该指针指向的对象,再根据对象找到当前类(指针指向的对象所属的类)的类型信息,并从此节点开始沿着继承链向上遍历,如果找到了要转化的目标类型,那么说明这种转换是安全的,就能够转换成功,如果没有找到要转换的目标类型,那么说明这种转换存在较大的风险,就不能转换。
对于本例中的情况①,pa 指向 A 类对象,根据该对象找到的就是 A 的类型信息,当程序从这个节点开始向上遍历时,发现 A 的上方没有要转换的 B 类型或 C 类型(实际上 A 的上方没有任何类型了),所以就转换败了。对于情况②,pa 指向 D 类对象,根据该对象找到的就是 D 的类型信息,程序从这个节点向上遍历的过程中,发现了 C 类型和 B 类型,所以就转换成功了。
总起来说,dynamic_cast 会在程序运行过程中遍历继承链,如果途中遇到了要转换的目标类型,那么就能够转换成功,如果直到继承链的顶点(最顶层的基类)还没有遇到要转换的目标类型,那么就转换失败。对于同一个指针(例如 pa),它指向的对象不同,会导致遍历继承链的起点不一样,途中能够匹配到的类型也不一样,所以相同的类型转换产生了不同的结果。
从表面上看起来 dynamic_cast 确实能够向下转型,本例也很好地证明了这一点:B 和 C 都是 A 的派生类,我们成功地将 pa 从 A 类型指针转换成了 B 和 C 类型指针。但是从本质上讲,dynamic_cast 还是只允许向上转型,因为它只会向上遍历继承链。造成这种假象的根本原因在于,派生类对象可以用任何一个基类的指针指向它,这样做始终是安全的。本例中的情况②,pa 指向的对象是 D 类型的,pa、pb、pc 都是 D 的基类的指针,所以它们都可以指向 D 类型的对象,dynamic_cast 只是让不同的基类指针指向同一个派生类对象罢了。
C++常见头文件
|
|
C++格式化字符串
- 采用stringstream数据流
|
|
-
C语言里面的sprintf也是格式化字符串的,但是不安全,已被淘汰
-
MFC里面的CString类的format函数也是格式化字符串的
-
Qt里面QString的库函数也有格式化字符串的
-
使用stringstream 将int or double 等类型转换成string,如果你想要转换多个int/double等类型的变量,而又始终用一个stringstream对象(避免总是创建stringstream的开销),那么你就需要在再一次用stringstream之前将stringstream的内容清空
1 2 3 4 5 6 7 8 9 10 11 12 13 14stringstream ss; int a = 100; double b = 100.2; ss << std::fixed << std::setprecision(2);//设置格式 ss << a << " " << b; cout << ss.str() << endl; ss.str("");//清空数据流 ss << 100; cout << ss.str(); /*输出 100 100.20 100 */ -
使用stringstream将string转为int / double
1 2 3 4 5 6 7 8 9string str("100.202"); stringstream ss1(str); double c; ss1 >> c; cout << c << endl; /*输出 100.202 */